
Abstract
Background
Artificial intelligence (AI), particularly GPT models like GPT-4o (omnimodal), is increasingly being integrated into healthcare for providing diagnostic and treatment recommendations. However, the accuracy and clinical applicability of such AI systems remain unclear.
Objective
This study aimed to evaluate the accuracy and completeness of GPT-4o in comparison to resident physicians and senior infectious disease specialists in diagnosing and managing bacterial, fungal, and viral infections.
Methods
A comparative study was conducted involving GPT-4o, three resident physicians, and three senior infectious disease experts. Participants answered 75 questions—comprising true/false, open-ended, and clinical case-based scenarios—developed according to international guidelines and clinical practice. Accuracy and completeness were assessed via blinded expert review using Likert scales. Statistical analysis included Chi-square, Fisher's exact, and Kruskal–Wallis tests.
Results
In true/false questions, GPT-4o showed comparable accuracy (87.5%) to specialists (90.3%) and exceeded residents (77.8%). Specialists outperformed GPT-4o in accuracy on open-ended (p = .008) and clinical case-based questions (P = .02). However, GPT-4o demonstrated significantly greater completeness than residents on open-ended (P < .0001) and clinical case-based questions (P = .01), providing more comprehensive explanations.
Conclusions
GPT-4o shows promise as a tool for providing comprehensive responses in infectious disease management, although specialists still outperform it in accuracy. Continuous human oversight is recommended to mitigate potential inaccuracies in clinical decision-making. These findings suggest that while GPT-4o may be considered a valuable supplementary tool for medical advice, it should not replace expert consultation in complex clinical decision-making.
Keywords
Introduction
The emergence of artificial intelligence (AI) has profoundly impacted medicine, offering the potential to deliver medical advice more conveniently and efficiently. 1 With the digitalization of medicine and the integration of software applications with health big data, the use of AI in healthcare has significantly expanded. 2 AI applications have been demonstrated across various medical specialties, from orthodontics, trauma evaluation to neurological and diagnostics.3–8
OpenAI's ChatGPT is a pioneering AI in natural language processing, capable of rapidly interpreting vast amounts of medical literature and patient data. The recent release of GPT-4o (omnimodal) enhances these capabilities, allowing it to process and generate text, images, video, and audio. It holds significant potential for providing theoretical explanations and treatment advice in medicine. 9 Approximately 80% of patients reportedly use online resources to address health-related concerns. Ayers et al. found that 78.6% of respondents preferred chatbot responses, citing higher quality and more empathetic answers. 10 However, whether AI can professionally deliver scientifically valid advice remains unclear, and the accuracy of its responses to medical queries is largely unknown. Therefore, assessing chatbots like GPT-4o is crucial for understanding the accuracy of the content that patients and healthcare providers might encounter.11,12
Recent literature has highlighted differences between AI systems like ChatGPT and human experts, particularly in the domain of complex medical decision-making. A study by Massey et al. indicated that ChatGPT-3.5 and GPT-4 performed below the level of orthopedic residents in orthopedic evaluations. 13 In a prospective study, Maillard et al. assessed the quality and safety of ChatGPT-4's management recommendations for patients with positive blood cultures, concluding that relying on GPT-4 without expert consultation is risky, especially in severe cases. 14 In another instance, ChatGPT's two diagnostic and therapeutic recommendations for brain abscesses conflicted with the guidelines of the ESCMID (European Society of Clinical Microbiology and Infectious Diseases), potentially endangering patient safety. 15 Wilhelm et al. evaluated the performance of four prominent large language models (LLMs) in clinical specialties such as ophthalmology, orthopedics, and dermatology, revealing variations in quality and reliability, with different models exhibiting distinct error patterns, such as diagnostic confusion and ambiguous advice. 16 These studies suggest that ChatGPT may not accurately address complex clinical scenarios, particularly in specialties like microbiology and antimicrobial therapy, where the interpretation of dynamic and complex clinical situations is critical. The advent of ChatGPT has introduced new opportunities and challenges in infectious disease management, particularly regarding antimicrobial recommendations. 17 Various authors have explored ChatGPT's application in infectious diseases, sparking discussions on whether chatbot AI might eventually replace traditional roles in disease management.18,19
It is urgent to evaluate chatbot AI's performance in addressing complex medical issues, along with the potential implications and risks of ChatGPT's growing use in healthcare. Infectious diseases, as a medical specialty, involve constantly evolving conditions that require considering complex treatment guidelines, patient backgrounds, pathogens, infection sites, and potential complications. Our study aims to assess GPT-4o's ability to provide diagnostic insights and treatment recommendations for bacterial, fungal, and viral infections, evaluating its performance in handling complex clinical questions according to international guidelines, and comparing it with resident physicians and expert groups.
Methods
Study design and participants
This comparative study aimed to evaluate the accuracy and completeness of responses provided by GPT-4o, resident physicians, and senior clinical microbiology experts on questions related to bacterial, fungal, and viral infections. The study included three groups of participants: three senior clinical microbiology experts, three resident physicians, and the GPT-4o model.
Inclusion and exclusion criteria
Resident physicians were eligible if they had completed at least 1 year of clinical training in infectious diseases or clinical microbiology. Senior experts were included if they had a minimum of 5 years of experience in infectious diseases or clinical microbiology and held a senior academic or clinical appointment. Participants who were involved in question design, pilot testing, or scoring were excluded to avoid bias. GPT-4o was tested using a consistent version throughout the study period; no exclusion criteria applied to the AI model.
A total of 75 questions were developed by a panel of infectious disease experts, covering three major infection types: bacterial, fungal, and viral. For each infection type, the assessment included 8 true/false questions, 8 open-ended questions, and 9 clinical case-based open-ended questions, resulting in 25 questions per category and 75 in total. The true/false and open-ended questions were formulated in accordance with both domestic and international guidelines from Infectious Diseases Society of America (IDSA), European Organization for Research and Treatment of Cancer and the Mycoses Study Group Education and Research Consortium (EORTC/MSGERC), American Thoracic Society/Infectious Diseases Society of America (ATS/IDSA), American Society for Microbiology (ASM), European Confederation of Medical Mycology (ECMM), among others. The clinical case-based open-ended questions were derived from real-world clinical scenarios constructed by the expert panel based on their practical experience. All cases were de-identified and did not involve any protected patient information.
Although the assessment was not based on a previously validated instrument, the test items were developed through expert consensus and aligned with real-world clinical decision-making. To improve clarity and face validity, the full set of questions underwent a pilot test involving three independent infectious disease clinicians. Feedback from the pilot test was used to refine ambiguous wording and improve content coverage.
Data collection
Participants were required to answer 75 questions independently. The true/false and clinical case-based open-ended questions were designed to evaluate the participants’ accuracy in diagnosing and recommending treatments for specific infections. The open-ended questions required more detailed responses, expecting participants to demonstrate their understanding and provide comprehensive explanations based on clinical guidelines and knowledge. Residents and specialists were permitted to use any necessary resources, except for ChatGPT and similar AI tools, to answer the questions. For GPT-4o, queries were manually entered, and responses were directly collected from the interface. To simulate expert-level clinical reasoning in response to case-based scenarios, a standardized role-based prompt was used prior to each clinical case input. Specifically, the following instruction was included before each case:
“If you were a specialist in microbiology and infectious diseases, with expertise in the diagnosis and treatment of infectious conditions, I would like you to provide professional recommendations based on the following clinical case.” This prompt was applied consistently to ensure contextual alignment across all cases.
The full list of true/false and open-ended questions is available in Supplementary Material 1, and the clinical case questions are presented in Supplementary Material 2.
Blind evaluation
The answers to the open-ended questions and the clinical case questions underwent a blind review by an expert evaluation panel. This panel used a Likert scale to assess the accuracy and completeness of the responses, comparing them against established international guidelines and relevant clinical knowledge.
Accuracy was evaluated using a six-point Likert scale, where (1) represents a completely incorrect response; (2) indicates that incorrect elements outweigh correct elements; (3) suggests a balance between correct and incorrect elements; (4) indicates that correct elements outweigh incorrect elements; (5) is used for responses that are nearly entirely correct; and (6) represents a completely correct response.
For assessing completeness, a three-point Likert scale was used: (1) represents an incomplete answer that only addresses certain aspects of the question and is missing significant parts; (2) provides an adequate answer that covers all necessary aspects of the question; and (3) represents a comprehensive answer that covers all aspects of the question and includes additional information or context beyond what was expected.
Statistical analysis
Statistical methods were used to compare the performance of different groups (senior specialists, GPT-4o, and residents). Accuracy was described using absolute numbers and percentages. The Chi-square test was employed to assess differences between groups, with Fisher's exact test applied when more than 20% of expected cell counts were less than five. The accuracy and completeness scores for the open-ended questions were described using the median and interquartile range. Normality was assessed with the Kolmogorov–Smirnov test, and the Kruskal–Wallis test was applied to evaluate differences in accuracy and completeness score between groups. A p-value of less than 0.05 was considered statistically significant. All statistical analyses were performed using SPSS 26.0 (SPSS Inc.; Chicago, IL, USA) and GraphPad Prism 9.0 (GraphPad Software Inc.; San Diego, CA, USA).
Results
True or false questions
In the comparison of accuracy in answering true or false questions among GPT-4o, specialists, and residents, no significant differences were found among the three groups (Figure 1) (p = .11). The percentage of correct responses was highest in the specialists group (90.3%), followed closely by the GPT-4o (87.5%), with the resident physicians showing a slightly lower accuracy rate (77.8%). While all groups demonstrated a strong ability to answer correctly, the residents had a slightly higher proportion of incorrect answers compared to GPT-4o and the specialists.
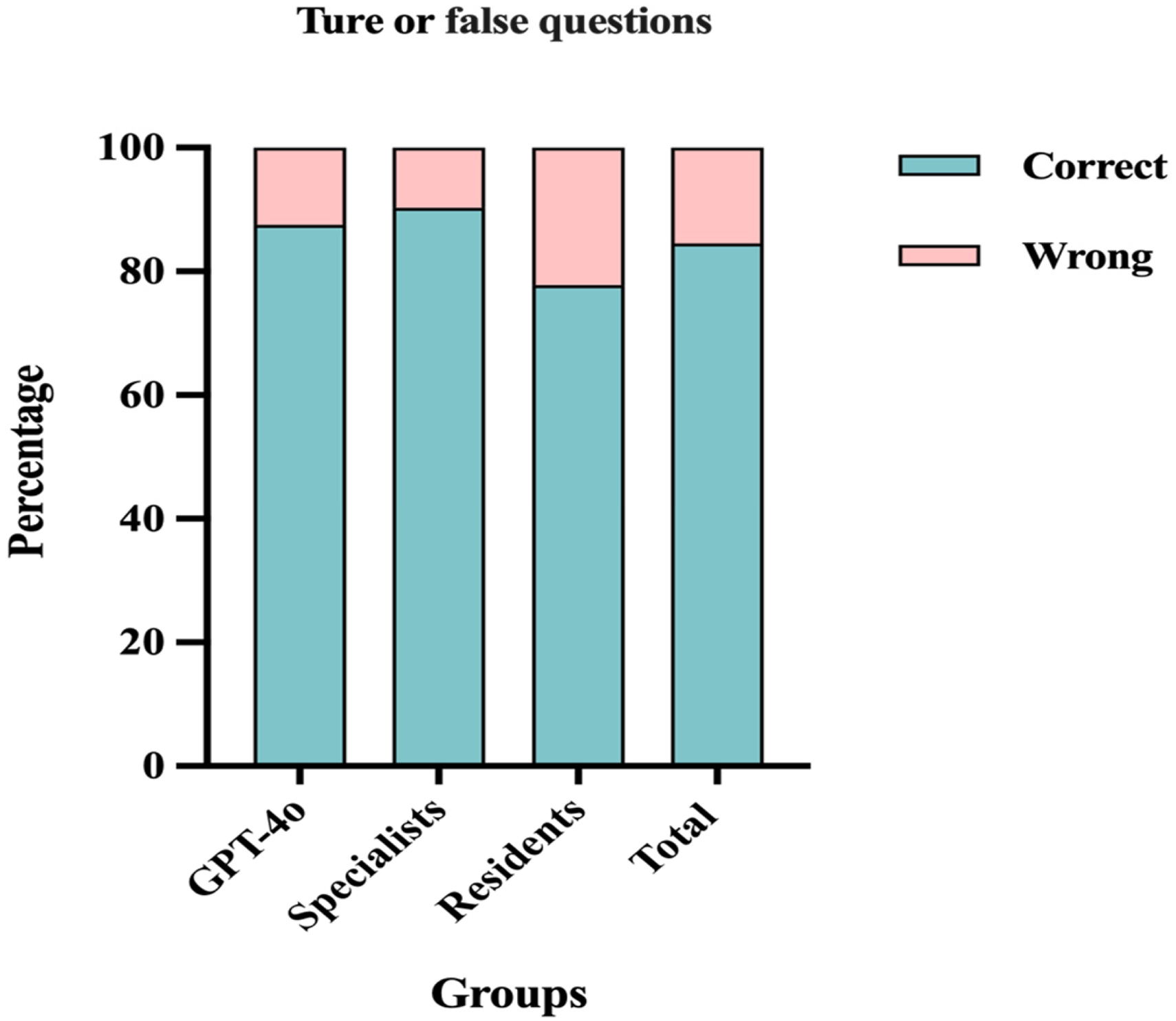
Percentage of correct and wrong answers for the true or false questions among GPT-4o, specialists, and residents.
Notably, there were no significant differences in the accuracy of responses across the different types of infections: bacterial, fungal, and viral (Supplementary Material 3 - Table S1). However, specialists achieved a higher percentage of correct answers for bacterial infections (100%) compared to GPT-4o (75.0%) and residents (70.8%) (p = .009). In contrast, the differences in accuracy among the groups for fungal infections (p = .54) and viral infections (p = .60) were not statistically significant (Figure 2). In contrast, GPT-4o performed better on questions related to fungal infections. Interestingly, GPT-4o outperformed the other groups on questions related to fungal infections.
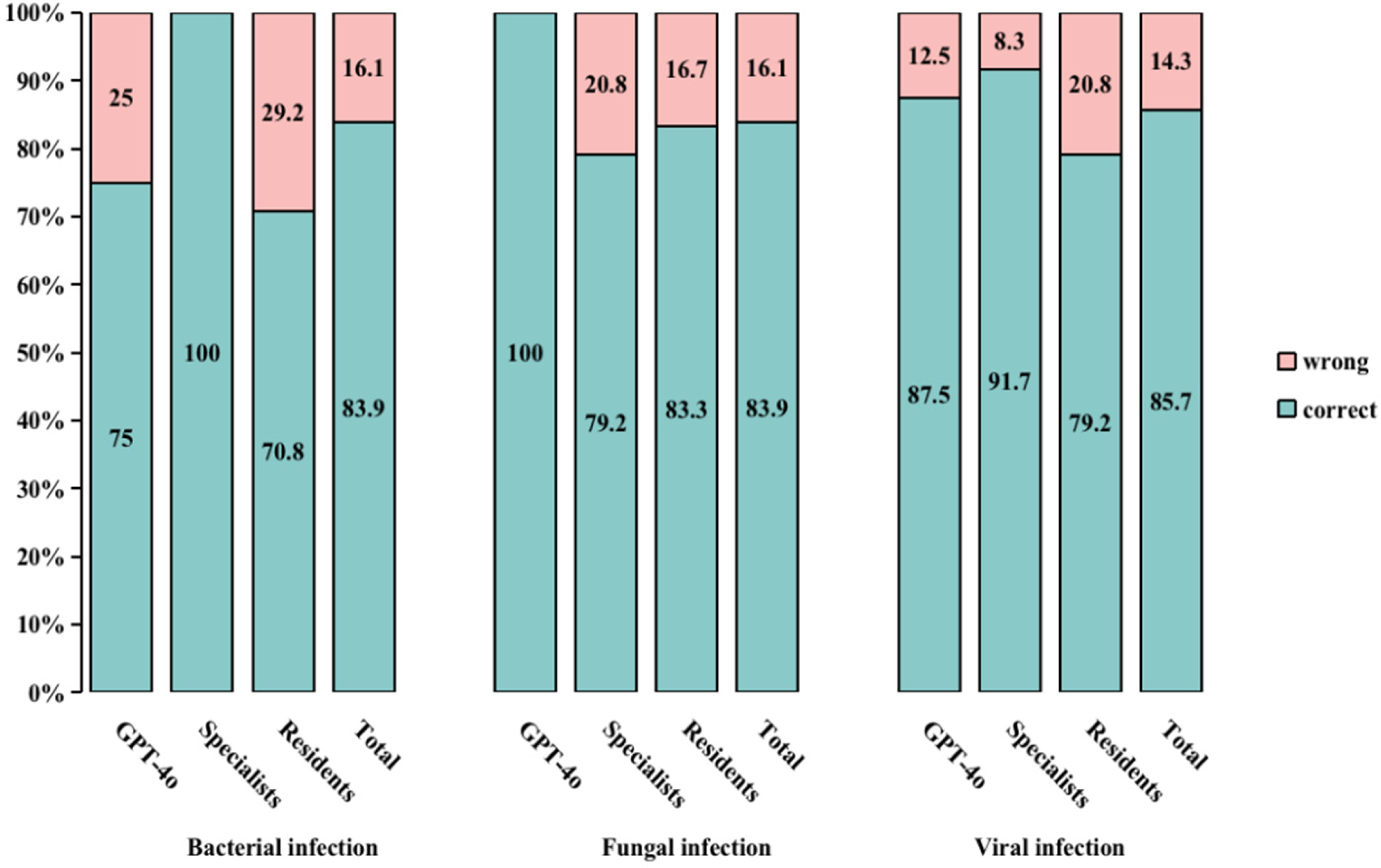
Percentage of correct and wrong answers for the true or false questions about bacterial, fungal, and viral infections in the different groups. aBacterial infection among the three groups:
Open-ended questions
When evaluating the accuracy and completeness of responses to open-ended questions across different groups, the observed differences in accuracy and completeness scores were statistically significant (Table 1). Specialists delivered more 6-point answers than both residents and GPT-4o, while GPT-4o excelled in completeness, achieving the highest percentage of 3-point scores.
Accuracy and completeness for open-ended infection questions among GPT-4o, specialists, and residents.

Results are presented as n (%).
P-value calculated with Fisher's exact test. *: P < .05; **: P < .01; ***: P < .001.
Further comparisons between the three groups showed that specialists outperformed GPT-4o in accuracy (p = .008), while no significant difference was observed between GPT-4o and residents (p = .09). In terms of completeness, GPT-4o demonstrated a significantly higher ability to provide comprehensive answers compared to residents (p < .001). Additionally, the difference in completeness between specialists and residents was statistically significant (p = .004) (Figure 3). Moreover, no statistically differences were observed in accuracy or completeness across different types of infectious diseases (Supplementary Material 3- Tables S2–3).
Comparison of accuracy and completeness in open-ended questions among GPT-4o, specialists, and residents. ap-value calculated with Kruskal–Wallis test, ****p < .0001; **p < .01; ns: p > .05. Accuracy: GPT-4o vs. Specialists p = .009; GPT-4o vs. Residents p = .09; Specialists vs. Residents p = .74; completeness: GPT-4o vs. Specialists p = .055; GPT-4o vs. Residents p < .0001; Specialists vs. Residents p = .004.
Clinical cases
Significant differences were observed among GPT-4o, specialists, and residents regarding both accuracy (χ² = 54.968, p < .001) and completeness (χ² = 53.761, p < .001) in clinical case responses (Table 2). Specialists demonstrated significantly superior accuracy and completeness, predominantly achieving the highest scores.
Accuracy and completeness for clinical case open-ended questions among GPT-4o, specialists, and residents.

Results are presented as n (%).
P-value calculated with Chi-square test. *: P < .05; **: P < .01; ***: P < .001.
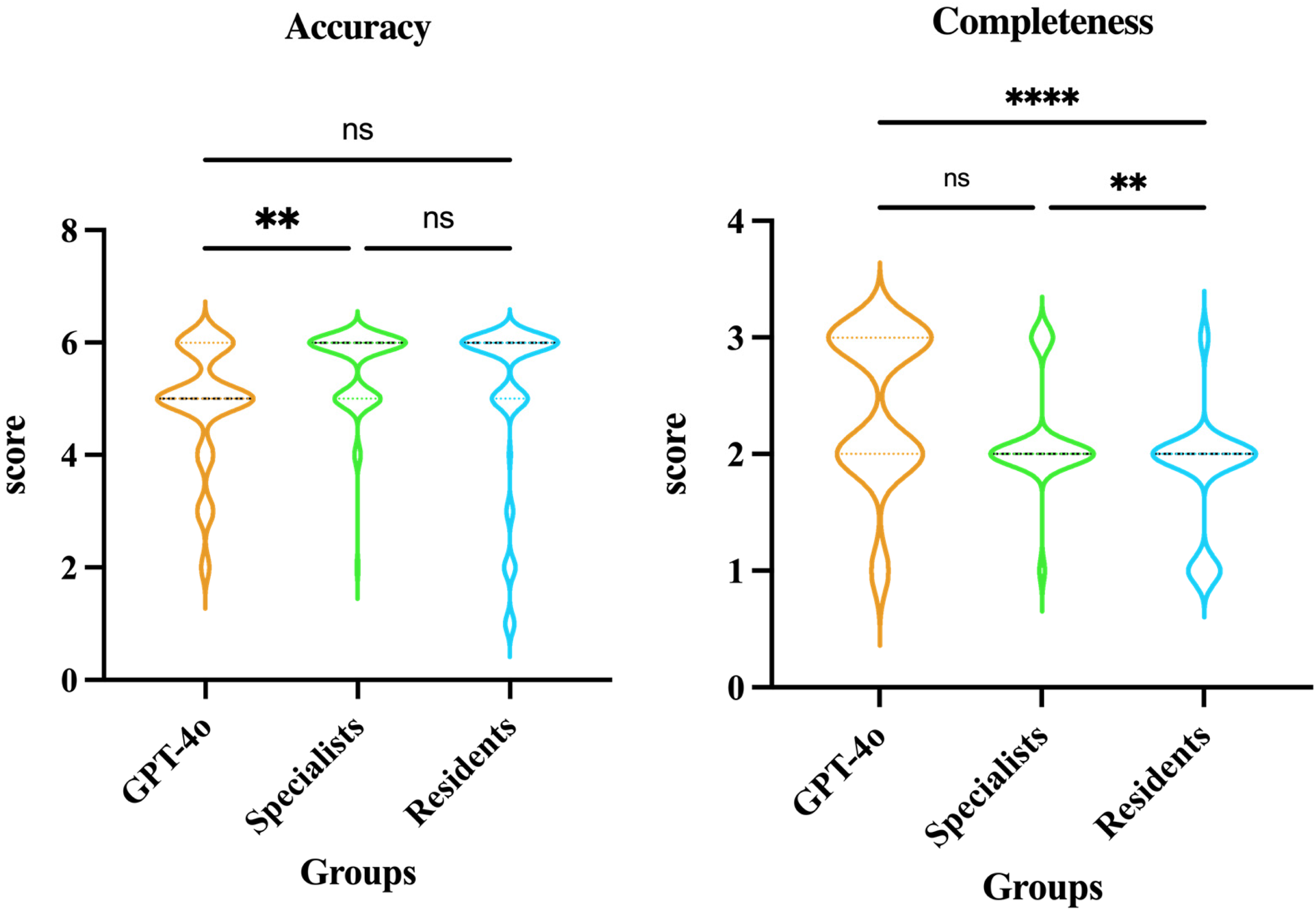
Violin plots (Figure 4) further illustrate these group differences. For accuracy, specialists consistently achieved significantly higher scores compared to both GPT-4o (p = .02) and residents (p < .0001). Although GPT-4o demonstrated higher median accuracy scores than residents, the difference did not reach statistical significance (p = .06).

Comparison of accuracy and completeness in clinical case open-ended questions among GPT-4o, specialists, and residents. ap-value calculated with Kruskal–Wallis test, ****p < .0001; *p < .05; ns: p > .05. Accuracy: GPT-4o vs. Specialists p = .02; GPT-4o vs. Residents p = .06; Specialists vs. Residents p < .0001; completeness: GPT-4o vs. Specialists p = .074; GPT-4o vs. Residents p = .01; Specialists vs. Residents p < .0001.
In terms of completeness, specialists again significantly outperformed residents (p < .0001). GPT-4o achieved significantly higher completeness scores than residents (p = .01) and showed comparable performance to specialists with no statistically significant difference detected (p = .074). Further subgroup analysis demonstrated significant variations in accuracy (χ² = 17.059, p = .004) and completeness (χ² = 17.114, p = .002) scores among responses to clinical questions classified by infectious disease categories (bacterial, fungal, and viral infections) (Supplementary Material 3- Tables S4–5).
Discussion
ChatGPT has garnered significant global attention due to its ability to rapidly respond to queries and provide accurate information on a wide range of topics. It enhances knowledge, offers explanations, provides critical insights, facilitates conversational dialogs, and assists with various tasks. 20
This study evaluated the performance of GPT-4o in comparison to residents and senior clinical microbiology experts in addressing bacterial, fungal, and viral infections, highlighting both the strengths and limitations of this advanced tool. The results indicate that GPT-4o performed well in answering true/false questions, consistent with findings from previous research. 21
In open-ended questions, GPT-4o provided more comprehensive responses, often offering additional background information or explanations beyond what was expected. However, specialists outperformed GPT-4o in terms of accuracy, particularly in cases requiring detailed clinical knowledge. This efficiency stems from ChatGPT's ability to process and generate language based on its training on vast amounts of data. Notably, this does not equate to true understanding, as GPT-4o often provides broader answers. This highlights a potential limitation in clinical decision-making, where precision and adherence to guidelines are paramount. Dyckhoff-Shen et al. emphasized the risks associated with AI-generated content that deviates from established medical guidelines, particularly in complex cases. 15 Our study supports this concern, as the additional information provided by GPT-4o, while comprehensive, may not always align with best practices or could introduce elements that are not clinically relevant, thereby complicating the decision-making process.
In the clinical case-based open-ended questions, specialists consistently outperformed both GPT-4o and residents in terms of accuracy and completeness. GPT-4o demonstrated better performance than residents in completeness, suggesting its potential to assist clinical reasoning for junior clinicians. However, GPT-4o frequently recommended higher-tier or broad-spectrum antibiotics, even when narrower-spectrum options would have sufficed. This highlights the importance of professional supervision in antibiotic selection to ensure appropriate and judicious use of antimicrobial therapy.
Additionally, ChatGPT does not disclose the sources of its information, which presents a risk for users who are unable to verify the reliability of the information provided. Yang et al. compared the responses of ChatGPT and Bard on treatment options for hip and knee osteoarthritis with the recommendations from the American Academy of Orthopaedic Surgeons (AAOS) Evidence-Based Clinical Practice Guidelines. The findings revealed that ChatGPT and Bard encouraged the use of non-recommended therapies in 30% and 60% of their responses, respectively. Notably, none of ChatGPT's responses cited any reference sources. 22
Therefore, it is crucial to ensure that ChatGPT's training data is accurate, comprehensive, and unbiased. This can be achieved by using diverse, high-quality data sources and implementing regular model updates. Moreover, encouraging human experts to verify and confirm AI-generated information will help mitigate inaccuracies and biases.23,24
However, the proficiency demonstrated by GPT-4o in providing comprehensive medical advice highlights its potential as a supportive tool for medical students and junior doctors. Empirical research has shown that this model can instantly provide relevant information on a wide range of medical conditions and treatment options, making it a valuable resource for junior doctors seeking guidance in clinical decision-making. A study by Kung et al. further supports this potential, showing that ChatGPT was able to pass the USMLE®, indicating its capability to provide medical information that could assist in clinical decision-making. 25
On the one hand, it is important to note that ChatGPT was not specifically developed for use in medical research. As a result, it lacks the necessary depth in medical knowledge, particularly in the mechanisms of diseases and treatments. However, its unexpected performance in providing foundational support for research and clinical practice suggests significant potential if developed in collaboration with the medical field. This indicates that, with proper collaboration, AI could bring revolutionary changes to medicine and healthcare. For instance, future efforts should focus on training AI models to have a comprehensive understanding of biological and medical sciences, thereby enhancing their accuracy and depth in analysis, diagnosis, and treatment planning. Moreover, appropriate ethical guidelines, limitations, and authorizations must be established to prevent unauthorized use and protect individual privacy. Additionally, further studies should be conducted in clinical settings using improved models to monitor their progress and effectiveness. On the other hand, misuse and over-reliance on AI systems are also significant concerns that must be addressed. Healthcare professionals may become overly dependent on AI for making medical decisions, potentially overlooking the limitations and possible errors of the technology. 26 ChatGPT often supplements its responses to critical questions by advising consultation with medical experts and emphasizing that the most up-to-date knowledge and guidelines should be used in clinical decision-making. This approach acknowledges the limitations of its recommendations and the potential dangers of relying solely on AI, particularly in complex clinical consultations, which could put patients at risk.
Despite the valuable insights gained from this study, several limitations should be acknowledged, which also provide directions for future research. First, this study evaluated only a single LLM—GPT-4o. Recent research has demonstrated significant variability in clinical performance across different LLMs. 27 As such, our findings may not be generalizable to other models, including domain-specific or open-source LLMs. Future studies should compare multiple models under similar clinical evaluation frameworks. Second, while we applied a standardized role-based prompt to frame each clinical case, we did not implement advanced prompt engineering techniques. Prior studies have shown that prompt design can significantly affect LLM output quality and relevance. 28 Thus, the absence of systematic prompt optimization may have impacted GPT-4o's performance and limits reproducibility. Third, the sample size was limited to three senior experts and three resident physicians, which may not fully represent the broader spectrum of expertise within the medical community. Future studies should include a larger and more diverse sample of participants to ensure generalizability. Fourth, the study focused on bacterial, fungal, and viral infections. While these are common and significant, expanding the scope to include other types of infections or medical conditions would provide a more comprehensive evaluation of GPT-4o's capabilities. Fifth, the accuracy and completeness of responses were assessed using a Likert scale, which, while rigorous, is still subjective to some extent. Future research could incorporate additional objective measures, such as time to correct diagnosis, to further validate the findings. Sixth, GPT-4o's responses were evaluated based on static queries and did not account for dynamic, real-time clinical interactions. Future studies should explore the model's performance in more interactive, real-world settings to better assess its practical utility in clinical practice. Seventh, the current study only included resident physicians and senior experts as human comparators. However, medical students and early-stage learners may benefit even more from LLM support, given their relative lack of clinical experience. Integrating such participants in future studies may help explore the educational value of LLMs in different levels of training. At the same time, the risk of uncritical acceptance of AI-generated responses may be higher among less experienced learners, highlighting the need for careful supervision and contextualization.
We anticipate that the integration of AI into medicine is inevitable, whether providers choose to embrace this revolution or not, particularly as LLMs are advancing at an astonishing pace. GPT-4o should be viewed as a supplementary tool in clinical practice, not as a replacement for the clinical judgment of healthcare professionals. Infectious disease specialists possess the essential expertise, training, and experience, and in clinical practice, the focus must always remain on accuracy and adherence to guidelines—areas where human expertise currently surpasses AI models.
Conclusions
In conclusion, while GPT-4o demonstrates significant potential as a supportive tool in infectious disease diagnostics and management, particularly in providing rapid and more comprehensive contextual information, it cannot yet replace the expertise of trained healthcare professionals. The model's limitations in accuracy underscore the necessity of maintaining human oversight in medical decision-making. Future research should focus on enhancing the precision and reliability of AI models by integrating a deeper understanding of life sciences and clinical guidelines into their training. Additionally, as AI continues to evolve and integrate into healthcare, ethical considerations, including the development of guidelines for AI use and the protection of patient privacy, will be crucial. Ongoing collaboration between AI developers and healthcare professionals is essential to ensure that these technologies are used effectively and safely to enhance, rather than replace, human judgment in healthcare.
Supplemental Material
sj-xlsx-1-dhj-10.1177_20552076251355797 - Supplemental material for Evaluating GPT-4o in infectious disease diagnostics and management: A comparative study with residents and specialists on accuracy, completeness, and clinical support potential
Supplemental material, sj-xlsx-1-dhj-10.1177_20552076251355797 for Evaluating GPT-4o in infectious disease diagnostics and management: A comparative study with residents and specialists on accuracy, completeness, and clinical support potential by Lili Zhan, Xiumin Dang, Zhenghua Xie, Chaoying Zeng, Weixing Wu, Xiaoyu Zhang, Li Zhang and Xinjian Cai in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076251355797 - Supplemental material for Evaluating GPT-4o in infectious disease diagnostics and management: A comparative study with residents and specialists on accuracy, completeness, and clinical support potential
Supplemental material, sj-docx-2-dhj-10.1177_20552076251355797 for Evaluating GPT-4o in infectious disease diagnostics and management: A comparative study with residents and specialists on accuracy, completeness, and clinical support potential by Lili Zhan, Xiumin Dang, Zhenghua Xie, Chaoying Zeng, Weixing Wu, Xiaoyu Zhang, Li Zhang and Xinjian Cai in DIGITAL HEALTH
Supplemental Material
sj-docx-3-dhj-10.1177_20552076251355797 - Supplemental material for Evaluating GPT-4o in infectious disease diagnostics and management: A comparative study with residents and specialists on accuracy, completeness, and clinical support potential
Supplemental material, sj-docx-3-dhj-10.1177_20552076251355797 for Evaluating GPT-4o in infectious disease diagnostics and management: A comparative study with residents and specialists on accuracy, completeness, and clinical support potential by Lili Zhan, Xiumin Dang, Zhenghua Xie, Chaoying Zeng, Weixing Wu, Xiaoyu Zhang, Li Zhang and Xinjian Cai in DIGITAL HEALTH
Footnotes
Acknowledgements
We would like to express our sincere gratitude to all those who contributed to the success of this study.
ORCID iDs
Ethical considerations
This study utilized de-identified clinical case materials that contained no personally identifiable patient information. The research protocol was reviewed by the Chinese Academy of Medical Sciences and Peking Union Medical College Shenzhen Hospital Ethics Committee, which determined that formal ethical approval was not required and granted an exemption. No patient consent was necessary for this study. The use of GPT-4o, an AI-based LLM, complied with OpenAI's terms of use, and all outputs were reviewed solely for research purposes.
Author contributions
LLZ conceptualized and designed the study, developed the methodology, oversaw data collection, contributed to the analysis and interpretation of the data, and drafted significant portions of the manuscript. XJC participated in the study design, conducted data analysis, contributed to result interpretation, and assisted in writing and revising the manuscript. XMD, ZHX, and CYZ assisted with data collection and contributed to the writing and revision of the manuscript. LZ provided expertise in infectious disease management, contributed to the development of the clinical scenarios, and reviewed the manuscript for important intellectual content. WXW and XYZ coordinated the study, facilitated communication within the research team, and contributed to the final editing and approval of the manuscript. All authors have read and approved the final version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Sanming Project of Medicine in Shenzen Municipality, (grant number No.SZSM202311002).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Due to space constraints, data not provided within the article can be shared upon request with any qualified researcher. The raw data supporting the conclusions of this article will be made available by the corresponding author upon reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.