
Abstract
Objective
Despite previous research identifying factors such as age, education level, income, and interest in technology that influence digital literacy among the elderly, this study attempts to use machine learning algorithms, especially ensemble learning algorithms, to predict and identify the key factors that affect the digital information literacy of the elderly, so as to propose effective strategies to improve the elderly's ability to utilize digital information and better integrate into the digital society.
Methods
This study used primary data on older adults from the Digital Divide Survey 2022 conducted by the Korea National Information Society Agency. A predictive model was built, and 15 variables that were highly important in predicting digital information literacy were identified. Prediction accuracy was assessed using an ensemble of algorithms including Random Forest, LGBM, XGBoost, AdaBoost, and CatBoost.
Results
The study found that in addition to demographic factors and personal technology use ability factors, relationship support factors and social digital environment factors are also important predictors of digital information literacy for the elderly. Among different predictive models, the CatBoost model, based on boosting ensemble, exhibited the highest predictive accuracy at 86.2%, followed by Random Forest (85.5%), LGBM (85.2%), XGBoost (84.5%), and AdaBoost (83.8%). The predictive accuracies of these models were higher than those of traditional machine learning models, indicating the effectiveness of ensemble learning algorithms in predicting digital information literacy among the elderly.
Conclusions
The academic significance of this study lies in the application of artificial intelligence technologies to the social sciences, specifically demonstrating the effectiveness of ensemble learning algorithms in predicting factors influencing the digital literacy levels of the elderly. This approach provides a novel and powerful tool for addressing complex social issues. The practical significance lies in the proposed strategies for improving the digital literacy of the elderly based on the research results, including education and training, social relationship support, social participation, technical support, and policy formulation, aiming to help the elderly better adapt to the digital environment, narrow the digital divide, and enhance the elderly's sense of participation and happiness in the digital society.
Keywords
Introduction
With the rapid development and popularization of information and communication technology (ICT) around the world, every aspect of human life has undergone a significant transformation. This technology has not only increased the convenience of life and expanded the opportunities for communication but has also largely changed the way information is accessed, processed, and used. 1 More importantly, ICT offers the elderly in accessing health information, engaging in social activities, and maintaining social connections, and this has become a key factor in improving the health and life quality for the older population.1–3 Despite the opportunities that ICT offers, the digital divide becomes more significant between different generations in which the older population was not able to acquire, validate, and effectively use information through ICT easily. This issue has become even more pronounced in the quarantine period during the COVID-19 pandemic.
According to the digital information literacy levels of various age groups in “The Report on the Digital Divide of 2020” conducted by the National Information Society Agency (NIA) of South Korea, there is a significant gap in digital information literacy among older people compared with the general public, with digital information literacy scores in the 60 s (85.6) and 70 s (29.7) age groups well below the level of the general public (100). 4 This gap is more significant in countries with an aging population and an information society, such as South Korea. The variation in information technology capabilities among the elderly exacerbates social differentiation and exclusion, further leading to social inequality. 5 Particularly, during the quarantine period of the COVID-19 pandemic, elderly individuals with little knowledge of digital information had faced more difficulties in daily life and were benefited less from online services.
Previous studies on digital information literacy among the older population have mainly utilized traditional econometric models to analyze the causal relationship between dependent and independent variables. It has been found that age, income, education, social support, and the need to be close with family have been identified as key factors influencing digital information literacy among older adults.6–10 In recent years, the development of artificial intelligence and machine learning techniques has provided new tools for social science research. These techniques are capable of assessing linear and nonlinear relationships between variables and accurately predicting influencing factors. 11 The applications of machine learning are not limited to areas such as medical diagnostics, 12 fraud detection, 13 and student satisfaction prediction, 14 but it also shows great potential in predicting the influencing factors of the digital divide and aging.11,15,16
A number of studies have reported a number of factors that influence digital information literacy among older adults, such as age, education level, income, and interest in technology.6–10 In this study, we aim to develop a deeper understanding of the complex relationships between these aforementioned factors and their interactions with other variables that may not have been fully considered before, through machine learning techniques. This study aims to establish a model based on public data and machine learning techniques to predict and analyze the key factors affecting the digital literacy of the elderly. This method identifies the influencing factors of digital information literacy of the elderly, thereby providing a scientific basis for designing effective intervention measures. These interventions should comprehensively consider various aspects such as education and training, social relationship support, social participation, technical support, and policy formulation. This comprehensive approach will enable the elderly population to better adapt to the digital environment, enhance their digital literacy, bridge the digital divide, and improve their sense of participation and well-being in the digital society. The results of this study will contribute theoretically to the exploration of the application of machine learning and artificial intelligence technologies in improving the health and well-being of the elderly. Additionally, the findings provide empirical evidence for enhancing the digital literacy of the elderly and offer valuable references for policymakers, social service providers, and technology developers. This ensures that the elderly can fully utilize information technology and enjoy the various benefits brought by the digital age.
Literature review
Digital information literacy
Digital information literacy is a multidimensional concept that aimed at describing an individual's ability to access, understand, evaluate, and apply information in the digital age.1,2 This concept encompasses terms related to information literacy, digital literacy, and ICT skills. In recent years, this concept has had an unprecedented impact on the quality of life of older adults as society enters the age of aging and digital information. Studies have shown that good digital information literacy is associated with positive health outcome in older adults and can reduce depression levels, alleviate loneliness, and enhance life satisfaction through newly built social relationships online.5,17,18
However, there is a significant digital divide among the elderly groups over 65 years old in South Korea, with their skills in using digital information being significantly lower than those of other age groups. 11 This phenomenon not only reflects the lack of training in digital skills in formal education but also highlights the deficiencies of older adults in using computers or smartphones for information retrieval, online shopping, online banking, administrative tasks, and social activities. 19 Despite the existence of arguments that the IT technology is too complex for older adults, the popularity of the Internet actually provides them opportunities to interact with society, enhance independence, and communicate across generations.5,18
Given the disadvantages faced by the elderly in digital information literacy, research in this field holds significant social importance. By identifying and understanding the key variables that influence the digital information literacy of the elderly, effective strategies can be proposed to enhance their digital information utilization capabilities. This not only helps bridge the digital divide but also significantly improves the quality of life for the elderly, thereby promoting overall societal progress and development.
Application of machine learning in digital information literacy research
Machine learning, a pivotal branch of artificial intelligence, is dedicated to mimicking the human learning process through a combination of mathematics, statistics, cognitive science, and computer science. This technique recognizes patterns by analyzing historical data and thus predicts future trends.16,20 Its applications in various fields such as disease diagnosis, 12 fraud detection, 13 text classification, 21 and image recognition 22 have significantly impacted the research and industry. However, traditional machine learning algorithms face challenges such as data imbalance, which limits their effectiveness in certain contexts. 23 To address these challenges, researchers have turned to new approaches such as ensemble learning and deep learning, aiming to improve performance and generalization by combining the strengths of multiple models.
Ensemble learning, which enhances the overall performance by combining the prediction results of multiple base learners, has achieved excellent results in various application scenarios. 24 Although these methods have been widely used in several research fields, however, relatively limited research has been conducted in the area of digital information literacy. Past studies have primarily focused on the use of traditional machine learning algorithms to address specific problems, such as Internet usage and successful aging judgments.15,16,25 Given the successful application of ensemble learning techniques in other domains and their capability to handle complex datasets, this study aims to bridge this gap, particularly regarding the factors influencing digital information literacy among the older population. We will focus on several widely used ensemble algorithms, including Random Forest, AdaBoost, XGBoost, LightGBM, and CatBoost, and explore how they can help improve digital information literacy among older adults.
The primary objective of this study is to utilize machine learning methods, particularly ensemble learning algorithms, to predict and analyze the key factors influencing the digital information literacy of elderly individuals. By doing so, the study aims to propose effective strategies to enhance the digital information utilization capabilities of the elderly. Unlike previous studies based on causal relationship models, this research leverages feature importance evaluation in the XGBoost algorithm to achieve more accurate predictions and analyses of the factors affecting elderly individuals’ digital information literacy. Consequently, the study seeks to develop effective strategies to facilitate the elderly's better integration into the digital society, improve their quality of life, and address the challenges posed by an aging population.
Methods
This study aims to provide valuable insights to enhance digital literacy among the elderly by predicting the factors influencing their digital literacy and assisting them in adapting to the digital development environment. The core of the research lies in utilizing advanced machine learning algorithms to predict the digital literacy of the elderly based on the 2022 Digital Divide Survey data conducted by the NIA of South Korea. The specific research methodology steps are as follows: firstly, selecting the raw data concerning the elderly from the 2022 NIA Digital Divide Survey data; then, selecting 15 variables deemed highly important in predicting digital literacy based on feature importance; and visualizing the specific contributions of these 15 features in predicting the digital literacy of the elderly using the SHAP method; constructing prediction models using ensemble machine learning algorithms, including Random Forest, LGBM, XGBoost, AdaBoost, and CatBoost; and evaluating the performance and prediction accuracy of each model; and finally, based on the analysis of results, determining the variables that are highly important and influential in predicting digital literacy, as well as identifying which machine learning algorithm is more effective in predicting the digital literacy of the elderly. The research framework is illustrated in Figure 1.
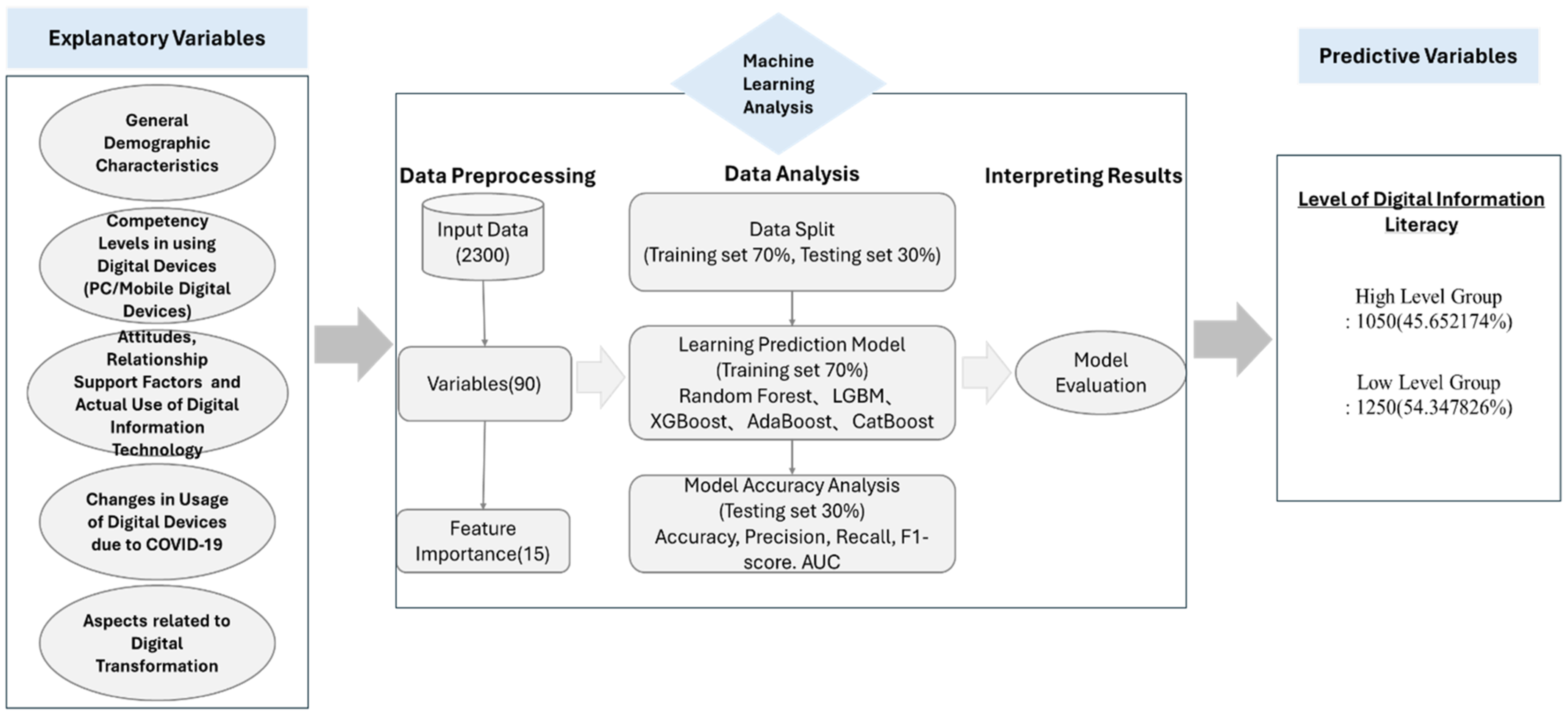
Framework.
Participants and data preprocessing
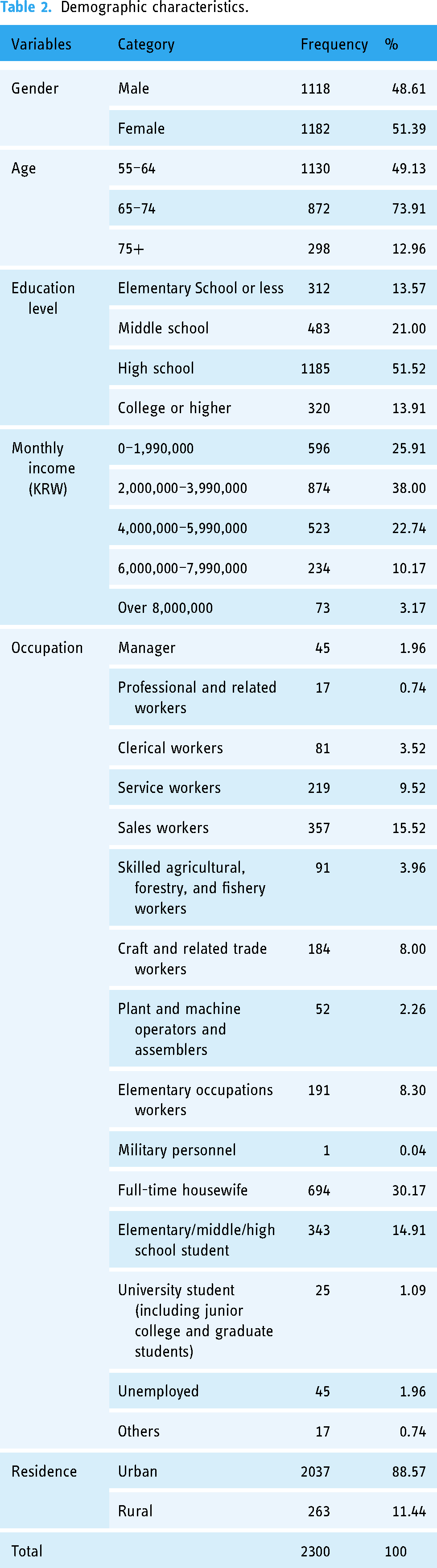
The data used in this study are a cross-sectional dataset from the 2022 Digital Divide Survey conducted between September and December 2022. The South Korean government has been conducting this survey since 2002 to measure digital usage and the digital divide among different population groups. This dataset includes general demographic characteristics, digital device usage proficiency (PC/mobile digital devices), digital literacy levels, attitudes toward and actual usage of digital information technology, as well as changes in usage and perceptions of digital transformation due to COVID-19, from 15,000 individuals residing in 16 cities across South Korea. The participants include general citizens, people with disabilities, the elderly, and low-income individuals, among others. In the interview, each participant answered about 160 to 180 questions. The survey questions were formulated based on the NIA (2022) questionnaire and referenced previous studies5,11,19,26–28 to organize the variable names and classifications used in this study (see Table 1). The survey employed a square root proportional allocation method, based on sociodemographic characteristics collected through multistage stratified sampling (e.g., gender, age, and residence). Consequently, these data are appropriate for this study, which investigates a sample of 2300 individuals aged 55 and above. Table 2 reports the basic characteristics of the sample population.
Survey content on the digital information divide.

Demographic characteristics.
This study utilized the open-source programming language Python (version 3.8.10) and Jupyter Notebook, along with machine learning libraries such as Scikit-learn (version 1.0.2), Pandas (version 1.4.1), Numpy (version 1.22.2), and Matplotlib (version 3.5.2) for analysis. The research process was divided into five steps: initial data selection, handling missing data and data structure processing, feature ranking to identify the most important features, machine learning algorithms to develop classifier models, and model evaluation.
To maximize the benefits from this approach, it is essential to minimize the number of discarded variables during the preprocessing stage. Fundamentally, data preprocessing includes data integration, handling of missing or noisy values, and technical processing, which enhances the authenticity and predictability of the data. Initially, we compared the questions included in the annual surveys to extract common questions and replaced them with identical variable names for the elderly sample. Due to the nature of the survey, variables with missing data due to lack of response were removed. Additionally, irrelevant or insignificant adjustment parameters used for formulating the dependent variable were also discarded. Subsequently, because the characteristics of the data structure were not uniform in dimensions and units, which could affect the model's evaluation of feature importance, we first converted categorical variables to numerical ones using label encoding (e.g., education level, income) and then applied min–max scaling. Finally, we created a discrete predictive variable based on the average value of the digital literacy index for the elderly, converting it into a binary classification problem. For the fifth step, we allocated the 2300 samples into 70% for the training dataset and 30% for the testing dataset.
Predictive variables
In this study, we utilized a binary dependent variable to predict the digital literacy levels of the elderly. This consisted of 19 questions encompassing both basic and advanced levels of digital literacy for the elderly. These questions were referenced from the NIA (2022) questionnaire and previous research analyses.11,19 All questions were rated on a five-point Likert scale (strongly disagree, disagree, neutral, agree, and strongly agree). The specific content is detailed in Table 3. To improve prediction accuracy, we create a discrete predictive variable based on the average value of the digital information literacy indicators for the elderly, assigning values 0 and 1 to represent low and high levels of digital information literacy, respectively. Among the 2300 participants tested, 1250 (54.347826%) exhibited a lower level of digital literacy, whereas 1050 (45.652174%) demonstrated a higher level of digital literacy. Discretization is a key step in machine learning research as it simplifies data representation and enhances understanding. 11
Dependent variables.

Explanatory variables
To improve prediction accuracy, we utilized the feature importance algorithm of XGBoost to identify the most critical explanatory variables in the predictive model. The feature importance algorithm is capable of eliminating redundant and irrelevant features, thereby improving the performance of the classifier. 29 As illustrated in Figure 1, we initially removed variables related to personal identity information and missing data from the original dataset of 2,300, resulting in 90 explanatory variables. Subsequently, we employed the XGBoost algorithm to calculate the importance scores of these 90 explanatory variables. This enabled us to identify the most crucial factors affecting the prediction outcomes, with all feature importance scores depicted in Figure 2.

Feature importance.
The data structure features impacting the digital information literacy levels of the elderly are not uniform in dimensions and units, which affects the model's evaluation of feature weights, thereby influencing its accuracy and convergence speed. Therefore, min–max normalization is applied for feature normalization, scaling the feature data to the [0,1] range. The transformation function is as follows:
From the 90 explanatory variables, we derived the top 15 explanatory variables based on the importance scores, forming the optimal feature subset. The results of the feature selection are presented in Table 4.
Independent variables.

Interpretability of SHAP method
To further understand the contribution of features to the model output, we calculated SHAP values. SHAP values provide specific contributions of each feature to the model's predictions, helping us identify which features have positive or negative impacts on the prediction outcomes for specific samples. By visualizing SHAP values (as shown in Figure 3), we can intuitively observe the specific contributions of the top 15 features in predicting the digital literacy of the elderly. The dots represent the samples for each feature, colored according to their feature values, ranging from blue to red, indicating the ascending order of values. Features such as Q4A5 (ability to use a PC), Q15A2 (how to solve problems when using digital devices), ADQ4 (educational level), and ADQ1 (age) contribute significantly to the model's predictions. Q4A5 (ability to use a PC), Q15A2 (how to solve problems when using digital devices), and ADQ4 (educational level) have a positive impact on the model's predictions, whereas ADQ1 (age) has a negative impact.
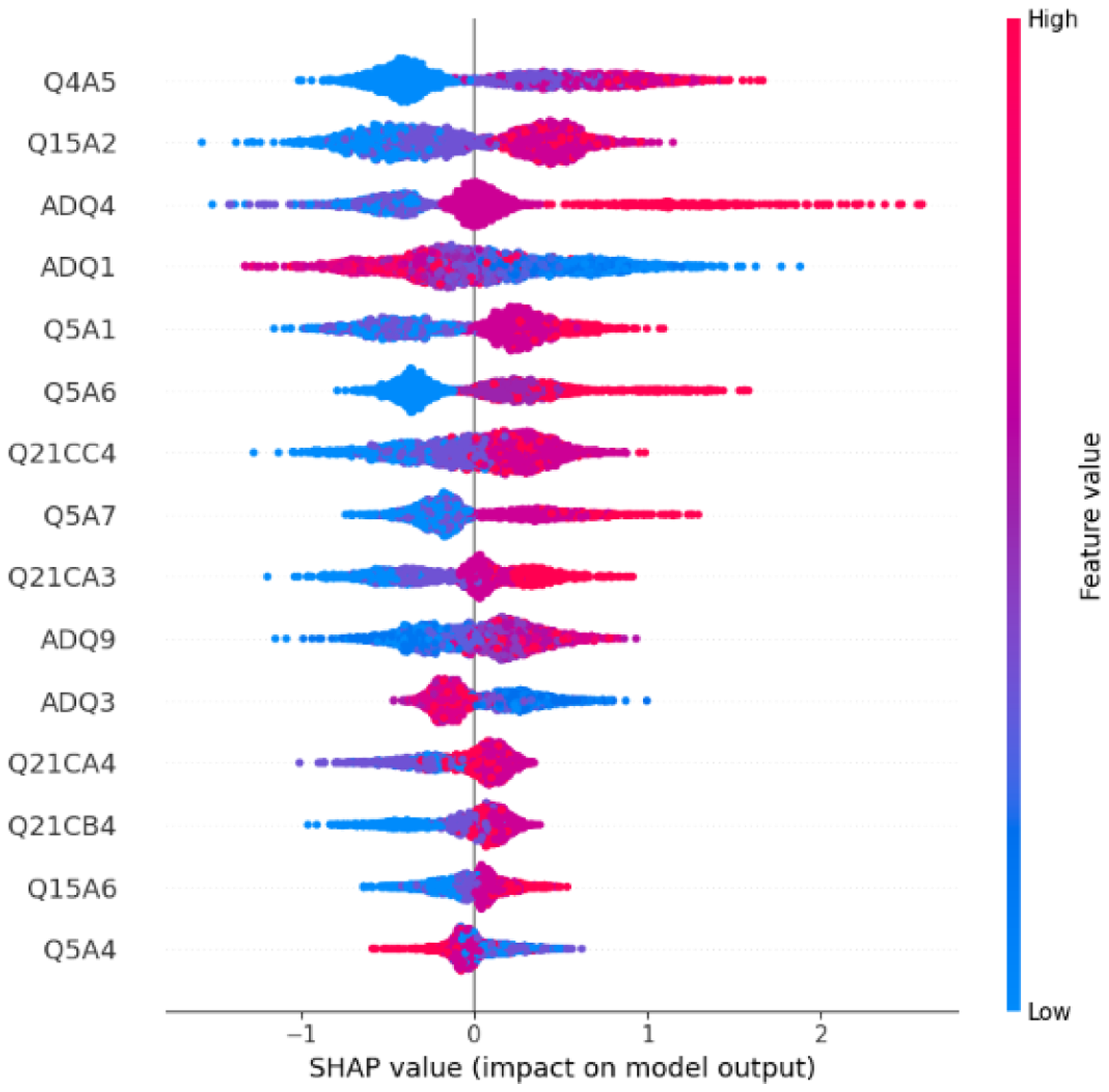
SHAP value.
Feature correlation test
This study selected the ETA coefficient to calculate the correlation between features and constructed a correlation matrix to test the degree of correlation among the selected features. The ETA coefficient 
The value of the ETA coefficient ranges between [0, 1], with higher values indicating stronger correlations between variables.
Assuming mmm is the sample size in dataset D, and each sample dataset contains n features (with the nth feature being the prediction target), we calculate the ETA coefficient between each pair of features to form a correlation matrix. 

Feature correlation heat map.
Model training
In order to determine the most effective binary classifier for predicting the digital information literacy level of the elderly, we adopted classic and popular ensemble learning algorithms, namely, the bagging representative algorithm Random Forest and the boosting representative algorithm AdaBoost, XGBoost, LightGBM, and CatBoost.
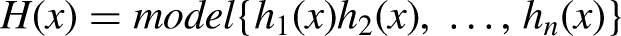



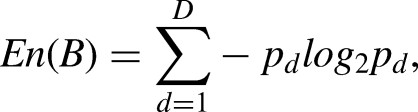

Evaluation metrics and analysis results
The evaluation criteria of a model are crucial for the measurement of the final results. To determine the best model for assessing the digital information literacy of the elderly, we employ various metrics calculated based on the confusion matrix, such as accuracy, precision, recall, and F1 score, for measurement. A higher value indicates better model performance. The comparison results of different algorithm performance metrics are presented in Table 5. Based on the confusion matrix, several evaluation metrics can be calculated to assess model performance:
The results of the performance criteria of selected models.

Accuracy: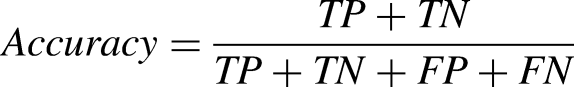
Precision:
Recall:
F1 Score:
Based on the performance on the test set, the CatBoost model achieved the highest accuracy and AUC values, indicating its superior generalization ability and demonstrating its advantages in practical applications. In contrast, while the XGBoost and LGBM models performed excellently on the training set, they exhibited overfitting issues on the test set. The other models also performed comparably on the test set, but CatBoost had a slight edge. Considering the confusion matrix and other performance metrics (such as accuracy, precision, recall, F1 score, and AUC), the CatBoost model demonstrated better balance in classifying positive and negative samples and performed excellently on the test set, further proving the numerous advantages of the CatBoost classifier in predicting panel data. Therefore, it is recommended as the best model for practical applications. It is simple and efficient, can handle missing and noisy data, and shows good interpretability. The optimal parameters for each classifier and their performance on the training and test sets are shown in Table 5.
Differences in digital information literacy between urban and rural populations
To describe the basic situation of digital information literacy among urban and rural populations, we conducted statistical analyses on both groups separately and further examined whether the differences in digital information literacy between urban and rural populations are statistically significant through an independent samples t-test. The results are shown in Table 6.
t-Test results.

Based on the comprehensive analysis, the mean digital literacy score for the urban population (0.477) is higher than that of the rural population (0.338). The t-test results indicate a t-statistic of 4.263 and a p-value much less than 0.05, demonstrating that the difference in digital literacy between urban and rural populations is statistically significant. This implies that the digital information literacy of the urban population is significantly higher than that of the rural population.
Discussion
Based on the results of the feature importance analysis, this study identified four dimensions that can predict the digital information literacy levels of the elderly: demographic factors, relational support factors, personal technology usage ability factors, and social digital environment factors. These dimensions are of great value in predicting the factors influencing digital information literacy among the elderly. This study was conducted to predict the digital information literacy of older adults in the current context, as many elderlies are keeping pace with technological developments amidst the acceleration of digital transformation. In particular, this study utilizes public data and machine learning, which have not been commonly used in previous digital information literacy research, to establish a predictive model of digital information literacy and perform related analyses. In this study, 15 variables that are significant in predicting digital information literacy among older adults were derived, which can be categorized into (1) demographic perspectives (ADQ1, ADQ9, ADQ3, ADQ4), (2) relational support perspective (Q15A2, Q15A6), (3) personal technology usage ability perspective (Q5A6, Q5A7, Q5A1, Q4A5, Q5A4), and (4) social digital environment perspective (Q21CB4, Q21CA3, Q21CC4, Q21CA4). The importance of these four perspectives for predicting the digital information literacy of the elderly will be discussed in the following text.
Firstly, the discussion of digital information literacy has largely focused on demographic factors such as age, income, occupation, and education. Research has shown that with increasing age, individual perceptual functions and cognitive abilities may decline, thereby affecting the ability of the elderly to use ICT.41,42 In contrast, older adults with higher-income levels usually have better living condition and better quality of life tend to use the internet for communication more frequently, thereby accessing more information technology resources.43,44 Moreover, the professional environment's demands for technology directly influence the digital information literacy levels of individuals in various occupational categories, with those working in information technology-related jobs usually having a higher level of technical proficiency and information processing capability compared with people in other professions. 15 The education level is directly linked to an individual's ability to acquire and utilize Internet-based ICT, with higher-educated individuals often possessing higher digital information literacy. 45 Therefore, age, income, occupation, and education are considered to be the main influencing factors in predicting the digital information literacy of the elderly, and this argument may have been reflected in the results of this study.
Secondly, relationship support is also an important influencing factor in predicting the digital information literacy of the elderly. When the elderly encounter issues using digital technology and can obtain assistance from others, this immediate problem resolution significantly improves their motivation to learn and use Internet technology.46,47 Compared with older adults who cannot obtain technical help, those who receive support show higher digital capabilities. 48 When the elderly face problems using information technology, they typically first seek help from family and friends to overcome technical barriers. This assistance not only resolves the difficulties they encounter in meeting digital needs but also further enhances their digital literacy.
Thirdly, an individual's ability to use technology directly determines the ease with which the elderly can navigate the digital world. According to “The Report on the Digital Divide” Survey results published by the NIA in 2022 and 2023, the digital information level of the older population is generally low, reflecting the severity of the information alienation phenomenon.19,49 This situation primarily stems from the elderly often not receiving sufficient training during conventional education to enhance their abilities to use digital tools such as computers or smartphones, affecting their skills in searching for information, conducting e-commerce, online banking, handling administrative tasks, and using social networks. The Internet usage ability of the older population is a quality guarantee for accessing digital information;50,51 therefore, in the parallel phase of digitalization and aging society, improving the digital technological skills of the elderly is an important consideration in addressing the challenges of a digital society.
Fourthly, the COVID-19 pandemic has accelerated the digital transformation of society, which not only changed people's lifestyles but also expanded the market for digital technology applications. Especially for the middle-aged and elderly group, there was a significant change in the awareness of digital information technology and the use of applications related to daily life during the pandemic. 5 According to the NIA's report in 2023, during COVID-19, the elderly had paid more attention to the Internet and mobile technology, with a significant increase in their use of digital technology. 19 This indicates that the change in the social digital environment is also a key factor in predicting the digital information literacy of the elderly.
Additionally, we compared the differences in digital literacy between urban and rural populations. The results indicated that urban residents exhibit significantly higher levels of digital literacy compared with their rural counterparts. This finding may be attributed to the availability of educational resources, the prevalence of information technology, and the opportunities for exposure in urban areas. Urban regions typically have better network infrastructure and more opportunities for digital technology training, which may contribute to the superior performance of urban residents in digital literacy. This disparity could affect the ability of rural populations to access information, participate in social activities, and engage in economic activities, thereby exacerbating the digital divide.
Based on the analysis results, this study proposes a comprehensive approach to improve digital literacy among the elderly, considering education and training, social relationship support, social participation, technical support, and policy formulation.
Firstly, to enhance the elderly's individual technical skills, specifically designed digital literacy courses should be developed. These courses should cover smartphone applications, computer operations, Internet usage, and security measures. The content should be presented in simple, understandable language and involve practical, hands-on methods, enabling the elderly to effectively grasp and apply these skills. Secondly, in terms of social relationship support, family members and friends should be encouraged to actively participate in the elderly's digital learning process. Community organizations and nonprofit institutions should offer specialized digital education programs for the elderly, organize digital technology study groups, and establish volunteer service teams. Young people or technology enthusiasts can provide regular one-on-one technical guidance, helping the elderly solve specific problems and enhancing their digital skills and confidence. Thirdly, from the perspective of social participation, relevant departments should engage in activities aimed at improving digital literacy among the elderly. This includes offering free training courses, developing applications and services tailored for the elderly, and emphasizing the usability and safety of these products during promotion. Additionally, traditional media and social media should be used to publicize the positive impact of digital technology on the quality of life of the elderly, motivating more elderly individuals to try and learn new digital skills. Fourthly, in terms of technical support, electronic devices designed specifically for the elderly should be developed and promoted. These devices should feature large fonts, simplified interfaces, and easy-to-use characteristics. Dedicated technical support hotlines or online help services should be provided to promptly address any issues the elderly encounter while using digital devices and the Internet. Based on feedback from the elderly, digital products and services should be continuously improved and optimized to better meet their needs and enhance their user experience. Finally, the government should formulate differentiated policies to address urban–rural disparities. For urban areas, policy support and financial investment should be used to promote the development and sharing of public digital education resources and to enhance the digitalization of public services. For rural areas, infrastructure investment should be increased to ensure widespread network coverage and access, and financial subsidies should be provided to help rural residents purchase necessary digital devices and participate in training.
Through these comprehensive strategies, the elderly will be better equipped to adapt to the digital environment, improve their digital literacy, enhance their sense of participation and well-being in the digital society, narrow the digital divide, and achieve broader social inclusion.
Conclusion
The implications of this study are as follows. From an academic perspective, the research results demonstrate the effectiveness of machine learning techniques, particularly ensemble learning algorithms, in predicting factors influencing the digital literacy levels of elderly. By combining XGBoost feature importance and SHAP value analysis, this study reveals the significant impact of key features on model predictions. This comprehensive analysis not only enhances the transparency of the model but also provides important insights for subsequent feature engineering and model optimization. Compared with previous research, the ensemble learning algorithms employed in this study exhibit remarkable performance, achieving a classification accuracy exceeding 80%, highlighting a significant advantage over traditional methods. Furthermore, the analysis of variable importance confirms that age, income, occupation, educational background, and individual technological proficiency are crucial factors influencing the digital literacy of elderly. In addition, the study identifies relational support and the social digital environment as predictive factors of digital literacy levels among the elderly. This finding aligns with existing structural equation model research, further validating the application effectiveness of ensemble learning techniques in this research domain. Lastly, the developed and optimized ensemble learning model in this study demonstrates potential for broader application in similar research across other fields, showcasing its theoretical value in practical applications.
The practical significance of this study lies in the targeted intervention recommendations based on the research findings. These recommendations encompass educational training, technical support, policy formulation, and social engagement to enhance the digital literacy of the elderly and bridge the digital divide. These suggestions can provide data support and scientific evidence for governments and relevant institutions to formulate policies, thereby promoting the development of digital literacy education programs and infrastructure for the elderly. Additionally, in the process of enhancing digital literacy among the elderly, this study recommends going beyond a single demographic perspective and individual skill enhancement. It emphasizes the impact of relational support and rapid digital transformation on the digital literacy of the elderly. Furthermore, the study's results indicate that urban populations exhibit significantly higher digital literacy levels compared with rural populations, reflecting an imbalance in the development of digital literacy between urban and rural areas. The overall advantage of urban residents highlights disparities in the dissemination of information technology and educational resources between urban and rural regions. This finding is significant for policymakers, underscoring the need to take measures to reduce the digital divide, improve the digital literacy of rural populations, and promote integrated urban–rural development.
This study has certain limitations and suggests future research directions. Firstly, the study relies on qualitative variables in the database to predict factors influencing the digital literacy of the elderly, which constrains our ability to confirm causal relationships between variables. Future research should adopt longitudinal methods to clarify the causal relationships between these variables. Secondly, the current study focuses on the elderly population without comparing it with other age groups. Subsequent research needs to explore the differences in digital literacy across different generations to comprehensively understand the digital literacy performance and needs of various age groups. Lastly, future research should further investigate the specific factors affecting the digital literacy gap between urban and rural areas, such as education, economic conditions, and social support, to develop more targeted policy measures that help rural populations better adapt to the digital age.
Footnotes
Acknowledgments
All authors would like to thank the NIA, which provided the data.
Contributorship
KH and WX conceived and designed the study; KH developed the methodology; WX acquired the data; KH and WX analyzed and interpreted the data; KH and WX wrote, reviewed, and revised the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
Ethical approval was not required as this study data are open-sourced, and the original research has already been conducted.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported in part by the Postgraduate Education Reform and Quality Improvement Project of Henan Province (YJS2022JD30).
Guarantor
XW.