
Abstract
Objective
Brain tumors are a leading global cause of mortality, often leading to reduced life expectancy and challenging recovery. Early detection significantly improves survival rates. This paper introduces an efficient deep learning model to expedite brain tumor detection through timely and accurate identification using magnetic resonance imaging images.
Methods
Our approach leverages deep transfer learning with six transfer learning algorithms: VGG16, ResNet50, MobileNetV2, DenseNet201, EfficientNetB3, and InceptionV3. We optimize data preprocessing, upsample data through augmentation, and train the models using two optimizers: Adam and AdaMax. We perform three experiments with binary and multi-class datasets, fine-tuning parameters to reduce overfitting. Model effectiveness is analyzed using various performance scores with and without cross-validation.
Results
With smaller datasets, the models achieve 100% accuracy in both training and testing without cross-validation. After applying cross-validation, the framework records an outstanding accuracy of 99.96% with a receiver operating characteristic of 100% on average across five tests. For larger datasets, accuracy ranges from 96.34% to 98.20% across different models. The methodology also demonstrates a small computation time, contributing to its reliability and speed.
Conclusion
The study establishes a new standard for brain tumor classification, surpassing existing methods in accuracy and efficiency. Our deep learning approach, incorporating advanced transfer learning algorithms and optimized data processing, provides a robust and rapid solution for brain tumor detection.
Keywords
Introduction
The brain, the most complex organ in the human body, oversees and coordinates numerous functions. It constitutes the central nervous system with the spinal cord, which consists of a vast network of approximately 86 billion neurons.1,2 Generally, the brain cell is formed through the neurogenesis process and it takes about six months to mature a new brain cell completely. But when brain cell DNA gets altered or certain genes malfunction due to damage, 3 it leads to the unregulated growth of dysfunctional cells, causing brain abnormalities. Brain tumors can develop at any age, but the highest risk is observed in children under 15 and adults between 85 and 89 years.4,5 Cancer web-portal statistics show over 308,102 global diagnoses annually, with around 251,329 deaths from primary brain tumors. 6 Including other types of brain tumors, the mortality rate is significantly alarming, making it one of the world’s most feared diseases.
Commonly brain tumors are categorized as benign (non-cancerous) or malignant (cancerous). Benign tumors grow slowly, don’t spread, and can often be large; meningioma is a common benign type, making up 30% of brain tumors, more frequent in women.7–9 Although benign tumors are typically removed via surgery, some can transition to premalignant and then malignant stages.10,11 Malignant tumors grow rapidly, with gliomas being the most prevalent, accounting for 78% of adult brain tumors.12–14 Particularly aggressive types include glioblastoma and astrocytoma.15,16 Of the 150+ distinct brain tumors, the main categories are primary and secondary (or metastatic). 17 Primary brain tumors originate from brain tissues and can be glial or non-glial. 18 Both benign and malignant tumors can be primary. Secondary or metastatic tumors begin in other body parts (e.g. breast, lungs, kidney, colon, and skin) 19 and travel to the brain, always being malignant and cancerous.
Researchers aim to detect brain tumors at their initial stage, as early diagnosis can enhance survival rates and reduce brain tumor cases and fatalities. Several computerized methods, such as computed tomography (CT) scanning, magnetic resonance imaging (MRI), positron emission tomography (PET), and others, are employed for diagnosis. 20 Of these, MRI is favored for its precision in depicting the brain’s anatomical structure, using a strong magnetic field and radio frequency signals.21,22 It offers superior contrast with up to 65,535 grey levels, often imperceptible to the human eye.23–25 Analyzing numerous MRI images manually can be challenging, and time-consuming, and also sometimes causes wrong diagnosis. With the evolution of artificial neural networks researchers have been investigating an automated diagnosis system of brain tumors by implementing various machine learning (ML)-based techniques and deep convolutional neural networks (CNNs). 26 However, the ML model depends on various handcrafted features, has much time complexity with low accuracy results, and is expensive to carry out at the same time. Compared to ML deep CNN algorithms can learn automatically, recognize complex patterns and shapes, and have the properties of self-learning. However, the drawbacks of the traditional CNN model are that it suffers from the vanishing-gradient problem, requires excessive data to train, and cannot analyze three-dimensional (3D) input images. On the contrary deep transfer learning (TL) models can provide better accuracy even in the small number of training samples. The classification task can be performed more effectively and reliably through TL frameworks.
In recent times, numerous TL models have emerged from deep learning algorithms, emphasizing “knowledge transfer.” These models have demonstrated efficiency across various sectors, including agriculture, industry, and medical disease prediction. The growing trend is to use CNN-based TL for a wide array of computer vision challenges. Besides, several TL research studies have been carried out for brain tumor classification. However, many researchers used the default model, the old noisy dataset that generates low outcomes. Various studies did not analyze the results with performance metrics. However, we have also investigated some effective TL studies. In this research, we conducted an outstanding TL experiment refining six TL architectures: VGG16, ResNet50, MobileNetV2, EfficientNetB3, DenseNet201, and InceptionV3 for brain tumor identification and classification. The main objective of this experiment is to build a robust and reliable brain tumor classification model employing effective fine-tuning of the parameters, evaluate the performance of the selected TL models, and further verify the proposed framework on different datasets through various performance and error measurement techniques.
The key contributions of this study are stated as follows:
To fit the intended deep learning model, we applied a suitable pre-processing method. Image enhancement and augmentation are performed to increase the number of images and resolve overfitting issues. We accomplished regularization and fine-tuning of the parameters to increase the accuracy rate and developed an extended layers-based framework to adjust the weights of the utilized datasets. To validate the prediction outcomes, we utilized two different datasets using two different optimizers. Furthermore, we implemented five-fold cross-validation (CV) to evaluate the results of the small datasets. Model’s accuracy, errors, and complexity are analyzed through various computation metrics, mean deviation, and receiver operating characteristic (ROC) values for each class. Finally, we provided a comparison of the experiment results with the previous attempts and presented that our proposed methodology has proved more effective for classifying brain tumors than other state-of-the-artodels. Section “Related works” provides a thorough summary as well as reviews of related literature, the inadequacies of the previous works, and the goal and importance of the research. Section “Proposed methodology” describes the steps of the suggested methodology and the selected models in detail. Section “Experiment and result analysis” analyzes the experimental findings and computation methods elaborately. In addition, a comparison of the previous research and our proposed framework is also presented in this section. The overall research outcomes of the methods, their limitations, and the next steps are concluded in section “Discussion.”
The main research contents of this article are arranged in the following:
Related works
Over the years many researchers have built intelligent systems to detect brain tumors using classical ML and deep learning techniques. The intricacy of current approaches in locating the precise boundaries and areas of tumors reduces the overall accuracy of recognition. Most of the experiment has poor accuracy and complex implementation architecture. Hence a fine-tuned, well-trained TL-based neural network architecture plays a very effective role in easily carrying out the classification of brain tumors.
Classification of brain tumor using CNN
In recent years, deep learning has been widely used for brain MRI classification. For this approach, a dataset is essential, and sometimes preprocessing is needed before self-selecting key features. CNNs are a popular deep learning method for images. They act as feature extractors, pulling vital classification information. Within CNNs, lower layers detect basic structures such as shapes, textures, and edges, while higher layers merge these to form comprehensive representations containing both global and local details. However, CNN has limitations in feature extraction in the case of small datasets, and cannot optimize important features while taking long training time.
Using CNNs, Seetha et al. 39 performed the classification of brain tumor with a training accuracy of 97.5% on the (BRATS) 2015 testing dataset. They trained the model on a small set of data since the dataset contains <300 magnetic resonance (MR) data, also no augmenting technique was applied to increase the training data. Besides the experiment lacks many useful information and result validation.
Sunanda Das et al. 27 developed a CNN model for the classification of brain tumors in T1-weighted contrast-enhanced MRI images; a dataset of 3064 photos of three different forms of brain tumors (glioma, meningioma, and pituitary). They used a Gaussian filter, and histogram equalization to preprocess the input data and three dropout layers in the classification model with a dropout rate of 25%, 40%, and 30%. Though dropout reduces overfitting, inappropriate dropout rates decrease the strength of the neural network. However, they gained a testing accuracy of 94.39%. Their testing loss is high.
A deep multi-scale 3D CNN architecture is proposed by Hiba et al. 28 in order to classify the grade of glioma brain tumors into low-grade gliomas and high-grade gliomas. 3D convolutional filters take advantage of generating more powerful contextual features that deal with large brain tissues’ variations. Instead of exploring only two-dimensional (2D) slices, it examines the volumetric information in MR images. They solved the heterogeneity and low contrast problem of the data through preprocessing and utilized a simple flipping method of augmenting technique. Their model achieved an accuracy of 96.49% using the benchmark (Brats-2018) dataset. However, their model is computationally memory exhausted as 3D CNN generates a number of trainable parameters.
Parnian et al. 29 developed Capsule Networks (CapsNets) to overcome the shortcomings in CNN to fully utilize spatial relations. The suggested improved CapsNet architecture incorporates additional inputs from the tumor coarse borders into its pipeline to sharpen the CapsNet’s focus. The model handled transformations in a “Routing by Agreement” process instead of a pooling layer, during which lower-level capsules forecast how their higher-level parents will behave. However, this method is incapable of interpreting the features of brain tumors efficiently. They do not perform any pre-processing technique and fail to extract important parameters. Therefore the model does not obtain a higher prediction outcome, on the contrary, model computation is complex. The accuracy of this approach is 90.89%.
Classification of brain tumor using a hybrid model
The related works provide substantial contributions to brain tumor detection, demonstrating impressive accuracy rates and innovative techniques. However, many of these approaches still face challenges, particularly in generalization, optimization, and handling small datasets.
Despite the high accuracy and promising results reported by Kuirdi et al., 40 , Khan et al., 41 , Badjie et al., 42 , and Rajinikanth et al., 43 , their methods exhibit several limitations. Kuirdi et al. 40 employed the Harris Hawks Optimized Convolutional Network with substantial accuracy, but their approach may be constrained by its reliance on a single dataset, potentially affecting its generalizability to other imaging conditions or populations. Additionally, the focus on noise elimination and specific segmentation techniques might not address all types of tumor variability. Khan et al. 41 used a fusion-based contrast enhancement and deep TL, yet their results are based on a limited set of datasets, which may not fully capture the diversity of brain tumors or imaging scenarios. The effectiveness of their approach might vary with different types of tumors or imaging conditions. Similarly, while Badjie et al. 42 achieved remarkable accuracy with AlexNet, their study primarily evaluated the model on a specific dataset, limiting its applicability to diverse clinical settings. Rajinikanth et al. 43 developed a Computer-Aided Disease Diagnosis system with high classification accuracy, but the system’s reliance on handcrafted features and a specific classifier might restrict its adaptability to other tumor types or imaging techniques. These limitations highlight the need for broader dataset validation and more adaptable methodologies to enhance the robustness and generalizability of brain tumor detection systems.
Moreover, despite the promising results reported by Rasheed et al.44,45 and Haq et al., 46 several limitations are evident in their approaches. Rasheed et al. 44 achieved impressive accuracy and high precision in classifying glioma, meningioma, and pituitary tumors. However, their methodology relied on a specific dataset, which raises concerns about the model’s ability to generalize across different imaging modalities or diverse patient populations. Moreover, the focus on only a few tumor types may limit the algorithm’s applicability to a broader range of brain tumors. Similarly, Rasheed et al. 45 integrated Gaussian-blur sharpening and Contrast Limited Adaptive Histogram Equalization (CLAHE) for tumor classification, achieving high accuracy and generalization. Nonetheless, their approach also suffers from limited validation across various datasets and tumor types, potentially affecting the robustness of the model in real-world applications. Additionally, Haq et al. 46 developed a CNN for nodule detection with notable precision and specificity. Yet, their method’s performance was primarily evaluated on nodule detection, which may not directly translate to the classification of different types of tumors or other imaging challenges. These limitations highlight the need for more comprehensive evaluations and broader applicability in developing robust diagnostic tools.
To address these gaps, our research introduces a novel methodology that not only incorporates advanced preprocessing and regularization techniques but also ensures extensive validation through multi-dataset evaluation and rigorous CV. By employing a diverse set of datasets and optimizing the model’s performance across various conditions, our approach aims to provide a more comprehensive and adaptable solution for brain tumor classification. This broader validation and adaptability are essential for developing models that can generalize well and perform reliably in diverse real-world scenarios.
In conclusion, our work fills the gaps identified in existing research by offering a more robust and generalized approach to brain tumor detection, supported by comprehensive validation across multiple datasets and advanced optimization techniques. This approach addresses the limitations of previous studies and contributes to the advancement of reliable and adaptable diagnostic tools.
For automatic brain MRI categorization, a variety of algorithms based on conventional ML and deep learning techniques have been conveyed. Kang et al. 30 presented an automated hybrid system for classifying brain tumors. In this method, several pre-trained deep learning models are utilized for feature extracting. Furthermore, various ML classifiers are used to ensemble three top features. From their report support vector machine (SVM) with radial basis function (RBF) provides better results than the other ML classifiers. The study reported 92.16% accuracy on the BT-small-2c dataset, 98.67% on the BT-large-2c dataset, and 93.72% on the BT-large-4c dataset. The main drawback of this research is that their accuracy is quite inconsistent. The model is not reliable. Their prediction outcome is also lower than us. Besides accuracy, they did not measure any other performance score and also did not analyze the computation time of their hybrid model.
A novel hybrid-brain-tumor-classification (HBTC) framework was designed and evaluated by Syed Ali et al. 31 for the classification of cystic, glioma, meningioma, and metastatic brain tumors. The HBTC framework received the input brain MRI dataset and performed pre-processing and segmentation to identify the tumor location. Through segmentation of the tumor area, the co-occurrence matrix (COM), run-length matrix (RLM), and gradient characteristics were obtained. Furthermore, they incorporated J48, meta bagging (MB), and random tree (RT) classifier to classify brain tumors. They gradually increase the performance from 64.8% to 98.8%. The study finds that the increase in region of interest size increases the classification accuracy. Among RT, meta begging, j48, and MLP classifiers, MLP classifier outperformed the others. However, the overall architecture of this research is complicated to carry out the tumor classification and requires a lot of matrix calculation that increases the computation time. Feature extraction is performed through conventional methods and is not suitable for detecting brain tumors easily.
Asaf et al. 32 proposed a hybrid deep learning model called DeepTumorNet that categorizes brain tumors as glioma, meningioma, and pituitary tumor. They incorporated a pre-trained GoogLeNet architecture as the base architecture. Instead of the last five layers, they added 15 new layers to the TL model. As the proposed model consists of a generalized GoogleNet model only, it lacks the characteristics of a hybrid model. Besides they compared the results of the proposed model along with several TL architectures while the minimum accuracy recorded is 97.66% and the maximum accuracy is 99.67% on the generalized GoogleNet model. However, they did not clarify the result with an appropriate confusion matrix and loss accuracy curve.
Classification of brain tumor using TL architectures
The issues of the classical CNN model in feature reduction and requiring large training data turn to a more extended neural network model. Deep TL approaches have greatly addressed these problems. The use of TL algorithms effectively minimizes the computational complexity of ML classifiers. In addition, it can provide better outcomes even training on a small dataset. Therefore, researchers are now exploring various TL techniques in the case of brain tumor detection. Deepak et al. 33 used a pre-trained GoogLeNet TL model to extract features from the figshare brain MRI image dataset. They added three new layers to the base model. Utilization of the SVM and K-Nearest Neighbor classifiers instead of the classification layer helped to increase the model performance. However, they recorded accuracy by taking 10 epochs due to overfitting. The loss curve shows the decrease in training loss while the increase in validation loss indicates model overfitting.
Rayene et al. 34 used nine TL models to classify three types of brain tumors using contrast-enhanced magnetic resonance images (CE-MRI) benchmark dataset. They modified the last three layers of pre-trained networks in order to adapt them to brain tumor classification tasks. They observed the highest accuracy on AlexNet and VGG16-19 architecture rather than the deeper architecture. However, except for accuracy, they did not measure any other scale of model validation. To evaluate the efficiency of the model measurement of validation loss and actual loss is crucial.
Arbane et al. 35 implemented three TL architectures, namely ResNet, Xception, and MobilNet-V2. To categorize brain MRI with and without tumors they adapted the last two layers of the pre-trained networks as well as the loss of the function of the last layer from softmax to sigmoid as they performed classification tasks on the binary class 253 BT dataset. This attained the best results with 98.24% and 98.42% in terms of accuracy and F1-score, respectively. However, their model is computationally complex to build and lower accuracy compared to our model. Besides they trained the model by taking 20 epochs which is less than required.
A multi-modal brain tumor classification study is conducted by Gopal et al. 36 including five varied class MRI datasets. They launched the experiment using a CNN-based AlexNet TL system. Besides they presented a comparison of the performance of the deep learning model along with six different ML classifiers with multiple CV protocols. The deep TL model increased the accuracy in a greater range than the ML classifier in the case of with and without CV. Among the CV techniques, TT CV recorded better outcomes than K2, K5, and K10. The model achieved the highest accuracy of 100% on binary class data, 95.97% on three class data, 96.65% on four-class data, 87.14 on five class data, and 93.74 on six class data.
Another multi-modal brain tumor classification study is proposed by Muhammad et al. 37 Initially, they built the training model using Densenet201 architecture. For feature selection, they applied two techniques: Entropy–Kurtosis-based high feature values and a modified genetic algorithm (MGA) based on metaheuristics after the average pooling layer. Feature reduction is fulfilled through thresholding. The selected features are then refined and fused using a non-redundant serial-based approach and final features are classified using a multi-class SVM cubic classifier. They reported an accuracy of 99.9% on BRATS2018 and 99.7% on BRATS2019 datasets. However, the major drawback of this study is that the fusion process increases the computational time. Besides the feature reduction process sometimes reduces important features that have an impact on the accuracy.
Hassan et al. 38 classified brain tumors utilizing the binary class 253 small BT dataset. They explored VGG-16, ResNet-50, and Inception-v3 architecture to address tumor identification. To crop the dark edges from the images Open source Computer Vision (CV) Canny Edge Detection technique is used. Furthermore, they trained the models for 15 epochs with a batch size of 32. They achieved accuracy 96%, 89%, and 75% accuracy at VGG-16, ResNet-50, and Inception-V3, respectively. However, the model needs to fine-tune the parameters. Besides the validation and loss of the model is quite inconsistent.
Analyzing the prior research we have seen that the performance of the TL approach challenges the conventional approaches. TL frameworks have proven effective in reducing computational complexity, and time complexity. It can easily optimize, extract, and learn a large number of parameters that inspire us to implement TL for brain tumor classification. Though several studies recorded outstanding performance, many of them have issues with model overfitting, long computation time, fine-tuning of parameters, and low accuracy rate. Some study is conducted using a single dataset or an imbalanced and unlabeled dataset. Many developed models cannot classify multi-class brain tumor data. Besides the models that are trained on small data cannot predict genuinely except for the used datasets. In our study, we aimed to address these problems through effective fine-tuning of the important training parameters, incorporating pre-processing and several augmentation techniques to meet the data scarcity. To verify the model’s strength two different datasets is explored. Besides we recorded and analyzed the results through performance score-precision, recall, F1-score, accuracy, standard deviation (SD), and ROC value. Our model provides more accurate results with low computational complexity. Table 1 shows a list of methodologies, datasets, and performance of the previous years’ research.
Summary of related works.

CapsNet: Capsule Network; CE-MRI: contrast-enhanced magnetic resonance images; CNN: convolutional neural network; COM: co-occurrence matrix; 3D: three-dimensional; DT: decision tree; HBTC: hybrid-brain-tumor-classification; MB: meta bagging; MGA: modified genetic algorithm; ML: machine learning; MLP: multi-layer perceptron; MRI: magnetic resonance imaging; RBF: radial basis function; RLM: run-length matrix; RT: random; SVM: support vector machine; TL: transfer learning.
Proposed methodology
We created a multi-class brain tumor classification and prediction methodology using six TL frameworks because of the great contributions of TL approaches in earlier research. The experiment integrates data collection, pre-processing, data augmentation, feature extraction, fine-tuning of the parameters, and CV. Furthermore, the result is evaluated through various performance metrics: precision, recall, F1-score, accuracy, SD, and ROC values. The schematic block diagram of the experimental framework is shown in Figure 1.

Overview diagram of the proposed methodology.
This study was conducted from 2023 to 2024, encompassing a collaborative effort among researchers from Jagannath University, Deakin University, King Saudi Arabia, and Umm Al-Qura University. The nature of the study involves developing a deep learning model for brain tumor classification using TL models. Specifically, the study was approved by the Institutional Ethics Committee (IEC) of Jagannath University, with the ethics waiver number IEC/2024/341.
Image preprocessing
Preprocessing is an efficient way to enhance the visual appearance of the images in the dataset. This helps to increase the quality and add parameters to the MR pictures while, removing irrelevant noise and background of undesired parts, smoothing the regions of the inner part to maintain relevant edges.47,48 As we choose high-resolution MR image datasets, it does not require much processing. Since the original size of the images in the dataset contains different pixel numbers for different images, we resize all the images and convert them into the same size of

Few samples of magnetic resonance imaging (MRI) images (a) before and (b) after pre-processing.
Data augmentation
Data augmentation plays a very important role in making the deep learning model more reliable by enabling the neural network to be trained on a huge amount of training data. It expands the amount of data by adding copies of already existing data after a minimal alteration. Serving as a regularizer it also aids in minimizing overfitting as well as network generalization errors while a ML model is being trained. 50
In this research, we applied several augmentation methods 51 on image data to create a diversity of images based on rotation, shifting, rescaling, zooming, horizontal flipping, vertical flipping, brightness, and shearing operations. The Image Data Generator feature of TensorFlow’s Keras framework was used to carry out these tasks. 49 The value of the image data augmentation parameters, are as follows: rotation_range = 7, rescale = 1.255, zoom_range = 0.1, width_shift_range = 0.05, height_shift_range = 0.05, brightness_range = 0.05, shear_range = 0.2, vertical_flip = true and horizontal_flip = true. Each of these changes is considered as a distinct image thus extensively increasing the number of images in the dataset. Figure 3 displays a few instances of augmented pictures.

Samples of augmented brain magnetic resonance imaging (MRI) images.
Transfer learning (TL)
TL approaches reuse pre-trained knowledge and hence can be trained using fewer training data. Due to the ubiquity of TL approaches, we incorporate six pre-trained architectures including VGG16, EfficientNetB3, ResNet50, MobileNetV2, DenseNet201, and InceptionV3 in our methodology and adapt them to meet our requirements through a smooth modification process. We selected these models because of their outstanding feature extraction capacity with low error rates and accurate classification skills. All of these models were trained on the Imagenet dataset and had a pre-trained weight. To adapt the weights and inputs of the given dataset, we added five new layers excluding the last output layer. To address the overfitting issues, the models were trained on the widely augmented data. Furthermore, important parameters of the models are tuned to increase the accuracy rate.

Main two blocks of MobileNetV2.
Fine-tuning and feature extraction
As mentioned earlier, the study explores six different TL algorithms. The original architecture of the TL models was trained on the Imagenet dataset that contained about 14,197,122 images of 20,000 different categories of objects. 63 Initially, we downloaded the pre-trained models. To configure the custom input for classification, we excluded the top layer of the original model using the command include_top = False for all the selected models. Then we concatenated five new layers that were trained only in the given MRI datasets to increase the efficiency, feasibility, and adaptability of the models on the target datasets. The models were trained and evaluated using binary class and multi-class MRI image datasets. To extract deep features and accommodate the new weights of the brain MRI image datasets, we concatenated one global average pooling 2D layer, followed by one dropout layer with a dropout rate of 0.55, one dense layer with dense unit 60, another dropout layer with a dropout rate of 0.32, and a dense layer with dense unit 4 in all our training model.
To regularize the weights in the additional layer, the already preprocessed images were given as input instead of the raw data. Labeling of the input class as Yes, No, Glioma, Meningioma, Pituitary, No_tumors upgrades the model learning. Besides resizing all the images to

EfficientNetB3 architecture of our proposed methodology: (a) The original EfficientNetB3 model and (b) fine-tuned EfficientNetB3 model.
As seen in Figure 5(b), a 2D global average pooling layer is used to achieve downsampling by calculating the mean of the input’s height and width dimensions (spatial dimensions.). On many accounts, it is preferable over the flattening layer. It acts as a regularizer to reduce the overfitting of the model. The dropout layer used then acts as a mask, suppressing half of the neurons’ contributions to the subsequent layer while protecting the functionality of all other neurons. During training, the dropout layer randomly sets input units to 0 at a frequency rate at each step. Inputs that are not set to 0 are scaled up by
When it comes to reducing the loss function value, an optimizer is deployed along with the classifier. The optimization process of the neural network is an essential part as it sustains the weights, learning rate, and bias value to minimize the functional loss at the output. The experiment is launched parallelly to get the topmost optimization value using two widely used optimizers, Adam, and AdaMax. A sparse_categorical_crossentropy rather than categorical_crossentropy loss function is implemented to compute the loss value. Generally, categorical cross-entropy (CCE) generates a one-hot array containing the likely match for each category, while a category index of the most probable matching category is produced using the sparse CCE. The model is trained with a batch size of 13, epochs 70 and patience 50 for small datasets, and patience 70 for big datasets. We run the model several times varying the dropout values and optimizer parameters: learning rate and epsilon value to get a better outcome. The final value of these parameters for all the models is shown in Table 2. We used beta_1 = 0.91 and beta_2 = 0.9994 for all the models. Tuning of the parameters in the additional layers reduces the false positive (FP) and false negative (FN) values in the prediction of input classes.
Final value of the fine-tuned parameters for all the models on the binary class dataset.

Experiment and result analysis
Experimental setup and implementation
We put into practice the entire framework in Keras with graphics processing unit (GPU) support for TensorFlow. The Anaconda Navigator using a Jupyter Notebook environment served as the platform for the whole experiment, including training and testing. It required a PC running Microsoft Windows 10 Pro with an Intel(R) graphics card, Core (TM) i3-6006U CPU running at 2.00 GHz, 2000 MHz, 2 cores, 4 logical processors, 8 GB RAM, & 120 GB SSD. and 26 GB virtual memory. Code is written in Python programming language with a number of libraries such as Pandas, NumPy, Matplotlib, Seaborn, TensorFlow, Keras, Scikit-learn, etc. We also utilized the hosted Google Colab GPU.
Dataset description
The datasets utilized for this experiment are collected from Kaggle’s repository, all available publicly on the internet. To avoid the problems associated with class imbalance, we exploited the balanced datasets.
Distribution of brain tumor dataset 1.

Distribution of brain tumors dataset 2.

K = 5-fold CV
To evaluate the performance of our brain tumor classification model, we employed 5-fold CV. The dataset was split into five subsets, with each fold used as a validation set while the remaining four folds were utilized for training. This process was repeated five times, ensuring that every subset was used for validation exactly once. The final performance metrics were obtained by averaging the results across all five folds, providing a robust estimate of the model’s generalization capability.
Evaluation of performance metrics
To assess the effectiveness of the developed model for classifying different classes from the input data, we used four metrics, accuracy, sensitivity or recall, precision, and F1 score. The values of these metrics are measured and obtained through the confusion matrix. In a 2D table of actual versus predicted classes, the confusion matrix presented us with the total correct and incorrect prediction of the model for each class.
The most obvious performance statistic is accuracy, which is inversely correlated with the fraction of properly predicted observations to all observations. The formula can be depicted as: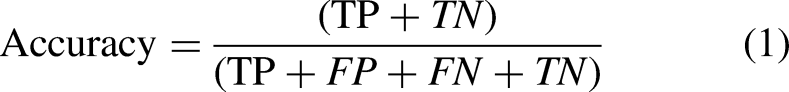



CCE loss
In addition, the loss function was used in this study to evaluate how well the anticipated model performed. A CCE loss was used to train the model as well as to lower the cost of the model parameters. The value of the loss function is minimized by increasing the number of epochs. It is obtained using the depicted equation:
Normalization of confusion matrix
Normalization of the confusion matrix is accomplished to compute and represent all the samples of each category on a scale of 1.00. The precision values are determined by adding the sums of the columns for each value or sample that is allocated to a certain class, and, then dividing the diagonal values by these sums. The diagonal values of the matrix represent the recall or sensitivity values. These values can be obtained using the following formula: 6.

Area under the receiver operating characteristic curve (AUC-ROC) curve
Graphs that display the TP rate and FP rate of classifiers are known as AUC-ROC curves. It shows the AUC-ROC curve. We utilized the ROC curve in the binary class dataset to evaluate the performance. Usually, it plots the true positive rate (TPR) and false positive rate (FPR) on the
Standard deviation (SD)
SD, a statistic that captures how much the data values deviate from the mean, is a frequently used method to quantify data spread. This is obtained by computing the square root of the variance, or the average of the squared deviations between each data value and the mean. When the SD is low, it indicates that the data values are near the mean; when it is high, it indicates that the data values are dispersed over a large range. The larger deviation also represents a larger bias or error. We computed the SD for model evaluation for both two-class and multi-class data.
Results analysis and discussion
As said previously this research explored two MRI brain tumor datasets for six deep learning frameworks. First, we launched the experiment on a small dataset containing only two types: “Yes” and “No.” After achieving remarkable accuracy in the small dataset, we relaunched the experiment on a big dataset containing three tumor classes. The outcome of these models according to the implemented methodology is analyzed for both datasets. The parameters of the models are trained and optimized taking batch size 13 on 70 epochs. To test the model’s gradient values in a small and big amount of data the experiment is launched using two widely used optimizers: Adam and AdaMax. Adam is selected as it functions well with a variety of paradigms, reduces memory requirements, and is easy to implement. Furthermore, it adjusts the learning rate for each weight of the neural network by estimating the first and second moments of the gradient. AdaMax is a variant of Adam that employs the L-infinity norm of the gradients rather than the second moment of the gradients. It is selected as it can handle the vanishing-gradient and exploding-gradient problems and also provide faster convergence. Besides AdaMax performs well in case of extremely sparse gradients.
Dataset-1 (two class)
We split the small dataset by taking 85% of the samples for training purposes, while the remaining 15% for testing. To keep the pdf smaller, we provided the loss, accuracy graph, and confusion matrix before and after normalization only for MobileNetV2 architecture. We launched two experiments in this dataset for the effective evaluation of the results.
Experiment 1
We perform classification by splitting the dataset. The classification result of each class is then evaluated using performance metrics precision, recall, F1-score, and accuracy for both optimizers.

Performance results of MobileNetV2 using Adam optimizer for the two-class dataset: (a) actual versus validation loss; (b) actual versus validation accuracy; (c) confusion matrix before normalization; and (d) confusion matrix after normalization.
True prediction value of the classes obtained through the confusion matrix in the two-class dataset without cross-validation.

Performance analysis of the models using optimizer Adam on two-class datasets without cross-validation.


Performance results of MobileNetV2 using AdaMax optimizer for the two-class dataset: (a) actual versus validation loss; (b) actual versus validation accuracy; (c) confusion matrix before normalization; and (d) confusion matrix after normalization.
Performance analysis of the models using optimizer AdaMax on two-class datasets.

Accuracy of the transfer learning models on two-class datasets using our proposed methodology.

As for both optimizers, the training and testing accuracy of all the models are recorded to 100, we launched another experiment in this dataset to validate the model performance.
Experiment 2
We launched this experiment implementing a five-fold CV approach along with various performance metrics precision, recall, F1-score, accuracy, SD, and AUC-ROC curve using AdaMax optimizers. The value of these metrics for each fold is listed through Tables 9 and 10 of all the model. We computed the average of the results obtained in all the test sets for all the metrics.
Performance analysis of the models using optimizer AdaMax on two-class datasets after cross-validation.

ROC: receiver operating characteristic; SD: standard deviation.
Performance analysis of the models using optimizer AdaMax on two-class datasets after cross-validation.

ROC: receiver operating characteristic; SD: standard deviation.
After CV, the VGG16 model achieved the highest accuracy of 99.95% in Fold4 with an SD of 0.115. The model achieved an average accuracy of 99.87% and an average SD of 0.120. EfficientNetB3 model achieved the highest accuracy of 99.98 in Fold5 with an SD of 0.105. The model achieved an average accuracy of 99.95% and an average SD of 0.111. DenseNet201 model achieved the highest accuracy of 99.986 in Fold4 with an SD of 0.109. The model achieved an average accuracy of 99.943 and an average SD of 0.113. InceptionV3 model achieved the highest accuracy of 99.996% in Fold5 with an SD of 0.103. The model achieved an average accuracy of 99.95 and an average SD of 0.110. MobileNetV2 model achieved the highest accuracy of 99.998 in Fold5 with an SD of 0.100. The model achieved an average accuracy of 99.96% and an average SD of 0.105. ResNet50 model achieved the highest accuracy of 99.96 in Fold4 with an SD of 0.109. The model achieved an average accuracy of 99.943% and an average SD of 0.113. As the result achieved effective outcome in all the parameters there is no issue of potential bias.
Dataset-2 (Four Class)
We justified the performance obtained in the two class 253 image dataset utilizing another four-class dataset. We split this dataset by taking 80% of the samples for training purposes, while the remaining 20% for testing. The classification of tumor classes is carried out for all the selected models. The result is evaluated through precision, recall, F1-score, accuracy, and SD. The model can classify glioma, meningioma, pituitary tumor tissues, and normal brain tissues more accurately.

Performance results of MobileNetV2 using Adam optimizer for the four-class dataset: (a) actual versus validation loss; (b) actual versus validation accuracy; (c) confusion matrix before normalization; and (d) confusion matrix after normalization.
True prediction value of the classes obtained through the confusion matrix in the four-class dataset.
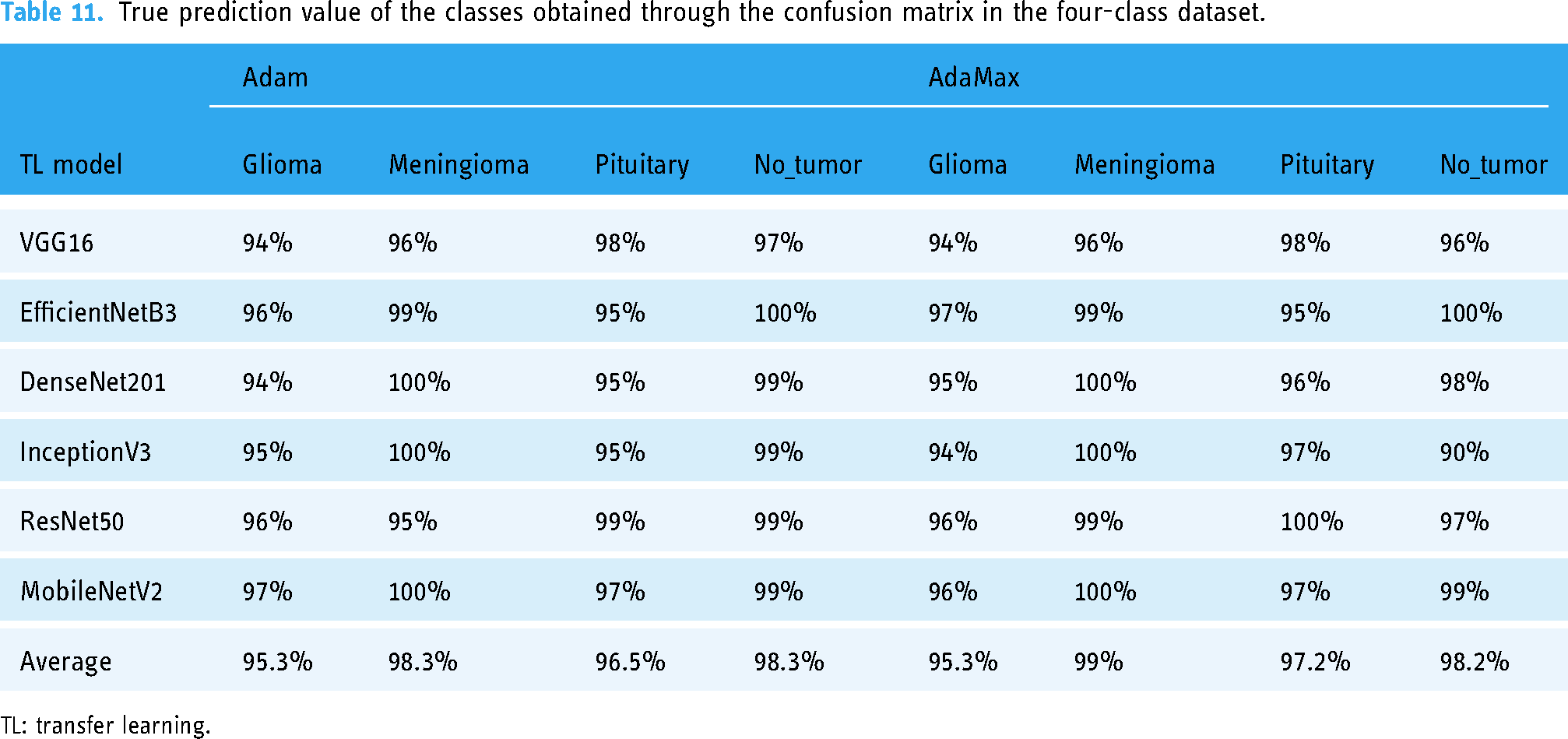
TL: transfer learning.
Performance analysis of the models for four classes using optimizer Adam.

Performance analysis of the models for four classes using optimizer AdaMax.

Accuracy and standard deviation (SD) of the transfer learning models on four class datasets using our proposed methodology.

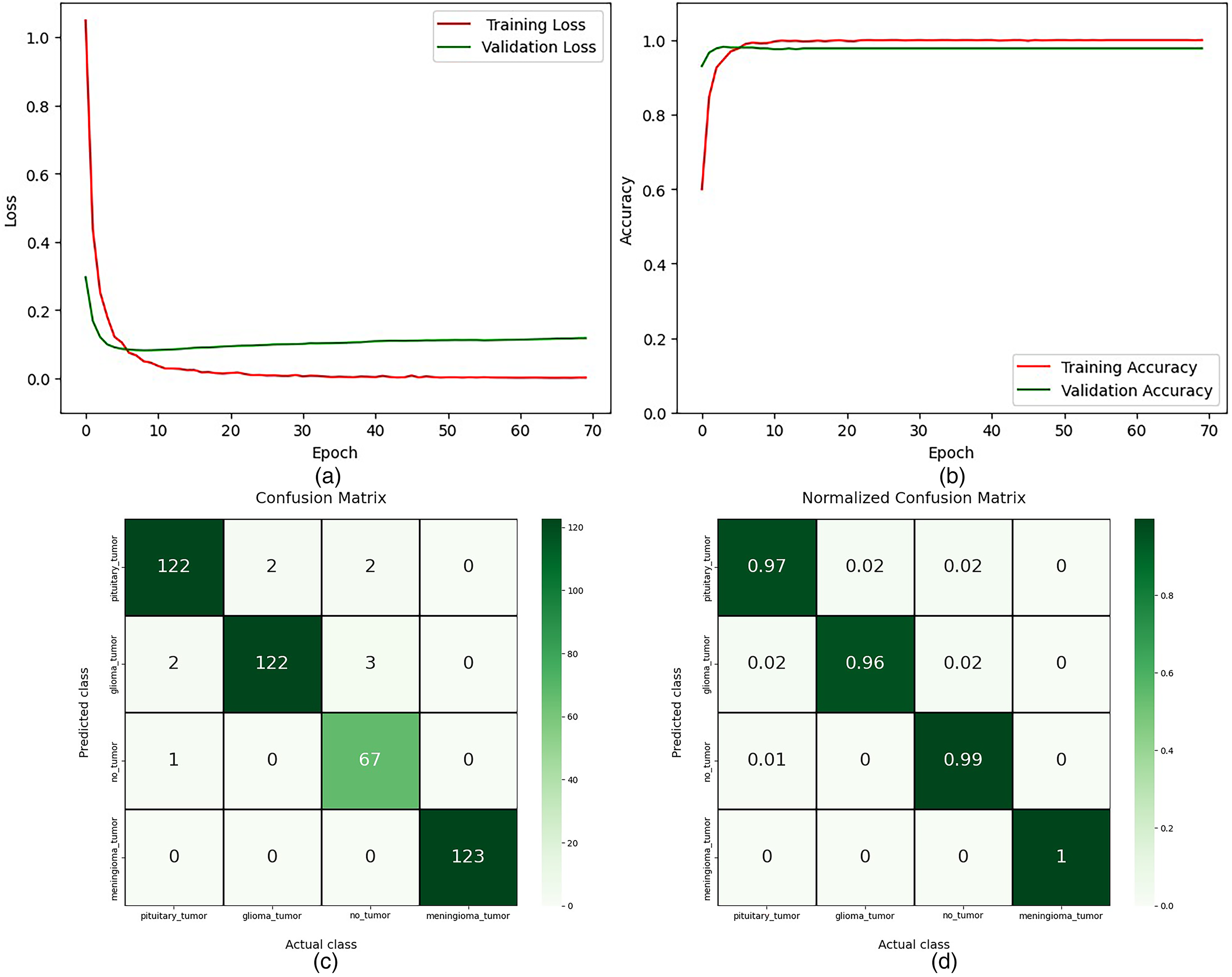
Performance results of MobileNetV2 using AdaMax optimizer for the four-class dataset: (a) actual versus validation loss; (b) actual versus validation accuracy; (c) confusion matrix before normalization; and (d) confusion matrix after normalization.

Some samples of misclassified images.
Discussion
To get a stable accuracy, we observe the result by increasing the number of epochs from 50 to 70. In experiment one, our proposed model achieves 100% testing accuracy on the two-class dataset. In experiment two, our proposed framework obtained 99.99% testing accuracy with ROC 100 utilizing the CV method on the two-class dataset. Furthermore, in the four-class dataset, our model achieved 98.20% accuracy. Our proposed framework has reduced the overfitting issues of the model. Tables 8 and 14 show that the performance results for Adam and AdaMax optimizers are quite similar. However, as indicated in Table 15, AdaMax demonstrates faster computational performance compared to Adam, reducing the time per epoch except for VGG16 and ResNet50. MobileNetV2, with the fewest parameters, exhibits the lowest execution time and highest accuracy, while InceptionV3 follows as the second fastest model with high accuracy. In contrast, DenseNet201, EfficientNetB3, and ResNet50 require significantly more computational time, but these models also provide high accuracy values. VGG16, despite its popularity, shows lower effectiveness in precision, recall, F1-score, and overall accuracy compared to other models. The number of total parameters, trainable parameters, and non-trainable parameters in each model remains constant regardless of the optimizer or dataset used. However, the execution time of different models is also influenced by the number of layers and parameters.
Parameters details and execution time of the models on both datasets using our proposed methodology.
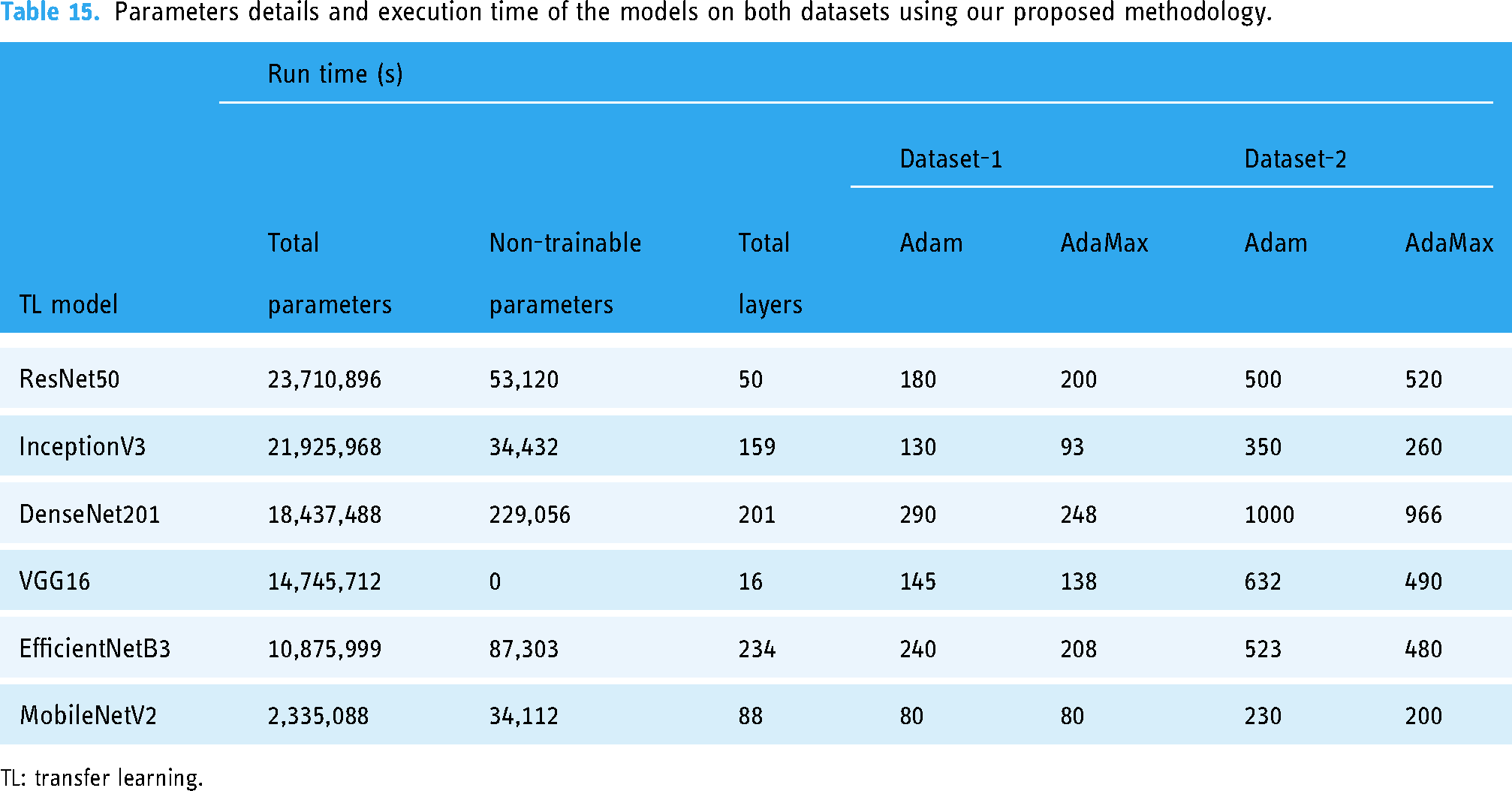
TL: transfer learning.
Comparison with the state-of-the-art methods
To address the detection and classification of brain tumors, numerous researchers around the world are working incredibly hard. Several datasets have been created using the clinical brain MRI reports of a lot of patients and various methodologies emerged of extreme research in this field. A comparison is carried out to demonstrate the efficacy of our experimented framework with other state-of-the-art methods considering both the 253 image dataset and the 3264 image dataset.
The experimented results of our proposed methodology for the corresponding study on the small dataset are illustrated in Table 16 along with the other state-of-the-art models. As listed in the table, in the small binary class dataset, our implemented framework appeared with excellently higher performance. As mentioned earlier, we achieved a test accuracy of 100% in all the selected models with the precision, recall, F1-score value 1.00 in each class in experiment one according to Tables 6 to 8. Our model can predict the actual number of each class with 100% accuracy as shown in Table 5. Besides the execution time of our model is also very small compared to others as shown in Table 15. Another experiment on the small dataset also achieved outstanding accuracy, ROC value, precision, recall, and F1-score value with small deviation for each fold of CV as shown in Tables 9 and 10. However, Hassan et al. 38 classified brain tumors utilizing VGG-16, ResNet-50, and Inception-v3 architecture using this 253 BT dataset with accuracy 96%, 89%, and 75% accuracy at VGG-16, ResNet-50, and Inception-V3, respectively. Their model obtained very poor accuracy while lacking other performance metrics for result analysis. Furthermore, they did not perform fine-tuning of the parameters. Arbane et al. 35 implemented three TL architectures, namely ResNet, Xception, and MobilNet-V2 to categorize brain MRI. This attained the best results with 98.24% and 98.42% in terms of accuracy and F1-score, respectively. To create tumor boundary they applied the OpenCV method. However, their model is computationally complex to build and lower accuracy compared to our model. An automated hybrid system for classifying brain tumors is presented by Kang et al. 30 To ensemble three top features they utilized several pre-trained deep learning models for feature extracting with various ML classifiers. The study reported 92.16% accuracy on the BT-small-2c dataset. Except for accuracy, they did not measure any other performance score and also did not analyze the computation time of their hybrid model.
Performance results in comparison among the suggested model and the other previous state-of-art works based on four class categories using 253 magnetic resonance (MR) image dataset.

The experimented results for the corresponding study on the big dataset are illustrated in Table 17 along with the other state-of-the-art models. The highest accuracy obtained in our experiment is 98.20% with a little deviation of 0.120. The precision, recall, and F1-score values are also higher in this dataset. Besides our model has low computational time thus low computation complexity compared to the existing studies. While the accuracy of the existing model is not more than 90%. Their accuracy is comparatively very low. However, our models performed smoothly on both datasets for all the selected architectures with greater accuracy. Sunanda Das et al. 27 developed a CNN model for the classification of brain tumors in T1-weighted contrast-enhanced MRI images; a dataset of 3064 photos of three different forms of brain tumors (glioma, meningioma, and pituitary). They used a Gaussian filter, and histogram equalization to preprocess the input data and three dropout layers in the classification model with a dropout rate of 25%, 40%, and 30%. Though dropout reduces overfitting, inappropriate dropout rates decrease the strength of the neural network. However, they gained a testing accuracy of 94.39%. Their testing loss is high. Parnian et al. 29 developed Capsule Networks (CapsNets) to overcome the shortcomings in CNN to fully utilize spatial relations. The suggested improved CapsNet architecture incorporates additional inputs from the tumor coarse borders into its pipeline to sharpen the CapsNet’s focus. The model handled transformations in a “Routing by Agreement” process instead of a pooling layer, during which lower-level capsules forecast how their higher-level parents will behave. However, this method is incapable of interpreting the features of brain tumors efficiently. They do not perform any pre-processing technique. Their model does not obtain a higher prediction outcome, on the contrary, model computation is complex. The accuracy of this approach is 90.89%. Utilizing a hybrid system for classifying brain tumors, Kang et al. 30 achieved 93.72% accuracy on the BT-large-4c dataset. The model is not reliable. Their prediction outcome is also lower than us. Besides except accuracy, they did not measure any other performance score and also did not analyze the computation time of their hybrid model.
Performance results in comparison among the suggested model and the other previous state-of-the-art works based on four class categories using the 3064 MR image dataset.

CNN: convolutional neural network; MR: magnetic resonance.
Practical implications and limitations
Although our proposed models demonstrated superior performance, it is essential to discuss their practical implications. Integrating these models into clinical workflows could potentially enhance the accuracy and efficiency of brain tumor diagnosis. However, challenges such as the need for robust validation in diverse clinical settings, potential biases in the datasets, and the limitations of the study should be acknowledged. Further validation and testing in real-world scenarios are necessary to confirm the generalizability of the models.
Ethical considerations of artificial intelligence (AI) models in clinical environments
To address ethical considerations in implementing AI models in clinical environments:
Addressing these concerns promotes responsible AI use in healthcare, prioritizing patient safety and fairness.
Conclusions
This experiment successfully developed an efficient and fine-tuned deep neural network architecture utilizing pre-trained models for the detection and classification of brain tumors. From data collection to feature extraction, the experiment employed effective preprocessing techniques, data augmentation, and fine-tuning of parameters, leading to the reconstruction of models and the observation of robust outcomes. Iterative optimization of various parameters resulted in stable and high prediction accuracy. Regularization and the addition of extended layers significantly enhanced prediction accuracy while reducing model overfitting. In addition, implementation of CV with several evaluation metrics makes the model computationally effective.
Among the six implemented models, MobileNetV2 stood out with the lowest execution time and highest accuracy, whereas VGG16 faced challenges and achieved the lowest accuracy. The comparison between the Adam and AdaMax optimizers showed consistent results, with AdaMax offering faster computation. For the small dataset, all models achieved 100% accuracy without CV for both training and testing. After performing CV, the models generate an average accuracy of 99.96% with higher precision, recall, F1-score, and ROC value demonstrating the effectiveness of our framework. On the larger dataset, the models maintained strong performance, with the highest testing accuracy reaching 98.20% and training accuracy reaching 100%.
Our experiment shows that the proposed framework is robust, reliable, and capable of supporting medical professionals in the timely and accurate diagnosis of brain tumors. However, real-time implementation and integration into clinical workflows would require further validation in diverse clinical settings.
Future work
Future research will focus on:
These steps aim to enhance the framework’s real-world applicability and effectiveness in brain tumor diagnosis.
Footnotes
Acknowledgement
The authors would like to extend their sincere appreciation to the Researchers Supporting Project Number (RSP2024R301), King Saud University, Riyadh, Saudi Arabia.
Contributorship
SMR contributed to conceptualization, data curation, methodology, software, formal analysis, visualization, writing—original draft and writing—review and editing. MMI contributed to supervision, methodology, investigation, validation, and project administration. MAT contributed to investigation, validation, methodology, visualization, and writing—review and editing. MAU contributed to supervision, investigation, resources, validation, and writing—review and editing. MK and MK contributed to investigation, validation, and visualization. MZK contributed to visualization, validation, methodology, and investigation.
Declarations of conflicting interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethics approval
Not applicable.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the Grant for Advanced Research in Education (GARE), Bangladesh Bureau of Educational Information & Statistics (BANBEIS), Ministry of Education, Government of the People’s Republic of Bangladesh, GO NO. 37.20.0000.004.033.020.2022, fiscal year 2022–2024.
Informed Consent
Not applicable.
Availability of data and materials
The selected datasets are sourced from free and open-access sources such as Dataset-1: https://www.kaggle.com/datasets/navoneel/brain-mri-images-for-brain-tumor-detection, Dataset-2: ![]() .
.
Guarantor
MAT.