
Abstract
Objective
This study aims to systematically review the current literature on the application of machine learning to predict return-to-sport (RTS) decisions after athletic injuries. The review focuses on identifying the types of machine learning models used, the commonly used predictive variables, and the methodological characteristics and limitations between studies in terms of design, model development, evaluation, and reporting.
Method
A comprehensive literature search was conducted on 1 May 2025 in three electronic databases: Web of Science, PubMed, and SPORTDiscus (EBSCO). Two independent reviewers selected the retrieved studies based on predefined inclusion and exclusion criteria. The Prediction Model Risk of Bias Assessment Tool (PROBAST) was used to assess the risk of bias in the included prognostic modeling studies.
Results
Of the 56 studies initially identified, 11 met the inclusion and exclusion criteria. Knee injuries were the most frequently modeled injury type for RTS decision-making (n = 4). The area under the receiver operating characteristic curve (ROC AUC) was the most commonly reported performance metric, presented in 82% of the included studies. Random Forest (RF) was the most widely used machine learning algorithm, applied in six studies (55%), and demonstrated the best predictive performance in four of them, with two studies reporting an AUC greater than 0.9. Some studies employed feature importance analysis or interpretability methods (e.g. SHAP) to identify key predictive variables. However, challenges remain in translating these models into clinical practice.
Conclusions
Machine learning techniques demonstrate promising potential for predicting RTS in athletes. Nevertheless, substantial heterogeneity across studies—particularly in RTS definitions, feature selection, and model development which limits the generalizability and clinical applicability of current models.
Introduction
Return to sport (RTS) represents one of the most critical and challenging phases in an athlete's rehabilitation process, involving complex, multistakeholder decision-making that includes the athlete, medical staff, and coaching team. Due to the high heterogeneity in injury types and recovery trajectories, 1 coupled with the current lack of consensus on optimal functional recovery standards and objective physiological RTS criteria, 2 RTS decisions are often fraught with uncertainty and debate. Anterior cruciate ligament (ACL) injury, one of the most prevalent types of sports-related injuries, 3 remains a central focus in sports medicine research. 4 However, reinjury rates following RTS after ACL reconstruction remain alarmingly high.5,6 Similarly, hamstring strain injury (HSI) carries a substantial risk of recurrence, with reported reinjury rates ranging from approximately 14% to 63%. Such variability is largely attributable to differences in the severity of the initial trauma, rehabilitation protocols, and RTS criteria applied across studies.7,8 These persistent risks raise concerns regarding the reliability of traditional clinical assessments and functional tests used in RTS decision making. 9
Premature RTS has been strongly associated with increased reinjury risk, 10 whereas delayed RTS does not necessarily guarantee complete functional recovery. Thus, developing a scientifically grounded and individualized RTS decision-making framework is essential to minimize secondary injuries and support long-term athletic health. Although prior studies have identified significant associations between specific functional benchmarks and reinjury risk, such as findings indicating that athletes failing to meet discharge criteria after ACL reconstruction are four times more likely to suffer graft rupture post-RTS compared to those who meet them 11 —these conclusions often rely on static, predetermined thresholds that fail to capture interindividual variability. In reality, RTS should not be reduced to merely satisfying a set of standardized functional criteria or achieving a certain score on performance-based assessments. The athlete is a complex, dynamic, and adaptive system. This complexity manifests not only within neuromuscular and musculoskeletal systems but also through multilayered interactions between individuals, organizations, sociocultural contexts, and environmental factors. 12 Variations in psychological readiness, physiological baselines, cognitive behaviors, and emotional regulation further challenge the applicability of one-size-fits-all RTS criteria. 2 Consequently, single-dimensional assessment strategies may be insufficient to comprehensively evaluate an athlete's readiness to safely return to sport.
In recent years, with growing interest in the complex interactions among multidimensional athlete-specific data, such as physiological, biomechanical, and psychological variables, machine learning (ML) techniques have been increasingly applied across various domains of sports medicine. These include medical image recognition,3,13 sports injury prediction,14,15 and decision support for RTS planning. 2 The occurrence of sports injuries and the subsequent recovery process leading to RTS represent a highly dynamic, open-ended, and nonlinear trajectory, encompassing psychophysiological healing, functional assessments, psychological adaptation, and environmental influences.2,12 Traditional statistical methods often struggle to manage such high-dimensional, multivariate, and interactive data structures. In contrast, ML offers promising advantages in modeling complex nonlinear relationships and extracting latent patterns, 14 positioning it as a potentially powerful tool in RTS decision-making.
Despite the growing interest in applying ML for RTS prediction, the current body of literature remains fragmented, and a comprehensive synthesis of its application landscape is lacking. Specifically, it remains unclear which types of ML models have been employed, how they perform across various RTS prediction tasks, and whether their interpretability and clinical usability are comparable. In the context of increasingly accessible, large-scale, and multisource datasets, systematically reviewing the modeling strategies, performance evaluation methods, and explainability techniques used in ML-based RTS prediction is essential. Such an effort could facilitate the development of more individualized, data-driven RTS decision frameworks.
Accordingly, this systematic review aims to examine and synthesize the existing literature on the application of ML techniques in predicting RTS outcomes among athletes. The specific objectives of this study are to:
Summarize the modeling strategies and ML algorithms used in RTS prediction tasks; Evaluate the performance characteristics and explainability approaches of different ML models within this context.
Methods
Study design
This systematic review was conducted in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. 16 The review protocol was prospectively registered in PROSPERO (Registration ID: CRD420251090967).
Search strategy
A comprehensive literature search was performed in May 2025 across three electronic bibliographic databases: PubMed, Web of Science, and SPORTDiscus (EBSCO). The search strategy combined the following terms: (“return to sports” OR “return to play”) AND (“machine learning” R “transfer learning”) AND (“athletic injuries” OR “sports injuries”). The complete search syntax is provided in Supplemental material 1.
Inclusion and exclusion criteria
The inclusion and exclusion criteria for this systematic review were established as follows. Studies were eligible for inclusion if they met the following conditions: (1) the population of interest comprised athletes or physically active individuals, including both professional athletes and recreational sports participants; (2) the primary focus of the study was the prediction of RTS following sports-related injuries, where RTS is considered a continuum encompassing return to participation, return to sport, and return to performance 17 ; (3) the study employed ML methodologies for modeling or predictive analysis; (4) the predicted outcomes were directly related to RTS, including but not limited to whether RTS occurred, the time required for RTS, or the level of RTS achieved (e.g. competition load and playing time); (5) only original research studies were included, such as retrospective or prospective cohort studies, case-control studies, data-mining analyses, or modeling studies; (6) studies were required to be published in full-text format and appear in peer-reviewed academic journals; and (7) to ensure recency and methodological relevance, only studies published between 2015 and 2025 were included. Studies were excluded if they did not primarily focus on RTS prediction (e.g. those limited to describing treatment approaches, investigating postinjury psychological status, or examining injury risk factors); if they did not utilize ML techniques for modeling or prediction; if the predictive targets were unrelated to injury-based RTS (e.g. studies predicting training outcomes or athletic performance without injury context); or if they were review articles, commentaries, conference abstracts, or opinion pieces. Additionally, studies involving nonathlete populations, those focusing solely on injury diagnosis or risk scoring without addressing RTS, and articles unavailable in full text were excluded.
Study selection and data collection process
After removing duplicates, two reviewers (JY and QZ) independently screened the titles, abstracts, and full texts for eligibility. Studies were included or excluded only upon consensus between the two reviewers. In cases of disagreement, a third reviewer (YZ) was consulted to reach a final decision through discussion. Reference lists of the included studies were also manually searched to identify additional eligible studies. These records were evaluated according to predefined inclusion and exclusion criteria. Studies that met all inclusion criteria and did not meet any exclusion criteria were included in this review.
Data extraction
Data from each included study were independently extracted by two reviewers (JY and QZ). Any discrepancies were resolved through discussion or adjudication by a third reviewer (YZ). Extracted data included study design, participant characteristics and background, the specific definition and type of RTS, details of the ML methodology, RTS-related prediction outcomes, model performance metrics, and model interpretability.
Risk of bias and applicability assessment
The risk of bias in the included prediction models was systematically assessed using the Prediction model Risk Of Bias ASsessment Tool (PROBAST). 18 PROBAST is specifically designed for evaluating the risk of bias and applicability of diagnostic and prognostic multivariable prediction model studies. Two reviewers (JY and QWZ) independently assessed each study across four domains: participants, predictors, outcome, and analysis. Each domain was rated as having low, high, or unclear risk of bias and applicability concerns. Disagreements were resolved through discussion and consensus with a third reviewer (YZ). Applicability was assessed based on the relevance of study participants, predictors, and outcomes to the review question.
Results
The search strategy and screening process are illustrated in Figure 1. A systematic search was conducted across three electronic databases: Web of Science, PubMed, and SPORTDiscus, yielding an initial total of 56 potentially relevant studies. After removing 6 duplicates, 50 articles remained for title and abstract screening. Of these, 27 articles were deemed eligible based on the inclusion criteria. Independent screening results were then merged, and any discrepancies were resolved through discussion among the authors (JY, YZ, and QZ). Ultimately, 11 studies were included in the final analysis.

PRISMA flow diagram.
Study quality
Among the included studies, four were rated as having an overall low risk of bias, four as unclear, and three as high risk (see Figures 2 and 3). The primary sources of bias were concentrated in the analysis domain. Specific issues included insufficient sample sizes in some studies and inadequate handling and reporting of missing data during model development. In terms of applicability assessment, six studies were rated as having low concern, four as unclear, and one as high concern. The main applicability issue stemmed from the limited relevance of the predicted outcomes to RTS decisions, thereby reducing the practical utility of the study findings in real-world RTS contexts. (The full PROBAST checklist is provided in Supplemental material 2.)

Risk of bias and applicability assessment.

Summary of risk of bias and applicability assessment within the study.
Sporting contexts and participant characteristics
Table 1 summarizes the fundamental characteristics of the 11 included studies. The majority employed a retrospective cohort design (n = 6, 55%),19–24 followed by prospective cohort studies (n = 3),25–27 as well as one case-control study 28 and one cross-sectional study. 29 Regarding the type of sports involved, five studies specifically focused on contact sports,19,20,22,24,26 while two included both contact and noncontact sports.25,27 The remaining four studies did not explicitly report information related to contact nature. The sports represented included football, American football, basketball, and track and field, among others. Four studies covered multiple sport disciplines, whereas five did not specify the type of sport involved. Sample sizes varied considerably, ranging from 32 to 1611 participants. Most studies (n = 9, 82%) reported participant age characteristics, with mean ages ranging from 15.0 ± 2.4 years (adolescent populations) to 30.0 ± 9.3 years (adult populations). The types of athletic injuries studied were diverse, with knee-related injuries being the most frequently reported (n = 4),21–23,28 followed by sport-related concussion (SRC) (n = 2).19,25 Other injury types included Achilles tendon rupture (ATR), 20 HSI, 27 general muscle injuries, 26 shoulder instability, 29 and mild traumatic brain injury (mTBI). 24 Follow-up periods for the prospective studies ranged from 12 to 24 months, while three of the retrospective studies did not clearly report follow-up durations. All studies performed predictive modeling related to the results of RTS, which were classified into three categories: (1) time-based results, such as the resolution time of symptoms or days of RTS19,26,27; (2) status-based outcomes, including readiness for RTS, reinjury occurrence, or game absence21–25,28; (3) performance-level outcomes,20,29 such as return to the performance level prior to injury or achievement of a functional threshold reported by the patient. To provide a clearer comparison of study characteristics and RTS outcomes, Table 1 also summarizes the outcome classification, type of RTS criteria, and assessment tools for all included studies.
Study characteristics and RTS criteria.

ACL: anterior cruciate ligament; ACLR: anterior cruciate ligament reconstruction; ACL-RSI: ACL-return to sport after injury; ATR: Achilles tendon rupture; BAMIC: British athletic muscle injury classification; HSI: hamstring strain injury; IKDC: international knee documentation committee; KOOS: knee injury and osteoarthritis outcome score; MRI: magnetic resonance imaging; mTBI: mild traumatic brain injury; NR: not reported; ROM: range of motion; RTS: return to sport; SAS: sport anxiety scale; SRC: sport-related concussion; SRPAS: successful recovery of patient acceptable symptom state.
Data analysis characteristics
Among the included studies, the majority (n = 7, 64%) relied on clinically recorded data by healthcare professionals, such as club medical staff or athletic trainers.19,21,23–27 The remaining studies utilized publicly available datasets (n = 2)20,28 or athlete self-reported data (n = 2).22,29 Despite considerable heterogeneity in the selection of predictor variables across studies, several common categories were identified. Demographic characteristics (e.g. age, sex, and body mass index (BMI)) were collected in most studies (n = 9). Injury- and rehabilitation-related factors (e.g. injury location, severity, and treatment methods) were included in five studies.20,26–29 Clinical assessments and symptom measures (e.g. SCAT scores, balance tests, and muscle strength evaluations) were present in seven studies. Three studies incorporated psychological factors or self-perception scales (e.g. SIRSI (shoulder instability return to sport after injury), KOOS (knee injury and osteoarthritis outcome score), sport-related anxiety scores) as predictors.22,28,29 Additionally, two studies utilized radiomic features derived from magnetic resonance imaging (MRI) sequences, such as structural attributes or manually annotated muscle injury regions.24,27
Regarding data preprocessing, approximately 45% of the studies (n = 5) did not report specific strategies. Approaches to handling missing data varied and included multiple imputation (n = 2),23,28 random forest-based imputation (missForest, n = 1), 24 spline interpolation with backward filling (n = 1) 20 and listwise deletion (n = 1). 21 Two studies applied Z-score normalization to standardize the distribution of continuous variables across different measurement scales,27,29 while one study employed min–max normalization. 22 Only four studies explicitly reported feature selection methods, including forward selection, 20 random forest-based feature importance ranking, 28 logistic regression-based filtering, 27 and a combined univariate-multivariate statistical approach. 25 The remaining seven studies (64%) did not specify their feature selection strategies.
Cross-validation was the most commonly used model training approach. Ten-fold cross-validation was applied in four studies,19,20,27,28 and five-fold cross-validation was used in three studies.21,23,26 Two studies with relatively small sample sizes adopted leave-one-out cross-validation (LOOCV).25,29 In addition, two studies used random or repeated random splits for model validation.22,24 Notably, only one study addressed the issue of class imbalance by applying the Synthetic Minority Oversampling Technique (SMOTE), a method designed to mitigate data imbalance and improve model training stability. 29 A structured overview of analytical characteristics is presented in Table 2.
Data analysis characteristics.
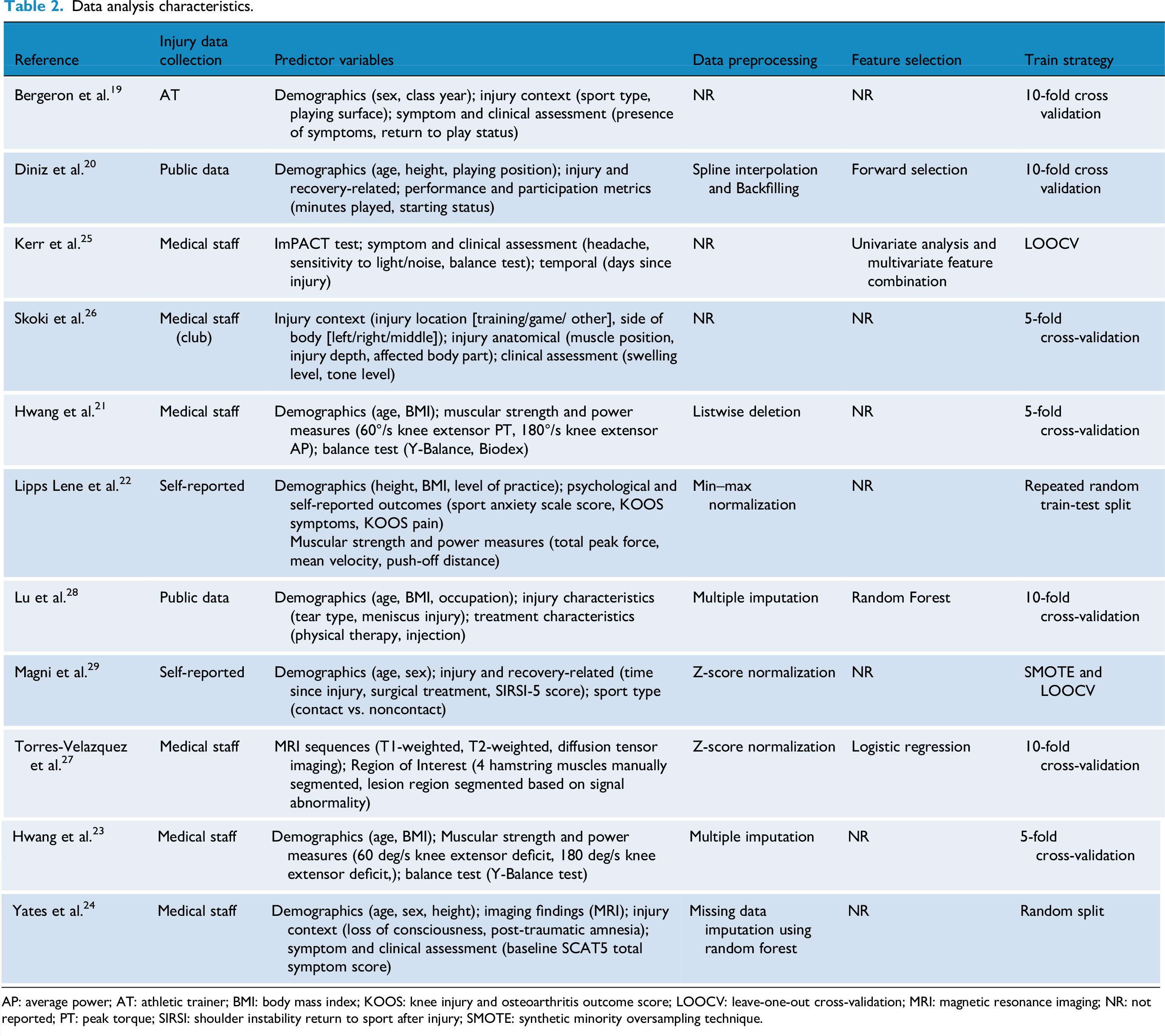
AP: average power; AT: athletic trainer; BMI: body mass index; KOOS: knee injury and osteoarthritis outcome score; LOOCV: leave-one-out cross-validation; MRI: magnetic resonance imaging; NR: not reported; PT: peak torque; SIRSI: shoulder instability return to sport after injury; SMOTE: synthetic minority oversampling technique.
Study results characteristics
Commonly used machine learning models
Among the 11 included studies, Random Forest (RF) was the most frequently used algorithm, applied in 6 studies (55%),19,21,23,24,28,29 with 2 studies utilizing it as the sole modeling method.24,28 Support Vector Machine (SVM) was employed in 5 studies,19,21,23,28,29 valued for its strong classification performance in high-dimensional feature spaces, which remains advantageous in clinical predictive modeling. Logistic Regression (LR), despite its limited modeling capacity as a traditional linear classifier, was used in 6 studies19,21,23,26,28,29 due to its interpretability and role as a benchmark model. Other commonly applied algorithms included XGBoost (n = 4),20,22,26,28 Decision Tree (DT) (n = 4),21–23,26 and Multilayer Perceptron (MLP) (n = 3).19,22,29 Less frequently used algorithms comprised Fisher Discriminant Analysis (FDA), 25 k-Nearest Neighbors (KNN), 29 and Radial Basis Function Network (RBFN) 19 (see Table 3).
Study results characteristics.

ACL: anterior cruciate ligament; AUC: area under the receiver operating characteristic curve; DT: decision tree; LR: logistic regression; MAPE: mean absolute percentage error; ML: machine learning; MLP: multilayer perceptron; NB: naïve Bayes; NR: not reported; RF: random forest; RSI: return to sport after injury; SVM: support vector machine; XGBoost: extreme gradient boosting.
Top-performing machine learning models
RF and XGBoost emerged as the top-performing models in the greatest number of studies, being identified as the best-performing algorithms in 419,21,23,24 and 3 studies,20,26,28 respectively. Notably, the RF-based model developed by Yates et al. 24 achieved the highest area under the receiver operating characteristic curve (AUC; 0.96) reported in this review for predicting whether athletes with mTBI would miss more than five games postinjury, demonstrating exceptional discriminatory power. Additionally, Torres-Velazquez et al. 27 applied Support Vector Classifier (SVC) to both binary and multiclass classification tasks predicting rehabilitation duration following hamstring strain injury, achieving AUCs of 0.95 and 0.81, respectively, highlighting its robustness across different outcome types. Hwang et al. 21 constructed predictive models for multiple RTS-related outcomes (e.g. single-leg hop test and Tegner activity score), with RF models achieving or approaching AUC values of 0.95, further validating the consistent performance and wide applicability of tree-based models in multioutput settings. Overall, 7 studies (64%) identified tree-based models (including RF and XGBoost) as the top-performing approach, underscoring the strong capability of ensemble learning methods to capture complex, nonlinear relationships, and to generalize effectively in the context of sports injury prediction. These findings suggest that ensemble learning remains one of the most promising strategies for constructing models related to RTS outcomes (see Table 3).
Model evaluation methods
Among the 11 included studies, researchers employed a wide array of performance metrics to evaluate the effectiveness and robustness of ML models in predicting RTS among athletes. The most commonly reported metric was the ROC AUC, presented in 9 studies (82%). Reported AUC values ranged from 0.57 to 0.96, reflecting substantial variability in model architecture, feature selection strategies, and data quality (see Table 3). According to established classification criteria, AUC values between 0.50 and 0.69 indicate poor discriminatory ability, 0.70-0.79 as fair, 0.80-0.89 as good, and values ≥0.90 as excellent performance. 30 In this review, studies reported AUC values below 0.70, indicating poor performance22,28; one study fell within the fair range 19 ; four studies demonstrated good discrimination20,23,25,27; and two studies achieved excellent performance.21,24 These findings suggest that some models possess strong discriminatory power for identifying high-risk athletes, especially when tailored to specific data structures and prediction tasks.
In addition to AUC, several studies reported complementary performance indicators to capture dimensions beyond pure discrimination. Sensitivity was the most frequently used secondary metric, reported in four studies,22,24,25,29 with values ranging from 0.24 to 1.00 and a mean of 0.61. Notably, the RF-based model developed by Yates et al. 24 achieved a sensitivity of 1.00, indicating perfect identification of positive cases. In contrast, the model by Lipps Lene et al. 22 demonstrated a sensitivity of only 0.24 in the absence of psychological variables, underscoring the critical influence of feature composition on predictive performance. Specificity was reported in three studies,24,25,29 ranging from 0.76 to 0.94 (mean = 0.86), suggesting good ability to correctly identify nonrisk individuals. Accuracy was reported in two studies,22,29 with an average of 0.72. Furthermore, the Brier Score which a composite metric quantifying the mean squared error between predicted probabilities and actual outcomes was used in two studies,20,28 yielding values of 0.12 and 0.07-0.08, respectively. These relatively low scores indicate well-calibrated probability estimates that closely approximate observed results.
Model interpretability
Of the 11 studies reviewed, 8 explicitly reported methods for assessing feature importance, reflecting a growing emphasis on model interpretability in the field of sports injury prediction (see Table 3). Common approaches included ranking-based methods such as information gain, chi-square test, and gain ratio 19 ; model-agnostic techniques like permutation importance21,23; and SHapley Additive exPlanations (SHAP) values,21–23 a game-theoretic approach to quantifying the marginal contribution of each feature to the model's output. Some studies integrated multiple interpretability techniques to enhance robustness and clinical relevance. For example, Hwang et al. 21 employed both SHAP and permutation methods to evaluate the contribution of features in various RTS-related outcomes (e.g. IKDC (international knee documentation committee) PASS, Tegner activity score). Lu et al. 28 combined global variable importance with partial dependency plots to illustrate nonlinear relationships between predictors and outcomes, thus strengthening clinical interpretability. Additionally, Magni et al. 29 utilized the signal-to-noise ratio (SNR) for feature evaluation, offering an alternative perspective on variable selection strategies. In general, these interpretability approaches facilitated the identification of key predictors of RTS, including the duration of symptoms, the location of the anatomical injury, muscle strength metrics, balance performance, and psychological factors. Such insights enhance the clinical utility of predictive models and inform targeted interventions. However, three studies did not provide a clear description of their methods to evaluate the importance of characteristics.24–26
Discussion
Among the 11 included studies, the RF algorithm emerged as the most frequently employed model, appearing in 55% of the studies, reflecting its widespread recognition and practical value in the domain of RTS prediction following athletic injury. The AUC was the most commonly reported performance metric, with 9 studies (82%) providing AUC values. As a result, AUC serves as a crucial benchmark for cross-study comparison of predictive model performance within this field. Notably, the highest reported AUC value across all included studies was 0.96 for an RF model, underscoring RF's strong empirical performance in this domain.
This observed advantage is not merely empirical but can be theoretically grounded in several algorithmic strengths of the RF framework, which make it particularly suitable for RTS-related data. The consistent superiority of RF can be explained by several methodological advantages that align closely with the structure of RTS-related datasets. RF inherently accommodates heterogeneous data types—continuous, ordinal, and categorical variables—such as demographic characteristics, clinical indicators, psychometric measures, and imaging-derived metrics. Unlike many parametric models, it imposes minimal distributional assumptions, which reduces the need for intensive preprocessing or encoding transformations. 31 Another important strength of RF lies in its robustness to outliers and missing data. RF-based imputation algorithms such as missForest have demonstrated superior performance compared to conventional approaches, particularly in datasets containing mixed variable types and nonlinear associations. 32 This property helps preserve statistical efficiency and mitigates bias that often results from listwise deletion or naïve imputations, an issue that is common in sports injury datasets with limited sample sizes. As an ensemble learning approach, RF aggregates a large number of decorrelated decision trees to generate a stable and generalizable prediction. This ensemble mechanism reduces variance, enhances predictive reliability, and enables the model to capture complex, nonlinear interactions among predictors. 33 Such characteristics are especially beneficial for RTS prediction, where recovery outcomes are influenced by interacting biomechanical, physiological, and psychosocial factors. In addition, RF models can implicitly detect higher-order feature interactions through their hierarchical tree structures and provide interpretable outputs such as variable importance rankings and partial dependence plots. These features make it possible to identify synergistic relationships—such as between neuromuscular function and psychological readiness—that are often difficult to specify a priori in parametric models. 31 Together, these methodological characteristics explain why RF consistently outperformed other models in the reviewed studies, achieving AUCs as high as 0.96 and demonstrating strong suitability for complex, multifactorial prediction tasks in sports injury research.
This review also revealed substantial heterogeneity in feature selection across the included studies. Such heterogeneity in variable composition complicates cross-study comparison and may limit the generalizability and clinical applicability of predictive models. Most models primarily relied on demographic and physiological-functional variables. For instance, Hwang et al. 21 used isokinetic knee extension strength and Y-Balance test metrics in ACL injury prediction models. Similarly, Bergeron et al.19,23 and Diniz et al. 20 incorporated athlete exposure data (e.g. minutes played and starting status) and demographic characteristics (e.g. age, sex, and height) into their model inputs. Skoki et al. 26 further extended feature construction by incorporating injury context (e.g. training vs. competition) and clinical indicators of soft tissue status (e.g. swelling grade and tension level), thereby enriching the models with injury-site-specific and experiential clinical information. Although prior studies have highlighted the significance of psychological factors in RTS decision-making,34–37 only a minority (18%) of the included studies incorporated psychological variables. For example, Lipps Lene et al. 22 introduced athletic anxiety scores, KOOS symptom and pain subscales, and self-reported functional ratings, and found that including psychological factors improved model performance (AUC increased from 0.57 to 0.60; precision from 0.46 to 0.51; sensitivity from 0.24 to 0.31), supporting the importance of psychological readiness in RTS prediction. Similarly, Magni et al. 29 used the SIRSI-5 questionnaire as a psychosocial indicator to capture athletes perceived recovery. Nonetheless, the limited number of studies that included psychological features, along with inconsistencies in variable types, measurement tools, and standardization, restrict the generalizability and cross-study comparability of these factors.
Another methodological source of variability that affects both model development and cross-study comparability lies in the substantial heterogeneity of sample sizes among the included studies, ranging from as few as 32 to as many as 1611 participants. Such disparities have important implications for model development and evaluation. Models trained on small datasets are particularly vulnerable to overfitting, as they tend to capture idiosyncratic or study-specific patterns rather than generalizable relationships. This often results in inflated performance metrics (e.g. accuracy or AUC) that fail to replicate in independent cohorts, thereby undermining external validity. In contrast, larger samples provide greater data diversity and more robust representation of interindividual variability, facilitating more stable model training and reliable validation. Consequently, the imbalance in sample sizes across studies complicates cross-study comparisons of predictive accuracy and likely contributes to the heterogeneity in model performance observed in this review. Empirical evidence further supports this interpretation. Increasing sample size has been shown to enhance classification accuracy and reduce variability in effect size estimation across datasets, thereby improving model generalizability. 38 Conversely, studies based on small samples are prone to report overly optimistic results that fail to replicate in larger, independent cohorts. For instance, in neuroimaging-based prediction research, models trained on limited samples (e.g. N ≈ 20) often achieved unrealistically high accuracies that substantially decreased when evaluated on more representative datasets. 39 Similarly, methodological analyses have demonstrated that cross-validation applied to very small datasets produces wide confidence intervals for performance estimates, undermining the stability and reliability of model evaluation. 40 Collectively, these findings underscore that sample size heterogeneity is not a trivial methodological issue but a critical determinant of model credibility and cross-study comparability. In addition to sample size variability, considerable heterogeneity in the operational definitions of RTS outcomes further complicates model evaluation and cross-study comparability. Definitions of RTS spanned multiple dimensions: symptom resolution (e.g. duration of concussion symptoms in Bergeron et al. 19 ), functional status (e.g. “readiness to return” in Kerr et al. 25 ), competitive level (e.g. return to elite competition in Diniz et al. 20 and Magni et al. 29 ), participation status (e.g. absence from five or more games in Yates et al. 24 ), rehabilitation duration (e.g. Skoki et al. 26 and Torres-Velazquez et al. 27 ), and combined objective-subjective criteria (e.g. PASS standards used by Hwang et al.21,23).
Among all included studies, two demonstrated excellent performance (AUC > 0.90). Yates et al. 24 developed a model to predict whether an athlete with mTBI would miss more than five games. This model achieved an AUC of 0.96, supported by a clearly defined outcome, high feature–outcome correlation, and the use of structured neurobehavioral data, thereby reducing model complexity. However, the relative simplicity of this task—despite its practical relevance may limit its ability to capture the full complexity of clinical RTS decision making. Similarly, Hwang et al. 21 constructed a model to predict whether patients following ACL reconstruction would achieve RTS goals at 12 months based on functional assessments at 3 months (e.g. single-leg hop, Y-Balance, muscle strength recovery), achieving an AUC of 0.95. The model's strong performance may be attributed to two factors: (1) the inclusion of structured, RTS-relevant functional variables that have been widely validated in rehabilitation settings and (2) the use of well-defined RTS criteria, such as recovery of the Tegner activity score, minimizing the risk of outcome label ambiguity. However, this highly standardized modeling framework may face limitations in real-world applications, where variability in rehabilitation trajectories, sport-specific demands, and psychosocial factors may compromise its generalizability. A further study by Hwang et al. 23 employed PASS thresholds from the IKDC and ACL-RSI scales as RTS outcome criteria, constructing models based on postoperative functional data. The resulting Gradient Boosting and RF models yielded AUC values between 0.835 and 0.844, indicating good predictive performance. Despite efforts to integrate subjective symptom perception and psychological readiness, the inclusion of these dimensions introduced added complexity and challenges in outcome standardization, potentially limiting cross-study comparability and interpretive clarity. It is therefore important to emphasize that reported model performance should not be interpreted solely as a reflection of the intrinsic superiority of specific ML algorithms. Model performance is shaped by multiple interacting factors, including the quality of feature selection, outcome definition, sample representativeness, and methodological rigor.15,41,42 The high AUC values observed in several studies may largely result from the use of well-defined and clearly dichotomized outcome variables. However, such “idealized” evaluation scenarios may obscure the limitations of these models when applied in complex, real-world clinical environments.
Despite the promising predictive performance reported in some studies, model interpretability remains a major bottleneck hindering the clinical translation of ML algorithms in RTS decision making. When the internal mechanisms of ML models are opaque or difficult for clinical experts to understand and validate, their practical utility in real-world decision making is substantially diminished. Approximately 73% of the reviewed studies explicitly reported using some form of interpretability method, although the depth and sophistication of these approaches varied considerably. Early studies on interpretability primarily focused on feature selection strategies. For example, Bergeron et al. 19 employed statistical methods such as chi-square testing, information gain, and gain ratio to assess the relevance of individual features to RTS outcomes. Similarly, Diniz et al. 20 used forward selection to sequentially incorporate features based on their incremental contribution to model performance. While these methods can enhance training efficiency to some extent, they fall short of providing a comprehensive understanding of the model's decision-making process and fail to capture complex feature interactions or their joint influence on predictions. In contrast, the recent development of explainable ML (XML) tools has substantially mitigated the “black box” nature of ML models. 43 Several studies, including those by Hwang et al.21,23 and Lipps Lene et al., 22 incorporated SHAP to enhance model transparency.44,45 SHAP, grounded in cooperative game theory, quantifies the marginal contribution of each feature to a specific prediction and supports both global feature importance ranking and local, individual-level interpretability. This capability offers clinicians a more intuitive framework for understanding model outputs, thereby enhancing trust and likelihood of adoption. It is important to note that SHAP provides insights into statistical associations rather than causal relationships. Therefore, its outputs should not be interpreted as causal inferences. Nonetheless, in clinical decision making, SHAP-based explanations retain substantial value. On the one hand, they help clinicians identify the most influential factors driving individual predictions; on the other hand, they facilitate the identification of modifiable intervention targets, thereby informing tailored rehabilitation strategies. This is particularly relevant in RTS contexts, where decisions are influenced by multifactorial and highly interactive elements. SHAP provides a structured pathway to trace contributing variables, offering a promising avenue for practical implementation.46,47
Although current research has demonstrated the potential of SHAP to enhance model transparency, a major translational gap remains: how to convert interpretability outputs into actionable clinical guidance for RTS decision making. Several directions may help bridge this gap. First, integrating SHAP-derived importance values into existing RTS assessment frameworks could lead to hybrid, data-informed decision-support tools. By mapping key predictive variables to conventional RTS risk stratification systems, researchers can identify modifiable bio-psycho-social factor clusters that guide structured, evidence-based interventions.17,48 Second, interpretability methods can facilitate individualized RTS planning. Instead of relying solely on population-level probabilities, patient-specific SHAP profiles can highlight dominant risk drivers—such as psychological fear versus neuromuscular imbalance—allowing clinicians to tailor interventions accordingly (e.g. psychological counseling vs. targeted physical rehabilitation). 49 Finally, dynamic interpretability approaches, such as WindowSHAP, could enable time-resolved monitoring of predictor importance throughout rehabilitation. By tracking temporal changes in key features, clinicians may identify high-risk recovery phases and adjust treatment intensity or focus accordingly, forming a closed-loop, adaptive management model for RTS. 50 Collectively, these strategies provide a feasible pathway for transforming interpretability insights into clinically actionable tools, thereby narrowing the gap between ML research and its practical implementation in sports medicine.
Limitations
Despite the implementation of rigorous inclusion and exclusion criteria, there remains considerable heterogeneity across studies in the definition and determination of RTS outcomes, which introduces variability in both the statistical synthesis and interpretability of results. Substantial methodological differences exist among the included studies regarding the types of ML algorithms employed, hyperparameter tuning strategies, feature engineering approaches, and data preprocessing procedures. These discrepancies further undermine the comparability of model performance metrics. Moreover, several studies were constrained by relatively small sample sizes or potential selection bias, which may weaken model generalizability and external validity. Another critical limitation lies in the insufficient integration of psychological variables within RTS prediction models. Although the biopsychosocial model underscores that psychological readiness—such as fear of reinjury, motivation, and confidence—plays a decisive role in determining successful return to sport, only a small proportion of the included studies (18%) incorporated such variables into their predictive frameworks. This omission not only restricts the models’ ability to capture the full complexity of recovery processes but also reduces their applicability in real-world rehabilitation decision making. Future research should therefore prioritize the inclusion of validated psychological assessments alongside physiological and biomechanical indicators to achieve a more holistic and ecologically valid prediction of RTS outcomes. Finally, most included studies employed static modeling approaches without longitudinal tracking or adaptive feature updating, thereby limiting real-time adaptability in dynamic clinical contexts. It is also important to note that RTS represents a progressive continuum—from “return to participation” to “return to performance”—rather than a single endpoint. Given the limited number of ML-based studies available, this review did not restrict specific RTS phases, which may have introduced further variability and affected the consistency and interpretability of findings.
Conclusion
This systematic review analyzed current ML-based studies aimed at predicting RTS in athletes. Although some models demonstrated high predictive performance, substantial heterogeneity in RTS outcome definitions, feature selection, and study designs limits the utility of model performance as the sole criterion for evaluating algorithm quality. Notably, limited model interpretability and barriers to clinical application remain significant challenges. In the context of the complex and multidimensional RTS process, reliance on singular functional or subjective indicators is insufficient to comprehensively capture an athlete's recovery status. Future research should focus on developing a standardized and multidimensional RTS decision-making framework that integrates physiological, psychological, and behavioral indicators to enhance ecological validity and model generalizability. Additionally, improving model interpretability is critical to facilitating the translation of ML algorithms into clinically actionable tools that support individualized and dynamic rehabilitation management.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251408523 - Supplemental material for From injury to comeback: A systematic review of machine learning models predicting return to sport in athletes
Supplemental material, sj-docx-1-dhj-10.1177_20552076251408523 for From injury to comeback: A systematic review of machine learning models predicting return to sport in athletes by Jin Yuan, Zhuojia Li, Quanwen Zeng, Jun Li, Anjie Wang, Yong Zhang and Fei Xu in DIGITAL HEALTH
Supplemental Material
sj-xlsx-2-dhj-10.1177_20552076251408523 - Supplemental material for From injury to comeback: A systematic review of machine learning models predicting return to sport in athletes
Supplemental material, sj-xlsx-2-dhj-10.1177_20552076251408523 for From injury to comeback: A systematic review of machine learning models predicting return to sport in athletes by Jin Yuan, Zhuojia Li, Quanwen Zeng, Jun Li, Anjie Wang, Yong Zhang and Fei Xu in DIGITAL HEALTH
Supplemental Material
sj-docx-3-dhj-10.1177_20552076251408523 - Supplemental material for From injury to comeback: A systematic review of machine learning models predicting return to sport in athletes
Supplemental material, sj-docx-3-dhj-10.1177_20552076251408523 for From injury to comeback: A systematic review of machine learning models predicting return to sport in athletes by Jin Yuan, Zhuojia Li, Quanwen Zeng, Jun Li, Anjie Wang, Yong Zhang and Fei Xu in DIGITAL HEALTH
Footnotes
Acknowledgements
The authors would like to gratefully acknowledge all those who helped us during the writing of this manuscript.
Ethical approval
Ethical approval was not required for this study.
Consent for publication
Not applicable.
Contributorship
JY and YZ were involved in conceptualization; JY in methodology; YZ and FX in funding acquisition and project administration; JY, QZ, and YZ in database search and risk of bias assessment; JY and ZL in data extraction; JY and JL in data analysis; JL and AW in supervision; and YZ, JY, ZL, FX, and AW writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
The authors declare that financial support was received for the research, authorship, and/or publication of this article: The authors acknowledge the support from the following funding: Key Project of Humanities and Social Sciences in Anhui Province Universities (2024AH052247); The Fundamental Research Funds for the Central Universities: The Generative Logic and Action Path of Digital Technology Empowering Youth Sports Participation (HIT.HSS.202314); The Basic Research Fund for Provincial Universities of Heilongjiang Province: An Experimental Study on Health Qigong Rehabilitation Prescriptions for Chronic Low Back Pain (2020KYYWF-FC13). Major Project of Philosophy and Social Sciences in Anhui Province Universities (2023AH040116); Outstanding Research Team of Universities under Anhui Provincial Department of Education—“Cognitive Neuroscience Innovation Team” (2022AH010060).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantor
Fei Xu
Availability of data
All data generated or analyzed during this study are included in this manuscript and Supplemental materials.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.