
Abstract
Background
Machine learning (ML) and artificial intelligence (AI) applications have increased across different stages of clinical research. Their use in clinical trials (CTs) has been discussed but not quantified.
Methods
A scoping review was conducted by searching PubMed, Embase (Ovid), and Scopus for CTs or protocols. The goal was to understand the extent of ML and AI applications in the design, conduct, and analysis of CTs. Screening was performed on Covidence, with GPT model support.
Findings
After title/abstract and full-text screening, 108 records were included; in some studies, AI/ML was applied across multiple stages. For the design, 20 studies involved advanced methods, six applied them to stratification, four to treatment selection during randomization, six to participant selection, two for outcome assessment, and two for site selection. Seven studies involved them in the collection and analysis of data from wearable devices, and one for monitoring. More commonly, AI/ML has been used at the analysis stage of 93 CTs; however, limitations in reporting trial objectives make it difficult to distinguish the purpose between primary and exploratory analyses.
Interpretation
This research identifies a serious mismatch between the potential and actual applications of ML in CTs. Considering the potential benefits of ML in CTs, such underuse could hinder the evolution of CTs toward faster and more efficient approaches.
Keywords
Introduction
Machine learning (ML) and artificial intelligence (AI) methods are gaining popularity across many sectors, including clinical research, 1 with numerous opportunities already identified in the literature. 2 They can reshape clinical settings, reduce complexity, lower risk of failure, and improve success and efficiency across all stages of clinical trials (CTs). 1 However, less is known about their current usage in these contexts; therefore, this review aims to identify the most common applications of these digital technologies and explore how they are implemented to provide insights for regulatory agencies and organizations planning to adopt them.
In the discussion paper “Using Artificial Intelligence & Machine Learning in the Development of Drug & Biological Products,” the US Food and Drug Administration (FDA) discusses the current and potential applications of AI and ML for interventional and non-interventional studies including aspects such as participants recruitment and selection for population enrichment, participant stratification, dose optimization, monitoring to improve adherence and retention, site selection, continuous data collection with devices, data management, analysis and real-time clinical endpoint assessment. 3
Similarly, the European Medicines Agency (EMA) and the European Medicines regulatory network published a “Draft reflection paper on the use of Artificial Intelligence (AI) in the medicinal product lifecycle” in December 2023, specifying that AI usage should be documented in the protocol along with their risk-benefit assessment following the ICH E6 guidelines and that the statistical analysis plan (SAP) must detail data handling and safety concerns. 4 National agencies, such as the Italian Medicines Agency's (AIFA) Clinical Trials Office, have raised concerns about reliability, transparency, and security, particularly in the case of non-fully validated algorithms. 5
Few reviews have examined AI-assisted tools in interventional 6 or non-interventional trials, 7 yet the growing interest has fueled discussions on their integration to improve the operational management, design, and conduct of CTs. A recent protocol aimed to review AI tools designed to optimize recruitment and retention, 8 which were previously identified as key areas of interest. 2 For example, wearables allow continuous monitoring to identify dropout risk and predict events, enabling personalized interventions. 2
AI-assisted procedures and ML-guided interventions have been explored for treatment selection and allocation, guided by reinforcement learning, 9 and predictive modeling of responses or optimal doses. 10 Advances have been made in patient-to-trial matching informed by real-world data, large language models (LLMs), 11 and in supporting prescreening and screening procedures with natural language processing (NLP); although these do not directly affect the design, they contribute to earlier planning phases. 12
Some reviews have described how high-dimensional data from wearable devices can inform trial design. 6 However, systematic evidence on AI/ML use for trial design, conduct, and analysis remains limited.1,13 It is important to determine whether these methods have real applicability or if current interest is merely speculative.
The aim of this scoping review is to summarize the current AI and ML usage in CTs. We describe the frequency of usage, field of application, model type, and clinical area. By examining current applications, we assess whether these methods are impactful, with practical rather than theoretical benefits. Of special interest are: (1) Design, that involves patient selection and cohort composition (screening, matching to the trial), predictive modeling for stratification (optimal treatment allocation, automatic recruitment, cohort composition and biomarker identification for risk stratification); (2) Conduct, which regards activities after the start of the trial, with monitoring via devices to collect passive data aimed at increasing adherence, retention, safety, and at reducing adverse events; and (3) Analysis, for the primary or secondary/exploratory endpoints, if included in the main paper or study protocol, covering complex modeling, imaging analysis, feature selection, and outcome prediction. AI-assisted procedures and ML-guided interventions themselves are beyond the scope of this review.
Methods
Protocol and registration
The protocol was drafted following the PRISMA Extension for Scoping Reviews (PRISMA-ScR), 14 available in Supplementary Table S1, and it was registered on the Open Science Framework (OSF) on October 16, 2024 (registration link: https://osf.io/8qb5n). 15
Eligibility criteria
For this review, peer-reviewed papers published without time restrictions up to February 28, 2025, written in English, were considered. They had to refer to CTs or protocols conducted in humans, regardless of intervention type. To be selected, studies had to implement AI/ML methods in the design, conduct, or main analysis of the trial. Papers were excluded if they concerned non-interventional studies, such as cohort, cross-sectional observational, and retrospective studies. Specifically, post hoc and secondary analyses of earlier published CTs were excluded. Articles were excluded if they did not mention AI or ML; however, if there was an implicit reference to these methods, the full text was reviewed. For interventions, studies on robotic, remote-controlled, computer-assisted intervention, or those testing AI-assisted intervention or ML-based predictive algorithms as experimental arm versus a control arm were excluded. These do not fit review’s scope, since advanced methods are validated as interventions against gold standard procedures or devices. An additional exclusion criterion included lack of full-text and non-peer-reviewed articles.
Search strategy and selection criteria
Potential studies were identified by searching three public bibliographic databases, such as PubMed, Embase (via Ovid), and Scopus, up to February 28, 2025. The search strategy was based on the partitioning of the research question into three main concepts: type of study, usage of AI/ML, and stage of application. This facilitates the conversion of the search into translated search strings, which are then applied across the three databases using the Polyglot Review Accelerator (https://sr-accelerator.com/#/polyglot, accessed on February 19, 2024) to maintain consistency in the searches. The search strings and methodologies are provided in Supplementary Table S2.
The selection of citations was performed using strings built on the three main concepts. The filter on randomized controlled trials (RCTs) was performed using Cochrane validated strings from PubMed (https://work.cochrane.org/pubmed, accessed on February 19, 2024), AI/ML methods used terminology that recalled the most known advanced methods, and the stage of application was built on different specifications of stages considered appropriate based on FDA discussion papers, which include design (screening eligibility, patient enrollment, risk stratification pre- and post-randomization), conduct (monitoring, adherence, retention with continuous collection of data from wearable devices), and analysis (imaging, endpoint detection with prediction algorithms, wearables). The string was developed to be as comprehensive as possible.
The selection of citations and more details on the steps of title and abstract screening that involved the use of different GPT models, gpt-4-turbo-2024-04-09, gpt-4o-2024-08-06, and gpt-4o-mini-2024-07-18, along with the prompts, are available in Supplementary Table S3. The title and abstract screening was performed in two separate instances: first, on articles collected up to February 19, 2024, with gpt-4-turbo using individual calls; then, it was repeated on those of the first instance with additional articles collected up to February 28, 2025, with gpt-4o, using a batch application programming interface call performed with gpteasyr package. 16 All articles chosen with at least one of the GPT models were included for full-text screening; the additional articles of the second instance did not undergo gpt-4-turbo screening again because of cost inefficiency. The first comparison was conducted on a sample of the included articles to refine the prompt. Once the prompt correctly identified the articles to include, it was tested on the full sample of 1,002 entries using different models, and a comparison with the gold standard was performed, as shown in Supplementary Table S4.
Data charting process and synthesis of results
Data charting was performed on Covidence, and variables of interest, such as country of conduct, study size, field of application, type of intervention, model type, and registration code, were extracted by a single reviewer. The results were summarized into tables with absolute and relative frequencies, grouped by the stage of application (design, conduct, and analysis), and more specific information related to the way AI/ML was applied was reported by each group.
Results
Selection of sources of evidence
The flow diagram is adapted from the PRISMA 2020 statement and reproduced with permission. As shown in Figure 1, references imported from Scopus (29,570), Embase (10,847), and PubMed (10,827) were loaded into Covidence, which removed 15,284 duplicates and marked 18,280 references as ineligible, leaving 17,624 articles for consideration. A sample of 1,002 articles was manually screened by the reviewers to define the gold standard, with the selection of 15 articles, which were used to develop a prompt for screening the titles and abstracts of references. The values of specificity and sensitivity were 0.9432 and 0.9333 for gpt-4-turbo and 0.9615 and 0.9333 for gpt-4o, respectively. The latter shows higher levels of both measures and higher cost efficiency; therefore, only the gpt-4o-2024-08-06 model with batch API execution was used to screen the remaining articles. The total error rate of GPT in the sample was 5.68% for gpt-4-turbo and 3.89% for gpt-4o, both lower than the measured error rates among human reviewers of 10.76% (95% CI: 7.43%–14.09%). 17 This demonstrates higher performance and faster screening when using GPT models.

PRISMA 2020 flow diagram of study selection.
The selected prompt and model were then applied to the remaining 16,622 articles, yielding 1,645 selected articles. These, together with the 15 articles initially selected manually, were subsequently screened in full-text. Summary data for each study included in the review are provided in Supplementary Table S5.
Literature analysis
The earlier publication of interest dates back to 2004, when these methods were employed in the exploratory analysis stage; at the time, these approaches were still commonly referred to as data mining. 18 This was followed in 2012 by a study that involved the use of AI/ML in the analysis of electroencephalography. 19 Only since 2020, there has been a real increase in the number of studies (Supplementary Figure S1). However, only 59 CTs were registered in ClinicalTrial.gov or national registries. Most of the studies were conducted in China (35 articles), followed by 27 in the USA, then six in the UK, four in Italy, and four in Spain; the full list is available in Supplementary Table S6, and a spatial distribution map in Supplementary Figure S2. Concerning the type of CT, 75 were single-center trials, 18 multicenter, 12 cluster trials, and three were protocols representing combinations of multiple subsequent trials, two in one case 20 and several so-called mini-trials in another, 21 and one was a protocol for a project involving a pilot study followed by a CT. 22 Regarding sample size, the studies had a median of 114 enrolled subjects, with a minimum of six 23 in a phase I oncology study with imaging and a maximum of 2,000,000 in the case of cluster trials with digital interventions using social media. 24 Neurology, Psychology and Mental Health, and Public Health emerged as primary fields of application. Behavioral interventions were common (43/108), followed by pharmacological ones in 28 studies. Study details and characteristics by application type are presented in Table 1.
Details and study characteristics by stage of application, only analysis, conduct and analysis (both C/A), design and analysis (both D/A), and only design.

n (%).
With regard to the primary question of the review, it was found that most of the studies used AI/ML only for analysis (80/108 articles), eight for both analysis and conduct,25–32 five for both design and analysis,20,21,33–35 and 15 only at the design stage.24,36–49 They are reported by subcategories within Design, Conduct, and Analysis of CTs in Table 2.
Type of application found in the design, conduct, and analysis of CTs.
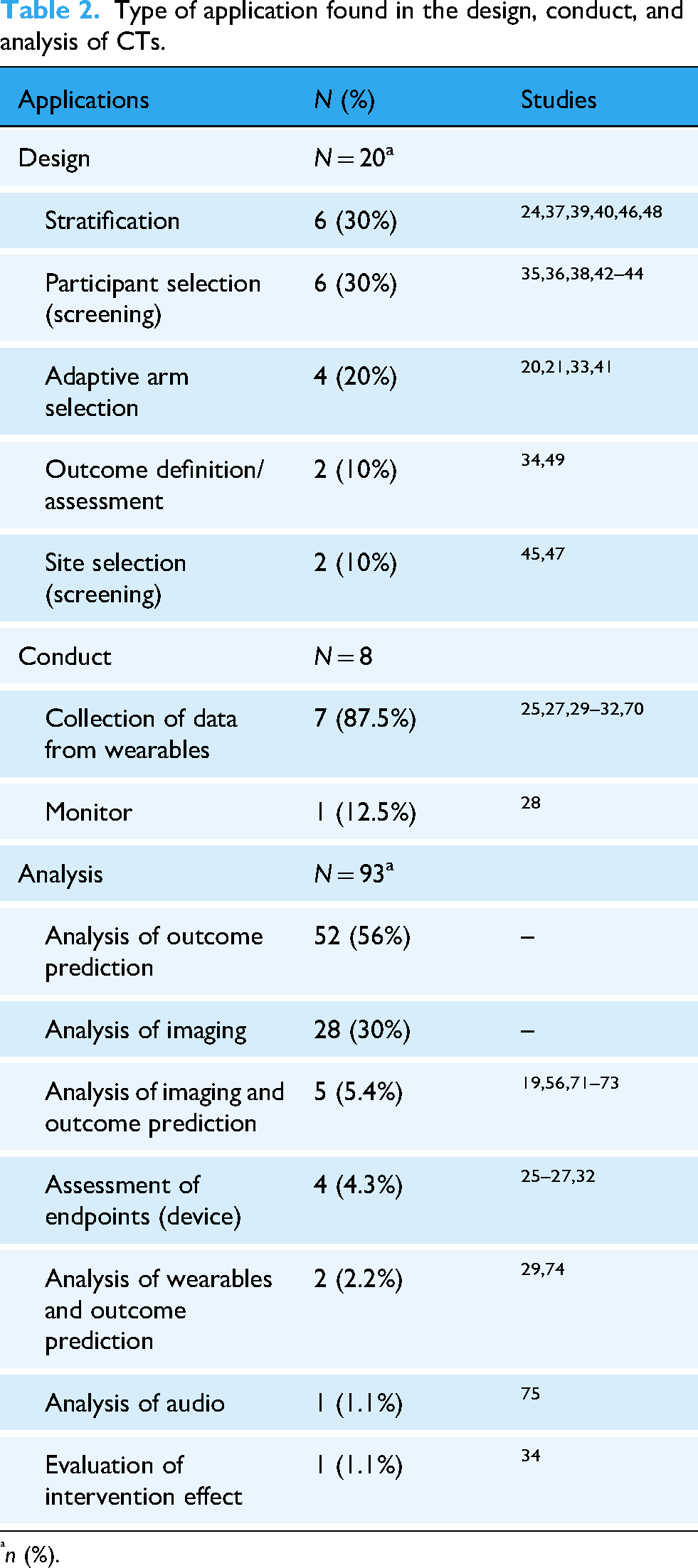
n (%).
For studies that involved ML at both the conduct and analysis stages, the collection of data from wearable devices was the most common application, followed by the analysis of collected high-dimensional data. Of relevance, the use k-nearest neighbors classifier to evaluate the differences in the training effect of virtual reality, 26 the collection of data with the Acumen IQ device, both monitoring and collection of secondary endpoint data, as well as an intervention through an ML-guided Hypotension Prediction Index. 27 Additional predictive modeling was developed to estimate hemoglobin worsening, 30 hospital readmissions, 31 the uptake of physical activity behavior, 32 and the risk in the context of transplant. 29
With regard to the use of models at the design stage to guide arm selection, there was a two-phase trial, with the first phase used for the development of treatment assignment scores and the second phase for allocating to the treatment with a higher probability of being optimal. 41 Similarly, but with additional predictive modeling, a protocol of an AI-adaptive trial with 12 mini-trials was found to allow for optimization of allocation ratios; however, no details of the AI algorithm were provided. 21 Another study involved reinforcement learning for adapting arm and treatment selection in the third one, 33 and the last aimed to develop an optimal treatment rule in the second and third trials, to test it through unequal treatment allocation. 20
In many cluster trials, it is challenging to clearly distinguish between intervention and design because the models can actively determine when and how the intervention occurs, as in adaptive intervention for malaria control, 33 and for identifying tuberculosis hotspots. 44 In some cases, it can also impact outcomes, such as in the Contrast Risk study, where the clinical decision support system predicts patient risk, guides follow-up decisions, and informs interventions with optimized fluid recommendations. 36
In different studies, ML algorithms were used for screening to identify the risk level for enrolling high-risk patients and then stratifying by predicted risk;35,36 additionally, they were used for site selection. 47 Site selection was performed in another study using NLP to identify cases of interest among imaging reports from primary care practices. 45 Other screening processes involved real-time speech processing, 38 a prediction model applied daily to EHRs (electronic health records) for the identification of high-risk patients, 42 application to CT scans for predicting the coronary artery calcium (CAC) score and identifying high-risk groups through imaging, 43 and screening individual X-rays with detection software guided by AI. 44
Risk prediction was also used for stratification; in one study, it was performed across sites to measure the primary outcome on subgroups. 40 In another, it was used to identify high-risk patients in both arms, with an additional diagnostic test in the interventional arm. 48 In a stepped wedge trial, it was applied at the patient level to inform clinicians randomized to weekly emails and reminders to improve attention to high-risk patients and usual cases, and for subgroup analysis. 39 In an educational cluster-randomized trial, a clustering algorithm was used to group the target population to guide the choice of educational content. 24 Similarly, clustering and classification were used for stratification on EEG (electroencephalography) profiles. 37 Of interest, a trial testing an assessment rule guided by AI used the derived scores to select high-risk subjects for follow-up outcome assessment. 46
In summary, regarding the design, AI/ML was used for cohort stratification pre- or post-randomization in six studies and during the randomization phase in four studies to optimize treatment allocation. Additionally, two studies used participant selection with imaging algorithms, four used predictive models, two were specifically for site selection, and two defined or assessed the primary outcome. ML models were constructed using data collected from wearable devices (7) and monitoring (1).
More common was the application in the analysis stage, with 93 references found, particularly as exploratory analysis in 52 studies, if included in the protocol or main paper of the trial. In 41 studies, it was applied for primary analysis. Table 3 shows the details of the type of application in the analysis stage by primary and exploratory analyses. Imaging was mainly used for primary analysis in the evaluation of treatment effects using magnetic resonance imaging or ultrasound. ML involved in outcome prediction has its main application in exploratory analysis for the development of predictive models for the response and outcome.
Application of AI/ML in the analysis by primary, exploratory, or both.

Regarding the transparency of AI/ML method reporting, the methods were specified in 86/108 articles. Convolutional Neural Networks were used in the context of imaging, as was Deep Learning, which was used in five studies for imaging and in two for predicting outcomes. Support Vector Machines or Support Vector Regression were applied to imaging analysis (1), combined with outcome prediction (4), and solely for predicting outcomes (4). Random Forests were also mainly used for predicting outcomes (8) and in one case in the context of imaging. In Supplementary Table S7, the specification and application of the ML algorithms for primary and exploratory analyses are summarized.
China appears to be the leading country; however, there is unclear reporting in eight studies50–57 that used AI/ML for the primary analysis, because they combined both validation of deep learning imaging with studies that had an interventional (pharmacological, acupuncture) experimental arm with randomized patients, and three that used it in the exploratory analysis. Among all Chinese studies, only 10 of them have been registered as into ClinicalTrial.gov58–61 and in China's national registry.62–67
The primary finding is the limited number of studies included for data extraction: only 108 of 17,624 unique studies (duplicates and non-RCTs removed). This suggests that the use of AI/ML is still quite restricted and primarily involves partial contributions to classic statistical analyses. The increasing number of published protocols signals growth; however, CT repositories were not screened for the identification of additional studies, and only studies reported in English were considered, which may have led to some underreporting.
Discussion
Overall, AI/ML techniques are often referred to by their commercial names, making it difficult to clearly identify them as ML models. Additionally, their role is rarely specified, making it unclear whether they are used in primary, secondary, or exploratory analysis. This lack of transparency highlights the need for regulatory guidance, as these methods are linked not only to operational complexity but also to regulatory constraints. Therefore, they are more common in secondary and exploratory analysis.
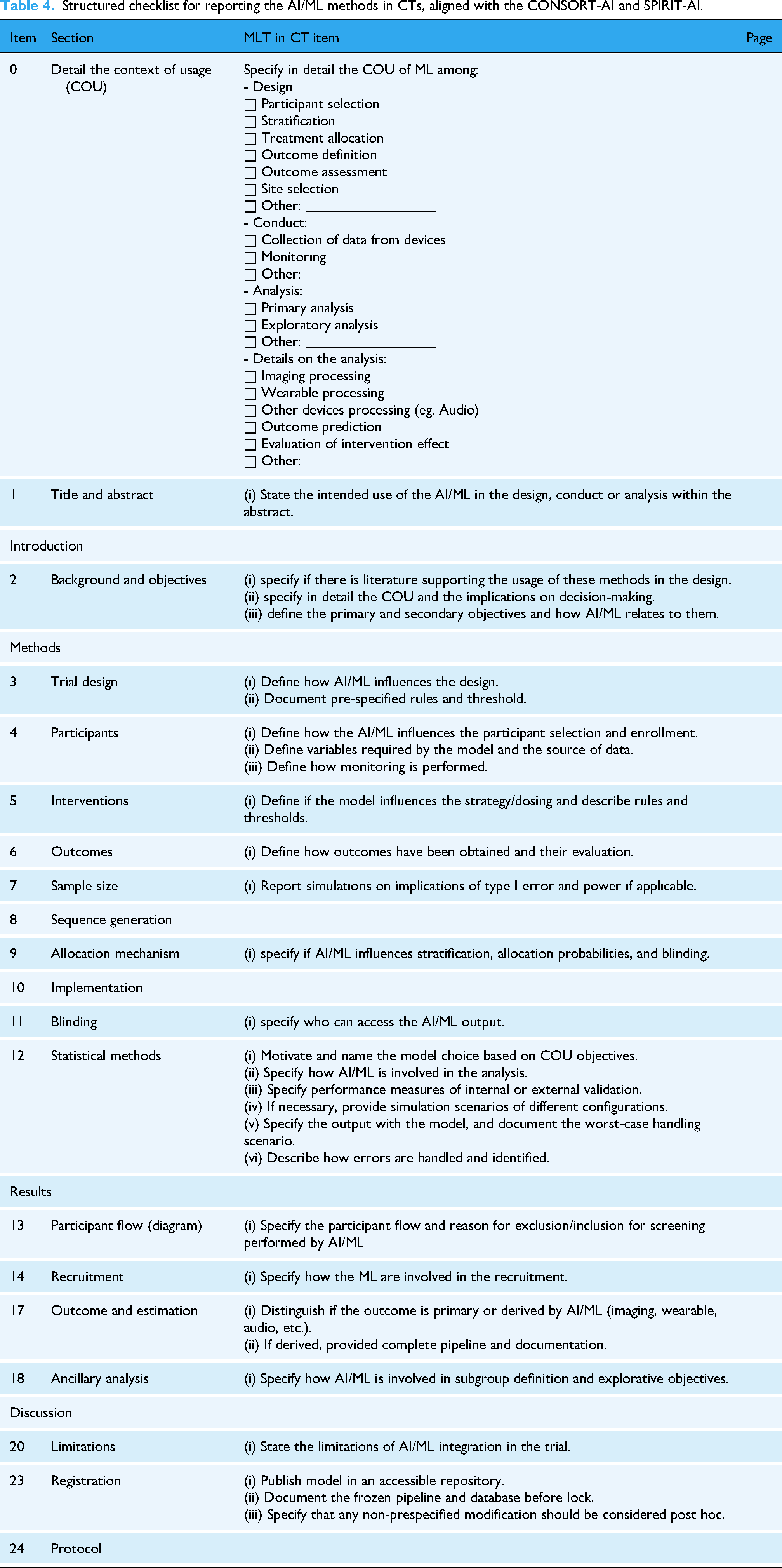
In the absence of formal standards and to mitigate the lack of transparency in reporting the AI/ML methods in CTs, a minimum requirement for authors should be adherence to the GCP ICH E6, with consideration of the EMA reflection paper. 4 In addition, reports and papers should at least include in the study protocol or as part of the CT data and documentation the following: (i) specify the context of usage (COU) of the algorithm in the trial (Design, Conduct, Analysis) in the abstract, report in the Introduction and Background if there is literature supporting the usage of these methods in the design and add details on the COU and the implications on decisions, (ii) describe the algorithm by motivating the model choice based on COU objectives (if in-house model, then specify all the process of model development with full description of the data, if commercial model, specify its commercial name, versioning and documentation references), (iii) specify performance measures of validation of frozen qualified model, (iv) ensure transparency and reproducibility by publishing the model in a accessible repository, by documenting the pipeline and database before lock, by specifying that non-pre-specified modification should be considered post hoc.
To promote standardized reporting, we developed a draft operational extension of the CONSORT-AI and SPIRIT-AI guidelines, 68 aimed at guiding the reporting of AI/ML methods in design, conduct, and analysis (Table 4).
Structured checklist for reporting the AI/ML methods in CTs, aligned with the CONSORT-AI and SPIRIT-AI.
Of interest, 92 articles were excluded at full-text review because they evaluated ML-integrated interventions, such as real-time monitoring, personalized alerts and therapies, AI-integrated chatbots, and prediction models for improving adherence via wearables. An additional 240 studies focused on AI interventions. The high number of excluded references, involving proceedings papers and congress abstracts, indicates that although applications are increasing, they remain at an early stage. Adoption in clinical settings depends on meeting regulatory requirements, and hesitation about compliance leads to delays in approval and implementation standards. 69
Indeed, critical gaps in the integration of AI/ML into CTs may stem from scalability and regulatory compliance issues, which are pressing concerns for healthcare providers and policymakers. The lack of standardized reporting and the challenge of validating AI/ML algorithms for clinical use can hinder their widespread adoption. Indeed, a spin-off of this review would be a synthesis of existing practices and identified gaps, contributing to the definition of a regulatory framework to develop robust guidelines that facilitate the safe and effective integration of AI/ML technologies into clinical research and practice. 3 Indeed, bridging these gaps could significantly accelerate the transition from experimental to routine clinical applications, addressing urgent healthcare challenges such as improving CT efficiency, enhancing the accuracy of diagnostic and prognostic tools, and reducing healthcare disparities through more personalized data-driven care. 10
Broader methods of patient-to-trial matching or trial success prediction were not readily found in the review, as they are mainly used by private companies and are either not mentioned or described using their commercial names, making it difficult to identify them as AI/ML in published CT results. The impact of such methods will become clearer in the future as they move from development to application.
Conclusions
The application of AI/ML in the design, execution, and analysis of CTs is still in its early stages. The use of commercial acronyms instead of detailed descriptions of the methods, along with vague explanations of their contributions to different trial phases and goals, has hindered the evaluation of their implementation. Although interest in this area is growing and more techniques, especially in risk modeling and prediction, are being developed, many are tailored to specific studies and lack scalability, which delays their broader application. Therefore, it is essential to transparently report the use of AI/ML, clearly defining their role from the initial protocol stage to the final publication, as suggested in the developed checklist.
Supplemental Material
sj-pdf-1-dhj-10.1177_20552076251393272 - Supplemental material for Current applications and future challenges of machine learning and artificial intelligence in clinical trials: A scoping review
Supplemental material, sj-pdf-1-dhj-10.1177_20552076251393272 for Current applications and future challenges of machine learning and artificial intelligence in clinical trials: A scoping review by Ajsi Kanapari, Giulia Lorenzoni, Honoria Ocagli and Dario Gregori in DIGITAL HEALTH
Footnotes
Acknowledgements
This research was carried out within the framework of the PhD Programme G.B. Morgagni at the University of Padua, Cycle XXXIX, Fellowship No. 8682. The fellowship was co-funded by Zeta Research s.r.l. and the European Union—Next Generation EU, under the National Recovery and Resilience Plan (PNRR), Mission 4 Component 1, Investment 4.1—Ministerial Decree No. 117/2023, I.3.3 “PNRR Innovative PhD fellowships addressing the innovation needs of enterprises.”
Contributorship
Conceptualization: DG and GL. Data curation: AK and GL. Design and methodology: AK, GL, and HO. Investigation: AK. Supervision: GL. Writing—original draft: AK. Writing—review and editing: GL and DG. All authors have read and agreed to the published version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The characteristics of the studies, search strings, and prompts are available in the Supplementary Material.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this work, the authors used GPT 4o in order to assess appropriate clarity and language of the manuscript (e.g. grammar, spelling, and style). After using this tool/service, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
Guarantor
DG.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.