
Abstract
Aim
To evaluate the ability of large language models (LLMs) to produce patient education materials for myopic children and their parents.
Methods
Thirty-five common myopia-related questions were used with two distinct prompts to produce responses aimed at adults (Prompt A) and children (Prompt B). Five ophthalmologists evaluated the responses using a 5-point Likert scale for correctness, completeness, conciseness, and potential harm. Readability was assessed via Flesch–Kincaid scores. The Kruskal-Wallis and Mann-Whitney U tests were used to identify significant differences in LLM performance.
Results
ChatGPT 4o achieved the most positive ratings (“good” and above) in correctness (Prompt A: 91%; Prompt B: 83%) and conciseness (Prompt A: 79%; Prompt B: 63%), as well as the lowest negative ratings in potential harm ratings (“not at all” and “slightly,” Prompt A: 99%; Prompt B: 97%) in the generation of educational materials for both adults and children (all p < 0.001). In terms of completeness, the results varied between the two prompts. Specifically, in Prompt A, ChatGPT 4.0 demonstrated the highest level of completeness (ChatGPT 4o: 69%, ChatGPT 4.0: 74%, ChatGPT 3.5: 51%, Gemini: 73%, p < 0.001), whereas in Prompt B, ChatGPT 4o achieved the highest score (ChatGPT 4o: 71%, ChatGPT 4.0: 65%, ChatGPT 3.5: 38%, Gemini: 46%, p < 0.001). The responses generated with Prompt B were significantly more readable than those generated with Prompt A across all LLMs (p ≤ 0.001).
Conclusion
Large language models, particularly ChatGPT 4o, hold potential for delivering effective patient education materials on myopia for both adult and pediatric populations. While generally effective, LLMs have limitations for complex medical queries, necessitating continued refinement for reliable clinical use.
Introduction
Myopia, also known as near-sightedness, is a common condition in which images of distant objects are focused in front of the retina due to excessive elongation of the eye. Over the past three decades, the global prevalence of myopia has increased significantly, particularly among younger generations, due to factors such as urbanization, intensified academic demands, and reduced time spent outdoors, which has led to its description as an “epidemic”. 1 Projections by Holden indicate that by 2050, nearly 49.8% of the global population will be affected by myopia. 2 The prevalence of myopia varies across regions, with the highest rates concentrated in East Asia and Southeast Asia. 3 In developed countries within these regions, up to 80–90% of children completing secondary education are myopic by the age of 17–18. 4 Furthermore, high myopia can deteriorate into pathological myopia, causing myopic retinopathy and potentially leading to vision loss. 4 Therefore, implementing effective strategies to prevent and slow the progression of myopia is essential.
Early screening and treatment can reduce the incidence of myopia. Daily management is fundamental to controlling myopia and is closely linked to lifestyle choices. Consequently, it requires the self-discipline of both the affected child and their parents. A lack of knowledge and awareness regarding refractive errors significantly contributes to axial elongation. 5 According to Kuehn, 6 more than one-third of individuals in the United States rely on the internet for self-diagnosis. The reliability of online health information services can significantly influence patients’ and their families’ understanding of myopia, directly impacting treatment compliance and overall effectiveness.
The application of artificial intelligence (AI) large language model (LLM) chatbots in medicine has recently generated significant interest. Large language models can generate conversational, personalized responses that simulate human dialog, making them potentially well-suited to support accessible, age-appropriate health education. Large language model-generated text has strong summarization capabilities and high comprehensibility, making it particularly accessible for school-aged children. Prior studies have demonstrated promising applications of LLMs in ophthalmology7,8 and broader medical domains9–13 but have also revealed variable accuracy and limitations in clinical reasoning. Importantly, little is known about how well these models can tailor responses to suit pediatric users, particularly for common but behaviorally sensitive conditions such as myopia.
With the rapid evolution of AI technologies, including LLMs, their capabilities continue to expand. A comprehensive evaluation of LLM performance in ophthalmology, particularly in the context of pediatric ophthalmology, is necessary. With children turning to the internet for health information worldwide, effective myopia education has become particularly crucial, especially for 8–12-year-olds, during this vision's critical development phase. 14 However, most existing educational materials still primarily target adult audiences. Given children's limited knowledge and greater susceptibility to misinformation, it is crucial to investigate whether LLMs can provide reliable and accurate medical guidance for younger audiences.
Therefore, this study aims to evaluate the ability of four leading LLMs—ChatGPT 3.5, ChatGPT 4.0, ChatGPT 4o, and Gemini—to generate reliable, understandable, and audience-specific educational responses to myopia-related questions. Specifically, two distinct prompts were employed to produce two sets of patient education materials, one tailored for children, and the other for parents, and the responses were assessed. Given the cognitive characteristics of children, particularly those within the high-incidence age group for myopia, we restricted the LLM output to create content that is more easily understood by children, addressing their specific questions about myopia. This work addresses a critical gap in AI-assisted patient education, provides a structured comparison of LLM performance in child-oriented health education, and offers implications for the future development of trustworthy AI tools in pediatric ophthalmology.
Methods
Ethics
Approval from the review board was not required because no human was involved. The study followed the Strengthening the Reporting of Observational Studies in Epidemiology reporting guidelines. 15
Selecting questions and LLMs
The study was conducted between June and August 2024 at the Optometry Center, Peking University People's Hospital. We selected questions that are commonly asked by patients from online health information outlets, including the American Academy of Ophthalmology (https://www.aao.org), the Brien Holden Vision Institute (https://bhvi.org), and the National Eye Institute (https://www.nei.nih.gov). Modifications were made to these questions, ultimately resulting in a total of 35 questions divided into three sections: “Pathogenesis and Risk Factors,” “Clinical Presentation, Diagnosis and Prognosis,” and “Treatment and Prevention.”
The LLMs used in this study were chosen on the basis of their advantages and wide applicability. ChatGPT 3.5, ChatGPT4.0, ChatGPT 4o, and Google Gemini were incorporated into the study to be tested at length, encompassing the two major technical paradigms and ecosystems of current mainstream LLMs. ChatGPT 4.0, developed by OpenAI, is the original version of the GPT-4 model, known for its powerful language generation and understanding capabilities, whereas ChatGPT 4o is an optimized version of GPT-4.0, making it more efficient and practical for computationally intensive applications. Gemini, as Google's next-generation multimodal model, emphasizes performance in information integration and factual consistency, representing an alternative architectural approach (based on PaLM 2/Gemini 1.5). All three versions of ChatGPT can be accessed at https://chat.openai.com/, and Gemini can be accessed at https://gemini.google.com/app. Gemini, ChatGPT 3.5 and ChatGPT 4o are publicly accessible at no charge, whereas ChatGPT4.0 requires a paid subscription.
Conducting the study
The statements sent to the LLMs were organized in the order of “question + prompt.” Drawing upon Piaget's theory of cognitive development stages, children aged 8–12 are in the concrete operational stage and are capable of understanding concrete logic but not yet fully grasping abstract concepts. Therefore, explicitly requiring “easily understandable” and age-appropriate content in the prompts helps the models generate semantically clear responses that avoid abstract terminology. The prompts were as follows: For patient parents, prompt A was used: “Please write a patient-targeted answer.” For myopic children, prompt B was used: “Given that ages 8–12 are a period of rapid progression for myopia, please write a patient-targeted answer that is easily understandable for children aged 8–12.” After each query, the conversation was reset to minimize memory retention bias from the LLMs. Therefore, we received 280 responses each using prompt A and prompt B (Tables S1–S8).
All the responses were modified into a uniform format to conceal any LLM-specific features and were then randomly shuffled and formed into eight questionnaires for grading, as shown in Figure 1. Five experienced ophthalmologists with a minimum of five years of experience performed a blind evaluation of the responses.

Flowchart of the study design.
The responses were graded in four metrics: correctness, completeness, conciseness, and potential harm. A 5-point Likert scale (1: “very poor,” 2: “poor,” 3: “medium,” 4: “good,” and 5: “very good”) was used for the first three evaluation metrics. For the fourth metric, potential harm, we also used a 5-point Likert scale (0: “not at all,” 1: “slightly,” 2: “moderately,” 3: “very,” and 4: “extremely”) for evaluation. The responses generated by the LLMs were scored by ophthalmologists on the basis of their professional experience and clinical judgment. Readability was assessed by the Flesch Reading Ease (FRE) score and Flesch–Kincaid grade level (FKGL), which were calculated using the following formula:


The calculation procedure was completed on https://goodcalculators.com/flesch-kincaid-calculator/.16,17 Higher FRE scores indicate easier readability. Flesch–Kincaid grade level is equivalent to the level of education in the United States.
Data analysis
R (version 4.3.1) and SPSS 27.0 were used to conduct the data analysis. The Friedman test and post hoc test were used to conduct a multivariable analysis. To compare the difference in readability and each metric among the four LLMs’ responses to the same prompt, the Kruskal-Wallis test and Dunn's test were employed, as the samples did not meet parametric assumptions. Bonferroni correction was used to adjust p values when multiple hypotheses tests were involved. To compare differences between responses of the same LLM to prompts A and B, the Mann-Whitney U test was used. A p value less than 0.05 was considered statistically significant.
Results
Readability
The word counts of the LLMs’ responses to prompts A and B are shown in Table 1. There was a significant difference between ChatGPT 3.5 and the other three LLMs in terms of word count (χ² = 45.49; ChatGPT 3.5 vs. ChatGPT 4.0: p < 0.001; ChatGPT 3.5 vs. ChatGPT 4o: p < 0.001; ChatGPT 3.5 vs. Gemini: p < 0.001). No significant differences were found among the latter three LLMs. Furthermore, the word counts of ChatGPT 4.0's responses to prompts A and B differed significantly (p = 0.022), and a similar trend was observed for Gemini (p = 0.030).
Word counts of LLMs’ responses to prompt A and prompt B.

Values are shown as mean ± standard deviation (SD), minimum, and maximum. Mann–Whitney U test was used to compare word counts between prompts for each LLM (p < 0.05). Statistical significance was set at p < 0.05.
To quantitatively evaluate readability, we employed the Flesch-Kincaid readability assessment. Additionally, Friedman and post hoc tests were conducted to statistically compare the results across each model. For the reading level variable, we transformed the categorical variable into ranks for calculation. Friedman tests revealed significant differences across all readability metrics, including FKGL (χ² = 155.63, p < 0.001), FRE score (χ² = 185.50, p < 0.001), average words per sentence (χ² = 20.70, p = 0.004), average syllables per word (χ² = 205.39, p < 0.001), sentences (χ² = 120.69, p < 0.001), and reading level (χ² = 193.10, p < 0.001).
To pinpoint the origin of the statistical discrepancy, we conducted a subgroup analysis. We began our analysis by examining the four LLMs within the prompt A subgroup, which revealed significant differences in FKGL (χ² = 17.42, p < 0.001), FRE score (χ² = 20.32, p < 0.001), reading level (χ² = 9.54, p < 0.05), average syllable per word (χ² = 13.98, p < 0.05), and sentence count (χ² = 43.25, p < 0.001) among the responses of the four LLMs to Prompt A. Dunn's post hoc test revealed that Gemini exhibited greater readability than ChatGPT 4.0 did, with a higher FRE score (p < 0.001), a lower FKGL (p < 0.001), a lower average syllable per word (p = 0.001), and a lower reading level (p < 0.05). In terms of Sentence Count, Gemini and ChatGPT 4o generated the most sentences, followed by ChatGPT 4.0 and then ChatGPT 3.5. Overall, Gemini generated the most readable text, whereas ChatGPT 4.0 produced the least readable content.
Similarly, we performed an analysis of the LLMs in the prompt B subgroup. In response to prompt B, there were no significant differences among the four LLMs regarding the FKGL (χ² = 3.62, p = 0.31) or FRE score (χ² = 3.73, p = 0.29). However, significant disparities emerged in several areas: reading level (χ² = 11.61, p < 0.05), average words per sentence (χ² = 12.50, p < 0.05), average syllables per word (χ² = 15.24, p < 0.05), and sentence count (χ² = 48, p < 0.001). Specifically, Gemini presented a lower reading level than ChatGPT 4odid (p = 0.0057), indicating greater readability. ChatGPT 4o generated answers with fewer average words per sentence than did ChatGPT 3.5 (p = 0.036) and ChatGPT 4.0 (p = 0.019). In terms of average syllables per word, ChatGPT 4o had a higher count than ChatGPT 3.5 did (p = 0.0064) and Gemini did (p = 0.042) but a lower count than ChatGPT 4.0 did (p = 0.0038). This phenomenon may be attributed to the constraints imposed by prompt B, which likely compelled all four models to adjust their output to a similar level of readability.
A comparative analysis of the prompt A and B subgroups was conducted. Regardless of the LLM, there is a significant difference in readability between the responses to prompt A and prompt B (Table 2). Specifically, responses to prompt B exhibit higher readability scores in terms of FKGL, FRE score, average syllables per word, and reading level. The results indicate that different prompts can significantly influence the readability of text generated by language models.
Flesch–Kincaid readability scores in different LLM models.

The data in the table are presented as mean ± standard deviation (except for reading level). We used the Mann–Whitney U test to perform the analysis, with p < 0.05 considered statistically significant.
FRE: Flesch Reading Ease Score; FKGL: Flesch–Kincaid grade level.
*In the table, we displayed the dominant reading level for each prompt. Numerical values were assigned to these levels for subsequent statistical analysis.
Correctness, completeness, conciseness, and potential harm
The 5-point Likert-scale score distributions of the responses generated by different LLMs for different prompts are shown in Figure 2. The results for correctness and completeness show similar trends (Figure 2(a)). For correctness in prompt A, the majority of evaluations for responses generated by the four LLMs were positive, with “good” being the most common rating. With respect to completeness, ChatGPT 3.5 received the most negative evaluations, with a significantly lower proportion of positive evaluations than its counterparts did. In terms of conciseness, ChatGPT 3.5 and ChatGPT 4o performed more favorably, achieving positive ratings of 73.71% and 79.43%, respectively, than ChatGPT 4.0 (69.14%) and Gemini (68.00%). Notably, none of the responses generated by the LLMs were categorized as “extremely harmful” by the ophthalmologists involved in the evaluation, and the majority were deemed to pose no harm at all.

Distribution of different ratings for large language model (LLM) responses to prompt A for parents (left) and prompt B for myopic children (right).
For prompt B, while Gemini and ChatGPT 3.5 did not perform as well as the other two models did, the majority of the LLMs’ responses still received positive reviews in correctness (Figure 2(b)). However, in terms of completeness, fewer than 50% of the evaluations for Gemini and ChatGPT 3.5 were positive, with negative ratings of 15.43% and 26.86%, respectively. For conciseness, despite some variations, the four LLMs received comparable percentages of “very good” ratings. Additionally, ChatGPT 3.5 and Gemini received substantially higher proportions of “very harmful” and “extremely harmful” ratings, whereas ChatGPT 4.0 and ChatGPT 4o received none. Notably, both ChatGPT 3.5 and Gemini received 1.14% “extremely harmful” ratings, highlighting the importance of developing safe and reliable AI models.
The Friedman test indicated significant discrepancies among the responses of different LLMs across all four evaluated metrics (correctness [χ² = 176.08, p < 0.001], completeness [χ² = 163.08, p < 0.001], conciseness [χ² = 118.36, p < 0.001], and potential harm [χ² = 91.10, p < 0.001]).
To further explore the influence of different models and prompts on response outcomes, we employed the Kruskal-Wallis and Wilcoxon tests for statistical analysis. Subgroup analysis of prompt A revealed that ChatGPT 4o outperformed the other models in all the metrics. The results 276 of the Kruskal-Wallis test revealed that there was a significant difference among the four LLMs in 277 terms of correctness (χ² = 32.29, p < 0.001) and completeness (χ² = 40.34, p < 0.001). ChatGPT 3.5 demonstrated an inferior average total correctness score of 3.90 ± 0.84 (Figure 3(a)), which was lower than those of ChatGPT 4.0 (4.26 ± 0.72), ChatGPT 4o (4.32 ± 0.66), and Gemini (4.26 ± 0.79) (all p < 0.001). Additionally, ChatGPT 3.5 (3.59 ± 1.01) failed to achieve higher scores in terms of completeness than did ChatGPT 4.0 (4.12 ± 0.87), ChatGPT 4o (4.19 ± 0.81), and Gemini (4.08 ± 0.90) (all p < 0.001). For conciseness (χ² = 5.59) and potential harm (χ² = 3.76), no significant differences were found across the four LLMs.

Mean scores of the responses generated by the four large language models (LLMs) for prompts A (left) and B (right).
For prompt B, ChatGPT 4o also demonstrated comprehensive abilities, similar to prompt A (Figure 3(b)). Significant differences were observed among the four LLMs in correctness (χ² = 43.4097, p < 0.001), completeness (χ² = 42.9907, p < 0.001), conciseness (χ² = 13.1456, p = 0.0043), and potential harm (χ² = 37.7021, p < 0.001). Dunn's post hoc test yielded similar results for correctness, completeness, and potential harm. Specifically, ChatGPT 4.0 (correctness: 4.02 ± 0.77, completeness: 3.90 ± 0.96, potential harm: 0.42 ± 0.60) and ChatGPT 4o (correctness: 4.11 ± 0.79, completeness: 3.98 ± 0.95, potential harm: 0.34 ± 0.53) provided greater correctness and completeness while posing lower risks than did ChatGPT 3.5 (correctness: 3.55 ± 0.98, completeness: 3.27 ± 1.21, potential harm: 0.82 ± 0.91), and Gemini(correctness: 3.70 ± 0.96, completeness: 3.55 ± 1.05, potential harm: 0.70 ± 0.89) (all p < 0.05). In terms of conciseness, a significant difference was found only between ChatGPT 4o and Gemini (p = 0.0014), implying that all four LLMs demonstrated a similar level of conciseness in their outputs.
The rating variability for potential harm is significantly greater than that for the other three dimensions. Across all the models and both prompts, the coefficient of variation (CV) exceeds 100%, reaching a maximum of 155.9% (ChatGPT 4o - Prompt B). This finding indicates that physicians were the least consistent in their assessments of this category, suggesting that it may involve the highest degree of subjectivity. In contrast, the other three dimensions generally have lower CVs, typically ranging from 15% to 30%, reflecting more consistent ratings and greater consensus among the raters. ChatGPT 4o exhibited the most consistent ratings overall for these three dimensions, with the lowest CVs; however, it also displayed extremely high variability in the potential harm category. The scores of each LLM on the four metrics are presented in Mean ± SD (Min, Max) format in Tables S9 and S10. The minimum and maximum scores given by the five ophthalmologists are also presented in Tables S11 and S12. Notably, the highest scores were assigned by nearly all the same rater, whereas the lowest scores were assigned by different raters.
Large language models exhibit significant variations in their responses to different prompts (Figure 4). In general, prompt A elicited more correct, complete, and concise responses from the four language models than did prompt B. When participants responded to prompt A, both ChatGPT 3.5 and Gemini outperformed their responses to prompt B in all four areas (all p < 0.02). ChatGPT 4.0 and ChatGPT 4o demonstrated higher accuracy (ChatGPT 4.0: W = 17953, p = 0.0021. ChatGPT 4o: W = 17374, p = 0.016) and conciseness (ChatGPT 4.0: W = 17670, p = 0.0061; ChatGPT 4o: W = 17963, p = 0.0028) in their responses to prompt A. Meanwhile, ChatGPT 4.0 exhibited greater completeness (W = 17277, p = 0.029) when responding to prompt A. Unlike other LLMs, ChatGPT 4o's responses to prompt A posed a greater risk of potential harm than did prompt B. However, there was no statistically significant difference between these risk scores (W = 15655, p = 0.66).
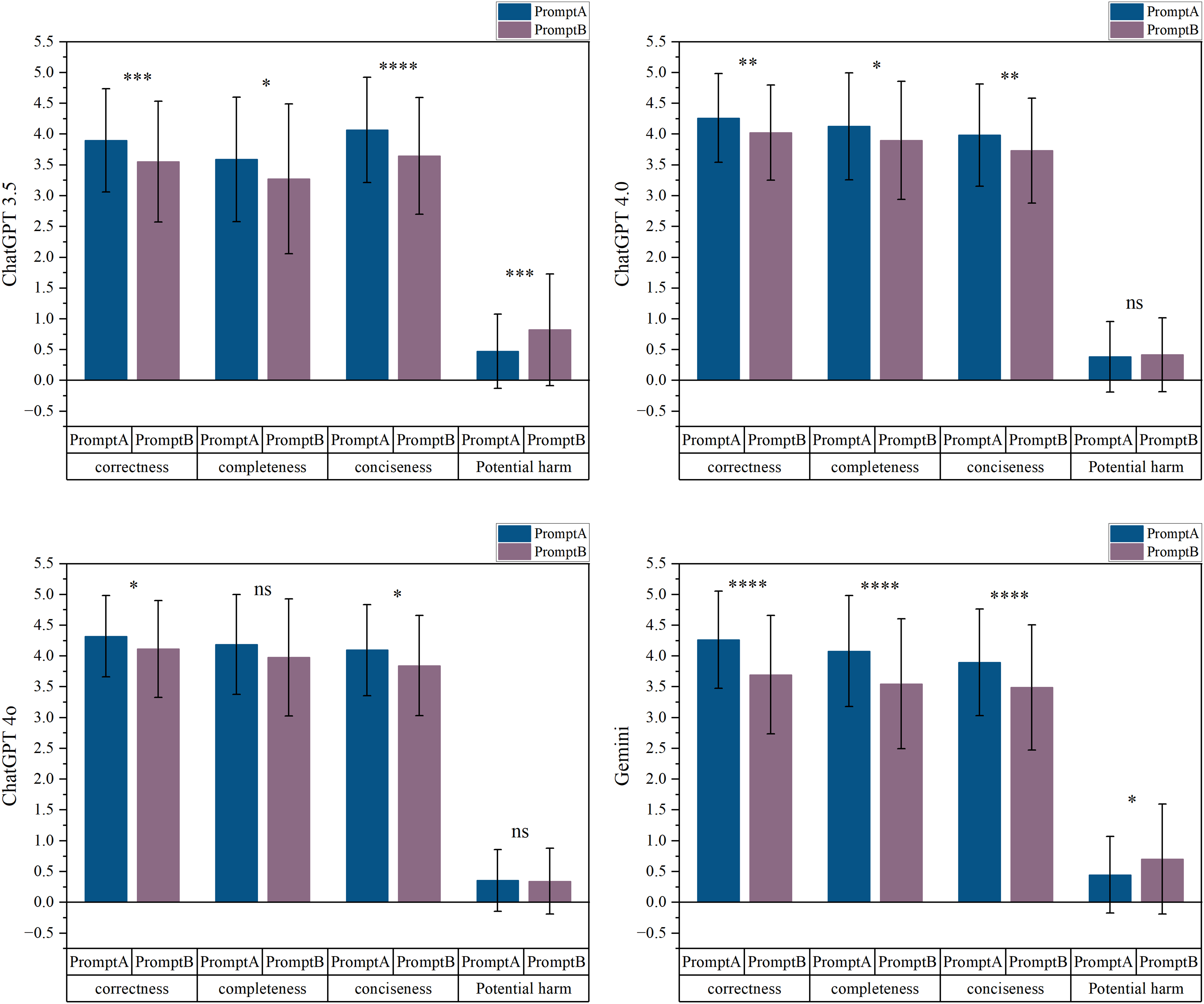
Large language model (LLM) performance on prompts A and B in correctness, completeness, conciseness, and potential harm.
Responses considered “discouraged”
To investigate common issues of LLMs when answering questions related to myopia, we rated the responses on the basis of their correctness scores. The evaluation criterion was as follows: if at least one of the five raters gave an accuracy score of 2 or less to a response, that response was considered “discouraged.” As shown in Figure S1, ChatGPT 3.5 received the highest number of “discouraged” ratings in both evaluations, followed by Gemini and ChatGPT 4.0. ChatGPT 4o performed the best.
For all 35 questions, questions 1, 2, 5, 13, 18, 19, and 33 received a significantly greater number of poor responses from LLMs. Among these seven questions, questions 1 and 2 are conceptual in nature, whereas the others require a certain level of clinical experience or extensive research of reliable literature to answer accurately. For example, question 19, “How effective are orthokeratology lenses in preventing or slowing the progression of myopia?” is influenced by numerous factors and requires clinical judgment on the basis of individual patient characteristics and clinical experience. This is likely because LLM responses are often based on general knowledge and pretrained materials and lack real-world case experience; thus, they may not be ideal for answering such questions.
Discussion
This study provides a comprehensive analysis of the use of LLMs in generating patient education materials on myopia. Thirty-five frequently asked questions, gathered from online platforms and clinical settings, were addressed using four LLMs: ChatGPT 3.5, ChatGPT 4.0, ChatGPT 4o, and Gemini. LLM chatbots delivered accurate and informative answers on myopia, adapting responses to different prompt structures. ChatGPT 4o consistently outperformed the other models across all the evaluation metrics, particularly in terms of accuracy, conciseness, and safety. While no statistically significant difference was observed between ChatGPT 4o, ChatGPT 4.0, and Gemini for responses to Prompt A, ChatGPT 4o proved to be the most reliable model for generating myopia education materials for patients, including both parents and children.
Large language model has been widely used in generating patient education materials on various topics, such as Helicobacter pylori infection, 18 dermatology, 19 cardiac catheterization, 20 bariatric surgery, 21 and orthodontics, 22 which has contributed to improving patient education. It was also used to transform inpatient discharge summaries into patient-friendly language and formats. 23 In terms of educational materials for ophthalmic patients, ChatGPT4.0 has been shown to generate high-quality, accurate, readability, and novel patient education materials on childhood glaucoma. 24 ChatGPT-4 has also been shown to improve the readability of existing materials on pediatric cataracts. 25
In our research, ChatGPT 4o provides the most accurate, complete, concise, and safe responses to both parents and children in the context of myopia patient education materials. Currently, there are few reports on the generation of educational materials using the GPT 4o. The only research retrieved thus far has been by Shaari et al., 26 who assessed the accuracy and readability of responses from GPT 3.5 and ChatGPT 4o regarding mandible fractures and reported no significant differences; however, the majority of the responses were deemed inappropriate for patient use. The answers generated by ChatGPT were often too specialized and not suitable for general patients, which may be due to issues with inaccurate prompts.
In our study, we used two different prompts to elicit the responses. An additional condition was attached to prompt B, which required the responses to be understandable for children aged 8–12 years. On the basis of the differences in Flesch-Kincaid readability scores, we can conclude that all LLMs responded well to the additional conditions. The FKGL decreased by approximately four grades, ranging from 9.63–11.99 to 6.36–7.01. This suggests that when querying LLMs, careful attention should be given to crafting prompts to elicit the most satisfying responses. Specifically, Gemini achieved the lowest FKGL for responses to both prompt A and prompt B, indicating that its generated text is the easiest to read. ChatGPT 4o's FKGLs were only marginally greater than Gemini's for both prompts, suggesting a balance of accuracy and readability. If we consider the FRE score, Gemini still ranks highest in terms of readability. However, ChatGPT 3.5 came second, which may be due to differences in the calculation methods of the two readability scores. Notably, in contrast to prompt A, the readability scores of the responses to prompt B across the four LLMs were not significantly different. This finding indicates that the LLMs were able to adjust the readability of their output to a comparable level when provided with more specific and constrained prompts, highlighting their adaptability to such requirements.
When considered comprehensively, ChatGPT 4o was the superior model. Compared with the other three models, its generated responses excelled in terms of accuracy, comprehensiveness, and conciseness and exhibited a high level of readability. Considering that ChatGPT 4o is the latest flagship generation model, the results seem feasible. Compared with previous versions, ChatGPT 4o not only matches ChatGPT 4 Turbo in English text processing but also demonstrates substantial improvements in non-English text and multimodal capabilities. 27 Chow et al. 28 compared the accuracy of ChatGPT 3.5 and ChatGPT 4o in answering multiple-choice questions related to radiation oncology. ChatGPT 4o answered 71.8% more than ChatGPT 3.5. Lee et al. 29 reported the accuracy of ChatGPT 4o, ChatGPT 4.0, and ChatGPT 3.5 in staging lung cancer on the basis of chest imaging. ChatGPT 4o achieved an overall staging accuracy of 74.1%, significantly outperforming ChatGPT 4.0 and ChatGPT 3.5. Günay et al. 30 reached a similar conclusion that ChatGPT 4o outperformed both Gemini and ChatGPT 4.0 in terms of ECG analysis accuracy.
Although the results show great promise in LLM for addressing medical-related issues, some problems still exist. First, their performance is unacceptable when questions that require certain investigations and clinical experience are involved. For example, questions such as “what causes myopia?” and “Can myopia cause blindness?” demand an extensive understanding of ophthalmology, optometry, and broader medical principles. The etiology and progression of myopia are intricate and involve potential interactions with ocular and systemic pathologies. A thorough understanding of human diseases and robust inferential reasoning are indispensable for providing a comprehensive response. Additionally, interpreting the effectiveness of orthokeratology and other lenses in slowing myopia requires massive amounts of reliable data from clinical trials and clinical experience due to variability among individuals. Therefore, it is not surprising that LLMs have limitations in answering these questions since they are not able to research and provide evidence from articles. Additionally, approximately 30% of the ChatGPT 4o responses were still rated as “slightly harmful.” While more specific prompts could reduce harmful responses, given that these patient education materials target children—even if the harm is only minor—clinicians must rigorously review all materials generated by LLMs before using them for patient education. Hence, while LLMs can be valuable tools, the risk of disseminating incorrect medical information cannot be neglected. It may misinform patients about their disease and affect their choice of treatment, potentially hindering effective health care. In Stroop et al.'s study, the rate of incorrect answers generated by ChatGPT was numerically low at 2/151 (1.3%) but was described as severe because this erroneous information directly concerned the choice of treatment options. 31 Giannakopoulos et al. evaluated the performance of LLMs in supporting evidence-based dentistry and reported that LLMs do not provide the sources of the information they use, which may undermine the safety and effectiveness of evidence-based treatment. 32 This finding serves as a reminder that great care should be taken when employing LLMs in medical applications.
While resetting the conversation after each prompt improved experimental control and consistency, it may not fully reflect real-world usage, particularly for children aged 8, which may undermine the safety and effectiveness of evidence-based treatmentuctions, allowing the model to retain prior context can enhance coherence, personalization, and responsiveness. 33 However, persistent context also introduces potential risks, such as information drift, cumulative error propagation, and compromised factual reliability. 34 These trade-offs are particularly salient in educational and pediatric settings, where sustained accuracy and safety are paramount. Further research is warranted to systematically evaluate how memory retention affects both the pedagogical utility and risk profile of LLMs in extended interactions.
This study represents a comparative analysis of the responses of ChatGPT 3.5, ChatGPT 4.0, ChatGPT 4o, and Gemini to myopia-related questions. By employing different prompts, we generated two sets of patient education materials about myopia that are suitable for both children and adults. A blind evaluation by five experienced clinicians further enhanced the rigor of our findings. A limitation of this study is that the questions were selected on the basis of frequently asked queries from patients on websites and in clinical settings, limiting the inclusion of personalized questions. Second, subjectivity in clinician scoring is inevitable, potentially leading to inconsistent scores for the same response. Additionally, individual comprehension varies significantly in real-world settings, making readability metrics a mere reference. Furthermore, this study provides only a comparative performance evaluation of generative AI models as of mid-2024. Given the rapid evolution of generative AI technologies, the findings may have limited temporal validity. However, this study establishes a clear evaluation framework for future research. Subsequent studies could extend this work by focusing on (1) risk monitoring, (2) real-world scenario simulations, (3) personalized input adaptation, and (4) optimized educational material generation. Additionally, we have compiled a set of myopia-related questions for LLM testing, which are included in Supplementary File. This resource provides a convenient reference for future studies exploring LLM applications in myopia research.
Conclusion
In conclusion, this study affirms the immense potential of LLMs, particularly ChatGPT 4o, in educating myopia patients and provides more specific guidance on their utilization. In clinical practice, ophthalmologists may utilize LLMs to assist in interpreting test results and providing eye care recommendations. However, continued improvement and optimization of LLMs are necessary, and caution should still be exercised when LLMs are used in clinical settings. It is crucial to avoid relying solely on LLMs for diagnosis or treatment decisions, ensuring that these AI tools serve a supplementary rather than substitutive role.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251362338 - Supplemental material for Using large language models to generate child-friendly education materials on myopia
Supplemental material, sj-docx-1-dhj-10.1177_20552076251362338 for Using large language models to generate child-friendly education materials on myopia by Xuewei Li, Yixuan Zhang, Tonglei Zheng, Yuanqi Deng, Yuchang Lu, Jie Hu, Sitong Chen, Yan Li and Kai Wang in DIGITAL HEALTH
Supplemental Material
sj-doc-2-dhj-10.1177_20552076251362338 - Supplemental material for Using large language models to generate child-friendly education materials on myopia
Supplemental material, sj-doc-2-dhj-10.1177_20552076251362338 for Using large language models to generate child-friendly education materials on myopia by Xuewei Li, Yixuan Zhang, Tonglei Zheng, Yuanqi Deng, Yuchang Lu, Jie Hu, Sitong Chen, Yan Li and Kai Wang in DIGITAL HEALTH
Footnotes
Acknowledgements
This work was supported by National Natural Science Foundation of China (Grant No. 82171092, 82371087), Capital's Funds for Health Improvement and Research (No. 2022-1G-4083).
Ethical approval
The Peking University People's Hospital Institutional Review Board exempted this study due to the absence of human subjects. This study adhered to the principles of the Declaration of Helsinki.
Contributorship
KW conceived conceptualization, funding acquisition, critically reviewed the manuscript for important intellectual content, and critically revised the manuscript. XWL conceived writing original draft manuscript; YXZ conceived formal statistical analysis; TLZ, YQD, YCL, JH, and STC conceived rate GPT's answers; YL and MWZ checked out to extract data, also participated in discussions on analytical methods and polishing articles.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Declaration of generative AI in scientific writing
ChatGPT 4.0 was only used in the writing process to improve the readability and language of the manuscript.
Data availability
All data will be made available in the supplemental materials.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.