
Abstract
Background
This study investigated the efficacy of ChatGPT-3.5 and ChatGPT-4 in assessing drug safety for patients with kidney diseases, comparing their performance to Micromedex, a well-established drug information source. Despite the perception of non-prescription medications and supplements as safe, risks exist, especially for those with kidney issues. The study's goal was to evaluate ChatGPT's versions for their potential in clinical decision-making regarding kidney disease patients.
Method
The research involved analyzing 124 common non-prescription medications and supplements using ChatGPT-3.5 and ChatGPT-4 with queries about their safety for people with kidney disease. The AI responses were categorized as “generally safe,” “potentially harmful,” or “unknown toxicity.” Simultaneously, these medications and supplements were assessed in Micromedex using similar categories, allowing for a comparison of the concordance between the two resources.
Results
Micromedex identified 85 (68.5%) medications as generally safe, 35 (28.2%) as potentially harmful, and 4 (3.2%) of unknown toxicity. ChatGPT-3.5 identified 89 (71.8%) as generally safe, 11 (8.9%) as potentially harmful, and 24 (19.3%) of unknown toxicity. GPT-4 identified 82 (66.1%) as generally safe, 29 (23.4%) as potentially harmful, and 13 (10.5%) of unknown toxicity. The overall agreement between Micromedex and ChatGPT-3.5 was 64.5% and ChatGPT-4 demonstrated a higher agreement at 81.4%. Notably, ChatGPT-3.5's suboptimal performance was primarily influenced by a lower concordance rate among supplements, standing at 60.3%. This discrepancy could be attributed to the limited data on supplements within ChatGPT-3.5, with supplements constituting 80% of medications identified as unknown.
Conclusion
ChatGPT's capabilities in evaluating the safety of non-prescription drugs and supplements for kidney disease patients are modest compared to established drug information resources. Neither ChatGPT-3.5 nor ChatGPT-4 can be currently recommended as reliable drug information sources for this demographic. The results highlight the need for further improvements in the model's accuracy and reliability in the medical domain.
Keywords
Background
In contemporary times, the utilization of search engines has brought about a revolutionary change in the way people acquire information, particularly concerning health-related matters. 1 The convenience and ease of searching for drug safety information online have rendered search engines highly popular among individuals seeking knowledge about medication safety. Over-the-counter medications and supplements, often regarded as innocuous and readily accessible, are extensively used by the general population. 2 Nevertheless, over-the-counter medications and supplements are associated with serious adverse effects in individuals with underlying kidney ailments.3,4 Kidney diseases, including chronic kidney disease, are prevalent conditions that affect a substantial proportion of the global population. 5 In order to ensure optimal patient care and avert potential harm, it is crucial to accurately interpret the safety of medications within the context of kidney disease.
While healthcare practitioners have traditionally turned to tertiary drug information resources such as Micromedex to determine the safety of non-prescription medications and supplements, the advent of advanced artificial intelligence large language models, including ChatGPT-3.5 and ChatGPT-4, has generated considerable interest in their potential to enhance clinical decision-making processes.6–10 These models employ state-of-the-art natural language processing techniques, with ChatGPT-4 demonstrating enhanced proficiency compared to its predecessor, to generate responses that closely resemble human-generated ones. 11 ChatGPT-3.5 and ChatGPT-4 have garnered attention due to its ability to comprehend and respond to intricate queries, making it a prospective resource for individuals seeking drug-related information.12,13 However, it is uncertain the extent to which these large language models can be used for guiding non-prescription medication and supplement safety considerations in patients with kidney disease. 14 We therefore sought to evaluate ChatGPT-3.5 and ChatGPT-4's performance in assessing the safety of over-the-counter medications and supplements in patients with kidney disease, while simultaneously comparing its performance to that of Micromedex.
Method
Study design
This study aimed to evaluate the accuracy of ChatGPT in assessing the safety of commonly used non-prescription medications and supplements in individuals with kidney disease. The study was designed as a comparative analysis, aiming to evaluate the efficacy of artificial intelligence language models, specifically ChatGPT-3.5 and ChatGPT-4, in this regard. The research was conducted over a period of 3 months, from March 2023 to May 2023. This timeframe was selected to ensure ample opportunity for data collection and analysis, allowing for a comprehensive evaluation of the AI models’ performance over a sustained period. The study was carried out utilizing virtual environments for accessing the OpenAI API and Micromedex database, thereby not being limited to a physical location. However, the coordination and oversight of the study activities, including the formulation of queries to the AI models and the categorization of responses, were managed from our research institution located in Mayo Clinic, Minnesota. A systematic approach was employed, comparing the outputs from ChatGPT with the categorization of safety provided by the Micromedex database. Additionally, the findings were confirmed by experienced pharmacists. This study does not involve human or animal subjects, nor does it include patient information or identifiable personal data; thus, ethical approval and informed consent were not needed.
Inclusion criteria encompassed medications and supplements commonly used by the general population and those of particular interest or concern for individuals with kidney disease. This included, but was not limited to, over-the-counter pain medications, common cold preparations, gastrointestinal upset remedies, topical treatments for skin conditions, and a broad range of dietary supplements known for their potential renal implications. Exclusion criteria were designed to narrow the focus of our study to non-prescription items, thereby excluding any prescription medications, medications primarily used for the treatment of conditions other than those for which over-the-counter versions are intended, and supplements not widely available or recognized by authoritative bodies such as the FDA or similar regulatory agencies. Additionally, products with scarce or ambiguous information regarding their safety in kidney disease were also excluded to maintain the integrity and reliability of our findings.
Accessing ChatGPT
Access to ChatGPT was facilitated through the OpenAI API, offering programmatic access to both the ChatGPT-3.5 and ChatGPT-4 language models. The specific version of ChatGPT-3.5 utilized in this study was the OpenAI version known for its proficiency in natural language processing tasks. Similarly, the GPT-4 version, which represents a more advanced iteration, was employed to ensure a comprehensive evaluation. The series of queries was conducted on in from March 2023 to May 2023 utilizing OpenAI versions of both ChatGPT-3.5 and ChatGPT-4, providing a robust comparison of their performance in assessing the safety of non-prescription medications and supplements in patients with kidney disease.
Selection of non-prescription medications and supplements
A comprehensive evaluation encompassing a cohort of 124 widely utilized non-prescription medications and supplements was selected for evaluation. The selection of these entities was grounded in their prevalent utilization within clinical practice, coupled with a discerning consideration for their potential relevance to individuals affected by kidney disease.
Query and categorization process
The inquiry presented to both ChatGPT-3.5 and ChatGPT-4 for each non-prescription medication and supplement was structured as follows: “Is [Name of the Medication/Supplement] safe in people with kidney disease?” Subsequently, the generated output from both ChatGPT-3.5 and ChatGPT-4 underwent thorough examination, and the outcomes were meticulously categorized into one of three classifications: “generally safe,” “potentially harmful,” or “unknown toxicity.” This method ensured a comprehensive evaluation of the safety assessments provided by both language models for non-prescription medications and supplements in the context of kidney disease.
Comparison with micromedex
To establish a foundation for comparison, the safety evaluation of the same non-prescription medications and supplements was conducted using the Micromedex database. Micromedex, a widely recognized and authoritative reference database, offers comprehensive information on drug interactions, adverse effects, and safety precautions. The safety categorization in Micromedex mirrored the process outlined earlier for ChatGPT-3.5 and ChatGPT-4.
The results derived from both ChatGPT-3.5 and ChatGPT-4, as well as Micromedex, underwent additional scrutiny by experienced pharmacists. These professionals meticulously reviewed the assessments provided by both language models and cross-referenced them with the information available in Micromedex. Their expertise and knowledge in pharmaceuticals served as an additional layer of validation, ensuring the robustness and reliability of the study's findings.
Concordance assessment
The concordance between the outputs from both ChatGPT-3.5 and ChatGPT-4 and Micromedex was determined. The level of agreement was then summarized to comprehensively assess the accuracy of ChatGPT, considering both iterations, in evaluating the safety of non-prescription medications and supplements for individuals with kidney disease. This approach allowed for a nuanced understanding of the performance of both language models in comparison to the widely used Micromedex database.
To calculate the Overall Concordance Percentage for both ChatGPT-3.5 and ChatGPT-4:
Determine the “Number of times Micromedex, ChatGPT-3.5, and ChatGPT-4 agree for all medications.” Divide that number by the “Total number of medications assessed.” Multiple the result by 100 to convert it into a percentage.
This method ensures a comprehensive assessment of the agreement between Micromedex, ChatGPT-3.5, and ChatGPT-4 across all evaluated non-prescription medications and supplements, providing a robust measure of overall concordance.
In addition, to enhance the accuracy of our agreement assessment between ChatGPT versions 3.5 and 4.0 and Micromedex, we have adopted the Cohen's Kappa test (κ) as the statistical method of choice. This approach calculates the agreement between the two sources by taking into account the observed agreement (Po) and the expected agreement by chance (Pe), according to the formula: κ = (Po - Pe) / (1 - Pe). The results of this test provide a more nuanced understanding of the agreement, categorized as follows: 0.10–0.20 indicating slight agreement, 0.21–0.40 indicating fair agreement, 0.41–0.60 indicating moderate agreement, 0.61–0.80 indicating substantial agreement, 0.81–0.99 indicating near-perfect agreement, and 1.00 indicating perfect agreement.
Results
In the comprehensive analysis of 124 commonly used non-prescription medications and supplements, a thorough examination was conducted across distinct subclasses, including pain medications (7), common cold medications (15), gastrointestinal (GI) upset medications (26), topical skin condition medications (8), and supplements (68) (Supplemental material1). Micromedex identified 85 (68.5%) of the assessed medications as “generally safe,” while designating 35 (28.2%) as “potentially harmful,” and 4 as “unknown.” Conversely, the language models, ChatGPT-3.5 and ChatGPT-4, presented nuanced perspectives, with ChatGPT-3.5 identifying 89 (71.7%) as “generally safe,” 11 (8.8%) as “potentially harmful,” and 24 (19.3%) as “of unknown toxicity.” The more advanced ChatGPT-4 identified 82 (66.1%) as “generally safe,” 29 (23.4%) as “potentially harmful,” and 13 (10.5%) as “of unknown toxicity” (Figure 1

Comparison of micromedex and ChatGPT assessments for 124 commonly used medications and supplements.

Concordance between micromedex and ChatGPT assessments by medication subclasses.
A granular analysis of 85 medications classified as “generally safe” by Micromedex revealed insightful findings. ChatGPT-3.5 identified 68 (80.0%) as “generally safe,” flagged 3 (3.5%) as “potentially harmful,” and classified 14 (16.5%) as “unknown toxicity” (Figure 3). In comparison, ChatGPT-4 marked a more substantial proportion as “generally safe,” identifying 74 (87.1%), and designating 4 (4.7%) as “potentially harmful,” with only 7 (8.2%) deemed “of unknown toxicity” (Figure 4). Shifting focus to the 35 medications classified as “potentially harmful” by Micromedex, ChatGPT-3.5 identified 8 (22.8%) as such, labeled 21 (60%) as “generally safe,” and assigned 6 (17.1%) to the category of “unknown toxicity” (Figure 5). Intriguingly, ChatGPT-4 demonstrated a nuanced perspective, designating 8 (22.9%) as “generally safe,” marking 26 (74.3%) as “potentially harmful,” and classifying only 1 (2.9%) as “of unknown toxicity” (Figure 6).

ChatGPT assessment of medications classified as “Safe” by micromedex.

ChatGPT assessment of medications classified as “Potentially Harmful” by micromedex.
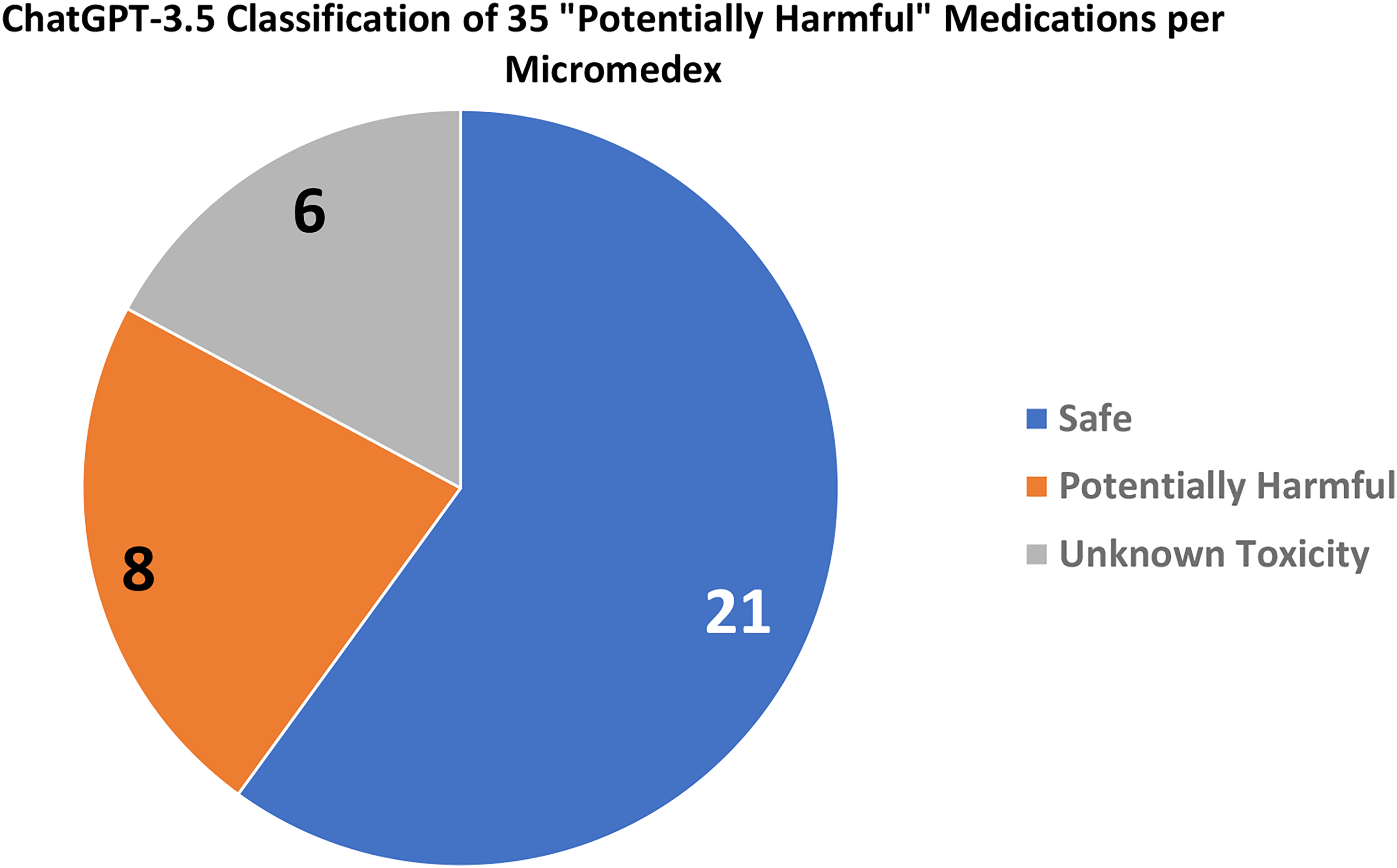
Classification of medications deemed “Potentially Harmful” by micromedex as evaluated by ChatGPT-3.5.
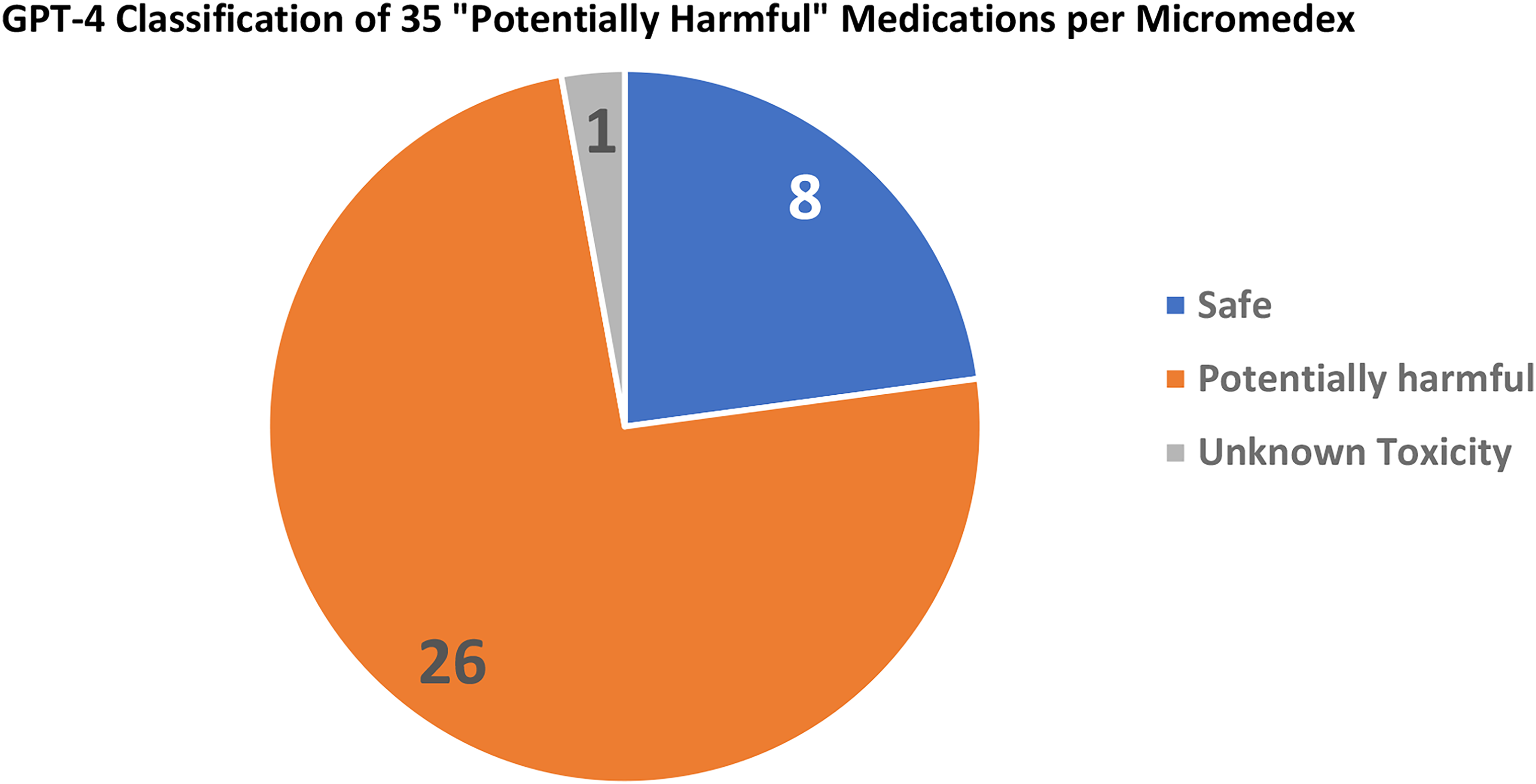
ChatGPT-4's reassessment of medications classified as “Potentially Harmful” by micromedex.
Upon applying the Cohen's Kappa test to assess the level of agreement between ChatGPT versions and Micromedex regarding the safety categorizations of the evaluated non-prescription medications and supplements, we observed the following:
The agreement between ChatGPT-3.5 and Micromedex yielded a Cohen's Kappa value of κ = 0.62, which falls into the range of substantial agreement. This suggests that, despite the observed limitations, ChatGPT-3.5 significantly aligns with the established drug safety assessments provided by Micromedex, with room for improvement. For ChatGPT-4, the Cohen's Kappa test indicated a higher level of agreement with Micromedex, achieving a value of κ = 0.83. This result falls within the range of near-perfect agreement, underscoring the marked improvement in ChatGPT-4's ability to assess the safety of non-prescription medications and supplements for individuals with kidney disease in alignment with Micromedex's recommendations.
Discussion
The principal aim of this study was to evaluate the efficacy of ChatGPT, an advanced artificial intelligence language model, in gauging the safety of non-prescription medications and supplements for individuals with kidney disease. 15 The investigation revealed that ChatGPT's proficiency in discerning the safety of these medications, when juxtaposed with Micromedex, a widely utilized tertiary drug information reference, was relatively modest. This assessment was extended to include the latest version, ChatGPT-4, to gauge any improvement in performance.
Micromedex, recognized for its credibility and expansive database, has long been a cornerstone for healthcare professionals seeking comprehensive and up-to-date drug-related information. 16 Its robustness positioned it as an apt benchmark for assessing the performance of ChatGPT. By comparing the outputs generated by ChatGPT-3.5 and ChatGPT-4 with the assessments provided by Micromedex, valuable insight was gained regarding ChatGPT's ability to discern medication safety in individuals with kidney disease.
In a comparative analysis between Micromedex and both ChatGPT-3.5 and its updated version, ChartGPT-4, it was observed that Micromedex exhibited superior performance in the identification of medications with potential harm, particularly concerning patients with kidney disease. While both platforms predominantly categorized medications as generally safe, Micromedex maintained a more stringent classification, identifying a greater proportion of medications as potentially harmful. In contrast, both ChatGPT-3.5 and ChatGPT-4 displayed reduced sensitivity in flagging medications that could be detrimental to this patient population. The concordance between Micromedex and ChatGPT-3.5 was quantified at 65%, indicating a suboptimal alignment of ChatGPT-3.5's evaluations with those of Micromedex. A salient factor contributing to this divergence was the limited dataset pertaining to dietary supplements. These supplements were predominantly categorized by ChatGPT-3.5 as having indeterminate toxicity, and they accounted for a substantial fraction of the medications that exhibited low agreement between the two platforms. Therefore, the paucity of data on supplements significantly influenced the observed discrepancy in performance metrics. While ChatGPT-3.5 showed potential in improving clinical decision-making, ChatGPT-4 presented a notable improvement in performance with a concordance of 81%. In addition, findings derived from the Cohen's Kappa statistical analysis further enrich our study by providing a quantitatively robust measure of agreement between the AI models and the Micromedex database. They corroborate our initial observation of improved performance in ChatGPT version 4.0 over version 3.5 and highlight the potential of AI in augmenting healthcare decision-making processes, with an emphasis on the continuous enhancement of AI technologies for better accuracy and reliability in clinical settings. However, caution is warranted, and further refinement and enhancement of these models are still necessary to ensure their accuracy and reliability in providing drug information specific to patients with kidney disease.17,18 Incorporating comprehensive and updated data on medications, including supplements, is crucial for enhancing the performance of AI models like ChatGPT. 19
Future studies should focus on addressing the limitations identified in this study to enhance the performance of AI language models like ChatGPT in evaluating the safety of non-prescription medications and supplements for patients with kidney disease.20,21 Expanding the dataset available to the model, particularly with regard to supplements, is crucial. 22 Additionally, investigating the reasons behind ChatGPT's lower sensitivity in identifying potentially harmful medications compared to Micromedex and identifying strategies to improve this sensitivity are necessary. This may involve refining the model's algorithms and training it on a larger and more diverse dataset of drug safety information specifically tailored to patients with kidney disease. Furthermore, it would be valuable to examine the performance of ChatGPT in other disease contexts beyond kidney disease, as different diseases may have unique considerations and interactions with medications. Such investigations would provide a more comprehensive understanding of ChatGPT's capabilities and limitations, enabling researchers to identify areas where the model excels and areas that require further improvement.
Several limitations should be considered in interpreting the findings of this study. Firstly, the focus on non-prescription medications and supplements excludes the evaluation of prescription medications commonly used by patients with kidney disease. Therefore, the generalizability of the findings to the broader context of medication safety in kidney disease may be limited. Secondly, the study relied on a single drug information resource, Micromedex, as the comparator for ChatGPT. While Micromedex is widely used and trusted, utilizing multiple drug information references or expert consensus could offer a more robust evaluation and mitigate potential biases or limitations associated with a single reference. Furthermore, the study evaluated ChatGPT's performance based on a specific query format, which might have influenced the model's performance. Exploring alternative query formats or refining the query structure could enhance the model's understanding and interpretation of drug safety information for individuals with kidney disease. In our study, we selected Micromedex as a reference for assessing the safety of non-prescription medications and supplements, given its broad acceptance and utilization as a drug information resource. However, it is crucial to clarify that while Micromedex is respected for its comprehensive database and commitment to high evidence standards, our comparison did not extend to validating Micromedex's precision against an independent comparative database or reference. Therefore, the mention of Micromedex's ‘superiority’ in our discussion aimed not to assert its infallibility but to contextualize the performance of ChatGPT versions against a recognized standard in drug information. Additionally, the study solely focused on ChatGPT's ability to determine medication safety, neglecting other important aspects such as dosing recommendations, potential drug interactions, and contraindications. Expanding the scope to encompass a broader range of drug information aspects relevant to patients with kidney disease would provide a more comprehensive evaluation. Moreover, the study did not involve direct clinical validation or assess the impact of ChatGPT's recommendations on patient outcomes. Evaluating the real-world clinical impact and effectiveness of AI language models like ChatGPT would provide valuable insights into their practical implications and utility in healthcare decision-making.14,23 Furthermore, future studies should focus on optimizing input prompts to guarantee that they are carefully crafted to extract the most pertinent and precise data from large language models.24,25 This may entail creating standardized prompt structures specifically tailored for medical queries, thus improving the accuracy of the generated responses. Finally, the study did not address the challenges and barriers to the implementation of AI language models in clinical practice, including user acceptance, integration into existing healthcare systems, and considerations related to data privacy and security. 26 Future research should investigate these implementation-related factors to ensure successful integration and adoption of AI language models in the healthcare setting. Despite these limitations, this study offers valuable insights into ChatGPT's performance in assessing the safety of non-prescription medications and supplements for individuals with kidney disease. Acknowledging these limitations lays the foundation for future research to build upon these findings, address the identified gaps, and enhance the accuracy, reliability, and applicability of AI language models in the field of drug safety and clinical decision-making.
In conclusion, this study, encompassing the analysis of both ChatGPT-3.5 and the updated ChatGPT-4, underscores that ChatGPT's performance in assessing the safety of non-prescription medications and supplements in patients with kidney disease is modest compared to a well-established drug information resource such as Micromedex. While AI language models, including ChatGPT-4, hold promise in various healthcare applications, including drug safety assessment, the findings emphasize that further advancements are necessary to enhance their accuracy and reliability in providing drug information tailed to the specific needs of patients with kidney disease. Continued research and development in this area, incorporating improvements based on ChatGPT-3.5 and ChatGPT-4 insights, will be essential to leverage the full potential of AI in improving clinical decision-making and enhancing patient care within the realm of medication safety.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241248082 - Supplemental material for Evaluating ChatGPT's efficacy in assessing the safety of non-prescription medications and supplements in patients with kidney disease
Supplemental material, sj-docx-1-dhj-10.1177_20552076241248082 for Evaluating ChatGPT's efficacy in assessing the safety of non-prescription medications and supplements in patients with kidney disease by Mohammad S. Sheikh, Erin F. Barreto, Jing Miao, Charat Thongprayoon, James R Gregoire, Benjamin Dreesman, Stephen B. Erickson and Iasmina M. Craici, Wisit Cheungpasitporn in DIGITAL HEALTH
Footnotes
Contributorship
Conceptualization: MSS, EFB, CT, JM, WC, JG, BD, SBE, and IMC. Data curation: MSS, CT, and WC. Formal analysis: MSS and WC. Funding acquisition: EFB and WC. Investigation: MSS, EFB, CT, WC, SBE, and IMC. Methodology: MSS, EFB, JM, WC, and BD. Project administration: CT, JM, and JG. Resources: WC and BD. Software: MSS and WC. Supervision: EFB, JM, WC, and IMC. Validation: MSS, EFB, WC, and JG. Visualization: MSS, EFB, and WC. Writing – original draft: MSS. Writing – review & editing: MSS, EFB, CT, JM, WC, JG, BD, and SBE. All authors have read and agreed to the published version of the manuscript.
Data availability statement
The data underlying this article will be shared on reasonable request to the corresponding author.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethics approval
This study does not require Ethics Committee or Institutional Review Board approval because it does not involve human or animal subjects, nor does it include patient information or identifiable personal data. Consequently, participant consent was waived for the same reasons.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Institute of Allergy and Infectious Diseases of the National Institutes of Health, (grant number K23AI143882).
Guarantor
W.C.’
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.