
Abstract
Objective
Medulloblastoma (MB) is a highly malignant brain tumor. Early diagnosis and treatment are important to improve patients’ survival. However, it is difficult to distinguish MB from other brain tumors in magnetic resonance imaging (MRI) with the naked eye. This study proposed a new hybrid deep learning model named InceptentionNet, combining Inception and self-attention mechanisms to recognize MB with MRI images.
Methods
InceptentionNet integrated multiscale feature extraction and dynamic focus on relevant regions. This model was trained using a dataset with 736 MRI images, including 106 MB and 630 non-MB images. Other single convolutional neural network models, including MobileNet, Residual Network, Densely Connected Convolutional Network, Visual Geometry Group, and Inception, were also trained. All models’ performance was evaluated. In addition, we conducted external tests to verify the generalization of the model.
Results
The InceptentionNet model achieved an accuracy of 98.07% ± 0.77%, a precision of 91.43% ± 4.56%, a F1-score of 93.54% ± 2.44%. And the area under curve and recall were respectively 99.41% ± 0.08% and 96.03% ± 3.61%. In external tests, this model still performed best, achieving 90.94% accuracy and 92.79% AUC. These metrics indicated that our model exhibited a good performance in distinguishing MB. The accuracy of InceptentionNet was the highest among other single models, indicating our hybrid model outperform other models. Additionally, images combined with attention heatmaps exhibited high clinical interpretability.
Conclusion
InceptentionNet demonstrates robust predictive capabilities and has the potential as a diagnostic assistant tool. In the future, the model should be trained and validated using larger data and multiclass classification should be expanded.
Keywords
Introduction
Medulloblastoma (MB) is a malignant embryonic tumor located on the posterior cranial fossa, originating from granule cell precursors. 1 Classified as grade IV in the World Health Organization pathological classification, MB exhibits highly malignant behaviors, and 30% patients were demonstrated metastasis at diagnosis.2,3 The mass effect caused by MB not only can lead nausea, vomiting, sensory and motor disorders, but can also cause the brain herniation followed by the brain stem compression and death.
MB is the most common intracranial primary malignant brain tumor in children, while rare in adults.4,5 Surgery, chemotherapy, and craniospinal irradiation are the main treatment methods for MB patients. 6 Considering the highly malignant behavior, MB should be diagnosed and treated as early as possible. However, since the interpreting magnetic resonance imaging (MRI) is complex and the variation among radiologist, it is hard to distinguish between MB and other brain tumors, especially those like ependymoma origin in the fourth ventricle. Pathology can distinguish MB, but biopsy and craniotomy surgery both harbor danger for patients to get tumor tissues. And not all patients can undergo operations. Hence, a noninvasive, automated, and highly efficient system for assisting in the diagnosis of MB is needed.
With the thriving of deep learning technology in the field of medical image recognition, many models based on deep learning have implemented in brain tumors, especially in gliomas. For example, Voort et al. 7 developed a single multitask convolutional neural network (CNN) using MRI scans to predict the mutation status and grade of gliomas. Xia et al. 8 used a CNN model to distinguish between glioblastoma and lymphoma. Tang et al. 9 proposed a new deep learning-based model to predict the tumor genotypes of glioblastoma using MRI scans. Chen et al. 10 used a CNN model to predict the PTEN mutation of gliomas. However, only a few researches have focused on the MB. Peng et al. 11 developed a fully automated pipeline to segmentate MB. Bareja et al. 12 used nnU-Net-based segmentation models to automatically delineate the MB. But these models can’t distinguish MB from other tumors nor the subgroups of MB. Chen et al. 13 used mask regional CNN to distinguish the molecular subgroups of MB. But they only used one model and the accuracy needs to be improved.
To focus on the most critical areas and improve the accuracy of the CNN model, self-attention has been introduced, allowing the CNN model to dynamically weight different parts of an image. 14 Introducing a self-attention mechanism into a CNN can significantly enhance its ability to identify MB by improving feature extraction and refining the network's focus on tumor-specific characteristics. This article proposed a novel approach called InceptentionNet that combined the strengths of both CNN and self-attention mechanisms to achieve more precise identification of MB with MRI images (Figure 1).

The workflow of this study.
Methods
Ethical approval
The public data of this study are all from Kaggle (https://www.kaggle.com/datasets/waseemnagahhenes/brain-tumor-for-14-classes). Since Kaggle is a public online platform, it does not require the approval of ethics committee. In addition, the external validation data were obtained from Shanghai Children's Medical Center. This study was approved by the Institutional Ethics Committee of Shanghai Children's Medical Center and the ethics approval number is SCMCIRB-Κ2022159–1.
Data acquisition
Training data
The training data in this study were obtained from Kaggle named Brain Tumor for 14 classes. There are 131 MB images in the dataset. To address concerns regarding duplicate images, we confirm that a two-step process was used: (1) we applied perceptual hash (pHash) comparison to automatically flag near-identical images; (2) all flagged pairs were manually reviewed by a radiologist to verify redundancy before removal. As a result, 25 duplicate MB images and 6 duplicate non-MB images were excluded. After excluding 25 duplicate images, 106 MB images were enrolled in this study. As for non-MB images, 636 images were randomly selected from other 13 brain tumor classes and normal class. After excluding six duplicate images, 630 non-MB images were enrolled. In the end, a total of 736 images were included in this study.
External validation data
We retrospectively collected MRI images of 118 patients from Shanghai Children's Medical Center for external validation. This study was approved by the Ethics Committee of Shanghai Children's Medical Center (SCMCIRB-Κ2022159–1).
Data preprocessing
To prepare the MRI images for model training, a series of preprocessing steps were applied to enhance image quality and highlight critical features. Noise reduction was performed using a Gaussian filter with a standard deviation of 2, effectively smoothing nonessential details while preserving the edges of key structures. Contrast adjustment was achieved through histogram equalization, which redistributed pixel intensity values across a broader dynamic range to improve the visibility of subtle features. These steps ensured a cleaner and more informative dataset, crucial for robust model performance. For example, after denoising, the average peak signal-to-noise ratio of the images increased by approximately 15%, and contrast adjustment led to a 22% increase in the standard deviation of pixel intensities, indicating improved feature differentiation.
To artificially expand the dataset and simulate real-world clinical variations, augmentation techniques such as random rotation (angles ranging between 0° and 45°), horizontal flipping, and zooming (scaling factors randomly selected between 0.8 and 1.2) were applied. These methods increased the dataset size from 736 images to 2944 images, with the number of samples in each tumor class augmented by a factor of four. This not only addressed the issue of data imbalance but also enhanced the model's robustness to variations in orientation and scale, which are common challenges in medical imaging. For instance, after applying these augmentations, the model's accuracy improved by approximately 5%, demonstrating the effectiveness of the augmented dataset in improving the model's generalization capability.
Model construction
Proposed deep learning model
In recent years, many models based on CNN have applied for medical image analysis given the great performance. Inception, also named as GoogLeNet, is a CNN architecture which allows the CNN to capture features at different scales, bringing excellence performance for image classification and object detetion. 15 For example, Rao et al. 16 used Inception V3 model to classify medical radiology images and obtained 99.98% accuracy. Singh et al. 17 used Inception V3 model to distinguish between health and blood cancer cells using cellular morphology dataset. However, just like other CNN models, Inception model lacks the capture of long-range dependencies across the image, which might be important to MB identification considering the complex tumor structures. And attention-based models can capture global dependencies but lack the spatial locality, which is essential for the medical image detection.18,19 To address these limitations and adapt to MB identification, a new model is needed to be proposed.
To address the limitations of conventional CNN models in capturing both local and global information, we developed a hybrid deep learning architecture named

The architecture of the InceptentionNet model.
The model consists of three main components. First, the stem module applies a 3 × 3 convolution (stride = 1, 64 filters) to process the input image and generate initial low-level features. Second, a modified Inception block is used to extract multiscale features through parallel branches with 1 × 1, 3 × 3, and 5 × 5 convolutions, each followed by batch normalization and ReLU activation. To preserve spatial information, we replaced the traditional max-pooling path with a 3 × 3 convolution followed by stride-2 downsampling. The outputs of the parallel branches are concatenated along the channel dimension to form a comprehensive feature representation.
After feature extraction, we introduced a multihead self-attention module consisting of four attention heads, each with 64-dimensional query and key vectors. The attention module dynamically reweighted the spatial features according to their contextual relevance. The attention scores were computed using scaled dot-product attention, followed by softmax normalization, allowing the model to highlight tumor-relevant regions—such as the posterior fossa or cerebellar vermis—with greater precision.
This architectural design was informed by both radiological knowledge and deep learning best practices. MB often exhibit diverse intratumoral appearances (e.g. necrosis, cysts, calcification) and variable locations in the posterior fossa, which makes local feature extraction and global context modeling equally important. The combination of Inception's multiscale feature extraction and self-attention's contextual sensitivity allows the model to better handle such complexity, thereby improving its ability to distinguish MB from other tumor types.
The InceptentionNet model was trained using the Adam optimizer with an initial learning rate of 0.005. To ensure efficient convergence while avoiding overfitting, we applied a learning rate decay strategy, which automatically reduced the learning rate when the validation loss plateaued. Training was conducted over a maximum of 40 epochs, with early stopping enabled—training was halted if the validation loss did not improve for 10 consecutive epochs. A mini-batch size of 8 was used throughout the training process, which was selected empirically based on GPU memory constraints and training stability. To further enhance generalization and reduce overfitting, a dropout rate of 0.3 was applied after each dense layer in the classification head. All hyperparameters were determined through preliminary grid search. These training configurations ensure a reproducible and reliable optimization process for the proposed model.
Model comparisons
To obtain the benchmarking performance and highlight the improvements, the InceptentionNet was compared with other single models based on CNN, including MobileNet, Residual Network (ResNet), Densely Connected Convolutional Network (DenseNet), Visual Geometry Group (VGG), and Inception.
MobileNet is a CNN model which is specially designed for mobile and embedded device application. 20 With high efficiency of computation and memory, this model is very suitable for devices with limited processing power. Since this model has good performance in visual recognition, such as image classification, this model is also used for medical image recognition. For example, Huang et al. 21 used MobileNet-V2/IFHO model to detect early-stage diabetic retinopathy, achieving an average precision of 97.521%.
ResNet introduced the residual learning concept and enable the training of deeper networks, significantly improving the CNN performance. 22 Sahli et al. 23 used the ResNet model combined with SVM for glioblastoma segmentation and classification. Shin et al. 24 used ResNet-50 to distinguish glioblastoma from solitary brain metastasis.
DenseNet is a CNN model which allows each layer to connect with other layer in a feed-forward manner. 25 DenseNet is also highly effective in image classification and object detection. For example, Guo et al. 26 used a model based on DenseNet to classify glioma subtypes and achieved an accuracy of 0.878. Alshammari et al. 27 used a DenseNet-based model to classify brain metastasis tumor with a accuracy of 98.5%.
VGG is a popular model at image classification tasks and notable for depth. 28 VGG-based models have widely applied in medical image recognition. Basha et al. 28 used VGG-16 to segment brain tumor. Saluja et al. 29 used VGG-16 for glioma grade classification.
Inception uses multiple convolutional and pooling operations in parallel within a single layer, having good performance of capturing features at different scales. 30 Wu et al. 31 used Inception model to classify glioma and encephalitis. Khaliki et al. 32 used inception-V3 to classify different brain tumors.
Statistical analysis
To evaluate the performance of the new model and other baseline models, several metrics were analyzed, including accuracy, precision, recall, F1-score, receiver operating characteristic (ROC) curve, and area under the curve (AUC). Accuracy assesses the correctness of predictions, and the equation is Accuracy = (True positives + True negatives)/(True positives + True negatives + False positives + False negatives). Precision assesses the accuracy of positive predictions, and the equation is Precision = True positives/(True positives + False positives). Recall assesses the ability to identify all true positives, and the equation is Recall = True positive/(True positives + False negatives). F1-score is the harmonic mean of precision and recall, and the equation is F1-score = 2 × (Precision × Recall)/(Precision + Recall). AUC assesses overall discrimination ability.
Results
Experimental setup
In this study, all images from Kaggle were used to train the model with five-fold cross validation, ensuring the robustness and prevention of overfitting. To maintain comparability and consistency, all models were trained using five-fold cross validation. For each model, hyperparameter tuning was performed using grid search to identify the optimal learning rate, batch size, and regularization parameters. All models were trained until convergence, defined as no significant improvement in the validation loss over 10 consecutive epochs, while early stopping was applied to prevent overfitting. Training was conducted on an NVIDIA RTX 3090 GPU with 24GB of memory, leveraging the PyTorch deep learning framework in Python (version 3.9). Model training and validation were monitored using performance metrics, including accuracy, precision, recall, F1-score, ROC curve, and AUC, to ensure comprehensive evaluation.
Cross-validation results
During the training, we used hyperparameters to optimize the performance of the hybrid model. An Adam optimizer with an initial learning rate of 0.005 was used during the training process. The batch size was 8. And the training process was monitored at different epochs (Figure 3(a)).

Accuracy and receiver operating characteristic (ROC) curves. Accuracy of InceptentionNet at different epochs (a). ROC curves of InceptentionNet (b), MobileNet (c), Residual Network (d), Densely Connected Convolutional Network (e), Visual Geometry Group (f), and Inception (g).
For comparison, we also implemented five widely used CNN architectures—Inception, MobileNet, ResNet, DenseNet, and VGG—under the same experimental settings. The results for all models are reported as mean ± standard deviation across the five folds, as shown in Table 1. Our model achieved the highest overall performance, with an accuracy of 98.07% ± 0.77%, a precision of 91.43% ± 4.56%, a recall of 96.03% ± 3.61%, an F1-score of 93.54% ± 2.44%, and an AUC of 99.41% ± 0.08%. Compared to Inception (97.52% ± 0.51% accuracy, 92.21% ± 0.01% AUC) and DenseNet (96.93% ± 1.44% accuracy, 99.43% ± 0.15% AUC), our model provides both superior performance and lower variance across all metrics, especially in recall and F1-score, which are critical for imbalanced diagnostic tasks.
The performing metrics of models.

AUC: area under curve; ResNet: residual network; DenseNet: densely connected convolutional network; VGG: visual geometry group.
In contrast, ResNet and VGG exhibited significantly lower performance, particularly in terms of recall and AUC, suggesting their limited suitability for MB identification tasks under the current dataset conditions. MobileNet achieved relatively strong precision (93.35% ± 8.72%) but suffered from unstable recall (58.41% ± 29.73%), indicating a higher rate of false negatives. These results confirm that InceptentionNet effectively balances sensitivity and specificity while maintaining robustness across folds, which is essential for clinical decision support systems in medical imaging.
In addition, Figure 3(b–g) shows the ROC curves and AUC values of each model in the five-fold cross validation. The results include the specific results of each fold and the corresponding average results (including 95% confidence interval).
External-validation results
In addition to performing five-fold cross-validation on publicly available datasets, we further evaluated the generalizability and real-world clinical applicability of our proposed model by conducting external testing using clinical samples collected from a hospital setting. Specifically, we retrospectively collected MRI images of 118 patients from Shanghai Children's Medical Center, including 66 MB images and 52 non-MB images. This study complies with the Declaration of Helsinki and has been approved by the Hospital Ethics Committee and the data was obtained from public database hence the informed consent was waived off (No.: SCMCIRB-Κ 2022159–1). The results of the external evaluation are presented in Table 2. Our model achieved outstanding performance with an accuracy of 90.94%, precision of 97.30%, F1-score of 91.96%, and a recall of 94.56%, surpassing all baseline and comparative models. Notably, the accuracy exceeded that of the baseline Inception model by more than 1%, underscoring the superior predictive capability of our approach.
The performing metrics of models in external test.

AUC: area under curve; ResNet: residual network; DenseNet: densely connected convolutional network; VGG: visual geometry group.
The ROC curves of all models evaluated on the external dataset are shown in Figure 4. Our proposed model achieved the highest AUC of 92.79%, with its ROC curve lying closest to the top-left corner, indicating excellent discriminatory power on real-world clinical data. These results substantiate that our model is not limited to a single dataset or overfitting to public data but demonstrates robust performance and strong generalization ability in authentic clinical scenarios. This external validation highlights the potential of our model to be integrated into clinical workflows, offering high-accuracy decision support for physicians and improved outcomes for patients.

The ROC curve of external validation.
Visualization and clinical interpretability analysis
To enhance clinical interpretability, we generated Grad-CAM-based heatmaps overlaid on representative MRI images (Figure 5), which visualize the spatial regions most strongly attended to by the InceptentionNet model during classification. These heatmaps provide an intuitive visual explanation of the model's decision-making process by highlighting areas that contribute most significantly to the final prediction.
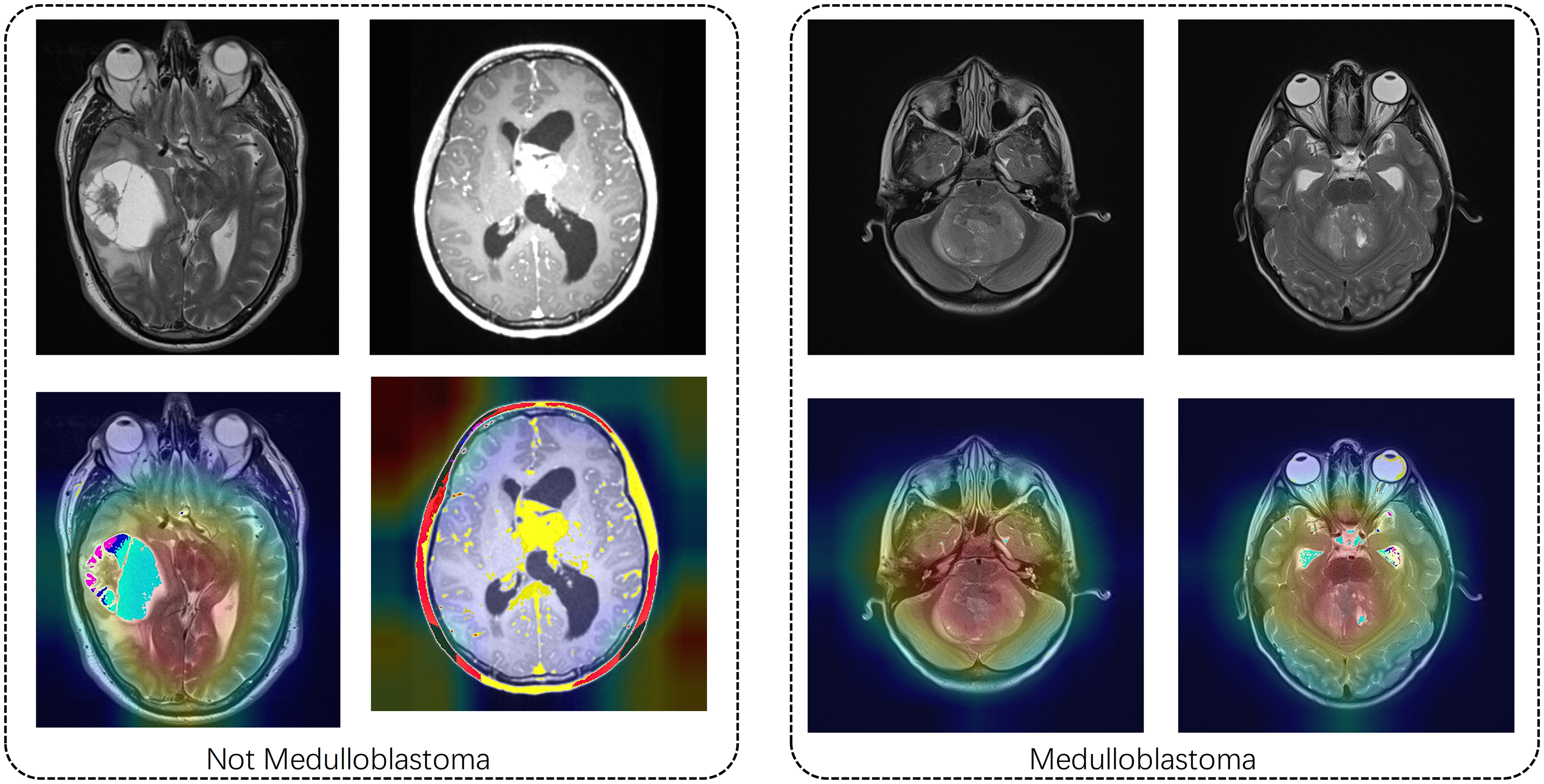
Images combined with attention heat for medulloblastoma and non-medulloblastoma.
The highlighted regions were found to correspond well with radiological hallmarks commonly associated with MB. Specifically, the model consistently focused on tumor localization within the fourth ventricle and adjacent midline structures—areas that are known to be frequent sites of MB occurrence. In addition, the attention maps accurately captured features related to mass effect, including compression of the brainstem and displacement of surrounding tissue, which are critical indicators in radiological assessment. Moreover, the model was able to identify signal heterogeneity patterns—such as hypointense or hyperintense regions on T1- or T2-weighted imaging—suggestive of necrosis, cystic degeneration, and calcification, all of which are commonly seen in advanced-stage MBs.
By focusing on these clinically relevant features, the generated heatmaps not only provide post-hoc interpretability but also demonstrate alignment with the diagnostic reasoning typically employed by expert neuroradiologists. This alignment further supports the feasibility of integrating the model into real-world radiological workflows as a complementary diagnostic aid.
Discussion
In this research, we proposed a new model named InceptentionNet which was consisted of Inception and self-attention. This model had both the spatial awareness and global focus and was particularly suitable for the identification of MB considering the complex tumor structures. InceptentionNet achieved outstanding performance on the task of identification MB images compared to other single CNN models according to the results of performance metrics. The accuracy as 90.94% and AUC was 92.79%, demonstrating excellent predictive capability. Images combined with heatmaps suggested that InceptentionNet also had a great clinical interpretability.
The excellent performance of our hybrid model might be attributed to the model architecture and the suitability of MB identification task. Traditional CNN models focus on local features, while the introducing of self-attention allows model to establish a global context across the whole image.33,34 So, the model can capture the relationships regardless the physical distance between pixels or features, which is very important to the recognition tasks of brain tumors considering the complex structures. 35 The combination of Inception and self-attention modules can enhance feature representation. The Inception model can capture multiscale features through multiscale convolution operations. Self-attention mechanism can enhance and refine the feature representation. Additionally, the attention mechanism can also provide intuitive insights about the model's decision-making process. We can easily understand how the hybrid model “views” the input by observing which areas receive higher attention weights. These advantages bring high performance of our hybrid model in the task of recognize MB. Besides, combining different mechanisms might help the model to be used in other data since it can capture features from multiple perspectives.
In addition to reporting average performance metrics, we analyzed the misclassified cases to better understand the limitations of the proposed model. Most false positive predictions occurred when non-MB tumors—such as cystic ependymomas or midline gliomas—shared anatomical locations or imaging characteristics with MBs. These tumors often exhibit similar intensities and occupy regions in the posterior fossa, leading the model to incorrectly classify them as MB due to overlapping visual cues. Conversely, false negatives were primarily associated with atypical presentations of MB. In these cases, the lesions were either very small or demonstrated weak contrast relative to surrounding brain tissue, which made accurate identification more challenging even for human observers. Some of these errors also appeared in MRI slices with motion artifacts or partial volume effects, suggesting that image quality plays a significant role in model sensitivity.
This research also has significant clinical values. MB is a malignant brain tumor which requires early diagnosis and treatment. But it is difficult to distinguish MB from other tumors, such as ependymoma, with the MRI scans by naked eyes. 36 Pathology is the gold standard to identify MB, while tumor tissues are needed from biopsy or craniotomy surgery, and both harbor danger for patients. Our model can noninvasively identify MB tumor with excellent performance, having the potential of clinical deployment and supporting radiologists.
There are several limitations in this research. Firstly, we only focused on binary classification, and the classification of pathological grades or genetic mutations were not enrolled in this study. In the future research, we will expand this model to multiclass tasks. Secondly, there was no external test group. Data form multiple centers should be used to confirm the model's generalizability in the future. Although the dataset used in this study is publicly available and facilitates reproducibility, it lacks comprehensive clinical annotation and may not fully represent real-world patient variability, which should be addressed in future multicenter studies. Finally, although there is a clinical potential in our model, a deployable system has not been developed. Further development is necessary for an integrated system for clinical translation.
Conclusion
This study developed a hybrid model named InceptentionNet which integrated Inception and self-attention mechanisms for the recognition of MB with MRI images. InceptentionNet can capture multiscale features and focus on critical regions, demonstrating high performance compared with other single CNN models. Additionally, images combined with attention heatmaps exhibited high clinical interpretability. Therefore, this model has the potential to assist radiologists with the MB recognition. For future work, this model should be trained and validated with more data and developed into an accessible diagnostic tool.
Footnotes
Ethical considerations
This study complies with the Declaration of Helsinki and has been approved by the Hospital Ethics Committee and the data was obtained from public database hence the informed consent was waived off (No.: SCMCIRB-Κ 2022159–1).
Author contributions
Conceptualization: CF, CL, HC, XC, and ZS; data curation: CL, HL, QZ, and SL; formal analysis: CF and CL; funding acquisition: HL, HC, XC, and ZS; investigation: CF and CL; methodology: CF, CL, HL, QZ, and SL; project administration: CF and CL; resources: CF and SL; software: CF and CL; supervision: HC, XC, and ZS; validation: HL and QZ; visualization: CL and HL; writing—original draft: CF, CL, HL, QZ, SL, HC, XC, and ZS; writing—review and editing: HC, XC, and ZS.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Fujian Province, National Natural Science Foundation of China, and Scientific Research Project of National Key clinical specialty construction project (Grant Nos. 2023J01583, 32200781, and 2022YBL-ZD-04).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantors
CF and CL.