
Abstract
Artificial intelligence is steadily permeating various sectors, including healthcare. This research specifically addresses lung cancer, the world's deadliest disease with the highest mortality rate. Two primary factors contribute to its onset: genetic predisposition and environmental factors, such as smoking and exposure to pollutants. Recognizing the need for more effective diagnosis techniques, our study embarked on devising a machine learning strategy tailored to boost precision in lung cancer detection. Our aim was to devise a diagnostic method that is both less invasive and cost-effective. To this end, we proposed four methods, benchmarking them against prevalent techniques using a universally recognized dataset from Kaggle. Among our methods, one emerged as particularly promising, outperforming the competition in accuracy, precision and sensitivity. This method utilized hyperparameter tuning, focusing on the Gamma and C parameters, which were set at a value of 10. These parameters influence kernel width and regularization strength, respectively. As a result, we achieved an accuracy of 99.16%, a precision of 98% and a sensitivity rate of 100%. In conclusion, our enhanced prediction mechanism has proven to surpass traditional and contemporary strategies in lung cancer detection.
Keywords
Introduction
The human body is made up of trillions of cells, which typically grow and transform themselves into new cells through cell division over time. During this process, cells become old and damaged, with damaged cells replaced by new ones. However, this process can become ineffective, leading to the unchecked growth of damaged or abnormal cells, which can be either cancerous or non-cancerous (benign). 1 Damaged cells may affect nearby body tissues and have the potential to spread to other parts of the body, forming additional tumors through a process called metastasis. 2
As previously explained, lung cancer is primarily a genetic disease. 3 However, external factors such as smoking tobacco, exposure to passive smoking and toxic gases, as well as polluted air, can also contribute to its development.4,5 These factors disrupt the cell division process and promote the exponential growth of damaged cells that would typically die or stop growing, ultimately leading to the formation of cancerous tumors.
Lung cancer is among the most prevalent and deadly malignancies globally. According to statistics from the World Health Organization, out of the 10 million cancer cases registered in 2020, almost 2.21 million were lung cancer cases. 6 Approximately 1.8 million people die from lung cancer annually, making it the leading cause of cancer-related deaths. Lung cancer has four stages; while detection at stages 1 and 2 is curable, these stages typically show no symptoms. Symptoms usually manifest in stages 3 and 4, which are extremely dangerous. Malignant cancer in these stages spreads rapidly and damages nearby tissues and organs, while benign tumors grow slowly and can be removed through surgery, therapy or other techniques.
The challenge lies in the early detection of lung cancer, as it often goes undetected during its initial stages, resulting in low survival rates. Currently, paramedics and doctors employ various diagnostic methods, including mammography, CT scans and MRI images. Anti-cancer treatments utilize a range of techniques, including laser surgery, radiation, chemical alterations and transplantation. However, these methods are costly, time-consuming and cumbersome. 7
Early identification is crucial for improving the chances of survival among lung cancer patients. Machine learning (ML) techniques hold the key to maximizing survival rates in this and other medical research areas. Various ML algorithms are applied in this study for the early diagnosis of lung cancer. 8 Furthermore, this study improves the performance of ML algorithms over previous studies by incorporating additional characteristics and parameters into the dataset. The four ML algorithms used in this study are extreme gradient boosting (XGB), support vector machine (SVM), decision tree (DT) and linear regression (LR). These models were selected based on a comprehensive literature review, demonstrating strong performance in terms of accuracy and precision.
The subsequent section of this paper examines several studies aimed at early stage lung cancer detection using different ML models on diverse datasets collected and uploaded to public repositories. The remaining blank area represents the prediction rate, which can be true positive (TP), true negative (TN), false positive (FP) or false negative (FN). The accuracy of a model's predictions, distinguishing between true and false positives and negatives, largely depends on the prediction rate.
The focus of this study is to detect lung cancer using ML techniques, employing SVM, XGB, DT and LR models. While relevant literature was reviewed for this research, the primary focus was on improving precision, accuracy and the F1-score. The results of this study show greater promise compared to previous studies discussed in the subsequent section.
The following sections of this article cover a variety of topics. The second section 2 provides a comprehensive literature review. The third section briefly introduces the dataset, preprocessing methods, techniques used and evaluation metrics. The fourth section analyzes the results and compares them with current publications. Finally, the fifth section concludes the article and outlines potential future directions.
Related works
The existing literature on lung cancer detection and classification offers a range of methodologies and findings. Several factors contribute to tumor development, including genetic inheritance, smoking, and alcohol consumption. Various techniques, such as narrow-band imaging (NBI) and broncho-over-white light (WL), have been utilized for the analysis of lung cancer, with NBI being recognized for its higher accuracy in early-stage detection. 9
Mamun et al. 10 explored ensemble learning methods, including XGB and light gradient boosting machines (LightGBM), for lung cancer classification, employing an oversampling technique, SMOTE, for enhanced results. This study introduces new ensemble learning models developed based on a survey dataset of 309 individuals with or without lung cancer. The results indicate that the XGBoost (XGB) ensemble learning technique outperformed other methods, achieving an accuracy of 94.42%, precision of 95.66%, recall of 94.46%, F1-score of 94.74% and an area under the curve (AUC) of 98.14%.
Similarly, Aljabar et al. 11 used the eXtreme Gradient Boost machine learning model to process a compiled dataset of diverse lung cancer types, showing improved performance in comparison to other models. This study utilizes gene expression and transcriptome data, specifically from real new generation RNA_seq (NGS) and microarray datasets. The results of the study demonstrate the effectiveness of the XGB model in improving the prediction of lung cancer diagnosis, detection, and relapse.
Multiple studies have utilized various ML models, such as SVM, K-nearest neighbors (KNN) and convolutional neural networks (CNN), for analyzing CT scans and other datasets for efficient and accurate lung cancer classification, each offering unique insights into model accuracy and performance.12–19
Significant efforts have been invested in enhancing lung cancer detection through innovative methods. A study employing a device named e-nose used exhaled breath samples for classifying lung cancer, asthma and COPD, offering promising yet improvable results. 16 Deep learning applied to chest X-ray films, as conducted by Ausawalaithong et al., 17 demonstrated the potential of ML algorithms in cancer detection. Various ML models, including gradient boosting machines (GBM) and custom ensembles, were analyzed for their efficacy in lung cancer detection based on diverse features, underscoring the supremacy of GBM. 18
Studies have also focused on early-stage lung tumor detection, using models such as SVM and CNN to achieve high accuracy. 19 El Guabassi et al. have explored and discussed the employment of artificial intelligence in lung cancer detection, showcasing a comparative analysis of various ML models for enhanced cancer detection. 20 This study integrates AI techniques, specifically artificial neural networks (ANN), Naive Bayes (NB), KNN, SVM, DT and LR, for the early diagnosis and prediction of lung cancer. This result indicated that SVM achieves a high prediction accuracy of 94.6% and has the potential to automatically predict lung cancer with a high degree of accuracy, highlighting its robustness in this particular medical application.
Early detection of lung cancer has been addressed by Abdullah et al., 21 who investigate and identify the most effective classifier among SVM, KNN and CNN for early detection, ultimately aiming to contribute to the improvement of prognosis and outcomes for patients with lung cancer. The proposed solution involves applying SVM, KNN and CNN to datasets obtained from the UCI ML repository, which contain information about patients affected by lung cancer. The use of these classifiers is facilitated by the WEKA tool. The experimental results indicate that SVM outperforms the other classifiers with an accuracy of 95.56%. CNN follows with an accuracy of 92.11%, while KNN achieves an accuracy of 88.40%.
Pradhan et al.'s goal is to improve lung cancer classification accuracy using an ensemble learning model, ultimately aiding in early diagnosis and treatment. 22 The author of this study combined ensemble learning with recurrent neural networks (RNN) and the best fitness-based squirrel search algorithm (BF-SSA) feature extraction method to address time and memory complexities and a commitment to achieving higher accuracy in practical applications. The datasets used were gathered from Kaggle and the UCI repository with 7 attributes and 56 attributes, respectively. The accuracy, precision, F1-score and recall of the proposed model are above 92% for both datasets, which shows better than CNN, neural network (NN), RNN, 5LEVEL-RNN and Self-Adaptive-Sea Lion Optimization-Recurrent Neural Networks (SA-SLnO-RNN) algorithms on lung disease diagnosis.
Yamini et al. investigate and test ML approaches for early detection and intervention, potentially saving lives in the face of the lung cancer epidemic. 23 This study proposed the LR, DT, RF, SVM, XGB classifier, gradient boosting and KNN to analyze lung cancer data. It offers insights into the performance of different ML models in the context of lung cancer prediction. The dataset contains a total of 16 variables, 15 of which are input variables and one of which is a class label. The results of the research indicate that the XGB classifier outperforms other ML models such as LR, DT, RF, SVM, gradient boosting and KNN in terms of accuracy when predicting lung cancer. In addition, the accuracy, precision, F1-score and recall of the proposed XGB classifier are 99.1%, 100.0%, 99.0% and 98.0%, respectively.
Singh et al. enhance the diagnosis and early detection of lung cancer, a highly fatal disease with challenging characteristics, through the application of ML techniques such as RF, XGB, DT, AdaB, SVM, GBM, LightGBM and Cat Boost. 24 This study focuses on improving and evaluating the classifier learning systems’ accuracy using specific models, with AdaBoost and XGB identified as top performers. Two datasets were used and gathered from Kaggle: the first dataset contains 309 records and 16 attributes and the second dataset contains 1000 records and 24 attributes. The results highlight the superior performance of the AdaB and XGB models, with accuracy rates of 96.77% and 96.75%, respectively.
Addressing the critical issue of early lung cancer diagnosis, the literature reveals extensive use of ML models optimized with diverse hyperparameters and datasets for enhanced prediction and classification results.25–31 Despite achieving commendable accuracy in lung cancer detection, continuous efforts are being made to improve these figures to reduce the chances of false negative or false positive detections, as highlighted in various studies.32,33 The exploration and application of numerous ML models, from ensemble learning methods to deep learning, underscore the ongoing pursuit of enhancing lung cancer detection and classification.
To enhance the effectiveness of lung cancer diagnosis, this study, inspired by prior research, employed similar ML models, including SVM, XGB, LR and DT, with a focus on optimizing the accuracy of each model individually. The goal of convergence toward 100% accuracy aims to minimize the possibility of erroneous lung cancer detection in patients. This endeavor has resulted in achieving more accurate and reliable results based on essential metrics such as precision, accuracy and F1-score.
Recent studies further expand on this pursuit. Alsinglai et al. introduced a framework for managing lung cancer patients with imbalanced datasets, employing models like XGB, LR and random forest (RF) and achieving an impressive accuracy of 98% with RF. 34 Other studies have explored the usage of AdaBoost and CNN on CT scan images, reporting significant improvements in accuracy, 35 and diverse ML models with Chi-square for feature selection, also reporting enhanced results. 36 The evaluation and comparison of various ML models on extensive datasets have consistently highlighted the potential of AdaBoost to outperform other models with high accuracy and AUC. 37
In the quest for optimizing lung cancer prognosis, studies like that of Wu et al. have adopted cost-effective and efficient methods, such as blood tests, to employ ML models like RF for accurate lung cancer detection, achieving remarkable results in terms of accuracy, recall and AUC. 38
The extensive datasets used in the research mentioned above, ranging from the Kaggle dataset to the Lanzhou University dataset, highlight the diverse sources for obtaining reliable and comprehensive data for enhancing lung cancer prediction and classification.10,12,19,20,31,34,36–38
In conclusion, the comprehensive literature review underscores the extensive and varied research conducted in the field of lung cancer detection and classification. Despite the impressive results achieved by numerous studies, the perpetual quest for enhancing accuracy and reducing errors remains paramount. This study aims to significantly contribute to this ongoing pursuit, providing valuable insights and findings that potentially augment the body of knowledge in this critical healthcare domain. A concise overview of the datasets, models, and results from selected related research studies is shown in Table 1.
Synthesis and summary of the selected related work.

Methods
Dataset
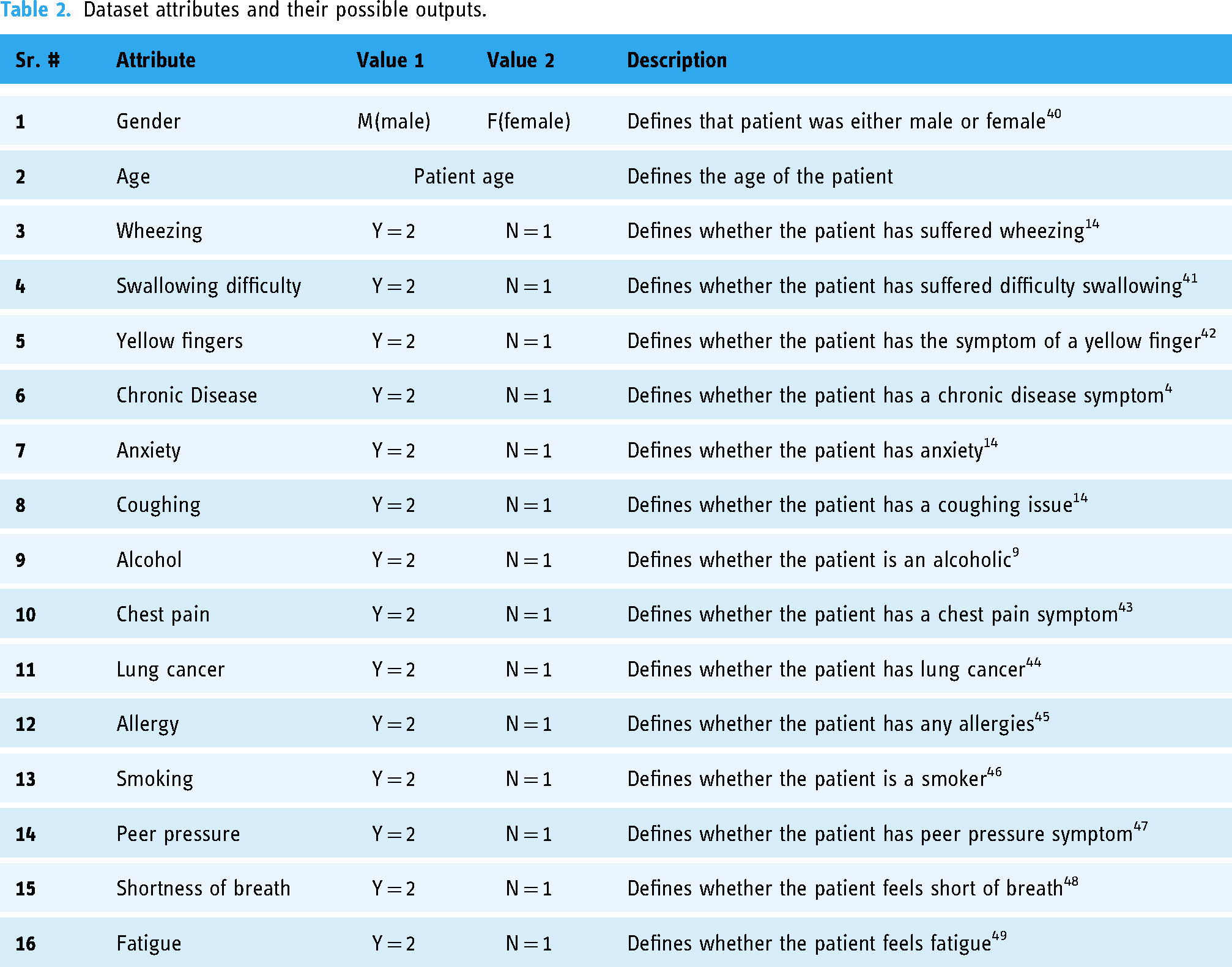
The dataset used for this research was taken from a public repository named Kaggle. 39 The data available in the dataset contained 309 entries and had a total of 16 attributes: 15 independent and 1 dependent, which are described in Table 2.
Dataset attributes and their possible outputs.
Preprocessing
Appropriately preprocessing the data before feeding it into the proposed methods can significantly improve their performance. Figure 1 illustrates the distribution of cancerous and non-cancerous cases across different age groups. The total number of cases is represented in blue, with cancerous cases in orange and non-cancerous cases in gray. It is notable that the majority of lung cancer cases occur within the age bracket of 50–70 years, with significantly fewer cases below 50 and above 70.

Number of lung cancers versus different age groups.
In this research, we proposed four methods: SVM, DT, LR and XGB. Our proposed SVM and LR methods require normalization (converting categorical to numeric data) or scaling of input data. SVM, in particular, is sensitive to the scale of the input features as it seeks to maximize the margin between classes, leading to biased models with upscaled data. Similarly, LR is sensitive to input feature scaling as it aims to fit a linear decision boundary between classes. Conversely, our proposed DT and XGB methods are not sensitive to input feature scaling and do not require normalization or scaling. Consequently, several preprocessing operations were carried out, including converting strings to numeric values, removing duplicates, implementing random oversampling for data balancing and scaling values between 0 and 1 before model training, to ensure compatibility with our proposed methods.
Following the preprocessing step, the dataset was divided into two sets: a training dataset and a testing dataset. The split was determined using the “train_test_split” method, with a parameter for “random_state” to ensure reproducibility, resulting in a 75% and 25% split.
Proposed methods
Figure 2 illustrates the block diagram of our proposed methodology. Drawing from thorough research, we designed and tested four proposed methods using a standard lung cancer dataset. The methods we selected include SVM, DT, XGB, and logistic regression (LR). Each of these models was improvised and trained using both default and tuned parameters.

Block diagram of our proposed methodology (a) overview; (b) SVM; (c) XGB; (d) Logistic regression; (e) DT.
ML models serve as invaluable assets in addressing complex challenges across various domains. Each model is characterized by a unique suite of hyperparameters, and these parameters play a pivotal role in shaping the model's performance and accuracy. To optimize these parameters, we employed the ParameterGrid method, allowing us to explore a range of parameter values beyond the defaults. Initially, we trialed single values to discern the optimal range, establishing these ranges by considering the extreme values for each parameter. From this analysis, the ParameterGrid was crafted—a grid designed to methodically assess each model autonomously, ensuring superior results. This fine-tuning phase was integral to our research, as it markedly enhanced the outcomes of our models. After this optimization process, we identified the fine-tuned parameters for each method, which are detailed as follows:
The proposed SVM method
Figure 3 illustrates the structure of the proposed SVM method. Our method comprises 16 variables, with 15 independent attributes as input data and 1 dependent attribute as classified output (see Figure 2(b)). These variables connect to a hidden layer, either from the input or output side. Notably, the method self-determines the number of hidden layers based on the input, with hyperparameters provided as function arguments. To achieve the objective of classifying a tumor as malignant (cancerous) or benign (non-cancerous), we adjust the values of the hyperparameters gamma and C. Figure 2(b) illustrates the bidirectional relationship between the inputs and outputs of each layer. Every layer communicates with both its preceding and succeeding layers, ensuring the accuracy of predictions. If inaccuracies are detected in the predictions of subsequent layers, parameters are adjusted iteratively to achieve a finely-tuned and precise result. This iterative process involves generating an output, applying hyperparameters, storing the modified output, and comparing the two. The superior output, in terms of accuracy, is recognized as the “tuned” output.

The proposed SVM method.
The proposed SVM method in this case involves a minor change in terms of optimization: hyperparameter tuning. The parameters were selected from a pre-defined range of values, and the mathematics behind the hyperparameter tuning and optimization are as follows:
Kernel selection: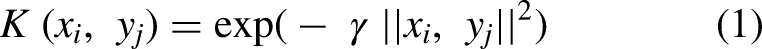

Our proposed SVM method employs the Gamma and C parameters to dictate the kernel width and regularization strength, respectively. Initially, both parameters are set at a default value of 1 and are of the float data type. While the C parameter can take any value, gamma is restricted to non-negative numbers. Our fine-tuned SVM parameters allow for improved adaptability to the dataset and problem at hand. In some cases, default SVM parameters may not yield optimal results, and our approach ensures better generalization and performance.
The proposed XGB method
The proposed XGB method employed the “n_estimators” and “learning_rate” parameters to regulate the number of DT and the optimization step size.
50
Additionally, default parameter values were set to 100 and 0.1, with data types of integer and float, respectively. “N_estimators” can range between 1 and positive infinity; however, “learning_rate” may vary between 0.0 and positive infinity. As XGB operates on multiple trees, depicted in Figure 2(c), the depth of these trees, denoted as levels such as “l1” and “l2,” is solely determined by the model's complexity required to attain maximum accuracy. The predicted outcomes from each tree are then aggregated with the associated detection error Y (see Figure 2(c), where Y is a small error generated by each tree and X is a variable to identify the error produced by each tree while predicting). Collectively, these results are utilized to classify whether the provided data pertains to a cancerous or non-cancerous nature. Consequently, the aforementioned parameters were adjusted to seek the optimal solution for detection. Tuning these parameters involves striking the right balance between model complexity (controlled by the n_estimator) and regularization (controlled by the learning rate). The parameters were selected from a pre-defined range of values, and the mathematics running behind the hyperparameter tuning and optimization are as follows: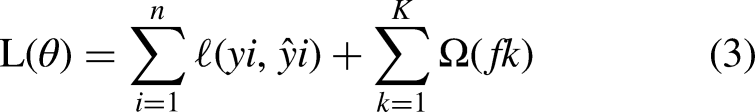

The proposed dt method
The proposed DT method utilized “random_state,” “min_weight_fraction_leaf” and “class_weight” parameters for controlling reproducibility, the minimum fraction of input samples required at a leaf node, and the weight of classes. In addition to this, the default parameter values are “None,” 0.0, and 1 with the data types of integer, float and float, respectively. It operates based on the number of input parameters needed to make decisions under given conditions. Beginning with the decision node (refer to Figure 2(e)), which lacks a definitive output classifiable as positive or negative, the process continues to delve deeper into subsequent decision nodes until a decision is reached at the leaf node. Parameters were tuned to ensure consistent and reproducible results; the splits are determined by impurity or entropy, along with class weights for dataset balancing.
“Min_weight_fraction_leaf” can be any float number; however, “class_weight” can be any fractional number, for example, [{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}]. The parameters were selected from a pre-defined range of values, and the mathematics running behind the hyperparameter tuning and optimization are as follows:
The objective is to find the optimal parameters θ that minimize the impurity or mean square error.


The proposed LR method
The proposed LR method utilized “C” and “max_iter” parameters for controlling regularization strength and the maximum number of iterations for the solver to converge. In addition to this, the default parameter values are 1 and 50 with the data types of float and integer, respectively. “C” must be any positive float number, and “max_iter” can be any positive number. By adjusting the “C” and “max_iter” parameters, our LR model can better handle the trade-off between regularization and fitting the data, potentially enhancing its predictive performance compared to using default parameter values and existing techniques. Figure 2(d) illustrates the input and assigns probabilities to each input. Subsequently, all inputs undergo a sigmoid function, yielding values ranging from 0.1 to 0.9 as probabilities. The process then assesses whether the probability surpasses the threshold value of 0.5; if so, it is classified into one class, whereas if it falls below 0.5, it is assigned to another class.
Evaluation
In this study, five metrics were used to evaluate our proposed methods: accuracy, precision, sensitivity, F1-score and area under the curve (AUC). Each metric was computed using the elements in a confusion matrix: TP, TN, FP and FN.
Accuracy measures the performance of the classification activity and the number of correctly predicted cases. It is calculated as follows: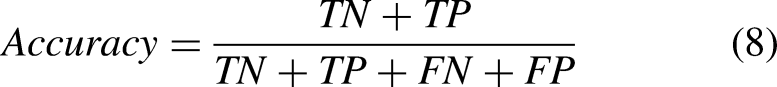
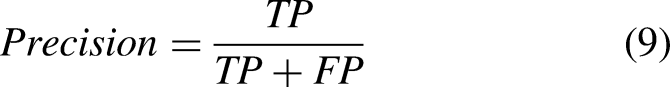


Experiments
To evaluate the effectiveness of the proposed methods, a simulation was conducted to predict lung cancer cases using 309 entries from the Kaggle dataset. The evaluation of the proposed models was based on four performance metrics: accuracy, precision, sensitivity and F1-score (as discussed in the Evaluation section). The simulation process also compared the performance before and after fine-tuning the hyperparameters for each method, utilizing 15 dependent attributes and 1 independent attribute (see Table 2) for training. The parameters were set for each proposed method as follows:
The proposed SVM method: A range of values was provided to the “ParameterGrid” method, with the optimal values for Gamma and C found to be 1. The proposed XGB method: An array of different values was passed as arguments to the “ParameterGrid” method, and the most feasible parameter values for “n_estimator” and “learning_rate” were determined to be 250 and 0.001, respectively. The proposed DT method: An array of different values was passed as arguments to the “ParameterGrid” method, and the most feasible parameter values for “random_state,” “min_weight_fraction_leaf” and “class_weight” were determined to be 90, 0.002 and “None,” respectively. The proposed LR method: An array of different values was passed as arguments to the “ParameterGrid” method, and the most feasible parameter values for “C” and “max_iter” were determined to be 100 and 50, respectively.
Results and discussion
Results were gathered in two phases: first, after training with default parameters, and second, after hyperparameter tuning. Both sets of results were compared, and the best outcomes were considered to conclude this research at this stage. Figure 4 displays the results for both pre- and post-hyperparameter optimization, showcasing the accuracy, precision, sensitivity and F1-score for the proposed methods.

Pre- and post-hyperparameter optimization results comparison.
The accuracy, precision, sensitivity and F1-score for each of the proposed models improved after fine-tuning the hyperparameters, with the exception of the precision of the proposed DT method, which decreased by 4%, and the sensitivity and F1-score of the proposed XGB method, which remained unchanged. Additionally, the F1-score of the proposed DT and LR decreased by 1%. Among these models, the proposed SVM method demonstrated the most significant improvement after hyperparameter fine-tuning, while the proposed XGB, DT and LR methods showed lesser improvement. Specifically, the accuracy, precision, sensitivity and F1-score results of the proposed SVM method improved by 13.45%, 13.0%, 10.0% and 7.0%, respectively. These results indicate that the proposed SVM method exhibits greater capability in detecting lung cancer cases after fine-tuning the hyperparameters.
Table 3 presents the results of accuracy, precision, sensitivity, and area under the curve (AUC) for the four proposed methods for detecting lung cancer. The proposed SVM method achieved the highest accuracy of 99.16%, precision of 98%, sensitivity of 100%, F1-score of 99% and AUC of 0.992. For XGB, DT and LR, the accuracy results are 94.16%, 94.12% and 91.06%, respectively. The precision results for XGB, DT and LR are 91%, 88% and 88%, respectively. The sensitivity results for XGB, DT and LR are 100%, 100% and 97%, respectively. The F1-score results for XGB, DT and LR are 95%, 94% and 92%, respectively. Additionally, the AUC results for XGB, DT and LR are 0.949, 0.941 and 0.916, respectively. These findings suggest that the proposed SVM method outperforms the other methods in detecting lung cancer.
Results for proposed methods for detecting lung cancer.
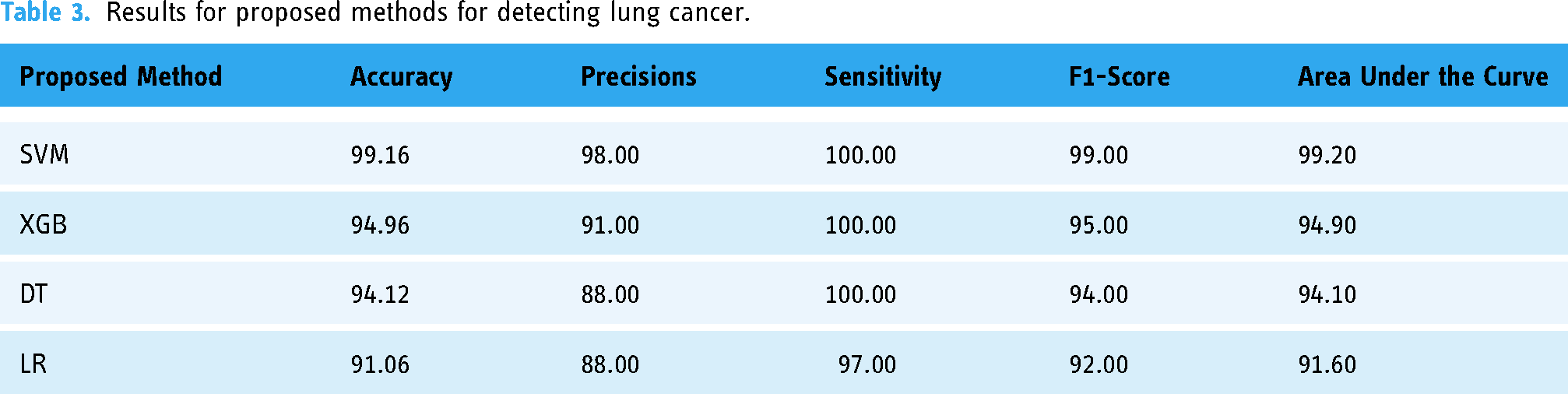
Table 4 displays the confusion matrix results for the proposed methods. The proposed SVM method exhibits the highest numbers of TP and TN, with the lowest counts of FN and FP compared to the other three methods. Conversely, the proposed LR method has the lowest TP and TN numbers, with the highest FN and FP counts among the proposed methods. This indicates that SVM demonstrates a higher number of correct predictions and a lower number of erroneous predictions compared to the other methods.
Confusion matrix results for the proposed methods.

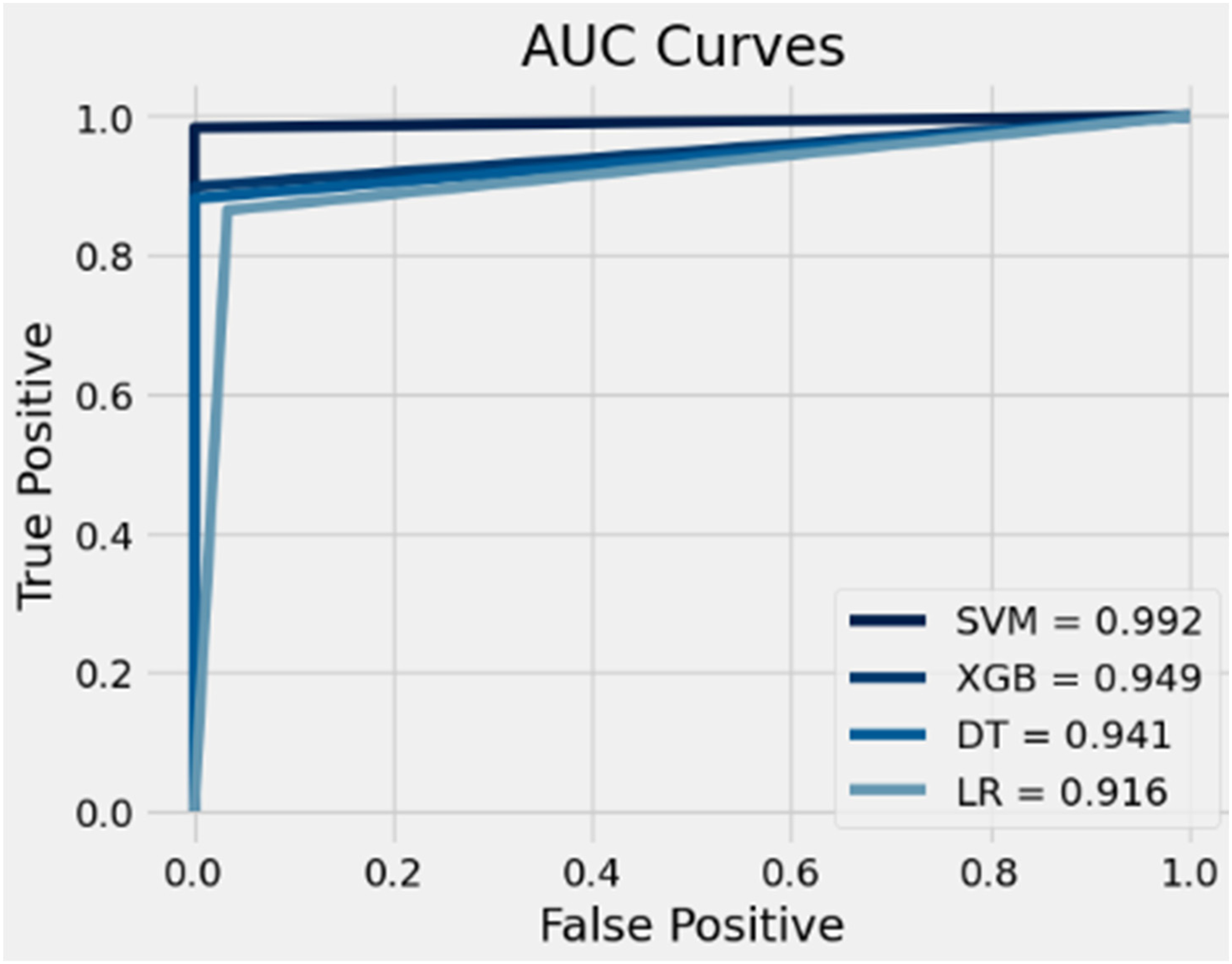
The results of the AUC for the proposed methods are depicted in Figure 5. Generally, all the proposed methods exhibit AUC values exceeding 0.9. Specifically, our proposed SVM method achieved the highest AUC value (0.992), followed by our proposed XGB method (0.949), our proposed DT method (0.941) and our proposed LR method (0.916), respectively. These findings indicate that the higher the AUC value, the better the performance of our proposed method in distinguishing between the positive and negative classes.
AUC results for the proposed methods.
Comparison with previous work
Mamun et al., 10 Dritsas et al. 32 and Vieira et al. 33 were selected as the related works for comparison with our proposed methods. We chose them to ensure a fair comparison, as they employ similar ML models and the same dataset as ours. Table 5 presents the comparison results among our proposed methods and the selected related works. From the table, it is evident that the accuracy of our proposed SVM, XGB and DT methods has improved by 3.76%, 0.54% and 0.82%, respectively, compared to the other related works. The sensitivity/recall results of our proposed SVM, XGB and DT methods all achieved 100%, indicating improvements of 4.6%, 5.54% and 5.0%, respectively. Regarding precision, our proposed SVM method achieved 98%, outperforming the other selected related works. As for our proposed LR method, it achieved accuracy, sensitivity and precision results of 91.6%, 97% and 88%, respectively. Based on these results, we can conclude that our proposed SVM method demonstrates superior performance in detecting lung cancer compared to the other selected related works.
Comparison table of the proposed methods with the selected related works.

Conclusion and future work
Lung cancer, recognized by the World Health Organization (WHO) as the leading cause of cancer-related deaths, remains a significant global health challenge.41–50 Early detection can critically enhance survival rates and improve patient outcomes. To address this, our study investigated the potential of ML for the early diagnosis of lung cancer.
Drawing from extensive research, we crafted and evaluated four proposed methods using a dedicated lung cancer dataset. Given the dataset's unbalanced nature, we applied random oversampling to ensure appropriate weighting.
Among our approaches, one stood out, showcasing an impressive accuracy of 99.16%, precision of 98%, recall of 100%, an F1-Score of 99% and an AUC of 99.2%. One of the main reasons our proposed method outperformed others is that we utilized hyperparameter tuning, focusing on the Gamma and C parameters, which were set at a value of 10. These parameters influence kernel width and regularization strength, respectively.
While these results are promising, one must note the limitations of our dataset's size. Exploring larger datasets in the future might provide more comprehensive and generalizable insights. Our next steps involve either delving into more extensive datasets or redirecting our focus toward harnessing ML for detecting other diseases, all in a bid to make significant contributions to global health.
Footnotes
Acknowledgements
None.
Contributorship
Syed Muhammad Nabeel contributed to conceptualization, investigation, data curation, writing—original draft preparation, writing—review and editing, visualization, supervision, and project administration. Sibghat Ullah Bazai contributed to conceptualization, investigation, data curation, writing—original draft preparation, writing—review and editing, supervision, project administration. Nada Alasbali contributed to methodology, software, resources, writing—original draft preparation, and funding acquisition. Yifan Liu contributed to data curation and formal analysis. Muhammad Imran Ghafoor contributed to software and formal analysis. Rozi Khan contributed to software, formal analysis, and funding acquisition. Chin Soon Ku contributed to validation, writing—review and editing and funding acquisition. Jing Yang contributed to data curation, writing—review and editing, project administration. Sana Shahab contributed to formal analysis, resources, writing—review and editing and funding acquisition. Lip Yee Por contributed to writing—review and editing and funding acquisition. All authors have read and agreed to the published version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
Ethical approval was not required for this study, as we analyzed publicly available data that was not collected from human subjects but from publicly available symptom checker apps.
Funding
The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through the large group research project under grant number RGP.2/550/44. This research was also supported by the KW IPPP (Research Maintenance Fee) Individual/Centre/Group (RMF1506-2021), Universiti Malaya, Malaysia, and the UTAR Financial Support for Journal Paper Publication Scheme through Universiti Tunku Abdul Rahman, Malaysia.
Guarantor
None.
Informed consent
A publicly available dataset from Kaggle was utilized. This dataset is detailed and has been recently used, making patient consent unnecessary