
Abstract
Objective
Machine learning (ML) has enabled healthcare discoveries by facilitating efficient modeling, such as for cancer screening. Unlike clinical trials, real-world data used in ML are often gathered for multiple purposes, leading to bias and missing information for a specific classification task. This challenge is especially pronounced in healthcare because of stringent ethical considerations and resource constraints.
This study proposed an integrated approach to enhance the quality of health evidence from a classification task for predicting Medicare's Diagnosis-Related Groups of ischemic heart disease (IHD) patients.
Methods
Eligible participants were identified from the Medical Information Mart for Intensive Care IV (MIMIC IV), a publicly available hospital database. Six ML models were selected for model triangulation. Sequential triangulation was employed via Local Process Mining (LPM) and Qualitative Comparative Analysis (QCA).
Results
A total of 1545 IHD hospitalizations from 916 patients were identified from the MIMIC IV. Eight health process features were identified through LPM aligned with clinical knowledge. The correlation coefficients for process features, ranging from 0.24 to 0.42, are higher than those for non-process features ranged from 0.02 to 0.36. A total of 56 unique combinations were identified from the QCA, with 28 configurations having raw coverage lower than 1.0%. The overall model performance (i.e. weighted F1 and area under the curve scores) increased after adopting this integrated approach. The proportion of cases misclassified by any of the six models decreased by 47% after incorporating process features (from 5.29% to 2.91%) and further decreased to 0.0% after applying the QCA solutions.
Conclusion
The integrated approach demonstrates its ability to enhance quality of a classification task through its clinical relevance, improved model performance, and reduced case-level error rates. However, more scalable QCA methods are needed for larger datasets. Developing health process feature engineering for broader applications can be a future direction.
Keywords
Highlights
Current classification tasks in machine learning that use real-world health data may be subject to noise, missing information, and bias. The quality of empirical insights derived from these tasks influences the quality of health evidence, as reflected in its validity and reliability.
This study proposed an integrated approach to enhancing the quality of health evidence in a classification task. It offers opportunities to enhance validity at both the case and variance levels, as well as to synthesize individual, episodic, and temporal information to increase internal validity. The use of publicly available real-world health data largely increased the reliability (i.e. reproducibility) of health evidence.
We showcased how this proposed approach could improve the predictive quality of classifying Medicare's Diagnosis-Related Groups, which serve as a hospital price estimator, for patients with ischemic heart disease.
As a result, the proposed approach enhanced quality through its clinical relevance, improved model performance and reduced case-level error rates.
Introduction
Recent technological progress, particularly in machine learning (ML) and deep learning (DL), has opened avenues for healthcare discoveries by enabling efficient model generation, especially in classification tasks such as cancer screening 1 and disease diagnosis. 2 However, unlike medical trials—particularly randomized controlled trials—which are conducted with rigorous protocols, study designs, and targeted data collection methods, the data used in ML and DL models are often sourced from public data that are collected for multiple purposes. These real-world data contain errors, noise, and missing information, which can lead to erroneous conclusions for specific classification tasks. This challenge is especially pronounced in healthcare because of stringent ethical considerations and resource constraints. 3
Patient-centered care emphasizes the importance of addressing the diversity of individual cases. However, current model generation methods, such as cross-validation, focus on the variance level, which might overlook records collected with a high proportion of missing information or bias, 4 and force them into a class in the testing set. The quality of healthcare-specific classification tasks has traditionally focused on overall performance on average, such as F1 score and accuracy, without sufficient attention to case-level variations in realistic clinical practice. 5 The goal of minimizing discrepancies between predicted class and observed data can overlook the varied impacts and consequences on individual patients. For example, the misclassification of patients with unique care needs, such as abandoned children without complete medical histories, is often underestimated by current quality metrics. A systematic approach that evaluates case-level outcomes while effectively controlling for bias is essential. The triangulation approach, which involves the use of various techniques and multiple data sources to verify the reliability and validity of research outcomes,6–8 offers a unique opportunity to synthesize evidence at both the variance and case levels.
In this study, we propose a triangulation approach to enhance the quality of health evidence in a classification task from case-based reasoning as well as variance-level process feature engineering. To demonstrate its capabilities, we conducted a case study using real-world hospital records.
Ischemic heart disease (IHD) is one of the leading causes of hospitalizations in the USA. 9 High costs have hindered low-income patients from adhering to relevant treatments. 10 Improved cost estimation would benefit dynamic management by health professionals. 11 Hospital providers receive fixed reimbursement amounts for services under the Diagnosis-Related Groups (DRGs) payment system, making DRG codes essential for cost monitoring and resource allocation. 10 However, coding is typically performed retrospectively, after discharge. Classification on the basis of patients’ electronic health records would support earlier cost management.10,11 We demonstrated how the proposed approach could identify “difficult-to-treat” cases while enhancing overall model performance in predicting DRG classifications for IHD patients.
Methods and materials
Eligible participants and their common process features were identified from the Medical Information Mart for Intensive Care IV (MIMIC IV) version 2.2, a publicly available hospital database containing over 65,000 de-identified patient records from the Beth Israel Deaconess Medical Center in Boston.12–14 Over 13 tables were used for this analysis, including “admissions_table”, “d_icd_diagnoses”, “d_icd_procedures”, “d_labitems”, “diagnoses_icd”, “drgcodes”, “hpcsevents”, “labevents”, “patients_table”, “ICU_stays” and “datetimeevents”.
Nature of the study
The study is methodological in nature, with the goal of enhancing the quality and generalizability of health evidence in a given classification task within real clinical settings. The case study was conducted from 18 June 2023 to 17 July 2024 at the University of Sydney School of Computer Science Innovation Center.
Evidence synthesis via triangulation
Triangulation is a series of approaches that enhances the validity of health findings through the convergence of information and evidence from multiple perspectives (e.g. data sources, diverse points of view, and theoretical methodologies).6,8 Six widely employed ML models were selected for model triangulation. Sequential triangulation was employed via local process mining (LPM) 15 and qualitative comparative analysis (QCA),16,35 synthesizing sequential findings from both the case level and the variance level.
Eligibility criteria for participants
IHD patients aged 20 years and above who were eligible for Medicare claims with principal diagnosis codes I20-I25 (ICD-10-CM) were extracted from MIMIC IV. Patients from outpatient settings, as well as those transferred without an approximate discharge record, were excluded from the analysis.
Classification labeling and model building
Hospital separation refers to the process by which an episode of care for an admitted patient ceases. 38 The Medicare claim of each hospital separation for eligible participants was assigned a DRG code on the basis of U.S. Center of Medicare and Medicaid regulations. 17 Over 90 DRG codes were grouped into three broad categories: bypass group, percutaneous cardiovascular intervention (PCI) group and others (Supplementary Appendix 1). The DRG codes in each group represented similar financial burdens for IHD patients. The labels were assessed by a clinician with the aim of maximizing sample balance and clinical relevance. Six commonly used ML models were selected to perform this classification task: logistic regression (LR), k-nearest neighbors (KNN), random forest (RF), decision tree (DT), support vector machine (SVM) and linear discriminant analysis (LDA).
Data randomization (also known as data shuffling) was adopted to prevent bias introduced by the initial record ordering, followed by standardization to eliminate redundancies and inconsistencies in the feature space. Seventy percent of data were utilized as training data, and 30% of the remaining data were treated as testing data. Most records were assigned to the first two categories (bypass and PCI groups). Since ML classifiers tend to exhibit bias toward the majority class, potentially leading to poor classification of minority classes, 18 an oversampling technique 19 was employed to balance the class distribution in the “Other” group. This technique involves duplicating existing records rather than generating new records, thus avoiding the introduction of bias in subsequent analyses while ensuring model performance. Five-fold cross validation 39 was employed to evaluate the performance in the training set. Hyperparameter tuning 40 was adopted in model optimization for each model.
Event log generation and mining local health process feature
Patients’ activities, such as when medication is dispensed and how they are transferred within the ICU ward, provide valuable information that has not yet been fully utilized in ML classification tasks. The discovery and conversion of these features pose significant challenges. Process mining is a technique for discovering complex behavioral patterns by using event logs.
15
To minimize the noise contributed from incomplete patients’ trace, the index event started at hospital admission. The end of care is defined as either of the following scenarios:
Died in a hospital stay Died within one year after hospital separation Discharged from a hospital.
The timestamps of clinical and administrative activities, including hospital admission, procedures, selected lab tests and medication scheduling, were extracted for eligible episodes to generate an event log. For patients with multiple ICU stays, events in each ICU stay were assigned distinct indices. A series of ICU events, such as falls, respiratory arrest, unplanned line or catheter removal, were grouped and labeled as significant ICU events.
LPM is a widely employed process mining technique aimed at discovering common local paths within 3‒5 activities. 15 It was employed to discover common behaviors observed in eligible IHD patients. The mining algorithm was chosen for its feasibility of conversion to feature space compared with end-to-end models (i.e. from hospital admission to discharge). The maximum number of transitions in the LPMs was set as five activities to enable long local trace discovery. The number of LPMs to be discovered was set to 10 to maximize the computational efficiency. The pattern mining included sequence, concurrency, exclusive and loop operators in the search space of the mining procedure to enable coverage of the complex behaviors of the IHD care flow.
The extracted events with timestamps were converted from CSV format to XES, a tag-based language designed to capture system behaviors. 20 The log projections were performed via Hidden Markov models to address large resource requirements. The discovered local health processes were then transferred and added to feature space for the classification task.
Qualitative comparative analysis
QCA is a technique used to study how exposures interact as a causal recipe in causing a specific outcome at the case level, as well as to discover complex cases. 16 This technique has demonstrated its potential in medical informatics to predict risk and outcomes after traumatic brain injury. 35 This approach has been widely adopted to study counterfactual effects of selected study factors and partial dependencies, 16 demonstrating its suitability for identifying “difficult-to-classify” cases. The selected features, including the added process features, were calibrated into binary variables (1 or 0) to reflect the membership of each case with the outcome (the allocated class). “1” represented the occurrence of certain features and/or above normal ranges. For example, records with cardiac troponin level above 0.04 ng/ml have been converted to 1 to indicate abnormalities in troponin level. 21
A truth table was generated to describe the outcome for each possible combination of present and absent interventions. Logical minimization was used to systematically compare the truth table rows with sufficient combinations of conditions. The “difficult-to-classify” cases in this study were defined as those with raw coverage below 1.0%, minimizing the reduction in case numbers. The identified “difficult-to-classify” cases were excluded from the original set. The classification task was performed again after applying the QCA solution.
Evaluation
The evaluation of this integrated approach was assessed across three layers:
Quality of components, reflected in the performance of the LPM,
15
QCA
16
and classification model triangulation
8
Quality of task objectives, measured by model-based and case-level performance16,36 Quality of clinical evidence, assessed by the generalization of the application to complex real-life settings, tolerance of bias and predictive validity.
The quality of LPM features was evaluated from five criteria: Support measures how often the pattern described by the LPM is found in the event log (Equation (1)); Confidence is a ratio of the events in the event log of the activities that are described in the pattern belongs to incidences of the pattern (Equation (2)); Determinism indicates the level of predictability of future behaviors (Equation (3)). It reflects the average number of enabled transitions during replay of the pattern instances on the pattern; Language fit is defined as the ratio of behaviors allowed by the local process observed in the event log (Equation (4)); Coverage measures the frequency of events that can be identified in the log (Equation (5)). The overall performance of the LPM was measured using the weighted average of these metrics, known as the fitness score.
15




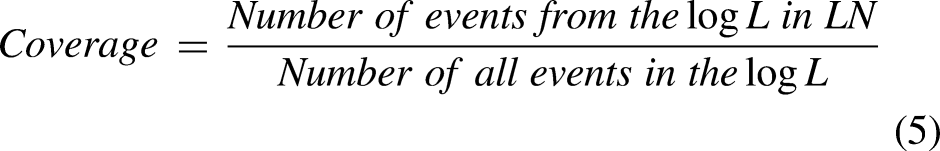
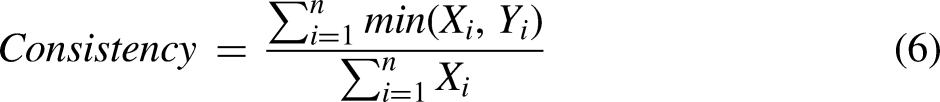

The importance of selected features with classification labels was evaluated via the correlation matrix both before and after adding process features. Traditional model evaluation metrics such as the area under the curve (AUC) and/or F1 score focus on the performance of individual models. In a multiclass task, the weighted AUC score is calculated by weighting the score of each group by its support, which is the number of true instances for each class label. The overall AUC score in this study is the average AUC of all possible pairwise combinations of the three classes. The weighted F1 score, regarded as a harmonic mean of the precision and recall, is calculated via Equation (8) and weighted by the number of true instances for each class label.
36

However, the nature of these metrics does not reflect performance on individual cases. A case-based measure—the proportion of errors—was used to calculate the proportion of cases that were never classified correctly by any of the six selected models. The performance was compared both before and after adding process features, as well as after applying the QCA solutions. The identified patterns were assessed on the basis of their clinical relevance, generalizability to complex real-life settings, tolerance to bias, and predictive validity.
The event log conversion and LPM were performed with the ProM plugin version 6.1, an open-source process mining software. 37 Event extraction, data preprocessing, analysis, classification model generation and visualization were performed in Python.
Results
A total of 916 eligible patients were identified from MIMIC IV (Table 1). Of these, 72.5% were males, and 27.5% were females. The overall average age at admission was 73 years, with no significant gender variation. A total of 1545 Medicare-claimed hospitalizations were extracted from eligible patients. The average hospital length of stay was 7.4 days for females and 7.5 days for males.
Baseline characteristics of eligible patients with ischemic heart disease (IHD).

Note. A total of 1277 records (82.7%) were allocated to Class 1 and Class 2. After oversampling, the cases were evenly distributed across the three categories, with approximately 30% in each category (Table 2).
The hospital length of stay in the study was not adjusted for leaving days because of a lack of relative information in the data.
Sampling size by classification group before and after sampling.
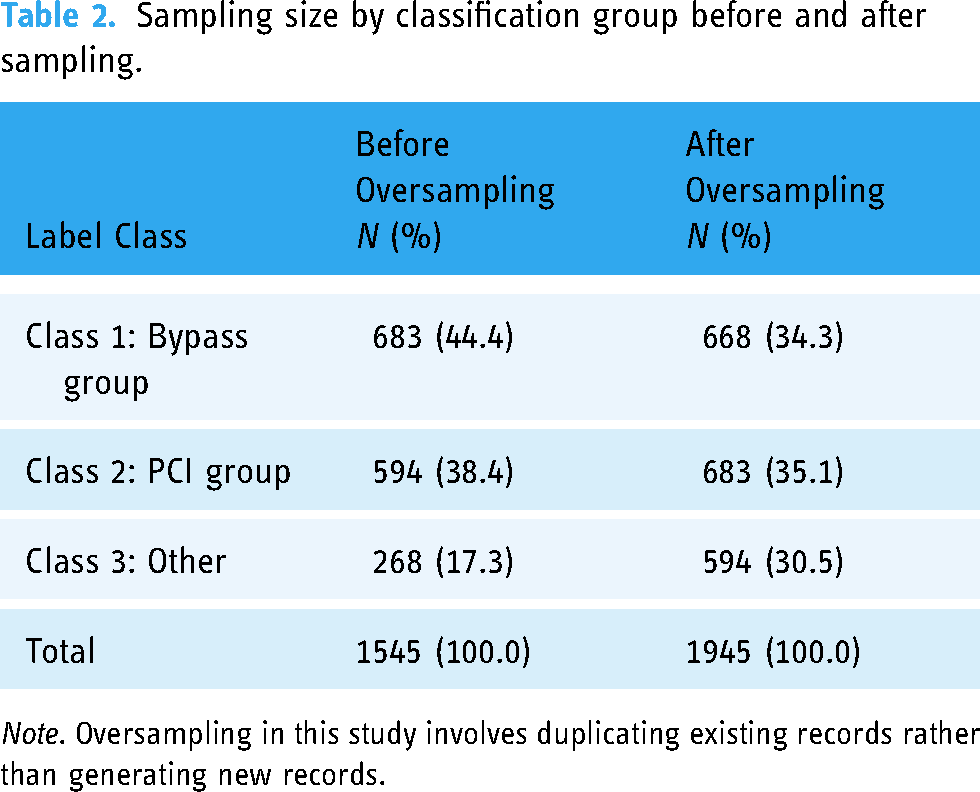
Note. Oversampling in this study involves duplicating existing records rather than generating new records.
Eight out of the 10 health process features were identified from the LPM after two processes that did not align with clinical facts were excluded (Table 3). The fitness score of the mined local processes ranged from 0.58 to 0.64. ICU stay and clinical imaging, such as X-ray, were identified as frequent clinical events in this cohort.
Local process mining and feature engineering.

Note. “Start” and “End” in the circles of each local process above represent artificial notations for the input place (i.e. the starting point of a local process) and the output place (i.e. the ending point of a local process). For activities with a duration, shown in rectangles, “Start” and “End” indicate the beginning and end time points of the activity.
The absolute correlation coefficients for process features, ranging from 0.24 to 0.42, were higher than those for non-process features, which ranged from 0.02 to 0.36 (Figure 1). The three local patterns “ICU_sig_event”, “Sig_event” and “ICU_ventilation” have the highest correlation coefficients with classification labels among those process features (0.42, 0.42 and 0.38, respectively). The “ED_visit” is positively correlated with DRG labels (0.24), whereas the remaining process features are negatively associated with DRG labels (−0.30, −0.32, −0.42, −0.42, −0.28, −0.28 and −0.38, respectively).

Correlation heatmaps of process and non-process features and outcomes. The figure presents the correlation between the machine learning features and classification labels. A higher absolute correlation indicates a stronger association between the paired variables. Process features are shaped as squares and labeled in red; the class label is shaped as hexagon and labeled in green, and non-process features are shaped as circles and shown in dark.
A total of 56 unique combinations were identified from the QCA, with 28 configurations having raw coverage lower than 1.0%. The model performance gradually improved in both the weighted AUC and weighted F1 score in all six models after adding process features. The improvement was further enhanced after the application of the QCA solutions (Table 4).
Model-oriented performance evaluation by scenario.

Note. The table is presented in descending order of weighted AUC score of the original set.
A value of 1.0% was chosen as the cutoff point, with “sacrifice” being the minimum number of excluded cases. A total of 105 (6.8% of 1545) records aligning with these QCA combinations were excluded from the original data. The proportion of errors experienced a dramatic reduction of 47% following the inclusion of process features, decreasing from 5.48% to 2.91%. This rate further decreased to 0.0% after the implementation of the QCA solutions, as detailed in Table 5.
Changes in error rates by scenario.

Point difference is presented as the difference between the index scenario and the original set. A negative sign indicates a decrease in the error proportion and an improvement in overall performance.
Discussion
Quality of classification task
For a given classification task, a model’s performance ceiling usually depends on feature quality,22–24 inter-annotator agreement, 25 and whether unknown information includes deterministic factors linked to the desired outcome. 24 Correlation-based feature selection techniques, such as principal component analysis (PCA), 7 are commonly employed in classification tasks but often receive insufficient attention concerning their clinical relevance and data scopes. 24 Moreover, current approaches, such as imputations, aim to predict missing information on the basis of variances in existing observations. However, imputations carry the risk of introducing false information via different similarity measures. 4 Existing modeling logic seeks to identify universal patterns from collected data, with techniques such as error minimization through cross-validation if training features encompass adequate distinct information for desired outcomes. 26 Consequently, only a variance-based approach might lack consideration and adherence to evidence-based medicine principles as mentioned in Cumpston et al. 27 from a patient-centered perspective (the case level). Insufficient attention at this level thereby impacts the quality of health evidence derived from these tasks.
In our approach, by excluding a small number of records with a clear strategy, we can ensure a more robust classification performance. The excluded cases can be investigated separately by requesting additional information through queries from different hospital systems or consultations with the clinicians in charge.
Importance of process features in a healthcare classification task
Process feature engineering is an umbrella term whose scope has not yet been clearly defined. It can take different forms related to operational processes and resource supply chains, on the basis of the strategy used for event log generation and the research question. In this work, we focus on the contributions of patients’ clinical information and their sequential interactions. To date, process mining has shown its capacity to identify issues associated with urgent public outbreaks and routine care. In 2020, Chang et al. 28 used process mining techniques to study how COVID-19 impacts the length of stay and delay of process in emergency department for acute cerebrovascular patients during the pandemic. Alharbi et al. 29 used process mining to detect hidden healthcare sub-processes amongst 356 patients with “altered mental status” diagnoses. Chen et al. 30 combined process information as features to predict unplanned ICU readmission in MIMIC IV. However, how to incorporate process information into a given classification task has not been systematically studied.
In addition to the use of traditional clinical features, our finding indicated that the occurrence of significant events during the first ICU stay may serve as a potential early indicator for estimating hospital costs. In-hospital falls, one of the significant events included in the LPM, align with existing evidence that factors such as staffing and unit design may influence fall risk. Since 2008, fall-related injuries have been considered in the CMS reimbursement and DRG regulation guidelines. 31 By incorporating these processes information, we observed improvements in the DRG classification performance at both the model and case levels. However, this study grouped various significant events (such as ventricular drain and unplanned catheter removal) due to computational complexity. Future research is needed to explore the variations in hospital costs associated with the occurrence and sequence of significant events in the ICU for IHD patients.
Importance of QCA in a healthcare classification task
QCA has been widely used in health literatures to understand complex configurations and asymmetrical effects. Cairns et al. 33 utilized QCA to identify pathways linking health and place in geographic areas with resilient outcomes. They reported that the social environment appears to be more important than the natural environment in influencing pathways to health resilience in the selected areas. Triangulating the QCA to understand configuration information helps us identify nonlinear relationships between the feature space and classification labels.
Our findings from the QCA indicated that the set of interrelated process events that positively impact clinical interventions could be very different from the set of events that hinder the effectiveness of the intervention. Certain clinical events that positively affect future clinical outcomes do not necessarily have a reverse effect when their order is changed or when they are removed from the clinical trace. For example, 274 patients who underwent processes such as “imaging”, “ICU_procedure”, “Sig_event”, “Admin_ICU”, “ICU_Access Lines” and “ICU_ventilation” but did not experience “ED_visits” or “ICU_sig_event” were classified as Class 1 bypass surgery with probabilities of positive and negative configurations of 90.5% and 9.5%, respectively. However, by simply changing “Sig_event” from 1 to 0 while keeping the rest of the configuration unchanged, we observed that all 20 cases in this process were classified as Class 1. This suggests that certain process-related factors, such as the occurrence and absence of “ED_visits” may have asymmetrical effects on classification outcomes, which might not have been adequately addressed in previous studies.
After implementing QCA solutions to address cases with rare coverage configurations, a noticeable enhancement in case-based performance becomes evident. Additionally, by excluding cases based on clear rules, bias is substantially mitigated compared with randomly excluding records without defined strategies.
Need for an integrated approach rather than traditional pipeline
Traditionally, ML engineers have followed a linear pipeline that includes data preprocessing, feature elimination and selection, model training, and performance evaluation. 42 This pipeline approach relies on existing data as the “ground truth” for performance validation. However, inherent assumptions and biases may unconsciously influence the quality assessment and the conclusions drawn.
This study proposed an integrated approach that enhanced quality across three layers:
First, component evaluation examined the quality of key techniques using fitness scores, coverage proportions, and weighted F1 and AUC scores for the LPM, QCA, and classification models. By leveraging the LPM technique to convert local process features, additional hidden configurational information can be incorporated into classifier training. Triangulating with the QCA solution enables the identification of cases that require special considerations and enhances the validity of the findings. Second, an evaluation takes into account both case-level and variation-level uncertainties, enabling the identification of individual needs while also ensuring overall performance. Third, the clinical relevance was assessed based on health insights from each component, enabling flexible cooperation among teams with varied expertise. By systematically identifying and addressing “difficult-to-treat” cases, it enhanced the generalizability of applying it in a real-life setting.
The process features discovered from the LPM illustrate not only the occurrence and absence of multiple events but also the controlled relationships among them. The path “ICU_Access_line” represents patients transferred from the ICU ward for a peripheral access line operation, followed by two hidden activities. One of these activities may trigger a side effect, necessitating the operation. This information cannot be fully reflected by the traditional pipeline through feature selection or elimination. However, the model's performance ceiling cannot be increased simply by adding configuration information. Triangulating the identified process features into the QCA added an additional layer to help identify cases lacking sufficient information, which further improved the inherent performance ceiling.
Limitations
This integrated approach has some limitations and needs further improvement. Firstly, as LPM is not inherently goal-oriented, meaning that the discovered common local patterns may or may not be directly related to the classification task, 15 future studies may require a goal-oriented process miner to establish causal relationships. In 2014, Yan et al. proposed an agent-oriented goal-mining approach for pattern discovery in executed processes using event logs. 41 However, the complexity of the mined end-to-end model via their approach presented ongoing challenges in translating it into feature space. A systematic incorporation of duration and configuration in this transition process is essential. 32
QCA techniques enabled the identification of “difficult-to-classify” cases. However, it is worth noting that the QCA technique demands significant computing resources and is most efficient when dealing with small-N problems, making it a prevalent choice in qualitative research. 34 There is a pressing need for a scalable QCA approach to address big data challenges.
Whether PM is utilized to augment hidden information or whether QCA is employed to address “difficult-to-classify” cases and achieve perfect classifiers (guarantee of 100% performance) has not yet been fully explored and validate by using this integrated framework. This is because, in real-world data, while cases may share common characteristics, the absence of determining factors in feature spaces cannot be entirely resolved by this integrated approach. Future research is needed to address this challenge effectively. Moreover, the impact of different stratifications (e.g. age, race) on the quality of this integrated approach requires further investigation.
Conclusion
The proposed integrated approach demonstrates its ability to enhance overall classification quality from its clinical relevance, improved model performance, and reduced case-level error rates. This approach minimized “difficult-to-classify” cases and combined enriched process information in the feature space. The findings from this paper also added values to quality enhancement from three layers. Our findings indicate that certain clinical events that positively affect future clinical outcomes do not necessarily have the opposite effect when their order is changed or when they are removed from the clinical trace. This triangulation approach also shows potential for uncovering asymmetrical effects among process-related factors, which have not been adequately addressed in previous studies.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251314097 - Supplemental material for Enhance health evidence quality in classification tasks: A triangulation approach utilizing case-based reasoning and process features
Supplemental material, sj-docx-1-dhj-10.1177_20552076251314097 for Enhance health evidence quality in classification tasks: A triangulation approach utilizing case-based reasoning and process features by Ruihua Guo, Ross Smith, Qifan Chen, Angus Ritchie and Simon Poon in DIGITAL HEALTH
Footnotes
Contributorship
RHG contributed to conceptualization, design, data analysis, output interpretation, and writing of the manuscript. RS contributed to the data analysis, output interpretation and editing. QFC contributed to output interpretation and editing. AR contributed to manuscript editing and guidance. SP contributed to conceptualization, design, output interpretation, manuscript editing and guidance.
Data availability
Data included in this study sourced from a publicly accessible critical care database. The data that support the findings of this study are available from PhysioNet. Restrictions apply to the availability of these data, which were used under license for this study. Data are available at ![]() with the permission of PhysioNet.
with the permission of PhysioNet.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Approval
The dataset supporting the conclusions of this article is available in the Medical Information Mart for Intensive Care version IV (MIMIC-IV).12–14 This database is a public de-identified database; thus, informed consent and approval from the Institutional Review Board at the Beth Israel Deaconess Medical Center were waived. Analysts finished the required “Data or Specimens Only Research” course and certificate to use this data (Record ID: 55008135). All methods were performed in accordance with the relevant guidelines and regulations.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.