
Abstract
Background and Objective
Current tongue segmentation methods often struggle with extracting global features and performing selective filtering, particularly in complex environments where background objects resemble the tongue. These challenges significantly reduce segmentation efficiency. To address these issues, this article proposes a novel model for tongue segmentation in complex environments, combining Mamba and U-Net. By leveraging Mamba’s global feature selection capabilities, this model assists U-Net in accurately excluding tongue-like objects from the background, thereby enhancing segmentation accuracy and efficiency.
Methods
To improved the segmentation accuracy of the U-Net backbone model, we incorporated the Mamba attention module along with a multi-stage feature fusion module. The Mamba attention module serially connects spatial and channel attention mechanisms at the U-Net ’s skip connections, selectively filtering the feature maps passed into the deep network. Additionally, the multi-stage feature fusion module integrates feature maps from different stages, further improving segmentation performance.
Results
Compared with state-of-the-art semantic segmentation and tongue segmentation models, our model improved the mean intersection over union by 1.17%. Ablation experiments further demonstrated that each module proposed in this study contributes to enhancing the model’s segmentation efficiency.
Conclusion
This study constructs a
Introduction
As an integral part of traditional medicine, traditional Chinese medicine (TCM) is gaining increasing global recognition.1,2 In China, TCM has demonstrated remarkable efficacy in treating chronic ailments such as diabetes, 3 gastritis, 4 insomnia, 5 etc., which can not be separated from its unique diagnostic approach and reliable clinical practice. One of the key diagnostic methods in TCM is observation, which alongside smelling and listening, inquiring, pulse feeling, and palpation, forms the basis of diagnosis. Among these, observation has garnered significant attention in the field of medical image processing, especially in intelligent tongue diagnosis, due to its intuitive nature6–8; therefore, tongue diagnosis is extensively researched because it reflects a wealth of information about the human body and is relatively easy to collect data. 9
In the context of intelligent tongue diagnosis, accurate tongue segmentation plays a critical role in achieving precise diagnostic outcomes. Despite the considerable research conducted on tongue segmentation 10 challenges persist, particularly as intelligent tongue diagnosis becomes increasingly utilized on mobile devices. Existing methods often result in mis-segmentation or over-segmentation due to factors such as skin variations and environmental conditions. This underscores the necessity for a tongue segmentation model that can adapt to complex environments with greater accuracy. 11 For example, U-Net has been favored in the field of tongue segmentation due to its compact size and strong ability to extract local features. However, its unique U-shaped structure and convolutional neural network (CNN)-based architecture present certain challenges. While the U-shaped structure facilitates the fusion of shallow and deep image features, the direct skip connections can inadvertently introduce shallow noise into deeper layers. To mitigate this issue, attention blocks have been incorporated into skip connections as a promising method for filtering out shallow noise.12,13 However, these attention blocks are prone to over-fitting in complex environments where tongue images are limited, even though they significantly improve the model’s inference time. 14 Moreover, while CNN-based models excel at extracting local features, they often struggle to capture global features, which is crucial for accurately segmenting tongue-like objects in challenging environments. This difficulty is exacerbated by noise transfer through skip connections and the model’s inherent limitations in global feature extraction. Given these challenges, it is urgent to develop a robust noise filtering method for skip connections that can also effectively extract global features and select relevant features for transmission. Manifestly, the Mamba model offers a potential solution by converting images into text sequences, thereby enhancing global feature extraction. Additionally, it incorporates a feature selection mechanism that selectively retains or discards information based on input content, 15 aligning with the objectives of this study. Therefore, we proposed an innovative feature filtering and extraction approach, inspired by the convolutional block attention module (CBAM) 16 and based on Mamba, for the skip connection in U-Net. This method effectively extracts global features while selectively preserving spatial and channel features. Furthermore, to enhance feature representation, we employed a fusion method that integrates the output features from each stage, thereby improving the model’s ability to capture local detail features.
The main contributions of this article are as follows:
This study is the first, to our knowledge, to leverage the capabilities of Mamba for global feature extraction and feature selection. This study could address the problem of U-Net’s limited ability to extract global features and skip-connection’s inability to select passing features. To bolster U-Net’s local feature extraction capability, we proposed a multi-stage feature fusion approach. This enhanced the local features extracted by the model. Our model achieved superior results in the tongue segmentation task, proving its efficacy for the complex environment tongue segmentation task. This could provide a strong foundation for subsequent intelligent tongue diagnosis in similarly challenging environments.
The rest of this article is organized as follows. The “Related work” section provides a review of the related work. The “Materials and methods” section presents the new model proposed in this article. The “Results” section presents the experiment results. The “Discussion” section analyzes the experimental results. Finally, the conclusion of this article is presented in the “Conclusion” section.
Related work
Tongue segmentation
Existing tongue segmentation methods can be categorized into three main approaches: threshold segmentation methods, active contour methods, and deep learning methods. As one of the earliest techniques used for tongue segmentation, threshold segmentation relies on the color space features of the tongue and background in an image, setting threshold values to distinguish between them. For instance, Du et al. 17 converted red, green, blue tongue images to hue, saturation, and intensity (HSI) color space, using thresholds based on hue and intensity components to segment the tongue, followed by converting the images into binary form. Similarly, Chen et al. 18 employed a chroma threshold in hue, saturation, and value space, applying color enhancement in the region of interest and then using luminance thresholds in LAB color space to obtain the complete contour. Huang et al. 19 also converted tongue images to HSI color space, analyzing hue, and intensity characteristics of neighboring sub-blocks based on the user-selected seed points to merge sub-blocks that met the criteria. However, threshold segmentation becomes less effective in complex environments where parts of the image, such as skin, resemble the tongue, leading to inaccurate results. To overcome this, template matching segmentation was introduced, constructing templates to compare similar regions in images. For example, Saparudin and Muhammad 20 and Gu et al. 21 employed threshold and Canny algorithms to detect tongue edges, followed by boundary refinement using Chan-Vese modeling. Despite these advancements, these methods struggle in complex environments where tongue-like noise significantly reduce segmentation performance. To address these challenges, deep learning methods have emerged, offering superior performance by effectively capturing semantic information in images and reducing the impact of noise. Among these, U-Net has become the backbone network for many tongue segmentation models.22–24 However, with the growing demand for mobile tongue diagnosis, recent studies have focused on developing smaller and faster networks that can still accurately segment the tongue.25–27 Yet, these models often compromise performance due to environmental noise, leading to incomplete segmentation. Given the critical importance of accurately segmenting the tongue, especially for analyzing tongue coating, the priority has shifted from reducing model complexity to improving segmentation accuracy in complex environments.
Attention mechanism
In segmentation models, the attention mechanism directs the model’s focus to the target region. To extract spatial and channel features from images, some studies have incorporated channel attention and spatial attention into models, particularly for medical images such as computed tomography, 28 magnetic resonance imaging, 29 tongue diagnostic, 30 and cell images. 31 However, using spatial or channel attention alone in datasets with limited samples often fails to distinguish between features that are similar to the target, leading to over-fitting. To address this issue, integrated methods like CBAM and coordinated attention, which combine spatial and channel attention, have been developed.32–34 Two common approaches have emerged for combining these attention features: parallel and serial connections of spatial and channel attention modules. The parallel approach, exemplified by DA-Net, 35 quickly extracts various attention features, enhancing the model’s efficiency. In contrast, the serial connection, represented by CBAM. 16 allows for multiple extractions of attention features from the same data, yielding deeper semantic features.36–38 However, feature loss during extraction can reduce the efficiency of backward feature extraction, impacting model performance. With the advancements in deep learning and the availability of enriched datasets, deeper networks like the transformer, based on the multi-head self-attention mechanism, have gained popularity in medical image processing.39–41 Unlike CNNs, transformers can capture global features by dividing an image into smaller patches and processing them as a sequence, similar to a sentence. However, transformers lack inductive bias and require large datasets to achieve optimal results. To overcome these limitations, recent studies have explored combining CNNs with transformers to acquire both local and global features.42–44 Although this hybrid approach addresses some of the transformer’s shortcomings, it has not significantly improved performance on small datasets. Moreover, transformers are limited in mining long-range dependencies within images due to word size constraints, and their numerous parameters result in time-consuming inference.
State-space model
To address the challenges posed by the lengthy inference times of transformers and the difficulties CNNs face in capturing global features, the sequence-structured state-space model was proposed by Gu et al. 45 To further enhance model inference speed, Jimmy et al. 46 introduced S5, which reduces model complexity to a linear level. Subsequently, Harsh et al. 47 developed H3, a model that uses a structure similar to self-attention, making the feature extraction capabilities of the sequence-structured state-space model comparable to that of the transformer. The Mamba model, incorporating a gating structure and H3, along with an input adaptive mechanism, further enhances the state-space model, improving inference speed, throughput, and overall metrics. 15 As Mamba’s effectiveness in processing continuous data and text data becomes evident, similar to the Transformer, research has increasingly applied it to image processing. Gu et al. 15 proposed a Mamba-based bi-directional positional coding module for image feature extraction, outperforming established vision transformer methods and significantly improving computational and memory efficiency. Zhu et al. 48 introduced a method to extract positional information of a two-dimensional (2D) image in four directions and connected the Mamba modules in series. Recently, an increasing number of researchers have applied visual Mamba, based on the multi-directional extraction of image position information, to medical image processing, where each Mamba module is combined in a U-shaped structure. 49 Although these methods integrate shallow features of structured spatial states with deep features through a U-shaped structure similar to U-Net, they do not effectively prevent noise in the shallow features from being transmitted to the deep features. One of the advantages of spatial state models is feature selection, which is also required in U-Net skip connections. However, there is still no effective method to select the transferring features for U-Net using this property. Similar to transformers, existing Mamba-based computer vision models lack effective local feature extraction methods and typically consist of stacked Mamba blocks, which also require pre-training in data-scarce medical image processing tasks. Many models have adopted the 2D-selective-scan (SS2D) method to assist the spatial state model in acquiring image spatial state features, but have not focused on channel features. Research in attention mechanisms suggests that the fusion of channel and spatial features can further enhance a model’s image-processing capabilities. Therefore, integrating channel and spatial feature selection methods to aid U-Net skip connections in filtering noise through the spatial state model’s feature selection property holds significant potential.
Materials and methods
The structure of the proposed TUMamba is shown in Figure 1. The model’s backbone is U-Net, and to mitigate the noise potentially introduced by skip connections, a Mamba-based approach was employed. This approach constructs an attention-like module that filters noise in both spatial and channel dimensions. Additionally, to enhance the model’s ability in extracting detailed features, we fused the outputs of each stage. The loss was computed on the output of each stage to improve the preservation of deep feature details. This section details the Mamba attention module and the multi-stage feature fusion module that we developed.

Overview of the model.
Mamba attention module
In U-shaped networks, shallow spatial and channel features are often transmitted through skip connections to deeper layers. While this direct transmission helps retain useful spatial and channel information for segmentation, it also carries noise from the shallow features. For example, in the initial stage of a U-shaped network, direct transmission features can introduce up to 50% noise to the features before convolution. Reducing this noise is crucial, particularly when segmenting the tongue in complex environments. Thus, replacing direct skip connection with a noise-reducing module that enhances shallow spatial and channel characteristics is necessary. Previous studies have indicated that attention mechanisms for tongue segmentation can lead to over-segmentation in complex environments due to small sample sizes and dynamic noise.11,12 To address these challenges, we propose the Mamba attention module, which integrates the selective state space model into attention extraction. Similar to CBAM, this module serially extracts spatial and channel features from tongue images. The Mamba attention module consists of patch embedding, spatial Mamba attention, and channel Mamba attention, as shown in Figure 2.

Structure of the Mamba attention module: (a) the overview of the Mamba attention module, (b) the structure of the spatial Mamba attention, (c) the structure of the channe Mamba attention, and (d) the structure of the SS2D and SSM. SS2D: 2D-selective-scan; SSM: state-space model.
To process images using Mamba, they are first subjected to patch embedding, similar to the vision transformer.
48
The image is divided into patches of size




Four different patch sequences: (a) S-shaped front-to-back, (b) S-shaped back-to-front, (c) N-shaped front-to-back, and (d) N-shaped back-to-front.
Multi-stage feature fusion module
The spatial features within the patch sequence were extracted through the aforementioned process. Similar to CBAM, we then apply a channel Mamba attention shown in Figure 2(c) for the channel feature extraction of the sequence after the spatial Mamba attention. First, we performed a dimensional transformation, swapping the channel with the patch. The input data shape of channel Mamba attention becomes
The Mamba attention module efficiently extracts global features from the image in skip connection. In complex environments, capturing detailed information also requires accurate local detailed features. CNN can extract local features efficiently, the preservation of details diminishes as the number of layers increases. To address these problems, this paper proposes an early output method that uses the U-shaped network’s structural properties to fuse multi-stage features, thereby enhancing detail acquisition ability. Its specific structure is illustrated in Figure 4. The input data of the multi-stage feature fusion module is the output from each stage. Since each stage outputs feature maps of different shapes and channels, they are first aligned. The alignment module is composed of an up-sampling module and a

Structure of multi-stage feature fusion module.
Loss function
In this article, losses are categorized into stage loss and result loss. Stage loss is computed for each stage of the feature map, ensuring that the output of each stage retains as many detailed features as possible. The computation of this loss is specified by equations (4) and (5).
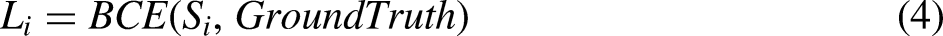



Results
In this section, we compare the tongue segmentation performance of the proposed model with existing model through metrics such as MIoU, precision, recall, and F1-score.
Datasets
This study utilized a publicly available dataset for its observational analysis. The tongue segmentation dataset includes images from two sources: TongueSAM.
50
They are 300 tongue images taken from Harbin Institute of Technology in 2014 and 1000 tongue images collected on the web in 2022. These datasets were merged to create a unified dataset of 1300 tongue images. The images come in two sizes:
Training details
The dataset was randomly divided into a training dataset and a test dataset, with a ratio of 4:1 for training to test data. All the models in the research are constructed by TensorFlow 2.6.0 and Keras 2.6.0. The training was conducted on a single Nvidia 3090 16G GPU. The models were trained with a learning rate of
Evaluation indicators
We used MIoU, precision, recall, and F1-score to assess segmentation performance. MIoU was the primary metric, while F1-score was the secondary evaluation indicator. The specific calculation methods for these metrics are shown in equations (8) to (11), where



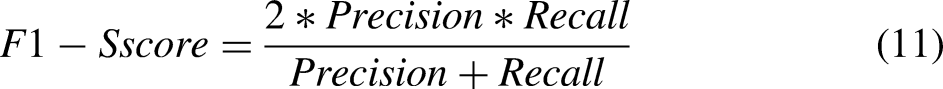
Segmentation performance comparison
In this section, we compared the proposed model from the “Materials and methods” section with other models using the previously mentioned metrics. The models were classified into four categories, the U-Net,
51
the models in which the attention guides the U-Net feature transfer using CBAM
16
or SENet,
52
the model for tongue segmentation in the complex environment such as OET Net
14
and RMP U-Net,
53
and the current best models for semantic segmentation of images such as Mobile Net,
54
Comparison of indicators.

MIoU: mean intersection over union.
Bold is the best result, underline is the second best.
We show the segmentation results of different models for images acquired in different environments since the dataset contains two types of images taken from the laboratory and complex environments. Figure 5 shows the results of different models for standard acquisition. In the standard setting, the different models have comparable effects on the segmentation of the tongue except for RMP U-Net. However, when examining the details of the segmentation results, particularly the center-upper region of the tongue, it becomes evident that models such as U-Net, SE U-Net, OET NET, Mobile Net,

Results of different models for tongue segmentation for standard acquisition.
Figure 6 shows the results of different models for complex environment acquisition. The U-Net exhibits over-segmentation caused by the background and clothing. Interestingly, the Attention model not only failed to reduce over-segmentation but exacerbated it. Regarding detail extraction, such as curved depression on the right side of the tongue, both SE U-Net and Mobile Net models were unable to effectively capture this feature.

Results of different models for tongue segmentation for complex environment acquisition.
Ablation experiment
We performed ablation experiments using U-Net as the backbone to evaluate the impact of adding and removing modules on tongue segmentation performance. The results, detailed in Table 2. For single-module additions, the Mamba attention module notably improved the segmentation performance, increasing the MIoU by 0.46% compared to the backbone U-Net model. As additional modules were stacked, the model’s efficacy continued to improve. The TUMamba model, which combines the Mamba attention module and the multi-stage feature fusion module with U-Net, achieved the best segmentation results, improving the MIoU by 1.17% over the backbone model.
Results of ablation experiment.

MIoU: mean intersection over union.
Bold is the best result.
Figure 7 illustrates the effect of different module additions and subtractions on tongue segmentation under laboratory conditions. The results indicate that these modifications affect tongue segmentation outcomes in a controlled environment. While multi-feature map fusion may introduce some ambient noise, the Mamba attention module effectively reduces noise interference.

Results of different module additions and subtractions for tongue segmentation for laboratory environment acquisition. 1: U-Net, 2: Mamba attention module, and 3: multi-stage feature fusion module.
Figure 8 displays the results of the ablation experiment in a complex interference environment. Although multi-feature map fusion does not completely address environmental noise interference, it enhances the smoothness of the segmentation results. The Mamba attention module helps the model mitigate environmental noise interference effectively.

Results of different module additions and subtractions for tongue segmentation for complex environment acquisition. 1: U-Net, 2: Mamba attention module, and 3: multi-stage feature fusion module.
Discussion
U-Net is widely recognized for its efficiency in image processing tasks, due to its effective capture of local features and its distinctive U-shaped structure, which integrates both shallow and deep information. Despite these advantages, U-Net struggles with capturing global features and is prone to transferring noise into semantic information through its skip connections. This limitation becomes evident in complex environments, as shown in Figure 6, where U-Net exhibits significant over-segmentation due to the presence of tongue-like objects. Traditionally, attention mechanisms have been used to address such issues. However, our experiments corroborated the findings of, 14 which suggests that incorporating attention into U-Net paradoxically, degrade performance. Analysis of the metrics Table 1 suggests that this poor performance is similar to over-fitting. While attention mechanism enhance the model’s recall, they concurrently reduce precision, resulting in segmentation outputs that include more of the target but also increased background noise. This problem stems from a mismatch between the sample size of the image dataset and variability in background features, as the training samples are adequate for handling the highly variable backgrounds. To address these challenges, we employed the recently introduced Mamba attention mechanism. Spatial Mamba attention enhances the model’s ability to manage background noise by processing four different order sequences and dividing images into smaller patches to extract global spatial information. Furthermore, to improve global channel feature extraction, we integrated channel Mamba attention following spatial Mamba attention, inspired by the CBAM framework. 16 As shown in Table 2, the Mamba attention module significantly improves both precision and recall, effectively resolving the over-segmentation issue. In conclusion, the proposed model addresses both over-segmentation and under-segmentation issues in tongue segmentation tasks within complex environments, achieving accurate separation of the tongue from tongue-like objects. Compared to current popular mobile segmentation models listed in Table 1, our model’s inference time is comparable to that of Mobile Net, indicating its potential for deployment on mobile devices for rapid and precise segmentation.
Our model’s inference time is comparable to that of Mobile Net, indicating its potential for deployment on mobile devices for rapid and precise segmentation. Figure 6, shows that while each model performs similarly in standard environments, there is still a gap in edge detail handling. To capture detailed information from each feature map, we fused the feature maps at each stage and applied robust supervision to the tongue image detail segmentation by calculating the loss for each stage’s feature maps. As shown in Table 2, this method significantly enhances the model’s segmentation performance, with Figure 5 illustrating that it effectively extracts more detailed features of the tongue edge.
In this study, we explored two common methods for fusing spatial and channel attention: serial and parallel connections. Serial connections, as utilized by Sanghyun et al. 16 and parallel connections, as described by Fu et al., 35 each offer distinct advantages. Based on the experimental results presented in Table 3, we chose a CBAM-like approach with serially connected attention mechanisms. While parallel extraction can improve feature extraction efficiency, it is less effective compared to serial connection, as it may fail to adequately filter out noise. Moreover, channel feature extraction first, as opposed to spatial feature extraction, can be less effective with Mamba due to potential loss of spatial features during sequence processing. Thus, a CBAM-like feature extraction architecture was adopted in our research.
Results of different structures.
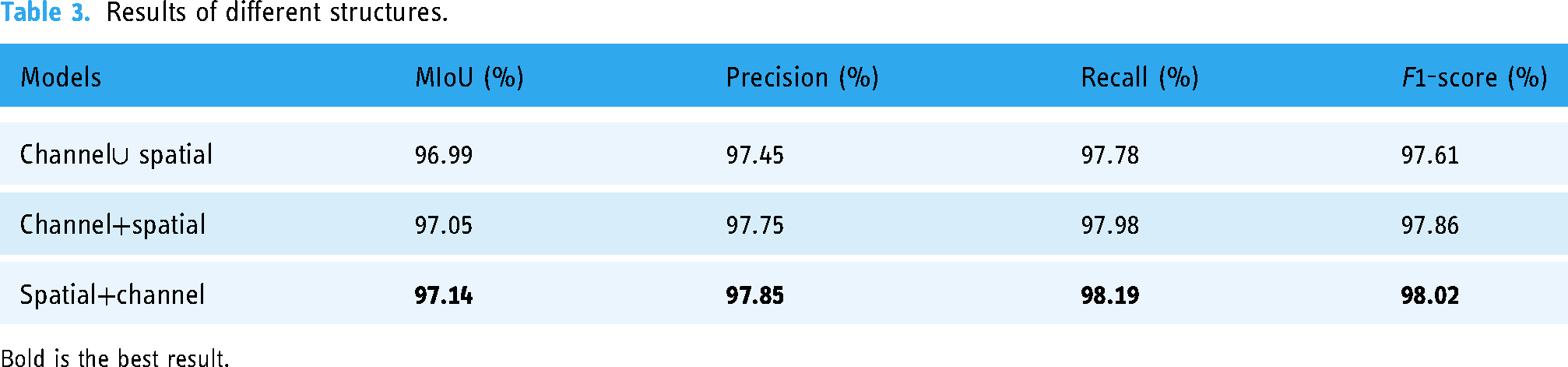
Bold is the best result.
Conclusion
In this article, we introduced a novel tongue segmentation model, leveraging both Mamba and U-Net architectures. Our approach incorporated a Mamba attention module to extract global spatial and channel features effectively. To maintain fine details and local information, we enforced strong supervision at each stage of the model, with the final results being a fusion of outputs from all stages. Our method excelled particularly in tongue segmentation tasks. However, it’s worth noting that model based on Mamba struggles with extracting precise location information. Although our method addressed this issue to some extent by employing four different sequences for location feature extraction, there remained a disparity compared to traditional convolution kernels. Therefore, our future main work will focus on Mamba for 2D image spatial information extraction. In this way, accurate extraction of images based on Mamba can be achieved. Then, combined with Mamba’s advantage of text feature extraction, we will construct a multi-modal macro-model of TCM.
Footnotes
Acknowledgements
We thank Cao et al.
50
for the open source tongue segmentation database. The public dataset is acquired at ![]() .
.
Contributorship
Fan Jiang: conceptualization; Fan Jiang: methodology; Fan Jiang: software; Fan Jiang and Yanmei Zhong: validation; Fan Jiang: writing–original draft preparation; Yanmei Zhong and Simin Yang: writing–review and editing; Simin Yang: supervision.
Consent to participate
Not applicable. The data used in this article comes from publicly available datasets, so informed patient consent is not required for this research.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, or publication of this article.
Ethical approval
The data used in this article comes from publicly available datasets, so there are no ethical conflicts.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Chengdu medical research project (Fund Number: 2020176).
Guarantor
FJ.