
Abstract
Background
ChatGPT and other AI-driven language models are increasingly used in healthcare for disseminating medical information. However, their performance in providing accurate and empathetic responses to patients with specific diseases remains uncertain.
Objective
This study aimed to evaluate the effectiveness and reliability of ChatGPT in providing esophageal cancer-related information using the SERVQUAL framework, focusing on five dimensions: Tangibles, Reliability, Responsiveness, Assurance, and Empathy.
Methods
Ten representative questions on esophageal cancer were selected through search engine analysis and specialist consultation. ChatGPT generated responses, which were evaluated by 48 gastroenterologists using a 5-point Likert scale aligned with the SERVQUAL model. Statistical analysis was conducted using R 4.4.0 to compare responses between specialist and non-specialist physicians.
Results
ChatGPT performed well in providing structured, logical, and generally informative responses, particularly in the prevention domain. However, limitations were identified in its responsiveness and empathy. Significant differences were observed between specialists and non-specialists in evaluating certain answers, especially regarding reliability and cutting-edge knowledge. ChatGPT often failed to reflect the latest clinical guidelines or regional risk-specific recommendations.
Conclusion
While ChatGPT shows potential in patient education for esophageal cancer, its current outputs lack clinical specificity and up-to-date medical insight. AI tools should be continuously improved with dynamic data integration and specialist supervision to ensure reliability and relevance in real-world healthcare scenarios.
Keywords
Introduction
The integration of artificial intelligence (AI) into healthcare has presented exciting opportunities for improving patient care and medical communication. One such advancement is the Chat Generative Pre-trained Transformer (ChatGPT), an AI-based conversational chatbot system developed by Open AI.1,2 With its ability to generate responses based on large language models, it has greatly facilitated the process of public access to medical knowledge.3–6 Consequently, numerous studies have been initiated to assess the availability and accuracy of medical information provided by it to the public.7–11 Despite the subsequent introduction of numerous other large language models, including Google Gemini, Bard, Deepseek and so on, ChatGPT as a pioneering invention, remains the most critical.12–14
However, the reliability of AI-generated content is particularly critical for diseases with high mortality and complex management pathways, such as esophageal cancer. Ranked as the sixth leading cause of global cancer deaths, this malignancy carries a 5-year survival rate of only 15–25%,15–18 and exhibits distinct risk factor profiles between histological subtypes that influence global incidence patterns.19–21 The urgent need for accurate, accessible information on prevention, early detection, and treatment underscores the importance of evaluating ChatGPT's performance in this high-stakes context. SERVQUAL model is used to assess the quality of healthcare services,22–25 with a particular emphasis on patient perceptions, encompassing five dimensions: Tangibles, Reliability, Responsiveness, Assurance, and Empathy.26–28 In particular, Eun Kyoung Yun et al. have highlighted the important role of the SERVQUAL model in the management of telemedicine services. 29 Joongwon Choi et.al have utilized the SERVQUAL model to assess the availability of ChatGPT in providing medical information related to kidney cancer. 30
Currently, there is no research evaluating the use of ChatGPT for providing esophageal cancer information. Through a multidimensional approach encompassing literature review, Q&A comparison and specialist evaluation, our research aims to evaluate the efficacy and reliability of ChatGPT-3.5 generated outputs in addressing the informational needs of the public and esophageal cancer patients.
Study objective
This study evaluates the effectiveness and reliability of ChatGPT in providing medical information on esophageal cancer using the SERVQUAL framework. By leveraging AI technology, we seek to enhance patient communication, support informed decision-making, and ultimately improve the quality of care for individuals affected by this disease.
Method
Questions selection and answers generation
This study utilized the large language model based on the ChatGPT-3.5 architecture developed by OpenAI in San Francisco, California, USA (last updated in September 2021). The search was conducted between 1 March and 10 March 2024, from China, Nanchang locale, using a desktop device (Windows 10, Chrome browser, logged-out mode) to avoid personalization bias. First, based on the global search engine market share data from StatCounter, 31 we selected five widely used platforms “Google, Bing, Yahoo!, Yandex, and Baidu” as data sources. For each engine, the query term “esophageal cancer” was entered, and the top 20 patient-facing questions were extracted from the “People also ask” and “related searches” sections. Extraction was performed manually by two independent researchers, with discrepancies resolved by consensus. In parallel, we conducted structured interviews with five frontline gastroenterologists (three from academic tertiary hospitals, two from regional medical centers). Each clinician provided the 10 most frequently asked patient questions regarding esophageal cancer in routine outpatient consultations. The search-derived and clinician-reported lists were merged, deduplicated, and categorized into seven domains (prevention, diagnosis, early symptoms, progression, prognosis, treatment, heredity). Two senior gastroenterologists independently reviewed the pool and selected 10 representative questions that were both clinically meaningful and frequently encountered. The questions of selecting input chat to generate pre-trained transformers are shown in Table 1 (ChatGPT input). The finalized 10 questions were submitted to ChatGPT-3.5 in separate, independent sessions (new chat window each time, identical prompt format). Model outputs were not further edited except for formatting. The complete set of generated answers is provided in Supplemental materials.
Question list.

Questionnaire design
We constructed a structured evaluation instrument based on the SERVQUAL framework. Each ChatGPT answer was rated by clinical experts using a five-point Likert scale (1 = strongly disagree, 5 = strongly agree) across the following adapted dimensions, shown in Table 2.
The questions designed according to SERVQUAL model.

To minimize bias, raters were blinded to the identity of the AI system and the study hypothesis. The order of questions was randomized for each rater using a computer-generated sequence. Detailed rating instructions and anchors were provided, and the full evaluation instrument is included in Supplemental materials. The mapping of SERVQUAL dimensions to textual answer properties was guided by prior applications of SERVQUAL in digital health information quality assessment 30 and refined through pilot testing with two gastroenterologists, who confirmed clarity and domain relevance. Minor revisions were made based on their feedback before full deployment.
Participant and recruitment
In May 2024, a total of 50 gastroenterologists were invited to participate in a questionnaire survey through the online platform Sojump. Eligibility for participation was based on the inclusion criteria for holding a medical practitioner qualification, being currently employed in the field of gastroenterology, and agreeing to take part in the study by completing the questionnaire. The specialist group was defined as physicians who manage more than 10 newly diagnosed esophageal-cancer patients per month (both squamous cell carcinoma and adenocarcinoma); those with ≤10 cases per month formed the non- specialist group. The exclusion criteria ruled out non-gastroenterological practitioners and deemed any questionnaires completed in less than 60 s as invalid. Additionally, participants had the option to withdraw voluntarily from the study, or they would be excluded if they were unable to complete the questionnaire for any reason.
Statistical analysis
All statistical analyses were performed using R version 4.4.0. The Likert-scale data derived from SERVQUAL evaluations were treated as ordinal variables. As the assumptions for parametric tests were not considered appropriate for this data type, the non-parametric Wilcoxon rank-sum test (Mann–Whitney U test) was employed to compare responses between specialist and non-specialist groups. Effect sizes were quantified using Cliff's Delta (δ) along with their 95% confidence intervals (CIs). The magnitude of effect sizes was interpreted as follows: |δ| < 0.147 (negligible), 0.147–0.33 (small), 0.33–0.474 (medium), and >0.474 (large).
Positive evaluation rate (PER) was calculated as the percentage of responses rated 4 (Agree) or 5 (Strongly Agree) on the 5-point Likert scale. This metric was used to assess the proportion of gastroenterologists who provided favorable evaluations of ChatGPT's responses.
Inter-rater reliability among the 48 gastroenterologists was assessed using the intraclass correlation coefficient (ICC) based on a two-way random-effects model for absolute agreement. ICC values were interpreted according to conventional guidelines: < 0.50 (poor), 0.50–0.75 (moderate), 0.75–0.90 (good), and >0.90 (excellent) (Figure 1).
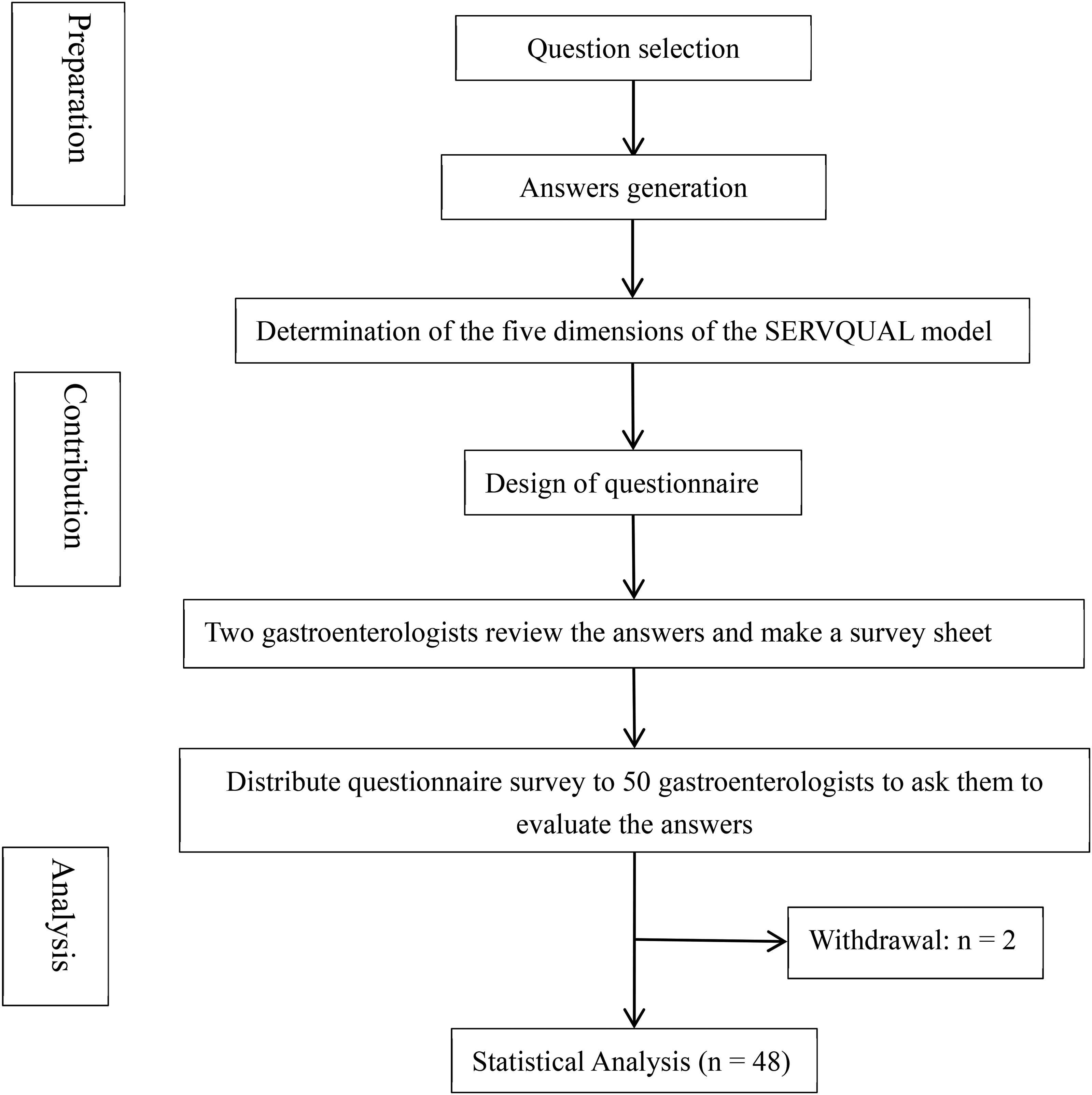
Flowchart of the whole process.
Results
Of the 50 questionnaires distributed, one invalid response, completed in less than 1 min, was discarded, leading to a final collection of 48 questionnaires. The recovery rate of the questionnaires was thus 96%. The general information distribution is given in Table 3.
General information distribution.

Among participants, 72.92% were male and 27.08% female. The age groups with the highest proportions were 20–40 years old (39.59%) and 40–50 years old (39.58%), while the proportions for over 50 years old were 20.83%, respectively. The majority of participating medical institutions were university or tertiary hospitals (91.67%), while secondary hospitals accounted for 8.33%. Most doctors saw an average of less than 10 esophageal cancer patients per month, accounting for 85.42%. A few doctors saw 10–20 patients with esophageal cancer per month (12.5%), and 2.08% saw more than 20 patients. To determine if there were significant differences in responses, we compared physicians seeing more than 10 esophageal cancer patients per month to those seeing fewer than 10. More than 10 patients per month were considered more experienced specialists, and those less than 10 were considered generalists. The results indicated that 40% of the questions (questions 1, 2, 3, and 4) showed significant differences in reliability and comprehensiveness. Consequently, we concluded that physicians seeing more than 10 esophageal cancer patients per month demonstrated greater clinical knowledge of esophageal cancer. Cronbach's alpha reliability analysis of the questionnaire indicated an overall alpha value of 0.99, suggesting high reliability and strong consistency among the question items.
Detailed responses and scores for all questions can be found in the Supplemental material. The corresponding average scores and PER for each question across the five SERVQUAL dimensions are summarized in Figure 2. The overall PER for the 10 questions ranged from 70.83% to 93.75%, with average scores ranging from 3.9 to 4.43. Question 7, regarding the hereditary nature of esophageal cancer, received the highest overall PER (93.75%) and score (4.43) among all questions, with particularly strong performance in Tangibles, Reliability, Assurance, and Empathy dimensions (all 95.83%). In contrast, question 4, concerning the early symptoms of esophageal cancer, had the lowest overall PER (70.83%) and score (3.9), with particularly low ratings in Responsiveness (66.67%) and Reliability (70.83%). Notably, questions 5, 7, and 10 demonstrated consistently high PER across all dimensions (>85%), while question 4 showed the weakest performance. The Responsiveness dimension generally received lower PER compared to other dimensions across most questions, suggesting limitations in ChatGPT's ability to provide cutting-edge information. Seven out of ten questions received an overall PER exceeding 85%, indicating generally favorable evaluations by gastroenterologists.

Evaluation of ChatGPT-generated esophageal cancer information using SERVQUAL framework (n = 48). (A) Heatmap of average scores across five dimensions. (B) Positive evaluation rates (percentage of ratings ≥4) by question and dimension.
Additionally, Table 4 summarizes whether there were significant differences between the responses of gastroenterologists with more than 10 monthly patients and those with fewer than 10. The inter-rater reliability for the overall evaluations, as measured by ICC, was 0.988 (95% CI, 0.982, 0.992), indicating excellent agreement among the gastroenterologists.
Wilcoxon rank-sum test results comparing SERVQUAL dimension ratings between specialists and non-specialists.

Discussion
Strengths, gaps, and risks in ChatGPT's medical responses
In this study, two specialists separately evaluated the comprehensiveness of each ChatGPT answer. The comprehensiveness of responses to 10 questions was recognized, providing valuable information for patients to refer. However, the answers also exhibited notable incompleteness, particularly the absence of cutting-edge therapeutic strategies, updated scientific results, and prognostic data. Furthermore, the specialists acknowledged the structured and logical nature of the answers but expressed skepticism regarding their specificity. They noted that ChatGPT did not provide examples or detailed explanations to help the public assess the applicability of the opinions.
We also surveyed gastroenterologists who evaluated ChatGPT responses to questions about esophageal cancer, with overall positive ratings for questions like “Can esophageal cancer be inherited?” However, the ChatGPT responses scored relatively low in terms of reliability and responsiveness to the latest insights, which indicates ChatGPT's responses lacked incorporation of emerging therapeutic modalities. The omission of such advancements may mislead patients regarding treatment options. This gap underscores ChatGPT's dependency on pre-2021 data, limiting its utility for real-time clinical decision support.32–34 Future AI iterations must integrate dynamic medical database updates to address this critical shortfall. Interestingly, a deeper analysis revealed statistically significant differences in specialists and non-specialists. Specialists consistently assigned lower ratings in the dimensions of reliability and responsiveness, comparing to non-specialists. These differences underscore the value of domain expertise in critically evaluating AI-generated content, especially in high-stakes contexts such as oncology.
In addition, Q4 (“What are the early symptoms of esophageal cancer?”) received relatively low scores because ChatGPT emphasized only general symptoms and overlooked the fact that early manifestations are often subtle and nonspecific. Such omissions may delay timely health-seeking, especially among populations with low health literacy. Enhancing symptom prioritization and linking vague complaints to actionable next steps will be crucial for future improvements.
ChatGPT is considered to serve as a useful source of information for both patients and healthcare professionals. 35 However, ChatGPT relies on large-scale data collection and subsequent training. Due to the limitations of its training data, ChatGPT may face challenges in providing accurate and in-depth specialized medical knowledge. Study shows that ChatGPT performed poorly in the diagnosis and treatment categories, with treatment being the only category where it was entirely incorrect. 36 Consequently, ChatGPT cannot replace the comprehensive diagnosis and treatment provided by medical professionals.
It also cannot be held accountable for answers generated through ongoing training, which face a number of data security and privacy risks.37,38 There is a potential risk of medical disputes, particularly when incorrect information is provided, as it can be challenging to determine accountability for erroneous responses.39,40 As an auxiliary diagnostic and treatment tool, there is concern that discrepancies between ChatGPT's information and that of medical specialists could exacerbate doctor–patient conflicts.41,42 Furthermore, ChatGPT is not capable of offering adaptive advice tailored to individual patients from different backgrounds. Harry Collin noted that ChatGPT may not fully capture the breadth or depth of understanding from patients with varying educational backgrounds and mental states. 43 Answers based on a college education level may present comprehension challenges for individuals with lower educational attainment.44–47
Study limitations and methodological considerations
Our study has several limitations that should be acknowledged. First, regarding sample composition, only 12.5% of respondents were specialists who saw more than 10 esophageal cancer patients per month, and 72.92% of participants were male. According to the Age-Standardized Incidence Rate per World Standard Population (ASIRW), the incidence of esophageal cancer is 11.13 per 100,000, reflecting its relatively low prevalence in the general population. 48 Within the spectrum of digestive system tumors, esophageal cancer occurs less frequently than colorectal, gastric, and liver cancers. 49 As a result, many physicians may encounter fewer than ten esophageal cancer patients monthly, potentially limiting the representativeness of our findings. Future studies should therefore include a higher proportion of subspecialists with extensive case exposure. Second, the study population was heavily skewed toward Chinese physicians, most of whom were based in universities or tertiary hospitals. This concentration may limit the applicability of results to other regions, community hospitals, and international settings. Because esophageal cancer incidence and clinical practices differ in regions, future research should strive to include clinicians from high-incidence countries and diverse healthcare contexts to improve external validity. Third, the evaluators in our study were physicians rather than patients. While physicians provide valuable expert perspectives on accuracy and reliability, this design may not fully capture the patient's perspective regarding clarity, empathy, and practical applicability. Future investigations should integrate patient feedback to more comprehensively assess the usability of AI-generated content in real-world contexts. Finally, although the adapted SERVQUAL scale showed excellent internal consistency, it has not undergone formal psychometric validation. Future studies should conduct confirmatory factor analysis and reliability testing to establish its validity within the context of AI-generated medical content. Moreover, certain SERVQUAL dimensions may not fully align with digital health evaluations. For instance, the “Tangibles” dimension, originally intended to assess physical facilities, was reinterpreted in this study as the logic and structure of AI-generated responses. While this adaptation enabled consistent scoring, it may not fully capture user experience with AI content, thereby constraining the generalizability of our results.
Challenges in applying AI to medical contexts and future directions
ChatGPT is still in its early stages in the medical field. Due to the lack of its most recent advancements, diagnostic and therapeutic advice requires further refinement before recommending it as a widely used linguistic model for the diagnosis and treatment. And low empathy scores reflect ChatGPT's inability to tailor its responses to the patient's specific context. While its responses are structurally coherent, they fail to accommodate, for example, geographic risks. This highlights that AI lacks human-like contextual interpretation, which remains crucial for patient-centered communication. Future developments should incorporate patient-specific adaptive frameworks, possibly through integrated demographic filters. On top of that, to improve reliability, AI tools like ChatGPT should be integrated with updated medical databases and supervised by healthcare professionals. Future models must address shortcomings in responsiveness and contextual accuracy before clinical implementation. It is also crucial to emphasize the significant role of physicians and specialists in patient diagnosis and prognosis.
And for the SERVQUAL model, future studies should perform psychometric evaluations such as Cronbach's alpha for internal consistency, and factor analyses to confirm the structure of the adapted instrument in the context of AI-based medical service evaluation. Moreover, the model has ethical and legal liability gaps that do not address AI accountability mechanisms and data privacy risks. Future studies should integrate AI-specific metrics with SERVQUAL and introduce patient perspective assessment.
In the future, we will keep up with the times by tracking the stability of answers to the same question across GPT versions and update cycles and integrating a continuous learning framework to enable the model to update medical guidelines in real time and label knowledge currency. We can develop more sensitive models to push precise recommendations, such as reducing hot food intake and mold contamination, for users in areas with a high prevalence of esophageal cancer. At the patient level, we will develop a trustworthiness score visualization component on the patient interaction page, which will indicate the reliability of the answer with 5 stars to avoid over-reliance by patients.
Conclusion
This study evaluated ChatGPT's ability to deliver esophageal cancer information using specialist assessments within the SERVQUAL framework. While ChatGPT generated coherent and logically structured responses, it showed clear shortcomings in accuracy, medical specificity, and contextual adaptability, particularly regarding up-to-date clinical knowledge and individualized guidance. Specialists with extensive clinical experience rated its performance more critically, underscoring the limitations of static AI models in complex medical contexts. Future improvements should focus on enhancing reliability through integration with updated clinical guidelines, incorporating geo-sensitive and demographically adaptive modules, and developing real-time learning mechanisms. Attention must also be given to ethical and legal safeguards, including transparent accountability systems, to address liability in medical decision-making. Ultimately, AI tools like ChatGPT should complement rather than replace physician expertise. Positioned as supervised educational adjuncts, they may help improve patient communication and health literacy. Further research comparing multiple large language models and including patient perspectives will be crucial for ensuring their safe and effective deployment in healthcare.
Supplemental Material
sj-doc-2-dhj-10.1177_20552076251393291 - Supplemental material for Effectiveness of ChatGPT to provide esophageal cancer information: A SERVQUAL-based analysis
Supplemental material, sj-doc-2-dhj-10.1177_20552076251393291 for Effectiveness of ChatGPT to provide esophageal cancer information: A SERVQUAL-based analysis by Wangxinjun Cheng, Yichen Liu, Chufan Zhou and Chuan Xie in DIGITAL HEALTH
Supplemental Material
sj-docx-3-dhj-10.1177_20552076251393291 - Supplemental material for Effectiveness of ChatGPT to provide esophageal cancer information: A SERVQUAL-based analysis
Supplemental material, sj-docx-3-dhj-10.1177_20552076251393291 for Effectiveness of ChatGPT to provide esophageal cancer information: A SERVQUAL-based analysis by Wangxinjun Cheng, Yichen Liu, Chufan Zhou and Chuan Xie in DIGITAL HEALTH
Footnotes
Ethics approval and consent to participate
This study was reviewed and approved by the Institutional Ethics Committee of the First Affiliated Hospital of Nanchang University (Approval No. (2025) CDYFYYLK (07-020)). All procedures performed in this study involving human participants were conducted in accordance with the ethical standards of the Institutional Ethics Committee and with the 1964 Helsinki Declaration and its later amendments. However, all participants were presented with a detailed information sheet on the first page of the online survey, which outlined the study's purpose, the voluntary nature of participation, data anonymity, and their right to withdraw at any time. Proceeding to complete and submit the questionnaire was considered implied consent.
Author contributions
Wangxinjun Cheng and Yichen Liu were responsible for the writing of the paper. Chufan Zhou was responsible for the data analysis. Chuan Xie was responsible for the guidance and proofreading.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Talent Team Plan-Ganpo Talent Support Plan-Major Academic and Technical Leader Training Project-Leading Talents (Academic) (20243BCE51001), Ganpo Talent Program (gpyc20240212), Natural Science Foundation of Jiangxi Province (20242BAB26122).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The data that support the findings of this study are not publicly available due to some privacy reasons but are available from the corresponding author upon request.
Generative artificial intelligence (AI)
The AI Usage Statement for this study clarifies that AI technologies were utilized to assist in data analysis and interpretation, with human oversight ensuring the integrity and accuracy of the research findings.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.