
Abstract
Introduction
Recent years have witnessed a persistent threat to public mental health, especially during and after the COVID-19 pandemic. Posttraumatic stress disorder (PTSD) has emerged as a pivotal concern amidst this backdrop. Concurrently, machine learning (ML) techniques have progressively applied in the realm of mental health. Therefore, our present undertaking seeks to provide a comprehensive assessment of studies employing ML methods that use diverse data modalities on the classification of people with PTSD.
Methods and analysis
In pursuit of pertinent studies, we will search both English and Chinese databases from January 2000 to May 2022. Two researchers will independently conduct screening, extract data and assess study quality. We intend to employ the assessment framework introduced by Luis Francisco Ramos-Lima in 2020 for quality evaluation. Rate, standard error and 95% CIs will be utilized for effect size measurement. A Cochran's Q test will be applied to assess heterogeneity. Subgroup and sensitivity analysis will further elucidate the source of heterogeneity and funnel plots and Egger's test will detect publication bias.
Ethics and dissemination
This systematic review and meta-analysis does not encompass patient interactions or engagements with healthcare providers. The outcomes of this research will be disseminated through scholarly channels, including presentations at scientific conferences and publications in peer-reviewed journals.
Introduction
Posttraumatic stress disorder (PTSD) is a severe and significant psychiatric disorder that may occur in people who have experienced or witnessed a traumatic event or a series of circumstances. 1 According to the American Psychiatric Association (APA), PTSD affects approximately 3.5% of U.S. adults each year. The lifetime prevalence of PTSD in adolescents aged 13−18 is 8%. It is estimated that 1 in 11 people will be diagnosed with PTSD in their lifetime and women are twice as likely to have PTSD as men. 2 The World Mental Health Survey Consortium revealed that over 70% of the general population worldwide has experienced at least one traumatic event in their lifetime around the world. 3 PTSD is most commonly associated with combat veterans. It may also occur in people who have experienced natural disasters, serious accidents, sexual assault, historical trauma, intimate partner violence and bullying. 4
As the Diagnostic and Statistical Manual of Mental Disorders 5th edition (DSM-5) noted, PTSD is characterized by intrusive experience, persistent avoidance of stimuli, negative alterations in cognition and mood and marked alterations in arousal and reactivity related to the traumatic events. 5 The symptoms of PTSD can vary in severity and be long-lasting. 6 Some research studies have found that a significant proportion of individuals with PTSD continue to experience symptoms years after the traumatic events. 7 Therefore, the early detection of PTSD and early intervention are of great importance and essential for proper treatment.
Machine learning (ML) is a powerful analytic technique that can process multiple types of data. ML approaches are gradually being applied to classify, identify and predict individuals with various psychiatric disorders. 1 Recently, ML methods have been utilized in classifying PTSD individuals, 8 identifying the onset of their disorders, 9 regulating their emotion, 10 selecting treatment for them 11 and analyzing their multivariate predictors 12 and ranking predicting features. 13 The commonly used ML algorithms are logistic regression (LR), 14 random forest (RF) 15 and support vector machine (SVM). 16 We aim to review the literature on the use of ML techniques in the assessment of PTSD subjects to distinguish individuals with PTSD from other psychiatric disorders or from trauma-exposed and healthy controls or to optimize the predictors of PTSD.
Review question
What accuracy can ML techniques achieve in the classification of people with PTSD by analyzing different types of data?
Methods
The present protocol was formatted in accordance with the guidelines outlined in the Preferred Reporting Items for Systematic Reviews and Meta-Analysis Protocols (PRISMA-P) statement. 17 The completed PRISMA-P checklist is shown in Supplemental Table S1.
Eligibility criteria
As this is a retrospective study and does not involve direct patient participation, ethical approval and informed consent are not needed. The selection criteria of studies are defined according to the PICOTS framework as shown in Table 1.
Selection criteria of studies in PICOTS format.

Abbreviations: ML: machine learning; PTSD: posttraumatic stress disorder; AUC: area under the curve.
Population (P)
This study will consider individuals affected by PTSD after experiencing trauma, without imposing any demographic or health-related exclusions based on age, gender, ethnicity or other relevant factors. Trauma events include military missions, traffic accidents, abuse, etc.
Interventions (I)
Supervised, unsupervised, semi-supervised or ensemble ML models are all eligible interventions to classify PTSD individuals. For the sake of computational convenience, we will also verify the following three aspects. (a) A clear description of the ML model, (b) a clear description of the data type model used and (c) a clear description of the data amount processed by the model which determined performance metrics. Studies will be excluded if they did not apply ML approaches or report data type and amount clearly.
Outcomes (O)
The performance of ML models in discriminating PTSD will be measured by the best accuracy of all the models reported in one article. Other performance metrics, such as sensitivity, specificity, area under the curve (AUC) and positive and negative predictive values, if reported, will also be recorded. Studies reported no accuracy metrics will be excluded.
Timing frame (T)
Given the evolution of ML technology and its surge in the field of mental health in recent years, literature retrieval will be conducted from the year 2000 to the present cutoff date of the search (May 2022). Researches conducted outside this timeframe will be ineligible.
Settings (S)
Studies with PTSD as a dependent variable in both clinical and non-clinical settings will be included. Correlation studies, qualitative studies, case studies, protocols, meta-analysis, reviews, editorials, comments, letters and notes will be excluded.
Due to our language limitations, only studies of English and Chinese will be included.
Data sources
We will search both English and Chinese databases for relevant studies: PubMed, Embase, Scopus, PsycINFO and Cochrane Library for publications in English and China National Knowledge Infrastructure Database (CNKI), the Wanfang database and China Science and Technology Journal Database for publications in Chinese.
Search strategy
The search strategy will follow the PICOTS frame including terms relating to ML and PTSD and being strict to the time span. A systematic literature search will be carried out based on the following terms: ((“Machine Learning”[Mesh]) OR (“reinforcement learning”) OR (“Natural Language Processing”[Mesh]) OR ((“Deep Learning”[Mesh]) OR (“Hierarchical Learning”)) OR (“Unsupervised Machine Learning”[Mesh]) OR ((“Supervised Machine Learning”[Mesh]) OR (“semi-supervised learning”) OR (“semi-supervised machine learning”)) OR (“Big Data”[Mesh]) OR (“Artificial Intelligence”[Mesh])) AND ((“Stress Disorders, Post-Traumatic”[Mesh]) OR (“post traumatic stress disorder*”) OR (“posttraumatic stress disorder*”) OR (“post-traumatic stress disorder*”)). A comprehensive search for relevant literature will also be conducted, which will entail tracing the references of the included studies to identify potential eligible sources.
Study selection
The screening process for the present study will involve independent assessments of each article retrieved during the search phase by two researchers to determine whether they satisfy the predefined inclusion criteria and to exclude any irrelevant articles. Reasons for study exclusion will be documented. In case of disagreements between the two researchers, a third researcher will be consulted to adjudicate. All articles identified during the initial search will undergo a title and abstract screening, with subsequent full-text review of the remaining articles. The selection process will be recorded and explained in detail using a flow chart as suggested by Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020. A summarized PRISMA flow diagram is shown in Figure 1.

Flow diagram outlines of review process and study selection.
Data extraction and management
Two independent reviewers will be responsible for extracting relevant information from the included studies. They will draw piloting forms independently and check with each other when complete. Any discrepancies between reviewers will be resolved through discussion or, if necessary, a third reviewer will be consulted.
Data extraction will encompass four key domains: (a) study characteristics (authors, year of publication, data type, diagnostic PTSD tool); (b) participant information (sample size, diagnosis) and (c) models (machine learning model, model type, accuracy, other measures). (d) Additional information deemed pertinent to the study, including event details and accompanying commentary, will also be extracted. To ensure the completeness of data, we will contact the authors for any missing or unclear information by e-mail with a response time limit of 10 days. The explicit information of extracted data is shown in Table 2.
Proposed data extraction form and description.
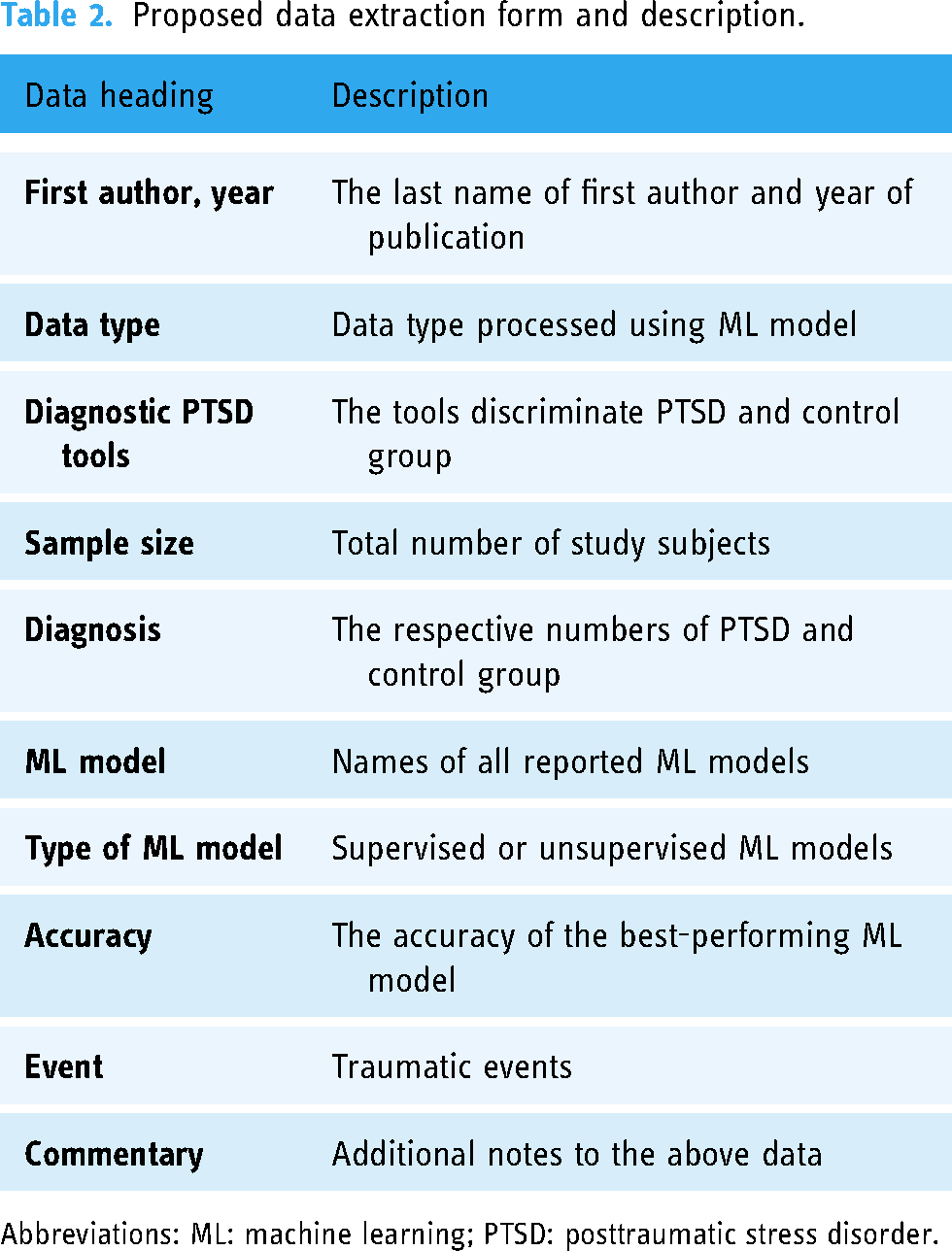
Abbreviations: ML: machine learning; PTSD: posttraumatic stress disorder.
Types of outcomes
The primary outcomes are the accuracies of the ML models in the included studies applied in the field of PTSD. We also chose other metrics, such as the AUC, sensitivity and specificity, and positive and negative predictive values for model performance as secondary outcomes.
Risk of bias assessment
Quality assessment (Supplemental Table S2) of the included studies will be conducted using the quality assessment tool proposed by Luis Francisco Ramos-Lima proposed in 2020. 18 It is divided into nine domains: representativeness of the sample, confounding variables, outcome assessment, ML approach, performance/accuracy, how the authors handled missing data, whether the test dataset was “unseen,” how the authors handled class imbalance, feature selection and hyperparameter tuning. Two investigators will conduct an independent assessment of the risk of bias for the studies included in this review. The evaluation outcomes will be documented in a concise tabular format with “Y” (yes) or “N” (no) for each item. In the event of discrepancies between the two reviewers, a third researcher will be consulted to resolve any disagreements.
Data synthesis and meta-analysis
The following data will be extracted from each selected study: (a) Qualitative synthesis: detailed characteristics of the study: medical profile and number of participants, type of ML algorithms, type of data, sample sizes, representativeness of the sample, confounding variables, outcome assessment, how the authors handled missing data, whether the test dataset was “unseen,” how the authors handled class imbalance, feature selection and hyperparameter tuning. (b) Quantitative synthesis: ML model metrics: accuracy, sensitivity, specificity, AUC and positive and negative predictive values.
Meta-analysis will be conducted on studies where data availability allows summary estimation with 95% confidence intervals (CI) for accuracy. The accuracy will be declared by point estimation and 95% CI. The significant level of two-tailed t-test will be set as 0.05. Forest plots will be used for the presentation of results. All statistics will be calculated in STATA MP 17 (Stata Corp LLC, 4905 Lakeway Drive, College Station, Texas 77845, USA).
Examining heterogeneity
The Cochrane's Q test will be chosen to qualitatively check for heterogeneity, with p less than 0.05 suggesting a significant heterogeneity across studies. I2 will be quantitively checked for the degree of heterogeneity. If I2 < 50%, heterogeneity is considered negligible and a fixed-effect model is appropriate for meta-analysis. When I2 ≥ 50%, heterogeneity is considered to be present and a random-effects model is applicable. If I2 > 75%, heterogeneity is considered to be significant among studies. A random-effects DerSimonian–Laird model will be applied to estimate the overall accuracy of all the included studies.
Subgroup analysis and sensitivity analysis
Studies of different data type, ML methods, type of ML models, PTSD diagnostic tools and traumatic events will be considered to classify into one group, when there are >2 studies in the group, to see the combined effects and heterogeneity for subgroup analysis. Sensitivity analysis will be applied by excluding one study each time to explore whether the results will change. If the results are driven by one study, we will exclude the study and perform descriptive analysis.
Publication bias
Funnel plots and Egger's test 19 would be adopted to detect publication bias only when there are at least 10 studies reporting the primary outcomes. 20 In case the available data are not in the required format or are highly heterogeneous, narrative analysis will follow.
Current status and plan
The review is undergoing a preliminary search and is expected to be completed in December 2023.
Ethics and dissemination
This systematic review and meta-analysis does not encompass patient interactions or engagements with healthcare providers. The outcomes of this research will be disseminated through scholarly channels, including presentations at scientific conferences and publications in peer-reviewed journals.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241239238 - Supplemental material for Machine learning methods to discriminate posttraumatic stress disorder: A protocol of systematic review and meta-analysis
Supplemental material, sj-docx-1-dhj-10.1177_20552076241239238 for Machine learning methods to discriminate posttraumatic stress disorder: A protocol of systematic review and meta-analysis by Jing Wang, Hui Ouyang, Runda Jiao, Haiyan Zhang, Suhui Cheng, Zhilei Shang, Yanpu Jia, Wenjie Yan, Lili Wu and Weizhi Liu in DIGITAL HEALTH
Footnotes
Acknowledgements
The authors would like to acknowledge the volunteers who participated in the study.
Contributorship
JW, HO, RJ and HZ contributed to the writing of this article and are the co-first authors. SC, ZS, YJ, WY and JW contributed to the article review and revised the article. WL and LW led the whole study, including putting this study forward and carrying out the study; they are the co-corresponding authors.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Innovative Research Team Project (20200106); Science and Technology Supply Project (2020JY17); Military Postgraduate Funding Projects (202346-295).
Guarantor
WL
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.