
Abstract
Background
With the development of the information age, an increasing number of patients are seeking information about related diseases on the Internet. In the medical field, several studies have confirmed that ChatGPT has great potential for use in medical education, generating imaging reports, and even providing clinical diagnosis and treatment decisions, but its ability to answer questions related to gallstones has not yet been reported in the literature.
Objective
The aim of this study was to evaluate the consistency and accuracy of ChatGPT-generated answers to clinical questions in cholelithiasis, compared to answers provided by clinical expert.
Methods
This study designs an answer task based on the clinical practice guidelines for cholelithiasis. The answers are presented in the form of keywords. The questions are categorized into general questions and professional questions. To evaluate the performance of ChatGPT and clinical expert answers, the study employs a modified matching scoring system, a keyword proportion evaluation system, and the DISCERN tool.
Results
ChatGPT often provides more keywords in its responses, but its accuracy is significantly lower than that of doctors (P < .001). In the evaluation of 33 general questions, ChatGPT and doctors demonstrated similar performance in both the modified matching score system and keyword proportion evaluation (P = .856 and P = .829, respectively). However, in the evaluation of 32 professional questions, doctors consistently outperformed ChatGPT (P = .004 and P = .016). Additionally, while the DISCERN tool showed differences between general and professional questions (P = .001), both types of questions were evaluated at a high level overall.
Conclusions
Currently, ChatGPT performs similarly to clinical experts in answering general questions related to cholelithiasis. However, it cannot replace clinical experts in professional clinical decision-making. As ChatGPT's performance improves through deep learning, it is expected to become more useful and effective in the field of cholelithiasis. Nevertheless, in more specialized areas, careful attention and continuous evaluation will be necessary to ensure its accuracy, reliability, and safety in the medical field.
Introduction
Background
Cholelithiasis (Gallstone disease) is one of the most common digestive diseases worldwide, with an incidence of 6%–25% and an increasing trend.1,2 The main types of cholelithiasis are gallstones, common bile duct stones, and intrahepatic bile duct stones. The principal clinical manifestations include abdominal pain, nausea, vomiting, and jaundice, among which laparoscopic cholecystectomy is considered the gold standard for the treatment of gallstones. 3 For common bile duct stones and intrahepatic bile duct stones, individualized treatment is often tailored to the specific conditions of the patient.4–8
With the development of the information age, an increasing number of patients are seeking information about related diseases on the Internet. According to surveys, there are at least 6.75 million searches for health-related information on the web every day. 9 Recently, artificial intelligence (AI) has gained popularity in the medical field, and ChatGPT (Generative Pre-trained Transformer) is one of the most representative tools among them. 10 ChatGPT is a large language model (LLM) with 175 billion parameters that can answer questions and provide results and is widely used in several fields, 11 It may even replace internet searches. In the medical field, several studies have confirmed that ChatGPT has great potential for use in medical education, generating imaging reports, and even providing clinical diagnosis and treatment decisions.12,13T The results of Deng et al.'s study show that ChatGPT has excellent applicability in clinical applications of breast cancer. 14 Yeo et al. 15 have also demonstrated that ChatGPT can be an effective auxiliary tool for patients and doctors in cirrhosis and hepatocellular carcinoma. A growing body of research has proven that ChatGPT is capable of taking on medical tasks, but its ability to answer questions related to gallstones has not yet been reported in the literature. Moreover, we still question whether AI can replace clinical experts when it comes to answering more professional questions. This is essential to ensure patient safety.
The main objective of this study is to evaluate the potential of ChatGPT and clinical experts to differentiate between general and professional questions, using the recommendations from the clinical guidelines for cholelithiasis as standard answers. This evaluation aims to provide clear insights for patients with cholelithiasis and clinicians when utilizing ChatGPT, to understand the value and limitations of ChatGPT in clinical decision support. The secondary objective involves using the DISCERN tool to assess the quality of ChatGPT's responses to questions related to gallstones.
Methods
Ethics
This cross-sectional study was conducted at the Department of Hepato-Pancreato-biliary Surgery, People's Hospital of Leshan from April 27, 2024 to May 21, 2024. As no patients are involved in this study, approval from the ethics committee is not required.
Question generation and standard answer development
This study referenced the clinical practice guidelines for cholelithiasis issued by the European Association for the Study of the Liver (EASL) and the Japanese Society of Gastroenterology (JSGE). A series of questions mainly covering the etiology, diagnosis, treatment decision, and prognosis of cholelithiasis were formulated. Standard answers, developed according to these guidelines, are used to evaluate the correct response rate of ChatGPT and clinical experts to questions related to cholelithiasis. To ensure the feasibility and accuracy of the assessment, and to avoid subjective judgment by the evaluation researcher in identifying ChatGPT's answers, we only compare the keywords in the answers, not the whole sentence. In addition to words such as Yes, No, Unknown, and Similar, we define keywords as: (1) only involving core nouns related to the problem, retaining only one keyword with the same meaning, and if it is not related to the problem, it is not recorded, such as asking whether gallstones can be prevented but involving specific preventive measures; when asked about clinical manifestations and the answer is related to treatment, such keywords are not recorded; (2) medical professional terms, involving examinations, treatments, drugs, etc., such as cholesterol, Ultrasound, Laparoscopy, Antibiotics, Nonsteroidal Anti-Inflammatory Drug (NSAID), etc. Keywords congruence is defined as: (1) exact consistency; (2) different nouns but with the same meaning; (3) Keywords of affiliation (Figure 1).

Flowchart of questions development and evaluation.
Question stratification
Two independent researchers, a professional doctor of hepatobiliary and pancreatic surgery who has worked in a tertiary hospital for at least 10 years, are tasked with stratifying cholelithiasis-related questions and answers according to their level of professionalism. They divide the questions into general and professional categories. General questions are defined as those that do not require specialized knowledge and are easily understood by the general public. Professional questions are defined as those requiring specialized knowledge, difficult for the general public to understand, and comprehensible only to doctors of related specialties. In cases of disagreement, the final decision is made after discussion between the two researchers.
Get answers from ChatGPT
Several studies have demonstrated that ChatGPT-4.0 outperforms other large language models,16,17 prompting its use in this study. Initially, questions are posed directly to ChatGPT-4.0 in Chinese to record answers. To check for repetition of answers and to eliminate the interference of other factors, questions are also asked in English and responses are recorded. When posing questions, a background condition is set before each query: “Please answer as a chief doctor of hepatobiliary and pancreatic surgery who has been working for at least 40 years and is familiar with the latest cholelithiasis research trends domestically and internationally:” to ensure contextual accuracy. Additionally, to avoid biases related to timing and user interaction, other accounts are used to pose questions and record answers 10 days after the first session, with the language of the question being Chinese. Complete answers are recorded in Microsoft Word.
Get answers from doctors
To adapt to clinical scenarios, where the diagnosis and treatment process often involves a multi-person medical team, we recruited five doctors (hepatobiliary and pancreatic surgeons with 5–40 years of experience in tertiary hospitals) to form a team for answering questions, ensuring comparability with ChatGPT's responses. The process was conducted in a double-blind format: the team was unaware of the standard answers and the study's purpose beforehand. The preformulated questions were answered using keywords, and each keyword was recorded only after agreement by at least three doctors. The entire process was documented by a surgeon assistant using Microsoft Excel.
Evaluate the quality and accuracy of answers
The quality and accuracy of responses from ChatGPT and the experts were evaluated by two independent researchers. In cases of differing opinions, the final decision was made through discussion.
For quality assessment, the DISCERN tool, a reliable health information quality assessment tool, was employed. 18 It includes 16 questions across three sections evaluating the reliability of information, details about treatment, and overall assessment. Each question is rated on a scale of 1 to 5, where “No” scores 1 point, “Partially” scores 3 points, and “Yes” scores 5 points. The total score is the sum of all scores across the 16 questions, with ≤26 indicating very poor quality, 27–38 indicating poor quality, 39–50 indicating average quality, 51–61 indicating good quality, and ≥62 indicating excellent quality.
Accuracy was assessed using two methods to ensure thorough evaluation. The first method employed a modified matching scoring system 19 : 11 point indicates the keyword is completely incorrect; 2 points indicate a mix of correct and incorrect keywords; 3 points indicate the keyword is correct or similar but insufficient; 4 points indicate an exact match of the keyword. Additionally, the number of keywords in the standard answers and the number of correct keywords identified were tallied.
To address potential shortcomings in the modified matching scoring system, especially when a response includes only one correct keyword while the standard answer contains multiple, a keyword proportion evaluation system was implemented. This system rates the accuracy based on the percentage of correct keywords from the standard answer: (a) 0–25% is rated as very poor; (b) >25%–50% as poor; (c) >50%–75% as average; (d) >75%–100% as good.
Data analysis
Statistical analysis was conducted using SPSS software (version 26.0). For normally distributed measurement data, descriptive statistics were reported as mean ± SD, and comparisons between groups were made using the t-test. For data with a skewed distribution, descriptive statistics were presented as the median (±interquartile range), and group comparisons were conducted using the Mann–Whitney U test. Categorical data were reported as the number of cases (percentage), and group comparisons were performed using the chi-squared test. A P-value of less than .05 was considered statistically significant. Data visualization was performed using R packages such as “pheatmap” and “ggplotify,” as well as GraphPad Prism (version 9.5.1) and Origin Pro 2024.
Results
In this study, a total of 65 questions were developed according to the clinical practice guidelines for cholelithiasis published by EASL and JSGE, with each question containing keywords as standard answers (Table 1). After question stratification, 33 were classified as general questions (50.77%) and 32 as professional questions (49.23%). For ChatGPT, varying the background, times, languages, and accounts when asking questions resulted in answers that were differently expressed but involved almost identical keywords, indicating high repetitiveness in ChatGPT's responses. The study predominantly used Chinese to pose questions directly. Across the 65 questions, 177 keywords were identified, with 96 (54.24%) from general questions and 81 (45.76%) from professional questions. ChatGPT's responses included 242 keywords, of which 117 (48.35%) matched the standard answers. The doctors’ responses contained 190 keywords, with 140 (73.68%) matching the standard answers (Figure 2), demonstrating higher accuracy despite fewer total keywords, with a P-value of <.001, indicating a statistically significant difference.
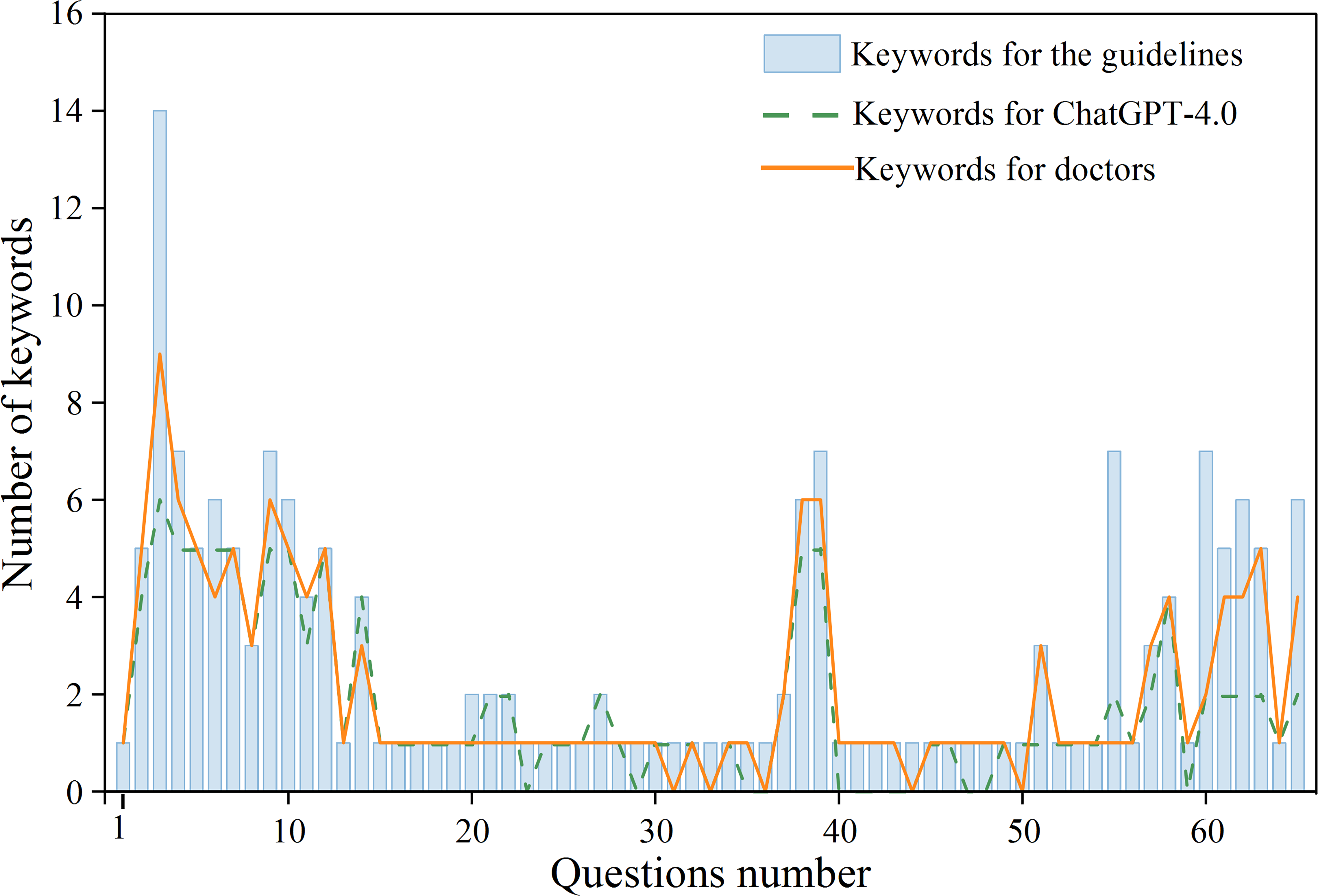
Number of keywords in the question.
Part of the questions and keywords display.

Comparison between ChatGPT and doctors in general questions
Among the 33 general questions, ChatGPT scored 4 (3,4) points in the modified matching score system, while the doctors scored 4 (4,4) points, showing similar performance with a P-value of .856, which was not statistically significant (Figure 3). In terms of keyword proportion evaluation, ChatGPT had 3 (9.1%) questions rated as Very Poor, 2 (6.1%) as Poor, 3 (9.1%) as Average, and 25 (75.7%) as Good. The doctors had 2 (6.1%) questions rated as Very Poor, 4 (12.1%) as Poor, 3 (9.1%) as Average, and 24 (72.7%) as Good (Figure 4). The evaluations were similar, with a P-value of .829, indicating no statistically significant difference (Table 2).

The scores of general and professional questions are in the modified matching score system. *: P > .05; ***: P < .05.
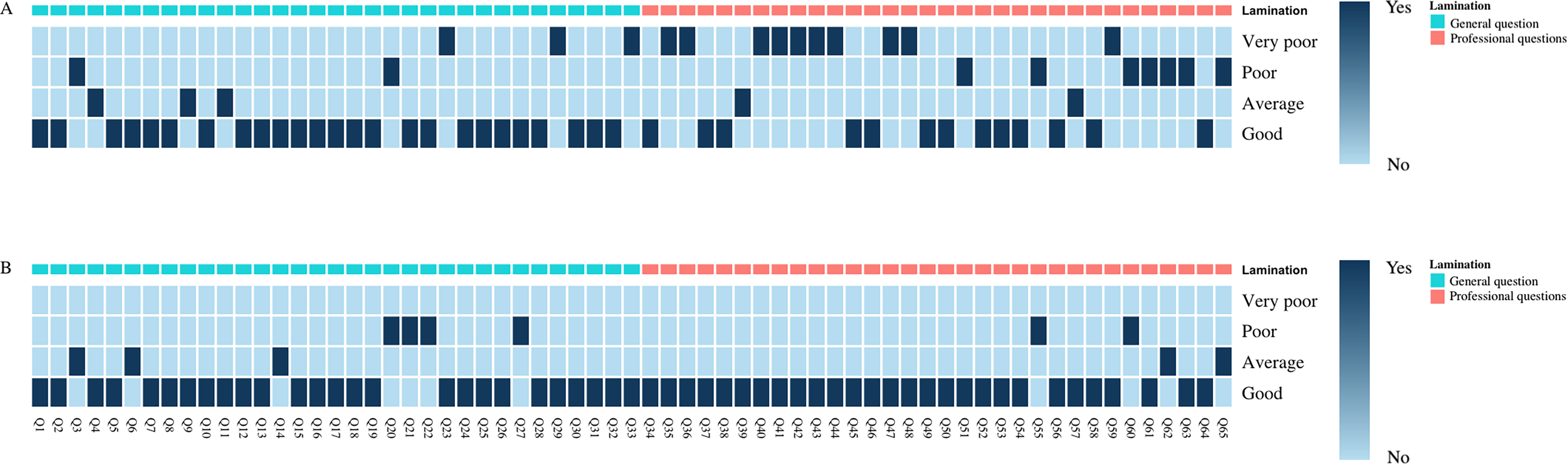
The scores of general and professional questions are in the keyword proportion scores.
Keywords the score in the modified matching score system and keyword proportion evaluation.

Comparison between ChatGPT and doctors on professional questions
In the evaluation of 32 professional questions, ChatGPT scored 3 (1, 4) in the modified matching score, while the doctors scored 4 (3, 4), demonstrating a higher performance by the doctors with a P-value of .004, indicating a statistically significant difference (Figure 3). Regarding keyword proportion scores, ChatGPT had 10 (31.1%) questions rated as Very Poor, 7 (21.9%) as Poor, 2 (6.3%) as Average, and 13 (40.7%) as Good. Conversely, doctors had 3 (9.3%) questions rated as Very Poor, 2 (6.3%) as Poor, 2 (6.3%) as Average, and 25 (78.1%) as Good (Figure 4). The expert evaluation was superior, with a P-value of .016, also showing a significant difference (Table 2).
ChatGPT complete answer quality analysis
According to the DISCERN score, for general questions, the median score was 59, with the highest at 63 and the lowest at 46 points. For professional questions, the median score was 51, with the highest at 63 and the lowest at 34 points. The quality evaluation revealed that 4 (12.1%) of the general questions were rated as Average, 19 (57.6%) as Good, and 10 (30.3%) as Excellent, with no answers classified as Very Poor or Poor. For professional questions, 2 (6.3%) were rated as Poor, 11 (34.3%) as Average, 16 (50%) as Good, and 3 (9.4%) as Excellent (Table 3). Most of ChatGPT's answers exhibited good quality, and the answers to general questions were of higher quality compared to professional ones, with statistical significance (P < .001, P = .026).
The complete answer of ChatGPT is scored in DISCERN.

Discussion
Although LLMs have been applied across various fields demonstrating significant potential,20–22 ChatGPT emerges as the most notable chatbot among them. It has shown its utility in providing information to patients and doctors before and after treatment, potentially playing a crucial role. However, the content available specifically in the field of cholelithiasis is quite limited, and few studies have evaluated LLMs’ efficacy in addressing specialized clinical issues. In this study, 65 questions were developed based on the clinical practice guidelines for cholelithiasis, covering pathogeny, clinical manifestations, risk factors, and treatment options, and classified to quantitatively assess the response performance of ChatGPT and clinical experts on general and professional questions. ChatGPT processes these questions using advanced algorithms from a vast database, which contrasts with the more limited, independent answering capabilities of clinical experts. In practice, diagnosis and treatment often involve collaborative efforts from a multi-person medical team. To mimic this real clinical environment, a team of five clinical experts was recruited to ensure comparability with ChatGPT. Most existing studies assessing ChatGPT's performance involve experts directly evaluating the chatbot's responses,23,24 which may introduce bias due to subjectivity or memory bias. To counter these limitations, this study utilized clinical practice guidelines to formulate standard answers and employed keyword comparison for evaluation, ensuring the feasibility, objectivity, and accuracy of the research.
ChatGPT's answers in this study involved 242 keywords, yet the accuracy rate was only 48.35%. This result highlights a characteristic of ChatGPT: while it can provide extensive information, it does not prioritize or emphasize the importance of specific answers, aligning with findings from Rachel and Walker.25,26 This trait allows users to access a broader range of information, yet it does not deliver definitive guidance. For instance, when questioned about the common clinical manifestations of gallstones, ChatGPT included both common and rare symptoms; similarly, when developing treatment plans, ChatGPT enumerated various options without recommending a singular, preferred treatment modality. Given these characteristics, ChatGPT seems better suited as an educational tool rather than a decision-making aid in clinical settings.
Several recent studies have shown that ChatGPT's responses align closely with those of experts,24,27,28 However, these studies may overlook potential biases such as subjective judgment, knowledge confusion, or memory lapses during the evaluation process by experts. Therefore, this study used the clinical practice guidelines for cholelithiasis from EASL and JSGE to develop questions and standard answers, focusing solely on keyword comparison to minimize the limitations observed in previous studies. Two scoring systems were employed to evaluate the consistency of ChatGPT's responses with those of experts. Overall, ChatGPT showed a positive accuracy, with a high median score on the modified matching score (4) and over 60% of responses rated as fair or good based on keyword proportion. However, the critical finding of this study concerns ChatGPT's performance on professional questions about cholelithiasis, where it demonstrated significant weaknesses. ChatGPT scored notably lower than experts in the modified matching score (3(1,4) vs 4(3,4), P = .004), with up to 53% of questions rated as very poor or poor in the keyword proportion evaluation. This suggests that ChatGPT has substantial limitations in addressing professional medical inquiries, often providing vague responses. For example, when asked whether “patients with Mirizzi syndrome should be treated surgically or endoscopically,” despite guidelines favoring endoscopy, ChatGPT would discuss both methods’ pros and cons without recommending a clear preference, which was counted as an error in this study. Additionally, some of ChatGPT's dichotomous answers were completely contrary to the guidelines. Another aspect to consider is ChatGPT's reliance on a vast corpus of internet text data, as acknowledged by its creator, OpenAI. 29 This dependency means that responses are based on historical internet information, 30 which may not reflect the most current clinical guidelines that are regularly updated, potentially leading to outdated answers.
Despite its limitations, ChatGPT's capacity to popularize science among the general public cannot be overlooked. In general questions that do not require specialized knowledge, ChatGPT's performance is comparable to that of experts, as evidenced by a P-value of .856 in the modified matching score test and a P-value of .829 in the keyword proportion rating. With a high median modified matching score (4) and 75.7% of questions rated as good, ChatGPT demonstrates its utility for patient education. Recent studies corroborate this, showing ChatGPT's effectiveness in educating patients about joint replacements, thyroid nodules,31,32 aligning with the findings of this study.
Furthermore, the quality of information provided by ChatGPT's answers is high. Although there is a disparity in quality between responses to general and professional questions, the DISCERN scores for both are above 50, with no questions rated as Very Poor and 87.95% and 59.4% of questions classified as Good or Excellent, respectively. ChatGPT offers a comprehensive context for each answer and outlines the advantages and disadvantages of different options, facilitating a more informed decision-making process for patients. However, a significant limitation noted in ChatGPT's responses relates to the “Evidence Source” category in the DISCERN evaluation, where ChatGPT received its lowest scores. For all answers, ChatGPT fails to indicate the source and quality of the evidence, which is a critical aspect. The general and extensive nature of the responses makes it challenging for patients or doctors to make reliable judgments based on the answers provided.
Limitation
This study has several limitations. First, the standard answers were formulated according to the clinical practice guidelines for cholelithiasis issued by EASL and JSGE. However, clinicians often respond based on their actual clinical experience or the clinical practice guidelines of their own countries, which may differ from these international guidelines. Second, this study aimed to evaluate the performance of ChatGPT in a medical environment comprehensively and in detail, thus employing the method of keyword comparison for research. While this approach allows for a nuanced analysis, it is more challenging to implement than binary classification and can introduce subjective bias. Efforts were made to minimize this bias through pre-developed keyword definitions, but more scientific methods may be needed for future keyword formulation.
Conclusions
The findings of this study suggest that ChatGPT performs similarly to clinical experts in answering general questions related to cholelithiasis. It demonstrates excellent accuracy and provides high-quality information for general questions, meeting the information needs of the general public effectively. Nevertheless, in more specialized areas, careful attention and continuous evaluation will be necessary to ensure its accuracy, reliability, and safety in the medical field.
Footnotes
Acknowledgments
The authors acknowledge gratitude to all the staff who participated in the study.
Author contributions/CRediT
Tianyang Mao: conceptualization, methodology, resources, writing—original draft, writing—review and editing. Xin Zhao: conceptualization, methodology, resources, writing—original draft, writing—review and editing, and contributed equally as the first author. Kangyi Jiang: investigation, formal analysis. Qingyun Xie: investigation, formal analysis. Manyu Yang: investigation. Ruoxuan Wang: investigation. Fengwei Gao: project administration, investigation, supervision, writing.
Ethical considerations
As no patients are involved in this study, approval from the ethics committee is not required.
Informed consent
No clinical data, human specimens, or laboratory animals were used in this study. All information was obtained from public resources, and none of the data involved personal privacy concerns. In addition, this study did not involve any interaction with users; therefore, no informed consent is required.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.