
Abstract
Objectives
This study aims to evaluate the stylistic and structural equivalence of Artificial Intelligence (AI)-generated summaries, particularly those by Large Language Models (LLMs) like ChatGPT, compared to traditional human-generated case summaries in neuro-oncological board decisions. The primary goal is to explore the stylistic alignment between AI-generated and human-authored summaries from board meeting audio recordings.
Methods
The study compares 30 traditional human-generated case summaries with 30 AI-generated summaries based on board meeting audio recordings. Two expert raters, blinded to the source of the summaries, evaluated a total of 60 cases. A Likert scale was used to assess the plausibility, linguistic style, evidence adherence, and reference accuracy of the summaries.
Results
The results indicated that both LLM-generated and human-reviewed summaries demonstrated consistently high performance across all criteria evaluated. The general plausibility ratings were comparable (LLM: 4.7, Human: 4.73, P = .959). Linguistic style ratings also showed similarity (LLM: 4.87, Human: 4.97, P = .512). In terms of adherence to evidence, the means were close (LLM: 4.8, Human: 4.87, P = .541). Reference accuracy was slightly higher for AI-generated summaries (LLM: 4.97, Human: 4.9, P = .664). These findings were consistent with the results from Rater 2, and statistical analysis using Kendall's tau showed no significant differences between methods (P > .05).
Conclusion
The study finds that LLM-generated summaries can effectively emulate the style and structure of human-authored ones, indicating their promise as an additional tool in neuro-oncology. These AI models can enhance documentation quality and serve as valuable support in clinical settings. While further research is necessary to explore broader applications, LLMs offer exciting potential as a complement to traditional decision-making processes.
Keywords
Introduction
The advent of Artificial Intelligence (AI) in medicine, notably through Large Language Models (LLMs) like ChatGPT, presents a groundbreaking opportunity to enhance decision-making in clinical settings such as neurosurgery and specifically neurooncology. This field, characterized by its complexity and the requirement for interdisciplinary board decisions, stands to benefit significantly from the rapid, evidence-based insights these AI systems can deliver.1,2 LLMs possess the ability to process extensive datasets swiftly, offering recommendations that support clinicians in managing intricate diagnostic challenges. This potential to improve accuracy and efficiency in clinical decisions is crucial as the volume and complexity of patient data continue to grow.3,4
Nonetheless, the introduction of generative AI into neurooncological practice is not without challenges. Concerns about data bias, the accuracy of AI-generated content, and the ethical implications of using such technology without human oversight demand careful consideration. While LLMs promise enhanced decision support, their integration into clinical workflows must ensure that AI complements the expertise of medical professionals rather than supplanting it. Recent studies underline the importance of aligning AI tools with clinical protocols to prevent discrepancies and ensure consistency with standard care guidelines.5,6
In this study, we investigate the stylistic and structural equivalence of AI-generated case summaries as compared to traditional human-generated protocols within interdisciplinary neuro-oncological board decisions. Utilizing the latest version of ChatGPT, we generate summaries and recommendations from anonymized transcripts of tumor board meetings. These AI outputs are evaluated against human-derived summaries by experienced neuro-oncology specialists, who are unaware of each summary's source.
Our research aims to assess ChatGPT's potential as a supplementary tool in the neuro-oncological setting, focusing on its stylistic alignment with human outputs. While our primary focus is on this alignment, we strive to contribute to the ongoing conversation about AI's role in healthcare by highlighting its possibilities for documentation support. Our findings suggest that AI systems like ChatGPT can enhance documentation processes, thus offering potential for improved patient outcomes and more efficient resource allocation.
Ultimately, this study seeks to encourage further exploration into integrating AI technology with clinical practice, stressing the essential role of human oversight in AI system deployment within medicine.
Methods
Large language model and web interface
We used the latest version of the generative pre-trained transformer (ChatGPT) with a German user interface, available on OpenAI's official web domain (https://chatgpt.com, accessed on December 12, 2024, version ChatGPT o1) for this study. All prompts were typed in the German language directly through the web interface in a newly opened ChatGPT context window, without any prior instructions and without using any other front-end graphical user interfaces (GUIs) based on the Application Programming Interface (API). There were no individual configurations set beforehand for the LLM. The prompts and ChatGPT responses used in this study are appended exactly as they were originally generated, in their original German version, and were translated from German by ChatGPT for the manuscript text.
Patient population and case selection
We compared 30 case summaries and recommendations from previous tumor board protocols with 30 case summaries and recommendations automatically generated by the LLM from newly created transcripts of audio recordings. The audio transcripts were compiled from recordings of five tumor board meetings between October and December 2024, after censoring all sensitive and identifying data. The transcripts contained only presentations of patient histories without the consensus recommendations.
In the first step, we extracted the most recent 30 case summaries from our interdisciplinary tumor board protocols covering August to September 2024. These human-authored summaries were based on audio transcripts of the tumor board's final recommendations, a practice consistently utilized over the years. All cases were anonymized and were not preselected; they covered any entities pertaining to Neurooncology (cranial, spinal, or peripheral nerves). One such summary was then presented to ChatGPT as a template to generate case summaries from the audio transcript, using the following prompt: Please provide anonymized, case-based summaries of patient presentations from an interdisciplinary neuro-oncological tumor board meeting according to the following template: Patient with a pathological fracture of T4, stabilized with posterior instrumentation and decompressed, known NSCLC, histologically and immunohistochemically the profile does not match a primary lung tumor. Here is the anonymized transcript from our tumor board: [Transcript]. Please make sure to be concise with no more than 2 sentences of patient history. Could you now please provide evidence-based recommendations for each case, based on your own literature research? Leave the case summaries unchanged otherwise and only add your recommendation in one sentence. Lastly, please provide literature references for all case summaries you generated and the ones pasted here: [30 human-generated case summaries]. Leave the case summaries and recommendations unchanged otherwise.

Example of step-wise generation of case summary with recommendation and literature reference over three prompts, translated from the German response via ChatGPT.
Evaluation and rating
Two independent raters, each with a subspecialty in neurooncology and neither of whom participated in any tumor board meetings, were asked to evaluate all 60 case summaries according to their general medical plausibility, linguistic style, adherence to evidence, and accuracy of provided literature references according to a Likert scale from 1 to 5 (Table 1). The raters were blinded to the creator of the respective case summary and recommendation (human vs. LLM).
Likert scaled rating items used by the raters.

Statistical analysis
We evaluated the case summaries across four criteria: general plausibility, linguistic style, adherence to evidence, and accuracy of references, using ratings from two experienced raters on a Likert scale from 1 to 5. The Mann-Whitney U test was employed to compare ratings between LLM-generated and human-generated summaries, assessing for significant differences with a P-value threshold of <.05. To evaluate the agreement in rankings between the two raters for the case summaries, Kendall's tau test was employed. A significance threshold of P < .05 was used to determine statistical significance of the correlation observed. The analysis was performed using DATAtab website (DATAtab Team (2025). DATAtab: Online Statistics Calculator. DATAtab e.U. Graz, Austria. URL https://datatab.net)
Ethical considerations
The study was approved by the local ethics committee of the Technical University of Munich under Reference Number: 2024-508-S-CB, with a decision dated 13th January 2025.
Results
In comparing the LLM-generated case summaries to the human-reviewed ones, the study demonstrates consistently high performance across the evaluated criteria by both raters.
The evaluation performed by Rater 1 on LLM-generated and human-generated case summaries demonstrated comparable performance across all measured criteria. The mean rating for general plausibility was 4.7 for LLM-generated cases, closely matching the 4.73 mean for human-generated cases. The P-value of .959 indicates no statistically significant difference between the two groups, suggesting that both LLM and human summaries were perceived as highly plausible by Rater 1. LLM cases received a mean score of 4.87 for linguistic style compared to 4.97 for human cases. With a P-value of .512, the difference is not statistically significant, indicating that both sets were rated highly for clarity and coherence, though human-generated summaries had a slight edge in linguistic execution. The adherence to evidence ratings showed means of 4.8 for LLM and 4.87 for human cases, with a P-value of .541. This lack of significant difference implies that both LLM and human-generated summaries effectively adhered to evidence-based guidelines, according to Rater 1. For the accuracy of references, LLM-generated summaries scored a mean of 4.97, marginally higher than the 4.9 for human summaries. The P-value of .664 illustrates no significant distinction, affirming that both groups maintained high reference accuracy (Table 2, Figure 2.).
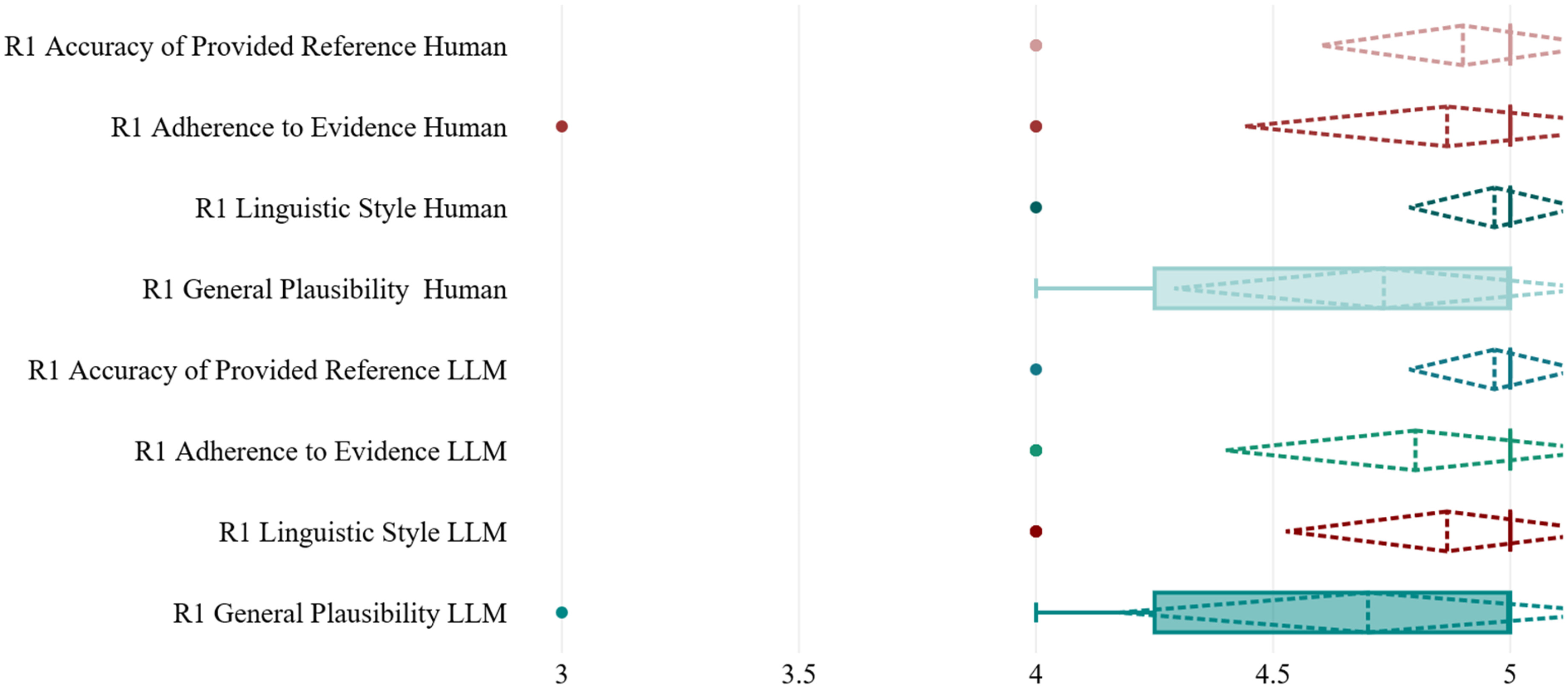
Boxplot with median, mean and standard deviation values of items rated by rater 1 (R1).
Mean, standard deviation and P values for items rated by rater 1.

Rater 2's evaluations show a close alignment between LLM-generated and human-generated case summaries, reflecting high-quality outputs across all criteria. For general plausibility, both types received similar mean ratings of 4.9 and 4.93, respectively, with a P-value of .831, indicating no significant difference. In linguistic style, LLMs had a mean of 4.83 compared to 4.93 for humans, with a non-significant P-value of .512. Adherence to evidence was identical for both, with means of 4.97 and a P-value of 1, demonstrating perfect alignment with guidelines. Both summation types achieved perfect scores for reference accuracy (Table 3, Figure 3).
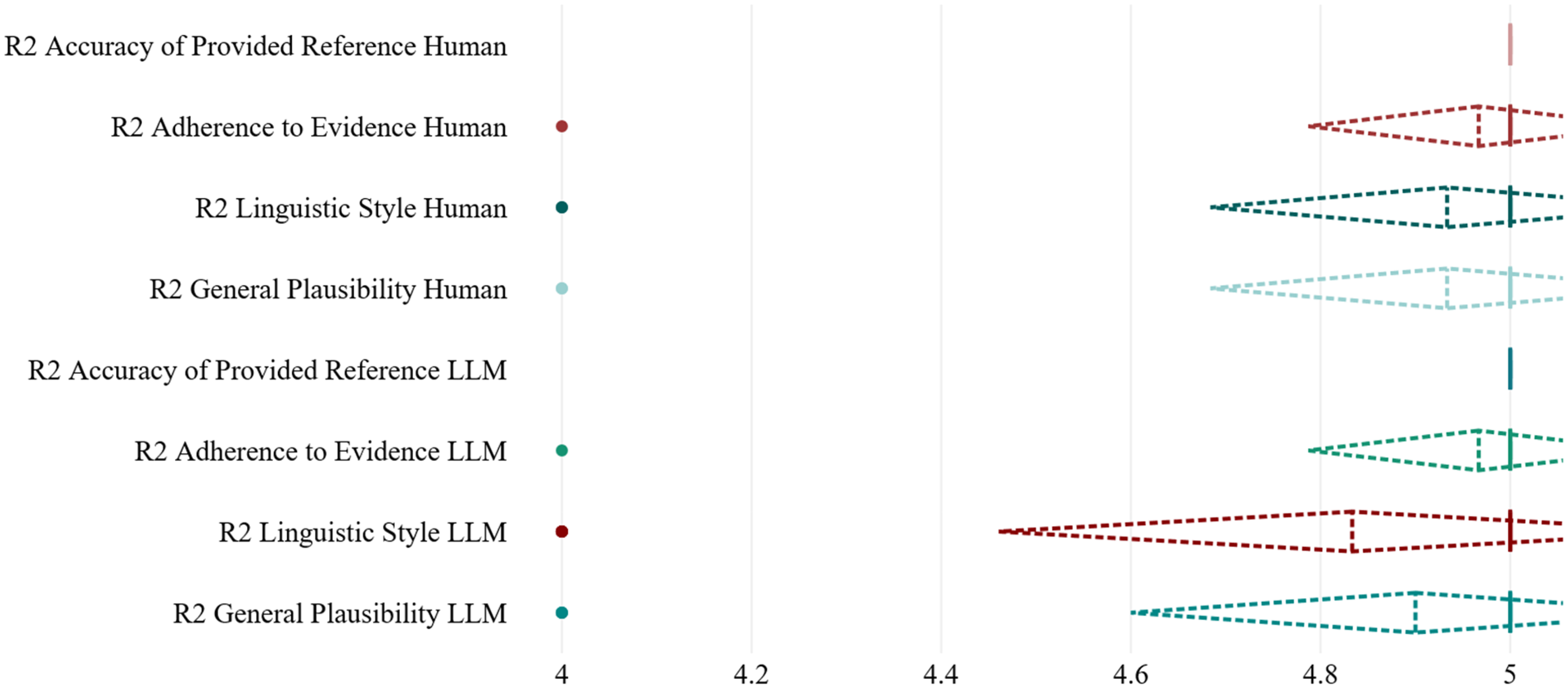
Boxplot with median, mean and standard deviation values of items rated by rater 2 (R2).
Mean, standard deviation and P values for items rated by rater 2.

Summary of percentage distribution of evaluation for LLM and human-generated cases from both raters is presented in Figure 4.

Percentage distribution of evaluation scores for LLM and human-generated cases from Rater 1 (R1) and Rater 2 (R2).
The Kendall's tau analysis revealed varying levels of agreement between the two raters across the different criteria (Table 4.). For LLM-generated summaries, the correlation between raters for general plausibility was marginally positive (r = .13, P = .951), indicating virtually no significant agreement. In contrast, adherence to evidence showed a strong positive correlation (r = .94, P = .753), suggesting substantial agreement despite a non-significant P-value due to sample size or variance. Linguistic style had a negative correlation (r = −.93, P = .793), indicating disagreement. Accuracy of references showed indeterminate results with P = 1.
Kendall's rank correlation coefficient values and P-values.

For human-generated summaries, general plausibility demonstrated a negative correlation (r = −.91, P = .833), and linguistic style also showed a negative trend (r = −.58, P = .979). Adherence to evidence was similarly negatively correlated (r = −.61, P = .97). As with LLM cases, accuracy of references was indeterminate.
These results collectively indicate that there are inconsistencies in the agreement between raters, particularly with human-generated content, while LLM summaries showed some areas of stronger concurrence. However, high P-values across most metrics render these observations statistically insignificant, implying a weak foundation for concluding substantial agreement or difference between human and LLM cases. Due to these findings, it is imperative to acknowledge the evaluation tool's limitations in providing clear agreement metrics. The observed inconsistencies and lack of clearly defined inter-rater reliability restrict definitive conclusions about the comparative performance of LLMs and human professionals.
The results signal that LLM-generated cases offer a performance closely mirroring that of human-reviewed cases, maintaining high standards of plausibility, linguistic quality, evidence adherence, and reference accuracy. The minor deviations noted were statistically insignificant, reinforcing the reliability of AI-generated case summaries as effective tools in supporting neurooncological board decisions.
Discussion
This study assessed the stylistic and structural validity of case summaries and recommendations produced by a LLM in comparison to traditional human-generated protocols within neurooncological board decisions. The results reveal that LLM outputs closely align with human evaluations across key performance dimensions, such as general plausibility, linguistic style, adherence to evidence, and reference accuracy. Nonetheless, it is important to note that while these results illustrate the LLM's potential for initial information synthesis, further investigation is essential to understand its role in ensuring decision-making efficacy.
Our findings indicate that LLM-generated summaries achieve high levels of plausibility and linguistic quality, comparable to human reviewers. This aligns with similar research reviews where AI systems demonstrate reliability in generating clinically relevant information.1,2,7 The marginally superior adherence to evidence observed in the LLM outputs underscores the potential of AI to integrate contemporary guidelines effectively.3,8
The integration of AI into clinical settings has been posited to streamline workflows and enhance decision-making quality.5,6 Our study reinforces this potential, suggesting that LLMs like ChatGPT can serve as valuable adjuncts in neurooncology, albeit its integration into clinical care presents notable limitations and ethical responsibilities.4,9,10
While our study provides insights into the stylistic and structural capabilities of LLM-generated outputs, it underscores the need for careful integration of AI in clinical practice. The specific findings suggest considerations around data accuracy, decision-making processes, and maintaining human oversight in AI-assisted recommendations. Future frameworks must address these points to enhance trust and efficacy in AI applications in healthcare.
Limitations of ChatGPT in clinical decision-making
Despite promising results, ChatGPT has inherent limitations that warrant caution. The reliance on AI for clinical decisions necessitates rigorous validation to mitigate risks associated with data bias and misinterpretation.11–13
One major concern is the model's reliance on a static training dataset, which means its medical knowledge might not include the most recent guidelines, trial results, or novel therapies developed after its training cutoff. In a rapidly evolving field like oncology, this raises the risk of outdated or incomplete recommendations. Ensuring the accuracy and reliability of ChatGPT-generated content requires rigorous validation and continuous updating aligned with current clinical practice. 14
Another well-documented issue is the tendency of large language models to produce convincing but incorrect or “hallucinated” content. 15 Additionally, LLMs may struggle with ambiguity in the source data, as they lack the ability to discern nuance or intent that human clinicians could naturally interpret. In a clinical context, such confidently presented inaccuracies—for example, a fabricated but plausible-sounding reference or an incorrect interpretation of a rare case—could mislead decision-making if not identified. Explainability is another limitation: the model does not provide transparent reasoning for its recommendations, operating as a “black box.” This opaqueness makes it difficult for clinicians to discern why a particular suggestion was made, complicating the task of verifying the AI's reasoning or explaining it to patients. Finally, like all AI trained on large datasets, ChatGPT can inherit biases present in the training data. If certain patient groups (e.g., rare pathologies) were underrepresented or if published literature itself contains biases, the model's outputs may inadvertently reflect or even amplify those biases. 14 In neurooncology, this might manifest as less familiarity with atypical presentations or uncommon treatments. Such limitations underscore that ChatGPT, in its current form, cannot be considered a standalone authoritative source for clinical decisions. Its suggestions must be viewed as preliminary and hypothesis-generating, to be carefully cross-checked against up-to-date medical knowledge and the patient's real-world data before any action is taken
A notable limitation of this study is the reliance on pre-existing audio transcripts, which may not fully capture the decision-making complexity present in live settings. While these transcripts serve as the source data for both human-generated and LLM-generated summaries—providing descriptions of patient histories and imaging findings presented by experts—they do not encompass the immediacy and context of human clinical reasoning during real-time discussions. Despite the consistency in the origin of data, the interpretive nuances and retrospective processing by LLMs might lead to disparities when compared to the real-time, dynamic nature of human decision-making. This reliance should be carefully considered, as it impacts the comparability of outputs and highlights the need for caution when evaluating AI's role within clinical settings. However, given that decisions in both cases are based on identical baseline conditions, the study maintains equipoise within its methodological framework, ensuring that the analysis remains grounded in a consistent evaluative environment.
The sample size of 30 cases per group limits the statistical power and robustness of the comparisons made between LLM and human-generated summaries. The relatively small sample size may contribute to the non-significant P-values and restricts our ability to detect subtle differences between groups. However, our sample size of approximately 30 cases per group aligns with standard practices for exploratory or pilot studies, especially in emerging fields like digital health and AI. Literature suggests that having about 30 participants per arm is sufficient to gain preliminary insights when prior data is lacking. 16 For example, an audit of UK pilot trials reflects this typical practice with a median target of 30 patients per group. 17 Similarly, Hertzog suggests that a sample size in this range provides adequate precision for estimating means and variability. 18 This convention is partly due to statistical principles, as around 30 observations often suffice for the Central Limit Theorem to approximate normal distributions and provide stable variance estimates. Additionally, the uniformly high scores observed across all domains hint at potential ceiling effects or rater bias, which diminishes the study's discriminatory capacity. This indicates that our current evaluation methods may not fully capture the nuanced differences between LLM and human outputs.16–18
Ethical and professional responsibilities
Integrating AI tools like ChatGPT into clinical decision-making raises key ethical issues. Given the study's findings that LLMs can closely mimic human stylistic and structural outputs, it is essential to ensure these tools are used responsibly alongside human oversight. Clinicians must rigorously evaluate AI-generated recommendations against clinical guidelines and retain ultimate responsibility for patient care decisions.
Transparency is vital; AI recommendations must be clearly identified within clinical teams to allow proper scrutiny and ensure they're not mistaken for expert judgment. Similarly, patients should be informed when AI tools influence their care decisions, respecting their autonomy and informed consent. A recent study supports the disclosure of AI's role during consent, provided it is communicated clearly and understandably to patients. 19 Physicians must remain patient advocates when using AI, presenting AI-derived recommendations as their own. This aligns with WHO's AI ethics principles, emphasizing human accountability and autonomy in AI-assisted care. 20 Hospitals might incorporate AI tool statements in general treatment consent forms, with clinicians prepared to discuss this with patients. 21
Legal and regulatory considerations in the EU and Germany
The deployment of ChatGPT in clinical settings faces regulatory challenges, with notable gaps in legal accountability for AI-generated medical advice in the EU. While physicians and hospitals remain liable for clinical decisions, AI developers like OpenAI avoid direct responsibility by disclaiming medical use. The EU's proposed AI Liability Directive and updates to the Product Liability Directive aim to address this by facilitating fault-based claims for AI-caused damage and classifying certain AI tools as “product” defects. 22 As demonstrated, AI models offer potential benefits in documentation and information consistency but require stringent validation to prevent data bias and misinterpretation. These considerations underscore the need for continuous ethical scrutiny and legal clarity to support the responsible adoption of AI in medicine.
Future directions
Further studies should explore the application of LLMs across diverse medical disciplines to validate their utility beyond neurooncology. 23 Research into real-time interactions between AI and clinicians could yield insights into the practical challenges and benefits of AI integration.24,25 Moreover, longitudinal studies assessing the long-term impact of AI on patient outcomes and healthcare costs are warranted.26,27 As AI technology continues to evolve, its integration into medical practice promises significant advancements in healthcare efficiency and accuracy28,29
The potential for AI to transform medicine extends beyond processing and analyzing data; it also offers profound advancements in predictive analytics and personalized care. 30 AI algorithms can predict patient outcomes by analyzing patterns in vast datasets, which is invaluable for early intervention and prevention strategies. 31 In personalized medicine, AI can tailor treatments to individual genetic profiles, enhancing the effectiveness of therapies and reducing adverse effects. Furthermore, AI-driven decision support systems can assist professionals by offering second opinions, reducing diagnostic errors, and enhancing overall care quality. 32 Recent advancements in AI, as highlighted by Apple Intelligence and Sora, underscore the transformative potential of integrating generative models into neurosurgery. Apple Intelligence enhances clinical workflows and communication through advanced writing tools, seamless integration with Apple products, and improved patient interaction via AI-powered functionalities 33 [Mohamed & Lucke-Wold, 2024]. Meanwhile, Sora's text-to-video capabilities provide enriched patient education and training opportunities, demonstrating the ability to convey complex medical information effectively through dynamic visual content. 34 These innovations address key challenges in patient communication and education, offering tools that enhance understanding and engagement. As AI continues to evolve, its deployment in neurosurgery promises to bolster educational outcomes and facilitate more efficient, patient-centered care across diverse clinical settings. As such, AI stands to significantly enhance the precision and personalization of medical interventions while also addressing time constraints faced by healthcare providers, allowing them to focus more on patient interaction and complex decision-making processes.
Conclusion
This study demonstrates that Large Language Models (LLMs), such as ChatGPT, can produce neuro-oncological case summaries with stylistic and structural quality akin to those created by experienced human professionals. These findings highlight the potential for LLMs to act as supplementary tools in clinical settings, improving consistency in documentation and aiding in information sharing. While AI technology advances, its integration into medical workflows promises to boost clinical efficiency. Nonetheless, ongoing research and ethical considerations are essential to ensure the responsible adoption of AI in healthcare, maximizing its benefits while safeguarding patient care standards.
Footnotes
Contributorship
M.G. and V.M.E. were responsible for conceptualization, methodology, formal analysis, writing the original draft, and project administration. A.K.A. and C.N. contributed to data curation, writing—review and editing, and visualization. H.M. and J.G. conducted the investigation. B.M. and A.W. provided supervision and were involved in the conceptualization and writing—review and editing. All authors reviewed and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this work, the authors used ChatGPT services to enhance the clarity and coherence of the paper writing. After utilizing this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the published article.
Appendix 1
Ein Patient klagt seit etwa einem Jahr über fortschreitende Gedächtnisstörungen. In der Bildgebung zeigt sich eine rechts frontal lokalisierte Raumforderung mit ausgeprägtem perifokalem Ödem, die auf ein Meningeom hindeutet.
Es besteht eine Läsion mit punktförmiger Schrankenstörung und entsprechender leichten Mehrspeicherung in der PET-Untersuchung. Der Befund wird bereits seit einiger Zeit beobachtet und könnte eine minimale Größen- oder Aktivitätszunahme zeigen.
Ein Patient mit einem bekannten Neoplasma (neuronal-meningealer Tumor) rechts insulär zeigt teilweise leptomeningeale Beteiligung. Unter aktueller medikamentöser Therapie wirken viele Befunde regredient, eine einzelne Stelle jedoch nach wie vor auffällig.
Hier liegt eine länger bekannte lumbale Spinalkanalstenose mit mehreren epiduralen tumorbedingten Engstellen vor, ohne pathologische Frakturen. Die klinische Symptomatik passt gut zu den radiologischen Engstellen und den dadurch verursachten Beschwerden.
Eine Patientin präsentiert multifokale, intraxiale Raumforderungen, insbesondere links temporomesial und in weiteren Hirnarealen. Die MRT-Aufnahmen zeigen ausgedehnte Läsionen mit teils starker Diffusionsrestriktion und einer unklaren, jedoch sehr vitalen Tumorkonfiguration.
Eine junge Person aus dem Ausland weist eine intraventrikuläre Raumforderung am Septum pellucidum auf. Differentialdiagnostisch kommen verschiedene Tumorentitäten infrage, genaueres ist noch unklar.
Eine Person mit vormals operiertem Hypophysen-Makroadenom hat jetzt einen Resttumor linksseitig im Bereich der A. carotis interna. Es gibt Hinweise auf eine mögliche Beteiligung des Infundibulums; endokrinologische Kontrollen sind notwendig.
Bei einer Patientin besteht eine sogenannte Meningiomatosis cerebri mit mehreren Herden, von denen einer frontobasal gelegen ist und bereits histologisch als WHO-Grad-I-Meningeom gesichert wurde. Weitere Läsionen verteilen sich über das gesamte ZNS.
Eine diffuse bzw. leptomeningeale Aussaat wird vermutet. Die Patientin ist in ihrem Allgemeinzustand stark eingeschränkt; weitere Diagnostik soll klären, ob es sich um eine ausgedehnte Metastasierung oder ein primäres Befallsmuster handelt.
Ein Patient hat eine rechts parasagittale Raumforderung, die hinsichtlich einer möglichen Metastase abgeklärt wird. Als möglicher Primärtumor steht eine Raumforderung in der Lunge im Raum, die noch weiter untersucht werden muss.
Hier liegt ein konvexitäres Meningeom rechts temporookzipital vor, das bildmorphologisch komplett entfernt wurde. Histologisch deutet sich ein WHO-Grad-II-Meningeom an, die molekularen Details sind ausstehend.
Ein Patient mit entdifferenziertem Prostatakarzinom zeigt in der Wirbelsäule ausgedehnte Metastasen. Neben orthopädischen und neurologischen Einschränkungen treten vor allem starke Schmerzen auf; das Staging ist bereits teils erfolgt.
Eine Patientin mit petroklivaler Raumforderung hat bereits eine Strahlentherapie erhalten. Die umfangreiche Läsion in der hinteren Schädelgrube geht teilweise in umliegende Strukturen über und erfordert eine weitere Abklärung.
Ein Patient weist ein Cholesterolgranulom der Felsenbeinspitze auf, das sich durch eine hyperintense Läsion in der MRT darstellt. Typischerweise können daraus druckbedingte Beschwerden entstehen, je nach Tumorgröße und Ausdehnung.
Bei einem Patienten findet sich eine paravertebrale Raumforderung in Höhe der Brustwirbelsäule. Das Gewebe wird noch entkalkt, weswegen eine abschließende histologische Einordnung bislang aussteht.
Es handelt sich um eine Person mit einem mehrfach behandelten Kordomrezidiv im Bereich der Schädelbasis. Bereits durchgeführte Operationen und Strahlentherapien bedingen einen komplexen Verlauf; die aktuelle Bildgebung zeigt keinen eindeutigen Tumorrest.
Bei einer Patientin wurde im Bereich des Nervus trochlearis ein Gefäß-/Hämangiombefund bestätigt. In der MRT zeigte sich eine hyperintense Raumforderung nahe des Nervenverlaufs; eine zunächst konservative Verlaufskontrolle ist vorgesehen.
Eine melanozytäre Läsion unklarer Dignität (Spektrum von Melanocytom bis Melanom) wurde in der Kopfregion entdeckt. Die endgültige Zuordnung erfordert erweiterte molekularpathologische Untersuchungen.
In der gesamten Wirbelsäule sind intradural-extramedulläre Raumforderungen nachweisbar, die schon länger bestehen. Die Patientin hat entsprechend multiple neurologische Symptome; die Läsionen werden auf ein langsames Wachstum hin untersucht.
Bei einem Patienten, der bereits eine Stabilisierung im thorakalen Bereich hatte, fällt eine Verdachtsprogression auf. Zusätzlich zeigen sich mögliche Neubildungen entlang der Wirbelsäule; die genaue Ursache ist noch zu klären.
Ein ehemals operiertes Nierenzellkarzinom hat zu ossären Metastasen geführt. Diese umfassen nun auch relevante Wirbelstrukturen, sodass eine erneute onkologische Therapie und gegebenenfalls Stabilisierung diskutiert wird.
Bei einer vertebralen Raumforderung wurde eine CT-gesteuerte Biopsie durchgeführt; eine definitive Diagnose liegt noch nicht vor. Der Patient beschreibt derzeit nur geringfügige Beschwerden, sodass der weitere Verlauf von der Histologie abhängt.
Eine Person mit vorherigem Tumor (vermutlich endokrin) hat neuartige Befunde in Schädelkalotte und Hirnparenchym, was auf eine mögliche Fernmetastasierung hindeutet. Der Allgemeinzustand ist reduziert, und eine koordinierte multidisziplinäre Abklärung ist notwendig.
Bei einem Patienten mit anaplastischem Oligodendrogliom, der schon mehrfach operiert und behandelt wurde, zeigt die Bildgebung nun neue progressionsverdächtige Herde. Klinisch wird über vermehrte Anfälle berichtet, was eine vertiefte neuroradiologische Klärung erfordert.
Eine Patientin mit mutmaßlichem Ependymom im 4. Ventrikel weist zunehmend Symptome wie Übelkeit und Gleichgewichtsstörungen auf. Die MRT-Aufnahmen zeigen eine intraventrikuläre, zystische oder solide Raumforderung, die sich über die Monate vergrößert zu haben scheint.
Diese Patientin leidet an einem sehr großvolumigen Oropharynx-Tumor, der bereits in mehrere Regionen hineinwächst (“mehretagig”) und metastasiert ist. Zusätzlich sind tumorbedingte Veränderungen im Bereich der Halswirbelsäule zu beobachten, was zu Schmerzen und potenziellen Stabilitätsproblemen führen kann. Aus onkologischer Sicht wäre eine Kombination aus chirurgischem Eingriff und adjuvanter Therapie sinnvoll, allerdings lehnt die Patientin jeden ausgedehnten, entstellenden Eingriff ab.
Bei dieser Patientin handelt es sich um ein Meningeom (tumorös veränderte Hirnhaut) in der vorderen Schädelgrube, das bereits mehrfach operiert und bestrahlt wurde. Im aktuellen MRT zeigt sich ein weiterer langsamer Tumorprogress.
Dieser Patient hat eine endokrine Grunderkrankung (Cushing-Syndrom) und weist zahlreiche Metastasen entlang der Wirbelsäule auf, die zunehmend zu Schmerzen und neurologischen Symptomen führen.
Ein Patient weist eine unklare Raumforderung im Bereich der rechten Parietalkalotte auf, welche radiologisch nicht eindeutig einzuordnen ist: Möglicherweise handelt es sich um ein veraltetes Hämatom, einen knochenbildenden Tumor oder eine Metastase. Die Tumorkonferenz befürwortete eine offene Resektion oder zumindest eine Biopsie, um endgültig Gewissheit über die Dignität zu erhalten. Nach Vorliegen der histologischen Untersuchung kann über eine gezielte Weiterbehandlung entschieden werden.
Eine Patientin erlitt eine pathologische Fraktur im Lendenwirbel L4, die im Rahmen der Bildgebung als sehr ausgedehntes Hämangiom identifiziert wurde. Der Befund wurde extern biopsiert und histologisch bestätigt, es handelt sich um ein aggressives Hämangiom mit begleitenden Schmerzen.
4 Sekunden
Appendix 2
Ein Patient wurde mit einer links temporalen Raumforderung operiert, die vollständig entfernt werden konnte. Die histologische Aufarbeitung ergab ein High-grade- Gliom, die molekularpathologische Einordnung steht jedoch noch aus.
Bei einer Person wurde im Rahmen einer Kopfschmerzabklärung eine Raumforderung im linken Tektalbereich und links am Thalamus entdeckt, die im PET nicht positiv war. Daneben liegt eine Glomerulonephritis vor.
Es liegt ein Lokalrezidiv eines intraspinalen Meningeoms WHO-Grad III in Höhe von L2 vor. Der Patient hatte zuvor bereits eine entsprechende Therapie, doch nun zeigt die Bildgebung erneut einen Tumor.
Nach einer früheren Nephrektomie bei Nierenzellkarzinom findet sich nun eine Raumforderung im Bereich des rechten Kleinhirnpedunkels. Die Bildgebung legt eine mögliche Metastase nahe.
Ein Patient mit bekanntem Leiomyosarkom erlitt eine pathologische Fraktur in TH3, die dorsal stabilisiert und dekomprimiert wurde. Die Histologie bestätigte die Sarkomdiagnose in diesem Wirbelbereich.
Diese Patientin hat ein bekanntes Pankreaskarzinom und ein Mammakarzinom. Eine Osteolyse am Dens axis wurde transzervikal biopsiert, ohne dass Tumor- oder Entzündungszellen nachweisbar waren.
Eine bithalamische Raumforderung wurde bereits zweimal biopsiert, jedoch ohne Nachweis von Tumorzellen. Die Klinik ist unklar, die Patientin wird daher weiter beobachtet.
Eine Raumforderung liegt rechts prävertebral auf Höhe L4 vor, welche CT-gesteuert biopsiert wurde. Der histologische Befund steht noch aus.
Bei einem Keilbeinflügelmeningeom links median erfolgte eine subtotale Resektion. Die Histologie ist noch nicht vollständig, derzeit kein Hinweis auf eine hohe Proliferationsrate.
Im Bereich der Hinterwand des Sinus sphenoidalis findet sich eine Raumforderung, die transnasal biopsiert wurde. Die Histologie bestätigte ein Chordom.
Bei einem Patienten mit multiplem Myelom kam es zu einer pathologischen Fraktur und Metastase in den Lendenwirbel LWK1. Nach dorsoventraler Stabilisierung bestätigte die Histologie das Myelom.
Ein vollständig reseziertes Olfaktoriusrinnen-Meningeom WHO-Grad I wurde histologisch bestätigt, die Molekularpathologie ist noch ausstehend.
Bei Verdacht auf ein High-grade-Gliom des Balkenspleniums (rechtsseitig, IDH-Wildtyp) erfolgte eine Resektion. Die Histologie bestätigt das hochgradige Gliom.
Es wurde eine intramedulläre Raumforderung auf Höhe C6 reseziert; postoperativ kein Hinweis auf Residualtumor. Histologisch liegt ein Ependymom vor, Grad und molekularer Status sind noch offen.
In L5 wurde eine Raumforderung dekomprimiert und debulkt, histopathologisch ergab sich ein follikuläres Lymphom.
Bei Meningeomatosis cerebri wurden bereits mehrfach Operationen und Bestrahlungen durchgeführt. Zuletzt erfolgte die Resektion progredienter Läsionen biokzipital und links temporal, MRT zeigt keinen Rest.
Ein Chondrosarkom im petroklivalen Bereich mit Beteiligung der Nasenscheidewand wurde mehrfach reseziert und debulkt, histologisch bestätigt.
Ein Lipom im Nackenbereich (rechts) wurde vollständig entfernt und histologisch als Lipom bestätigt.
Eine Raumforderung links temporo-operkulär wird bildmorphologisch primär als glialer Tumor eingestuft, differentialdiagnostisch ist aber auch eine parasitäre Genese zu erwägen.
Ein sakrales Chordom wurde extern biopsiert und mittels Kohlenstoff-Ionen bestrahlt, nun zeigt sich ein massiver Tumorprogress sowie Verdacht auf pulmonale Fernmetastasen.
Nach Resektion einer links frontalen Metastase besteht nun bildmorphologisch der Verdacht auf eine Radionekrose. Ein PET-Befund stützt diese Vermutung, da keine Tumoraktivität sichtbar ist.
Bei einem auswärts resezierten Glioblastom (links parietal) und erfolgter Radiochemotherapie besteht nun eine lokale Größenzunahme mit begleitender Meningeosis gliomatosa. Der Patient lehnt weitere chirurgische Maßnahmen ab.
Eine Raumforderung in der Sella und im hypothalamischen Bereich wurde bereits reseziert und bestrahlt, zeigt aber nun einen Progress.
Bei einem anaplastischen Astrozytom (WHO Grad 3) rechts temporal, bereits mehrfach operiert und systemisch behandelt (inkl. Bevacizumab/Avastin), zeigt sich nun ein bildmorphologischer Progress im Bereich der Commissura anterior.
Ein sphenoorbitales Meningeom linksseitig wurde in der Vergangenheit bereits reseziert und bestrahlt. Aktuell findet sich kein eindeutiger radiologischer Progress, jedoch eine klinische Verschlechterung mit neuem Gesichtsfelddefekt, bei stabilem Visus.
Ein bekanntes NSCLC wurde bereits operiert und bestrahlt. Aktuell besteht ein bildmorphologischer Verdacht auf Progress, der abgeklärt werden muss.
Im rechten Kleinhirnpedunkel wurde eine entzündlich wirkende Läsion festgestellt, die radiologisch nicht eindeutig tumorverdächtig erscheint.
Ein links temporales Glioblastom wurde reseziert und adjuvant radiochemotherapiert. Nun besteht der Verdacht auf ein Progressionsgeschehen am dorsalen Resektionsrand und zusätzlich im Balkensplenium links.
Ein intraossäres Hämangiom im rechten Sakralbereich wurde bereits reseziert, doch nun zeigt die Bildgebung ein Lokalrezidiv.
Ein intraspinales Meningeom auf Höhe Th1 (WHO Grad 1) wurde reseziert, die molekularpathologische Bewertung zeigt ein Low-Risk-Profil. Postoperativ findet sich kein Hinweis auf ein Rezidiv.
4 Sekunden