
Abstract
Background
China recently established a series of pilot regional health data centers with a mandate to acquire, consolidate, analyze, and translate data into evidence for health policy decision-making. This experiment with “big data” has the potential to influence population health and is the focus of this study.
Methods
This study used national longitudinal survey data from the China Family Panel Studies over the period 2014–2020 to empirically assess the impact of China's establishment of pilot regional health data centers on population health and health inequality. A difference-in-differences model was employed to investigate the policy effect on population health, with additional exploration of possible mechanisms of influence. The corrected concentration index was used to measure health inequality, while Wagstaff decomposition method was applied to examine the marginal influence of the policy effect on health inequality.
Results
Overall health status of local residents has improved after the establishment of the pilot regional health data centers. Using mechanism analysis, the findings demonstrated that improvements to population health were driven by promoting healthy lifestyles and innovations in medical practices. Furthermore, due to differences in individual e-health literacy, the pilot centers produced “pro-rich” health inequality where high-income groups benefited more from the establishment of the pilot centers in terms of health than low-income groups.
Conclusions
This study has highlighted the potential to improve population health, in general, with the advent of big data centers, but for these benefits be unevenly distributed among the resident population.
Introduction
While good health by most metrics has improved over the past century 1 and is crucial for human development,2,3 health inequality remains a common problem.4–6 Health inequality is often manifest in differences in health outcomes between different socioeconomic groups7,8 with income-related health inequality shown to be greater than solely income or health inequality.9–11 Inequalities in health among socioeconomic groups have been a focus of public health policy in many countries. 12
To advance population health and to address income-related health inequality, China has embarked on a series of ambitious health system reforms.13,14 The success of these reforms was critically dependent on access to and the availability of data, methods, and expertise so that health policy decision-making was evidence-based. With enhanced data collection tools, the advent of an array of valid, reliable, and linkable data sets, and the availability of sophisticated data storage, retrieval, and analysis systems, the opportunities to employ such “big data systems” to inform health policy decision-making in China is at a vital and promising stage of development.
For example, the Chinese State Council issued a circular in 2016 concerning the application and development of “big data” in the health and medical sectors. 15 This initiative aimed to acquire, consolidate, analyze, and translate data into evidence for health policy decision-making. The council acknowledged the importance of “big data” as a strategic national resource and as a tool to foster the development of health systems and to enhance population health. 16
Medical big data represent the specialized application of “big data” in the medical domain,17,18 and it bears significant potential in addressing contemporary medical challenges and in fostering evidence-based health policy decision-making. 16 Medical big data are becoming increasingly pivotal as a resource for crafting more effective personalized treatments and services for patients, 19 enhancing healthcare delivery and patient outcomes, 18 and minimizing resource wastage. 17
The use of “big data” in healthcare plays an increasingly important role in medical diagnosis and management.20–22 Existing research primarily focuses on two areas. The first provides a general overview of how big data can enhance population health management or improve health outcomes for specific diseases, such as enhancing precision health management, 23 improving cardiovascular care, 18 and advancing precision treatment for breast cancer. 24 The second focuses on the technical applications of “big data” in healthcare, such as its use in reducing medical errors, 25 supporting clinical decision-making, 26 achieving real-time health evaluations, and assisting in remote monitoring. 27 While these studies highlight the positive role of big data in improving population health and the quality of medical services, the direct impact of big data on health outcomes has rarely been empirically explored. There is also limited understanding of how big data may influence the health of individuals and populations. Specifically, research on China's regional health data center pilots is primarily limited to descriptive theoretical analyses regarding policy implications and future trends. 16 No relevant empirical studies on health outcomes have been conducted. China's regional health data center pilots serve as a testing ground for the application of big data in healthcare in China's healthcare system. Understanding the impact of these center pilots on people's health and health inequalities is crucial for the further development of big data in healthcare. Consequently, the purpose of this study is threefold: First, to evaluate the health consequences of China's establishment of a series of regional health data centers; Second, to assess their potential mechanisms of influence; and third, to estimate the impact of the pilot programs on socioeconomic-related health inequality.
This study makes three key contributions. First, this is the first study to empirically examine the impact of pilot regional health data centers on population health. Previous studies were mostly descriptive and aimed at the analysis of the practical application of “big data” in healthcare. Our study provides evidence for the health effects of pilot regional health data centers from an empirical perspective. Second, this study examines the mechanisms by which pilot programs affect population health. We suggest that healthcare big data can support healthy lifestyles and foster medical innovations, thereby promoting population health. Finally, this study focuses on e-health literacy and examines the unequal distribution of health benefits resulting from the pilot programs, which particularly favor the wealthy. This reminds policymakers to be wary of the uneven benefits of digital welfare across populations caused by the characteristics of pilot programs.
This paper is organized as follows: the second section introduces the policy background and puts forward a theoretical framework. The third section reports on the data, model, and econometric procedures employed. The empirical results are presented in the fourth section, followed by a discussion in the fifth section. The final section concludes the manuscript.
Theoretical framework
Policy background
Since October 21, 2016, a national pilot program has been initiated in stages for constructing regional health data centers across China. The program aims to diminish data barriers and enhance the application of “big data” in healthcare. A total of six regional health data centers have been established. The first batch of pilot centers was announced on October 21, 2016, and comprised two regional data center pilots in Fujian and Jiangsu Provinces. The second batch of pilot centers was announced on December 12, 2017, and comprised data centers in Shandong, Anhui, and Guizhou Provinces. The third announcement was made in July 2018 and resulted in the establishment of the Ningxia Hui Autonomous Region Regional Data Center. These centers were designed to integrate existing regional “big data” in healthcare, including health data, administrative data, and electronic medical records, to effectively address persistent medical challenges, support academic research, and provide evidence for decision-making. 16
Theoretical hypotheses
The Chinese government's pilot policy on regional health data centers is approached from two key perspectives: the demand side, representing individual citizens with health needs, and the supply side, involving the supply and innovation level of medical services. The primary goal is to diminish data barriers for all individuals and enhance the application of “big data” in healthcare. From a supply perspective, pilot centers facilitate the sharing of “big data” resources in healthcare, which creates an accessible data foundation for medical innovation. Moreover, the government stresses the application of “big data” in healthcare, including support for the development of various internet medical enterprises and the promotion of clinical and scientific research, thereby driving innovation in medical practice. Medical innovations aid healthcare decision-making,28,29 improve the safety and accuracy of healthcare, 30 and help to enhance the way in which healthcare is organized and delivered. 31 From the perspective of client demand, the establishment of the pilot centers helps to promote the importance of health and helps to form a variety of health applications, wearable devices, and “new technology” for people to use.31,32 The applications can help users and patients to improve people's awareness of health, improve health planning, and encourage healthy lifestyles. The users or patients can become advocates for their own health.
Therefore, China's regional health data centers have the potential to drive innovation in medical practice and promote healthy lifestyles, thereby improving population health. Three research hypotheses have been proposed. Hypothesis 1: The pilot regional health data centers can enhance population health. Hypothesis 2: The pilot regional health data centers can enhance population health by promoting healthy lifestyles. Hypothesis 3: The pilot regional health data centers can enhance population health by enhancing innovation in medical practices.
E-health literacy refers to the population's subjective acceptability of accessing health information online and their ability to evaluate health information and solve health problems on electronic resources.33,34 The pilot regional health data centers emphasize the use of “new technologies.” The acceptance and use of “new technologies” are based on people's strong digital skills. People with good digital skills and high subjective acceptance can benefit more from new medical methods.
34
However, due to differences in e-health literacy among populations, people's acceptance of “new technologies” varies. For instance, higher socioeconomic groups typically exhibit greater e-health literacy,
35
are more willing to try new types of technology platform,
36
and are more prone to explore the internet for health information,
33
showing higher subjective acceptance of new technologies. Therefore, due to differences in e-health literacy, groups with higher socioeconomic status may benefit more from the pilot regional health data centers, which in turn affects health status and leads to health inequality. Hypothesis 4: The pilot regional health data centers have varying health impacts across socioeconomic groups, leading to “pro-rich” health inequality.
Figure 1 shows the research framework.

Research framework.
Methods
Data
In this empirical study, microdata were drawn from the Chinese Family Panel Studies (CFPS). The CFPS is a national longitudinal survey initiated by the Institute of Social Science Survey of Peking University in 2010 and conducted biennially. It documents changes in Chinese society, economy, demographics, education, and health to support academic research and inform public policy analysis. 37 As of 2020, six survey waves had been conducted comprising 2010, 2012, 2014, 2016, 2018, and 2020. 38 The survey spans 25 provinces, municipalities, and autonomous regions in China, representing approximately 95% of the total population. 39 The CFPS adopts proportional probability sampling with implicit stratification, multistage, multilevel, and population proportionality to enhance the validity and representativeness of its sample. 40 It is also supported by the Survey Research Center at the University of Michigan and other authoritative institutions responsible for survey design and methodology. 41 The target sample size is 16,000 households, with all household members in the selected households included as survey respondents. Prior to the launch of the CFPS national baseline survey in 2010, two pilot surveys were conducted in Beijing, Shanghai, and Guangdong in 2008 and 2009, respectively, to review the reliability and validity of the survey. 38 In 2008, while the target sample size was 2400 households, the resulting data were collected from 2375 households across 24 counties and districts. In 2009, a follow-up survey was conducted with the households sampled in 2008, with data collected from 1995 households. 42 The pilot survey sample constitutes 15% of the expected sample size of the formal survey, indicating good validity of the questionnaire. In 2010 (baseline survey), the response rates to the CFPS at the household and individual levels were 81.28% and 84.14%, respectively. 43
The CFPS is a representative and authoritative source of microdata for academic research and public policy analysis 37 and has been used widely in academic research.41,44,45 The CFPS is selected as the main database for microindividual analysis because of its high representativeness and authority, which provides a reliable data foundation for this study. The CFPS also encompasses multidimensional data across almost all age groups, including health, education, migration, and socioeconomic status,46,47 thereby supporting the comprehensive analysis of various issues from multiple perspectives. It should, however, be noted that although the initial sample of the CFPS is broad in coverage, it is less representative in some remote and ethnic minority areas. 41 In addition, due to the long period of CFPS data collection, some indicators, such as exercise-related variables, may be investigated only in some survey waves. In our study, we only used four waves (2014, 2016, 2018, and 2020) of the CFPS due to the absence of key variables, such as “exercise frequency,” in the 2010 and 2012 surveys.
We restricted the analysis to adult respondents aged 16 and above, as defined by CFPS. Missing values in the dependent and demographic variables were excluded. Finally, we obtained an unbalanced panel comprising 42,547 observations from 14,282 respondents.
Apart from that, patent-related data were sourced from the China National Intellectual Property Administration, as referenced in Howell's study. 48 Information on the number of medical enterprises and entrepreneurship came from QICHACHA, which provides detailed information such as address and establishment date of the enterprise. 49 Socioeconomic characteristics at the city level were obtained from China's Urban Statistical Yearbooks.
Measures
Dependent variable
This study used the “self-assessed health (SAH)” variable in the CFPS questionnaire as an indicator of individual health status. Despite the potential for subjective measurement errors, SAH can serve as a relatively accurate measure of health and is widely used in previous literature.50,51 Self-assessed health reflects respondents’ perception of their own health status, and offers a comprehensive measure of health status. It was selected from the question, “How do you assess your health?.” Among the answers, 1 represents “excellent,” 2 represents “very good,” 3 represents “good,” 4 represents “fair,” and 5 represents “poor.” To enhance the interpretability of health status, we inverted the health variable, assigning values 1 through 5 to denote “poor” to “excellent.”
Additionally, the “health change” variable was used as an alternative dependent variable for robustness checks. Respondents were asked about the change in health status compared to one year ago. Answer 1 indicates that the health status had not changed or had improved, while answer 0 indicates that the health status had deteriorated.
Two main measures have been used in the literature to capture health inequality: single health inequality and socioeconomic-related health inequality. This study focused primarily on socioeconomic-related health inequality. The unequal distribution of wealth and power is a fundamental cause of health inequalities.52,53 Attaining a higher social status not only ensures a more conducive and relaxed work environment but also alleviates economic constraints faced by patients during medical treatment, facilitating access to high-quality medical resources.
This study used the corrected concentration index (CCI) 54 to measure socioeconomic-related health inequalities, as the SAH is a bounded variable. We further employed the Wagstaff-type decomposition method to assess the contribution of pilot programs to health inequality. 55
Independent variables
The core independent variable was “pilot policy,” which represented the establishment of the pilot regional health data centers and was labeled as “DID.” The process of implementation started on October 21, 2016, and continued until 2018. Given the lag in initiation of the data centers after implementation, this study designated 2017, 2018, and 2019 as date of intervention for the three sets of pilot data centers. Consequently, Fujian and Jiangsu provinces were designated as having operational data centers from 2017, Shandong, Anhui, and Guizhou provinces from 2018, and Ningxia Hui Autonomous Region from 2019. All other regions were assigned as control groups.
Mechanism variables
The first mechanism through which the pilot programs may improve health is by promoting healthy lifestyles. Healthy lifestyles can be reflected in both prolonged exercise duration and increased exercise frequency.56,57 This was assessed through two variables: “exercise hours” and “exercise frequency,” extracted from CFPS questionnaire queries: “How often did you exercise last week?” and “How many hours did you spend exercising last week?,” respectively. The “exercise hours” indicates the time individuals allocate to physical activity, while “exercise frequency” denotes the regularity of physical activity. The classification for exercise frequency was as follows: (1) for less than once a week, (2) for once or twice a week, (3) for three to four times a week, (4) for five to seven times a week, and (5) for more than seven times per week. The term “exercise” encompassed various activities, including daily walking, running, jogging, mountain climbing, martial arts, indoor and outdoor physical exercise, ball games, and water sports. This comprehensive definition captured an individual's daily physical activity. Longer exercise time and more frequent exercise indicate a healthier lifestyle. 56
The second mechanism through which the pilot programs may improve health is by enhancing innovations in medical practice. Drawing on the study of Fritsch and Wyrwich, 58 this study selected indicators to measure innovation in medical practice based on innovation output. Three indicators were employed: the number of medical patent applications applied for by hospitals (i.e., Medical patent applications variable), the number of medical patent inventors in hospitals (i.e., Medical patent inventors variable), and the number of medical enterprise entrepreneurship (i.e., Medical enterprises entrepreneurship variable).
Control variables
Following the Grossman model of the demand for medical care 59 and insights from prior research, this study categorized control variables into individual demographic characteristics and medical treatment status characteristics. The demographic characteristics included gender, age, age squared, retirement status, marital status, household registration status (i.e., hukou status), education, number of cigarettes smoked per day (i.e., smoking), and total income in the past year. Medical treatment status characteristics included whether the respondent had been hospitalized in the past year (i.e., hospitalized) and their out-of-pocket medical expenses in the past year. The total income and out-of-pocket medical expenses were log-transformed in 2020 RMB (1.00 USD = 6.9 RMB). All variables are defined in Table 1.
Definition of variables.

Empirical strategy
Step 1: The impacts of the pilot regional health data centers on health and its mechanisms of influence.
We employed a time-varying difference-in-differences (DID) model, as referenced by Zhou et al.,
60
to investigate the impacts of China's pilot regional health data centers on population health. The DID model is a widely used econometric method for evaluating the impact of nonrandomized interventions. This model assumes that, in the absence of treatment, the change in outcomes between the pre- and postintervention periods for the treatment group is similar to that of the control group. The implementation of the DID model involves two steps. First, in a natural experiment, a treatment group and a control group are selected: the treatment group consists of individuals affected by the intervention or policy, while the control group includes those unaffected. Second, the DID estimator (represented by the pilot policy variable in this study) is calculated.
61
This estimator captures the pure treatment effect by comparing how outcomes change before and after an intervention between individuals who have been exposed to the intervention (treated) and those who have not (untreated).
62
The DID model effectively controls for confounding factors, such as permanent differences between treatment and control groups, and time trends in outcomes unrelated to the intervention,
63
which enables us to estimate a relatively pure policy effect. Finally, the following regression model is estimated: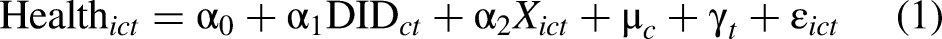
It is noteworthy that the Chinese government's selection process for the pilot regional health data centers may be subject to potential selection bias. The decision-making process may be guided by the evaluation of local capabilities and resources for the storage, management, and utilization of high-quality, high-capacity medical data. Therefore, the government may prioritize provinces with high levels of healthcare, abundant medical resources, and advanced developmental statuses, while excluding areas with limited medical resources. Given the potential selection bias in this empirical setting, a DID-based propensity score matching (PSM-DID) model was employed to manage potential selection bias. 64 Propensity score matching is a widely used technique that minimizes selection bias. 61 The purpose of the matching procedure is to identify a group of nonpilot provinces that exhibit characteristics similar to those of the pilot provinces, thereby minimizing the potential for bias. 65 We also incorporated county-fixed effects into our regression models to minimize the impact of regional characteristics on the selection of pilot programs. The county fixed effects controlled for any unobserved variations in the region, including the quality of care, the adequacy of medical resources, and access to healthcare.
Step 2: The mechanisms through which pilot programs influence health.
Besides examining the direct effect specified in equation (1), this study also delves into potential mechanisms of influence. Given the substantial endogenous bias inherent in traditional mediation effect tests, this study draws upon the study by Dell
66
to validate the causality channel in the mechanism test. In practice, we replaced the dependent variable in the regression with a healthy lifestyle (as captures by exercise) and medical innovation output: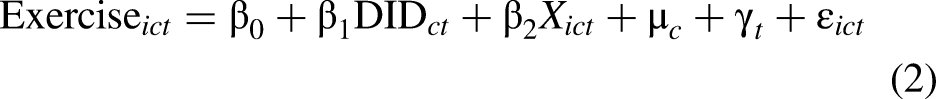

The second mechanism of influence is through enhancing innovation in medical practices. Equation (3) is employed to examine the impact of pilot programs on local medical innovation, where
Step 3: Estimate the impact of pilot regional health data centers on health inequality.
This study utilized the CCI
54
to measure socioeconomic-related health inequalities and employed the Wagstaff-type decomposition method to assess the contribution of pilot programs to health inequality.
67
(1) Corrected CI
The CI, as introduced by Wagstaff et al.,
68
quantifies the degree to which inequalities in health-related variables are consistently associated with socioeconomic status. The formula used for the CI is:
Given that the health variable (i.e., SAH) in our study was bounded, the CCI was utilized to measure the health inequality. It is commonly used to measure socioeconomic inequality in bounded SAH.
69
The CCI is calculated as follows: (2) Wagstaff decomposition
In order to assess the impact of pilot programs on health inequality, a Wagstaff-type decomposition method
55
was employed as referenced by Gu et al.
69
The decomposition starts from the following equitation:
Substituting equation (4) and equation (5) into equation (6), we get:
Results
Sample description
Table 2 provides an overview of the sample characteristics. Respondents, on average, reported a health status of 2.7, indicating generally good health. Approximately 62% of respondents perceived no change or improvement in their health compared to the previous year. 3.7% of observations were covered by the policy pilot. Nearly half (47.6%) of the respondents were male, and approximately 31% of the respondents held urban hukou. On average, respondents engaged in physical activity once or twice a week, accumulating seven hours of exercise per week. After logarithmic transformation, the mean total income was 4.440, with a median of 0. This is primarily because the sample includes individuals aged 16 and above, encompassing both teenagers attending school and retired elderly individuals, most of whom have an income of 0.
Sample characteristics.

Figure 2 plots the average health status for the treatment and control groups across each survey year. As shown in Figure 2, the health status for both groups exhibited a downward trend from 2014 to 2016, with the control group consistently reporting better overall health than the treatment group. By 2016, the health status of the two groups was largely comparable. Following the announcement of the first batch of pilot regional health data centers in 2016, the health status improved significantly for both groups, with the treatment group benefiting more. By 2018, the treatment group reported better health than the control group. Consequently, Figure 2 suggests that the notable improvement in health among the treatment group may be linked to the pilot programs.

Time trend of health status in the treatment and control group.
The health impact of the pilot programs
Results of the DID method
The baseline regression results are presented in Table 3. The first column showed the results from the univariate regression, followed by inclusion of all control variables in the second column. The third column provided the comprehensive results incorporating all control variables, county-fixed effects, and year-fixed effects. Regression results across the three columns showed minimal change, with the coefficient of the DID variable remaining significantly positive at the 1% statistical level. The results in the third column indicate that the implementation of the pilot programs has led to a slight improvement in the overall health status of the population in the pilot area by 0.166 units. Hypothesis 1 is confirmed.
Effect of pilot program on health status.

Notes: *p < 0.1, **p < 0.05, ***p < 0.01. T-values were reported in parentheses, which were estimated using the robust standard errors of cluster heteroscedasticity at the county level. The first three columns displayed the results of the main regression, and the fourth column provided the result of the robustness test. Columns 3 and 4 controlled for county-fixed effects, year-fixed effects and control variables related to the individual demographic characteristics and medical treatment status characteristics.
The baseline regression passed the parallel trends test (see Supplementary Table A1), which verified noteworthy treatment effects on individuals’ health conditions during and after policy implementation. Additionally, we replaced the dependent variable “health” with the “health changes” variable for additional robustness testing, as shown in column (4) of Table 3. The results remain unchanged, thus confirming hypothesis 1 once again.
For other control variables, higher total income, good education, and being married were associated with better health, while increased out-of-pocket medical expenses, hospitalization, and older age were linked to reduced health.
Robustness test and endogenous processing
There may be several endogeneity issues to be considered in this study. One pertains to the nonrandom selection of policy pilots. As we discussed in the third section, the inherent medical advantages of pilot provinces may not only elevate the chances of being chosen for the pilot but also impact the health status of local residents. To tackle this issue, this study employed the PSM-DID method, and the results closely corresponded with the baseline regression findings (see Supplementary Table A2 and Table A3). Another consideration involves the potential bias caused by omitted variables, where certain unobservable contemporaneous policies or other influencing factors could interfere with policy outcomes. A placebo test was conducted to exclude the interference of the above factors, demonstrating the inherent effectiveness of the policy (see Supplementary Figure A1). Consequently, our results remained consistent and robust after addressing endogenous issues, such as the potential selection bias, omitted variable bias. Hypothesis 1 is again confirmed.
Mechanisms analysis
Table 4 displays the outcomes related to healthy lifestyles as an influencing mechanism. Both the coefficients in the first and second columns were significantly positive, suggesting that the implementation of the pilot programs had notably increased both the hours and frequency of exercise per week. This increase is attributed to the promotion of various healthcare apps in the pilot programs and the emphasis on developing industries such as health management, health consultation, and health culture. These efforts have fostered a positive atmosphere for health management and fitness in society, motivating people to invest more time in exercise and promoting healthy lifestyles. Healthy lifestyles further contribute to the improvement of individuals’ health status. Hypothesis 2 is confirmed.
The potential mechanism of the effect of pilot programs on health—promoting healthy lifestyles.
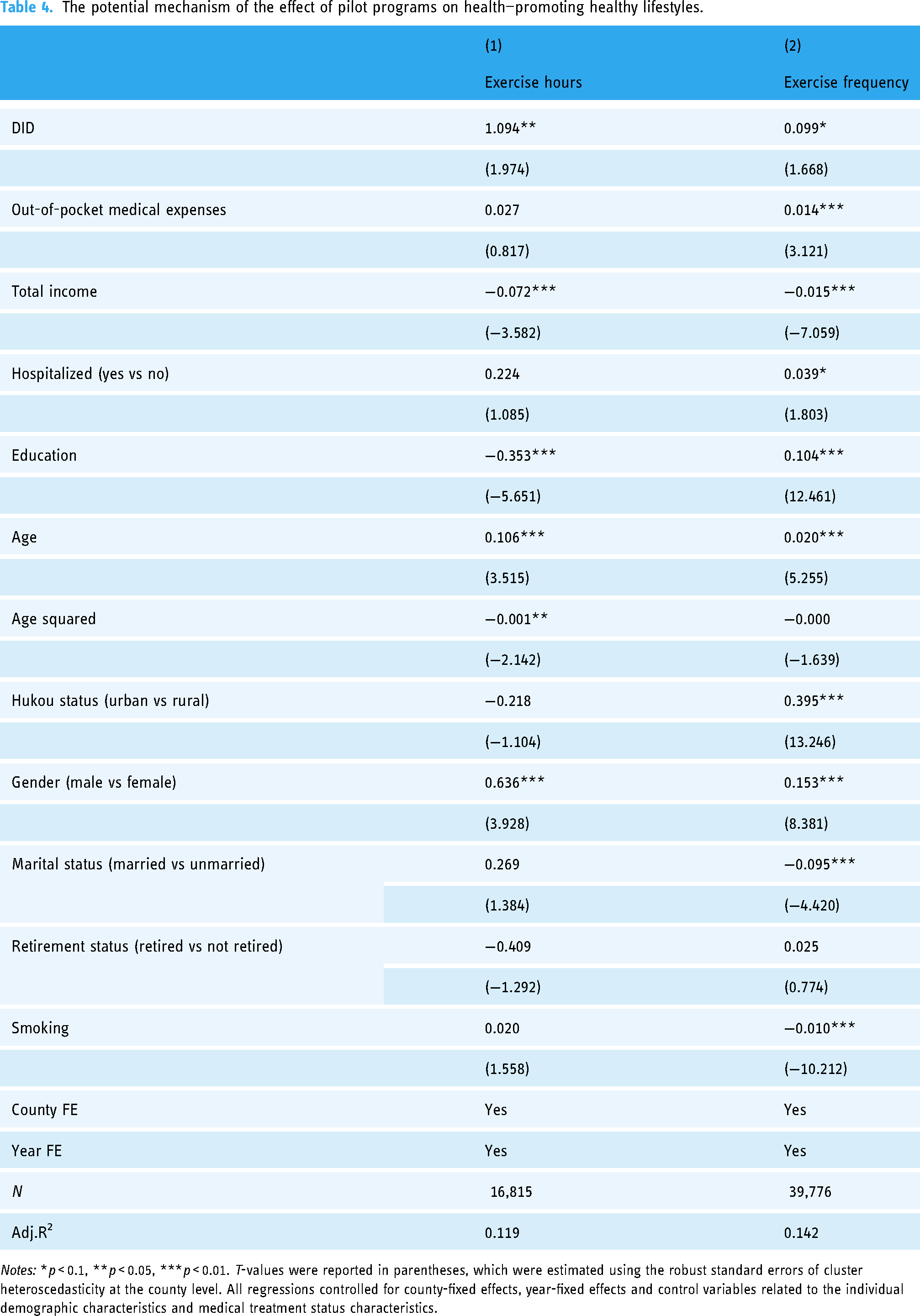
Notes: *p < 0.1, **p < 0.05, ***p < 0.01. T-values were reported in parentheses, which were estimated using the robust standard errors of cluster heteroscedasticity at the county level. All regressions controlled for county-fixed effects, year-fixed effects and control variables related to the individual demographic characteristics and medical treatment status characteristics.
Table 5 shows the results related to the mechanism of enhancing innovations in medical practice. The notably positive coefficient in the first column suggests that the pilot programs had markedly enhanced the entrepreneurial activities of medical enterprises in society. Furthermore, the coefficients in the second and third columns, both significantly positive, signified a substantial increase in the number of patent applications and patent inventors in hospitals. This suggests that the pilot programs have led to the continuous emergence of professional new treatment instruments, new drugs, and new therapies. Consequently, doctors’ intraoperative and postoperative medical diagnoses, as well as health monitoring, have become more precise and efficient, thereby enhancing medical capabilities and benefiting patients. Hypothesis 3 is confirmed.
The potential mechanism of the effect of pilot programs on health—cultivating medical innovation output.

Notes: *p < 0.1, **p < 0.05, ***p < 0.01. T-values were reported in parentheses, which were estimated using the robust standard errors of cluster heteroscedasticity at the county level. All regressions controlled for county-fixed effects, year-fixed effects. The selection of control variables was based on existing literature, including Regional GDP, added value of the tertiary industry, local fiscal healthcare expenditure, number of domestic patent applications accepted, urban proportion, number of certified physician assistant in urban areas, number of certified physician assistant in rural areas, number of general hospitals, number of traditional Chinese medicine hospitals, number of specialized hospitals. The first three variables were expressed in logarithmic form.
The impact of the pilot programs on socioeconomic-related health inequality
The CCI and Wagstaff-type decomposition method were used to investigate the impact of the pilot programs on socioeconomic-related health inequality. Table 6 revealed an overall CCI of 0.158, with a p < 0.001. A positive overall CCI suggested a prevalent “pro-rich” health inequality. The contribution rate of the pilot programs to the overall CCI was 1.7%, suggesting a notable positive contribution to the socioeconomic-related health inequality. Therefore, pilot regional health data centers directly enhanced the health of all residents, but potential variations in policy coverage resulted in a skew of medical resources toward high-income groups. Hypothesis 4 is confirmed.
Decomposition of health inequality.
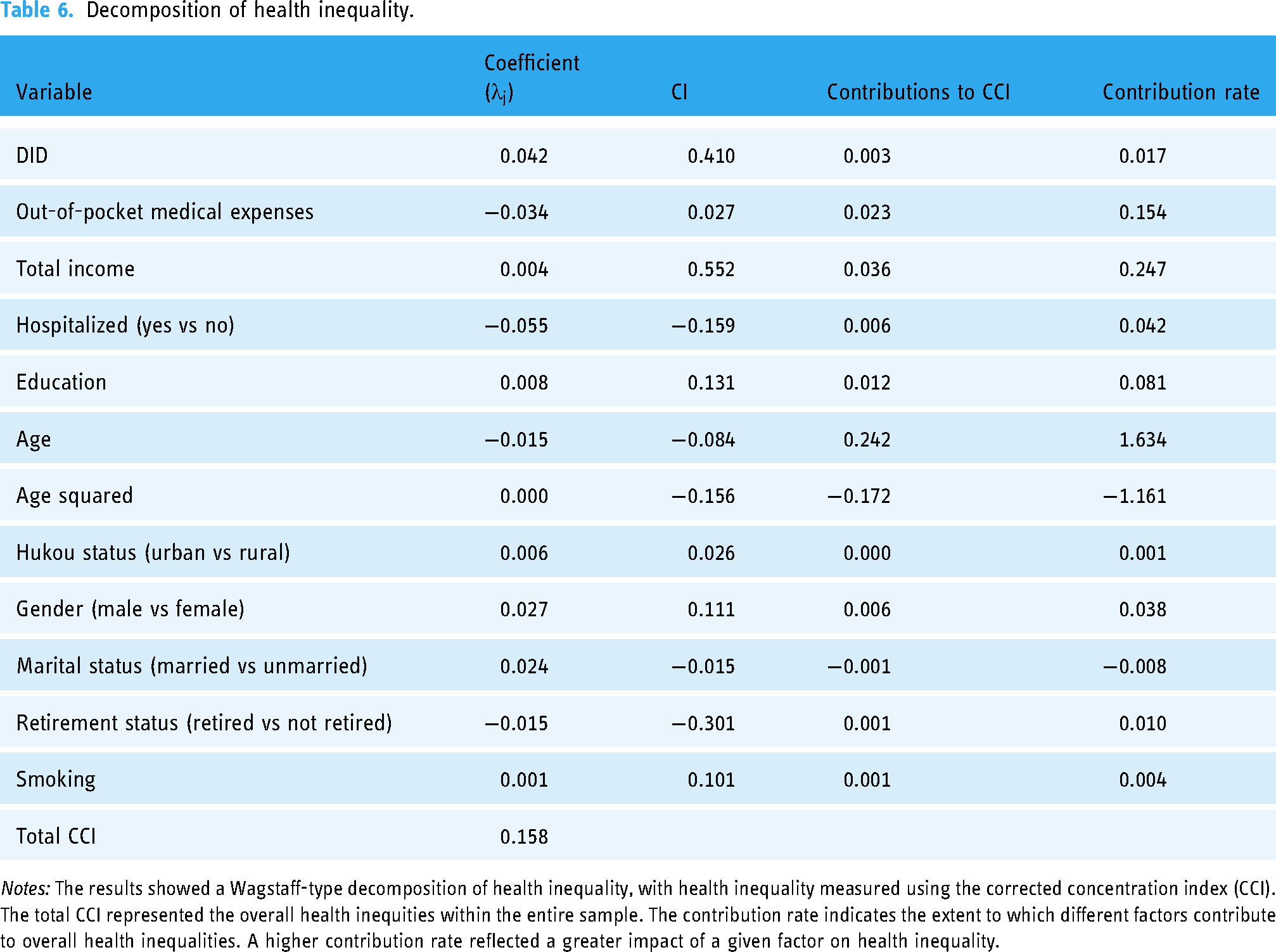
Notes: The results showed a Wagstaff-type decomposition of health inequality, with health inequality measured using the corrected concentration index (CCI). The total CCI represented the overall health inequities within the entire sample. The contribution rate indicates the extent to which different factors contribute to overall health inequalities. A higher contribution rate reflected a greater impact of a given factor on health inequality.
We further validated the robustness of this result by stratifying the entire sample into “high-income” and “low-income” groups based on the mean of the income variable (see Supplementary Table A4). The regression coefficient was greater for the “high-income” group, indicating a greater impact of regional data centers on health among this demographic. This reaffirms that the pilot regional health data centers have widened the health gap between high- and low-income groups, exacerbating health inequality among these groups.
Discussion
This is the first study to explore the impact of pilot regional health data centers on population health and health inequality in China. We found that pilot programs promoted the overall health status of the residents in the pilot areas. China's “big data” in the health and medical sectors is part of the national big data strategic layout. The use of “big data” in healthcare spans various areas and presents cost-effective opportunities for global healthcare improvements. 70 For example, during the COVID-19 pandemic, “big data” in healthcare significantly aided Singapore, Taiwan, South Korea, and Hong Kong in enhancing traditional public health measures and curbing the spread of SARS-CoV-2. 71 Additionally, “big data” can be applied to public health promotion, healthcare management, drug and medical device monitoring, and routine clinical practice. 16 All these practices provide opportunities for improving people's health. Our findings are consistent with previous studies.72,73 Dash et al. 72 highlighted the importance of “big data” in healthcare to improve people's health. Pastorino et al. 73 reported that “big data” in healthcare can benefit patients from several aspects such as increasing earlier diagnosis and the effectiveness and quality of treatments by the discovery of early signals and disease intervention, reduced probability of adverse reactions.
Establishing medical big data centers to support equitable discovery and innovation in digital healthcare is a significant global concern. 74 Health Data Research UK, for instance, is committed to “uniting the UK's health data to enable discoveries that improve people's lives.” 74 Similarly, the Estonian eHealth project focuses on improving the quality and efficiency of health services and aims to digitize all patient information and prescriptions. 75 Additionally, the European Health Data Space promotes the sharing of health data between EU countries to support research and public health surveillance. Our study has revealed that the regional health data centers in China are associated with improvements in population health. It also offers valuable insights for the development of “big data” in healthcare in other countries.
We also found that the improvements to population health were driven by pilot programs promoting healthy lifestyles. “Big data” in healthcare advocates for mobile health and wellness services to implement novel and innovative ways to deliver care and coordinate health as well as wellness. Companies such as Apple and Google have developed specialized platforms, such as Apple's Research Kit and Google Fit, for developing research applications for fitness and health statistics. 72 These applications can improve healthcare by accelerating interactive communication between patients and healthcare providers. 72 The applications can also help users and patients improve health awareness, health planning and encourage healthy lifestyles. The users or patients can become advocates for their own health. Our findings are similar to a study in Europe, which identified 10 big data priority projects to be implemented in Europe to support the sustainability of the health system by supporting healthy lifestyles. 76
We also found that regional data center pilots can help drive innovations in medical practices, and thus improve population health. “Big data” in healthcare can promote new medical technology that can improve the cure rate of the disease. 77 Previous studies have demonstrated that the application of “big data” in healthcare based on digital technology can be used to reduce medical errors, 25 support clinical decision-making, 26 and achieve real-time health evaluations and monitor remote patients. 27 Innovative technology based on big data supports precision medicine. 73
We also found “pro-rich” health inequalities brought about by the pilot programs. One explanation for this finding was that high-income groups may benefit more extensively from the establishment of the pilot programs due to their higher e-health literacy. Health inequalities arising from medical big data constitute a significant global concern. Cruz's analysis of the American case demonstrates that to fully address health inequalities, both technical and social factors must be considered with medical big data. 78 A previous study found that individuals with good digital skills and high subjective acceptance can benefit more from new medical methods. 34 Effectively addressing health inequalities requires recognizing and confronting the disparities between groups influenced by factors such as socioeconomic status. Among these, the difference in digital literacy among different groups is an important factor that prevents different groups from enjoying digital welfare equitably.79–81 Digital literacy must be integrated into digital health policies; otherwise, digital health policies will exacerbate health inequalities. 82
To ensure that China's pilot regional health data centers yield more equitable health outcomes, the Chinese government should first implement a national e-health literacy promotion program designed to enhance the population's ability to use health information services, particularly among low-income and less educated groups. For example, targeted education and training programs can be developed to help these groups overcome barriers they may encounter when using health information services, such as unfamiliarity with technology, language barriers, or difficulty understanding health information. To improve the accessibility and ease of use of the platforms, digital health platforms with intuitive interfaces should be developed to lower the barriers to use for all users, especially those who are not familiar with technology. Additionally, improvements should be made to advance equity in digital access to medical services. The government should accelerate the digital transformation of medical infrastructure, facilitate seamless access to the national health information platform for primary healthcare units, and enhance the overall digital capacity of health services.
This study has some limitations. First, we only used four waves of CFPS data, so the study panel duration is shorter. Future research could use more years of panel data to explore the long-term impact of the pilot regional health data centers on people's health. Second, in addition to the two mechanisms we proposed, other possible impact mechanisms of the pilot regional health data centers on people's health level can be further explored. For example, improving the efficiency of medical matching based on data and promoting the sharing of medical resources may also significantly improve people's health. Third, the utilization of health big data faces several challenges, including heightened complexity, challenges in acquisition, large volume and variety, and privacy concerns. 19 It can pose a significant challenge to existing stakeholders within the health system, potentially disrupting established authority and power structures. Moreover, when confronted with an abundance of medical data, health big data harbor the potential to generate new discoveries and information. However, it can also deviate from established practices and understanding, resulting in heightened uncertainty until the information gains credibility. While further exploration of these aspects bears notable importance, it unfortunately lies beyond the purview of this paper's study model. All of these aspects are worth studying in the future.
Conclusion
This is the first study to explore the impact of China's pilot regional health data centers on population health and health inequality. This study reveals that while the establishment of healthcare big data centers was associated with an improvement in population health, it was also associated with an exacerbation in socioeconomic-related health inequality. China's regional health data centers can support healthy lifestyles and promote medical innovation, thereby improving health.
This study has important policy implications for the development of pilot regional health data centers. The “big data” in healthcare helps to monitor the trends of major diseases and provide evidence for policy-making in healthcare. By leveraging opportunities for “big data” development in healthcare, the Chinese government can strengthen the popularization of health care knowledge and investment in medical innovation, make full use of information technology to strengthen health care work and improve medical quality. While maintaining the strategic positioning of “big data” in health and medical care, residents’ e-health literacy will be included in the scope of policy attention, and attention will be paid to the health inequality brought about by the policy. The government should implement community-based digital health literacy programs targeting vulnerable populations, such as the elderly, low-income groups, and rural residents, to enhance digital health skills. Efforts should also prioritize the development of user-friendly digital health platforms featuring intuitive interfaces and multilingual support to cater to diverse populations. Furthermore, it is essential to offer subsidies and incentives for digital health tools, which will facilitate the acquisition of necessary devices and lower the barriers to usage, thereby promoting digital health equity.
Future studies could further explore the dynamic nature of health inequalities arising from medical big data, identifying and assessing the extent and changing trends of health inequality across different populations and regions. Additionally, ethical issues associated with the use of medical big data—including personal privacy protection, data security, informed consent, and the impact on existing health system stakeholders—warrant further investigation.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251314102 - Supplemental material for The impacts on population health by China's regional health data centers and the potential mechanism of influence
Supplemental material, sj-docx-1-dhj-10.1177_20552076251314102 for The impacts on population health by China's regional health data centers and the potential mechanism of influence by Jiaoli Cai, Yue Li and Peter C Coyte in DIGITAL HEALTH
Footnotes
Contributorship
J.C. contributed to the design of the study. Y.L. contributed to statistical analysis. J.C. and Y.L. wrote the first draft. P.C.C. critically revised the paper for important intellectual content. All authors approved the final version.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported by National Natural Science Foundation of China (grant number 72374021).
Guarantor
JLC.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.