
Abstract
Recommender systems are dynamic systems used across digital platforms that personalize curation based on the individuals’ history of interactions. News recommender systems (NRSs) can enhance personal relevance and loyalty while reducing the power laws of curation. However, NRSs also denote a displacement of editorial agency and control due to technical complexity and limited transparency in personalized exposure. This study aims to bridge the gap between algorithmic curation and editorial control through a conceptual exploration of dashboards as a dynamic evaluation approach allowing translation between the personalized exposure and the situated realities of editors. We demonstrate the possibilities and limitations of dashboards by configuring three theoretically driven views on news recommendations based on a dataset containing personalized recommendations presented to audiences of a Scandinavian tabloid news site. The theories used are agenda-setting, uses and gratifications, and news repertoires. The construction of dashboards informs a discussion about how theoretical ideas about news use are informing for how evaluation approaches are pre- and configured, but also their potentials of refiguring the editorial control in algorithmic curation.
Introduction
The threshold for media organizations to get involved with recommender systems has decreased in recent years with the growing number of tools, models, and trained data scientists. The rapid spread of artificial intelligence (AI) applications offers new opportunities to augment human performance (Shneiderman, 2022) but also sparks discussions about the consequences of personalized recommendation, such as unfair conditions for competition, biases embedded in training data, or the logic embedded in the models. Despite a curious consensus among tech companies and legislators about the need for ethical, fair, and responsible AI, the integration with everyday practices still appears problematic (Seppälä et al., 2021). Kitchin (2014) points to an epistemological gap between data scientists’ theory-agnostic and domain-independent work, where prediction is the goal. The epistemological contrast is prevalent in the implementation of recommender systems in news which essentially substitutes (parts of) the situated editorial practices guided by human intuition with statistical models calculating relevance by past behavior of users. While editorial knowledge and values are considered in the design of recommender systems (Møller, 2024), editors have few options to control and monitor recommenders in action. Monitoring performance is especially complicated when each user potentially receives a unique representation, meaning that most aspects of quality assurance must rely on personal experiences or abstracted measures of model accuracy. That stands in contrast to traditional editorial curation practices and constraints on editorial accountability. We take this tension as a starting point for exploring dashboards as data configurations that invite users to draw particular inferences and interpretations in how measures are selected, organized, and portrayed.
Adding to an emergent body of research aiming to ensure editorial accountability and control of AI news applications (Stray, 2023; Vrijenhoek et al., 2022), we conceptually explore the potentials and limitations of dashboards as a mediating device to monitor and control recommender systems. Based on a dataset containing 32.720 Danish news readers’ exposure and interaction with three types of news recommender systems, we configured a dashboard presenting three views on news recommender systems drawing on classical media theories: agenda-setting, uses and gratifications, and a repertoire view. The dashboards do not aim to evaluate the systems nor present a directly applicable solution. Rather, it is to expose implicit theories embedded in recommender system evaluation (e.g., Seaver, 2022) and map out a potential path that aligns closer with the dynamic aspects of the systems and the situated realities of news editors and audiences. Through the three different dashboard views, we demonstrate how it is possible to tell vastly different stories about the performance of recommender systems based on the same underlying data. Following the analysis of these different dashboard perspectives, we discuss the possibilities and limitations of dynamic evaluation and suggest fruitful ways forward for academics and the industry to further develop dashboards as tools for analysis, vehicles for storytelling, and, consequently, devices for decision-making.
Concretely, this article contributes to existing research on three levels. Theoretically, we forward an understanding of dashboards as a dynamic method for editorial monitoring of recommender systems and public auditing. In contrast to momentary evaluation approaches comparing model performance by selected measures, dashboards provide insight into how users experience and interact with the personalized feed and take the changing landscape of recommended content into account. On a methodological level, the article advances an understanding of dashboards as configurations of data sources, statistical techniques, and visualization conventions that shape the stories editors and other users tell. We demonstrate through the empirical case how the same data can be represented in alternative dashboards that afford vastly different interpretations of the recommender systems. Lastly, the article offers reflections on how to turn the theoretical and methodological challenges of AI evaluation into practical tools to think with for advancing our understanding of recommendations in – and beyond – the news industry.
Evaluating news recommender systems
A global survey about AI in journalism from 2019 stated that 45% of newsrooms are motivated to implement AI to deliver more relevant content to users (Beckett, 2019). Recommender systems are a type of AI system used to help people navigate information-intensive digital services, such as social media, e-commerce sites, and streaming platforms. Recommender systems reduce users’ information load by ranking and filtering items that match their history of interactions (Burke et al., 2011). Recommender systems are a common feature on news aggregation platforms and newsletters but are also increasingly used by digital news media to curate daily agendas. Such systems offer a promising potential for matching between users and articles more effectively and could extend the relevance and reach of the journalistic content while enhancing user engagement and customer loyalty (Bodó, 2019; Gulla et al., 2021).
From a democratic standpoint, news recommender systems are, however, controversial. Personalized news exposure taps into narratives of news tabloidization (Spillane et al., 2020) and raises serious concerns about reducing exposure diversity, reinforcing biases related to popularity, audience selectivity, and fragmentation (Abdollahpouri, 2019; Pariser, 2011; Rahwan et al., 2019). Yet, studies on news recommender systems have failed to detect such effects empirically (Möller et al., 2018), and instead point to a more nuanced story about effects being diverse and distributed (Bodó et al., 2019) as well as contingent on fluctuating data flows and positioning in the news flow (Einarsson et al., 2024).
On a more concerning note, studies point out that the adoption of recommender systems denotes a shift in organizational roles and responsibilities where the agency is moved from the editorial office to the design room (Schjøtt Hansen and Hartley, 2021). Studies have addressed the editors’ perceived opportunities (Bodó, 2019; Smets et al., 2022) and examined how editorial concerns are voiced in design processes (Møller, 2024). In a recent study, Hartley and Thylstrup (2024) point to the epistemological challenges occurring when computer scientists seek to operationalize “fluffy” editorial or ethical values, which, from their perspective, adds layers of complexity to their workflow. Where prior studies have pointed to the limited involvement of editorial staff in recommender system design and the epistemological differences between the domains, we intend to highlight that editorial agency and control of algorithmically mediated news exposure are conditioned by the introduction of dynamic evaluation approaches which can translate between the abstracted system logics to the situated realities of editors and users.
Recommender systems are conventionally evaluated through offline evaluation, online controlled experiments, and user studies. Survey studies on evaluation methods for recommender systems find that offline evaluation is the most common approach and is used to gain an understanding of the predictive quality of one or more algorithms using a baseline dataset (Beel et al., 2013; Raza and Ding, 2022; Zangerle and Bauer, 2022). Measures for offline evaluation dominantly focus on model accuracy, precision, and recall (Beel et al., 2013) but recent research has contributed to operationalize “beyond accuracy” metrics that include coverage, serendipity, and diversity (Diakopoulos and Koliska, 2017; Ge et al., 2010; Helberger et al., 2018; Kruse et al., 2024; Raza and Ding, 2022; Vrijenhoek et al., 2021, 2022). Assessing model performance beyond accuracy is a step toward selecting models based on democratic values and editorial profiles. Still, extracting knowledge from model evaluation depends on a static data foundation and technical expertise to decipher the output.
Online evaluation appears less frequently in scholarship on recommender systems but has the strength of connecting models with dynamic real-world data (Bauer et al., 2023; Zangerle and Bauer, 2022). In addition to prediction accuracy, online experiments include measures of user acceptance, such as Click-Through Rates (CTR), clicks, purchases, or user satisfaction from questionnaires. For instance, a Nordic study about news recommender systems reports increases in clicks, time spent, and total visits from a three-week online experiment (Gulla et al., 2021). While reported less frequently, controlled online experiments are a common practice for data scientists to compare models and make design decisions about the size and scales of objects on dynamic websites (Kohavi et al., 2020). Relatedly, a body of qualitative user studies also exists, providing insights into experiences of recommendations and assessing the appropriateness in the context of use (Harambam et al., 2019; Monzer et al., 2020; Van den Bogaert et al., 2022). Instead of providing detailed insights into the effectiveness of recommendations, qualitative user studies emphasize users’ experiences and meaning-making but also fundamentally question the assumptions made by reducing news interest and preference to behavioral traces (Swart, 2021).
In sum, the existing literature on news recommender systems reflects a rich methodological repertoire to assess potential and consequences in the design of systems and capture stakeholders’ perceived opportunities and concerns regarding the implementation. The scholarship identifies two particular challenges relevant to our study: First, how can recommender systems be evaluated when each user potentially has a unique view? Personalized exposure denotes a fundamental change compared to editorial news curation practices, both by prioritizing exposure by statistical calculation of personal relevance and by editors not being able to see what individual audiences are exposed to. Also, this obscures representations when aggregating or averaging exposure. The second challenge relates to the dynamic nature of recommender systems (Seaver 2019), where output is directly impacted by fluctuating news flows of news production and consumption. In short, how can evaluation methods account for the changing data foundation caused by fluctuating flows in news production and use? In line with scholars examining algorithms in editorial practices (Stray, 2023; Svensson, 2022), these challenges illustrate how news recommender systems are not merely about the technical design but also require ongoing attention, care, and maintenance in order to fulfill their democratic mission of mediating citizens access to and knowledge of societal events. Hence, an important step towards bringing ethical principles of responsible and fair adoption of AI systems into everyday practices (Seppälä et al., 2021) includes methodological development, which can account for the fragmented and dynamic nature of recommender systems.
Moving from the concrete to the abstract
Among the central qualities of data sciences is the possibility to dynamically shift perspectives from abstract representations to specific instances and vice versa (Aradau and Blanke, 2022; Kitchin, 2014). Depending on the data at hand, the trained data scientists can, by a few commands, view the performance of their systems at large, the performance of each article, or the log of specific articles exposed to an individual or a group. This information feeds back to the engineers’ heuristic model of how people behave and how recommender systems might accommodate use. As Seaver (2022) points out, such practices imply a behavioral theory where the central goal of the model is to capture and sustain attention. We contest such a pragmatic and empiricist approach as it disregards the normative democratic role of media and places responsibility for curation on technical domains. As an alternative to the heuristic approach, existing theories related to media exposure and effects resonate with traditional editorial considerations and provide reflections on theoretical selections. In the following, we outline agenda-setting theory, uses and gratifications theory, and repertoires as relevant perspectives to monitor and control news recommender systems.
Agenda-setting theory, originally devised by McCombs and Shaw (1972), is a mass communication theory arguing that the role of news media is to add salience to topics of public attention. According to the agenda-setting theory, news exposure is a proxy for salience, which helps citizens navigate which topics, events, or discussions are the most important at the moment. Agenda-setting theory assumes a media-centric perspective, attending the analytic focus on media exposure, not consumption. That is useful to understand how media represents public matters and assess the fairness of media exposure. In the agenda-setting terminology, recommender systems can be described as intermediaries (Harder et al., 2017; Trielli and Diakopoulos, 2022) positioned in between the actors setting agendas (e.g., publishers and editors) and the audiences exposed to them. In the evaluation of recommender systems, the agenda-setting perspective offers a media-centric position that analytically highlights salience in terms of the visibility of agendas, actors, or topics and how recommender which recommender systems potentially can reorder (Bucher, 2012) and agenda diversity aligning with the normative ideals of news media (Helberger et al., 2018; Vrijenhoek et al., 2022).
In contrast to the agenda-setting stipulating the media's role, uses and gratifications (Katz et al., 1973) was introduced as a theoretical framework recognizing the agency and competence of audiences to select and attribute meaning to their media uses. Audiences become users who are active and goal-oriented in their news consumption, seeking to fill diverse needs—be it social, informational, or entertainment. In that sense, news media is not about representing a particular view on public events but presenting relevant opportunities for users to interact with. Resonating with current perspectives on engagement measures in news and journalism (Ferrer-Conill and Tandoc, 2018), quality can be considered in terms of various types of measures for engagement, such as clicks, dwell time, or scroll depth, as well as the ways in which contextual factors influence these. Although we recognize that engagement relates to much broader contextual and affective dimensions (Dahlgren and Hill, 2022), measurable behaviors can provide insights into intensity and depth of use.
The final view takes a news repertoire perspective—a perspective that embodies a richer conception of audiences that connects behavioral characteristics with the social function the news serves in users’ everyday lives (Hasebrink and Domeyer, 2012). The repertoire perspective acknowledges that users tend to have habitual patterns of media use that consist of the same media channels and content genres (Makhortykh et al., 2021). News services often take place in “checking cycles” (Costera Meijer and Groot Kormelink, 2015), where users routinely run through a number of different apps and websites to check up on the lives of their friends and the world at large. While such behaviors are deeply personal, users’ repertoires are also associated with the characteristics of the social group they belong to (Peters et al., 2022; Swart et al., 2017). Among the strengths of a repertoire perspective is its recognition of a broader media sphere than the individual media at hand. However, given the limitations of our case, we cannot analyze media use across domains but instead highlight repertoires as a more nuanced conception of audiences that views audiences, their characteristics, and practices in connection with the content-related features suggesting the meaning they pursue.
In sum, the three perspectives described imply distinct conceptions of news media and its users, which have consequences for the analysis and possible interpretations. The advantage of a theory-driven approach to scaling between the micro and macro levels of analysis is not that the theories are comprehensive but rather the opposite. Each of these theories poses known strengths and limitations, which open up discussions about the intentions of recommender systems and how well they achieve claimed goals.
From static to dynamic evaluation
Dynamic monitoring of performance is common in news rooms, where journalists, editors, and managerial staff have access to frequently updated reports on various measures of audience engagement, content performance, and commercial performance. The so-called editorial dashboards have gained attention in journalism research for their deep integration into everyday practices (Kristensen and Hartley, 2023). Dashboards afford editors to understand audiences’ needs and interests (Ferrer-Conill and Tandoc, 2018) but also have a performative capacity to generate internal competition among staff, encouraging them to optimize content for simplistic metrics like clicks, reading time, or customer conversion (Christin, 2020; Petre, 2021).
The qualities, however, of dashboards reside in the ability to provide a dynamic real-time representation of ongoing matters “at a glance” (Few, 2006). Taking a genealogical approach, Tkacz (2022) describes the evolution of the conception of dashboards from the original intent for dashboards as a protective feature on horse carriages to car displays and towards being an information visualization tool informing managerial decision-making. Tkacz highlights dashboards as an approach to formatting relationships between “people and things, modes of perception, gestures, spaces and so on” (p. 92), which is activated in response to external actions (e.g., a speedometer is zero until the car is moving). In other words, dashboards are designed with an activity and a reader in mind who can scan the display with minimal effort and adjust actions accordingly in a recurring feedback loop. Finally, Tkacz argues that dashboards imply a separation where the reader is distanced from the activity she is monitoring through measures, figures, and icons. Interestingly, this corroborates with journalism scholarship criticizing the reduction of the rich and diverse needs and interests of audiences to clicks (Kormelink and Meijer, 2018), but is also somewhat different from its uses to monitor personalized exposure, which, from an editorial perspective, is largely non-transparent (Diakopoulos, 2015) and external to their agency (Schjøtt Hansen and Hartley, 2021). Hence, despite the bleak reputation of dashboards in journalism, this study is interested in questioning whether and how dashboards could further editorial agency in an algorithmically curated reality.
This aim connects to critical data studies which recognize that dashboards are not a mirror but a translation of reality (Kitchin and McArdle, 2017) that configures data into stories (Jarke and Macgilchrist, 2021), but also that certain narrative structures can provide constructive alternative future vision (Hockenhull and Cohn, 2021). Extending the narrative theory of Ricœur (1984), dashboards can be seen as configurations that organize and stabilize a vast array of dynamic information into coherent narratives about user behavior. Here, dashboards both require a preconfigured understanding of how to interpret the meaning of data organized in charts and statistics and simultaneously invite the user to draw inferences and construct explanations for future, the refigured interpretation. In these steps, which Ricœur calls the “three moments of mimesis” (Ricœur, 1984, p. 53)—prefiguration, configuration, refiguration—the narratives translate between the fictional world (in this case, of abstract objects such as engagement measures and trending news stories) and the real world (of concrete user actions and editorial decision making). The dashboards themselves constitute a configured interpretation where the designers have selected aspects of the processed data, leaving most of it out, and organized the data into charts and statistics that congest, compare, rate, and rank entities. In this way, we argue the dashboard performs much the same function as the narrative in fictional and historical accounts do. Whereas narrative conventions such as actors and temporal ordering are essential for telling a story with words, statistical conventions such as visualizations, recognizable categories, and established measures are the cornerstone for telling stories with data. In order to shift attention from prediction accuracy towards narratives closer to editorial realities, the following presents a case where real-world data about interactions with news recommendations are structured by traditional media theories.
Methodological approach–building dashboards
The central aim of this research is to push thinking of recommender system evaluation from strict measures of accuracy towards the dynamic domains the systems interact with. Methodologically, we connect to work on speculative dashboards (Hockenhull and Cohn, 2021) where dashboards not merely reflect a particular reality, but process-oriented artifacts that can be constructed and used to explore ideas. Given the domain of application is news, we specifically explore how recommender systems can be adopted to reflect editorial realities. Hence, based on a large data set containing users’ exposure to and interactions with news recommender systems, we constructed three dashboards reflecting distinct perspectives on editorial thinking. These are agenda-setting, uses and gratifications, and news repertories. Accordingly, the dashboards are prototypical operationalizations – or configurations, as we return to below—of different ideas about the value of news content and audience practices.
This research is conducted as part of a practice-based research project in collaboration with a national news organization aiming to fine-tune news recommender systems to a Scandinavian news context in a responsible way. Prior to this research, the project had offline tested and compared several recommender systems on a national tabloid news site. The highest-performing recommender systems in terms of accuracy, diversity, and computational efficiency were also included in a four-week online experiment to assess the performance of the recommenders and estimate their possible effects on audience news exposure and reading flows. The experiment was coincidentally performed during a national election. In this study, we use the data material generated from the online experiment not to assess performance or implications but rather to configure representation that can inform ongoing editorial decision-making.
The raw data includes the news exposure and consumption of 32.720 logged-in users, the type of exposure, and meta-data about articles, classifications, and user demographics. The data also contains information about the “mode of exposure,” namely, whether the exposed content was curated through editorial curation, non-personalized recommendations (article similarity), or personalized recommendations. The personalized recommendation involves collaborative filtering and content-based filtering. Collaborative or social filtering is a personalized mode of exposure recommending news articles based on similarity in news reading patterns with other readers calculated by matrix factorization (Raza and Ding, 2022). By contrast, content-based filtering is computed based on the similarity between content features in users’ reading history and attributes in the content catalog based on the NRMS technique (Wu et al., 2019). The non-personalized recommendations include exposure to semantically similar articles using article metadata, such as title and abstract text. Thus, the editorially curated mode serves as a form of baseline comparison to the algorithmic recommendation underlying the three other models. The exposure column in Table 1 shows how many times each mode was exposed to users.
Overview of the mode of exposure and item lists.

The analytic perspective we present is fixated on different algorithmic techniques to recommend content whereas several other factors also impact the performance of recommendations. That is, for instance, positioning in the news flow and the selection criteria for including an article on the item list. It impacts a great deal whether articles behind a paywall are included or not. In practice, context-specific decisions regarding positioning, article lists, and function of the recommender is expected to be included.
Figure 1 shows the general trends across the period in which data was gathered. The figure reflects a gradual increase in exposure and consumption leading up to a national election held on November 1st but also weekly fluctuations. In the dashboards presented in the following section, the temporality is fixed to a daily representation. This supports the aims of representing the ways that news recommendations manifest in concrete situated exposure and experiences at the moment but constrains the possibilities for general trends over time.

The fluctuating news flow.
Instead of searching for generalizable impacts of recommendations, our approach resembles critical design approaches to dashboards (Hockenhull and Cohn, 2021), considering dashboards as a critical design artifact that encompasses decisions about how reality is condensed to simpler and intuitively understandable narratives. Similarly, we take the dashboards as the center of analysis and ask how data is rendered intelligible and made actionable through the moment of configuration. In the following, discuss our process of (pre)configuration of dashboards monitoring news recommender systems, as well as speculations about how such a view can refigure editorial knowledge of news recommender systems. Concretely, by drawing on real-world data, we constructed a dashboard allowing comparison of modes of exposure by three views relevant to monitoring from an editorial perspective: agenda-setting, uses and gratifications, and repertoires.
Configuration of dashboards to monitor recommender systems
Two dominant criteria were especially considered when developing the dashboards. The first included the acknowledgment of diverse knowledge editors tap into when making content-related decisions. Thus, the dashboards are designed to account for the performance of recommender systems in multi-perspective monitoring of news recommendations organized into three views: the agenda-setting view, the uses and gratifications view, and the repertoire view. The multi-perspective acknowledges that editors do not exclusively make decisions based on audience behavior, commercial incentives, or democratic ideals but rather a combination (Ferrer-Conill and Tandoc, 2018). Yet, each of the views draws on a specific theoretical foundation and ideals about the function of news and journalism, thus also what counts as editorially relevant knowledge. The second criterion included the move between the abstracted metrics and concrete exposure. The move between the abstract and the concrete is a central opportunity for the type of reasoning enabled by the current generation of datafication (Aradau and Blanke, 2022) but is typically not included in dashboards, which have been criticized for stabilizing knowledge on simple metrics. This turn is important for establishing a connection between metrics like CTR, diversity, and popularity and the actual exposure experienced by users which is particularly troublesome in personalized environments. Finally, the following analysis should not be conceived as a directly employable dashboard but rather as an example of an evaluation approach to recommender systems that configure data dynamically into narratives that denote ideals of journalism, situate them in practices, afford agency, but also possess uncertainty and limitations.
The agenda-setting perspective
Agenda-setting focuses on the role of media in ordering public agendas. The focus of evaluation from an agenda-setting perspective is to compare how the recommenders align with editorial content priorities. The aggregating variable, therefore, is not what people click on, but rather salience measures in exposure. Table 2 illustrates how agenda-setting can be operationalized on different levels of abstraction. On the most abstract level, agenda-setting can be presented in aggregated variables such as coverage (% of catalog covered by recommender) and diversity (evenness of the distribution across categories). However, agenda-setting operates naturally on an intermediary level where exposure is aggregated across various content classifications or features or, more concretely, where exposure is summarized by each article.
Possibilities for concrete and abstract visualization.

Representations as composed in Figure 2 provide an overview to compare whether recommenders are over- or underexpose certain content categories. Figure 2(a) visualizes the percentage of exposure by each of the models across the five most frequent content categories. Interestingly, the bar chart shows that the editorially curated exposure—not recommended in Figure 2—adds more salience to Celebrity and entertainment and sports in comparison to the recommender systems. Instead, collaborative filtering overexposes Crime and catastrophes, and content-based filtering overexposes Culture in comparison to editorially curated exposure. On a more granular level, Figure 2(b) compares the ranking of the most exposed articles by collaborative filtering and editorial curation. Comparing the lists shows that there is no direct overlap, confirming that recommender systems affect the exposure. The editorial curation adds salience to the top story of the day, namely a recently published book by a high-standing Danish intelligence officer and his critique of the government in office and the latest news of the ongoing election. Collaborative filtering appears to add priority to a political scandal involving the Danish politician Søren Pape and his unsuccessful run for office. Both types of exposure also expose softer news articles about weight loss (editorial), sex, and “how you can delay your electricity bill,” whereas collaborative filtering appears to expose a broader range of societal agendas.

Visualizing differences of agenda-setting by recommender model. (a) The figure to the left displays the distribution of exposure by each model across five content categories. (b) The table on the right displays ranked lists of the most frequently exposed articles by collaborative filtering and editorial curation.
Also related to the agenda-setting function of media is the diversity of media exposure. Diversity is a complex concept with variations in how it is approached and measured (Loecherbach et al., 2020; Vrijenhoek et al., 2021). According to Napoli (1999), diversity can be approached as a structural condition of media sources, the content and its framing, and the exposure of news on a single or across channels. Vertical exposure diversity is the diversity of content on a channel, which can be an indicator of audience polarization (Napoli, 1999) and a central measure to assess the democratic implications of recommender systems (Möller et al., 2018; Vrijenhoek et al., 2021).
The type of exposure diversity that can used to analyze the real-time performance of recommender systems is the evenness of distributions of exposure across categorical variables. In Figure 3, we demonstrate diversity measures computed across all articles exposed, topical categories, and actors, and averaged topic diversity per user. Also, as recommender systems personalize exposure, average topic diversity is included which computes topic diversity per user and presents the average. The Gini index is a statistical technique commonly used in economics to indicate economic inequality in a society. Gini results in a number between 0 and 1, where 0 represents perfect equality and 1 represents perfect inequality. Translated to the dashboard a Gini index on 1 for topic diversity means that only a single topic is exposed. In comparison, Shannon's diversity index is more commonly used to assess exposure diversity (Loecherbach et al., 2020), which accounts both for the richness (i.e., the number of features exposed) and the evenness of the composition. The higher the Shannon index, the more diverse the exposure is.

Metrics for exposure diversity.
Comparing the measures displays both similarities and differences between the results depending on statistical technique. Notable variations are that editorial curation is reflected as more diverse when computed by the Shannon index compared to the Gini. When comparing actor diversity across the modes of exposure, editorial curation is the least diverse when computed by the Gini measure and the most diverse with the Shannon H’ index. Similarly, when comparing topic diversity with average topic diversity, differences also occur. When aggregated across the complete material, content-based filtering and article similarity showcase more variety, whereas when averaged per user, content-based filtering appears more diverse. In other words, the diversity index is a measure vulnerable to the statistical technique used, the classification it is aggregated across, and how the data is composed. Hence, from an editorial perspective, diversity can provide important information to assess the quality of recommendations. Yet, given the ambiguous nature of diversity indexes, additional visualizations, such as Figure 2, are required to support translation into the editors’ realities.
The uses and gratifications perspective
The uses and gratifications theory focuses less on what media do to people but rather on what people do with the media. Translated to ongoing evaluation of news recommender systems, the uses and gratifications perspective can provide insights into what users find valuable by using behavioral input as a proxy. Available behavioral measures include clicks, Click-Through Rates (CTR), and dwell time per click (readtime). Compared to diversity measures, behavioral measures are more intuitively interpretable. Figure 4(a) shows that article similarity performs best in terms of CTR and readtime and that collaborative filtering outperforms content-based filtering and editorial curation. Figure 4(b) and (c) also illustrates how uses can be considered in relation to contextual variables. Figure 2(b) shows CTRs in relation to positioning on the news site (on the front page versus on article pages). The table shows that users are more likely to click recommendations on article pages, whereas editorial curation is more likely to be clicked on the front page. This could indicate different uses of the front page and article pages. On the front page, users might prefer a broader editorial curation, whereas when scanning or reading an article, they appear more prone to diving into similar content (article similarity) or pursuing their personal interests. Moreover, Figure 4(c) shows that CTRs are generally higher on mobile devices where users are particularly prone to click personalized recommendations.

Uses and gratifications dashboard. Selected information includes (a) a table comparing the type of exposure across clicks, exposure, CTR, and readtime, (b) a table comparing CTR by positioning in the news flow, and (c) a boxplot comparing CTR across the device used by the participant.
Comparison of models on behavioral measures provides a means to evaluate performance but also reflects on the function different types of exposure serve in users’ reading sessions. At a more granular level, Figure 5 displays ranked lists of the most clicked content by three different modes of exposure. The lists suggest that across all types of exposure, explicit content is frequently clicked. The lists have a common tendency that users frequently click on content related to sex (e.g., “Vækker forargelses: Smider tøjet med 18-årig datter // Arouses outrage: Drops clothes with 18-year-old daughter” and “Raser mod Brittney: hun bodyshamer // Rases against Brittney [Spears]: She body-shames”) and scandals (e.g., “Findsens bombe // Findsen's bomb” and “Sender skjult stikpille til fyret FCM-træner // Launch covert criticism at fired FCM [soccer] coach). Content figuring on the collaborative filtering and article similarity lists have relatively high CTR, editorial curation can also drive clicks towards important content, such as an article providing the overview of the election, although its CTR is fairly low (0.5%). The popularity of softer news items, such as celebrities, entertainment, and explicit content over hard news, such as politics, even during an election, is in line with previous research (Bright, 2016; Ørmen, 2019).
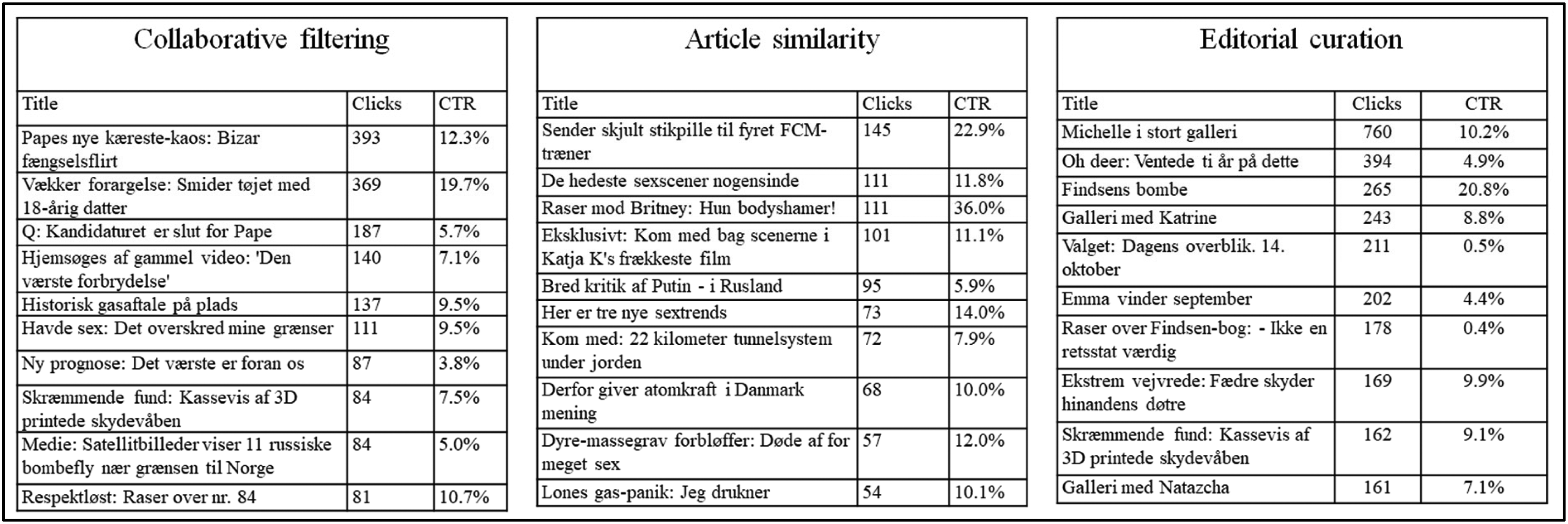
Top lists for modes of exposure (collaborative filtering, article similarity, and editorial curation) arranged by click frequency.
In comparison to the agenda-setting perspective, the uses and gratifications view on recommender systems offers a more laissez-faire perspective on content relevance where the quantity of engagement is attributed more than the quality of content. This resonates with advertisement-based business models in journalism (Hindman, 2018). While our configuration of engagement is rooted in click rates, more direct commercial indicators, such as conversion rates and clicks on paywall articles, are natural extensions of this behavioral perspective. A click is an ambiguous measure that can be attributed to several meanings (Kormelink and Meijer, 2018). However, the engagement perspective is productive, in this case, to disclose indications of where in the news flow recommender systems might contribute constructively.
The repertoire perspective
Like uses and gratifications, the repertoire perspective recognizes that users approach media with different motives and use different media for a variation of purposes. The repertoire perspective recognizes news reading as a practice, thus also residing on habitual patterns and preferences, but also influenced by socio-economic conditions (Hasebrink and Popp, 2006). Although, behavior on a single platform cannot capture the complexity of practices across platforms (Taneja et al., 2012), it can provide insights into how users’ patterns of preferences are served by different types of news exposure. Thus, we adopt the repertoire perspective similar to Makhortykh et al. (2021), grouping users into preference groups to demonstrate how recommender systems perform across different groups of news users. These groups are defined by the news topics they tend to interact with the most on the site.
In order to capture different repertoires, we conducted a clustering analysis, grouping users into preference profiles. We employed hierarchical clustering on a dataset involving 41,000 users and their proportional distribution of their clicks across nine content categories. Only users who had clicked ten or more articles in the period leading up to 2022-10-14 were involved. We use gap statistics to determine the number of clusters which is appropriate for hierarchical clustering (Tibshirani et al., 2001) which resulted in five distinct clusters.
Viewing audiences as belonging to a particular group of users affords analysis of how news recommender systems cater to the needs of different groups of audiences. For example, the table in Figure 6 illustrates that collaborative filtering works better for some clusters (notably, Crime and Politics & Society) than for others (especially Culture & Human Interest). As these are the raw CTR percentages, they should be interpreted more as illustrative than statistically conclusive. On the more granular level, Figure 7 displays how the repertoire perspective also opens to analyzing exposure and consumption of individual articles mediated by a particular mode of exposure but across different clusters of users. This form of analysis can contribute to understanding users’ preferences but also to disentangling group-based differences in exposure.

Results of cluster analysis and impacts on exposure. The table displays the identified clusters, the cluster size, and the demographic composition. The table also shows the CTR across personalized and editorially curated exposure. The figure shows the composition of users’ clicks across content categories (right side) and the exposure mediated by systems (left side).

Top lists ordered by clicks for collaborative filtering across three of the clusters (crime, culture and human interest, politics and society). The table displays the title of the article, number of clicks, and the click-through rate of the article.
In sum, the repertoire perspective provides interesting insights into the diverse functions news recommender systems can have in relation to confirming or extending existing interests, but it is also complex to measure by its nuanced understanding of user behavior that is driven both by purpose and habits. Notably, the perspective demonstrates that not one recommender system fits all users. This illustrates that the differences in content preferences captured by the clusters map into different types of recommendations. Some, especially the Culture & Human Interest users, are more aligned with editorial priorities, whereas collaborative filtering works better for the rest (measured by CTR). Like for the other perspectives, the simplest form of recommendation—article similarity—produces among the highest CTRs across clusters suggesting that content preferences might not be as stable as the repertoires suggest but more dependent on interests in the moment. That is rather conjectural, however, and thus a topic for further research. Nonetheless, the repertoire perspective offers a different view that emphasizes differences in user preference and the suitability of various recommender systems for satisfying or challenging these preferences.
Re-configuration: representations that empower actions
Thus, the three views give different accounts of how recommender systems serve user preferences as well as the journalistic goal of the news organization. In the agenda-setting view, all recommenders exposed users to a diverse menu of content on par, or to some extent superseding, editorial curation. Through the uses and gratifications perspective, we saw that collaborative filtering and, in particular, similar article recommendations seemed to align more with user interests. Likewise, the repertoire view demonstrated a variation of this with some differences across clusters, suggesting that news recommendation is not a one-size-fits-all, at least in this empirical case. Although the primary goal of this article is not to compare recommendation algorithms systematically or statistically, it is noteworthy how well the simplest of automated recommendations, the similar article approach, seems to perform better on engagement measures than the personalized recommendation approaches and editorial curation (Figure 4). Taking into consideration how costly it is to develop, deploy, and maintain recommender systems, this is a highly interesting indication for further research.
The central problem that this analysis deals with is that recommender systems when introduced into a journalistic context, introduce dynamic and algorithmically governed news exposure, which reduces transparency and editorial control. This is not because recommenders are particularly complex and black-boxed technologies (Pasquale, 2015) but rather because they differentiate exposure on scale, making it practically infeasible to trace what is exposed to whom. Where common approaches to evaluate recommender systems are by metrics of precision, accuracy, click-through rates, conversion, or, most recently, diversity (Raza and Ding, 2022), our analysis attests that metrics in isolation are insufficient to understand the editorial implications of recommender systems. The insufficiency of current evaluation approaches relates both to the reduction of complex analysis into abstract metrics and also the need to account for the dynamic nature of recommender systems. In the context of the discussions concerning the assessment of normative values in recommender systems (Stray et al., 2024; Vrijenhoek et al., 2021), we suggest that dashboards offer a dynamic approach to assess performance and impacts of recommender systems on an ongoing basis. In practice, the ongoing monitoring could enable editorial staff to gain an intuitive understanding of news exposure and consumption mediated by recommender systems as a precondition to engage in technical discussions and to take responsibility for the exposure on the site. The opportunity to switch between different dashboards and visualizations further serves the epistemological goal of showing that there are no baseline measures to view content diversity or user practices objectively. Yet, curating dashboards is not completely unproblematic. Dashboards are ultimately aggregates that are preconfigured in time (ie. hourly, daily, weekly). Also, as previous scholarship on dashboards has pointed out, translating data into meaningful narratives (Jarke and Macgilchrist, 2021) is challenging as representations inherently reside on epistemological questions about what counts as relevant knowledge. In news media, this is not a banal question, but one that is deeply intertwined in historical discussions about the societal function of the media (Jensen, 2002).
The analysis exemplifies how media theories can contribute to prefiguring and configuring relevant stories of news recommender systems through dashboards. The agenda-setting perspective depicts a media-centric view on recommender systems comparing algorithmic curation with editorial curation on the salience of topics, agendas, and actors, as well as the diversity of the composition. The agenda-setting perspective is prefigured by data on exposure and content-related metadata, such as categorical classifications, and actor detection methods. The uses and gratifications perspective configures analysis of performance based on available measures of engagement, such as click-through rates, dwell time, conversion rates, and reading time. Also, as behaviors vary by contextual circumstances, contextual metadata, such as device, time of use, and positioning of recommender prefigure analysis. The uses and gratifications perspective can offer insight into how recommenders stimulate engagement, and under what circumstances they can serve users’ needs. Finally, the repertoire perspective configures analysis of how different types of exposure meet the needs of different user groups. This form of analysis is prefigured by behavioral data to index preferences and metadata on users, such as demographic information and profiling based on habits and preferences. Explicating the theoretical position highlights that the way data is composed, classified, selected, and statistically aggregated is theoretically informed by ideals of the role of media but also guides attention toward the strengths and limitations of each view. The multiple perspectives reflect the variations of purposes news media serve: They act as accountants of the public discussion, as sources of information and entertainment for people, and tie closely to individuals’ habits and preferences. Indeed, news organizations emphasize different editorial values, ie. public service broadcasters might favor a fair and balanced overview of public affairs whereas commercial tabloid media are dependent on engagement. In any case, enabling a multiple perspective provides the means for editors to weigh, compare, and contrast systems based on competing values, thus also balance it to their editorial profile.
Configuring evaluation of news recommender systems into interpretable dashboards, moreover, presents potential for refiguration. Where previous scholarships have indicated that when recommenders are employed, responsibilities of curation and control shift toward the technical domain (Møller, 2024; Schjøtt Hansen and Hartley, 2021), building evaluation systems that editors can monitor “at a glance” can be viewed as an invitation for editors to monitor algorithmically governed exposure and take ownership it. However, as previous studies on dashboards in newsrooms have shown (Petre, 2021), the configuration of metrics can also guide attention toward the performance of simple measures, thus being counterproductive for the purpose. Also, representations such as lists of most clicked articles could motivate journalists to game the systems and try to develop ways in which their articles get visibility through the recommender systems. Therefore, the promise of dashboards lies in how they prompt users to ask new questions about the phenomenon they describe, be it for journalistic purposes or in other domains. Thus, the dashboard gives rise to new ideas and interpretations that might inspire new measures to be developed, displays to be designed, and strategies to be formed. In this way, the configuration exists in a continuous circle of critical interpretation, giving rise to its own re-configuration.
Concluding remarks
This study conceptually explores dashboards as devices for editorial monitoring of news recommender systems and the challenges related to their configuration. We argue that dashboards hold the potential as devices that can enhance editors’ knowledge about the dynamic and situated implications of recommender systems that, in turn, enable accountability of exposure and capacity to intervene or engage in informed discussions with data scientists. Yet, this conceptual exploration should also be conceived as a critical remark to the introduction of complex and adaptive systems in institutional domains where fair and equal treatment of people is expected and the insufficient methodologies we have to re-interpret outputs of such systems. The case of news recommender systems displays that the challenge is not primarily about algorithmic black boxing, but rather about the uncertainty of news exposure when it is diversified on scale and changes over time. Indeed, exposure biases can be mitigated by value-centric design approaches and assessed by experiments or user studies. Yet, acknowledging the adaptive nature of recommender systems also points to the need for dynamic methods for ongoing and situated assessment. Dynamic methods, such as dashboards, could potentially be a viable method for editorial monitoring of recommender systems as well as more public auditing. Reflecting on the dashboard design illustrates the intrinsic problems of abstracting a complex material reality and the critical decision of appropriate selection of measures, sampling, grouping variables, and statistical operations. Making abstractions, such as computing diversity indexes, is critical for viewing possible consequences at scale but also limited without examples grounding the measures in reality and comparable baselines.
Footnotes
Acknowledgements
This article is a product of fruitful collaboration and conversations with several colleagues. We would like to thank the anonymous news provider for participating in this research and providing insights during the process. Also, we would like to thank Anna Schjøtt Hansen and Dieuwertje Luitse for organizing the workshop on The Politics of ML Evaluation, and Nanna Thylstrup for detailed feedback on the early draft. Finally, we thank the anonymous reviewers for their thoughtful comments.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Innovationsfonden, Danmarks Frie Forskningsfond (grant number 0175-00014B, Grant No. 0132-00080B) and Velux Foundation (Grant No. VEL67499).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.