
Abstract
Social media are being increasingly used for health promotion, yet the landscape of users, messages and interactions in such fora is poorly understood. Studies of social media and diabetes have focused mostly on patients, or public agencies addressing it, but have not looked broadly at all of the participants or the diversity of content they contribute. We study Twitter conversations about diabetes through the systematic analysis of 2.5 million tweets collected over 8 months and the interactions between their authors. We address three questions. (1) What themes arise in these tweets? (2) Who are the most influential users? (3) Which type of users contribute to which themes? We answer these questions using a mixed-methods approach, integrating techniques from anthropology, network science and information retrieval such as thematic coding, temporal network analysis and community and topic detection. Diabetes-related tweets fall within broad thematic groups: health information, news, social interaction and commercial. At the same time, humorous messages and references to popular culture appear consistently, more than any other type of tweet. We classify authors according to their temporal ‘hub’ and ‘authority’ scores. Whereas the hub landscape is diffuse and fluid over time, top authorities are highly persistent across time and comprise bloggers, advocacy groups and NGOs related to diabetes, as well as for-profit entities without specific diabetes expertise. Top authorities fall into seven interest communities as derived from their Twitter follower network. Our findings have implications for public health professionals and policy makers who seek to use social media as an engagement tool and to inform policy design.
Introduction
Of an estimated 3 billion internet users around the world (over 40% of the global population), approximately 310 million actively use the social networking site Twitter (according to Twitter's own figures from July 2016). Since Twitter's launch in 2006, the platform and its users have been the protagonists of several major events (e.g. the Arab Spring, protest movements in Iran, Spain and elsewhere1–7), and it has become a prominent venue for companies, personalities and ordinary people to broadcast news and events, send public messages, express opinions and socialise.8,9
There is growing interest in the potential uses for Twitter, and other social media, in public and population health. Research has been carried out on the use of Twitter for epidemiological applications and public health surveillance. For instance, influenza spread,10,11 contagious disease outbreaks 12 and tobacco use 13 have been mapped using public data from Twitter. Geographic or spatial risk factors have also been elucidated using Twitter.14,15 This medium is being increasingly used for health information sharing, 16 primary care, delivery of health support, primary prevention and public health education.17–21
Health promotion has typically drawn on unidirectional, top-down social marketing and advertising strategies to disseminate health-related messages to a wide audience. 22 The recent use of Twitter in health promotion coincides with the influx of commercial agencies into social media to sell commodities, trends and ideas. 22 The confluence of health promotion and commercial agents on Twitter has led to a cacophony of short health-related messages directed at users and passed through social networks. Some users who create and disseminate content have the exclusive aim of promoting health, while others may have additional or alternative aims (e.g. commercial interest, self-promotion). Yet this complex environment is rarely acknowledged in public health promotion research, reviews and planning. Instead, public health marketing strategies and evaluations focus on the quantity of messages disseminated by health authorities over time, the number of followers an account has attracted and the design of new slogans.20,21 There is little critical analysis of the wider landscape of, and relationships underpinning, health-related content on Twitter, or of the impact that messages have in the broad user base.
In this paper, we investigate messages on Twitter (‘what’ is discussed and by ‘whom’) relating to a single clinical and public health concern: diabetes. Diabetes is a clinical condition associated with blood sugar regulation by the hormone insulin and other endocrine factors. Complications associated with unmanaged or poorly managed diabetes can typically affect the heart, blood vessels, eyes, kidneys and nerves. There are two types of diabetes: type 1 (often abbreviated as T1 or T1D on Twitter) occurs when the pancreas does not produce sufficient insulin; type 2 (T2 or T2D) develops when the body does not effectively respond to insulin. In 2012, the global prevalence of diabetes of both types was estimated to be nine percent among adults aged 18 years and over. 23 However, this is likely to be an underestimate; in the United States alone, 27.8% of all diabetes cases are thought to be undiagnosed. 24 Globally, around 10% of all people with diabetes have T1, which typically requires the daily administration of insulin. The remaining 90% have diagnoses of T2, which is commonly associated with obesity, poor nutrition and physical inactivity. Both types have genetic components, although no known genes directly cause diabetes. 23 T2 is managed predominantly through health education, diet and activity change, and weight loss; treatments also may include medication and, in more advanced cases, regular insulin administration. 23 People who have diabetes are encouraged to self-surveil their blood sugar levels and self-manage their lifestyles and insulin levels (through diet, physical activity and medications, where prescribed) in order to control their blood sugar levels and minimise related health complications such as those described above.
Previous research on diabetes and social media has focused on the possibilities that the internet and social media open up for both self-management25,26 and clinical management27–29 for people living with the disease. Others have focused on the dissemination of information relating to diabetes-specific outreach events 30 or from specific platforms. 31 Our approach is different; instead of assuming that patients, clinicians and health promotion organisations are the main protagonists in the Twitter conversation about diabetes, we place all stakeholders on an initial equal footing with respect to Twitter exchanges around the broad category ‘diabetes’.
We compiled over 2.5 million English-language tweets containing the term ‘diabetes’, which were generated by more than one million users over a period of 8 months (March 2013 to January 2014). These are the type of messages that users encounter when they search for the term ‘diabetes’ on Twitter, or click on the hashtag #diabetes. We analysed these tweets (public messages comprising of text strings with a maximum length of 140 characters), using a mixed-methods approach that combines mathematical and computational techniques with anthropological analysis. We used tools from data and network science to detect patterns in social interactions1,32,33 and to extract topics from the messages.34,35 We then interrogated these patterns using discourse analysis approaches from anthropology,36–38 which permit the elaboration of themes, personalities, and contexts. As a result, we extract and classify the topics that appear in the messages, and identify the important participants in the conversations (which include patients, practitioners, public health authorities, commercial entities and others).
Researchers have called for improving our understanding of social media to inform its use in public health policy making and practice. 29 Our work contributes to this understanding by addressing three questions. First, what are the main themes of messages posted on Twitter that contain the term ‘diabetes’? To answer this question, we extract the topics that appear in the tweets by processing word co-occurrence networks, and analyse their content, participants, and evolution over time. Second, who talks about diabetes on Twitter and in what capacity? To answer this question, we investigate the Twitter users who drive conversations by analysing networks of interactions (posting, sharing/retweeting, following) among the users. And third, which users contribute content to which topics and themes? We answer this question by examining the type of accounts that post in the different themes. We discuss the relevance of this interdisciplinary research for public health professionals and policy. The methods employed in this project are general and may be applied in other studies where similar data become available.
Methods
Data from Twitter
We collected every tweet containing the term ‘diabetes’ (2,698,114 tweets in total), posted between 26 March 2013 and 19 January 2014 by 1,202,143 different users (Figure 1). We also collected information about ‘retweets’: a retweet event is when a user re-broadcasts a message (or ‘status’) originally posted by another user and which is disseminated to his or her followers. Each retweet is a time-annotated interaction between two users: the target (the author of the original tweet, or the target of the attention) and the source (the user who retweeted the message, or the source of the attention). We recorded 1,219,282 retweets from June 2013 up until when the data collection ended. We also recorded 41,582 friend–follower relationships among a select subset of the users along with their Twitter biographies, messages of at most 140 character in which users can describe themselves. All data were collected by Sinnia using Twitter Gnip PowerTrack API (https://gnip.com/realtime/powertrack/). We have made available a list containing tweet IDs used in this study (see the Data Statement at the end of the article).
The number of daily tweets in English containing the term ‘diabetes’ (blue line), the number of daily tweets containing some version of the ‘Mathematics joke’, a particularly recurrent tweet (red line, see also Table 7), and the number of tweets mentioning the actor Tom Hanks (green dashed-line), who revealed his diabetes in October 2013.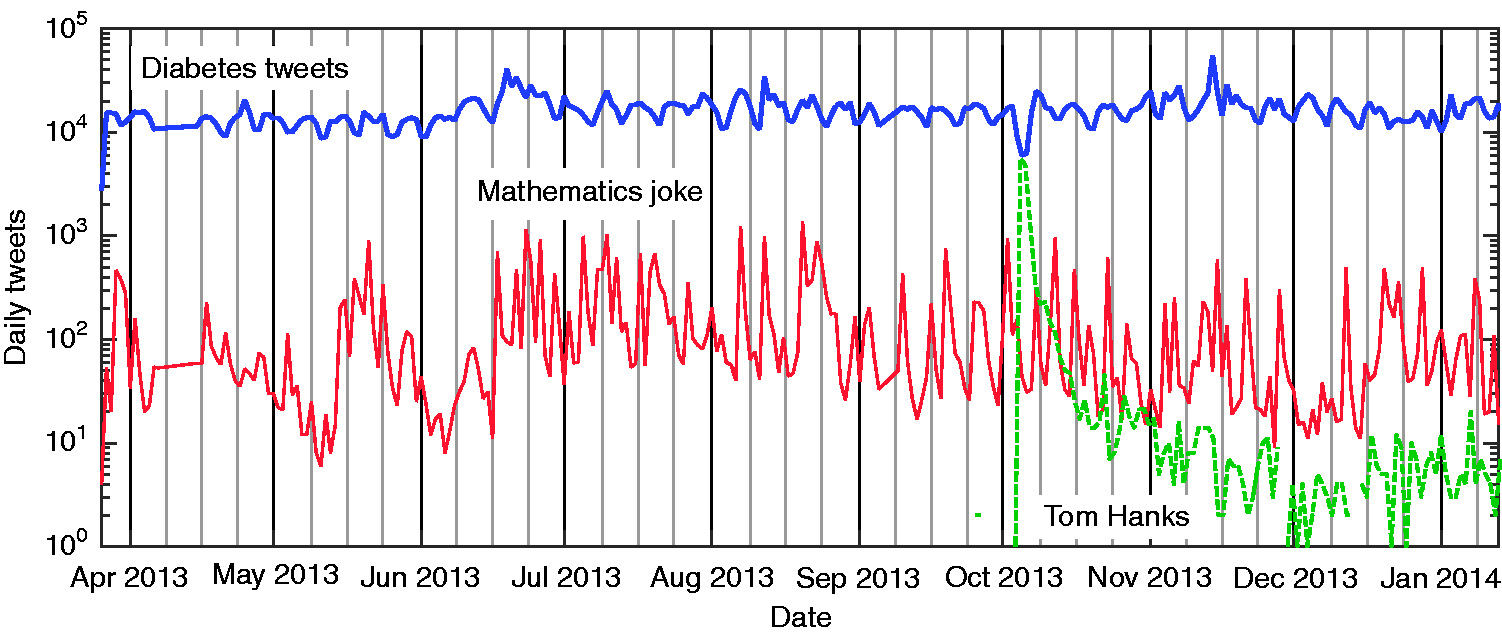
There is an ongoing debate about the ethical implications of using Twitter data for research. Some authors maintain that the lack of complicated privacy settings on Twitter means that messages placed in the public domain are intended to be there; alternatively, other authors consider that posting tweets should not be interpreted as permission to use tweets for research. 39 We believe that the topic, analysis and results presented here serve the public interest and pose no risk to users. None of the tweets we analyse and reproduce here contain notable amounts of sensitive or private material. Indeed, the most prominent users in our data set also maintain other online profiles and produce tweets for public consumption.
Construction of the different networks
The number of ‘diabetes’ tweets follows weekly cycles of activity (Figure 1). Consequently, we group the data into weekly bins. Given that the date of the original message and the date of its retweet are not always the same, retweets are labelled by the date of the original posting.
Retweet network
For each week w, we construct a directed, weighted retweet network with N(w) nodes, corresponding to all of the users who participated in a retweet event either actively (by retweeting) or passively (by having their statuses retweeted by someone else). A directed connection (edge or arc) exists between two nodes if the source node has retweeted the status of the target node, and the weight of the edge corresponds to the number of retweets (see Figure 2), i.e. we define the N(w) × N(w) adjacency matrix of the retweet network as In retweet networks, nodes that are exposed to content can ‘pass it on’ to their followers. The flow of data goes in the opposite direction to the interest of the users, where interest is represented by arrows which indicate the direction of attention. (a) Projections of a retweet network. The original retweet network is directed. The co-citation projection joins nodes who are the targets of the interest of other nodes. Nodes 5 and 6 have both been retweeted by node 4, hence they are connected in the co-citation projection (edges in red). In turn, nodes 2 and 8 have both retweeted statuses by node 1, which is why they are connected in the bibliographic projection (edges in magenta). Both of the projections have several disconnected components. (b) Example of retweet, co-citation and bibliographic networks constructed from one week's worth of interactions in our data. There are approximately 44,000 nodes, each coloured according to their weakly-connected component in each network.

In a retweet network, the direction of the edge signifies an explicit declaration of interest (i.e. source nodes find certain messages worth passing along to their followers) and information flows in the opposite direction (i.e. from the target nodes), as shown in Figure 2. Such retweet networks have a distinct structure, with many weakly connected components and an abundance of ‘star’ motifs, in which a highly retweeted node (with high in-degree) is surrounded by many nodes that point almost exclusively to the star node. Figure 3(b) shows a typical network for one week in our data with 44,000 nodes and about 4000 weakly connected components. Over 50% of the nodes belong to a giant connected component (nodes in purple) whereas each of the smaller components contain less that 1% of the nodes.
A fundamental feature of retweet networks is the fact that they are directed (they may contain extreme asymmetry of interest, ‘leaders’ and ‘followers’ and other roles). Directionality entails additional computational challenges, which is why it is often neglected. However, ignoring directionality in such settings destroys valuable information and can severely affect the results and their interpretation. 1 Our analysis below takes the directed and temporal nature of the network into full account.
Co-citation and bibliographic projections of the retweet network
To understand not only who drives conversations and produces influential content, but also which users are instrumental in the dissemination of content, we study two useful networks derived from the original retweet network: the co-citation and bibliographic projections.
33
These projections reflect the asymmetry of the original adjacency retweet matrix
The co-citation network projection of (a) Number of nodes, number of components and size of the two largest connected components in the co-citation projection through the observation period. (b) Same measurements for the bibliographic projection.

The bibliographic network projection is the converse of the the co-citation network. It is also built from the original retweet network
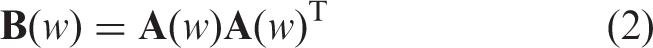
Note that all nodes in the original retweet network exist in both projections. However, depending on their connectivity (induced by the interest elicited or the interest bestowed) they may appear isolated in one or both of the projections. Figure 3 shows an illustration of the construction of the co-citation and bibliographic projections in a simple example, as well as the retweet, co-citation and bibliographic networks compiled from a typical week in the data.
Follower network
In addition to the retweet network, we also constructed a follower network for a small subset of users of interest (see Section ‘The ‘who' of diabetes on Twitter’). In this network a directed connection between two nodes exists when the source node follows the target node on Twitter (i.e. is subscribed to the target's content). The interpretation of the follower network is similar to the retweet network (Figure 2) in the sense that a directed connection is a declaration of interest, with content flowing in the opposite direction. 1 One key difference between retweet and follower networks is that connections in the retweet network can be understood as localised expressions of interest associated to a specific tweet, whereas in follower networks a connection may be understood as a more general (and stable) expression of interest.
Computation of the hub and authority scores over time
Hub and authority scores provide a useful tool to analyse directed networks.
32
Intuitively, a hub is a node whose outgoing connections point to important nodes in the retweet network (authorities); conversely, an authority is a node with many incoming connections from hubs. The entries of the lead eigenvectors of the adjacency matrices of the co-citation and bibliographic projections
Henceforth, for notational simplicity, we drop the w from the matrices
An alternative way to understand hub and authority scores is through the singular value decomposition (SVD) of
As explained above, the bibliographic and co-citation networks contain several disconnected components (Figures 3 and 4). The largest connected component in a typical co-citation network in our dataset contains about 10–15% of the nodes, yet it is responsible for producing about 50% of messages that have at least one retweet. This observation is consistent with Wu et al. 9 who report that about 50% of URLs on Twitter are posted by a small minority of ‘elite users’. On the other hand, since the number of users who retweet is much larger than those whose messages are retweeted, the bibliographic projection has a much larger giant connected component, with about 75% of the nodes.
Given the fragmented nature of the projection networks, we compute hub/authority scores weight-averaged over all components as follows. Let the co-citation network for a given week
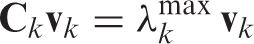
To extract the hub scores in each week we follow the same procedure on matrix
Topic extraction
Topic extraction from the data proceeds in several steps. First, the tweets in the dataset are grouped in weekly bins (as for the networks constructed above). For each week, the raw text is pre-processed and a word co-occurrence network is created. The probability that the tweets in each bin belong to different topics is computed using techniques from textual analysis and community detection for graphs. Note that topics are extracted using only the original tweets: retweets are excluded because they do not add any new topical information. The details of each of the steps for topic extraction are as given as follows.
Text pre-processing
Prior to topic extraction, the text of each tweet is processed in the following way.
Convert words to lowercase, e.g. the terms ‘diabetes’, ‘Diabetes’ and ‘DIABETES’ are all processed as the same word. Remove all punctuation signs and non-alphanumeric characters, i.e. we compare tweets based only on the words they contain. Replace collocations for specific terms (e.g. ‘Type 2’ or ‘T2D’ are replaced by ‘type2’) in order to homogenise terms that are known to refer to the same concept. Remove stop-words and special words (articles, conjunctions, etc.),
35
numbers and vestigial URLs, which bear no topical information. Stem the text.
41
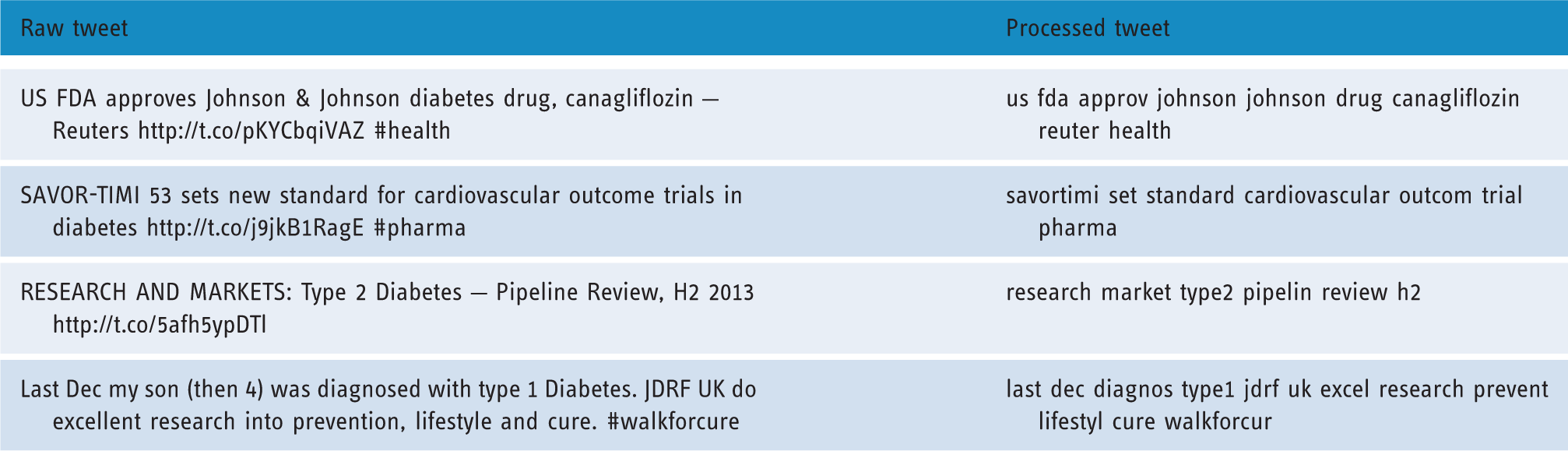
This step strips suffixes so that related words are mapped to the same stem, e.g. ‘house’, ‘houses’, ‘housing’ are replaced by ‘hous’. Examples of ‘raw tweets’ and their processed version prior to topic extraction.
The result of this pre-processing step is illustrated in Table 1, which contains examples of ‘raw tweets’ and their processed version.
Topic extraction from word co-occurrence graphs
After text pre-processing, we extract the topics from the tweets in each weekly bin in the following steps.
Following Lancichinetti et al.,
34
we create a word adjacency graph for each weekly bin. The nodes in the graph are words, and edges indicate two words that co-appear in tweets with higher probability than one would expect at random (i.e. when the probability of such an edge in a random network with the same degree sequence is less than 0.05). We analyse the word co-occurrence graph using Markov Stability42,43 (in contrast with the use of Infomap in Lancichinetti et al.
34
) to extract relevant communities (or groups) of words that co-appear in tweets more consistently than with words outside of their own group, and to consider groupings of different granularity.1,44 The communities of words are used as the input for the Latent Dirichlet Allocation (LDA) topic extraction method.
45
Hence, the communities obtained with Markov stability provide an initial guess for the topics to which a tweet is likely to belong. Specifically, we assume that each document (tweet) d
i
belongs to a topic (community) t
k
with a prior probability P0(d
i
|t
k
) that is proportional to the number of words that document d
i
has in topic t
k
. LDA then proceeds iteratively to produce the posterior probability that document d
i
belongs to each topic t
k
: P(t
k
|d
i
). LDA also produces P(h
j
|t
k
), the probability of finding word h
j
in a document given topic t
k
. We make the assumption that, given their brevity, each tweet can only belong to at most one topic. This entails collecting only the assignments of topics to documents with abnormally large values (i.e. the outliers) of P(t
k
|d
i
), and discarding all other values. A tweet is assigned to a topic if P(t
k
|d
i
) > pc(99) + IPR, where pc(99) is the 99th percentile of the distribution and IPR is the inter-percentile range: IPR = pc(99) − pc(1). Figure 5(a) shows an example of this criterion where a tweet about the FDA's approval of a diabetes drug is assigned to a topic that contains almost 2000 tweets about this event. (a) Box-plot of the posterior probability of a specific tweet d
i
after LDA optimisation. The red line indicates the median LDA assignment score for this tweet, the box indicates the 25th and 75th percentiles, and the whiskers mark the interpercentile range (IPR, see the text). There are three topics (red crosses) that lie outside the interpercentile range, the one furthest to the right is designated as the topic of the tweet. This tweet belongs to a topic which covers the FDA's approval of a diabetes drug in late March 2013. The topic belongs to a theme the ‘Commercial’ thematic group in Table 2. (b) The number of topics extracted varies for each week with an average of 75.

This method for topic extraction is applied separately to each of the 43 weeks in our dataset. Figure 5(b) shows the number of topics in each week. The average number of topics per week is 75.
Themes from topics
In order to identify the dominant themes in the dataset, we applied open thematic coding 38 to the topics obtained in the previous section, for a random selection of weeks. In total, we analysed in-depth 290 topics (from weeks 34, 39, 44 and 50 of 2013, and week 2 of 2014) containing 63,000 processed tweets with identified topic.
Thematic groups and associated themes obtained through open coding applied to the topics detected in the tweets of the collected dataset.
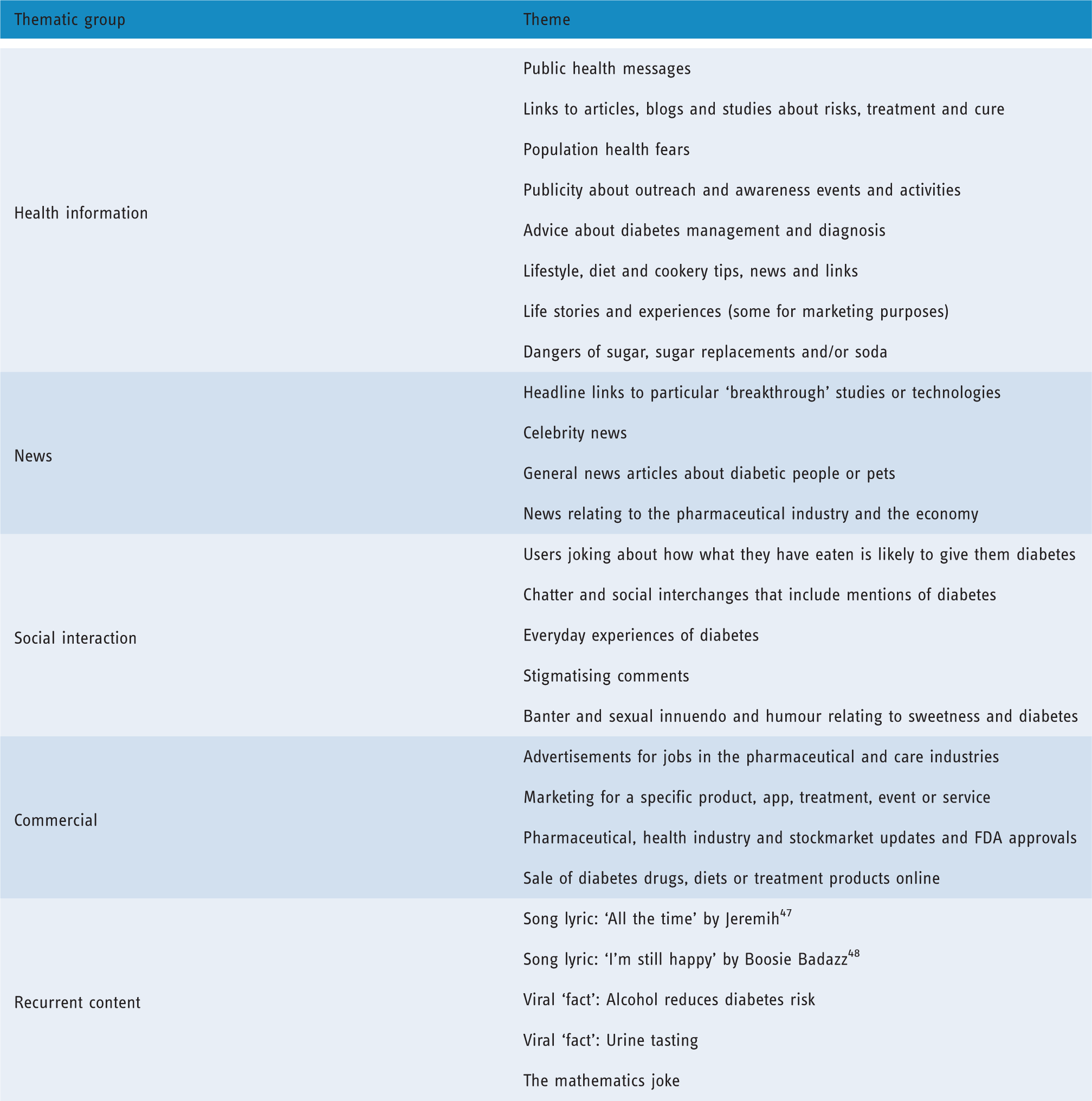
In summary, our analysis of content progressed as follows: first, we automatically extracted weekly topics from the tweets; second, we manually applied open thematic coding until saturation to obtain a list of coded themes; and third, we manually placed these themes into thematic groups.
In order to learn which themes dominated in tweets by the most influential accounts, we also analysed the tweets by the top authority nodes. Here, tweets belonging to each user were coded according to themes identified in the thematic analysis.
Interest communities in the follower network of authorities
To complement the textual analysis above, we also analysed the community structure of the follower network of the 1000 accounts with the highest cumulative authority score over the observation period. The giant connected component of this network comprises 880 nodes, with the rest being either isolated or suspended. To extract the communities in the networks, we used the Markov stability community detection framework as described by Beguerisse-Díaz et al. 1 and Amor et al. 46 ; we found a robust partition of the network into seven communities of different size. We labelled the communities according to the type of accounts that each contains (e.g. health agencies, diabetes advocacy, research scientists and so on).
Results
The ‘what’ of diabetes on Twitter
As described above, the tweets in our dataset were first automatically grouped into topics, and their content was then manually assigned themes using open thematic coding. These themes fall into one of four broad thematic groups: health information, news, social interaction and commercial. For tweets in these groups, although the content and messages changed from week to week, the themes remained constant. In addition to these four thematic groups, we identified a fifth group of tweets with consistent and recurrent content. In this distinct group, the specific content was repeated consistently across the data sample (i.e. the tweets did not change from week to week). In Table 2, we present the thematic groups and the themes within each group. Figure 6 contains a visual summary of the thematic groups as ‘word-clouds’ with the 200 top words in each thematic group (i.e. the words most likely to appear in the topics), and ‘word-clouds’ with the usernames (scaled to size of number of tweets) of the 200 most active users (available also as a supplementary spreadsheet, see the Data statement). Note that the term diabetes has been removed from the analysis because it appears in all of the tweets. It is important to remark that the most active users (e.g. those who tweet the most) are not necessarily the most important, or ‘central’ in the different networks, from the point of view of information generation.
Top 200 words and most frequent authors in each of the thematic groups in Table 2. The size of each word is proportional to its probability of appearing in a topic in the group. The size of the username is proportional to the number of tweets in the thematic group.
We now discuss in more detail the themes, topics and users found in each of the five thematic groups.
Health information tweets
One of the largest thematic groups consists of health information, research findings, recommendations, advice and warnings, which are all abundantly tweeted and retweeted. Figure 6(a) contains a word-cloud with the 200 most probable words in the topics of this group (the total number of distinct terms is 29,647 in 90 topics from open thematic coding). The top 10 words in this thematic group are: risk, type2, disea (disease, diseased), heart, research, month, obe (obese, obesity), fruit, news, awar (aware, awareness). Such terms are typical of tweets that fall within this broad thematic group, as seen in Figure 6(a) and the supplementary spreadsheet, as well as in Table 3 at the end of the article containing specific examples of tweets. The tweets in this group include information about diabetes (its causes, treatments and cures); technologies and pharmaceutical products that can be used for managing it; as well as risks associated with the disease. Other health-related messages include publicity about outreach and awareness events, activities and information. These individual messages are typically not long-lived, and are only visible at the top of a user's timeline for short periods of time. 49 In general, there is a high turnover in the content that each user is exposed to, even though many messages (e.g. those from newspapers and online media) are posted multiple times. One of the themes that is less variable in this regard concerns the dangers of sugar, sugar replacements and/or sodas. Its frequency is unsurprising given the nature of diabetes as a problem of blood sugar regulation. It is worth mentioning that the largest spike of activity in our data (in November 2013, see Figure 1) is in part due to a surge in tweets about World Diabetes Day on 14 November 2013.
The health information in the collected sample does not appear to be directly or specifically associated with health promotion groups. Instead, such tweets are posted by users with different claims to expertise: individuals who have experienced diabetes; personal trainers marketing their services; companies selling lifestyle products or services; and other users with an apparent interest in diabetes, cookery and healthy eating. These tweets include advice about diabetes management and diagnosis, cookery and diet tips, life stories and experiences, and links to articles about new treatments or promising cures. Some tweets make claims about ‘curing’ diabetes, or offer natural or ‘miracle’ treatments. Advice of this nature appears to be authoritative in tone and language, making it difficult to distinguish it from advice disseminated by official health authorities. Links contained in such tweets point to different types of authoritative sources of content: from people who have first-hand experience of diabetes, to marketing agencies trying to sell a particular food, supplement or device, to hospitals attempting to communicate a specific health message. Home remedies and ‘miracle’ cures appear alongside health tips and recommendations. Digests and newsletters specifically containing diabetes-related news (where the authors gather information from multiple sources around the internet and supply it to their followers) appear at different moments in time and mix all such messages together.
News tweets
News-related tweets in the collected dataset typically list a headline of a news article; they sometimes give the first line of the story and often also provide a weblink to the complete story. These tweets rarely relate to health promotion or education messages. Figure 6(b) contains the 200 most probable words theme (out of 10,416 in 29 topics). The top 10 words are: type2, risk, fruit, type1, eat, peopl (people, peoples), blueberri (blueberry, blueberries), cut, research, juic (juice, juicer, juicing, juicy). Some news-related tweets communicate research breakthrough studies or technologies, which may be reported with messages of hope for those who have diabetes, in particular T2. Just as common in this thematic group are tweets with celebrity news (especially about celebrities diagnosed with diabetes) and diverse news about people or pets with diabetes. Another prominent theme in this group consists of tweets disseminating news headlines about the pharmaceutical industry and stock market. Diabetes treatment is a lucrative industry because diabetes is a chronic condition that requires regular and ongoing treatment (rather than cure), and so the demand for pharmaceutical products and lifestyle aids is inelastic. 50 Furthermore, the number of people with T2 is projected to increase dramatically in the future as a result of population ageing and obesity, 51 which will further expand the market. Table 4 contains examples of tweets in this category.
Social interaction and humorous tweets
Twitter is not simply an information-sharing technology, but also a space that permits (virtual) social interaction.3,8 Social interaction tweets use language differently to the thematic groups above: they are typically informal in tone, their attention to spelling and grammar is limited, and they often use exclamation marks and punctuation to express fun, laughter, exasperation, sarcasm, irony, and abuse. The top 10 words (out of 31,061 in 97 topics) in this group are: give, health, food, die, think, fat, year, diet, diseas (disease, diseased), cau (cause, causes, causing). See Figure 6(c) for the theme's word-cloud. Users frequently joke about how what they have eaten is likely to give them diabetes, with a wide variety of sugary foods and drinks, junk foods and other ‘unhealthy’ options being cited. Such tweets indicate a level of awareness of dietary guidelines and diabetes aetiology. Users have conversations and interact about a diversity of topics in chatter that is not necessarily directly related to diabetes but may include references to it. People who have diabetes, particularly T1, also talk about their daily experiences of their bodies, sugar management, and social acceptance or stigma; such tweets may elicit retweets or messages of support from others. Some users also talk in terms of “us” (with T1) and “them” (without). For example, one user talks about T1 as being a ‘perk’ or feature he/she looks for in a romantic partner: I haven't stopped thinking about this girl for seriously like…a month. AND she has diabetes! #diabetesperks
On the other hand, stigmatising comments, especially tweets which blame diabetic people for bringing the disease on themselves through, for example, poor diet or lack of physical activity, are abundant in the dataset. Figure 6(c) and the supplementary spreadsheet contain numerous examples of profanity and pejoratives. Faced with such messages, users with T1 diabetes frequently point out that it is important to differentiate between T1 and T2, insinuating that while T1 diabetes is not a person's ‘fault’, T2 may well be. Other tweets include calling other people ‘diabetic’ as an insult and wishing diabetes upon a person a user does not like. Table 5 contains examples of social interaction, humorous and stigmatising tweets.
A distinct theme in this category consists of tweets with sexual innuendo. At their mildest, such tweets refer to boy-band members or other (often celebrity) ‘crushes’ that are so sweet they are diabetes-inducing. At their most extreme, tweets joke that others' bodily fluids and genitals are so sweet they are diabetes-inducing. These tweets contain weblinks to pornography websites or other explicit material. Like the jokes discussed earlier, these tweets reflect a baseline awareness of the links between sugar and diabetes.
Commercial tweets
As mentioned previously, diabetes is an industry with an attractive (and expanding) market: it is a chronic condition which is currently incurable, and it requires constant and regular testing, surveillance and treatment. The top 10 words (out of 5841 words in 20 topics) in this group are: type2, drug, job, manag (manage, manager), care, health, marijuana, sale, test, forsal (for sale). See Figure 6(d) for the theme's word-cloud and the most active users within this topic. People with diabetes depend on different technologies, consumables, health services and pharmaceutical products. This commercial dimension of diabetes is reflected in many Twitter messages. Tweets concerned with stockmarket listing announcements, FDA approval (e.g. Figure 5(a)), court cases and business recruitment (for example, a company hiring a new CEO or advertising for new staff) are common. Table 6 contains typical examples of these types of message.
Recurrent content
While the specific content of tweets in different themes varies over time, there are some tweets whose content appears consistently across time over our dataset. The top 10 words (out of 8731 words in 19 topics) in this theme are: sugar, eat, blood, sweet, risk, type2, drink, high, reduc (reduce, reducing, reduction), health. Figure 6(e) contains this theme's word-cloud. There is a large number of tweets repeating lyrics from two specific rap songs, both of which contain the term ‘diabetes’ (see Table 7). Of these, ‘All the Time’ by Jeremih 47 was released in 2013, so it is possible that the appearance of one line from the song in many tweets in our sample may be linked to marketing and initial responses to the song. The lyric repeated from the song relates to the sexual innuendo discussed previously, so its continued presence may result from it being used to express a joke rather than as a direct and deliberate citation (indeed, the song name or artist are rarely mentioned). The second song ‘I'm Still Happy’ by Lil Boosie (now Boosie Badazz) 48 was released on a 2010 digital mixtape, suggesting that the lyric has been consistently attractive to users over time. This lyric is about determination in the face of challenges; the artist himself has T1 and has talked with his fans about the challenge of managing his diabetes.
In addition, several specific viral ‘facts’ and jokes are posted frequently and repeatedly (for example, that tasting urine for sweetness was a method to detect diabetes in the past, 52 or that consuming alcohol moderately has been reported to reduce diabetes 53 ). These few specific facts appear to intend to entertain or amuse. They retain almost identical phrasing over time, with sustained popularity. In fact, such facts are repeated more consistently over time than other headlines, health messages and reports.
One of the most prominent instances of recurrent content in our data corresponds to various versions of a mathematics-themed joke. A typical instance of this joke is Math Problems: If Jim has 50 chocolate bars, and eats 45, what does he have? Diabetes. Jim has diabetes…
The ‘who’ of diabetes on Twitter
We now turn our focus to the analysis of the users in the retweet networks extracted from our dataset. Figure 6 provides a visual illustration of the users that posted more tweets in the topics contained within each of the thematic groups. Although helpful, this figure does not provide information about how important these users are perceived to be in the community, or the impact they have in the conversation about diabetes. Therefore, in order to understand who are the key users that influence diabetes-related content on Twitter over time, we examine the hub and authority scores of all nodes for each of the weekly retweet networks from June 2013 to January 2014 (see Section 2.3 for a description of the methodology). We then examine the content generated by the most important users (according to their hub and authority scores), and we finally analyse their follower network (i.e. who follows whom within this group of important users).
Authorities and hubs in the weekly retweet networks
Top 10 users by aggregate authority score, number of weeks with non-zero authority score and a brief description.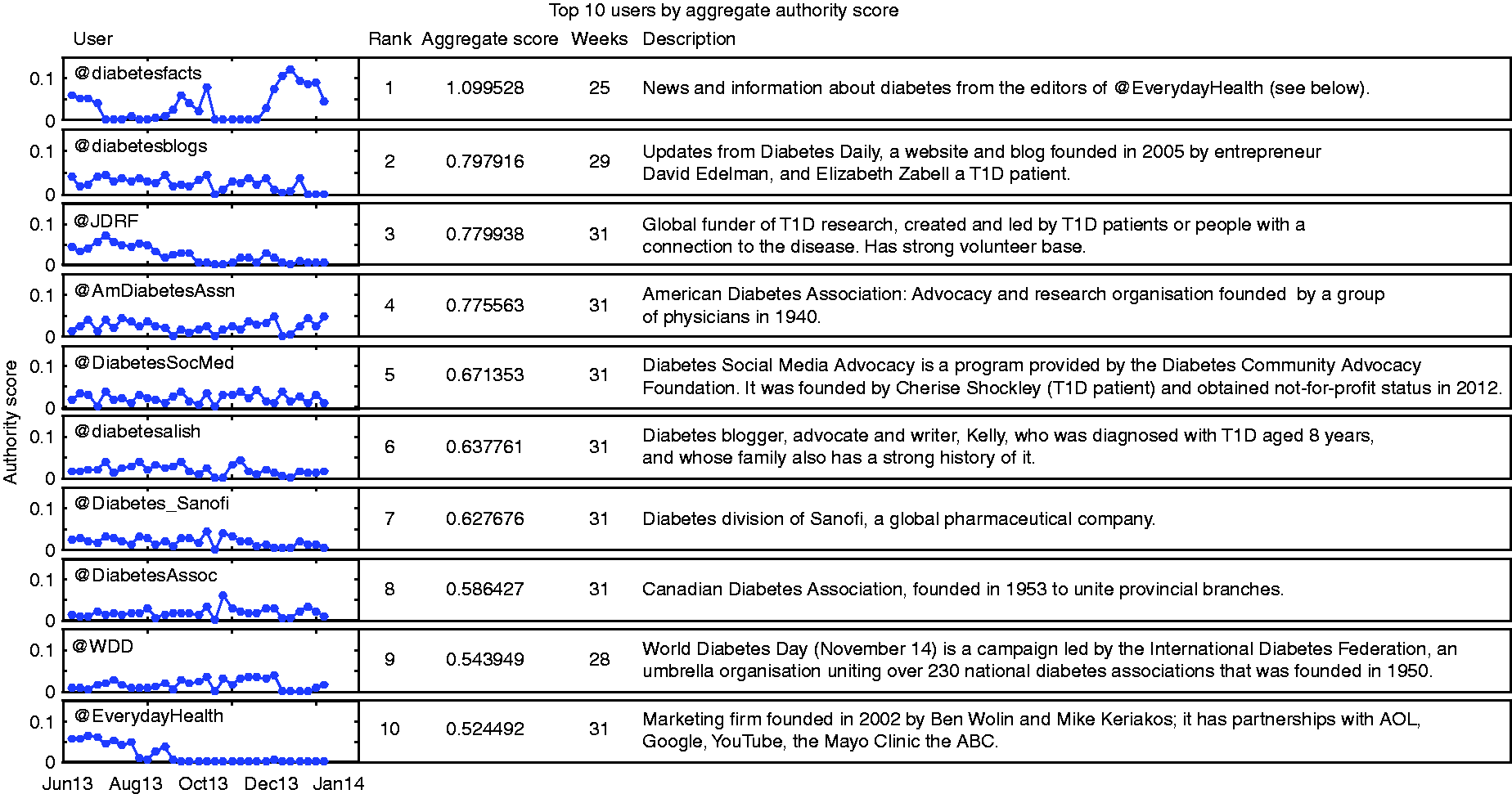
Three of the nine institutional accounts belong to stockmarket-listed commercial ventures (i.e. established with the purpose of generating profits for shareholders). Of these, two (@diabetesfacts and @EverydayHealth) belong to Everyday Health Media. This company, which does not claim to have any specific diabetes expertise, owns and operates a range of brands. It was founded in 2002 by Ben Wolin (an entrepreneur who has previously worked for Beliefnet, acquired by News Corp., PBS, Warner Brothers and Tribune Interactive) and Mike Keriakos (a media sales expert who began his career at Procter and Gamble and who built partnerships between Everyday Health and AOL, Google, YouTube and the ABC). The other listed company account, @Diabetes_Sanofi, belongs to the global pharmaceutical firm Sanofi, which produces diabetes treatments.
Another three of the top 10 authorities correspond to national and international diabetes associations: @AmDiabetesAssn (the American Diabetes Association) @DiabetesAssoc (the Canadian diabetes association) and @WDD (which belongs to the International Diabetes Federation). The latter account is established especially to promote World Diabetes Day (14 November), although it disseminates diabetes information and messages all year round. These associations were originally founded by physicians and they focus on advocacy and research.
The remaining three authorities in the top ten belong to not-for-profit organisations founded by people who have experienced T1. These organisations target T1 specifically: one is a funding body (@JDRF, an organisation previously known as Juvenile Diabetes Research Foundation), and the other two are blog platforms that host discussions and disseminate information (@diabetesblogs and @DiabetesSocMed).
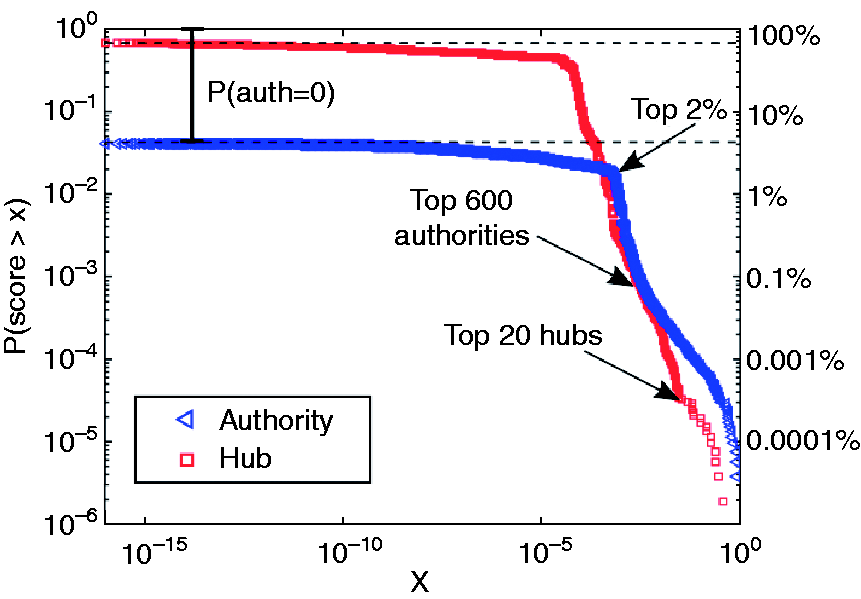
Figure 8 shows the complement of the cumulative distribution function (CDF) (i.e. 1 − CDF) of the aggregate authority scores (blue triangles). The distribution of authorities shows that over 95% of users involved in a retweet event do not feature as an authority at all (in our weekly binning). Users who do attain a non-zero authority score fall into two categories.
Users with a sporadic or marginal appearance (i.e. they appear in only a handful of weeks and/or not in the giant components of the weekly co-citation networks). These users are concentrated in the long plateau in Figure 8. Users who appear more regularly usually as part of the weekly giant connected components. These users constitute the top 2% in the heavy tail of high scores in Figure 8. Cumulative distribution of aggregate hub (red) and authority (blue) scores on a doubly-logarithmic scale. The horizontal dotted lines show the proportion of nodes with zero aggregate hub (< 10%) and authority (≃ 95%) scores.
In the supplementary spreadsheet, we provide the top 1000 accounts by aggregate authority score as a further resource for research. As with the top 10 users discussed above, this longer list contains accounts of known commercial, public and advocacy organisations, as well as medical schools, hospitals, individual activists and bloggers. In addition, we note the appearance of academic publishers (@bmj_latest, ranked 55; @NEJM, ranked 67); comedians (@ChelcieRice, ranked 28; @SherriEShepherd, ranked 85); news and media outlets (@medical_xpress, ranked 40; @foxnewshealth, ranked 82); entertainment (@FoodPorn, ranked 197); and large health-oriented organisations (@WHO, ranked 88; @NIH, ranked 111), all of which have a focus much broader than diabetes.
These accounts disseminate content and information about diabetes on Twitter efficiently, with messages that elicit a wide, measurable response through re-tweets and replies from the general population. The sustained presence of the top authorities (i.e. the sustained strictly positive authority score in Figure 7) is an indication that these users consistently produce content that resonates with the general Twitter-using population.
Two different rankings of hub nodes. (a) Top 10 users ranked by their aggregate hub score, along with the number of weeks in which they appear with a non-zero hub score. (b) Top 10 users ranked by their number of weeks with a non-zero hub score. Note the change in the scale of the y-axis.
These hub nodes have a highly variable number of followers. For instance, in August 2016 @Diabetes_Month had over 20,000 followers, whereas @abdSauce had about 50. What all hubs have in common is a high rate of retweeting and a feeble, unsustained presence throughout the observation period. Figure 9(a) shows the scores over time for the top 10 hubs based on aggregate score, along with the number of weeks in which they have a non-zero score. The data shows that, in most cases, the high aggregate hub score is the result of a ‘one-off’ surge. We thus term these ‘intermittent hubs’.
The biographical information provided by these users about who they are and what they do is sparse, often vague and difficult to corroborate. For example, the account @1MEDICAL2NEWS claims to be a Dr Richard Billard from Los Angeles, but while the account had a high level of activity on Twitter in our data (and until August 2014) there is no other evidence online that this doctor exists. Given the extremely active Twitter account, it is unusual that this doctor has absolutely no other online presence. The rate at which this particular user retweeted (on average, 65 times per day), together with the lack of any original tweets (or non-retweets), further suggests that it could have been an automated account assigned an authoritative-sounding alias.
Figure 8 shows the complementary CDF of aggregate hub scores for all users (red squares). In contrast with the authority scores, most users (∼90%) have a non-zero aggregate hub score), and the split between low scoring and high scoring hubs is more even, with around 50% of the ∼1.2 million users contained in the heavy-tailed part of the distribution. There is a distinct bend at the right end of the heavy tailed regime of the distribution that contains the top 20 users by aggregate hub score, half of which have been discussed above.
To obtain a clearer picture of ‘persistent hubs’, we created an additional activity ranking of hubs by number of weeks in which the users have a non-zero hub score (Figure 9(b)). The top hub according to this persistence score is still @1MEDICAL2NEWS, which is a hub in each of the 31 weeks for which we computed the hub scores. Another noteworthy appearance is @diabetesalish, who is also a top 10 authority, and who was active as a hub in each week as well. The top 1000 (intermittent and persistent) hub accounts are included in the supplementary spreadsheet as a resource for further research.
@JDRFAdvocacy: a US Government-funded organisation which focuses on building support for T1D research; the advocacy account of @JDRF; (authority rank, hub rank) = (38, 234). @askmanny: Manny Hernandez, a prominent Venezuelan–American diabetes advocate who has had diabetes since 2002, and whose professional expertise is in social media, technology and health (authority rank, hub rank) = (12, 208). @amidiabetic: Diabetes advocate and writer Stuart Wimbles, who runs a diabetes information website and reportedly has T1D, although there is little additional information about him online; (authority rank, hub rank) = (20, 366). @DiabetesMine: A website/blog/newsletter run by Healthline, a consumer health information website. The company has a large team of staff and a panel of three medical advisors (a Professor of Emergency Medicine, a drug information specialist, and a pharmacist) who provide insights into user needs; (authority rank, hub rank) = (13, 208), @KayleighAdams3: Account currently suspended; (authority rank, hub rank) = (300, 64). @theNGdoc: Nigeria Diabetes Online Community, a non-government organisation launched in 2013 to provide empowerment, education and support for diabetics in Nigeria. An original idea by Cherise Showkley (@DiabetesSocMed), the site is officially recognised by the International Diabetes Federation, and two of its Directors are medical doctors; (authority rank, hub rank) = (127, 200). @BattleDiabetes: Account of informationaboutdiabetes.com, a website with no details about who it belongs to, but which traces to Jill Knapp, a T2 diabetic who is an advocate for the American Diabetes Association; (authority rank, hub rank) = (49, 442). @KellyRawlings: Diabetes advocate, T1 diabetic, journalist, and editor of Diabetes Forecast, a publication of the American Diabetes Association; (authority rank, hub rank) = (107, 387). @diaTribeNews: Account of the diaTribe Foundation, a non-profit organisation founded by T1 diabetic Kelly Close to help people with diabetes to live better lives. Close was previously a financial sector analyst and also runs Close Concerns, a healthcare information firm focusing on diabetes and obesity; the Foundation Board contains one medical doctor; (authority rank, hub rank) = (171, 273). @MyGlu: T1D Exchange, a non-profit organisation providing connectivity for people whose lives are affected by diabetes. The site's leadership team contains a physician and pediatric endocrinologist, but it also makes a clear disclaimer that discussions on the site should not be a substitute for medical advice; (authority rank, hub rank) = (122, 326). @abdSauce: Top hub account, has been taken down or switched hands since data were collected; a Pinterest account with the same handle belongs to Rasheed Adewole, who works with the Nigeria Diabetes Online Community (@theNGdoc); (authority rank, hub rank) = (676, 6), @dr_bolajidauda: Top hub account, no longer active at the time of analysis; (authority rank, hub rank) = (637, 7). Twitter accounts with the highest combined aggregate hub and authority score (top 2% on both rankings, on a logarithmic scale). The colour of each data point corresponds to the user's combined hub/authority score; blue denotes a lower hub or authority both (relative to the other accounts on shown here), a transition towards red denotes strength on both scores. Shown here are the usernames of 35 accounts that score highly both as hubs and as authorities; usernames in black are discussed further in the text.
In addition to posting messages that evoke a broad response (as authorities), these users also engage by retweeting and replying to messages posted by other users (as hubs). The empty upper-right corner in Figure 10 indicates that there are no accounts at the very top as both hubs and authorities.

Extended analysis of authorities: content and relationships
The analysis so far has established the persistence and relevance of a relatively small number of authorities in the collected retweet networks. To further our understanding of the group of authorities, we perform two further analyses. First, we analyse in detail the thematic content produced by the top 10 authorities. Second, we extract the network of followers within the top 1000 authorities and characterise the interest communities within the network of authorities.1,46
Two accounts, @Diabetes_Sanofi and @diabetesblogs, do not appear to be dominated by any one of the themes listed, but contain a mixture of all the ‘Health Information’ themes. Two other accounts, @WDD and @AmDiabetesAssn participate in themes that are related to outreach and advocacy activities, events and news. The not-for-profit organisation and research funding body @JDRF produces tweets that contain life stories and experiences of diabetes sufferers more than any other top 10 authority.
Two accounts, @diabetesfacts and @EverydayHealth (owned by the same company) focus predominantly on lifestyle and diet-related tips, hints and advice. Unlike the other authorities, these do not produce outreach or advocacy messages at all. Typical messages posted by these accounts include: @diabetesfacts: Tips on adjusting your insulin pump during exercise from diabetes educator Gary Scheiner @Integ_Diabetes – http://t.co/28Hx8c7PES @EverydayHealth: Medical costs for people with #diabetes are more than 2x those of people without it. Are you budgeting for diabetes? http://t.co/2ohMOVJvwp @EverydayHealth: The best beverages to quench your thirst with #diabetes http://t.co/HbR4poFfF5
The messages posted by the accounts @diabetesalish and @DiabetesSocMed are dominated by a mix of social interactions, banter and advocacy. They participate in news topics, but to a lesser degree than the other top 10 authorities. Their tone is different to the others: it is informal and conversational rather than authoritative or informational. For example: @DianetesSocMed: Happy Mother's (aunts, fur baby moms, god moms, etc.) to all the women in the diabetes community! Have a great day! @diabetesalish: #dblog:Dear240 #bgnow: You R but fleeting & temporary, I am permanently fabulous. #Iwin #diabetes #doc #dsma http://t.co/w9iZw83f97
Two accounts, @diabetesblogs and @diabetesalish, occasionally feature marketing or product promotion messages. Such instances of marketing are to be expected, as some bloggers generate income by advertising goods and services, and sponsoring blog advertising in this way is not regulated by governments. In this case and others, while marketing might not be made explicit to other users, it is still possible that ostensibly non-commercial accounts are also practising marketing, especially accounts owned by stockmarket-listed firms.
The topics where the highest number of top 10 authorities converge are related to advocacy and awareness. For example, a topic about Diabetes Blog Week in May 2013 gathered 6 of the top 10 authorities: @diabetesalish, @diabetesblogs, @DiabetesSocMed, @Diabetes_Sanofi, @diabetesfacts and @EverydayHealth. In other weeks, the top 10 authorities appear together in topics related to promotion of blogs by diabetics (using the hashtag #dblogs, which appears in 15,901 tweets in the data set), and diabetes social media awareness (using the hashtag #dsma, which is promoted by @DiabetesSocMed and appears in 10,945 tweets).
This directed network has a large weakly connected component of 880 nodes (see Figure 11): the rest of the nodes are either isolated (a handful are connected to only one node) or have since been deleted or blocked. We work below with this network of 880 Twitter users and their follower relationships.
(a) The Twitter follower network of the top authorities. The nodes correspond to the 1000 users with the highest aggregate authority score and the follower network was obtained by mining Twitter in September 2015. The users are coloured according to their interest community, as obtained through the analysis of the follower network using Markov stability. We find seven main communities (there are an additional six very small communities not shown). (b) The authority follower network coarse-grained by the obtained communities. Word clouds of the Twitter biographies of the users in each interest community were computed a posteriori to help establish the thematic content of each of the seven groups, as summarised in the description. The directed arrows reflect the direction of interest between groups, and the width of the arrows is proportional to the number of connections between the groups.
It is important to note that, unlike the retweet networks studied up to this point, the follower network is not ‘conversation-centric’. In a retweet network, the existence of a connection is the result of one user retweeting a message containing the term ‘diabetes’ at least once. In contrast, in the follower network a directed edge indicates an interest by the ‘follower’ to receive information from the ‘followed’ on a more permanent basis. This declaration of interest may reflect more general information beyond the specific retweets about diabetes.
As discussed above, the top 1000 authorities form a heterogeneous group of users, including, among others: public health institutions and foundations; diabetes advocates, researchers, activists and patients; hospitals and medical schools; academic and mainstream publishers, media and personalities; companies. The most central nodes in this follower network according to pagerank55,56 (a proxy for importance) are users with a broad reach and not diabetes-specific:
Centers for Disease Control & Prevention (CDC), @CDCgov (ranked 65 as an authority in the previous section); National Institutes of Health, @NIH (authority rank 111); New York Times-Health, @NYTHealth (authority rank 150); World Health Organization, @WHO (authority rank 88); CDC flu updates, @CDCFlu (authority rank 87); recall information from the US Food and Drug Administration (FDA), @FDArecalls (authority rank 651); news about medical research and health advice from the New York Times, @nytimeswell (authority rank 412); National Public Radio-Health, @NPRHealth (authority rank 336); US Office on Women's Health, @womenshealth (authority rank 93); New England Journal of Medicine, @NEJM (authority rank 67).
The high centrality of accounts relating to health research and information (@NIH, @NEJM, @CDCgov, @WHO, @CDCFlu, @womenshealth), health-specific news media (@NYTHealth, @nytimeswell, @NPRHealth), health advocacy (@WHO) and commercial activities relating to foods and medicines (@FDArecalls) indicates that health in general is a key concern to users in this network. Diabetes is one health concern, but it is not isolated from others.
Beyond a ranking of centrality, it is important to extract information about relevant communities in this follower network, so as to reveal information about who the authorities are and about their interests. A community in a network is usually defined as a highly cohesive group of nodes, with above-expected connections within the group.
57
In directed networks such as the follower network, we define communities in terms of flows of information, i.e. as groups of nodes in which interest or information is retained and circulated. To extract such interest communities, we use the Markov stability framework,42,43 a dynamical framework especially well-suited to extract directed communities.1,44 In this follower network, we found a robust partition into seven main interest communities (Figure 11(b)) and six additional communities with three nodes or fewer. Each of the seven larger communities contains a distinct group of users characterised by domain of activity, background, interests or employer (see supplementary spreadsheet for the full list).
Through this succinct analysis of the follower network of authorities we obtain a clearer global picture of: the general participants in the diabetes-specific discussions analysed earlier; the groups of interests that are present; the audiences involved in the debate; and how they relate to each other. For instance, as Figure 11(b) shows, the largest community (C0), which contains generalist health and medicine agencies, is clearly seen as a reference by all other communities, and especially by the three other large communities: C1 (Diabetes), C2 (Lifestyle) and C3 (Science writers and media). There are other clear asymmetries in the follower-followed relationships: C2 accounts strongly follow C1 accounts (but this following is not reciprocated to the same extent), whereas C2 users do not strongly follow C3 accounts (which largely ignore C2). The connection between C1 and C3 is not strong in either direction. The presence of the UK retailer Tesco as a distinct community (C5) in this network is also noteworthy; Tesco is a high-profile supporter of the charity Diabetes UK (@DiabetesUK, in C1; https://www.diabetes.org.uk/tesco/ accessed on 8 October 2015). As we have noted previously, humour is a prominent feature in our datasets, and it makes another significant appearance here. Community C6 accounts, which contain many comedy and parody accounts, have also been observed in other follower networks obtained from different topical issues. 1 To provide a visual interpretation of the communities found, Figure 11(b) also contains word-clouds constructed from the Twitter biographies of the members in each community. The word-clouds are aligned with our descriptions of the interest communities. In particular, the members of communities C0, C1, C2, C3 and C5 use consistently-themed language to describe themselves. In contrast, the members of the celebrity and humour communities (C4 and C6) are heterogeneous in their self-descriptions, yet clearly identifiable through examination of their usernames. As noted by Beguerisse-Díaz et al., 1 the word-clouds obtained from the biographies can be thought of as an independent annotation or ‘self-description’ of the communities. It is important to remark that the biographies were not used in the analysis of the network.
Discussion
Twitter is a source of information and interaction for a growing section of the world's population. 58 Hence, understanding online conversations around health issues on Twitter (and social media platforms more broadly) is important, especially since such platforms are frequently considered as possible tools in public health outreach and health promotion initiatives.20,21,59–61 Such initiatives are designed based on extended assumptions about the Twitter health landscape, the messages which dominate it and the interactions of users within it. However, detailed data-driven research can help ascertain the validity of such assumptions and enrich our understanding of the online landscape and its implications for population health.
In our study, references to diabetes on Twitter fall into four broad thematic groups: health information, news, social exchanges and commercial messages (Table 2). While these groups define a body of consistent themes, specific messages are largely irregular and variable over time, both in their language and content.
In contrast, there exists an additional group of highly consistent messages that are propagated through popular culture and humour, including jokes, song lyrics or viral ‘facts’. Such messages are consistent in content and style over time as they continue to be posted and shared. Humorous tweets, banter, jokes and social engagement (both supportive and stigmatising) are common in our data. Tweets with such content have a different tone and vocabulary than tweets containing authoritative posts, formal health messages or news headlines. This observation is in line with previous reports, which have found that the most retweeted tweets are emotionally evocative (either humorous or evoking anger).46,62,63 Moreover, we also find that these tweets appear on Twitter more persistently over time than other tweets in the sample (Figure 1). From a health promotion perspective, this highlights a need to consider not only the consistency of slogans or lines in the messages, but also their style and sentiment. The importance of sentiment in promoting dietary choices has also been discussed in the literature.64–66
The abundance of jokes and sexual innuendo about foods and substances that contribute to diabetes indicates at least a basic understanding of diabetes, some of its causes and its connection to blood sugar. The embedding of such fundamental understandings about diabetes in online social media may be the result of health efforts in nutrition over the past decades. This observation is at odds with assumptions that more health education is required to help people to understand the sorts of foods which might contribute to the development of diabetes. Furthermore, such use of humour may imply a sense of powerlessness to make ‘healthy’ choices as users seemingly mock health advice when faced with realities of the food and drink products they encounter on a daily basis. 67
When it comes to the ‘who’ of diabetes on Twitter, our analysis shows a clear separation between the relatively few accounts that produce the most engaging content (authorities), and the broader audiences that disseminate and respond to it (hubs), as seen in Figure 10. Only about 10% of the accounts in our dataset (approximately 120,000) produce tweets that evoke some (heterogeneous) response (Figure 8). Among the top authority accounts, we find a mix of stockmarket-listed firms; public, civil and grassroots organisations; and individuals who have experience as diabetes patients and care-givers. The engagement levels of all authorities are sustained throughout the observation period, and it is difficult to clearly discern between these different groups based on the content, style or theme of their tweets alone. These observations reflect the fact that the health landscape today no longer consists of government and citizens alone. 65 Other entities (such as commercial agents, individual bloggers and automated accounts) also exist and exert influence on the health promotion landscape, and on the conversations taking place around such themes. Their motives are sometimes challenging to discern, and sponsorship arrangements can be difficult to identify or regulate. Similar findings have been noted with respect to Facebook, another social media platform used for health care and communication. 31 Such entities, which are assumed by health authorities to be extrinsic to the healthcare arena, need to be acknowledged and considered in successful strategies for health promotion.
Our results show that the role of hubs in disseminating information is less persistent over time than the role played by authorities in generating information. Hubs are generally far less transparent about their identity. Some accounts, for example, claim to have medical expertise, but these claims cannot always be verified. As a result, it is difficult for Twitter users to be ‘informed citizens’ and discern legitimate from misleading or discredited information, or a bona-fide health expert from a social-media expert, or a marketer with business motivations from a marketer with public health ones. Establishing the credibility of an account by the number of messages, followers or even through the published user profile, for example, can therefore be misleading. This poses challenges to the use of Twitter as a health promotion platform, and requires the use of sophisticated techniques (e.g. collaboration of health professionals with practitioners of network and data science). Further research and engagement with ‘real’ people, and not simply their virtual online personae which represent them, is necessary to elucidate the expertise and intentions of users generating some of the key diabetes-related content on Twitter.
This research has implications for health policy makers and health promotion practitioners. We show that key authorities in relation to diabetes on Twitter are not simply those with accredited and formally recognised health expertise, but also bloggers (men and women), patients, celebrities, advocacy organisations, stockmarket-listed firms, news media and automated accounts. There are diverse stakeholders that use Twitter; even when limited to the English language, these accounts originate from a range of countries (notably, several Nigerian accounts have prominent roles as both hubs and authorities). It may be that establishing long-term collaborations with the most influential users, as well as enhancing the connections between different communities of users, may be more effective health promotion strategies than running short-term government-led campaigns and slogans aimed at informing people who have (or who are at risk of developing) diabetes. In addition, it is important that policy makers understand what social media users already know about health before new initiatives are introduced: simply telling users what they already appear to know, for example, about which foods contribute to diabetes, may hinder health agencies' impact and credibility.
Our findings also have implications for programme evaluation, where ‘number of tweets/followers’ is commonly assumed to equate to ‘impact’. Other metrics that leverage the structure of the network of interactions to consider relative impact, or a sustained high-centrality presence over time (e.g. via centrality metrics such as hub-authority scores) may more closely reflect the reality of Twitter use for health purposes.
The health information landscape on Twitter is complex, and it cannot be assumed that people can easily discern ‘good’ and ‘bad’ information. Our observations echo previous reports that there is more information available to consumers than they have the capacity to process and understand.68,69 In this context, public health approaches and messages that simply aim to ‘inform’ the public might be insufficient in themselves, or even be counterproductive as they make a complicated cacophony of messages even busier. This is particularly relevant for health policy makers. For instance, information that is disseminated by bloggers, stockmarket-listed firms or automated accounts may be in line with broad health recommendations (and indeed may provide a valuable service to users), but without clear distinction from ‘legitimate’ health advice, such information might equally push particular aspects of a commercial agenda that could lead to harm or greater health costs in future. In this case, public health agencies may have to develop novel approaches to ensure that the electronic health information landscape is one that promotes healthy citizens and not only sweet profits.
Data statement
The Supplementary Spreadsheet that accompanies this article, with the lists of the top users and topic keywords is available from the publisher's website. The IDs of the tweets used in this research and the supplementary spreadsheet can be downloaded from the ReShare UK Data Service repository.70
Footnotes
Acknowledgements
We thank E. Garduño for useful advice and discussions on how best to gather and process the data. We thank H. Harrington and S. Yaliraki for fruitful discussions and comments on the manuscript.
Contributorship
MBD and AM researched literature and conceived the study, carried out quantitative (MBD) and qualitative (AM) data analysis, and prepared the first draft of the manuscript. GGH and MBD collected the data. MBD, AM, MB and SU wrote the paper. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
Not applicable.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MBD acknowledges support from the James S. McDonnell Foundation Postdoctoral Program in Complexity Science/Complex Systems Fellowship Award (#220020349-CS/PD Fellow). MB acknowledges funding from the EPSRC (grant numbers EP/I017267/1 and EP/N014529/1).
Guarantor
MBD/AM.
Peer review
This manuscript was reviewed by Tim Robbins, University of Warwick and Dhiraj Murthy, Goldsmiths, University of London.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.