
Abstract
Background
NLP models like ChatGPT promise to revolutionize text-based content delivery, particularly in medicine. Yet, doubts remain about ChatGPT's ability to reliably support evaluations of cognitive performance, warranting further investigation into its accuracy and comprehensiveness in this area.
Method
A cohort of 60 cognitively normal individuals and 30 stroke survivors underwent a comprehensive evaluation, covering memory, numerical processing, verbal fluency, and abstract thinking. Healthcare professionals and NLP models GPT-3.5 and GPT-4 conducted evaluations following established standards. Scores were compared, and efforts were made to refine scoring protocols and interaction methods to enhance ChatGPT's potential in these evaluations.
Result
Within the cohort of healthy participants, the utilization of GPT-3.5 revealed significant disparities in memory evaluation compared to both physician-led assessments and those conducted utilizing GPT-4 (P < 0.001). Furthermore, within the domain of memory evaluation, GPT-3.5 exhibited discrepancies in 8 out of 21 specific measures when compared to assessments conducted by physicians (P < 0.05). Additionally, GPT-3.5 demonstrated statistically significant deviations from physician assessments in speech evaluation (P = 0.009). Among participants with a history of stroke, GPT-3.5 exhibited differences solely in verbal assessment compared to physician-led evaluations (P = 0.002). Notably, through the implementation of optimized scoring methodologies and refinement of interaction protocols, partial mitigation of these disparities was achieved.
Conclusion
ChatGPT can produce evaluation outcomes comparable to traditional methods. Despite differences from physician evaluations, refinement of scoring algorithms and interaction protocols has improved alignment. ChatGPT performs well even in populations with specific conditions like stroke, suggesting its versatility. GPT-4 yields results closer to physician ratings, indicating potential for further enhancement. These findings highlight ChatGPT's importance as a supplementary tool, offering new avenues for information gathering in medical fields and guiding its ongoing development and application.
Introduction
Background
One of the recent advancements in artificial intelligence (AI) tools is ChatGPT, 1 an innovative AI chatbot garnering significant attention for its prowess in executing diverse natural language processing (NLP) tasks. Within a mere 2 months post-launch, ChatGPT amassed a staggering 100 million monthly active users, establishing itself as the fastest-growing consumer application in recorded history. 2 This tool represents a large-scale language model, trained on extensive textual corpora, with the capacity to generate responses reminiscent of human-like interactions based on textual inputs. 3
In the realm of linguistic diversity, the advent of GPT-4 signifies a noteworthy advancement over its predecessor, GPT-3.5. Distinguished by its augmented multilingual abilities,4,5 GPT-4 represents a substantial leap forward in model sophistication, boasting enhanced proficiency across various languages, an expanded contextual understanding, and adeptness in image processing. These advancements hold promise for diverse application domains. 6 Notably, GPT-4 has garnered recognition for its superior performance in comparison to preceding iterations, positioning it as a notable milestone in the progression of conversational AI technologies. 7
Preliminary investigations have demonstrated ChatGPT's efficacy in generating domain-specific information across various disciplines, including but not limited to medical licensure examinations and academic writing. 8 Furthermore, there is ongoing exploration of its integration into clinical settings such as internal medicine, 9 surgery,10,11 oncology,12,13 and radiology,14,15 suggesting its potential utility in medical education and clinical decision-making support systems. However, its aptitude for cognitive recognition and evaluation remains an area yet to be elucidated.
Artificial intelligence in the field of cognition
In recent years, there has been considerable scholarly attention directed toward exploring the potential applications of AI in the realm of cognitive science, encompassing cognitive assessment, diagnosis, training, among other areas. The advent of deep learning methodologies has revolutionized AI, enabling machines to attain human-like performance across various intricate cognitive tasks. 16 Notably, interpretable AI has emerged as a promising approach for facilitating cognitive health assessments. 17 Recent research endeavors have elucidated the efficacy of AI-driven gaming interventions in enhancing attention, perception, 18 and clinical evaluation of cognitive states among elderly individuals with diverse cognitive profiles. 19 Additionally, the utilization of robotic systems for human-machine interaction has demonstrated promise in identifying mild cognitive impairment (MCI), 20 while the development of AI-based cognitive scales has exhibited reliability in cognitive assessment settings. 21
Moreover, the integration of ChatGPT, an AI-driven conversational agent, into cognitive research has yielded noteworthy insights. Studies by Elyoseph et al. have highlighted ChatGPT's proficiency in evaluating emotional awareness 22 and providing psychological support, 23 while Mohamad et al. have underscored its utility in offering fundamental explanations for neuropsychological testing. 24 Furthermore, research conducted by Vagelis et al. has demonstrated ChatGPT's objectivity in responding to inquiries pertaining to dementia and cognitive decline. 25 Francesca et al. have explored the synergistic potential of integrating ChatGPT with social robots to enhance cognitive functioning in individuals with autism spectrum disorder (ASD). 26 Additionally, efforts have been made to introduce AI companions to older adults with cognitive impairments. 27 However, despite these advancements, the direct involvement of ChatGPT in cognitive performance remains relatively unexplored, with limited evidence regarding its ability to generate score patterns in neuropsychological tests. This study seeks to rigorously evaluate the ability of ChatGPT to participate in cognitive performance through comparative analysis with traditional methods.
Cognitive function evaluation
Cognition represents a sophisticated cognitive faculty inherent to the human brain, encompassing the capacity to acquire, assimilate, and apply information to meet environmental demands. It encompasses essential processes such as attention, perception, reasoning, and memory. Cognitive impairment denotes an aberrant presentation of the brain's foundational functions related to the acquisition, retention, reorganization, and processing of information, resulting from brain injury. Such impairment may manifest as deficits in attention, memory, executive functions, reasoning, judgment, and communication abilities. The assessment of cognitive function holds pivotal significance in clinical practice, offering a comprehensive understanding of an individual's cognitive status and attributes. 28 This assessment aids in the diagnosis, classification, and etiological analysis of cognitive impairment. 29
Traditional neuropsychological tests remain the cornerstone for evaluating cognitive function, employing established scales such as the Mini-Mental State Examination (MMSE) and the Montreal Cognitive Assessment (MoCA) is commonplace in clinical settings to gauge overall cognitive functioning. In this study, we extracted select content from these established scales to administer to participants. Subsequently, the responses were evaluated and scored by healthcare professionals, as well as using the AI models GPT-3.5 and GPT-4. The primary objective of this investigation is to compare the performance of physician assessments against GPT-3.5 and GPT-4 in evaluating cognitive function. A secondary objective is to perform a subgroup analysis comparing the performance of each group on different cognitive domains. Additionally, we aim to enhance the evaluation potential of ChatGPT by improving scoring protocols and interactive methods.
Method
Subject
From June 2023 to March 2024, 60 healthy subjects were recruited from the community, including 37 males and 23 females, with an average age of 67.15 ± 4.34 years and an average years of education of 7.28 ± 3.27 years, and 30 stroke patients, including 18 males and 12 females, with an average age of 68.03 ± 3.74 years and an average years of education of 7.07 ± 3.72 years, were matched from the rehabilitation Medicine Department of Changzhou First People's Hospital. There was no significant difference in gender, age and years of education between the two groups, and they were comparable. Inclusion criteria: (a) adult subjects ≥18 years old; (b) clear consciousness, can cooperate with the test; (c) informed consent of the subject and his family; exclusion criteria: (a) Unable to listen to the complete content due to hearing impairment; (b) aphasia exists; (c) taking drugs that may affect intelligence and spirit; (d) the subjects and their families do not cooperate and are not willing to accept the test. Prior to the start of the study, all participants signed a written informed consent form. The study has been approved by the Ethics Review Committee of Changzhou First People's Hospital, (2023)No. 169.
Artificial intelligence
We utilized ChatGPT versions 3.5 and 4.0 (www.chat.openai.com) to assess cognitive performance in both healthy participants and stroke patients.
Test content and scoring criteria
Memory
The subjects were asked to listen carefully to a short story and repeat the story as completely as possible after listening. The retelling was recorded by a rehabilitation physician, and the retelling was scored both by physician and by ChatGPT according to the scoring criteria.
The story is as follows: Mr Li Guangming, a private detective, was shot and killed during a bank robbery in Osaka Castle this Friday. All four robbers were wearing masks, and one was armed with a short-barrelled shotgun. Detectives pored over the witness statements last night. A police spokesman said he was a very brave man. He fought fiercely with the armed bandits.
Chinese version: 李/光明先生/一名私人侦探/本星期五/在大阪城/发生的一起银行抢劫案中/被枪杀。/四个抢劫犯/都佩戴面具/其中一人手持/一只短筒/猎枪。/昨天晚上/警探们/仔细地研究了/目击者的证言。/一位警方发言人说/“他是一个非常勇敢的人。/他与/武装匪徒/进行了激烈的搏斗。
Scoring criteria: original score (maximum score 21). (a) Divide each story into 21 sections (i.e. points). Score based on the number of correctly recalled sections. (b) Score 1 point for reciting each subsection verbatim or using similar synonyms. (c) Score 0.5 points for recalling only part of each subsection or using synonyms with roughly similar (vague) meanings.
Calculation
The subjects will be required to start at 100 and then decrease by 7, continuously decreasing by 5 times (93, 86, 79, 72, 65). Scoring criteria: 1 point is awarded for each correct answer. If the previous answer was wrong but the next answer was correct, 1 point is also awarded.
Language
(1) After the examiner says a sentence, the participant is asked to repeat it as accurately as possible. The first sentence is: “I only know that Zhang Liang was the person who came to help today” (Chinese version: 我只知道今天张亮是来帮过忙的人). After the participant has finished repeating, the second sentence is: “When the dog is in the room, the cat always hides under the sofa” (Chinese version: 狗在房间的时候猫总是躲在沙发下面). Repetition must be accurate, with 1 point awarded for each sentence. Note that omissions, substitutions, additions, and changes in order during repetition do not score points.
(2) Please ask the participant to name as many animals as possible within 1 minute. If the patient can name ≥11 animals within 1 minute, 1 point is scored. Mythical animals such as dragons, phoenixes, and qilins are also considered correct.
Abstraction
Ask the participant to explain in what way each pair of words is similar, or what they have in common. In what way are trains and bicycles similar? In what way are watches and rulers similar? Without providing any further explanation or prompting. If answered correctly, each pair of words is awarded 1 point. Only the following answers are considered correct: Trains and bicycles: conveyance; means of transportation; used for travel. Watches and rulers: measuring instruments; used for measurement.
Input source
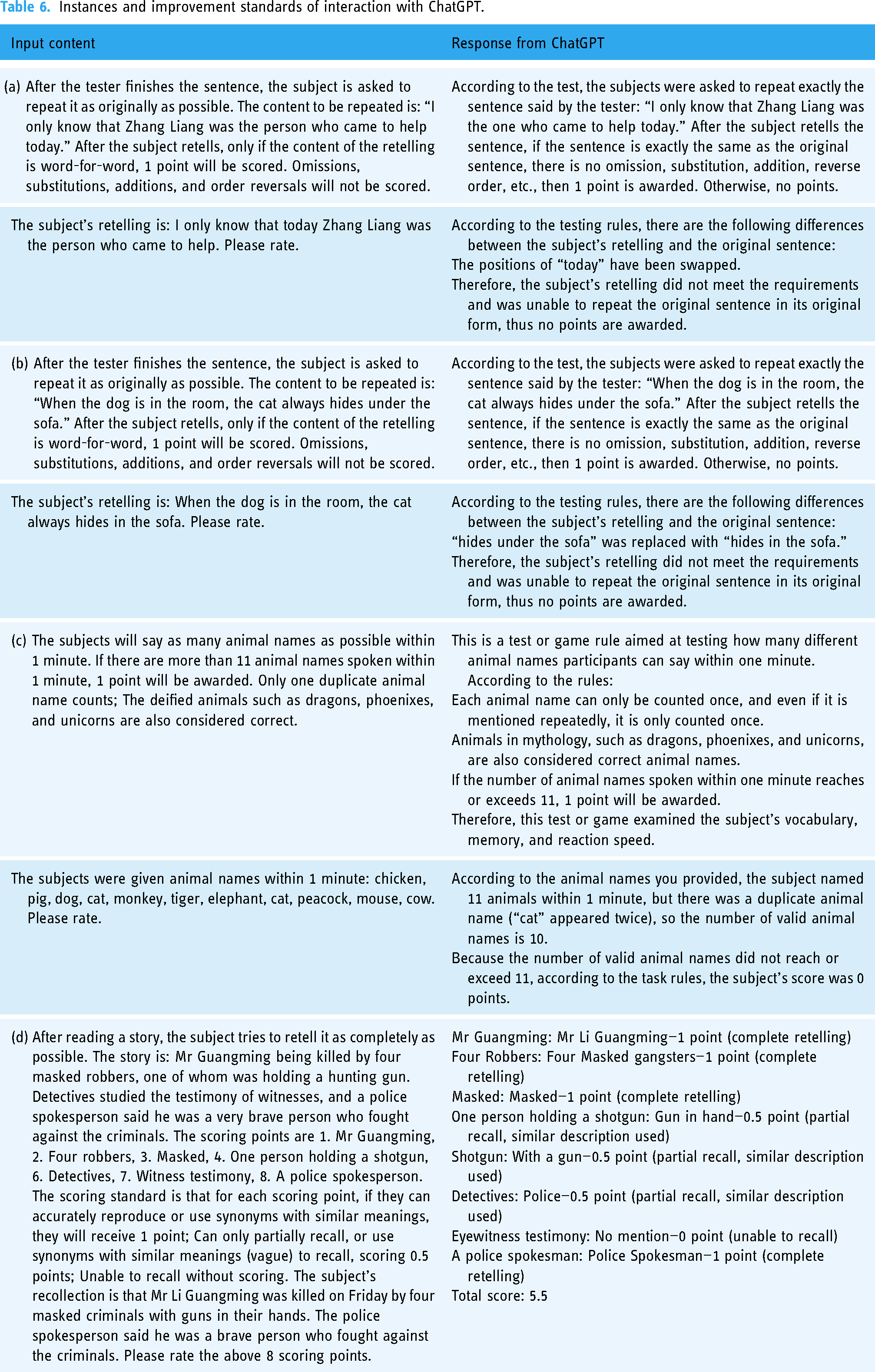
The evaluation content is derived from the Immediate Story Recall subscale of the Rivermead Behavioral Memory Test-II (RBMT-II), 30 the Calculation subscale of the MMSE, 31 and the Language and Abstraction subscales of the MoCA. 32 By interacting with ChatGPT, the assessment process is demonstrated, and scores are created based on the scoring criteria. In both GPT-3.5 and GPT-4 modes, the participation results of each subject are obtained through separate conversations in new tabs, including assessments of memory, calculation, language, and abstraction. In GPT-3.5 mode, the memory and language assessment results for healthy subjects, as well as the language assessment results for stroke subjects, differ from those of physician, leading to improved results through new interactions. That is to say, in addition to completing the original four conversational assessments, healthy subjects had two additional improved conversations, while stroke subjects had one additional improved conversation. (The specific interaction instance is detailed in Table 1, 2, 3, 4, 6, with a reference to the interaction template of one subject. The Chinese versions of all interaction instances can be found in Supplementary Materials.) Considering the generative nature of AI, multiple inputs are provided to ensure the consistency of ChatGPT's understanding.
Instance 1 of interaction with ChatGPT.

Instance 2 of interaction with ChatGPT.

Instance 3 of interaction with ChatGPT.

Instance 4 of interaction with ChatGPT.

Scoring
The cognitive performance of all participants was scored by physicians, GPT-3.5, and GPT-4 according to the scoring criteria. Two rehabilitation physicians participated in the physician scoring to test the consistency between raters. The results showed good consistency among raters for each cognitive item (ICC > 0.95, P < 0.001).
Statistics
Physicians and ChatGPT evaluate the cognitive performance of participants based on scoring criteria. SPSS22.0 statistical software was used to process the data. When the data were normally distributed, t-tests and ANOVA was used for comparison. When the normal distribution is not followed, the Mann–Whitney U test is used for comparison. Significance level α = 0.05.
Result
Descriptive statistics
Table 5 shows the gender, age, education level, and cognitive function scores of participants in the healthy and stroke groups. The results showed that there was no statistically significant difference in gender, age, education level between the two groups of participants (P > 0.05). Compared with the healthy group, the stroke group had lower scores in memory, calculation, language and abstraction, and the difference was statistically significant (P < 0.05).
Comparison of cognitive scores between the health group and the stroke group.
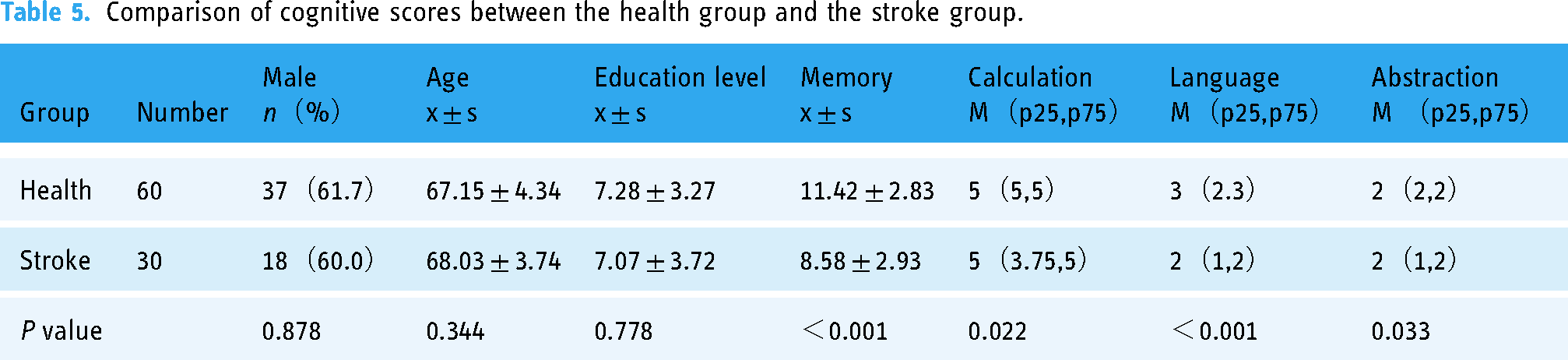
Among healthy subjects, there were significant differences in memory scores between the physician group, GPT-3.5 group, and GPT-4 group (P < 0.001), with a significant difference in GPT-3.5 and physician group scores (P < 0.001). There was a significant difference in GPT-3.5 and GPT-4 group scores (P < 0.001), while there was no significant difference in GPT-4 and physician group scores (P = 0.8) (Figure 1). Among stroke subjects, there was no significant difference in memory scores between the physician group, GPT-3.5 group, and GPT-4 group (Figure 2).

Comparison of memory scores among three groups of health subjects.

Comparison of memory scores among three groups of stroke subjects.
Among healthy subjects, the comparison of memory scores between the physician group and the GPT-3.5 group showed differences in the 2nd, 8th, 9th, 10th, 12th, 14th, 16th, and 17th sections (P < 0.05) (Figure 3). The comparison of memory scores between the physician group and the GPT-4 group showed that there was only a difference between the 7th, 9th, 15th, and 20th sections (P < 0.05) (Figure 4).

Comparison of memory sections between physician group and GPT-3.5 group.

Comparison of memory sections between physician group and GPT-4 group.
Among healthy subjects, there were differences in language scores between the physician group and the GPT-3.5 group (P = 0.009), but no significant differences in the rest (P > 0.05) (Figure 5). Among stroke subjects, there were differences in language scores between the physician group and the GPT-3.5 group (P = 0.002), but no significant differences in the rest (P > 0.05) (Figure 6).

Comparison of three group in calculation, language and abstraction (health subjects).

Comparison of three group in calculation, language and abstraction (stroke subjects).

Comparison between physician and GPT-3.5 groups in memory sections and language (health subjects).

Comparison between physician and GPT-3.5 groups in language (stroke subjects).
In the above results, GPT-3.5 scores differed with physicians on memory and language assessments in healthy subjects and language in stroke subjects. The differences were extracted separately, and the accuracy of GPT-3.5 evaluation was attempted to be improved by re interacting and improving the scoring criteria. The interactive instance and improvement standards are shown in Table 6. After testing, optimizing the interaction process and scoring rules can reduce most of the differences, with only differences observed in 8th and 14th sections of memory (P < 0.05), and no significant differences observed in the rest (P > 0.05) (Figure 6).
Instances and improvement standards of interaction with ChatGPT.
Discussion
The integration of NLP models, notably exemplified by ChatGPT, into cognitive assessment frameworks represents a paradigm shift in the field of neuropsychology and medicine. We highlight a pioneering study aimed at investigating the reliability and efficacy of ChatGPT, particularly GPT-3.5 and GPT-4, in analyzing cognitive performance. The results delineate specific relationships between NLP-generated evaluations and those conducted by healthcare professionals, while also illuminating potential avenues for refinement and optimization.
Cognitive assessment serves as a cornerstone in various fields, including healthcare, education, and research. It enables the evaluation of cognitive functions such as memory, attention, language, and executive functions, providing valuable insights into an individual's cognitive health. Traditionally, cognitive assessments have been conducted by trained professionals using standardized neuropsychological tests. However, the advent of NLP models presents an opportunity to complement or potentially revolutionize these conventional methodologies. The research highlights the promise of NLP models, exemplified by ChatGPT, in furnishing text-based content and serving as an information conduit in diverse domains, including medicine. NLP models possess the capability to comprehend and generate human-like text, making them suitable candidates for cognitive assessment tasks. Their potential lies in their ability to process natural language input, interact with users in a conversational manner, and generate responses that mimic human cognitive processes to some extent.
In contrast to physician-led evaluations, the performance of GPT demonstrates notable efficacy in various domains, indicating good accuracy and reliability. GPT exhibits proficiency in objectively and systematically appraising cognitive function, generating coherent and accurate responses, and adapting to diverse contextual nuances. Despite minor disparities observed in memory and speech domains, these discrepancies underscore the early-stage limitations of GPT in capturing subtle cognitive nuances accurately. However, such differences do not undermine the potential utility of GPT; instead, they underscore the imperative for continuous refinement and enhancement. Strategies aimed at ameliorating dissimilarities through refined scoring and interaction protocols represent crucial avenues for advancement. In this study, we achieved favorable outcomes through well-designed, short and ‘few-shot’ examples for fine-tuning purposes. Through systematic refinement efforts, researchers have managed to achieve partial alignment between GPT-derived evaluations and those conducted by physicians. This iterative refinement process is pivotal for enhancing the reliability and validity of NLP models in cognitive assessment contexts. Furthermore, this investigation underscores the superiority of more sophisticated NLP iterations such as GPT-433,34 in cognitive evaluation tasks, evident in their closer approximation to physician assessments. Ongoing advancements in NLP technology are poised to further augment proficiency in cognitive appraisal, signaling a trajectory of continual enhancement and integration of NLP-based cognitive assessment methods into clinical practice.
In individuals with a history of stroke, the utilization of ChatGPT, particularly GPT-3.5, revealed disparities primarily in verbal assessments when compared to evaluations conducted by physicians. This observation suggests that while ChatGPT may exhibit variations in certain cognitive domains, it has the potential to yield outcomes akin to conventional assessments within this distinct demographic. Such findings are promising, indicating the viability of ChatGPT in furnishing cognitive evaluations for individuals with specific pathological conditions. It is imperative to acknowledge, however, that within a specified population, the complexity and heterogeneity of cognitive profiles persist, necessitating thoughtful consideration regarding the model's ability to effectively encapsulate the nuances and severity of cognitive decline. 35 Furthermore, there is a need to emulate the holistic approach of physicians, encompassing comprehensive scrutiny of patients’ medical histories, clinical presentations, and pertinent contextual details, within the framework of the GPT model. 36 Substantial further inquiry is warranted to validate and substantiate these deliberations. Overall, caution is warranted in deploying GPT within specific pathological contexts, and concerted efforts toward enhancement and refinement are requisite, particularly in populations with distinct pathophysiological profiles 37 like stroke patients.
Presently, ChatGPT's response to cognitive content is still in its early stages; however, with further research and model refinement, several advantages in cognitive evaluation are anticipated. Firstly, there is the prospect of amalgamating diverse cognitive assessment protocols into an extensive database, encompassing test parameters, methodologies, benchmarks, scores, and outcomes, thereby enabling cognitive assessment services to be accessible without temporal or spatial constraints, facilitating on-demand participation in assessments, and furnishing immediate results and recommendations. Secondly, there is the potential to mitigate the laborious time and resource investments inherent in conventional assessment methodologies, thereby circumventing the influence of certain unstable variables on evaluation outcomes. Relative to conventional “question-response” frameworks, ChatGPT exhibits the capacity to engender a highly intelligent, proficient, and precise assessment model, laying a robust foundation for cognitive screening and decision-making across large population cohorts. Thirdly, there lies the possibility of delivering efficacious cognitive enhancement services for individuals with cognitive deficits. By means of assessment and screening, individuals exhibiting latent cognitive impairment can be meticulously categorized into distinct cognitive domains such as memory, numeracy, executive function, and verbal acuity, subsequently receiving tailored cognitive training regimens. Such interventions hold promise in ameliorating the overall prognosis of individuals grappling with cognitive impairment and enhancing their quality of life.
Several limitations are in this study. Firstly, the sample size was relatively small, which may limit the generalizability of the findings. Future research should focus on enhancing sample size and refining selection criteria to ensure comprehensiveness and complexity in the cognitive content under investigation, as well as to delineate the cognitive status of the participant cohort more accurately. Additionally, efforts to integrate the findings of this study into practical clinical settings warrant attention. Secondly, all subjects in the study were sourced from China, and the ChatGPT interaction process was conducted exclusively in Chinese. It is important to recognize that language variations may exert influence on the performance of GPT and subsequent test outcomes. 38 Hence, future investigations should consider cross-cultural and multilingual contexts to ascertain the robustness and applicability of findings across diverse linguistic and cultural backgrounds.
Conclusion
Our study demonstrates that cognitive performance assessments generated by ChatGPT exhibit good reliability in both healthy and stroke populations. Improvements in assessment methods and interaction protocols can enhance the accuracy of these evaluations. Compared to GPT-3.5, results produced by GPT-4 are more closely aligned with those of physicians. While challenges and limitations persist, the trajectory of ChatGPT in the field of cognition is marked by significant promise and potential. With continued refinement and innovation, ChatGPT is poised to play a pivotal role in augmenting cognitive evaluation practices, ultimately enhancing patient care and clinical decision-making in the realm of neuropsychology and medicine.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241264639 - Supplemental material for Evaluating cognitive performance: Traditional methods vs. ChatGPT
Supplemental material, sj-docx-1-dhj-10.1177_20552076241264639 for Evaluating cognitive performance: Traditional methods vs. ChatGPT by Xiao Fei, Ying Tang, Jianan Zhang, Zhongkai Zhou, Ikuo Yamamoto and Yi Zhang in DIGITAL HEALTH
Footnotes
Acknowledgements
This article is part of the ongoing work of the author and team in applying ChatGPT to cognitive assessment in clinical practice.
Contributorship
All authors make authorship contributions including conceptualization, expertise, technicalities, preparation of the initial draft, review and revision of the final version of this study.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
The study was approved by Ethics Committee of Changzhou First People's Hospital. Informed consent was taken from all study participants.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.