
Abstract
Background
Large language models have a huge positive impact on various disciplines, including healthcare. As family caregivers are an essential part of the healthcare system, they need support and can benefit from the technology. However, there is no consensus on reliable and valid measures to evaluate large language models.
Objective
This study aims to review the literature on the evaluation measures of large language models for caregivers.
Methods
We conducted a scoping review guided by Arksey and O’Malley methodology and the PRISMA-ScR checklist. A literature search on PubMed, EMBASE, CINAHL, and PsycINFO, from 2018 through July 2024, was carried out. An additional rapid review was conducted for the recent literature update from July 2024 through November 2025.
Results
All 10 final publications that met the inclusion criteria out of 1812 focused on ChatGPT, whereas three of them also addressed other large language models, such as Google Bard and Bing AI. The most commonly assessed core conceptual components of evaluation measures were accuracy, reliability, readability, and comprehensiveness. Overall, the included studies reported that large language models’ responses were somewhat accurate and reliable and mixed results in readability and comprehensiveness. The final 14 publications from a rapid review offered additional evidence on ChatGPT-centrism.
Conclusions
This review provides a comprehensive overview of the measures for evaluating large language models and highlights the need for their improvement using reliable and valid measures. The findings guide the direction of future research and practice to maximize the benefits through continuous quality improvement.
Keywords
Introduction
Artificial intelligence (AI) technology has been a breakthrough and has impacted our lives and work. Within this field, generative AI systems, capable of autonomously creating new content such as text, images, or music, have evolved dramatically since their introduction decades ago. 1
Large language models (LLMs) are a fundamental, notable example of how generative AI has evolved and specialized in text-based generative tasks. Language models have advanced over the past several decades since their inception. 2 Eliza is typically considered the first chatbot.2–4 Eliza is known as an early natural language processing program, created in 1966 by Massachusetts Institute of Technology researcher, Joseph Weizenbaum. However, Eliza is not a LLM. It is a rule-based chatbot run by a certain script and was able to parody the human–computer conversation by emulating a psychotherapist, which served as a stepping stone toward more advanced systems. Language models have evolved with the advance of AI over the past decades, and LLMs have taken the world by storm. 5 The four main aspects of LLMs, the most popular and widely used AI language models at present, are pretraining (trained with massive text data from various resources), adaptation (adapting to tasks), utilization (applying in the real world), and evaluation (assessing performance). 5
Large language models have shown the potential to interpret vast amounts of information, such as providing health-related information and supplementing diagnostic processes, but the use of LLMs warrants caution.6,7 Concerns include disseminating misinformation, producing AI hallucinations, and amplifying existing biases. Careful consideration of their potential effects and ethical implications has been emphasized.8,9 Nevertheless, LLMs have been very useful and have huge potential because they operate round-the-clock without breaks, provide real-time information promptly that is easy to understand, and are available to many users at free or low-cost rates. 10 As such, because of these numerous benefits, LLMs are increasingly being adopted across diverse fields, including finance, business, and cybersecurity, and their use is rapidly expanding within the healthcare field as well. 11
The representative examples of LLMs at present are Chat Generative Pre-trained Transformer (ChatGPT) by OpenAI, Gemini by Google, and LLM Meta AI (LLaMA) by Meta. As of today, the user numbers of ChatGPT, Gemini, and LLaMA are several million worldwide. OpenAI's first generative language model, GPT-1, was introduced in 2018, but it was not a public product and established the foundation for subsequent models, such as GPT-2 and GPT-3, 12 and then ChatGPT was launched based on GPT-3.5 to the world by OpenAI in November 2022. After that, LLaMA by Meta AI and Gemini by Google DeepMind were released in 2023. ChatGPT, LLaMA, and Gemini quickly went viral, and they have captured millions of users around the world. Since their debut, the practicalities, applications, impacts, and concerns of LLMs in healthcare have been explored and investigated.8,10 However, a consensus has not been reached on the most reliable and valid measure for evaluating the use of LLMs in healthcare yet. Among the various users of LLMs, understanding the implications of LLMs for family caregivers with reliable and validated evaluation measures is crucial because they are an essential part of the healthcare system. 13
More than one in five Americans are family caregivers, 14 and when estimated globally, hundreds of millions take on caregiving roles. Family caregivers, also known as informal caregivers, experience a high burden while caring for their loved ones. 15 Caregiving burden has been a long-standing issue because it leads to numerous negative impacts on both caregivers and care recipients.13,15 While a large number of interventions that support caregivers have been developed,16,17 research on the use of LLMs for caregivers has not been extensively explored despite the huge potential and benefits of using LLMs, such as providing educational opportunities, increasing available information, and reducing language barriers. 18 Additionally, concerns about the reliability of LLM outputs (e.g., the risk of AI “hallucinations” producing incorrect information) and the lack of established evaluation standards raise questions about how such tools should be assessed. There are recently published reviews regarding the use of LLMs,19–21 but two reviews were limited to care settings, either emergency medicine or oncology,19,20 and the other one did not specify care settings or users. 21 To date, no comprehensive review has focused on how LLMs are being used to support caregivers across multiple care contexts, what benefits or limitations have been observed, and what gaps exist in this nascent field. Therefore, our research question for this scoping review is: What measures have been used to evaluate LLM's use among family caregivers in healthcare research? Thus, this review aims to explore existing literature on the use of LLMs, such as ChatGPT, LLaMA, and Gemini, and reveal the gaps in the literature regarding the measures used to evaluate LLMs and the findings that emerge from their application for family caregivers.
Methods
According to the methodology by Arksey and O’Malley22,23 and the PRISMA-ScR checklist (Supplemental material 1), 24 this scoping review was undertaken to provide an overview of the existing literature regarding the use of LLMs for family caregivers and guide future directions for improving LLM evaluation measures. The search was conducted with PubMed, EMBASE, CINAHL, and PsycINFO databases on the 13th of July 2024. The protocol for this review was registered on the Open Science Framework Registry on 8 January 2025 (http://osf.io/a8b9y). To ensure transparency regarding the literature search prior to registration, we established predefined eligibility criteria, conducted independent screening, and documented all decisions before synthesis. Publications from peer-reviewed journals written in English were included. Given the recent emergence of LLMs, we limited the time of published years between 2018 and July 2024. We excluded certain types of publications, such as conference presentations, editorials, commentaries, reviews, and unpublished works, and publications that do not explicitly explain the type of technology, whether it is an LLM or not, and do not focus on its use for caregivers or patient–caregiver dyads. The search keywords included LLMs and caregivers. The details of search terms are presented in Table 1. Titles, abstracts, and full-text publications were reviewed independently by two reviewers, using a free web and mobile application, Rayyan (SH and HC). 25 Although Rayyan has AI-assisted screening features, our screening process followed the traditional two independent reviewer approach without using the AI features. The interrater reliability, measured using the percent agreement method, 26 is 96% for the title/abstract screening and 83% for the full-text screening. And then, all disagreements between two independent reviewers were resolved manually through discussion with a third person, who has expertise in health informatics and computer science (YC). A narrative synthesis was used to summarize findings regarding the evaluation measures used across studies and the extent of caregiver involvement. In addition, a table of evidence was established by including the language model type, evaluation dataset, study aim, target users (caregiver type), key evaluation measure and score, and relevant findings in Table 2.
An overview of used search terms (n = 1812).

NIH: National Institutes of Health; NLM: National Library of Medicine.
Characteristics of included studies in this scoping review (n = 10).

LLM: large language model; HCC: hepatocellular carcinoma.
Given the fast-evolving nature of LLM advancement, after we completed the review with published literature from 2018 through July 2024, we posited that additional rapid review was necessary to capture newly published literature from 1 July 2024, through 6 November 2025. This rapid review was intended to reflect the most current evidence, rather than to be a comprehensive review involving a rigorous review process, such as having two independent reviewers.
Results
Study characteristics
From the initial search, we identified 1812 publications across the four databases, PubMed, EMBASE, CINAHL, and PsycINFO. After removing duplicates, 1290 titles and abstracts were screened. After that, 46 full-text publications were reviewed. 36 publications were removed because of wrong technology (e.g., not using LLMs), wrong publication type (e.g., commentary), and wrong population (e.g., no family caregivers). Ultimately, 10 publications that met the inclusion criteria were assessed and analyzed (Figure 1). Characteristics of all included studies, such as specific models, evaluation datasets, study aims, target users, evaluation measures and scores, and main relevant findings, are summarized in Table 2. The details of key evaluation measures are presented in Table 3. While all 10 studies used ChatGPT, 3 of them also addressed other LLMs, such as Google Bard and Bing AI. In terms of the target health conditions of patients (care recipients), two studies addressed caregivers of individuals with dementia,27,35 two addressed those with vision disorders,29,33 two addressed those with liver diseases,10,34 one addressed those with stroke, 32 one addressed those with autism, 31 one addressed the importance of vaccines for caregivers of children aged 0–24 months, 30 and one with epilepsy. 28 Most studies assessed questions or posts that are commonly made by caregivers,10,27–29,31–33,35 whereas one study prompted LLM to create educational materials for caregivers, 34 and another study prompted LLM to edit the content for caregivers. 30

PRISMA flow diagram for the scoping review process (publications from 2018 to 2024).
Evaluation measures of included studies in this scoping review (n = 10).

PEMAT-P: Patient Education Materials Assessment Tool for Printable Materials; SMOG: Simple Measure of Gobbledygook.
Measures for evaluating LLMs
All studies included for this review employed different measures for evaluating LLMs, leading to some overlap across the literature. Based on the core conceptual focus of each measure's component, four key components that were most commonly addressed emerged from the literature review: accuracy, reliability, readability, and comprehensiveness. In more detail, we identified all evaluation measures of LLMs from all included publications, as presented in Table 3. We then counted the number of each evaluation measure that appeared across all publications. Based on the numbers, we determined the most commonly used measures.
Accuracy
Based on a review of the literature, including nine publications that addressed accuracy. Accuracy refers to whether the information is precise, factually valid, and free of errors.10,27–32,34,35 Pradhan et al. 34 evaluated accuracy with eight transplant hepatologists based on a 5-point scoring system, which was adapted from Dy et al. 36 and Storino et al. 37 A score of 1 indicating <25% is accurate, 2 indicating 26%–50% is accurate, 3 indicating 51%–75% is accurate, 4 indicating 76%–99% is accurate, 5 indicating 100% is accurate. Aguirre et al. 27 assessed whether the responses did not contain inaccurate or false information using a 5-rating scale by adapting the levels of cognitive complexity regarding clinical decision-making from Hurtz et al. 38 Kim et al. 28 assessed accuracy using 4-rating scales (sufficient educational value, correct but inadequate, mixed with correct/incorrect/outdated information, incorrect). Yeo et al. 10 used a 4-rating scale (comprehensive, correct but inadequate, mixed with correct and incorrect/outdated data, completely incorrect). McFayden et al. 31 also used a 4-rating scale (completely correct/clear/concise, almost correct/clear/concise, partially correct/clear/concise, completely incorrect/unclear/unconcise) on three domains: correctness, clarity, and conciseness. Lim et al. 29 assessed accuracy using a 3-point scale (poor, borderline, good). Neo et al. 32 also used a 3-point Likert-like rubric for accuracy (unsatisfactory, borderline, satisfactory). Loughran et al. 30 had a panel of subject matter experts and linguistic experts to ensure the accuracy of ChatGPT responses, and Saeidnia et al. 35 used both quantitative (questionnaire) and qualitative (interview) approaches to evaluate the level of correctness of ChatGPT responses, but these two studies did not provide the details about a scale or rubric.
Reliability
Based on three publications in this review, reliability is defined as consistency between multiple evaluators or across similar conditions (i.e., reproducibility, consistency) or whether the information is based on reliable sources.10,28,33 Yeo et al. 10 evaluated reproducibility by entering each question into ChatGPT twice and having two independent hepatologist reviewers and another senior hepatologist as a third reviewer to assess the similarities between the two responses. Two responses were graded separately and classified as significantly different if categorized into opposing groups (grades 1–2 vs. 3–4). Nikdel et al. 33 also assessed the rate of agreement of acceptable, incomplete, or unacceptable between two ophthalmologists. Kim et al. 28 assessed the internal consistency (reliability) of ChatGPT-4 by comparing it with ChatGPT-3.5 and the official guide, “Epilepsy Patient and Caregiver Guide,” published annually by the Korean Epilepsy Society.
Readability
Based on three publications, we define readability as how easy the information is to read or comprehend.30,32,34 Pradhan et al. 34 used three validated scoring systems, including the Flesch Reading Ease Score (FRS), 39 the Flesch–Kincaid Grade Level Score (FKGL), 39 and the Simple Measure of Gobbledygook (SMOG). 40 Neo et al. 32 used a 3-point Likert-like rubric. Loughran et al. 30 assessed readability but did not provide a detailed explanation of the measure(s).
Comprehensiveness
Based on three publications included in our literature review, comprehensiveness is defined as whether the information covers all necessary aspects.27,29,35 Lim et al. 29 assessed comprehensiveness using a 5-point scale, and Aguirre et al. 27 assessed comprehensiveness using a 4-rating scale whether the ChatGPT's response was thorough and complete. Saeidnia et al. 35 evaluated comprehensibility and completeness of ChatGPT-4 responses, but there was no detailed information about a scale or rubric.
Findings derived from the application of LLM evaluation measures
Accuracy
Most publications proposed that LLMs provided accurate information, ranging 70%–99% of the time.10,27–32,34,35 To elaborate on the accuracy rates across publications, Aguirre et al. 27 reported that most responses (93%) of ChatGPT-3.5 contained factual information. Pradhan et al. 34 demonstrated that most education materials generated by LLMs, including ChatGPT-4, DocsGPT, Google Bard, and Bing Chat, showed accurate medical information more than 76% of the time. Kim et al. 28 reported that 40 out of 57 responses (70%) of ChatGPT-4 were classified as sufficient educational value with no entirely incorrect response, and better results than those from ChatGPT-3.5 (i.e., 10 responses were better, 45 were similar, 2 were worse, and 0 was much better in ChatGPT-4 compared to ChatGPT-3.5).
Yeo et al. 10 and McFayden et al., 31 using ChatGPT-3.5 and ChatGPT-4, respectively, demonstrated that ChatGPT achieved high accuracy in responding to questions related to cirrhosis/hepatocellular carcinoma and autism. However, both studies mentioned areas where ChatGPT did not respond correctly or provided outdated information. To elaborate further, ChatGPT could not provide correct information regarding the cutoff for certain situations, such as liver stiffness measurements indicating the need for an upper endoscopy, the maximum time window that is recommended for performing an upper endoscopy, and the minimum antibiotic course duration for empiric gram-negative coverage in Yeo et al. 10 and outdated information was used in McFayden et al. 31
In terms of specific contents/domains, Yeo et al. 10 proved that ChatGPT-3.5's performance was better in basic knowledge, lifestyle, and treatment than diagnosis and preventative medicine. In a Lim et al. study, 29 ChatGPT-4 demonstrated better accuracy compared to ChatGPT-3.5 and Google Bard. This study showed that all three LLMs performed well in the domains of “clinical presentation” and “prognosis.” In the “pathogenesis,” “risk factors,” and “diagnosis” domains, ChatGPT-3.5 and ChatGPT-4 performed well, but Google Bard did not. In the “treatment and prevention” domain, all LLMs performed poorly. In addition, all three LLMs showed substantial self-correction capabilities through further prompts. In contrast, Neo et al. 32 showed that both ChatGPT and Google Bard provided readable responses with some general accuracy and were tied in accuracy.
Loughran et al. 30 had a panel of subject matter experts and linguistic experts to ensure the accuracy of ChatGPT responses and indicated that using ChatGPT to edit human-written content as an editorial tool appears to be safer for avoiding inaccuracies created by ChatGPT because no issues with accuracy were identified in the edits made by ChatGPT.
Saeidnia et al. 35 reported that both informal and formal caregivers expressed the need for and importance of further evolution with an interdisciplinary approach with computer scientists, healthcare providers, and caregivers to improve the accuracy and reliability of ChatGPT responses.
Reliability
Yeo et al. 10 demonstrated a high reproducibility, with 90% of ChatGPT-3.5 responses remaining consistent across repeated questions. In addition, Nikdel et al. 33 study also presented a high agreement between two ophthalmologists and a high reproducibility of responses on different days. In a Kim et al. study, 28 no explicitly stated assessment measure specifically for reliability was provided, distinct from the accuracy assessment.
Readability
Pradhan et al. 34 demonstrated that most materials generated by ChatGPT-4, DocsGPT, Google Bard, and Bing Chat showed similar readability but were above the desired sixth-grade reading level. However, Neo et al. 32 found the opposite, suggesting most responses from both ChatGPT-3.5 and Google Bard were relatively easy to understand, with ChatGPT slightly better in satisfactory grades. The most significant difference between these two studies is that they used different measures. Neo et al. 32 used a 3-point Likert-like rubric, while Pradhan et al. 34 used the FRS, FKGL, and SMOG. On the other hand, Loughran et al. 30 highly valued ChatGPT as an editorial tool because it excelled at editing content to be easier to read or understand.
Comprehensiveness
In the Aguirre et al. study, 27 ChatGPT-3.5 received the lowest ratings in comprehensiveness that were assessed by three clinicians with more than 15 years of experience with patients with dementia and their caregivers. However, Lim et al. 29 concluded the opposite, indicating all three LLM-Chatbots, ChatGPT-4, ChatGPT-3.5, and Google Bard, demonstrated high mean comprehensiveness scores that three ophthalmologists evaluated regarding the responses to common myopia-related queries. Furthermore, informal caregivers appeared to have more positive opinions on ChatGPT's responses compared to formal caregivers. 35
A figure was constructed to visually summarize the evaluation measures of LLMs that were commonly addressed in this review (Figure 2). Since the scales of measures across publications varied, we normalized all scales to a 0–100 scale for display. We selected those that were most commonly used and aligned with the focus of our review for visual representation rather than detailed analysis. Supplemental material 2 provides the underlying data and normalization process, including three sheets: Sheet 1, “Raw Data,” presents the reported numbers of all publications; Sheet 2, “Normalization Process,” presents 0–100 scale normalization process of all publications; and Sheet 3, “Final Data,” presents the normalized values.
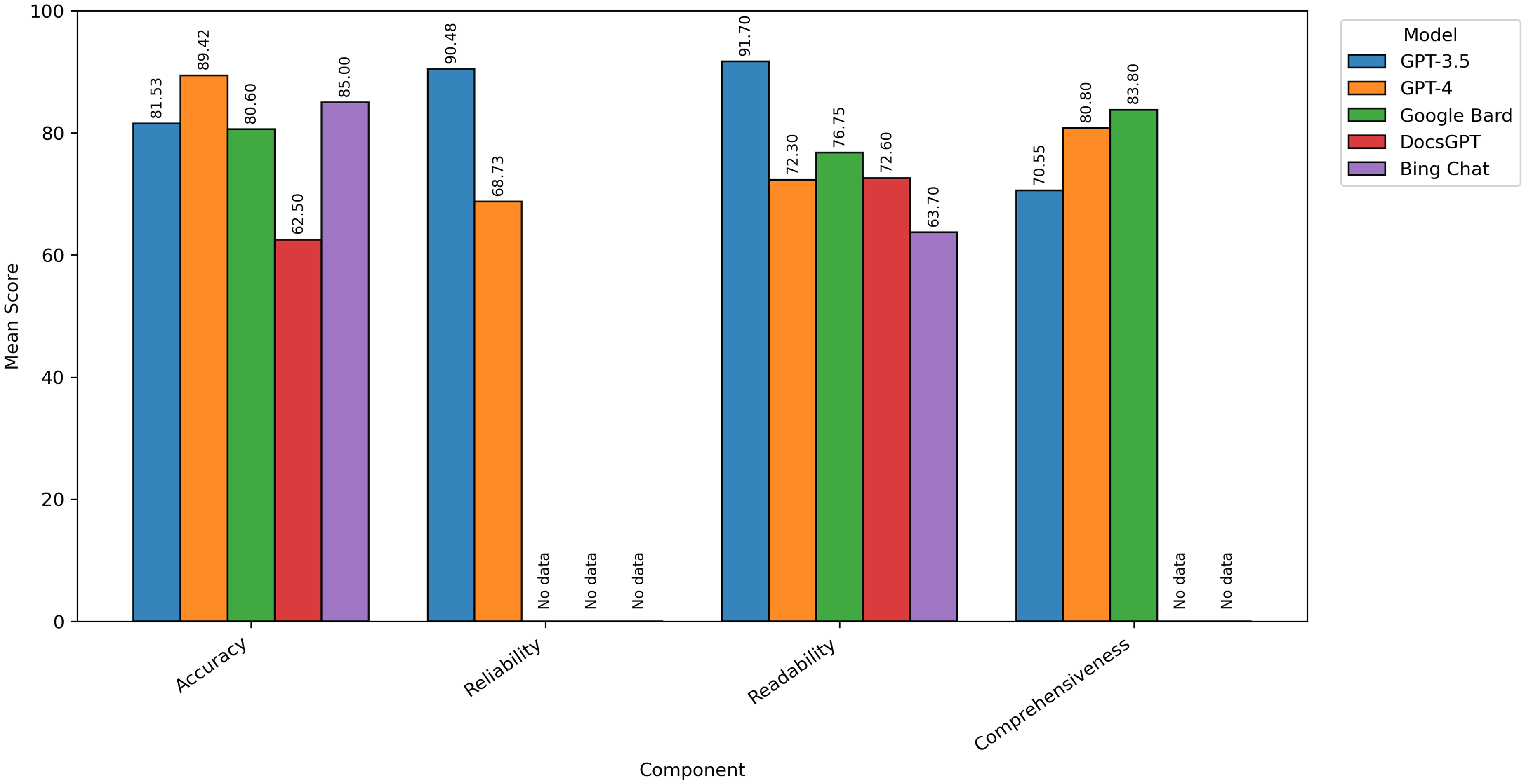
Mean score of each measure component across large language models.
Recent literature update from 2024 through 2025
Since the field of LLMs is rapidly evolving, as of 6 November 2025, a rapid review was conducted. Of the 1557 publications extracted from the same four databases, PubMed, EMBASE, CINAHL, and PsycINFO, duplicates were removed. From 1157 publications, one author (HC) screened publications based on titles/abstracts, and 43 publications were selected. Another author (SH) then screened full-text publications, resulting in 14 final publications (Figure 3). This rapid review was not intended to be exhaustive to identify the most commonly used evaluation measures, but rather to examine whether the recent literature continues to reflect ChatGPT-centrism or exhibits more diverse models.
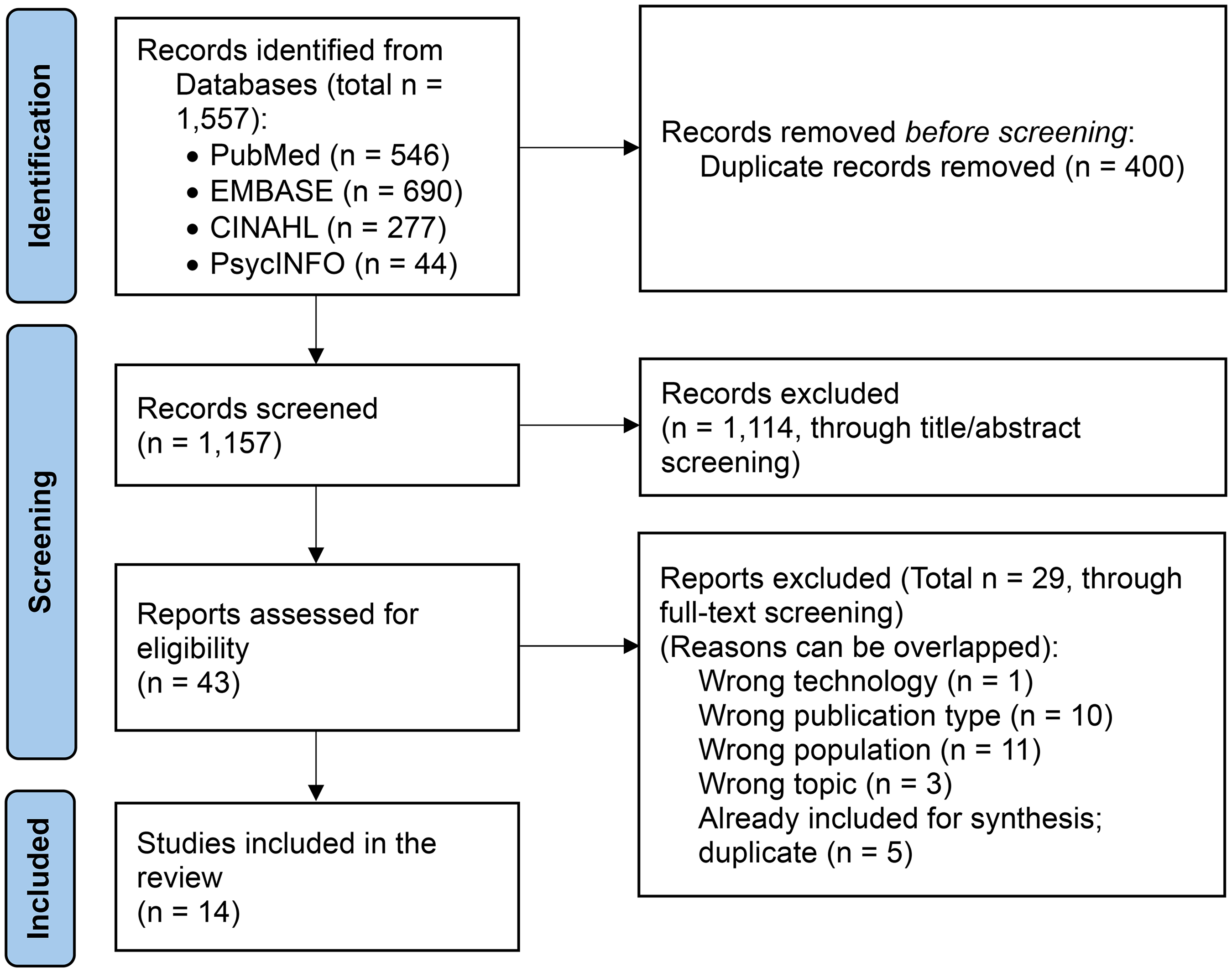
PRISMA flow diagram for the scoping review process (publications from 2024 to 2025).
Overall, the updated literature continued to demonstrate a strong emphasis on ChatGPT-based evaluations (Table 4).41–54 While a small number of studies referenced alternative AI-driven tools or emerging systems, these varied substantially in design and purpose and were not always directly comparable to general-purpose conversational LLMs. Examples included AI-assisted search (e.g., Google SGE, Microsoft Bing Chat), 50 or medical literature synthesis platforms (e.g., OpenEvidence),44,47 and caregiving domain-specific small language model prototype (e.g., Parmanto et al.), 49 which differ conceptually from publicly deployed LLMs, such as ChatGPT or DeepSeek. This pattern demonstrates that ChatGPT remains the dominant reference model in applied research, likely reflecting its accessibility and familiarity among researchers.
Recent literature update results (n = 14).
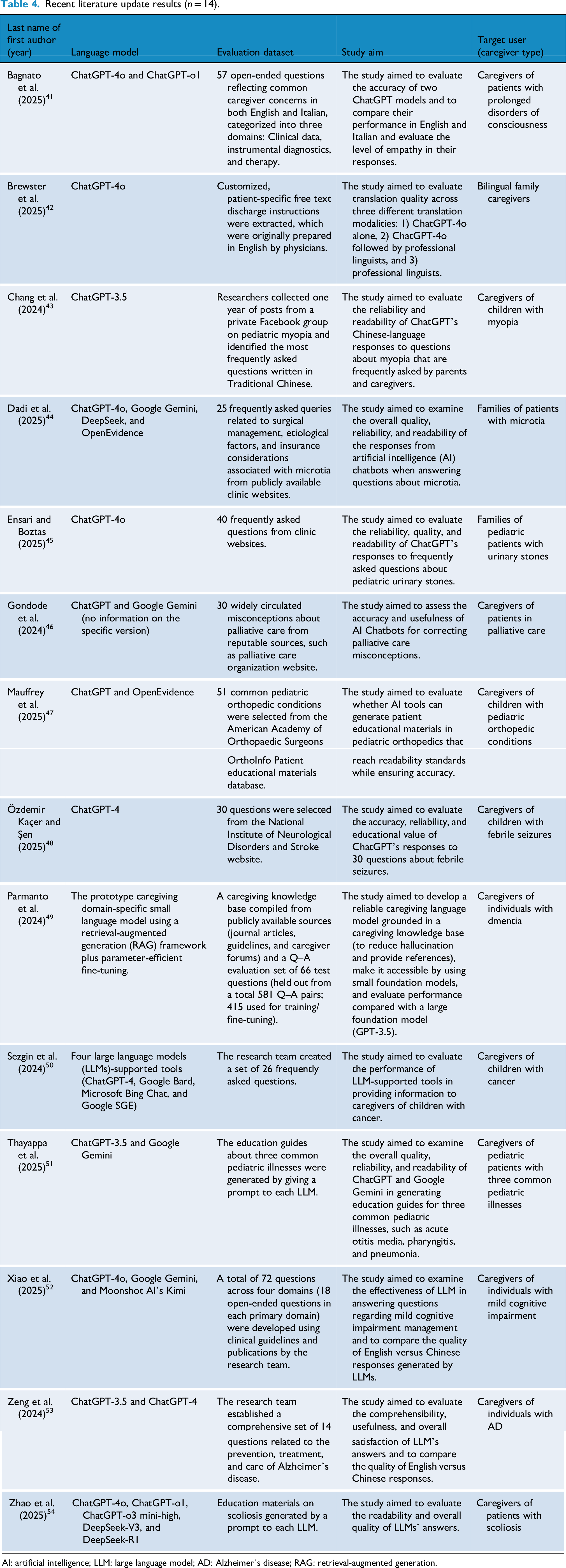
AI: artificial intelligence; LLM: large language model; AD: Alzheimer's disease; RAG: retrieval-augmented generation.
Discussion
Generative AI, especially LLMs, has created a great deal of evolution in healthcare and is still advancing. 55 Our review also contributes to the ongoing efforts to guide the meaningful use and development of LLMs. This review delivers insights into a comprehensive overview of LLM evaluation measures when using LLMs for caregivers. This review reports the four main key components for the evaluation measures that were most commonly addressed in included studies for this review: accuracy, reliability, readability, and comprehensiveness.
One thing to consider is that the components of the evaluation measures can vary depending on the users. One study thoroughly assessed the relevance, evidence-based quality, and actionability of LLMs when used by healthcare professionals, rather than family caregivers. 56 In this case, they assessed the quality of LLMs if the clinical practice is justified or should be changed and if the contents are based on medical literature, which are prioritized for healthcare professionals rather than family caregivers. 56 Therefore, to establish a comprehensive evaluation tool of LLMs, the characteristics of users should be considered.
The findings of this review inform future directions for advancing LLMs through conceptually essential measures for continuous quality improvement and for their use by family caregivers, such as answering caregivers’ questions, developing educational materials tailored to their needs, or editing content to enhance readability. One of the publications included in this review emphasized the benefits of LLMs in providing emotional support to patients and caregivers, 10 which has been addressed in the literature. 57 Besides emotional support, providing detailed information, including medical information, financial and legal information, and emotional support, is of utmost importance for family caregivers.58,59 Given that healthcare professionals experience burden and difficulty in empathic communication and providing quality care due to lack of time and resource-limited settings,60–62 utilizing LLMs that support both patients and their family caregivers to independently find information and receive emotional support would ultimately also benefit healthcare professionals.
Because ChatGPT has been the most successful in becoming widely adopted, it is also the most used in research. In terms of accuracy and reliability, the literature included in this review indicates that LLMs provided somewhat accurate information, but the performance varies depending on specific domains. Another recently published study also corroborates these findings, showing that ChatGPT-3.5 performs relatively accurately on basic medical knowledge but is relatively poor in specific areas, such as pharmacology, social welfare, law and regulations, endocrinology/metabolism, and dermatology. 63 Therefore, future research evaluating the accuracy of LLM responses should raise awareness of the caution of using LLMs for certain medical decision-making, such as diagnosis, treatment plan, medication management, and legal/financial decisions, and highlight possible risks and harm that can be exacerbated by the use of LLMs.
Nevertheless, our review revealed that LLMs’ responses often require higher educational and literacy levels, especially when using the FRS, FKGL, and SMOG tools for readability evaluation. There is no research confirming whether using these measures is an appropriate way to evaluate the readability of LLMs. In the literature, patients’ readability was evaluated by recruiting and interviewing patients by addressing the importance of directly assessing patients’ ability, rather than retrospectively using a simple readability assessment tool, such as the FRS. 64 This highlights the need for further research to determine the ideal and most appropriate measures for assessing family caregivers’ readability when using LLMs. That is, researchers should carefully consider and choose the most appropriate evaluation methods and tools. In addition, as reliability and validity are very important when obtaining medical information, an ongoing commitment to improving key measures for evaluating LLMs is required. Future studies also need to consider whether these methods and tools should be modified and subjected to rigorous reliability and validity assessments, depending on the specific LLM. Furthermore, other studies highlight the need for clear criteria for the required number of prompts (i.e., iterations with effective prompts) and the ideal word count per prompt (i.e., ideal length) to yield better, more accurate output from LLMs.65,66 That is, family caregivers may need education on how to use LLMs more effectively (e.g., clearer prompts, the need for follow-up prompts, shorter question lengths). Ultimately, it is crucial to develop evaluation measures that focus on the most frequently mentioned components revealed from this review (e.g., accuracy, reliability, readability, comprehensiveness), while incorporating considerations for the use of family caregivers.
Importance of digital literacy among caregivers
Another important consideration is that effective support for family caregivers is often hindered by challenges with health literacy. Recent studies highlight that low e-health literacy was observed among patients and their family caregivers,67,68 potentially exacerbated by geographical disparities impacting rural populations. 67 This indicates that equitable digital interventions for patients and their family caregivers should evaluate their literacy level as a means to address geographical disparities. Although the National Institutes of Health and the American Medical Association both recommend that patient education materials be written not above the eighth-grade reading level, the majority of patient education materials published in high-impact medical journals are written significantly above the recommended reading grade. 69 Our review findings resonate strongly with this issue in the context of AI. While LLMs hold promise, several studies included in this review demonstrated the limitations of LLMs, including outdated information and inappropriate educational or literacy levels. Nevertheless, LLMs have the potential to support family caregivers as the main source of valuable information because they can provide information at a specific literacy level as per request through multiturn conversations (i.e., need to ask ChatGPT to rephrase at another literacy level). As demonstrated in Siddiqi et al., 68 where caregivers expressed that they desire a chatbot that can promptly provide reliable, complete, and coherent information in multiple languages, the findings of this review may support the development of LLMs by considering readability and literacy to support caregivers. One of the exemplary cases of practically utilizing LLMs in the real world is the use of LLM-based chatbots, which can be utilized by healthcare professionals, patients, and their families. 70
Research and practice implications
Our findings indicate that the performances of LLMs in the most commonly addressed components of measures, including accuracy, reliability, readability, and comprehensiveness, still require human oversight and conservative use among family caregivers. While LLMs can provide general health information, clarify basic medical concepts, and offer emotional support, they remain limited in their ability to guide medical diagnosis, interpret test results, or recommend treatments. Healthcare providers need to emphasize that patients and their families contact them when they encounter immediate health problems to avoid delays in care. These limitations, however, do not imply that caregivers should be discouraged from using LLMs. Instead, LLMs should be positioned as supplementary, low-risk educational tools that support general education, lifestyle recommendations, caregiving resource navigation, and emotional support. They should not be used particularly for high-risk areas involving clinical decision-making, diagnosis, test result interpretation, treatment recommendations, urgent care management, and medication management. Such clinical and medical decisions should be made with healthcare providers.
To promote safer and more effective use, healthcare providers and researchers can incorporate LLM guidance into caregiver education. This includes educating that LLM-generated information should not be treated as definitive clinical advice, and that LLMs are most appropriate for exploring resources or receiving general explanations and emotional reassurance. Providers can also help family caregivers adopt a simple verification approach to safely use information generated by LLMs. This process includes: (1) reviewing the initial response for clarity, source references, and any red-flag warnings; (2) comparing the output with a second, independent LLM to reduce single-model omissions and to evaluate consistency in key recommendations across multiple models; and (3) confirming essential information through authoritative clinical resources or direct communication with healthcare professionals (e.g., messaging providers through patient portal). Nonetheless, when the LLM models provide conflicting answers, if anything is unclear, or in urgent or high-risk situations regardless of model agreement, caregivers should immediately contact healthcare providers. Although this process cannot eliminate all errors generated by LLMs, it reduces the risk of single-model omissions or hallucinations and makes system limitations more visible to the user.
A risk-based perspective is also essential. For low-risk informational tasks, such as understanding a diagnosis or learning lifestyle recommendations, LLMs can offer helpful, readable guidance. For moderate-risk situations, such as seeking advice about minor symptoms or routine daily care, caregivers should follow stricter safeguards, including clear warnings, consistent messages across repeated prompts, and explicit instructions on when to seek care. For high-risk scenarios, such as medication adjustments, clinical thresholds, or new severe symptoms, caregivers should not rely on LLMs. In these cases, direct contact with healthcare providers is required, and systems should be designed to gently redirect users to professional help.
Large language models cannot replace healthcare professionals. As the application of LLMs is still at an early stage, we recommend that researchers report the findings of the use of LLMs transparently and prioritize caregiver safety, not just efficiency and accuracy, which will guide the process of improving LLMs for family caregiver use. Relying on a single “accuracy” measure is also insufficient for evaluating LLM performance in caregiving contexts. A global accuracy score averages responses across questions with very different levels of clinical risk and can mask serious errors in high-stakes scenarios. An LLM may perform well on general, low-complexity questions while producing unsafe or misleading recommendations on clinically sensitive topics. For caregivers, even a small number of errors in these areas can meaningfully increase risk. Evaluations must therefore move beyond aggregated accuracy metrics and incorporate scenario-specific assessments that examine safety, actionability, and variability across risk levels.
Limitations
This review has limitations. First, since our rapid review was intended to confirm ChatGPT-centrism, the main focus of identifying the most commonly used evaluation measures may not reflect literature published after July 2024. Due to an extremely rapid change in language models driven by AI and automation, evidence is changing rapidly, and timeliness is key. For example, ChatGPT versions have changed. Google Bard changed to Gemini, and Bing AI changed to Copilot as of March 2025. This makes comparison between LLMs challenging in this review. With all the competition in LLMs, the applications of LLMs for caregivers and accompanying research projects need a rapid turnaround of evidence to stay abreast of evolving advancements. Second, this review is limited to include English-written publications only. We might miss some other language models introduced in other languages from other tech-leading countries. Third, although we sought to capture all LLMs, as presented in Table 2 and Table 4, ChatGPT was predominantly presented across publications. We speculate that many healthcare researchers are more familiar with or accessible to ChatGPT compared to other LLMs. Even our additional rapid review of recent literature offered further evidence of ChatGPT-centrism. We believe that the findings of this review can make a valuable contribution by opening new directions. Future studies would benefit from systematic cross-model evaluations using comparable benchmarks and clearly defined model categories by bringing more diverse LLMs into healthcare research and applications, as LLMs are still relatively new and evolving. In addition, one of the included studies in our review used the term accuracy interchangeably with comprehensiveness. In a Yeo et al. 10 study, when accuracy was evaluated using a 4-rating scale, the response options were “comprehensive,” “correct but inadequate,” “mixed with correct and incorrect/outdated data,” and “completely incorrect.” This study treated “comprehensiveness” as implying some level of accuracy without enough detailed information, although comprehensiveness is distinct from accuracy in terms of dictionary definitions. Any areas of ambiguity, such as the meaning of each measure, were discussed by three authors (SH, HC, and YC) to ensure the quality and rigor of this review. We determined that Yeo et al. evaluated accuracy, rather than comprehensiveness, for two reasons: (1) their explicitly stated aim was to examine the accuracy, and (2) three out of four response options are accuracy items (“correct but inadequate,” “mixed with correct and incorrect/outdated data,” “completely incorrect”). This suggests that future survey development should ensure construct consistency and highlights the importance of a clear definition of each measure.
Conclusions
Large language models represent a significant breakthrough in health informatics and can swiftly provide human-like, practical, and informative responses to inquiries from family caregivers. The findings of this review provide some insights into how to better evaluate and develop LLMs for caregivers. For continuous quality improvement on LLMs through future research, we also make suggestions to serve as a foundation for developing LLM evaluation measures that incorporate the following components: accuracy, reliability, readability, and comprehensiveness.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076261425343 - Supplemental material for Exploring evaluation measures of large language models for family caregiver use: A scoping review
Supplemental material, sj-docx-1-dhj-10.1177_20552076261425343 for Exploring evaluation measures of large language models for family caregiver use: A scoping review by Soojeong Han, Hannah Cho, Yong K Choi and Gregory L Alexander in DIGITAL HEALTH
Supplemental Material
sj-xlsx-2-dhj-10.1177_20552076261425343 - Supplemental material for Exploring evaluation measures of large language models for family caregiver use: A scoping review
Supplemental material, sj-xlsx-2-dhj-10.1177_20552076261425343 for Exploring evaluation measures of large language models for family caregiver use: A scoping review by Soojeong Han, Hannah Cho, Yong K Choi and Gregory L Alexander in DIGITAL HEALTH
Footnotes
Acknowledgments
The authors would like to express gratitude for the support of librarians at Columbia University Health Sciences Library.
Ethical approval
Not applicable, because this study is a review of the literature and did not require research ethics approval or patient consent.
Contributorship
SH initiated the review study, established a search strategy, designed the study, and wrote the first draft of the manuscript. SH, HC, and YC contributed to data analysis. SH and GLA provided scientific oversight and supervision. All authors contributed to conceptualization, manuscript writing, and editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Soojeong Han is a postdoctoral research fellow, supported by the National Institutes of Health, National Institute of Nursing Research – Reducing Health Disparities through Informatics training grant (T32 NR007969).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantor
SH.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.