
Abstract
Objective
Gestational diabetes mellitus (GDM) is one of the most common pregnancy complications. Electronic health records (EHRs) promise GDM risk prediction, but missing data poses a challenge to developing reliable and generalizable risk prediction models. This study aims to address the problem of missing EHR data in GDM prediction before 12 weeks gestation.
Methods
A total of 5066 women with singleton pregnancies, aged 18 to 50, were included in this retrospective study. This study evaluated 6 imputation methods, combined with 4 classification machine learning models. The evaluation encompassed downstream predictive performance, robustness to variable missingness, ability to restore original data distribution, and influence on feature selection based on 10-fold cross-validation.
Results
Our findings revealed a significant improvement in model performance with imputation. When using the top 30 features, logistic regression (LR) with multivariate imputation by chained equations using classification and regression trees (mice) achieved the highest area under the receiver operating characteristic curve of 0.6899, compared to 0.6336 for the LR model without imputation. Mice also led to the best average performance across prediction models and yielded the most accurate restoration of the original data distribution. LR models trained on data imputed by mice remained the most robust across varying levels of missingness. The classification algorithm primarily accounted for differences in predictive performance. In addition, we identified 18 key features for early GDM prediction in the Chinese population.
Conclusion
This study demonstrates the critical role of imputation in improving the performance and fairness of GDM prediction models. The findings provide practical guidance for integrating imputation into clinical machine learning pipelines.
Keywords
Introduction
Gestational diabetes mellitus (GDM) is abnormal glucose tolerance with onset or first recognition during pregnancy 1 and is considered the most common pregnancy complication. 2 GDM affects approximately 14% of pregnancies worldwide and the prevalence continues to rise,1,3 causing a high disease burden globally. 4 GDM has long been associated with more obstetric and neonatal complications, such as hypertensive disorders of pregnancy, fetal macrosomia, and even long-term metabolic diseases in both the mother and her offspring.5,6
It is recommended to screen for GDM between 24 and 28 weeks of gestation by the International Association of Diabetes and Pregnancy Study Groups (IADPSG). 7 However, early detection and intervention before 20 weeks’ gestation prevents emergency cesarean section 8 and adverse neonatal outcomes, 9 while later diagnosis of GDM is associated with more obstetric complications. 10 High-risk groups benefit more from early detection and intervention.9,11
Despite the benefit of GDM early detection, performing an oral glucose tolerance test (OGTT) before 24 weeks is not a recommended approach. Limited evidence supports the efficacy of OGTT screening before 24 weeks among the population. 7 Moreover, the OGTT procedure is burdensome, requiring pregnant women to wait for 2 hours with blood glucose measurements taken at 1-hour intervals. As a result, many do not complete the screening globally. 12 The academic community has yet to establish a consensus on more convenient screening approaches. 7
Electronic health records (EHRs) offer a vast data source that has the potential to improve early diagnosis and treatment of GDM. EHR-based screening can help identify high-risk pregnant women who would benefit from early OGTT testing, reducing unnecessary tests for low-risk individuals. 13 However, missing data within EHRs is a major challenge hindering the development of reliable and generalizable risk prediction models. Missing data is a common situation in real-world clinical settings. 14 For instance, a real-world EHR dataset has a mean missing rate of 74.6%. 15 However, current studies on GDM prediction rarely mention how to handle missing values, 16 which either deleted all missing cases 17 or simply used one imputation method. 18 Unevaluated imputation can introduce bias and limit the applicability of AI models in clinical settings.19,20 This is particularly concerning for equity, as patients with incomplete data may be excluded from risk prediction, potentially exacerbating existing health disparities. 21
In this study, we investigated the use of imputation techniques to improve the reliability and accuracy of real-world GDM prediction. This study presents a systematic and comprehensive evaluation of imputation methods, ranging from traditional to advanced techniques. We evaluated imputation methods’ downstream predictive performance, robustness to variable missingness, ability to restore original data distribution, and influence on feature selection, to demonstrate the reliability of evidence derived from imputed datasets. Six imputation methods were tested, including mean-mode imputation, K-nearest neighbor (KNN) imputation, two kinds of implementations of multivariate imputation by chained equations (MICE), and two deep learning-based models: multiple imputation with denoising autoencoders (MIDAS) and generative adversarial imputation nets (GAIN). Following data imputation, we applied four supervised learning models to assess their effectiveness in early GDM prediction, including random forest (RF), logistic regression (LR), light gradient boosting machine (LGBM), and extreme gradient boosting (XGB).
GDM risk models and missing-data imputation
GDM risk models
A variety of predictive models for GDM have been proposed, typically using risk factors available in early pregnancy or even preconception. Predictive models often include maternal age, BMI, prior GDM, family history of diabetes, and early glucose.22,23 Machine learning methods have been applied in recent years to improve prediction. Tree-based models and regression models are common model choices. Zhang et al. found that ML models across 25 studies attained a pooled area under the receiver operating characteristic curve (AUC) of 0.8492 for GDM prediction. 22 However, the performance of some models may be overestimated due to insufficient validation with independent test sets.24,25 A study externally validated 12 prediction models in a cohort of 3723 participants, with C-statistics ranging from 0.67 to 0.78. 26 Among individual studies, Cubillos et al. developed 12 ML models on a cohort of 1611 women, achieving a high sensitivity of 0.82 and AUC of 0.81 using data collected between the 4th and 20th weeks of pregnancy. 19 They enhanced model performance with expert-guided data augmentation. Zaky et al. reported an ensemble model using first-trimester data of 138 pregnant women, which reached around 89% accuracy. 27 The inclusion of novel biomarkers, such as HOMA-IR and NT-proBNP, may have contributed to this enhanced performance. In summary, existing GDM prediction models suggest that first-trimester variables can yield moderate discrimination.
Missing-data imputation in EHRs
EHR-based studies routinely confront missing data. Missingness can arise because tests are ordered selectively or patients skip visits, which often is not random but correlated with underlying health status. 28 In GDM and other clinical prediction research, standard practice has been to exclude incomplete records or to drop highly incomplete features. For example, in one recent retrospective study of antenatal records, any pregnancy with missing “critical” variables was discarded and features with >20% missingness were removed entirely. 29 Such deletion reduces statistical power and can bias results if the missingness is informative. By contrast, a range of imputation methods has been developed to recover incomplete data. Traditional approaches include mean-mode imputation, KNN, and MICE. More sophisticated techniques include machine learning, deep learning, etc. 30 For instance, Beaulieu-Jones and Moore demonstrated that a deep autoencoder yielded more accurate imputed values and improved disease prediction compared to standard multiple imputation in a clinical dataset. 31 However, one study showed that simpler methods like KNN can achieve results comparable to deep learning. 30 No single approach is universally superior. Developing optimal predictive models may require testing the effects of different imputation methods on the data. Meanwhile, this evaluation based on real-world data fills a gap in the literature where imputation studies are often reliant on synthetic datasets with artificial missingness. 32 It highlights the practical effectiveness of imputation in a clinical context.
Methods
Overview of methodological workflow
Figure 1 illustrates the overall methodological framework of this study. Data collection and preprocessing were followed by a 10-fold cross-validation partitioning. We evaluated existing LR models as baselines and developed novel prediction models based on data imputation. Both baseline and newly developed models underwent cross-validation. Feature selection was performed through statistical tests or machine learning-based methods. The impact of varying the number of selected features on prediction performance was examined (see the right part of Figure 1). The impact of varying the number of features on prediction accuracy was then evaluated. Subsequently, multiple classification models were trained and evaluated, with Bayesian optimization for hyperparameter tuning. Additional analyses were conducted to assess the impact of imputation strategies on data distribution, downstream performance, feature ranking, and interpretability. Subgroup analysis based on the number of missing variables per case was also included.
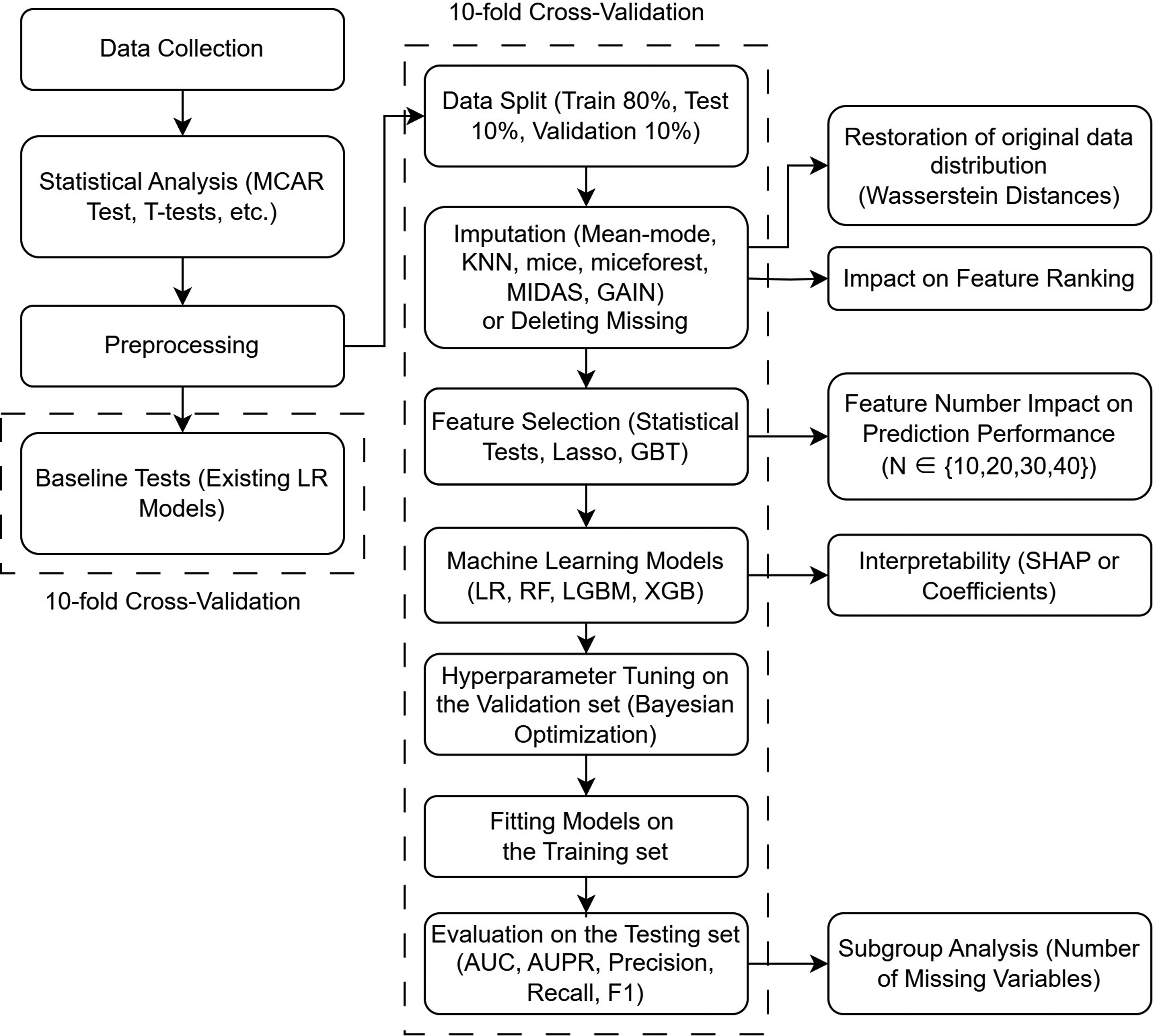
Workflow of model development and evaluation.
Data collection and preprocessing
This retrospective study collected data from pregnant women who delivered at Peking Union Medical College Hospital (PUMCH) in Beijing, China, from July 1, 2020, to June 30, 2022. A total of 5409 women with singleton pregnancies, aged 18 to 50 years, were identified. Our inclusion criteria included: (a) registration for perinatal care at PUMCH, (b) single pregnancy, (c) early pregnancy (at 0–12 weeks gestation). Our exclusion criteria were: (a) a history of type 1 or type 2 diabetes (N = 128), (b) failure to participate in 75 g OGTT screening within 24–28 weeks or loss of 75 g OGTT data (N = 215). The final dataset consisted of 5066 individual cases. The gold standard for GDM diagnosis was based on the International Association of Diabetes and Pregnancy Study Groups (IADPSG) guidelines. 7
As we used anonymized and deidentified data and did not constitute human research, the need for written informed consent was waived by the Ethics Review Board of the PUMCH due to the retrospective nature of the study. This study was approved by the Ethics Review Board of Peking Union Medical College Hospital, Chinese Academy of Medical Sciences (I-22PJ122). All procedures were performed by the Declaration of Helsinki.
The predictor variables comprised clinical and demographic parameters obtained from maternal EHRs: (a) basic characteristics, including maternal age, parity, and gravidity, recorded in pregnancy files; (b) physical measurements, including height and weight before pregnancy; (c) maternal medical history, including smoking, drinking, history of abnormal pregnancy, abortion, GDM, macrosomia, and polycystic ovary syndrome; and (d) family history of hypertension and diabetes. Laboratory tests included: (a) liver function tests, (b) renal function tests, (c) fasting blood glucose levels, (d) lipid metabolism tests, (e) thyroid function tests, (f) complete blood count, and (g) nutritional tests for iron and iodine.
The dataset was preprocessed to improve the overall performance. First, new categorical variables were introduced into our dataset. Categorical variables were created to indicate gravidity (history of pregnancy), parity (history of childbirth), advanced maternal age (35 years old and over), and pre-diabetes (fasting plasma glucose ≥ 5.1 mmol/L). 7 Body mass index (BMI) was categorized based on Chinese obesity standards 33 into four groups (0, 1, 2, 3). Then, non-continuous and non-binary variables were one-hot encoded to improve compatibility with imputation models like MIDAS. Continuous variables were standardized for better imputation and data comparability. To avoid excessive bias, we deleted 7 features with a missing rate greater than 80%, including HbA1C, TSAT, TIBC, Fe, GA%, Hcy, and SF. After preprocessing, the resulting dataset comprised 93 features (maximum missing data rate: 75.25%) and 926 complete cases (no missing data), hereafter referred to as the “no-missing dataset.”
Statistical analysis
Little's missing completely at random (MCAR) test is used to determine whether the missing data are missing completely at random by IBM SPSS Statistics for Windows, version 25.0 (Armonk, NY: IBM Corp). The Python package SciPy (https://scipy.org/) running on Python 3.9 was employed for the following statistical analysis. Normality tests were conducted based on the D’Agostino and Pearson test. For continuous variables with a normal distribution, the t-test was used for comparison. For non-normally distributed continuous variables, the Mann–Whitney U test was applied. Categorical data were analyzed using the χ2 test. The Friedman test was used to examine whether different imputation methods show significant differences in GDM prediction performance.
Workflow
Before developing our own models, we tested two available logistic regression models proposed in previous literature as baselines. They were both conducted on Chinese people, consistent with our sample.18,34 The baseline tests serve two purposes: (a) to highlight differences in data distribution across studies, which represents a primary limitation in the generalization of medical AI applications, 35 and (b) to demonstrate the impact of missing data on predictive modeling. We excluded cases with any missing variables for the two models, leading to a significant reduction in the size of both the training and test sets. We trained the two models separately using variables from both models on our data. For these two models, we used 10-fold cross-validation the same as with machine learning models. The AUCs of the two models are reported in the “Result” section.
To prevent any potential data leakage, we strictly segregated the training and test sets before the imputation phase. 36 The original data was randomly divided into a training set and a test set at a 90:10 ratio. All imputation models were fitted on the training set without the target variable “GDM” and subsequently used to impute values in the test set. Then, 1/9 of the training set was randomly sampled as the validation set for parameter tuning. This resulted in a final split of 80% for training, 10% for testing, and 10% for validation. To ensure a fair evaluation of the imputation model's generalizability, we performed a 10-fold cross-validation outside the entire imputation-prediction process. 37 This approach effectively mitigates potential biases introduced by repeated imputation procedures. Unless otherwise stated, all evaluation metrics are averaged based on 10-fold cross-validation.
Imputation methods
The imputation methods assessed in this study comprised mean-mode imputation, KNN imputation, MICE, MIDAS, and GAIN. Thus, traditional methods, advanced methods and emerging deep learning methods are taken into account. Supplementary Table S1 provides the hyperparameter settings of imputation methods. For multiple imputation methods such as MICE, MIDAS, and GAIN, we generated five imputed datasets and develop a predictive model on each of them in one cross-validation loop. The final prediction for each individual was obtained by averaging the predicted probabilities across the models, in order to account for the uncertainty introduced by multiple imputation in accordance with Rubin's rules for combining estimates. 38
Mean-mode imputation uses the mean to fill in missing values for numerical features and the most frequently occurring category (mode) for categorical features. KNN imputation is based on the values of KNN in the observed data. Discrete variables are rounded. The Python package sklearn (http://scikit-learn.org) was used for Mean-mode and KNN.
The MICE method is one of the most commonly used methods to handle missing data.39,40 In this study, we chose two robust models, classification and regression tree (CART) and LGBM, to be used within MICE. We used the R package mice (https://CRAN.R-project.org/package=mice) and the Python package miceforest (https://pypi.org/project/miceforest/) to implement the two kinds of MICE. In this study, the two methods are referred to as “mice” and “miceforest,” respectively.
Multiple imputation with denoising autoencoders (MIDAS) is a fast multiple imputation method based on deep learning. MIDAS employs a class of unsupervised neural networks known as denoising autoencoders. Compared with conditional imputation, MIDAS provides higher accuracy while completing imputation much more quickly. We used the Python package MIDASpy for a rapid deployment. 41
Yoon proposed generative adversarial imputation nets (GAIN), which surpassed multivariate imputation methods such as missforest in multiple datasets. 42 Considering the potential of adversarial generative networks in imputation, we chose GAIN as another deep learning method. The Python package hyperimpute was used for GAIN. 43
Feature selection
Feature selection was conducted after imputation. We integrated three different methods to pick the most relevant features for prediction. The first method was a statistical approach. We employed t-tests, the Mann–Whitney U test, and the χ2 test to calculate p-values, which served as criteria for selecting significant features. Second, we used lasso regression to avoid collinearity problems, ranking feature importance based on the absolute values of the coefficients. Third, we used a machine learning method, gradient boosting tree (GBT), to evaluate feature importance. Feature selection was based on the average ranking of feature importance from the three methods. To reduce the dimensionality of the data after preprocessing, we selected the top N features, using values of N from the set {10, 20, 30, 40}. Adhering to the recommended minimum of 20 events per variable (EPV) for reliable model development, 44 our whole dataset (N = 5066) is sufficient to support the development of models comprising up to 40 features.
Machine learning models
We evaluated the performance of four widely used machine learning models after handling the missingness—logistic regression (LR), random forest (RF), LightGBM (LGBM), and XGBoost (XGB).45,46 For LR and RF, we utilized implementations from the scikit-learn library. LGBM was implemented using the LightGBM package (https://pypi.org/project/lightgbm/), while the XGBoost package (https://pypi.org/project/xgboost/) was used for the deployment of XGB. Hyperparameter tuning for all models was conducted using Bayesian optimization. Detailed hyperparameter optimization ranges are provided in Supplementary Table S2.
Evaluation
Various metrics were employed to assess imputation-based predictive model performance. We reported the AUC, the area under the precision-recall curve (AUPR), precision (P), recall (R), and F1-score (F1) for each experimental combination. All metrics were presented as cross-validated averages. The Youden index was used to determine the optimal cutoff values. We also repeated the experiments with the dominant predictor, “history of GDM,” excluded. This was done to prevent this complete feature from confounding the evaluation of imputation's impact on other variables and to enhance the generalizability of our findings.
Metrics commonly used to evaluate data reconstruction, such as mean absolute error (MAE) and mean squared error (MSE), were not applicable in this study due to the unknown true values in the original data. Given the discrepancy in case numbers between the fully complete subsets and the original dataset (926 vs. 5066), a fair evaluation of imputation methods might not be achievable using only the fully complete subsets. Therefore, we calculated the Wasserstein distances (WS distances) between the original and imputed data to evaluate the ability of imputation methods to recover the original distribution, that is, their fit to the data distribution. For methods supporting multiple imputations, distances were computed for each imputation replicate and pooled using arithmetic means. 38 WS distance allows comparison between lists of different lengths. A smaller WS distance indicates an easier transition between the two distributions. 47
We additionally conducted a subgroup analysis on the number of missing variables for each case in the test set to demonstrate the applicability of the imputation methods. The number of missing features per case ranged from 0 to 52, with a median of 6. Accordingly, we stratified the data into four subsets: [0, 3), [3, 6), [6, 9), and [9, 53), where each interval includes the lower bound but excludes the upper bound. For example, [0, 3) includes cases with 0, 1, or 2 missing features. The F1-score, recall, and precision were calculated using the cutoff values obtained from the whole test sets.
Finally, we tested how predictive performance changed with feature rankings provided by different imputation methods, while simultaneously trying to find a minimum effective subset of features. Narrowing down to a smaller subset of features benefits the decision-making process for clinicians, enhancing practicality and efficiency. The optimal prediction model in previous experiments was tested on the imputed dataset with the smallest WS distance, incrementally adding variables according to the rankings established in the feature selection step. We conducted 10-fold cross-validation, and for each fold, LR with fixed hyperparameters was performed on five multiple imputed datasets during the process. In the interest of interpretability, we reported the model coefficients, as the best prediction model was a LR model.
Result
Participants
We identified 1094 cases of GDM within our dataset, resulting in an overall incidence rate of 21.59%. When we considered only the subset with complete data (N = 926), the GDM incidence was 22.89%. Table 1 presents descriptive statistics and missing rates for variables that demonstrated statistical significance (p < 0.05), including 27 variables. The raw data had a maximum missing rate of 95.5% and an average missing rate of 17.92%. There were 13 variables with missing rates greater than 50%. Only 63 cases were complete. The p-value of Little's MCAR test was less than 0.001, which rejected the null hypothesis that the dataset was MCAR. The missing patterns of 10 variables (A-TPO, A-Tg, FT3, FT4, HDL-C, HbA1C, LDL-C, TC, TG, TSH) correlated with the value of GDM (1 representing diagnosed with GDM, 0 representing normal). Descriptive statistics and abbreviations for all 55 variables are shown in Table S3 of the supplementary material.
Variables with statistical significance (p < 0.05).

Note: PAB, prealbumin (mg/L); BMI, body mass index (kg/m2); GGT, gamma-glutamyl transferase (U/L); FPG, fasting plasma glucose (mmol/L); WBC, white blood cell count (109/L); PLT, platelet count (109/L); TG, triglycerides (mmol/L); HGB, hemoglobin (g/L); ALT, alanine aminotransferase (U/L); ALP, alkaline phosphatase (U/L); LDL-C, low-density lipoprotein cholesterol (mmol/L); TC, total cholesterol (mmol/L); NEUT%, neutrophil percentage (%); HbA1C, hemoglobin A1C (%); TIBC, total iron-binding capacity (μg/dL); uBLD, urine occult blood (an ordinal variable with an integer value from 0 to 4 depending on the concentration of urine occult blood); HDL-C, high-density lipoprotein cholesterol (mmol/L); uGLU, urine glucose (an ordinal variable ranging from 0 to 5 based on the concentration of glucose in the urine).
Baseline models
Two available prediction models were tested as the baselines on our dataset. Duo et al. trained LR models including “age,” “BMI,” “family history of diabetes,” “FPG,” “ALT/AST,” and “TG/HDL-C” (AUC = 0.825, N = 1289). 18 Guo et al. used fewer variables to construct the LR model, only using “age,” “BMI,” “family history of diabetes,” and “FPG” (AUC = 0.69, N = 6572). 34 Our data yielded worse results for both models (AUC = 0.6350, N = 1647 for Duo's and AUC = 0.6497, N = 4975 for Guo's). The larger dataset used by Guo et al. may partially explain the discrepancy with published results. The above results indicate that missing data seriously affects the performance of prediction models in clinical practice.
Imputation-based machine learning prediction
Table 2 provides the AUCs resulting from combinations of various imputation methods and prediction models. Based on the average AUCs across all models, miceforest imputation performed the best when feature number was set to 20, 30, and 40. The mean-mode method was better than the others when the number of features was 20, while mice imputation exhibited superior performance in all other feature number settings. The Friedman test showed that the differences among imputation methods were approaching significance (p = 0.3539).
GDM prediction AUC by imputation methods and machine learning models.

At the level of prediction models, LR consistently exhibited its advantages, as observed from the color fill in Table 2. When using the top 30 features, the LR with mice imputation reached the highest AUC of 0.6899, compared to 0.6336 for the LR model without imputation. The 20-feature LR with mean-mode obtained the second best AUC (0.6893) among all combinations. It is worth noting that the AUC of the LR without imputation declined with increasing numbers of features, even falling below the AUC of a baseline model at 20 features. This could indicate overfitting due to the small dataset size. While imputation significantly improved LR and LGBM, RF and XGB did not benefit much. The observed advantage in mice persisted even after excluding the dominant risk factor, “history of GDM” (see Supplementary Table S4), 48 indicating that imputation, rather than the non-missing dominant variable, primarily drove the improvement.
Given the optimal performance of the 30-feature group, subsequent evaluation concentrated on its remaining metrics (Supplementary Table S5). Analysis of performance metrics for the LR model with 30 features revealed that while imputation enhanced the average AUC, the best AUPR was achieved by LR trained on the no-missing dataset. RF trained on the no-missing dataset showed the best recall (0.7403) and F1-score (0.4577) among all the combinations. The RF model with GAIN imputation demonstrated superior performance in terms of specificity and precision, achieving values of 0.7629 and 0.3743, respectively. GAIN imputation yielded the best average specificity.
Subgroup analysis
The 30-feature group performed the best, so the subgroup analysis focused on its results. The corresponding average number of cases in each subset across the cross-validation folds was 133.9, 33, 339.7, and 42.1, respectively.
Figure 2 illustrates the changes in F1-score, recall, and precision across these subsets. On the whole, there was a loss of performance as the number of missing features increased. Different imputation methods exhibited similar patterns of fluctuation. However, the miceforest methods produced a distinctly curved upward trajectory for LR's recall and F1-scores. Furthermore, the miceforest consistently produced stable F1-scores. XGB exhibited notable sensitivity to the imputation methods and the number of missing variables. All methods had a precision peak in [3, 6) groups, likely because of the small sample sizes.

Influence of imputation strategy and missing value count on classification metrics.
Restoration of original data distribution
The WS distance was generated by comparing different imputed datasets to the original dataset. A single comparison for each variable generated a WS distance. Figure 3 shows that the 25th percentile and median of WS distances across all imputation methods were nearly identical. However, the 75th percentile and upper whisker differed substantially among the methods. Mice performed the best in terms of the interquartile range (IQR), suggesting that mice was more effective at estimating variables with high missing rates, as the WS distance is correlated with missingness. GAIN, KNN, and MIDAS performed worse than miceforest, while the mean-mode method performed the worst.

Wasserstein distance between original and imputed data distributions. Outliers are not shown.
In summary, the MICE-based methods achieved the best overall performance in approximating the distribution of the original dataset.
Features ranking and interpretability
LR outperformed all models and mice imputation demonstrated the best overall performance. We conducted tests on mice-imputed datasets to observe how the performance of this combination changed as the number of features varied. The feature importance rankings obtained from the feature selection step are shown in Supplementary Table S6. All rankings generated by imputation were similar, which means the feature importance rankings were not sensitive to the imputation methods. Only the ranking from the no-missing dataset differed significantly from the others, and led to worse downstream performance, as shown in Figure 4. We re-evaluated two baseline models using the same mice-imputed datasets. The LR model proposed by Duo et al. 18 exhibited an AUC of 0.6656 on the mice-imputed dataset and the model developed by Guo et al. 34 achieved an AUC of 0.6582. As the number of features increased, the average AUC slightly declined. Fewer features effectively predict early GDM. Figure 4 shows that the top 18 features identified by the mean-mode method were sufficient to bring the LR model close to its maximum performance. However, the AUC of the 18-feature LR model decreased to 0.6647 when cases with missing data were removed (N = 1315), highlighting the data enhancement capabilities of imputation. The regression coefficients based on mice-imputed datasets were aggregated and visualized as a boxplot in Figure 5. Since the dataset is standardized, these coefficients can be considered as the relative importance of features.

Average AUC of LR on the mice-imputed dataset using different feature rankings.

Box plot of coefficients from 10-fold cross-validation on the mice-imputed datasets. PAB, prealbumin; BMI, body mass index; GGT, gamma-glutamyl transferase; LDL-C, low-density lipoprotein cholesterol; FPG, fasting plasma glucose; WBC, white blood cell count; HGB, hemoglobin; NEUT%, neutrophil percentage; PLT, platelet count; TG, triglycerides; TC, total cholesterol; Cr, creatinine; uGLU_0.0, 1 represents no urinary glucose detected. 0 represents urinary glucose is detected.
Discussion
By jointly analyzing imputation approaches and downstream classifiers, this study assessed their combined influence on early GDM prediction performance based on incomplete EHR datasets. Mice achieved the highest AUC of 0.6899 and yielded the best data distribution restoration, consistent with previous findings.49,50 The LR model trained on mice-imputed data with an optimized feature set achieved the best performance among all experiments, with an AUC of 0.6901. Mice may be the preferred default method when its computational cost and the inherent uncertainty of multiple imputation are not primary concerns. Surprisingly, the mean-mode imputation with LR achieved the second best AUC (0.6893) and provided an effective feature subset, though mean-mode imputation caused greatest distributional bias. When the classifier was LR, the mean-mode method outperformed MICE-based methods when the top-20 features were using. This may result from that the mean-mode imputation is particularly suited for skewed distributions with high missing rates, where it is challenging for imputation algorithms to learn the data patterns. 30 The simple imputation method may also play a regularizing role, reducing variance by shrinking imputed values toward the mean, thereby preventing the model from overfitting. 49 The mean-mode method is generally not recommended because it leads to biased estimates of statistics. 51 Nevertheless, given its superior performance in downstream predictive tasks, the mean-mode imputation method may be considered acceptable for training and applying GDM prediction models. KNN is another competitive simple imputation method. When combined with LR, it yielded a slightly lower AUC than the mean-mode method but performed best in terms of specificity and precision, and provided a better fit to the data. Although GAIN imputation significantly improved specificity, its AUC performance was suboptimal. Generation-based imputation methods did not outperform traditional methods, potentially attributed to the relatively low dimensionality of our dataset compared to studies where generation models showed superior results.31,42,52 The models trained on the no-missing dataset demonstrated the highest average AUPR. The RF model trained on the no-missing dataset exhibited superior recall and F1-score compared to all other imputation-prediction method combinations. In practical applications, a complementary approach that combines the model trained with imputed data and the one trained without missing data can be considered to enhance overall predictive capability.
The classification method primarily accounted for the differences in predictive performance. Complex machine learning models, such as XGB, appeared more sensitive to noise introduced by imputation, leading to worse performance compared to traditional models like logistic regression with L2 regularization. XGB exhibited poorer performance with imputation methods that had larger Wasserstein distances (i.e. mean-mode imputation). These findings suggest that for datasets with high missingness, the choice of classifier should be made with caution.
The subgroup analysis demonstrates that LR with mice is robust to variations in the number of missing variables. In addition to mice's strong fitting performance, this robustness may be attributed to the feature selection stage applied to the imputed dataset, which balances the level of missingness and feature importance, thereby mitigating the impact of missing data in individual features. This finding supports the use of mice to enhance predictive models in clinical environments, where the extent of missing data can vary substantially across patient records. Integrating imputation into hospital risk prediction workflows holds promise for improving patient equity, given the widespread prevalence of missing data in clinical settings.
The effect of the number of features was analyzed based on mice imputation, identifying 18 key features for GDM prediction in the Chinese population. These features include age, personal and family disease history, physical examination findings, complete blood count, liver and kidney function parameters, and lipid-related biomarkers. Except for the last one, all features can be obtained from routine medical checkups, indicating the high practical applicability of the 18-feature model. The underperformance of the two external models may be attributable to earlier gestational age and regional differences. However, our results suggest that these gaps can be addressed using a few more features. Our results indicate that including more features can lead to overfitting when training on small datasets, but imputation can help mitigate this issue. It is recommended to consider simultaneously hematology, lipid profiles,53,54 liver function, and kidney function 55 when predicting the risk of GDM. This combination of factors provides models with good discriminatory ability, even in the absence of GDM history. Imputation facilitates the inclusion of a greater number of informative features in prediction models with large sample sizes, further underscoring its necessity in clinical predictive modeling.
Notably, significant differences were observed in the feature importances derived from the imputed dataset compared to the dataset without missing values. Consequently, the feature ranking obtained from the dataset without missing values could not maximize downstream model performance when applied to the imputed dataset. This highlights the impact of the bias introduced by missing data and underscores the importance of conducting sensitivity analyses on prediction models to ensure reliable results. 14
Our primary contribution lies in demonstrating the effectiveness and necessity of integrating imputation into EHR-based GDM prediction through extensive analyses. We also provide practical recommendations on optimizing the synergy between imputation methods and predictive modeling. However, this study has some limitations. Firstly, as a single-center retrospective study, it was constrained by limited sample size and diversity, and we were unable to perform external validation. Secondly, while we conducted various experiments, the highest AUC achieved is 0.6901, below the commonly accepted threshold of 0.7 for moderate diagnostic ability. 56 Achieving significantly higher discrimination might require a larger sample size or additional clinical, genetic, or microbiomic features than were available in this study.27,57,58
Building upon these findings, several directions warrant future investigation to advance robust and equitable GDM prediction systems. Future research should assess the capability of more advanced imputation methods, such as pre-trained models, 59 in enhancing prediction. Next, future work should focus on building integrated predictive frameworks that combine conventional clinical features with emerging biomarkers. 13 Subsequently, external validation should be conducted across multiple institutions and populations to evaluate the generalizability and fairness of imputation-based predictive models. Finally, the practical feasibility of deploying imputation-integrated prediction workflows into clinical decision support systems requires exploration, including aspects such as computation time, clinician trust, and long-term maintenance. 60
Conclusion
This study demonstrates that effective imputation of missing data significantly enhances early prediction of GDM and improves patient equity. During imputation-based machine learning model development, careful model selection is required to prevent degradation, such as the decline in XGB performance observed in this study. In contrast, imputation consistently improved the AUC of LR for GDM prediction. MICE-based methods remain a reliable default when computational resources are not a constraint. Mean-mode imputation, despite its statistical simplicity, shows strong predictive performance when paired with LR. The identification of 18 key features highlights the importance of routine medical checkups in early GDM prediction. Imputation enhances the model's capacity to incorporate relevant features, improving the predictive performance and robustness of the risk assessment.
In summary, these findings provide empirical guidance for addressing missing data in GDM model development. Furthermore, they inform future research into imputation methodologies and demonstrate the potential of integrating imputation into clinical prediction models.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251352436 - Supplemental material for Enhancing early gestational diabetes mellitus prediction with imputation-based machine learning framework: A comparative study on real-world clinical records
Supplemental material, sj-docx-1-dhj-10.1177_20552076251352436 for Enhancing early gestational diabetes mellitus prediction with imputation-based machine learning framework: A comparative study on real-world clinical records by Leyao Ma, Lin Yang, Yaxin Wang, Jie Hao, Yini Li, Liangkun Ma, Ziyang Wang, Ye Li, Suhan Zhang, Mingyue Hu, Jiao Li and Yin Sun in DIGITAL HEALTH
Supplemental Material
sj-pdf-2-dhj-10.1177_20552076251352436 - Supplemental material for Enhancing early gestational diabetes mellitus prediction with imputation-based machine learning framework: A comparative study on real-world clinical records
Supplemental material, sj-pdf-2-dhj-10.1177_20552076251352436 for Enhancing early gestational diabetes mellitus prediction with imputation-based machine learning framework: A comparative study on real-world clinical records by Leyao Ma, Lin Yang, Yaxin Wang, Jie Hao, Yini Li, Liangkun Ma, Ziyang Wang, Ye Li, Suhan Zhang, Mingyue Hu, Jiao Li and Yin Sun in DIGITAL HEALTH
Footnotes
Acknowledgments
The authors would like to thank the participants of this study, as well as the clinicians and information staff at Peking Union Medical College Hospital for the data collection in this study.
ORCID iDs
Ethical considerations
This study was approved by the Ethics Review Board of PUMCH, Chinese Academy of Medical Sciences (JS-2763).
Consent to participate
As we used anonymized and deidentified data and did not constitute human research, the need for written informed consent was waived by the Ethics Review Board of the PUMCH due to the retrospective nature of the study.
Author contributions
Conceptualization was done by LKM, YS, and JL; methodology was accomplished by LY, JH, YXW; formal analysis and data curation were done by LYM, YNL, ZYW, and SHZ; writing—original draft preparation by LYM, MYH and LY; writing—review and editing by LY, JH and YXW; supervision by LKM, YS and JL.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the China Medical Board (CMB-OC, Q629500), Science and Technology Project of Beijing (Z231100004623010), the Chinese Academy of Medical Sciences (CAMS) Innovation Fund for Medical Sciences (CIFMS; grant 2021-I2M-1-056, and 2021-I2M-1-023).
Data availability statement
The datasets generated and analyzed during the current study are available from the corresponding author on reasonable request.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantor
Dr Jiao Li and Dr Ying Sun.
Supplemental material
Supplemental material for this article is available online.
Peer review
None.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.