
Abstract
Background/Objective
Although the internet has broadened access to medical resources, concerns persist regarding the quality and accuracy of available content. ChatGPT, a general-purpose large language model, may help bridge this gap. This study evaluates its safety and user perception in addressing pediatric healthcare queries.
Methods
Nine experts independently evaluated 41 questions, with three experts assigned to each of the following topics: vitamin D (15 questions), food allergies (16 questions), and sleep problems (10 questions). Each question was answered separately by ChatGPT3.5 and ChatGPT4. Ratings were determined by expert consensus or, in cases of disagreement, the lowest rating. Additionally, 27 parents evaluated ChatGPT's responses.
Results
Experts rated 73.2% of responses from ChatGPT3.5 as “completely correct” or “correct but not comprehensive,” while 26.8% were rated as “partially incorrect” or “completely incorrect.” For ChatGPT4, these figures were 68.3% and 31.7%, respectively. The difference in accuracy ratings between the two versions was not statistically significant (chi-square test, p = .819). Over 80% of parents rated the responses as “completely clear with no further doubts” or “very clear with few doubts,” with no significant difference found between versions (generalized mixed-effects model, p = .617). A total of 73.1% of parents expressed trust in ChatGPT's medical information, and 88.0% indicated a likelihood of continued use. Rating trends between parents and clinicians were consistent for both ChatGPT3.5 and ChatGPT4 responses (McNemar's test, ChatGPT3.5: p = .481; ChatGPT4: p = .143).
Conclusion
As over a quarter of responses contained expert-identified inaccuracies, the current performance of ChatGPT is insufficient for safe and reliable use in clinical decision-making. Nevertheless, it has potential to expand health information access for parents. However, these findings should be interpreted with caution given the small sample size and potential selection bias regarding parents’ educational backgrounds. Future improvements should enhance accuracy, clarity, and integration between parents and healthcare professionals.
Introduction
The World Health Organization emphasizes that “investing in children is one of the most important things a society can do to build a better future. 1 ” Ensuring healthy growth and development in children is a shared goal between parents and healthcare systems. To achieve this, pediatric care relies heavily on anticipatory guidance, a foundational proactive process in which healthcare professionals provide parents with age-appropriate information and advice to prepare them for their child's upcoming developmental stages and to prevent potential problems. 2 For example, this includes advising on childproofing a home before an infant begins to crawl, or discussing normal changes in sleep patterns before they occur.
However, implementing this standard of care faces significant real-world challenges. Parenting is inherently demanding, with new parents often experiencing both joy and anxiety while seeking reliable information. While parents with greater social resources and higher education often gain professional knowledge from healthcare providers and experiential knowledge from online platforms, social networks, and direct observation, 3 widespread access remains inequitable. Due to socioeconomic disparities within countries 4 and varying levels of national development, not all children and caregivers can easily access high-quality pediatric healthcare. In China, for example, there are only four pediatricians for every 10,000 children. 5
To bridge this gap, digital platforms and social media have risen as alternative sources of information, improving the reach and equity of anticipatory guidance. 6 Yet, this accessibility comes with risks. Online health information varies in quality, with misinformation rates ranging from 21% to 44% on Google 7 and up to 87% on social media, 8 potentially misleading parents and harming children. Therefore, ensuring the accuracy and reliability of online health information is critical.
ChatGPT, developed by the American company OpenAI, represents a significant evolution in this digital landscape. As a natural language processing model based on the generative pretrained transformer (GPT) architecture, it was trained on a large and diverse corpus of textual data to generate coherent and contextually relevant responses.9,10 In the medical domain, ChatGPT has demonstrated promising performance, including success on standardized exams such as the US Medical Licensing Examination 11 and the German State Examination in Medicine. 12 Its potential in clinical decision support for professionals is also an active area of research. 13 However, researchers have reported inaccuracies in ChatGPT's responses to clinical questions, cautioning against uncritical reliance on its output. 14 A recent systematic review by Douma et al. 15 identified numerous studies evaluating ChatGPT's role in pediatric patient education, largely focusing on content accuracy and readability metrics. However, few studies have assessed the specific disconnect between expert clinical validation and real-world parental perception using a simultaneous, dual-evaluation framework. It is important to note that while specialized medical artificial intelligence (AI) models are currently under rapid development, general-purpose large language models (LLMs) remain the primary source of AI-driven information accessible to the general public. Consequently, evaluating the safety and parental perception of these widely used, first-line digital tools remains a critical public health priority.
To this end, the primary objectives of this study were to: (1) quantitatively evaluate the clinical accuracy and safety of responses generated by ChatGPT (versions 3.5 and 4.0) through a rigorous panel assessment by pediatric experts. (2) Assess the user experience, specifically focusing on the clarity, perceived utility, and trustworthiness of the AI-generated information from the perspective of parents.
Methods
Study design
This study employed a comparative descriptive approach, analyzing the ratings from expert panels and parents who evaluated responses generated by two versions of ChatGPT to selected pediatric healthcare questions. Figure 1 shows the study design flowchart.

Study design flowchart.
Selection of questions
The clinical questions used in this study were sourced from the latest three clinical guidelines released by the Chinese Medical Association: the practical guidelines for clinical issues related to vitamin D nutrition in Chinese children (2022), 16 the evidence-based guidelines for food allergy of children in China (2022), 17 and the Chinese guideline for the treatment of bedtime problems and night waking in children under 6 years of age (2023). 18 These guidelines were developed in accordance with the World Health Organization Handbook for Guideline Development, 19 and are registered on the practice guidelines registration platform, 20 with registration numbers IPGRP-2020CN114, IPGRP-2020CN138, and IPGRP-2022CN304, respectively. To generate clinical questions, different guideline development groups adopted multiple strategies. These included administering surveys to professionals to identify high-priority topics, conducting individual interviews with experts to gather diverse perspectives, and facilitating group discussions to reach consensus on final items. Specifically, the vitamin D guideline group conducted expert interviews and collected 50 questions on children's vitamin D deficiency and nutritional rickets. Following a survey among healthcare professionals, 35 high-priority questions were identified. After several rounds of expert discussions, 16 clinical questions were finalized. The food allergy guideline group developed 16 clinical questions through pediatrician surveys. The bedtime problems guideline group used advisory committee discussions and expert consultations to initially generate questions. These questions were then evaluated for importance by 271 healthcare professionals from various levels of medical institutions across eight provinces and municipalities in eastern, central, western, and northeastern China, resulting in the selection of 10 clinical questions.16–18 These questions are practical in nature, designed to address common parental and clinical dilemmas. Examples of the questions include: “Is it necessary to monitor the serum 25(OH)D levels before supplementing vitamin D?” “Does breastfeeding prevent food allergies?” and “Does increasing daytime physical activity levels improve sleep problems and night awakenings in children?”
Initially, the three guidelines include 42 questions (16 on vitamin D, 16 on food allergies, and 10 on bedtime problems). The authors then reviewed this combined list to ensure each question would serve as a distinct prompt for our evaluation of ChatGPT. Within the vitamin D guideline, we noted that the answer to Question 1 (“How to assess the nutritional status and classification of vitamin D?”) would necessarily incorporate the core information required to answer Question 3 (“What is the appropriate level for serum 25(OH)D?”). To ensure each of our 41 prompts to ChatGPT was as unique as possible and to avoid evaluating the same information twice, we chose to use the more comprehensive Question 1 as the representative prompt for this topic and excluded Question 3 from our set. This resulted in the final set of 41 questions used in our analysis (15 on vitamin D, 16 on food allergies, and 10 on bedtime problems).
ChatGPT version and interaction settings
As illustrated in Figure 2, the ChatGPT interface is similar to that of social chat platforms, making it user-friendly and accessible. The first free version available to the public was ChatGPT3.5, followed by the launch of a paid version, ChatGPT4, by OpenAI on 15 March 2023. According to official sources, ChatGPT4 provides enhanced capabilities relative to ChatGPT3.5, offering more accurate and detailed responses. 21

The interface of ChatGPT responding to the questioner's inquiries.
Prompt engineering and response generation procedures
ChatGPT exhibits language bias, as demonstrated by its performance on the Chinese National Medical Licensing Examination, where answer accuracy in English was higher than that in Chinese (86.25% vs. 81.25%). 22 Therefore, although the clinical guidelines used for question selection were originally published in Chinese, the questions were translated into English to align with ChatGPT's language capabilities. All questions and responses were translated between Chinese and English by ChatGPT and verified by two senior professional medical English translators. To clearly define the required role, each query started with: “I am a mother, please play the role of an experienced pediatrician from now on to answer my questions.” Since ChatGPT generates responses based on the ongoing conversation context, each question was entered in a new chat session to reduce personalization from prior interactions. This strategy ensured that previous questions and answers did not influence the current response, supporting a more standardized evaluation. Responses from ChatGPT3.5 and ChatGPT4 were compared to assess performance differences.
Expert panel evaluation of clinical accuracy
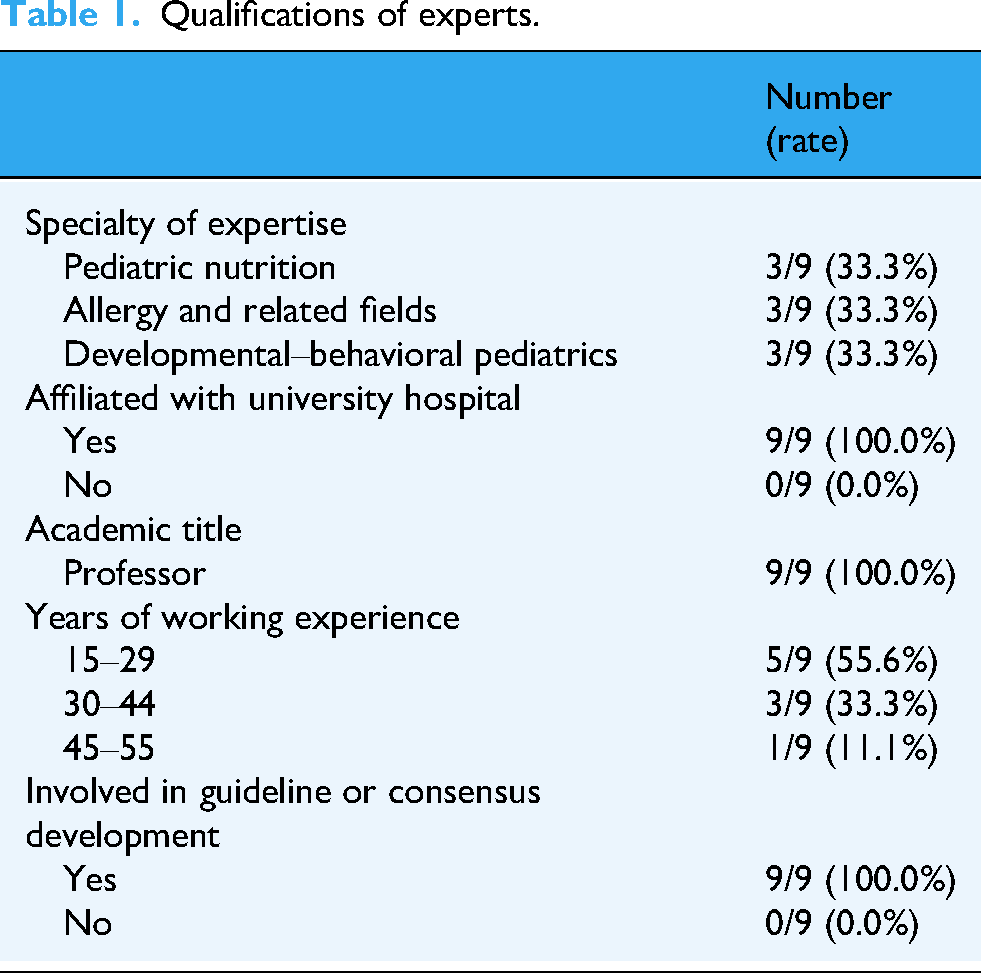
All 41 clinical questions were separately answered by ChatGPT3.5 and ChatGPT4 in July, 2023, resulting in 82 question–response pairs. A panel of nine senior pediatric experts was recruited to evaluate the accuracy of ChatGPT's responses. The experts were personally invited by the corresponding author based on their extensive clinical experience and established reputation in specific subspecialties relevant to the study questions. As shown in Table 1, all nine experts held the academic title of Professor, were affiliated with major university hospitals, and had prior experience in clinical guideline or consensus development, ensuring a high level of domain-specific knowledge. The panel was composed of three experts in pediatric nutrition, three in allergy, and three in developmental–behavioral pediatrics.
Qualifications of experts.
The evaluation was conducted remotely in August 2023. Each of the 82 question-response pairs was assigned to a group of three experts corresponding to their area of specialization (e.g., questions on vitamin D were sent to the three nutrition experts). The materials were compiled into a Microsoft Excel spreadsheet and sent to the experts via email. The file contained the original questions and guideline recommendations, followed by the responses from ChatGPT3.5 and ChatGPT4, which were presented in a randomized and blinded order to minimize bias. The accuracy of ChatGPT's responses was graded as: (a) correct and comprehensive, no additional information needed according to the experts; (b) correct but not comprehensive, with experts indicating additional information was necessary; (c) partially correct and partially incorrect; and (d) completely incorrect. This category method was adapted from established methodologies used in prior research evaluating the accuracy of online health information.23,24 Each expert independently and asynchronously rated the responses. The final accuracy rating for each response was determined by majority agreement among the three experts. In cases where all three experts provided a different rating, the most conservative (lowest) rating was assigned.
Parental evaluation of clarity and user perception
In July 2024, 27 parents were recruited from a primary school and a kindergarten in Chongqing, China, through convenience sampling. Invitations were distributed by teachers to parent chat groups. Interested parents were first provided digital informed consent on the Wenjuanxing platform.
After providing consent, parents were invited to participate in the response evaluation task. To mitigate the significant burden of evaluating all 82 responses, we employed a randomized partial evaluation design. The 41 clinical questions were divided into their three original topic blocks (vitamin D, food allergies, bedtime problems). The 27 participating parents were then randomly assigned to evaluate all the questions within one of these three blocks: eight parents were assigned to evaluate the responses for the 15 vitamin D questions; nine parents were assigned to evaluate the responses for the 16 food allergy questions; and 10 parents were assigned to evaluate the responses for the 10 bedtime problems.
For their assigned block of questions, each parent evaluated the responses from both ChatGPT3.5 and ChatGPT4. The evaluation materials were provided in a Microsoft Excel spreadsheet sent via Wechat App. Within the spreadsheet, the responses from the two ChatGPT versions for each question were presented in a randomized and blinded order.
Parents rated the clarity of each response using a 4-point Likert scale: (a) completely clear and I have no further doubts; (b) very clear with few doubts; (c) moderately clear but I still have many doubts; and (d) no help. This scale was developed by the research team to assess the clarity and usability of the responses from a parent's perspective, serving as a complementary evaluation to the experts’ accuracy assessment.
Upon completing the evaluation task, parents were directed to a survey on the Wenjuanxing platform. They completed a demographic questionnaire first. The demographic characteristics of the participants are detailed in Table 2. Among the 26 who completed the demographic questionnaire, 84.6% were female, and the majority (57.7%) were aged 30–39 years. Most parents had attained a college or bachelor's degree (76.9%), and 15.4% held a master's degree or above.
Demographic characteristics of parents.

Parents then answered five supplementary questions gauging their general views on using ChatGPT for parenting advice: (a) Do you trust the medical information provided by ChatGPT? (b) If you had these concerns while raising your child, did ChatGPT's responses alleviate your anxiety? (c) Compared to traditional search engines (e.g., Baidu, Google, etc.) and information from doctors, which responses do you prefer? (d) In the future, how likely are you to ask ChatGPT medical questions while raising your child? (Please rate on a scale of 1–5, where a higher number indicates a greater likelihood.) (e) Would you adopt medical advice given by ChatGPT? These questions, developed by authors, which were analyzed individually, explored key themes such as trust, anxiety alleviation, and future usage intention.25,26
Statistical analysis
All statistical analyses were performed using R (version 4.4.2) and Microsoft Excel 2019, with a two-tailed significance level set at α = 0.05.
Analysis of expert and parent ratings. The primary ratings provided by parents for response clarity were on a 4-point scale (1–4). These raw parental ratings were treated as ordinal variables. To examine the difference in clarity ratings between ChatGPT3.5 and ChatGPT4 while accounting for the nested data structure (multiple ratings per parent and per question), a generalized mixed-effects model was applied. In this model, the ChatGPT version was a fixed effect, while Parent ID and Question ID were included as random effects. For the expert ratings, the distribution differences between the two ChatGPT versions were assessed using the chi-square test.
Consistency analysis (McNemar test). To conduct the consistency analysis between expert and parent evaluations, the variables were first dichotomized. Expert ratings of “(a) correct and comprehensive” or “(b) correct but not comprehensive” were classified as “generally accurate.” Parent clarity ratings were first averaged for each response across all parents who evaluated it. An average score of ≤2 was then classified as “generally helpful.” The consistency between these two dichotomized variables (“generally accurate” vs. “generally helpful”) was then evaluated using the McNemar test. This test was also used to assess rating consistency between the two ChatGPT versions within each group (experts and parents).
Ethical Considerations
All procedures involving human subjects/patients were approved by the Ethics Committee of the Children's Hospital of Chongqing Medical University in Chongqing, China (Approval No: (2024)IRB(STUDY) No.239).
Results
Evaluation by experts
All questions and responses are detailed in the supplement. The responses were generally well-structured, typically beginning with a concise summary in the opening paragraph, followed by more detailed explanations. Each response maintained a friendly tone, consistently acknowledged individual variability, and advised users to consult a healthcare provider for professional guidance.
The qualifications of the nine participating experts are detailed in the Methods section (Table 1).
As shown in Table 3 and Figure 3, the expert ratings for the 41 questions were distributed across four categories. For ChatGPT3.5, 21 responses (51.2%) were rated as “correct and comprehensive,” nine (22.0%) as “correct but not comprehensive,” seven (17.1%) as “partially correct and partially incorrect,” and four (9.8%) as “completely incorrect.”

Evaluations of ChatGPT's responses from doctors and parents.
Expert and parent evaluations of ChatGPT3.5 and ChatGPT4 responses.
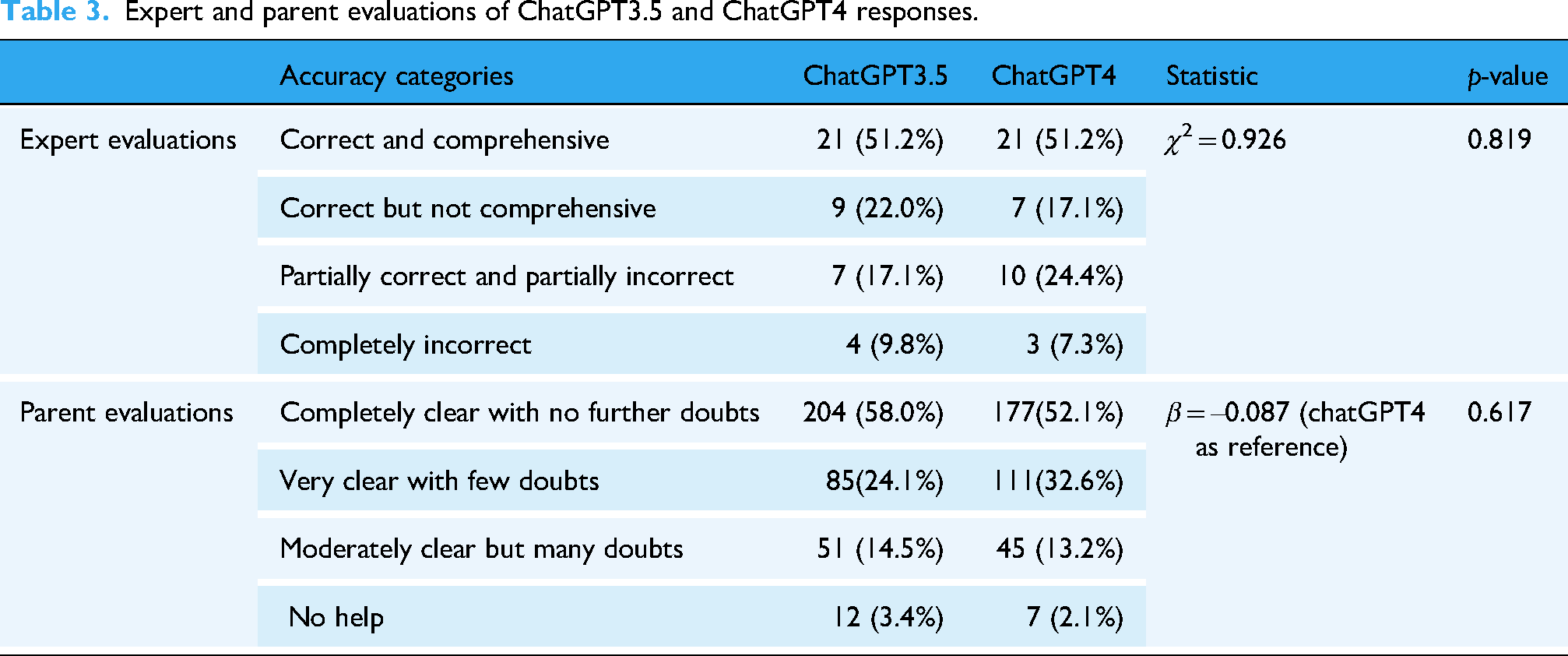
For ChatGPT4, the ratings were similarly distributed: 21 responses (51.2%) were “correct and comprehensive,” seven (17.1%) were “correct but not comprehensive,” 10 (24.4%) were “partially correct and partially incorrect,” and three (7.3%) were “completely incorrect.” Responses rated as “correct and comprehensive” or “correct but not comprehensive” accounted for 30 of 41 (73.2%) for ChatGPT3.5 and 28 of 41 (68.3%) for ChatGPT4, reflecting a decrease of approximately 5% in the latter. However, the difference in the distribution of accuracy ratings between ChatGPT3.5 and ChatGPT4 was not statistically significant (χ2 = 0.926, p = .819).
For instance, a “correct and comprehensive” response was provided for the question regarding whether skin-prick tests can diagnose food allergies; in this case, ChatGPT's answer aligned clearly with established guidelines and was deemed sufficient by the experts. An example of a “correct but not comprehensive” response was given for the question, “Can early sleep hygiene guidance reduce bedtime problems and nighttime awakenings in children?”—experts noted that the response lacked a definition of early sleep hygiene guidance. In another example, for the question “Can additional intake of nutritional supplements improve sleep problems and nighttime awakenings in children?” ChatGPT mentioned melatonin, which the experts identified as a drug rather than a nutritional supplement; this response was thus rated as “partially correct and partially incorrect.” A response categorized as “completely incorrect” was observed for the question regarding pacifier use to improve bedtime problems and nighttime awakenings in children, as the provided information contradicted established clinical guidelines.
Evaluation by parents
A total of 27 parents participated in the evaluation. The demographic characteristics of the 26 parents who completed the questionnaire are presented in the Methods section (Table 3).
We collected 352 evaluations from 27 parents based on 41 responses from ChatGPT3.5, including evaluations from eight parents on 15 questions about Vitamin D, nine parents on 16 questions related to food allergies, and 10 parents on 10 questions concerning bedtime problems. Twelve evaluations were missing due to parents skipping certain questions, and the total was calculated as 15 × 8 + 16 × 9 + 10 × 10 – 12 = 352. For ChatGPT4, we gathered 340 evaluations (15 × 8 + 16 × 9 + 10 × 10 – 24 = 340). As shown in Table 3 and Figure 3, more than half of the responses from both ChatGPT3.5 and ChatGPT4 were considered completely clear, and over 80% of the responses received ratings of either “completely clear with no further doubts” or “very clear with few doubts.” A generalized mixed-effects model showed no statistically significant difference between the distributions of ChatGPT3.5 and ChatGPT4 (β = −0.087, p = .617).
Consistency between expert and parent evaluations
In the evaluations of the 41 responses from ChatGPT3.5 and ChatGPT4, the rating trends between parents and experts were consistent (McNemar test, ChatGPT3.5: p = .481; ChatGPT4: p = .143). Additionally, both experts and parents demonstrated consistent evaluation patterns for each version (McNemar test, experts: p = .500; parents: p = 1.000; see Table 4).
Comparison of consistency between parent and expert evaluations.

Parents’ general perceptions of ChatGPT's role
Table 5 summarizes the perceptions of ChatGPT's role in sourcing pediatric health information among 26 parents. Of these, 19 (73.1%) expressed high trust in the medical information provided by ChatGPT, rating it as “strongly trust” or “somewhat trust.” A total of 16 parents (61.6%) believed that ChatGPT's responses either completely or mostly alleviated their anxiety. Slightly more parents preferred ChatGPT's responses over those from traditional search engines, although substantially fewer preferred them over responses from doctors (73.1%). Furthermore, 22 of 25 parents (88.0%) who rated ChatGPT ≥ 3 indicated that they would likely consult it for medical questions in the future. However, no parents reported fully adopting or fully disregarding medical advice provided by ChatGPT.
General perceptions of parents about ChatGPT's role in obtaining accurate medical information.

Discussion
With technological advances, traditional media such as television, radio, newspapers, and government sources are no longer the preferred sources of pediatric healthcare information for most parents. 27 A Canadian study found that 55.3% of respondents preferred the internet. 28 However, misinformation on the internet and social media is widespread and may mislead parental decision-making.7,8 Unlike traditional search engines that rely on keyword matching, LLMs possess advanced natural language processing capabilities that enable them to interpret and respond to complex medical queries more accurately, incorporating context into their responses. Compared to Google search results, ChatGPT reportedly provide more accurate clinical information and higher-quality responses. 29
In this study, all questions submitted to ChatGPT were derived from clinical guidelines developed in China. These guidelines were utilized systematic methods to collect clinical questions deemed most important by healthcare professionals. As a result, this study partially addressed the “selection bias in the lack of representativeness and balance of the question set” noted in previous studies. 30 Our findings highlight the potential of AI-based tools like ChatGPT to provide accurate and reliable information, surpassing traditional internet resources in terms of both accuracy and comprehensiveness. The relatively low rate of completely incorrect responses (9.8%) represents a substantial improvement over the error rates reported for traditional online sources, which can be as high as 44%. 7 However, when considering the broader category of any response containing inaccuracies (“partially” or “completely” incorrect), this rate rises to over 25%. In the context of clinical practice, where patient safety is paramount, such a significant error rate is unacceptable for a tool intended for direct use by patients or parents. Therefore, while promising, its current performance indicates a need for extreme caution and significant further development before it can be considered for reliable clinical integration. Merely expanding the training data is insufficient; a more sophisticated approach is required. For instance, future iterations could implement retrieval-augmented generation (RAG) architectures. This would allow the model to dynamically pull information from curated, up-to-date medical knowledge bases—such as specific clinical guidelines or resources like UpToDate—before generating a response, significantly reducing the risk of outdated or nonauthoritative advice. 31 Furthermore, domain-specific fine-tuning on datasets of pediatric question-answer pairs vetted by experts could improve both accuracy and the appropriateness of the language used. 32 Beyond technological enhancements, exploring different models of implementation is possible. Rather than being a stand-alone tool for parents, ChatGPT could be integrated into clinical workflows as an assistant for healthcare professionals. For example, it could generate initial drafts of responses to common parent queries, which are then reviewed and personalized by a pediatrician before delivery. For parents with limited access to healthcare resources, ChatGPT provides a convenient and rapid way to obtain health information. A recent article presented a comprehensive discussion of the opportunities and challenges in promoting ChatGPT in low- and middle-income countries. 33 The authors proposed that ChatGPT could deliver accurate and user-friendly maternal and child health information to pregnant women and new parents. Our study findings provide valuable data to support this envisioned application. However, the observed differences in ratings between experts and parents indicate that individuals without formal medical training may struggle to discern subtle nuances related to clinical appropriateness or professional depth. This underscores the importance of ongoing professional oversight in evaluating the quality of ChatGPT-generated content.
A noteworthy and somewhat counter-intuitive finding of our study is the lack of a statistically significant improvement in accuracy from ChatGPT4 over ChatGPT3.5, a result that echoes findings in other recent medical AI evaluations. 34 While methodological factors such as our study's limited sample size—discussed in the Limitations section—undoubtedly play a role, several factors intrinsic to the models themselves may also explain this observation. First, the design philosophy of newer models may be a key factor. ChatGPT4 is subject to more intensive safety alignment to make the model more cautious. 35 While crucial for safety, this enhanced cautiousness can result in responses that are more verbose and laden with disclaimers, which experts may have perceived as less direct or comprehensive. Second, while ChatGPT4 possesses a larger model architecture and training dataset, this increased complexity does not always guarantee superior performance on specific tasks. It can sometimes introduce greater response variability or even inconsistent viewpoints, which may negatively impact its perceived accuracy in a domain requiring factual consistency. Furthermore, the inherent lack of transparency—the “black box” nature of these large models—contributes to their performance unpredictability. Even developers do not fully understand the reasoning pathways for every output. 36 Finally, it is possible that our question set, while clinically relevant, was not complex enough to fully leverage the advanced reasoning capabilities that differentiate ChatGPT4. For summarizing established guideline-based information, the performance of ChatGPT3.5 may be largely adequate, with the true advantages of the more advanced model only emerging in tasks requiring more complex, multistep diagnostic reasoning. It is essential to acknowledge that the landscape of generative AI is evolving rapidly. Since this study's data collection, RAG and medically fine-tuned models have emerged as the new standard to mitigate hallucinations. However, our findings serve as a critical real-world baseline. Despite technological advancements, general-purpose LLMs remain the primary access point for caregivers due to their widespread availability. Our observation that ChatGPT4 did not significantly outperform ChatGPT3.5 empirically supports the premise that simply scaling up general-purpose models is insufficient to ensure clinical safety. This validates the necessity of the industry's shift toward specialized architectures.
Beyond these technological insights, a critical finding of our study is the apparent disconnect between expert-identified inaccuracies and the high level of interest and generally positive attitudes among parents toward ChatGPT. This highlights a behavioral risk that transcends specific model versions: public trust tends to outpace AI capability. Documenting this discrepancy is vital for developing future patient education strategies. Several factors may explain this phenomenon. As noted in our results, ChatGPT's responses were well-structured and maintained a friendly tone. This aligns with broader research suggesting that ChatGPT can demonstrate greater empathy than human responses in online forums, with one study finding that 78.6% of evaluators preferred its replies over those from doctors. 37 Another notable strength is its ability to provide detailed and actionable advice. For example, when asked, “Can cosleeping reduce children's bedtime problems and night waking?” ChatGPT not only responds affirmatively but also offers practical strategies. One such response includes: “Gradual withdrawal: If your child is used to your presence during sleep, consider gradually withdrawing your involvement over time. Start by sitting farther away from the bed or crib and gradually move closer to the door until your child can fall asleep without your physical presence.” For caregivers, this accessible and empathetic communication style, coupled with the ability to meet the growing demand for timely and accessible health information more effectively than traditional sources, can engender significant trust. However, this discrepancy between expert scrutiny and parental trust reveals a potential challenge for medical safety: Users may be highly satisfied with potentially harmful advice simply because they are unaware of its limitations. The most direct reason is likely that nonprofessionals lack the domain expertise to identify subtle but critical flaws. While it is encouraging that no parents indicated that they would fully adopt the medical advice provided by ChatGPT without further consultation, most respondents acknowledged the necessity of confirming such advice with healthcare professionals, which aligns with ChatGPT's own disclaimers emphasizing the importance of medical guidance. This may reflect parents’ recognition that face-to-face communication with physicians is essential for addressing their remaining questions and alleviating uncertainty. 38 However, this reliance on the user's discretion is not a foolproof safety measure. The existence of this perception gap powerfully illustrates why the ultimate responsibility for validating AI medical tools must lie with rigorous professional oversight, rather than being placed on the end-user.
In addition, ChatGPT offers several other advantages for caregivers: (a) ChatGPT is not limited by time or location. However, caregivers in low- and middle-income countries may encounter barriers related to device availability and internet infrastructure, 33 which must be considered when evaluating the true accessibility of this technology. (b) ChatGPT enables personalized, two-way interaction, allowing caregivers to ask follow-up questions and gain a deeper understanding of their concerns. This dynamic exchange supports more thorough information delivery and enhances comprehension, especially for caregivers with varying levels of health literacy.
Despite these benefits, ChatGPT has limitations as a medical resource for caregivers. Its response quality is heavily influenced by the clarity and specificity of the input questions. 39 This may be particularly challenging for caregivers with lower educational attainment. For example, when asked, “What are the ways to supplement vitamin D?” ChatGPT offered general suggestions such as dietary sources and sun exposure. However, this response did not address the more specific clinical inquiry about supplementation methods. When the question was reframed as, “What are the ways to supplement vitamin D with medication?” ChatGPT provided a more relevant and satisfactory answer. This example highlights the importance of input formulation and suggests that caregivers may need guidance on how to effectively phrase health-related queries. Another consideration is that ChatGPT can be trained, which represents both a strength and a potential risk. Some researchers have raised concerns that if the model is extensively trained with biased or malicious data in the absence of supervision, it could be manipulated to serve commercial or harmful interests. 14 Citation fabrication by ChatGPT and the lack of transparency regarding data sources also raised concerns about scientific accuracy and trustworthiness.40–42
Finally, the potential for ChatGPT in pediatric healthcare is accompanied by profound ethical challenges that require careful consideration. As our study shows, misinformation exists, the issue of misinformation extends beyond simple inaccuracies. It also includes subtly flawed or out-of-context advice that appears credible, which can be more dangerous than overt errors. When caregivers trust and act on AI-generated medical advice without professional oversight, this reliance may lead to severe risks, including the delayed diagnosis of serious conditions, the administration of inappropriate home remedies, or a false sense of reassurance that prevents timely medical consultation. Such misinformation not only risks causing direct physical harm but can also erode public trust in evidence-based medicine over time. 43 Furthermore, as AI strives for personalization, the risk of providing a generally correct but contextually harmful answer—without access to a child's specific medical history—becomes increasingly significant. For instance, ChatGPT might correctly state the standard 400 IU daily vitamin D dose for a breastfed infant, but to a parent of a preterm baby, this seemingly correct advice is actually inadequate and could lead to preventable deficiency. This risk is compounded by the challenge of overreliance, a phenomenon partly explained by automation bias, 44 where users tend to overtrust automated systems. A long-term dependency on AI for instant answers may also lead to a degradation of parental skills in critical thinking and intuitive decision-making. This can devalue the essential nature of the physician–parent relationship, replacing nuanced dialogue with transactional information retrieval. These challenges culminate in a critical accountability vacuum. 45 Moreover, the limitations of automated safety alignment pose a more direct threat, especially to vulnerable populations. For instance, postpartum depression affects 17.22% of mothers globally, 46 with higher rates in developing countries. 47 In low- and middle-income countries, 76.3% to 85.4% of individuals with severe mental disorders receive no treatment. 48 While ChatGPT incorporates safety mechanisms designed to prevent the generation of self-harming or suicidal content, any failure or misinterpretation by the algorithm could have catastrophic consequences. Addressing this complex ethical landscape requires a robust integration of professional oversight across all levels. The most immediate solution is a human-in-the-loop system, 49 integrating AI as an assistant within clinical workflows to preserve professional accountability, complemented by proactive user education to foster critical digital health literacy. 50 Ultimately, these efforts must be supported by a clear policy and regulatory framework, developed collaboratively to set firm standards for the validation and safe deployment of medical AI. 51 Together, these three pillars—professional integration, user empowerment, and systemic governance—form a necessary foundation for harnessing AI's potential while mitigating its inherent risks.
Limitations
This study has several limitations. First is the issue of representativeness and generalizability. The number of clinical questions, while sourced from authoritative guidelines, is limited and may not fully reflect the types of inquiries that caregivers typically raise. The small and relatively homogeneous sample of parent participants, recruited via convenience sampling, further constrains the applicability of our findings. Specifically, the demographic profile of our parent sample was skewed toward higher educational attainment, with 76.9% holding a college or bachelor's degree. This likely influenced our findings in two key ways: for instance, participants with higher health literacy may have rated the clarity of responses more favorably than a general population would, as they are better equipped to comprehend medical terminology. As recent reviews indicate that ChatGPT's responses often default to a high-school reading level or above, 15 parents with lower literacy might struggle to interpret such information. Furthermore, the high trust levels observed even among this educated cohort suggest that ChatGPT's authoritative tone is highly persuasive. This may pose a significant risk, as uncritical reliance could be even more pronounced in lower-literacy populations who may lack the skills to verify information. Consequently, our results regarding user experience may be optimistic and should be interpreted with caution when considering broader, more socioeconomically diverse populations. The composition of our expert panel, consisting exclusively of senior professors, represents another limitation. While their seniority ensures a high level of clinical authority, it may have introduced a specific evaluation bias. Senior experts typically adhere to stricter standards regarding guideline compliance and may possess different expectations regarding clinical nuance compared to junior clinicians, who might prioritize practical utility or be more accustomed to digital assistance tools. Consequently, our accuracy ratings likely reflect a more rigorous, academic standard than those potentially obtained from a panel with diverse experience levels. Moreover, the entire study was conducted within a Chinese healthcare context. Cultural nuances and differences in healthcare systems mean that our findings, particularly regarding parental perceptions and behaviors, may not be directly transferable to other populations. A critical consequence of the small sample size is the potential for insufficient statistical power, meaning our failure to detect a significant performance difference between ChatGPT3.5 and ChatGPT4 should also be interpreted with caution.
Second, the study's methodology has inherent constraints. Our evaluation was static, analyzing single-shot responses rather than the dynamic, multiturn conversations that often characterize real-world use. We also did not collect data on parents’ prior experience with LLMs or their health literacy levels, which are likely important factors influencing their interaction and interpretation of AI-generated advice. Furthermore, expert evaluations, despite being based on guidelines, are subject to variability in clinical judgment.
Third, the scope of our findings is constrained by the tools themselves. Our analysis was limited to two versions of ChatGPT and did not include comparisons with other prominent LLMs like Bard or Bing. The model's training data cutoff of September 2021 also means it may not reflect the most current clinical guidelines. Future research should aim to overcome these limitations by employing larger, more diverse, and multicenter international samples of both questions and participants, conducting longitudinal and interactive analyses, and performing comparative assessments across a range of LLMs.
Finally, we acknowledge that this study represents a snapshot of performance prior to the widespread adoption of RAG architectures. While this limits the applicability to the newest specialized tools, it establishes a necessary historical benchmark against which the efficacy of future medical models can be quantified.
Conclusion
This study evaluated the potential of ChatGPT in addressing pediatric healthcare queries through a dual-evaluation framework involving clinical experts and caregivers. By systematically assessing 41 clinical questions, we identified a significant trust-accuracy gap: while medical experts highlighted inaccuracies in over a quarter of the AI-generated responses, the majority of parents expressed high trust and perceived the information as clear and helpful. This discrepancy underscores that while general-purpose LLMs like ChatGPT offer unprecedented accessibility to health information, their current performance is insufficient for safe, standalone clinical decision-making. Future integration of AI in pediatrics must prioritize human-in-the-loop systems, where professional oversight validates AI output, coupled with efforts to enhance digital health literacy among parents to bridge the divide between user trust and clinical safety.
Supplemental Material
sj-xlsx-1-dhj-10.1177_20552076261427505 - Supplemental material for Safety and user perception of general-purpose large language models in pediatric healthcare: Evaluations of ChatGPT by doctors and parents
Supplemental material, sj-xlsx-1-dhj-10.1177_20552076261427505 for Safety and user perception of general-purpose large language models in pediatric healthcare: Evaluations of ChatGPT by doctors and parents by Jing Tan, Lin Wang, Guanghai Wang, Yonghong Yang, Feiyong Jia, Xia Chi, Xiaoli Xie, Tingyu Li, Binrang Yang, Huifeng Zhang, Min Gong, Yuxin Wu, Xiuyu Shi and Li Chen in DIGITAL HEALTH
Footnotes
Abbreviations
Acknowledgments
We would like to express our gratitude to the following individuals for their assistance in recruiting parents: Mrs Gao Wenting from Dawn Kindergarten, Mrs Liu Ruixue and Mr Liu Jun from Starlight School, and Mrs Chen Tingting from Shuren Bowen Primary School. Additionally, we sincerely thank the 27 parents who participated in the survey.
Author Contributorship
Jing Tan—conceptualization, data curation, formal analysis, investigation, methodology, writing–original draft, writing–review and editing. Lin Wang, Guanghai Wang, Yonghong Yang, Feiyong Jia, Xia Chi, Xiaoli Xie, Tingyu Li, Binrang Yang, Huifeng Zhang—investigation, writing–review and editing. Min Gong, Yuxin Wu, Xiuyu Shi—conceptualization, writing–review and editing. Li Chen—conceptualization, funding acquisition, investigation, methodology, writing–review and editing.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the National Key Research and Development Program of China (2022YFC2705201), and Chongqing's Technological Innovation and Application Development Sichuan Chongqing Joint Implementation Key R&D Projects (CSTB2022TIAD-CUX0003).
Data availability
All data generated or analyzed during this study are included in this article and its supplementary information files.
Important note on generative AI
ChatGPT was utilized to provide responses to clinical inquiries and to support the translation process.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.