
Abstract
Background
Large language models such as ChatGPT are increasingly used by patients seeking perioperative information, yet their reliability for anesthesia-related patient education remains insufficiently evaluated. This study assessed the quality of ChatGPT-4.0 responses to frequently asked anesthesia questions using a multi-rater evaluation framework.
Methods
Twenty-two common anesthesia-related patient questions were identified through online search. Each question was submitted once to ChatGPT-4.0 (GPT-4-turbo; chat.openai.com) without follow-up prompts. Five anesthesiology and reanimation specialists—each with more than 20 years of experience—independently evaluated each response using a validated 4-point Likert-type scale (1 = excellent; 4 = unsatisfactory). Inter-rater reliability was calculated using a two-way random-effects model (ICC[2,1]).
Results
A total of 110 ratings were collected. Among these, 61.8% were classified as excellent, 32.7% as satisfactory requiring minimal clarification, and 5.5% as satisfactory requiring moderate clarification. No responses were rated as unsatisfactory. Mean scores for individual questions ranged from 1.0 to 2.4. Reviewer-wise averages ranged from 1.27 to 1.73, indicating generally positive evaluations with modest variability in scoring strictness. The overall inter-rater reliability was poor to fair (ICC = 0.25).
Conclusions
ChatGPT-4.0 provided high-quality responses to frequently asked patient questions about anesthesia and may serve as a supportive digital health tool for patient education. However, limited agreement among evaluators highlights the need for expert oversight and contextual refinement when integrating large language models into clinical communication pathways.
Keywords
Introduction
Anesthesia has been successfully applied for many years to temporarily eliminate pain and consciousness during surgical and medical procedures. Approximately 313 million surgical procedures are performed worldwide every year and a large proportion of these procedures are performed under anesthesia. 1 Especially in developed countries, approximately 40 million anesthesia applications are performed annually. 2 These data show that anesthesia is an indispensable component of modern medicine and that people are very often associated with anesthesia.
ChatGPT is an artificial intelligence (AI) chatbot developed by OpenAI that has the capability of responding to complex queries in an interactive, conversation-based format. Released to the public in November 2022, it is the fastest-growing consumer application in history, having surpassed 100 million users by January 2023. 3 With a user-friendly interface, ChatGPT has wide- ranging implications for impacting healthcare delivery and patient education. 4 The utilization of AI in healthcare systems is crucial and imperative due to its ability to enhance precision and accuracy while reducing the time required for various aspects of the system. 4
Despite the growing body of literature evaluating ChatGPT performance across various medical specialties, anesthesia-related patient education represents a distinct and underexplored knowledge domain. Unlike specialties such as orthopedics, ophthalmology, or hepatology—where patient questions often focus on disease-specific management or procedural outcomes—anesthesia-related inquiries are closely linked to perioperative anxiety, safety concerns, and risk perception. Misinterpretation or inaccurate information in this context may have immediate implications for patient trust, informed consent, and perioperative decision-making. Therefore, assessing the quality of large language model–generated responses specifically within the field of anesthesia is particularly important and addresses a meaningful gap in the existing digital health literature.
Searching for information about health and disease on the internet has become a natural part of life and coping with a disease today. 5 For this reason, it has become common for patients to use the internet and artificial intelligence applications to get information about anesthesia, which is the most common condition faced by patients. In the light of the information in the literature, the authors planned this study based on the hypothesis that ChatGPT will provide satisfactory answers about the questions frequently asked by patients about anesthesia.
Methods
The query “patients’ questions about anasthesia” was searched on Google (www.google.com). A thorough review of “frequently asked questions” sections of numerous clinics was documented. Common questions were identified through a review of frequently asked questions sections on anesthesia-related clinic websites. Question selection was performed by the study authors, all of whom are anesthesiology and reanimation specialists with long-standing clinical experience and academic appointments. The same group of anesthesiologists subsequently evaluated the ChatGPT responses to ensure domain-specific consistency and expertise. To ensure reproducibility, websites were included if they provided publicly accessible, patient-facing educational content related to anesthesia or perioperative care. Questions addressing general anesthesia concepts, perioperative safety, preparation, and recovery were included, whereas highly procedure-specific or institution-specific questions were excluded. The final set of 22 questions was predefined prior to ChatGPT evaluation, and no questions were modified for wording or language after selection.
The questions were submitted to ChatGPT using the GPT-4-turbo model
The rating scale assigns scores of 1 to 4:
“Excellent response not requiring clarification": Responses did not include any information that contradicted current literature. “Satisfactory requiring minimal clarification": Responses requiring minimal clarification lacked additional information or detail. “Satisfactory requiring moderate clarification": Responses requiring moderate clarification had outdated or irrelevant information. “Unsatisfactory requiring substantial clarification": Responses had either incorrect or overly generalized information that could be misinterpreted.
In this study, each of the 22 questions posed to ChatGPT was evaluated by five independent anesthesiologists and reanimation specialists. All of the anesthesiologists and reanimation specialists who evaluated the ChatGPT responses had over 20 years of professional experience. To determine the inter-observer agreement, the intraclass correlation coefficient (ICC) was calculated using a two-way random-effects model with absolute agreement (ICC[2,1]). This method is suitable for assessing consistency among multiple raters evaluating the same set of items. The ICC was selected to quantify inter-rater reliability among multiple evaluators rating the same set of responses. A two-way random-effects model with absolute agreement was chosen because the raters were considered representative of a broader population of clinicians, and because absolute agreement rather than consistency was of primary interest.
Descriptive statistics were calculated using mean values with corresponding standard deviations, as all ratings were complete and no missing data were observed. Inter-rater reliability was interpreted according to commonly used thresholds, with ICC values <0.50 indicating poor reliability, 0.50–0.75 moderate reliability, and >0.75 good reliability. Statistical analyses were performed using SPSS software (version 29.0; IBM Corp., Armonk, NY, USA).
Results
The questions and answers of ChatGPT 4.0 are shown in Table 1.
Frequently asked questions about anesthesia and answers from ChatGPT.
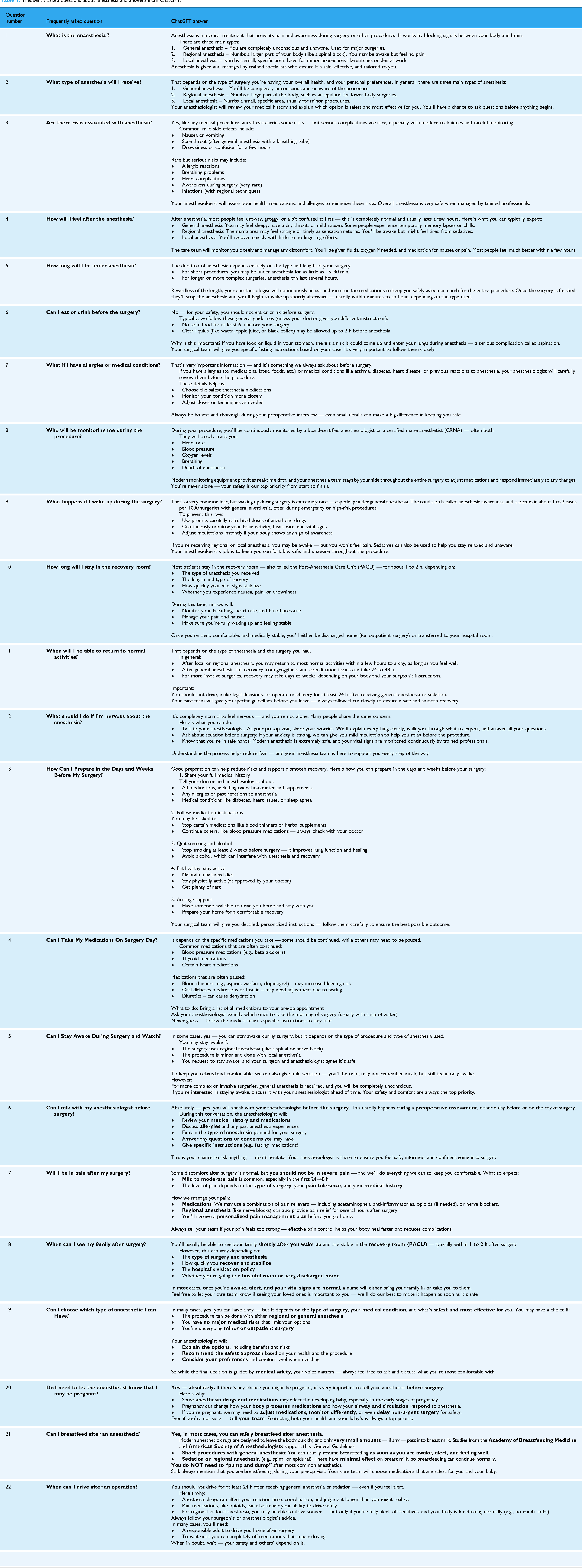
A total of 22 frequently asked questions were submitted to ChatGPT, and each response was independently evaluated by five anesthesiology and reanimation specialists using a 4-point Likert-type scale (1 = Excellent, 2 = Satisfactory with minimal clarification, 3 = Satisfactory with moderate clarification, 4 = Unsatisfactory). This resulted in 110 individual ratings.
Analysis of the rating distribution revealed that 61.8% of the assessments were classified as excellent (score = 1), 32.7% as satisfactory requiring minimal clarification (score = 2), and 5.5% as satisfactory requiring moderate clarification (score = 3). Notably, no responses were rated as unsatisfactory by any evaluator.
The average score across all questions ranged between 1.0 and 2.0, indicating generally high-quality outputs. Reviewer-wise analysis demonstrated that the mean scores provided by individual evaluators varied between 1.27 and 1.73, suggesting modest variability in rating strictness among assessors.
To assess inter-observer agreement, the ICC[2,1] was calculated using a two-way random-effects model. The resulting ICC value was 0.25, indicating poor to fair reliability among raters. The ICC value was 0.25, indicating poor to fair agreement among reviewers. This suggests that while reviewers shared some consistency in their evaluations, there were notable individual differences in scoring across questions.
The average ratings across reviewers were as follows: Reviewers 1 - 1.27, Reviewers 2 - 1.64, Reviewers 3 - 1.64, Reviewers 4 - 1.41, and Reviewers 5 - 1.73. These results indicate that while the majority of evaluators rated ChatGPT's responses positively, there was a modest level of variation in stringency among reviewers.
The average answers given by the evaluators to the questions are shown in Table 2.
Average evaluation scores given by anesthesiology and reanimation specialists for each question answered by ChatGPT.

Discussion
The most important finding of this study is that ChatGPT provides satisfactory and useful answers to frequently asked questions by patients about anesthesia, which is a very intensively applied procedure, and supports other examples in the literature that it can be used for patient education.
Yeo et al. evaluated the effectiveness of ChatGPT in answering questions from patients with cirrhosis and hepatocellular carcinoma and showed that the artificial intelligence application can be used as an additional information tool to improve outcomes for patients and physicians. 9 In another study investigating the role of ChatGPT in patient education in obstructive sleep apnea, a common disease affecting sleep, it was shown to provide generally appropriate answers. 10 Alqudah et al. evaluated the effectiveness of ChatGPT in the field of ophthalmology 11 this study, it was emphasized that the artificial intelligence application answered the questions in this field with moderate accuracy and reproducibility and that certain improvements are needed to be used in patient education. Almagazzachi et al. evaluated the use of ChatGPT in patient education on hypertension, which is a global epidemic affecting almost one third of the adult population; it was stated that artificial intelligence applications should be under human supervision and control in order to provide accurate and reliable information to patients in this way. 12 Frequently asked questions about a surgical procedure such as hip arthroscopy, which patients frequently and frequently ask questions, were evaluated by 2 high-volume hip arthroscopists and it was stated that they answered the questions with satisfactory accuracy. However, the authors found incorrect information especially in some questions and emphasized that caution should be exercised when using ChatGPT for patient education about hip arthroscopy 13 effect of ChatGPT on the frequently asked questions of patients about some orthopedic surgeries has also been studied in the literature and it has been shown that it can produce satisfactory answers.14,15 Studies on ChatGPT in most disciplines in medicine are increasing day by day in the literature. Kuo et al. evaluated the answers of ChatGPT to common patient questions related to anesthesia by 3 different board certified anesthesiologists and emphasized that artificial intelligence performed similarly to anesthesiologists in terms of general quality, but they should not be used independently and may be useful with supervision. 16 In the current study, the authors had anesthesia and reanimation specialists with more than 20 years of experience evaluate the responses of ChatGPT to frequently asked questions about anesthesia by patients and showed that ChatGPT was able to provide generally satisfactory results to the results of patients, but it was found that there was a moderate difference especially between the evaluators. In the light of this information, our current study shows that the use of artificial intelligence applications in patient education, just like other studies in the literature, can be most effective when used under the control of physicians and healthcare professionals.
Our findings can be directly compared with previous studies evaluating the quality of ChatGPT responses in medical contexts. For example, Kuo et al. evaluated the performance of ChatGPT-3.5 across more than 100 medical questions and reported that while most responses were generally acceptable, a substantial proportion required clarification or contained incomplete information. 16 In contrast, in the present study using GPT-4, over 60% of responses were rated as excellent, with no responses classified as unsatisfactory. This comparison suggests that newer iterations of large language models may demonstrate improved response quality, particularly for patient-focused educational content. Although differences in study design and rating frameworks limit direct numerical comparison, our findings support the notion of progressive performance improvement with model advancement from GPT-3.5 to GPT-4.
This study has several limitations. First, the evaluations were conducted exclusively by five anesthesiology and reanimation specialists. While their medical expertise is indisputable, their specialty may influence how they interpret and prioritize information in responses related to anesthesia-related patient education, potentially affecting the generalizability of the results. Second, the number of evaluated questions was limited to 22, which may not fully reflect the breadth of frequently asked patient questions across different subspecialties. Third, although the use of a 4-point Likert-type scale provided structured scoring, the inherently subjective nature of qualitative evaluations may contribute to variability in interpretation, as reflected in the low inter-rater agreement (ICC = 0.25). Lastly, only a single AI model (ChatGPT-4.0) was assessed without comparison to alternative platforms or versions, limiting the scope of inference.
Conclusion
ChatGPT-4.0 was able to provide generally high-quality answers to frequently asked patient questions, as evaluated by five anesthesiology and reanimation specialists. Most responses were rated as excellent or satisfactory with minimal clarification. These findings suggest that ChatGPT may serve as a supportive tool in patient education. However, the moderate variability in scoring among reviewers highlights the need for professional oversight when using AI in clinical communication.
Footnotes
Acknowledgements
None.
Human ethics and consent to participate
Not applicable.
Consent for publication
All authors accept that.
Author contributions
YA conceptualized and designed the study. YA, EE, HG, TG, OK, and LO contributed to data collection and question selection. YA and EE performed data analysis and interpretation. YA drafted the manuscript. All authors critically reviewed the manuscript for important intellectual content and approved the final version.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and materials
All data and materials are available. The datasets used during the current study are available from the corresponding author (YA) on reasonable request and after ethical permission.
Declarations
We confirm that all experiments were performed in accordance with the Declaration of Helsinki.