
Abstract
Background
Thrombolysis is the first-line treatment for patients with acute ischemic stroke. Previous studies leveraged machine learning to assist neurologists in selecting patients who could benefit the most from thrombolysis. However, when designing the algorithm, most of the previous algorithms traded interpretability for predictive power, making the algorithms hard to be trusted by neurologists and be used in real clinical practice.
Methods
Our proposed algorithm is an advanced version of classical k-nearest neighbors classification algorithm (KNN). We achieved high interpretability by changing the isotropy in feature space of classical KNN. We leveraged a cohort of
Results
In terms of interpretability, only onset time, diabetes, and baseline National Institutes of Health Stroke Scale (NIHSS) were statistically significant and their contributions to the final prediction were forced to be proportional to their feature importance values by the rescaling formula we defined. In terms of predictive power, our advanced KNN (AUC 0.88) outperformed the classical KNN (AUC 0.75,
Conclusions
Our preliminary results show that the advanced KNN achieved high AUC and identified consistent significant clinical features as previous clinical trials/observational studies did. This model shows the potential to assist in thrombolysis patient selection for improving the successful rate of thrombolysis.
Background
Stroke is the third leading cause of death and chronic disability globally. 1 As a leading cause of adult disability, up to 74% of stroke survivors are dependent on activities of daily living, 2 which causes a huge burden to the society. Among different types of strokes, ischemic stroke is the most common, accounting for 87% compared to hemorrhagic stroke. 3 In the treatment of ischemic stroke, thrombolysis is the first-line treatment. 4 For acute ischemic stroke patients, a prompt treatment with thrombolytic drugs could restore blood flow before major brain damage has occurred and greatly improve short-term and long-term recovery after stroke, 5 as a result largely reducing the burden stroke brings to the society.
In most cases, thrombolysis therapy is subject to the latest guidelines. The guidelines are drawn up based on the large quantities of clinical evidence, therefore, the proposed eligibility and dosage consideration for thrombolysis treatment should normally be safe and efficient for most of the patients. However, in clinical practice, still, a number of patients present unpredictable outcomes after thrombolysis treatment, including symptomatic hemorrhage (13% among patients receiving thrombolysis) 6 and failed recanalization (37% among patients receiving thrombolysis), 7 suggesting that a more accurate patient-tailored clinical decision support tool based on guidelines to improve thrombolysis safety and efficiency is needed.
Previous studies leveraged machine learning models to assist neurologists in deciding the safety and efficiency for each patient more accurately8–36: they all simply reused the existent machine learning algorithm and trained the algorithm based on their patient cohort to predict thrombolysis outcome. However, when reusing the current machine learning algorithms, there is always a trade-off between flexibility and interpretability 37 : Inflexible algorithms have a restrictive ability to estimate the boundaries between different outcome classes, therefore presenting lower predictive power. But inflexible algorithms are often easy to be interpreted. On the other hand, flexible algorithms generate more accurate predicted outcome but suffer from low interpretability. If we are only interested in predictive power and the interpretability of the predictive model is simply not of interest, more flexible algorithms would be a good choice. However, in some settings, if the importance of inference outweighs the predictive power, we should turn to a more restrictive method since it's quite easy to tell which predictors are the causes of algorithm decision or result.
In our case, to make the model be trusted by clinicians and eligible to assist in clinical practice, the interpretability of algorithm is critical since all clinical decision support tools must go through clinical validation to be approved by the local authority before being used in real clinical practice. The interpretability of the algorithm allows to tell which predictors the algorithm leverages as important factors to be considered when predicting the clinical outcome or deciding the thrombolysis eligibility. These predictors then need to be confirmed related to the clinical outcome of patients going through thrombolysis by previous clinical trials or following clinical trials in case that the algorithm generates new features during training. For instance, according to the current clinical evidence, stroke patients with a small infarct core but a large penumbra will benefit a lot from thrombolysis with minimal side effects. 38 As a result, a clinically significant algorithm should not only predict thrombolysis outcome with high discriminative ability, but also devotes more attention to the penumbra related features.
To further improve the performance of current algorithms and offer the new algorithm the possibility to be used in real clinical scenario, in this research article, we propose a newly developed algorithm that combines the interpretability of restrictive algorithm and the predictive power of flexible algorithm. Our preliminary results show that the new algorithm maintains the interpretability while improving predictive power when compared with other common machine learning algorithms.
The research article is organized as follows: In the Related works section, we summarize previous thrombolysis outcome prediction models in terms of algorithm flexibility and interpretability, compare previous works with our proposed algorithm, and illustrate the originality of our study. In the Methods section, we introduce in detail our algorithm design and the methodology we used to demonstrate that the algorithm can maintain the interpretability while improving predictive power. In the Results section, we show the results of exploratory data analysis and model validation. In the Discussion section, we interpret the results of model validation, compare our findings with early studies, explain the clinical significance, and discuss limitations as well as propose future directions for the study.
Related works
Of the many algorithms used by previous thrombolysis outcome prediction studies, some can generate more flexible decision boundaries, others can only generate restrictive decision boundaries. Table 1 in the Supplemental Material summarizes previous thrombolysis outcome prediction studies in terms of algorithm flexibility and interpretability. The algorithms used by previous research, from the most restrictive to the most flexible, were logistic regression,8,19–21,24,25,33,36 naïve Bayes classifier, 33 risk score,9,10,12–16,35 nomogram,22,23,28,30,31,34 tree-based machine learning models,29,33,36 support vector machine,11,17,29 and deep learning neural network.11,26,27,29,32,33
Characteristics of patients with low dosage (LD) and normal dosage (ND) at baseline in training and test datasets.

Note: Data are presented as mean ± SD or n(%). Clinical feature is considered significantly different in two groups LD and ND when its associated
BMI: body mass index; NIHSS: National Institutes of Health Stroke Scale.
Most of the previous studies preferred restrictive models (logistic regression, naïve Bayes classifier, risk score, nomogram, and tree-based machine learning models). For these restrictive models, feature importance can be inferred, respectively, through feature coefficients, difference of the feature likelihood between the two classes, point assignment of each feature, graphic preliminary score assigned to each feature and weight metric.
Regarding flexible algorithms, there are two common ways to increase the interpretability: (1) A reactive approach to calculate individual predictor importance using SHapley Additive exPlanations (SHAP) framework proposed by Lundberg and Lee in 2017. 39 (2) A proactive approach to increase model predictive power by boosting interpretability, where a very popular example is the attention mechanism introduced in 2014 40 to allow the deep learning neural network decoder to leverage the most relevant parts of the input vectors in a flexible manner. Most of the previous research adopting support vector machine and deep learning neural network didn’t infer feature importance. A research in 2012 11 leveraged the reactive approach to calculate the individual predictor importance from neural networks and support vector machines. The proactive approach is preferred when compared with the reactive approach since the former can not only boost interpretability but increase model predictive power at the same time.
In this research article, we adopted the proactive approach to increase the interpretability of k-nearest neighbors classification algorithm (KNN), a rather flexible machine learning model with nonlinear and non-smooth boundaries based on the local geometry of the distribution of the data on the feature hyperplane. Our proposed algorithm can not only predict the thrombolysis therapy outcome with high discriminative ability but also tell which clinical features are the key to a good outcome.
Methods
Algorithm design
Our algorithm is an advanced version of KNN. We here changed the isotropy in feature space of classical KNN and developed a new algorithm that maintains the interpretability of previous models while in the meantime improving the predictive power when compared with the existing algorithms.
KNN is an intuitive supervised machine learning algorithm where an object is classified by a plurality vote of its K neighbors, with K a positive integer calculated in the training process.
41
When implementing KNN, the first step is to transform each data point into a vector composed of the mathematical values of each of its features. The algorithm computes the distance between each data point (vector) and then finds the
In training phase, the following parameters need to be defined in algorithm input: the p -value threshold p to determine significant features, the set of hyperparameters
Let
Then the feature importance of each statistically significant feature in
Next SD along the feature axis for each significant feature in
The rescaled significant features are the input of the following KNN. In the KNN model training, we found the
Our advanced KNN algorithm improves greatly the interpretability of classical KNN: the
In testing phase, we first included features only statistically significant in training dataset, then rescaled the test data using the same formula, assuming that the test data share the same mean, SD, and importance value with the training data, and finally made prediction based on the nearest k points.
In Algorithm 1 and Algorithm 2 as available in the Supplemental Material, we also annotated each step with time complexity. In training algorithm,
Participants and clinical assessments
We leveraged a cohort with acute ischemic stroke undergoing thrombolysis, but without following endovascular thrombectomy, to prove that our new algorithm maintains the interpretability of previous models while in the meantime improving the predictive power when compared with existent algorithms. The data of cohort were collected from The First Affiliated Hospital of Xiamen University from November 2013 to May 2020. The patient consent is waived as the retrospective non-identifiable data were used. The approval number is SL-2020KY023-01.
The inclusion criteria were as follows: (1) diagnosis of early ischemic stroke; (2) thrombolysis treatment with intravenous recombinant tissue plasminogen activator; (3) age superior to 18; (4) completion of baseline National Institutes of Health Stroke Scale (NIHSS) assessments; and (5) completion of 3-month modified Rankin Scale (mRS). The exclusion criterion was endovascular thrombectomy treatment following thrombolysis treatment.
The following information was obtained from each patient's clinical profile, namely, general clinical information including age and sex, risk factors including cardioembolic risk factors, diabetes, hyperlipidemia and hypertension, baseline information including body mass index (BMI), onset time and baseline NIHSS. A patient was considered to have cardioembolic risk factors if chronic rheumatic heart disease (International Classification of Disease 10th Revision (ICD-10): I05-I09), or nonrheumatic mitral valve disorders (ICD-10: I34), or nonrheumatic aortic valve disorders (ICD-10: I35), or endocarditis, valve unspecified (ICD-10: I38), or atrial fibrillation and flutter (ICD-10: I48) were found in medical history.
Additionally, the thrombolysis dosage was recorded for treatment option definition and 3-month mRS was recorded for clinical outcome assessment definition. Two thrombolysis treatment options were available: a thrombolysis dosage
Statistical analysis
Analysis of variance (ANOVA) test with no assumption of equal variances and Fisher’s exact test were employed for statistical analysis on characteristics of patients at baseline in different groups (LD vs. ND; FO vs. UFO). A logistic regression with
Validation of the predictive models
The proposed algorithm was trained on training dataset and validated on the test dataset. Since the proposed model is an advanced version of classical KNN, the performance of proposed advanced KNN was tested in comparison with the performance of classical KNN. We also varied feature importance calculation hyperparameters to test their impact on algorithm discriminative ability while all other hyperparameters were held constant. The predictive power was assessed according to area under the receiver operating characteristic curve (AUC). Pairwise AUC comparisons between models were tested using bootstrap method, with 1000 bootstrap replicates. 42 Other classification metrics such as accuracy, precision, recall, and F1 score were also reported for reference.
Results
Exploratory data analysis
Initially
Before constructing the outcome prediction model, statistical correlation between treatment option and the other clinical features was first tested. Table 1 shows, respectively, characteristics of patients with LD and ND at baseline in training and test datasets. In training dataset, cardioembolic risk factors and baseline NIHSS were significantly different between LD and ND groups. In test dataset, significant differences were only evident for BMI. We then constructed a logistic regression on training dataset to test the correlation between treatment option and the other clinical features. The estimated coefficients and associated
The coefficient and associated
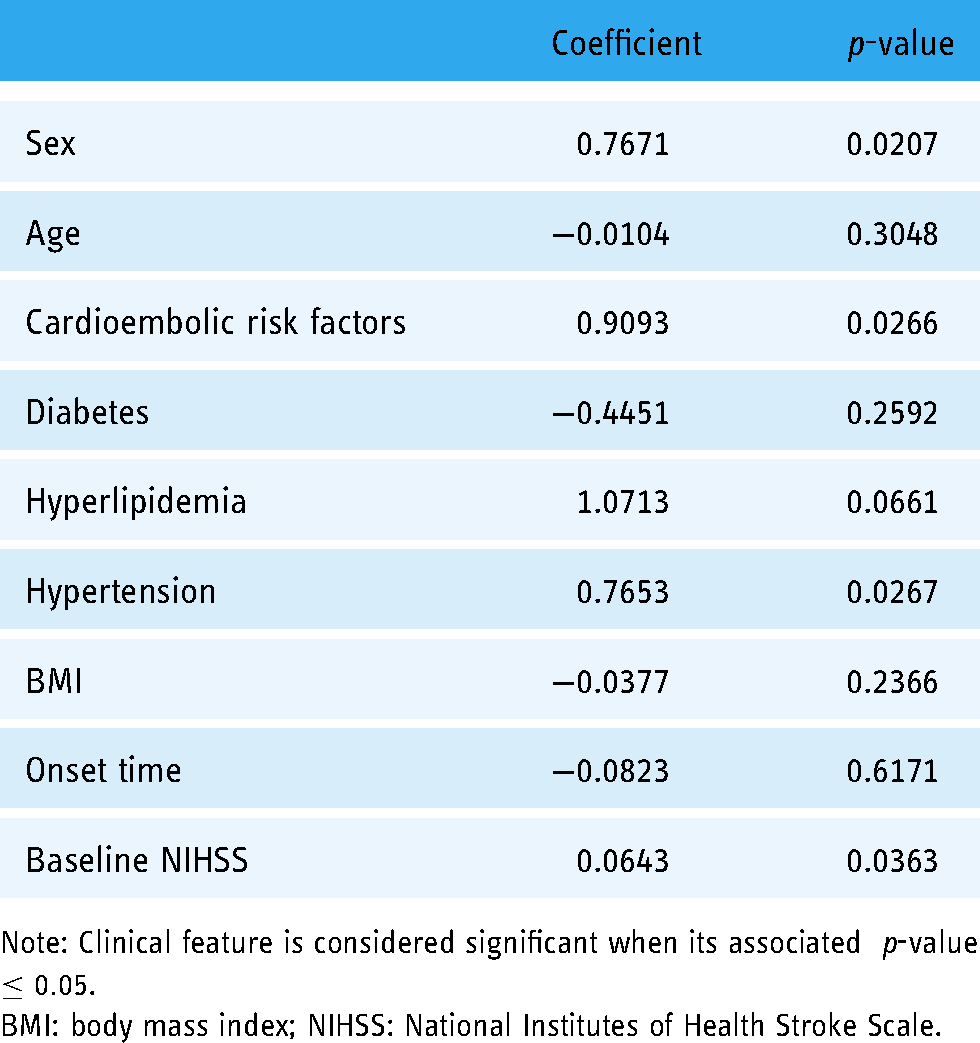
Note: Clinical feature is considered significant when its associated
BMI: body mass index; NIHSS: National Institutes of Health Stroke Scale.
Characteristics of patients with favorable outcome (FO) and unfavorable outcome (UFO) at baseline in training and test datasets.

Note: Data are presented as mean ± SD or n (%). Clinical feature is considered significantly different in two groups FO and UFO when its associated
BMI: body mass index; NIHSS: National Institutes of Health Stroke Scale.
Model development and validation
The advanced KNN prediction model with the following parameters proved to have the optimal discriminative ability on our test dataset with an AUC of
Figure 1 shows that on test dataset, our advanced KNN outperformed the classical KNN in terms of AUC. And with AUC comparison test, there were significant differences between classical KNN and advanced KNN (

Comparison of classical k-nearest neighbors classification algorithm (KNN) and advanced KNN. The left figure (a) shows the AUC obtained on training dataset, using respectively classical KNN (orange) and advanced KNN (blue). The right figure (b) shows the area under the receiver operating characteristic curve (AUC) obtained on test dataset, using respectively classical KNN (orange) and advanced KNN (blue).
Performance comparison on test dataset of advanced k-nearest neighbors classification algorithm (KNN) with weight metric of decision trees, classical KNN, and advanced KNN with coefficient of linear model in terms of accuracy, precision, recall, and F1 score.

Based on the optimal model, feature importance calculation hyperparameters were varied to test their impact on algorithm performance while all other hyperparameters were held constant. The feature importance of onset time, diabetes, and baseline NIHSS score were respectively

The impact of feature importance calculation hyperparameters variation on algorithm predictive power. The left figure (a) shows the area under the receiver operating characteristic curve (AUC) obtained on training dataset, using respectively the weight metric (blue) and the linear coefficient (orange) as feature importance calculation method. The right figure (b) shows the AUC obtained on test dataset, using respectively the weight metric (blue) and the linear coefficient (orange) as feature importance calculation method.
Discussion
Summary of main findings
In this article, we proposed a new algorithm that combines the interpretability of restrictive algorithm and the predictive power of flexible algorithm for thrombolysis outcome prediction. Our proposed algorithm is an advanced version of classical KNN. We achieved high interpretability by changing the isotropy in feature space of classical KNN.
Our preliminary results show that our advanced KNN maintains high interpretability while not compromising the predictive power: model inference revealed that three variables: onset time, diabetes, and baseline NIHSS proved significant feature importance in outcome prediction. Compared with the classical KNN, our advanced KNN outperformed the classical KNN in terms of AUC (0.88 vs. 0.75,
Moreover, the predictive power of algorithm is highly dependent on the feature importance values: based on the optimal model, feature importance calculation hyperparameters were replaced with those of linear models to test their impact on algorithm discriminative ability while all other hyperparameters were held constant. There were significant differences between the two models with different feature importance calculation methods (AUC 0.88 vs. 0.75,
Comparison with previous studies
As we have stated in the Related works section , most of previous thrombolysis outcome prediction studies preferred restrictive algorithms (logistic regression, naïve Bayes classifier, risk score, nomogram, and tree-based machine learning models) for the high interpretability, while compromising the ability to generate true decision boundaries. Most of the previous research adopting flexible algorithms (support vector machine and deep learning neural network) didn’t infer feature importance, except for the one published in 2012 11 which leveraged the reactive approach to calculate individual predictor importance from neural networks and support vector machine.
In this research article, we adopted a proactive approach to increase the interpretability of KNN, a rather flexible machine learning algorithm, by changing the isotropy in feature space while in the meantime improving its predictive power. The results indicated that our advanced KNN outperformed classical KNN in terms of discriminative ability. Besides, model inference revealed that three predictors, onset time, diabetes, and baseline NIHSS proved significant feature importance in thrombolysis outcome prediction.
Consistent with early clinical observational studies and clinical trials, onset time, diabetes, and baseline NIHSS were leveraged as important predictors by our algorithm when predicting the thrombolysis outcome: The phrase “time is brain” emphasizes that as stroke progresses, human nerve tissue is rapidly lost, requiring emergent therapy. 43 Research also reveals that early treatment with intravenous alteplase improves outcome.44–46 History of diabetes mellitus and admission glucose level (AGL) is associated with poor clinical outcomes after thrombolysis since they are related to lower recanalization rates,47,48 indicating an impaired fibrinolytic response in the setting of elevated blood glucose concentration. 49 Both chronic and acute hyperglycemia contribute to coagulation activation,50,51 whereas hyperinsulinemia decreases fibrinolytic activity by increasing plasminogen activator inhibitor production.52,53 High baseline NIHSS, which in most cases represent severe or diffuse neuron impairment due to ischemic stroke, has also been demonstrated to be related to poor outcome54,55 by multiple studies.
Clinical implications
In the literature review 56 we published earlier, we reviewed the literature on the feasibility of machine learning models to assist in stroke thrombolysis. We identified two factors that will hinder the implementation of models in the thrombolysis setting: the interpretability and the processing time of the model. This research study aims to address the issues related to interpretability. The interpretability of the algorithm allows neurologists to better understand the decision making process of an AI algorithm, which improves the trust between neurologists and machines.
Limitations and future directions
The limitation of this study is concerned with both the model interpretability and predictive power. First, the sample size was relatively small and was selected from a single medical center. Further external validations using multicenter data are recommended to validate the predictive power of the model. Second, no radiological features were included in this pilot study. Given the massive information the medical images contain regarding the thrombolysis outcome prediction, 57 we shall extract and include penumbra and vascular features from medical images as we proposed in our early study 56 to test if the algorithm can identify the same significant radiological features as previous clinical trials/observational studies did. The application of the model to a larger cohort from multicenter with radiological features included would generate more convincible evidence for the eligibility of our algorithm to assist in thrombolysis patient selection in clinical practice.
Conclusions
In summary, in this study, we proposed an advanced KNN which can maintain high interpretability while not compromising the predictive power when compared with classical KNN. The advanced KNN achieved high AUC and identified consistent significant clinical features as previous clinical trials/observational studies did. This model shows the potential to assist in thrombolysis patient selection for improving the successful rate of thrombolysis.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076221149528 - Supplemental material for A new machine learning algorithm with high interpretability for improving the safety and efficiency of thrombolysis for stroke patients: A hospital-based pilot study
Supplemental material, sj-docx-1-dhj-10.1177_20552076221149528 for A new machine learning algorithm with high interpretability for improving the safety and efficiency of thrombolysis for stroke patients: A hospital-based pilot study by Huiling Shao, Wing Chi Lawrence Chan, Heng Du and Xiangyan Fiona Chen, Qilin Ma, Zhiyu Shao in Digital Health
Supplemental Material
sj-pptx-2-dhj-10.1177_20552076221149528 - Supplemental material for A new machine learning algorithm with high interpretability for improving the safety and efficiency of thrombolysis for stroke patients: A hospital-based pilot study
Supplemental material, sj-pptx-2-dhj-10.1177_20552076221149528 for A new machine learning algorithm with high interpretability for improving the safety and efficiency of thrombolysis for stroke patients: A hospital-based pilot study by Huiling Shao, Wing Chi Lawrence Chan, Heng Du and Xiangyan Fiona Chen, Qilin Ma, Zhiyu Shao in Digital Health
Footnotes
Acknowledgments
The authors would like to thank the clinicians in the Department of Neurology, The First Affiliated Hospital of Xiamen University for their professional clinical advice.
Contributorship
Huiling Shao, Xiangyan Fiona Chen, Heng Du, and Wing Chi Lawrence Chan researched literature and conceived the study. Huiling Shao, Qilin Ma, and Zhiyu Shao were involved in protocol development, gaining ethical approval, patient recruitment, and data analysis. Huiling Shao wrote the first draft of the manuscript. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
The ethics committee of The First Affiliated Hospital of Xiamen University approved this study (REC number: SL-2020KY023-01).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Guarantor
Huiling Shao.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.