
Abstract
Background
Advancements in artificial intelligence (AI) have markedly improved healthcare accessibility, providing patients with immediate medical information via chatbots. Individuals with chronic cough often seek support through online resources; however, unregulated tool use raises concerns regarding misinformation, safety risks, and clinical guideline deviations. Therefore, critically evaluating chatbot-provided information on chronic cough is crucial.
Objective
To conduct a performance evaluation of six AI chatbots—ChatGPT-4o, ChatGPT-5, DeepSeek V3, Copilot, Gemini 2.5 flash, and Perplexity—in responding to high-frequency chronic cough queries, with respect to accuracy, reliability, readability, and clinical guideline adherence.
Methods
Based on an inductive analysis of Google Trends and Chinese online health communities, 25 queries were formulated. Two clinical experts evaluated the responses for accuracy, supplementarity, and incompleteness, following the European Respiratory Society (ERS) chronic cough guidelines. Reliability was assessed using DISCERN, EQIP, JAMA, and GQS, while readability was measured via six standard metrics, including the Flesch–Kincaid Grade Level.
Results
Perplexity achieved the highest reliability scores out of the tested models (DISCERN: 51.00±3.94; EQIP: 69.40±6.34), while Copilot recorded the lowest (DISCERN: 37.60±4.19; EQIP: 52.40±6.94; pairwise P<0.001vs. Perplexity). Although Copilot demonstrated comparatively better readability, no model achieved the recommended 6th-grade reading level. Pooled accuracy reached 80.39%, but critical clinical details were frequently omitted across all models.
Conclusion
While AI chatbots offer accessible health advice for chronic cough, their usefulness is constrained by significant deficiencies in readability and reliability. Widely used tools such as Copilot systematically omit guideline-based content, potentially introducing safety risks. Future research should explore whether enhanced chatbots can safely support patient decision-making and evaluate their real-world clinical applicability.
Introduction
Coughing is a key protective reflex behavior in the human body. While an infrequent and mild cough is typically benign and beneficial to one’s health, a severe or persistent cough is often indicative of disease. Chronic cough is defined as a cough that lasts for more than 8 weeks, this being the only or main symptom in adults,1,2 with normal chest X-ray findings. The global prevalence of chronic cough is estimated to range from 4.4% to 18.1%.3–6 A meta-analysis reported a pooled prevalence of 9.6%, 7 a finding that aligns with recent estimates from The Lancet Respiratory Medicine. 8 A nationwide survey in China reported annual and lifetime prevalence rates of 4.1% and 7.0%, affecting approximately 27.2 and 46.4 million adults, respectively. 9 Chronic cough is etiologically complex, often involving conditions such as cough variant asthma, eosinophilic bronchitis, and upper airway cough syndrome. 2 These underlying causes tend not to have specific imaging manifestations (e.g., chest X-ray findings are typically normal), and the symptoms overlap. Furthermore, 20%–30% of chronic cough cases can be ascribed to less common etiologies that are frequently overlooked in clinical practice, leading to delayed diagnosis and misdiagnosis. 1 Therefore, patients often undergo multiple referrals and repeated investigations, resulting in a prolonged diagnostic process that places a significant burden on the healthcare system. Data indicate that individuals with refractory chronic cough incur healthcare costs that are threefold higher than the general population in the 5 years preceding diagnosis, 10 accompanied by a 36% increase in annual medical visits. This burden primarily stems from frequent consultations in secondary care and intensive diagnostic procedures, with annual management costs ranging from €5,159 in Europe to approximately $50,000 in the US for persistent cases.11,12
Furthermore, persistent coughing can lead to physical complications such as rib fractures, pneumothorax, and urinary incontinence, seriously affecting social function and mental health. In the aftermath of the COVID-19 pandemic, coughing in public often arouses vigilance and even discrimination from others, leading to social withdrawal, anxiety, and depression in patients.13–15 This intense physical and mental pain contrasts sharply with diagnostic uncertainty, driving patients to seek immediate information support and psychological comfort outside of the traditional medical system.
This large and unmet demand prompts patients to turn to the Internet. Studies indicate that many patients seek support through online resources because they feel that their doctors do not give them adequate attention or because they are dissatisfied with their treatment outcomes.16–18 In recent years, the rapid development of artificial intelligence (AI) technology, especially AI chatbots based on large language models (LLMs), has created new opportunities for the dissemination and acquisition of healthcare information. In contrast to general Internet searches, which simply retrieve existing webpages, these chatbots generate synthesized, conversational responses by drawing on extensive training data, thereby producing answers that may not exist verbatim in any single existing source.19–21 For conditions such as chronic cough, which have complex causes and a high demand for information among patients, AI chatbots are a convenient “information assistant” to fill the communication gap between doctors and patients.
Nevertheless, the information quality and reliability of AI-generated information remain in doubt. Ordinary patients with limited medical knowledge may be misled by inaccurate, incomplete, or hard-to-understand information. 22 Therefore, systematic evaluation of the reliability, readability, and consistency of AI chatbot responses with clinical guidelines is crucial. While some studies have evaluated AI performance in areas such as back pain, early diabetic kidney disease, and COPD,23–26 there is a gap in research focusing on chronic cough, a common issue that affects numerous patients.
The present study aimed to assess the performance of six generative AI chatbots—ChatGPT-4o, ChatGPT-5, DeepSeek V3, Copilot, Gemini 2.5 flash, and Perplexity—in responding to queries related to chronic cough, focusing on the reliability of the generated information, readability, and consistent adherence to clinical guidelines.
Methods
This study was conducted in September 2025 at the Department of Pulmonary and Critical Care Medicine, First Affiliated Hospital of Soochow University, Suzhou, China. Since the study did not involve any patient data, the ethics committee’s approval was not required. Additionally, there is no relationship between the authors and the AI companies or related websites involved in the study.
To comprehensively evaluate the quality of the responses provided by AI chatbots to chronic cough issues, we formulated a multisource and representative set of queries. The set comprises common questions drawn from different channels—including Google Trends, Haodf.com, Zhihu, and Baidu Tieba’s “cough” section, the latter three being well-known online health communities in China—covering the various information needs of the general public, patients, and clinicians for chronic cough.
High-frequency search phrases related to “chronic cough” or “chronic coughing” worldwide from 2004 to 2025 were retrieved from Google Trends (https://trends.google.com) and classified under health-related topics. The 25 most frequently searched questions were systematically documented.
In addition, we collected highly interactive questions from three well-known Chinese online health communities—Haodf.com, Zhihu, and the “Cough” forum of Baidu Tieba. This choice was guided by participation indicators such as page views, replies, and likes, ensuring that the questions included represent common patient counselling content. Since the queries from the Chinese online health communities were originally written in Chinese, a rigorous translation process was implemented to ensure semantic reciprocity. Two bilingual respiratory experts independently translated these queries into English. To finalize the English tips for AI chatbots, any differences in translation were resolved through discussion, and a third expert then back-translated the final English versions to confirm semantic equivalence with the original Chinese. This process ensured that the English translations accurately reflected the clinical intention of the original patient’s counselling. Although the raw materials were obtained from the patient community, we invited seven patients to review the translated prompts, thus ensuring the clarity and relevance of the prompts from a nonprofessional perspective. Subsequently, prior to the formal evaluation, we conducted a preliminary test of five questions on ChatGPT-4o. This allowed us to adjust the specific terms to avoid triggering the security rejection mechanism of the model and ultimately derive the final prompts used in this study.
This comparative study was conducted using six AI chatbots, selected for their accessibility and model diversity: ChatGPT-4o, ChatGPT-5, DeepSeek V3, Copilot, Gemini 2.5 flash, and Perplexity. All models were tested on September 25, 2025, via their official web browser interfaces using publicly available versions. To reduce randomness and avoid interference from previous conversations, each query was submitted to each chatbot in the original English order in new, independent sessions, and all responses were recorded (see Supplementary Materials 1–6).
AI model specifications
This study evaluated six advanced AI chatbots, including both proprietary and open-weighted systems. All evaluable models were processed using instruction adjustment and human feedback–based reinforcement learning. ChatGPT (OpenAI), Copilot (Microsoft), and Perplexity are proprietary models accessed through the cloud interface. Gemini (Google DeepMind) is a multimodal model, while DeepSeek V3 (DeepSeek-AI) is an open-weighted model built on a hybrid expert (MoE) architecture.
The evaluated model represents a stable version publicly available at the time of the study (September 2025). Specific versions included the following: ChatGPT-4o (May 2024 release); ChatGPT-5 (OpenAI; released August, 2025); DeepSeek V3 (DeepSeek-AI; updated December 2024); Gemini 2.5 flash (Google DeepMind; stable release June 17, 2025); Copilot (Microsoft; Consumer version powered by GPT-4o); Perplexity (Standard version; default model).
Quality and reliability
Information quality was defined as the extent to which the provided information satisfied user requirements. 27 The following criteria were used to assess the reliability of the information provided by the six AI chatbots:
DISCERN
This standardized measurement tool was designed by the University of Oxford to assess the quality of written health information, and is widely used in health website evaluations.28,29 The tool consists of 16 items, each rated on a scale of 1–5, with higher scores indicating higher quality. As the official DISCERN scoring standard has not been formally established, this study used a classification standard from previous studies 30 : 63–75 points: Excellent Quality; 51–62 points: Good Quality; 39–50 points: Average Quality; 27–38 points: Poor Quality; 15–26 points: Very Low Quality.
Ensuring Quality Information for Patients (EQIP)
This questionnaire, consisting of 20 questions, was used to assess the quality of patient information. Each item was rated using a four-point scale: “yes,” “partially,” “no,” or “not applicable.” “Yes” was assigned a score of 1, “partially” 0.5, and “no” 0. The overall score was calculated by multiplying the ratio of “yes” by 100. The total score was divided into four categories: 0%–25%: Severe Quality Problems; 26%–50%: Serious Quality Issues; 51%–75%: Good Quality with Minor Issues; 76%–100%: Well written.
Global Quality Scale (GQS)
This scale was used to evaluate the overall quality of the information, with a 5-point Likert scale: 5 points: Excellent Quality; 4 points: Good; 3 points: Fair; 2 points: Bad; 1 point: Very Bad.
JAMA benchmark criteria
This tool was used to evaluate four aspects of the information: authorship, source and references, disclosure, and timeliness. Each item was answered as either “yes” or “no,” with “yes” scoring 1 point and “no” scoring 0. The total score range was 0–4. 31
Readability
Readability, which refers to the level of reading comprehension required for individuals to understand written material, is a crucial factor in determining the intelligibility of health information. 32 The readability of AI-generated responses was assessed using widely recognized metrics and an online calculator (https://readabilityformulas.com).
In this study, six commonly used metrics were employed: the Automated Readability Index (ARI), Gunning Fog Index (GFI), Flesch–Kincaid Grade Level (FKGL), Coleman–Liau Index (CL), Flesch Reading Ease Score (FRES), and Simple Measure of Gobbledygook (SMOG).33–36 We compared our readability scores with the 6th-grade benchmarks recommended by the AMA and NIH. 37 According to the FRES formula, a good readability threshold was considered ≥ 80.0 points, while < 6 was the threshold for the other five formulas.
Consistency with clinical guidelines
Criteria for evaluating AI-generated responses based on the ERS guidelines for chronic cough.

ERS: European Respiratory Society.
In this study, queries that did not align with the scope of the guidelines, including those related to chronic cough cancer, ICD-10 chronic cough, and chronic coughing at night, were excluded. Only 17 queries that were considered applicable for evaluation were included, and the responses were analyzed for accuracy, incompleteness, and supplementarity. The frequency distributions of these data were then statistically analyzed.
Two clinical experts, each with over 10 years of clinical experience in managing respiratory diseases at a tertiary care center, conducted the evaluation. The experts were only provided with the questions and corresponding responses, without having any information about which model generated the answers. Prior to the evaluation, the experts underwent training to ensure a unified understanding of the scoring criteria. This design helped avoid any subjective bias toward specific models, thereby ensuring the objectivity and fairness of the evaluation results. In case of discrepancies, discussions were held. If agreement could not be reached, a third expert’s evaluation was sought for final scoring and statistical analysis.
Statistical analyses
All statistical analyses and plotting were performed using R software (version 4.3.0). P < 0.05 was considered statistically significant. The normality of each variable’s data was assessed using the Shapiro–Wilk test, while Levene’s test was used to assess the homogeneity of variance. Based on these results, appropriate statistical tests were chosen for group comparisons.
For variables that violated the assumptions of normality or homogeneity of variance, nonparametric Kruskal–Wallis tests were performed, followed by Dunn’s test with Benjamini–Hochberg correction for multiple comparisons. For binary data obtained through consistency analysis against clinical guidelines (such as accuracy, incompleteness, and supplementarity), Fisher’s exact test was used for comparison between groups.
Results
Multisource queries related to chronic cough.


Heatmap of AI chatbot performance on chronic cough–related questions. The heatmap visually depicts the performance scores of the six chatbots—ChatGPT-4o, ChatGPT-5, Perplexity, Copilot, Gemini2.5 flash, and DeepSeek—across multiple evaluation metrics. The color gradient represents score levels, with darker colors indicating higher scores. Reliability (a) was measured using the tools DISCERN, EQIP, JAMA, and GQS. Readability (b) was measured using standard readability indices, including ARI, GFI, FKGL, CL, SMOG, and FRES. Abbreviations: AI, artificial intelligence; EQIP, ensuring quality information for patients; JAMA, JAMA benchmark criteria; GQS, global quality Scale. Readability metrics: ARI, automated readability index; GFI, gunning fog index; FKGL, Flesch–Kincaid grade level; CL, Coleman–Liau index; FRES, flesch reading ease score; and SMOG, simple measure of Gobbledygook.
Reliability analysis
Reliability scores across six AI chatbots (mean ± SD).

Abbreviations: AI, artificial intelligence; EQIP, Ensuring Quality Information for Patients; JAMA, JAMA Benchmark Criteria; GQS, Global Quality Scale.
For DISCERN scores, Perplexity achieved the highest reliability scores (51.00 ± 3.94), significantly outperforming the other models. In contrast, Copilot achieved the lowest score (37.60 ± 4.19; pairwise P < 0.001 vs. Perplexity). The remaining chatbots demonstrated similar performance (Figure 2). Reliability evaluation of AI chatbots on chronic cough issues. The violin plots represent the DISCERN (a), EQIP (b), JAMA (c), and GQS (d) scores of the six chatbots, with the grades marked below each plot. Abbreviations: AI, artificial intelligence; EQIP, ensuring quality information for patients; JAMA, JAMA benchmark criteria; GQS, global quality scale.
According to EQIP scores, all chatbots were rated as “good quality with minor issues,” with Perplexity and DeepSeek achieving the highest scores (Figure 2).
For GQS scores, all chatbots provided information at the “Fair” level (Figure 2), with Perplexity performing the best, although this difference in performance was not statistically significant.
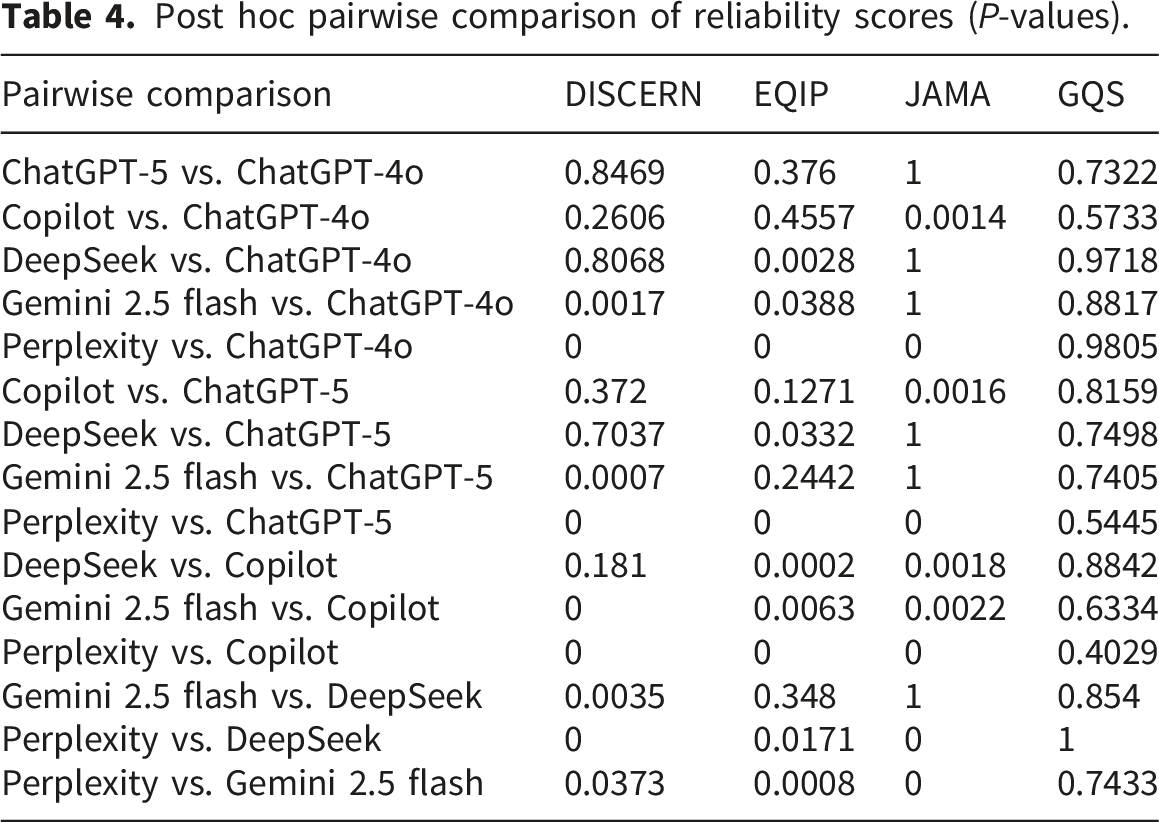
Post hoc pairwise comparison of reliability scores (P-values).
Readability
Post hoc pairwise comparison of readability scores (P-values).

Abbreviations: ARI, Automated Readability Index; GFI, Gunning Fog Index; FKGL, Flesch–Kincaid Grade Level; CL, Coleman–Liau Index; FRES, Flesch Reading Ease Score; SMOG, Simple Measure of Gobbledygook.
As shown in Figure 3, none of the readability indices for the six chatbots met the 6th-grade reading level standard. The FRES scores were significantly lower than the 80–90 range recommended for good readability. Comparison of readability of AI chatbots on chronic cough–related questions. The solid red line indicates the 6th-grade level, which is the highest recommended reading level for patient education materials. Abbreviations: ARI, Automated Readability Index; GFI, Gunning Fog Index; FKGL, Flesch–Kincaid Grade Level; CL, Coleman–Liau Index; SMOG, Simple Measure of Gobbledygook.
Consistency with clinical guidelines
During the consistency evaluation with clinical guidelines, two experts contended that eight queries did not meet guideline explanation. Consequently, evaluation analysis was conducted for the remaining 17 queries. Descriptive statistics showed that accuracy was the highest among the three metrics, with a pooled accuracy of 80.39%. Among the six AI chatbots, Copilot demonstrated the lowest accuracy, incompleteness, and supplementarity (41.18%, 70.59%, and 23.53%, respectively), while Perplexity showed the highest accuracy, incompleteness, and supplementarity (100%, 29.41%, and 82.35%, respectively) (Figure 4). Consistency evaluation of AI chatbots against clinical guidelines on 17 chronic cough–related questions. AI, artificial intelligence.
Furthermore, Fisher’s exact test was performed to analyze differences between groups in accuracy, incompleteness, and supplementarity. Significant differences were observed between some of the six chatbots (accuracy: P = 0.0001; incompleteness: P = 0.163; supplementarity: P = 0.004). Accuracy differed significantly between Copilot and three models (DeepSeek, P = 0.036; Gemini 2.5 flash, P = 0.0045; Perplexity, P = 0.0045; vs. Copilot, respectively), while supplementarity differed significantly between Copilot and Perplexity (P = 0.024). All other pairwise comparisons were nonsignificant.
Discussion
As a cutting-edge technology in the field of AI, large language models (LLMs) are emerging as versatile intelligent tools in healthcare settings,39–41 with capabilities in contextual learning, reasoning, and decision-making. 42 Their ability to use prompts to generate diverse solutions has already shown potential for application in fields such as education, geriatric medicine, traditional Chinese medicine, and ophthalmic nursing. Nevertheless, the quality and reliability of the information they provide, and more importantly, whether this information can be understood by the general public, have become pressing issues. The results of this study indicate that these LLMs vary greatly in the quality of information they provide, exhibit significant differences in readability, and risk omitting key guideline content. This observation is consistent with prior evaluations across diverse healthcare domains, including asthma, allergy, respiratory conditions, 43 ophthalmology, 44 diabetes and endocrinology, 45 and healthcare quality management, 46 where generative AI models demonstrated variable performance in terms of completeness, accuracy, and relevance, with additional multilingual disparities reported in some disease-specific assessments.
This study included six chatbots, these being two versions of ChatGPT, Perplexity, Copilot, Gemini, and DeepSeek. As shown in Figures 1 and 2, the information quality of each chatbot was evaluated through DISCERN, and it was found that all responses showed average information quality, consistent with the findings of Tan et al. 47 DISCERN primarily focuses on reliability and emphasizes the internal characteristics of health information, including the mechanisms, efficacy, and risks of treatments, other possible treatment plans, the consequences of not pursuing treatment, and the impact of treatment choices on quality of life. Of all the models, only Perplexity reached the “Good Quality” level on the DISCERN scale, and even this was achieved only marginally. Nevertheless, it performed significantly better than the other chatbots. Copilot had the lowest score and was classified as “Poor Quality” under the DISCERN criteria. This is likely due to the fact that the design prioritizes concision and search efficiency over comprehensive medical detail, rather than simply evaluating informational accuracy.
The performance differences among AI models observed by DISCERN are reflected in the overall trend of the other three information quality assessment tools (JAMA, EQIP, and GQS). Specifically, Perplexity showed the best overall performance, with DeepSeek and Gemini 2.5 flash reaching a moderate level, while Copilot was ranked the lowest among all tools, except for a relatively high score on JAMA. This difference may be due to the different focusses of the JAMA standard, which mainly evaluates the transparency of sources of information and citation criteria. Tools such as DISCERN, EQIP and GQS put more emphasis on evaluating clinical accuracy, completeness and applicability. In addition, the EQIP results showed that all chatbots’ answers were classified as “Good Quality with Minor Issues; ” however, Copilot still demonstrated the poorest performance, indicating that, although most models can provide structured, readable, and generally reliable information, Copilot is limited in the depth and integrity of the clinical content it can provide. Demir et al. 48 studied AI-generated responses related to endophthalmitis, revealing that Copilot performed the worst, with the lowest DISCERN score among the AI models, including ChatGPT, DeepSeek, Gemini, and A-eye Consult. This may be due to the quality and diversity of the dataset, which are important factors affecting model performance. Copilot is an AI chatbot that streamlines information retrieval and search, highlighting concision and clarity. 49 Furthermore, Copilot may retrieve web searches and information from a variety of unreliable websites. Malak et al. 50 evaluated multiple AI chatbots, including Copilot, Gemini, ChatGPT, and Perplexity, on their responses to four questions related to female urinary incontinence. They reported no significant differences in EQIP scores among the chatbots, in contrast to the results of our study. This discrepancy is likely attributable to differences in sample data or contextual information between diseases, or possibly to the confidence-filtering mechanism based on the Bing search engine. 38 Additionally, these phenomena may be related to differences in the architectural design of the models and the size of the training datasets.51–53 While all of the aforementioned chatbots are LLMs, the development teams have made adjustments. In practice, Perplexity, with its Retrieval-Augmented Generation (RAG) engine, 54 can perform real-time searches and integrate authoritative medical information from the web, ensuring the timeliness, accuracy, and transparency of citations. This architecture fulfills the core requirements of the DISCERN and JAMA evaluation tools, specifically source transparency and content reliability, by providing responses that are grounded in verifiable, up-to-date sources. Consequently, Perplexity’s superior performance across multiple quality metrics reflects its ability to combine generative capabilities with external knowledge validation—a feature that is not present in purely generative models. Conversely, DeepSeek and Gemini 2.5 flash demonstrate mid-range performance, reflecting the common limitations of pure generative models. DeepSeek employs a mixture-of-experts (MoE) framework and reinforcement learning to optimize logical rigor, which may improve the structural quality of the text, as is partially reflected in EQIP and GQS. Although Gemini 2.5 flash shows efficient reasoning and multimodal processing capabilities, it is essentially a generation model that relies on large volumes of static training data. Therefore, although the information quality of both models is highly dependent on the breadth, quality, and timeliness of their training datasets, the absence of external real-time validation makes it difficult to ensure that the information they provide is fully consistent with the latest and most specific clinical knowledge. This limitation may reduce their DISCERN scores for transparency and reliability of treatment-related information. Nevertheless, both models performed competently on structural quality (EQIP and GQS), suggesting that they remain viable options for general medical inquiries where it is not critical to draw from the absolutely most current sources.
For readability, this study used six standard metrics to comprehensively assess the complexity of the health information generated by the chatbots. As Figure 3 depicts, Copilot performed better on key indices such as ARI and FRES, approaching the recommended 6th-grade reading level and thereby generating relatively more readable health information. This result is comparable to the readability evaluation of ChatGPT, BARD, Gemini, Copilot, and Perplexity responses on palliative care by Volkan Hancı et al. 55 However, the overall readability of all chatbots, including Copilot, did not meet the 6th-grade reading level. This common phenomenon can be interpreted through the lens of cognitive load theory.56–58 Since medical information is highly specialized, the large number of medical terms, pathological mechanisms, and complex concepts included in the models create an inherent “intrinsic cognitive load” for the reader. When AI attempts to provide accurate and complete medical explanations, this high cognitive load determined by the nature of the content is inevitable. Therefore, the generated text naturally exceeds the vocabulary and grammar categories required for lower reading levels. This also highlights a realistic challenge: in attempting to ensure information accuracy and professional depth, the AI chatbot may deviate from the need for comprehensibility for the general audience. This also makes it difficult for users with low health literacy to understand relevant information, implying that the language and structure of health information generated by AI still need to be further optimized and improved.
Copilot’s good readability may have resulted from its search engine integration and practical design, which facilitate clear and direct information organization. 59 While this method effectively reduces the external cognitive load, the intrinsic complexity of medical concepts remains a fundamental constraint. Therefore, even if the syntax has been improved, how to achieve an appropriate balance between professional accuracy and public understanding of medical information warrants further examination. Additionally, a particularly worrying finding is the “useability paradox” observed in Copilot. Although it achieved the best readability score, making the response most easily accepted by the public, it also scored the lowest in terms of accuracy and completeness. This combination raises concerns about potential implications for public health, as widely accessible but incomplete information may be readily accepted by patients with limited health literacy. This underscores the importance of integrating readability enhancements with clinical accuracy safeguards. Therefore, high readability should not be regarded as the only standard for measuring the effectiveness of health advice. Without clinical accuracy, “user-friendly” AI chatbot answers may inadvertently promote the spread of misconceptions.
This study conducted an evaluation of the consistency of 17 chronic cough–related queries against current clinical guidelines. The results revealed that these chatbots accurately answered most questions, with a pooled accuracy of 80.39%. This indicates that, after extensive training on large medical datasets, these chatbots are able to encode and generate medical knowledge in a standardized, consistent, and accurate manner. However, there are significant differences in performance among different models, which directly relates to their core architecture and optimization goals. Different AI models use different trade-off strategies in responding to medical queries. Perplexity adopts the strategy of “maximizing information,” and its RAG mechanism strives to provide answers that are as comprehensive and verifiable as possible through extensive retrieval and integration. 60 This method ensures high accuracy and integrity, reducing the risk of errors caused by missing information; however, it may reduce the efficiency of user decision-making at the cost of providing abundant information. In contrast, Copilot adopts a “simplified response” strategy, prioritizing speed and simplicity in design. 61 This allows the chatbot to filter out details considered unimportant or redundant when dealing with complex medical queries. Although this may improve the user experience through smoother interaction, the risk of missing key guideline content also increases significantly, resulting in high incompleteness and low information accuracy. The performance of other models such as DeepSeek was intermediate between the two, reflecting a strategy of balancing the amount of information provided and controllability.
Statistical analysis indicated differences between the groups; however, not all pairwise comparisons were statistically significant. Regrettably, Copilot has been reported to show substantial incompleteness (70.59%) in key medical information, indicating that some AI chatbots that prioritize user-friendliness and efficiency may systematically ignore some clinical details that are critical to clinical decision-making.62,63 For example, when answering the question “chronic cough causes,” Copilot omitted causes including ACEI-induced cough and factors related to chronic cough in children. This also raises a core question in the field of medical information: Should the cost of simplicity be incompleteness? In the future, AI development should focus on improving algorithms to better define the boundaries and priorities of medical information to ensure that the rigor and safety required by clinical guidelines are not sacrificed for readability and timeliness.
This study has several limitations. In regard to query design, our dataset comprised a hybrid of keyword-based prompts (from Google Trends) and natural language questions (from Chinese online communities). Although keyword-based prompts reflect typical search engine behavior, they often lack the clinical granularity of specific patient narratives. Additionally, while these issues arose from the community and covered complex questions, they were translated from Chinese into English for model input. Despite rigorous translation verification to ensure semantic equivalence, this method still cannot completely eliminate the risk of potentially distorting subtle semantic differences or the cultural background intrinsic to the original patient problems. Furthermore, this study only assessed the model’s performance with English input–output, without taking into account its performance with pure Chinese input or comparing the input and output of the same problem across multiple languages. Additionally, this study was not validated among Chinese-speaking populations. Therefore, the conclusions of this study should be interpreted with caution when applied to Chinese clinical environments.
Although this study was based on a limited number of queries, the evaluation dataset was constructed through a systematic induction method derived from wide multiplatform screening. By screening and synthesizing high-frequency inquiries from search engines and online health communities, a large number of potential inquiries were distilled into a concise and representative collection, reflecting the most urgent information needs of patients with chronic cough. This design ensured that each test item had a high degree of clinical relevance and was a reliable exploratory benchmark. Furthermore, the sample size aligned with previous studies on medical chatbots, balancing the depth of qualitative review with the breadth of topics. Future research may be further expanded on this basis to include a wider range of long-tail queries by expanding the dataset.
Our evaluation was based on the network interface under the “default settings” of the model, wherein specific reasoning parameters such as temperature are preset by the platform and are not disclosed. This lack of transparency, combined with our analysis relying on a single response to each query, captured only a specific “snapshot” of the model performance. Since generative AI models are inherently random and nondeterministic, the same prompt may produce different outputs. This study did not evaluate the repeatability or internal variability of responses, and future studies should address these issues using repeated sampling strategies.
Furthermore, because models such as DeepSeek were trained on multilingual data, including English, their performance with English inputs in this study may not fully reflect their behavior in purely Chinese-language settings. This study assessed only the accuracy of the AI-generated information and did not evaluate whether patients were able to comprehend this information.
In light of these results, future research should focus on the following aspects. First, future studies should explore the effectiveness of different prompt strategies in enhancing the readability of AI chatbots text, thus overcoming the existing readability barriers. Approaches such as simplifying sentence structures and reducing technical terms may be used to improve readability and reduce barriers for users seeking medical care information. Moreover, the inconsistent information quality provided by chatbots suggests that current AI models significantly vary in their retrieval and presentation of medical information. This inconsistency highlights the need for standardized guidelines in AI information dissemination. Hence, developers should prioritize integrating structured citation mechanisms and improving fact-checking algorithms to enhance the reliability of the medical advice generated by chatbots.
Conclusion
This study provided the first systematic assessment of the accuracy, reliability, readability, and consistency with clinical guidelines of chronic cough–related information generated by six AI chatbots. The results showed that Perplexity generated the best responses, reflecting excellent text quality, while DeepSeek and Gemini 2.5 flash performed at an intermediate level. In contrast, Copilot generated the lowest-scoring responses across DISCERN, EQIP, and GQS, raising concerns about the reliability of the information. None of the AI-generated responses met the 6th-grade reading level, with Copilot achieving the highest readability score. While AI-generated responses were mostly accurate, they often omitted key guideline details. The omission of these key details, such as drug interactions or population-specific dosages, introduces clinical risks by potentially misleading judgment and consequently increasing the chance of experiencing adverse events. To address these gaps, AI developers should focus on designing chatbots that can identify omitted details and provide traceable links to source guidelines, ensuring transparency and verifiability. For healthcare stakeholders, integrating these tools into clinical workflows involves establishing information validation protocols to help clinicians critically appraise AI-generated content, thereby achieving a balance between medical rigor and public accessibility.
Supplemental material
Supplemental material - Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment
Supplemental material for Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment by Zhen-Yun Wu, Bei-Bei Hu, Qiu-Xia Mao, Yan-Xia Han and Qian Zhao in Digital health.
Supplemental material
Supplemental material - Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment
Supplemental material for Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment by Zhen-Yun Wu, Bei-Bei Hu, Qiu-Xia Mao, Yan-Xia Han and Qian Zhao in Digital health.
Supplemental material
Supplemental material - Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment
Supplemental material for Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment by Zhen-Yun Wu, Bei-Bei Hu, Qiu-Xia Mao, Yan-Xia Han and Qian Zhao in Digital health.
Supplemental material
Supplemental material - Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment
Supplemental material for Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment by Zhen-Yun Wu, Bei-Bei Hu, Qiu-Xia Mao, Yan-Xia Han and Qian Zhao in Digital health.
Supplemental material
Supplemental material - Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment
Supplemental material for Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment by Zhen-Yun Wu, Bei-Bei Hu, Qiu-Xia Mao, Yan-Xia Han and Qian Zhao in Digital health.
Supplemental material
Supplemental material - Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment
Supplemental material for Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment by Zhen-Yun Wu, Bei-Bei Hu, Qiu-Xia Mao, Yan-Xia Han and Qian Zhao in Digital health.
Supplemental material
Supplemental material - Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment
Supplemental material for Accuracy, reliability, readability, and European respiratory society guideline consistency of six generative artificial intelligence chatbots in providing health advice for chronic cough: A cross-sectional comparative assessment by Zhen-Yun Wu, Bei-Bei Hu, Qiu-Xia Mao, Yan-Xia Han and Qian Zhao in Digital health.
Footnotes
Acknowledgments
Ethical considerations
This study did not involve human or animal participants.
Author contributions
WZY and HBB contributed to study design, data analysis, methodology, software, visualization, and writing of the original draft. MQX contributed to conceptualization and supervision. HYX and ZQ contributed to project administration, validation, supervision, and resources. All authors have reviewed and approved the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/orpublication of this article: This study was supported by the Suzhou Foundation Pilot Project (SSD2024077).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
AI declaration
During the preparation of this manuscript, the authors used AI tools (specifically DeepSeek) to assist in refining the R code for generating figures. The authors have reviewed the content of the final manuscript and take full responsibility for it.
Supplemental material
Supplemental material for this article is available online