
Abstract
In insurance, there is still a significant gap between the anticipated disruption, due to big data and machine learning algorithms, and the actual implementation of behaviour-based personalization, as described by Meyers (2018). Here, we identify eight key factors that serve as fundamental obstacles to the radical transformation of insurance guarantees, aiming to closely align them with the risk profile of each policyholder. These obstacles include the collective nature of insurance, the entrenched beliefs of some insurance companies, challenges related to data collection and use for personalized pricing, limited interest from insurers in adopting new models as well as policyholders’ reluctance towards embracing connected devices. Additionally, the hurdles of explainability, insurer inertia and ethical or societal considerations further complicate the path toward achieving highly individualized insurance pricing.
Introduction
The history of artificial intelligence (AI) usage in the economic field is not one of a continuous succession of successes, as it is often told. Let's take the example of insurance. Insurers seem to be prime candidates for transforming uncertainty into knowledge, the unknown into risk and risk into premiums or contributions through AI. In fact, insurers have been collecting a wealth of data on their clients for a long time and have been using them for pricing purposes using predictive statistical models. If we were to approach this term vaguely, one could almost say that a ‘primitive’ form of AI has been in use for a long time.
However, several recent studies, including one with an evocative title – ‘The revolution that did not happen: Telematics and car insurance in the 2010s’ (Francois and Voldoire, 2022) – indicate that attempts to use AI for pricing in auto insurance and health insurance have not been successful. An article from L’Argus de l’assurance (Madeline, 2019; cited by Benoît et al., 2021: 1), a leading industry journal in France, suggests that Big Data is still in a state of ‘searching for use cases’ in the insurance sector in France, characterized by remaining ‘challenges’ or ‘promises’. 1
On the contrary, we must acknowledge that the movement toward individualization of products and services is now definitively underway, notwithstanding the collective nature of insurance, based on risk pooling. This movement is not unique to the insurance sector. In all domains, consumers desire personalized offerings. AI is a powerful tool for individualization: it allows for a better understanding of the consumer, their needs, and aspirations. As Minty (2023) writes, ‘personalization is not going to go away. That's because it is neither a technological thing nor an insurance thing. It is a social trend to which businesses are adapting and learning how to apply technologies to remain relevant and profitable. Nothing new there then’. This is also what makes Swiss Re's Head of Innovation say (Meyers, 2018: 72) if you do not have a wearable device that tracks your health then you will find it nearly impossible to buy life insurance. If not in the next 5 to 10 years then I am convinced we will see this implemented within the next 20 years. How can I make such an outrageous claim? That's easy. The event of Big Data will bring about a revolution in customer experience similar to what we have seen in communications and planning.
We will attempt to identify, based on current literature, the main causes of the gap between the announced disruption and reality and what leads Meyers (2018: 20) to say that ‘behaviour-based personalization is ‘in the making,’ but it is not stabilized (yet?)’. Our article is based on a review of recent documents on the impact of AI on insurance. A significant proportion of these articles have been written by French actuaries, who have the technical skills to understand the principles and practical applications of AI systems. We have also enriched our article with academic publications.
We have identified eight reasons that represent as many fundamental obstacles to the radical paradigm shift that is being heralded, with insurance guarantees that would closely reflect the risk of each individual: the collective nature of insurance, the convictions of certain insurance companies, challenges related to data collection, the moderate interest of insurers in new models and of policyholders in connected devices, the hurdle of explainability, insurer inertia, and finally, moral or societal considerations.
For purposes of this article, we define AI, using the terms set forth in the European Union Artificial Intelligence Act dated 13 June 2024, as a machine-based tool ‘designed to operate with varying levels of autonomy and that may exhibit adaptiveness after deployment and that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments.’ Although our paper often mentions the term ‘personalization,’ it is important to understand that the instrument of this personalization is AI.
The collective nature of insurance
Insurance is an activity fundamentally based on a collective perspective of the risks posed by each policyholder. An insurer cannot predict in advance whether a particular individual will experience a loss. The occurrence of such a loss is, for an individual, a matter of randomness, uncertainty (Frezal, 2018; Landes, 2015). However, the insurer can, based on past observations of claims for similar risks, estimate the distribution of claims for a group of policyholders, including its mean or variance (Cevolini and Esposito, 2022). ‘Until an individual insured is treated as a member of a group, it is impossible to know his expected loss because, for practical purposes, that concept is a statistical one based on group probabilities’ notes Abraham (1985: 423). According to Barry and Charpentier (2020), insurance can be defined as ‘the transformation of unknown individual uncertainty or chance into a measurable aggregate risk. Technically, it consists of pooling uncertainty and applying the law of large numbers’. Finally, as von Mises wrote it, cited by Charpentier (2022), When we speak of the ‘probability of death’, the exact meaning of this expression can be defined in the following way only. We must not think of an individual, but of a certain class as a whole, e.g., ‘all insured men forty-one years old living in a given country and not engaged in certain dangerous occupations’. A probability of death is attached to the class of men or to another class that can be defined in a similar way. We can say nothing about the probability of death of an individual even if we know his condition of life and health in detail. The phrase ‘probability of death’, when it refers to a single person, has no meaning for us at all. The probable is the event seen from the perspective of the whole, the bank (or the casino), God, or someone who can play an indefinite number of times: the results of the draws will always tend more and more towards their probability. Risk is the same event seen from the perspective of someone who has only one chance to play, who cannot know what will come out of the draw, but who can calculate what he is likely to gain or lose in uncertainty, depending on the decision he makes.
The traditional technical elements of insurability – the randomness of the event, maximum loss, average loss per occurrence, time period between two occurrences, to name a few (Berliner, 1985: 325) – disappear and are replaced by a number. The logic is no longer that of regularity within a collective but that of ‘singularity’ (Ewald, 2012: 71). Barry and Charpentier (2020: 2) write that ‘the new techniques, while bearing some familiarity with insurance mechanisms, seem particularly challenging for traditional conceptions of insurance since they claim to predict the individual case rather than the group’. According to Barry (2020: 1), ‘whereas previously people were simply categorized into relatively broad equivalence classes, current techniques seek to assign a number to each individual (…), [differing] from a classical categorization’. One can legitimately question the statistical significance of this number, as Barry (2020) or Charpentier (2023) do.
In fact, this objective represents the extreme limit of a movement that is itself ancient: risk segmentation (Barry and Charpentier, 2020; Bénéplanc et al.: 142). This involves creating homogeneous groups sharing certain distinctive characteristics. As noted by Barry (2019: 16), during the twentieth century, we witnessed a long trend of increasingly fine-grained risk segmentation and a shift from ‘a perspective of equity based on pooling randomness’ towards a ‘scientific approach aiming for an ideal of perfect individual adjustment’. As written by Bamman et al. (2014: 153), cited by Barry (2019: 17), machine learning ‘offers a bountiful harvest of modeling techniques that minimizes the need for categorical assumptions’.
However, two objections can be raised. First, individualizing premiums through precise knowledge of each risk is an utopian perfection that one may not believe in. Not everything that can happen to an individual policyholder is necessarily predetermined or encoded in their genes. Insurance is not – at least for the moment – an exact science (Barry, 2019).
However, in a world where risk would perfectly be known thanks to AI, do we still need insurance? Insurance presupposes randomness. Information dispels randomness and, consequently, insurance, according to an effect that some economists call the ‘Hirshleifer effect’, named after the economist who highlighted the link between information and insurability (Gollier, 2015). According to Gollier, ‘risk then becomes inequality through the revelation, assumed here to be complete, of information’ (2015: 199). In place of insurance, there would be varying degrees of capacity among ‘insured individuals’ to save for future losses.
Another argument, more technical – or statistical – is added by some experts: Abraham (1985: 423) points out that ‘most individual loss experience is not statistically credible enough to warrant individual rating’. Applying statistical reasoning to samples consisting of a single individual seems futile unless one considers machine learning as a separate technology not bound by the laws of statistics.
Finally, the smaller the group size, the less robust the pricing exercise becomes (Barry, 2019: 11). Even with all the desired variables, an unexpected risk can materialize, challenging the financial balance of the small group. Charpentier et al. (2015) demonstrate that the assumption of a strong segmentation in a competitive market – with the objective for some insurers of attracting ‘good’ policyholders with reduced premiums – leads to a situation they call the ‘segmentation spiral’ (Charpentier et al., 2015: 61) – or ‘downward spiral’ (Davet, 2011: 44) – in which ‘a few rare companies are (potentially) at equilibrium, with very low market shares and significant result variability, while others are losing money (on average) with much larger market shares’. In practice, the smaller the portfolio, the greater the result variability will be, resulting in the regulatory obligation for insurers concerned to mobilize additional capital. Zajdenweber (2015), relying on mathematical theorems analyzed by Feller (1968), goes so far as to claim that the creation of highly homogeneous (and therefore strongly ‘segmented’) portfolios does not lead to the lowest possible variance and thus argues for the creation of the most diversified portfolios possible.
Convictions of certain forms of insurance companies
Some forms of insurance companies may choose to avoid the excessive individualization of premiums permitted by AI. We can think first of complementary insurance mutuals (e.g. Macif, GMF, Maif, Matmut, SMABTP). These companies are private legal entities, nonprofit and ‘neither members nor directors (…) seek profit through their membership in the company. The only benefit they can receive is to contribute at a lower cost to cover the risks they have taken on. The mutual insurance company's purpose is to help them save money’ under French law (Bigot, 2011: 238). Therefore, they do not seek to optimize their results by strongly individualizing their coverage.
This is also the case for mutual insurance companies governed by the Mutual Insurance Code (e.g. MGEN). Sometimes referred to as ‘mutuelles 45’ or ‘complementary health’, their activity is mainly centred around health and personal protection insurance, even though the type of insurance they can practice is significantly broader.
These mutual insurance companies guarantee their ‘participating members’ – defined as natural persons who benefit from the insurer's services, in other words, policyholders – the full payment of the commitments they undertake towards them. As in the case of mutual insurance companies, participating members are both members of the company and policyholders, which creates a de facto solidarity among them and between them and the company. A significant portion of mutual insurance companies initially served a population identified by the practice of a profession (e.g. Mutuelle Générale de l’Éducation Nationale), an activity (e.g. Mutuelle des Motards) or a common location (e.g. Mutuelle de Poitiers), even though they have since opened up to a broader audience. It should be noted that the contracts offered by mutuals, especially in individual health insurance, historically emphasize ‘solidarity’ because they practice limited selection (prohibited in terms of health status but possible based on age, for example). Therefore, the individualization of insurance premium relatively low.
Finally, personal protection institutions (e.g. Malakof Humanis or Klesia) also promote solidarity and only weakly segment their risks.
Among the top 20 insurance companies in France, five have chosen to explicitly or implicitly mention solidarity in their mission: CNP Assurances (committed to ‘an inclusive and sustainable society and providing solutions to the greatest number’); Natixis Assurance, through the purpose of BPCE and Caisse d’Epargne (the latter aims to ‘promote solidarity’ 3 ); AG2R (emphasizes ‘professional and intergenerational solidarity’ 4 ); Crédit Mutuel Arkéa (identified as an ‘ethical and inclusive company’ 5 ); and MAIF (strives to ‘guarantee a real common betterment’ 6 ). When including companies that incorporate solidarity as part of their commitments, 15 out of 20 companies declare that solidarity is at the heart of their corporate vision. These companies are likely to prioritize solidarity over the individualization of coverage rendered possible by AI, provided that they translate their commitments into concrete actions.
The mutualistic form is not unique to France. According to the Association of Mutual Insurers and Insurance Cooperatives in Europe (AMICE), ‘approximately half the insurance firms in Europe are mutual insurance companies or cooperatives or their subsidiaries and they represent approximately 400 million members/policyholders underwriting more than €469 billion in insurance premiums. One-third of all insurance in Europe is placed with insurance companies which follow the mutual/cooperative model’ (AMICE). Mutual or cooperative insurance companies are also prevalent in the United States and Canada. These mutual or cooperative entities often bring together policyholders based on geographical or professional criteria. They share with their French counterparts a lack of profit-seeking, with profits primarily reinvested for the benefit of their members, and the fact that these members are both members of the mutual or cooperative insurance company and insured by it, maintaining a strong sense of solidarity.
The challenges of collecting data for AI and using it for individualized pricing
AI relies on data. The greater the number and diversity of data, the more accurate the insurer's ‘measurement’ of the risk being covered can be expected to be. This implies the need to obtain data about policyholders. Some data are obvious (gender, age, address, etc.), but others are more difficult (or even prohibited) to collect. In some cases, policyholders may find it advantageous to hide certain data. The willingness of policyholders to share data about themselves can also influence the success of an insurance product offering. For products targeting young drivers, data sharing may be more readily consented to than for a fleet of professional vehicles whose drivers may fear that telematic data will be used for surveillance purposes (Francois and Voldoire, 2022).
Furthermore, many data points that could be valuable for identifying and selecting risks are subject to protection, especially those covered by the General Data Protection Regulation (GDPR), which, under certain conditions, prohibits the processing of certain sensitive data, such as racial origin, political beliefs, biometric data for identification, or health data. Even if these data points are relevant, they cannot be used. In addition to the GDPR, the collection and use of relevant data for risk selection are heavily regulated. In the context of group insurance, while the collection of health or behavioural data is not prohibited, the exclusion of an insured individual is not possible. As stated by the French Supreme Court, cited by Del Sol (2020), ‘the principle of non-individual risk selection (…) in mandatory collective coverage prohibits exclusion that does not concern the entire group of insured individuals’. 7
Regarding individual insurance, Article L. 110-2 of the Mutual Insurance Code stipulates that ‘mutual insurance companies (…) cannot, in any case, collect medical information from their members or individuals seeking coverage, nor set contributions based on health status’. 8 Insurers subject to the Insurance Code are not bound by the same obligations and can indeed practice pricing based on health status, incorporating this variable into their models. However, if they wish to offer their policyholders ‘responsible and solidarity-based’ contracts, which benefit from favourable taxation, they must renounce selection and pricing based on health status for these same contracts. It is estimated that 95% of health insurance contracts are ‘solidarity-based’ (Del Sol, 2020).
In automobile insurance, it is noteworthy that insurers do not have access to data on traffic violations and license point deductions from the national driver's license database, even though this data is likely highly predictive (Gollier, 2015).
Genetic data serve as a good example of highly predictive data for each individual, the use of which is nevertheless prohibited. The threat, as described by Ewald (2012: 8), was as follows: It was imagined that new genetic knowledge would destroy the mechanisms of solidarity and risk pooling. The great threat was supposed to come from insurers. Their interest in knowing the risks of policyholders would undoubtedly lead to increased selection, discrimination, and exclusion. There were concerns that insurance, which had hitherto been the great instrument of solidarity, would become the very instrument of its destruction.
9
Wauters and Van Hoyweghen (2016) show that the fear of discrimination due to genetic factors remains nonetheless strong among insurance applicants. In fact, insurance is the leading sector in which this fear is manifested. The systematic review by Wauters and Van Hoyweghen (2016) of the literature on the nature, extent and basis of this fear identified 42 written studies on this theme, 35 of which concern insurance. The authors also note that the existence of regulations prohibiting discrimination on the basis of genetic data is not enough to reassure insurance applicants.
It should be noted the causal link between genetic predispositions and health status is not always clearly established (Lehtonen and Liukko, 2011). Furthermore, genetic inheritance is independent of any behavioural choices, which argues, for moral or social reasons, against taking it into account. Van Hoyweghen and Rebert (2012: 876) go as far as suggesting that ‘advances in genomics and postgenomics, which make differentiating between the “genetic” – that which has been “given” to us – and “the nongenetic” – that which has been “made” by us – more difficult’ may lead to an extension of the non-discrimination restrictions to all medical conditions and ‘turn private life insurance of actuarial risk discrimination increasingly into “discriminatory” practices’.
In the field of auto insurance, Barry and Charpentier (2020: 6), citing Tselentis et al. (2017: 140), note that we may be witnessing a change where ‘other unfair characteristics such as age, type of car, etc., which do not necessarily reflect the chance of being involved in a crash’ will no longer be considered.
Even when data can be used, their processing must be subject to rigorous procedures. As noted by Jeanningros and McFall (2020: 5), citing the New York State Department of Financial Services (2019), insurance regulators require that ‘the use of external data sources, algorithms, or predictive models are not unfairly discriminatory. The insurer must establish that the external data sources, algorithms, or predictive models are based on sound actuarial principles with a valid explanation or rationale for any claimed correlation or causal connection’.
Furthermore, it is entirely possible that individualization of insurance policies may involve costly (and therefore unprofitable) data collection for insurers. As Swedloff (2014: 359) wrote, cited by McFall et al. (2020: 4): It might be extraordinarily expensive to harness big data and generate more refined risk classifications. Each carrier might have to spend significant sums to make marginal improvements to their risk classification scheme. These costs could be exacerbated because carriers may feel pressure to follow popular trends. Given the press coverage on the wonders of big data, firm leaders may spend exorbitantly even if the new classification scheme costs more than it generates.
The moderate interest of insurers in new models that would allow for greater individualization…
According to Barry and Charpentier (2020), as cited by Francois and Voldoire (2022: 2), ‘the models discussed by academic actuaries to price automobile contracts remain highly traditional. It would seem that the implementation of telematics devices has only added to the list of Big Data failures (…): while Big Data analytics promise to radically disrupt certain markets, their implementation often leads to more modest results’. Jeanningros and McFall (2020: 2) write that ‘despite its visibility, self-tracking data is of marginal importance in the health and life insurance sector’.
As expressed by a candidate actuary (Bachelet, 2022: 5),
10
Rather than directly modeling pure premiums with machine learning, we prefer to use the latter to create a new variable summarizing interactions. The valuation of this variable is then done by reintroducing it into existing generalized linear models, thus reducing its errors by construction. Among other advantages, this approach allows us to maintain the interpretability of tariff coefficients, which is essential in automobile pricing. The most commonly used practice to approach the performance of Machine Learning models is the manual addition of cross-terms or interactions (i.e., age and residential area) among the explanatory variables in the rate equation: this addition is completed with a significance test, which allows us to assess whether the interaction should be kept in the model. Most of the time, the researchers recommend adding the new variables to the existing classification (…) as the new variables work best in combination with the traditional ones (…). Some also highlight how telematics variables may become a necessary input to existing models in replacement of other variables that are being removed by regulation. Professionals (…) we interviewed confirmed that the first step they have to take to conduct this assessment is the creation of clusters of policyholders who are differentiated on the basis of classical actuarial variables: driver's gender and age, type of vehicle driven, driver's previous claim history (…) and place of residence (…). This operation is the crucial foundation for a first tariffication of policyholders differentiated by segments according to standard actuarial methods. We can certainly say that digital insurance premiums are not customized (…) the basis for tariffication still remains the classical actuarial model, based on variables independent of individual behavior, such as age and gender (…) People belonging to the same segment, in other words, can pay different premiums.
Telematics was supposed to refine pricing, but the results have been modest. Francois and Voldoire (2022: 8) write that The challenge (…) consists of using (a) more granular understanding to target pricing more effectively and offer individual rates. This objective has only been poorly achieved. The link that insurers have managed to build between risk measurement and claims experience is very tenuous.
Performance of standard modelling technique, according to various criteria, from low + to high +++++.
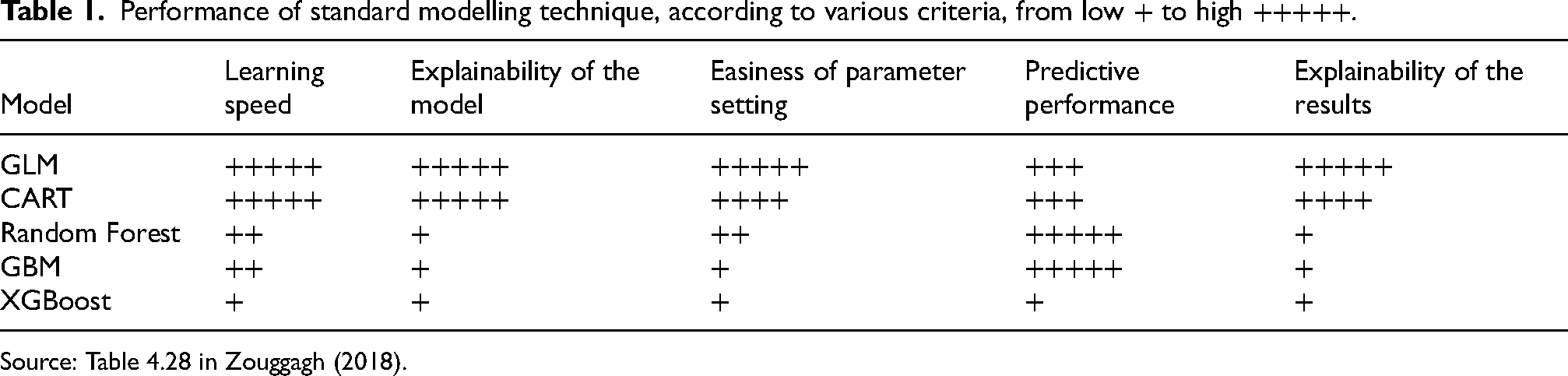
Source: Table 4.28 in Zouggagh (2018).
Adding to the challenge is the requirement for model explainability, which will apply to machine learning models, especially due to the upcoming European regulation on AI. This highlights that traditional models such as generalized linear models (GLMs) and generalized additive models (GAMs) outperform machine learning models (Bucci, 2022). For Fauchet (2022: 33), GAMs and GLMs Are still preferred (…) notably for their interpretability (the algorithm's operation must be understandable by an expert in an interpretable format) and explainability (a layperson must explicitly understand the elements responsible for the algorithm's decision-making).
The relatively limited interest of insurers in machine learning is shared by actuaries, who play a central role in the functioning of insurance companies. The shift in the role of actuaries, who are traditionally responsible for pricing, with the introduction of AI can be described as follows (Maisnier and Lhenri, 2020): It involves a transition from a world where actuaries use mathematics to model reality (more or less complex) to a world where data scientists use autonomous programs to find patterns in data. Moreover, the operation of machine learning algorithms generally goes beyond the concepts of average and expectation on which classical statistical approaches are based. Consequently, models are no longer limited by the law of large numbers and can perform analyses at much finer levels.
14
…and the moderate interest of insured for connected objects
Telematics insurance presents advantages for insurers, policyholders, and society at large. In the context of automobile insurance, Verbelen et al. (2018: 2) state: Telematics insurance gives a high incentive to change the current driving pattern and stimulates more responsible driving (…). Users’ feedback on driving behavior and gamification of usage-based insurance can further enhance the customer experience by making it more interactive, gratifying, and even exciting (…). Less and safer driving is encouraged, leading to improved road safety and reduced vehicle travel with less congestion, pollution, fuel consumption, road cost, and crashes.
However, both in automobile insurance and health insurance, policyholders do not seem to be convinced of the benefits of connected insurance. In the case of health insurance, Jeanningros and McFall (2020) attempted to understand why the Vitality health insurance product, distributed worldwide by various insurers, did not achieve the success expected by the product's creator, Discovery. This programme offered rewards (gifts or discounts with brands like Starbucks, Apple or Amazon) as incentives for certain physical activities. Apart from the lack of conviction regarding the value of self-tracking for setting health insurance premiums, the authors suggest that policyholders have little attachment to brands that struggle to gain recognition (Jeanningros and McFall, 2020: 9). Regarding connected devices, Jeanningros and McFall (2020: 10) note that they ‘do not determine behaviour; wearers play around with them, forget them, and discard them’. According to Jeanningros and McFall (2020: 12), the Vitality product: Has been widely read as a sign that health and life insurance is going the way of telematics schemes in vehicle insurance, to individualize premia based on tracked behaviour. We suggest that such an outcome is much easier to accomplish in theory than it is in practice. Risk pricing in insurance is an arcane technical practice conducted in a highly regulated and competitive market context. Even if self-tracking data was to be modelled as a pricing factor it is not clear that there would be sufficient incentive for insurers to use it given the regulatory environment, infrastructural expenses and reputation costs of doing so. There are also reasons to be sceptical about the clinical and actuarial reliability of self-tracking data and the devices and apps used to gather it. Insurance industry actors don’t know how to risk assess the health of human beings – they know how to risk assess aggregates, groups, collectives, pools, populations.
Cevolini and Esposito (2022: 123) noted that customers of an Italian insurer who subscribed to ‘telematics’ insurance didn’t even download the application that would allow them to record and transmit data. The insurer subsequently abandoned this offering. For another Italian insurer, as highlighted by Cevolini et al., ‘those who paid for a telematics policy did it “essentially because of the discount rather than … the opportunity to understand their [driving] behaviour”’. This point is confirmed by another study that lists receiving a discount on premiums as the primary reason for subscribing to telematics insurance in Italy (Swiss Re, 2017).
Another illustration of the relative lack of interest among policyholders in connected car insurance is a study conducted by a Belgian insurer in this market. To be statistically significant, the study aimed to recruit at least 5000 ‘connected’ drivers who would be offered a 20% premium discount. However, only 243 volunteers were found. The commercial director of the insurer (Meyers and Hoyweghen, 2020: 10; Meyers, 2018: 139 et seq.) drew the following conclusion from this failure: ‘an insurance product which links the premium to driving behaviour will probably not be offered any time soon’.
As Tanninen et al. (2022) points out, ‘the use of data-driven personalized choice architectures that strive to affect consumers’ behaviour – has been criticized as a form of manipulation (…) and an invasion of people's decisional privacy’. Tanninen adds that ‘aligning user aims with the goals of the insurance arrangement is difficult to achieve and sustain tracker qualities that are experienced as helpful at one moment can easily become unwelcome at another (…). For algorithmic encounters to appear gratifying, people must feel that their self-determination is not unpleasantly infringed’.
One blind spot in studies on telematics insurance is the cost of installing the device (or connected objects in health insurance) when the data is not directly captured by the driver's phone or integrated devices in all cars. One study suggests that this cost may be borne by the driver, for whom ‘the perceived value of premium discounts and value-added services (VAS), such as theft protection is higher than the perceived costs to install the black box and subscribe for VAS’ (Swiss Re, 2017: 12).
When the cost of the telematics device is borne by the insurer, the issue of the cost price is still relevant, albeit in this case concerning the insurer. In 2016, a representative from AG Insurance stated (Meyers, 2018: 133–134): In 2007-2008 we didn’t really carry out a test project, but rather a study (…). We did not go through with it back then, and the main reason for this was the cost of the technology, which was still very high at the time (…). We all built in a black box (…) in our car, and a device that gave auditory and visual signals, when one was, for instance, cornering aggressively or accelerating aggressively. Then, we asked ourselves: ‘let's see, what is the effect on drive style?’ (…) We concluded that drive style did improve but we decided to stop the project. Because we still had problems with the technology from time to time (…) and the issue of costs remained. It stays a relatively expensive technology. I know there are, by now, a sufficient number of alternatives.
The challenge of explainability
The upcoming European regulation will subject several AI systems to an obligation of explanation regarding their mode of operation and the results they produce. In general, the European Union AI regulation made on 14 June 2024 establishes transparency as one of the fundamental principles of AI systems, defining ‘transparency’ as the fact that these systems: developed and used in a way that allows appropriate traceability and explainability, while making humans aware that they communicate or interact with an AI system, as well as duly informing deployers of the capabilities and limitations of that AI system and affected persons about their rights.
The requirement for transparency in favour of individuals subject to algorithmic processing is not entirely new. Article 13 of the General Data Protection Regulation, for example, states that when ‘automated decision-making, including profiling, exists (…) meaningful information about the logic involved, as well as the significance and the envisaged consequences of such processing for the data subject [shall be provided]’. Furthermore, Article 4 of the 7 October 2016 law stipulates that any person affected by algorithmic processing can demand that the relevant authority provides ‘the rules defining this processing as well as the main characteristics of its implementation’.
However, as Francois and Voldoire (2022) note, the data generated by telematics devices used in auto insurance often takes the form of ‘synthetic’ or ‘aggregated’ scores, typically calculated by device providers, which are difficult to interpret in any meaningful way: In most cases, the raw data recorded by devices (acceleration and deceleration speeds, abrupt braking or cornering, etc.) was not used directly. Instead, this data was processed to create an overall score, which was then used by insurers to try to improve rate calculations. These indicators were integrated into the generalised linear models used by actuaries, following a classic methodology; in other words, the experiments carried out within insurance companies aimed to improve existing actuarial models, following stabilised method. (p. 6) The scores integrated into pricing models most often summarise information collected by telematic devices, and are calculated by external service providers according to opaque procedures. (p. 9) Already insurers are using data to divide us into smaller tribes, to offer us different products and services at varying prices. Some might call this customized services. The trouble is, it's not individual. The models place us into groups we cannot see, whose behavior appears to resemble ours. Regardless of the quality of the analysis, its opacity can lead to gouging.
Finally, these scores and the resulting pricing can lead to losses for the insurer (the score is ‘good’, but the insured has claims) or misunderstanding by the insured (the score is ‘bad’, but the insured has no claims) (Francois and Voldoire, 2022: 24).
The inertia of insurers
As mentioned above, Francois and Voldoire (2022) conducted a study on four automobile insurance products to understand why the AI revolution in insurance did not occur.
The first reason identified by Francois and Voldoire (2022: 2) relates to the ‘organizational inertia’ of insurers. Two mechanisms are at play here. The first one relates to a ‘set of organizational routines challenged by disruptive technologies’ (Francois and Voldoire, 2022: 2). In practical terms, the individuals responsible for implementing the mechanism do not do so. However, in insurance, ‘organizational routines are very powerful’ (Francois and Voldoire, 2022: 2). As Ewald (2012: 20) notes, ‘insurance protection systems (…) have a very high viscosity (…) they have a “stabilizing” function, they absorb shocks, smooth events over time, prevent ruptures and revolutions’. 19
The second mechanism concerns the role of certain professional groups that resist the implementation of innovations because they challenge their technical skills, ‘disqualifying’ them (Francois and Voldoire, 2022: 3). This is the case with actuaries, who have a predominant role in insurance organizations and whose techniques could be rendered obsolete by big data. Moreover, legacy infrastructures and deeply rooted institutionalized practices act as a barrier to change as much as a real opportunity in a sector ‘ripe for disruption’ (McFall et al., 2020: 2). One of the most significant sources of frustration for data scientists is the heaviness of pricing processes. In practice, ‘pricing innovation is often constrained by IT constraints’, even when it is simply a matter of adding a variable to the pricing model (Fauchet, 2022: 4). McFall (2015: 32) speaks of the ‘interoperability challenges of the legacy infrastructures within traditional insurance companies’. Other authors also emphasize the obsolescence of the IT structures of these insurers, which do not allow them to take advantage of new technologies (Giraud, 2022).
Francois and Voldoire (2022: 3) also consider that ‘the failure of telematics is not necessarily the symptom of an inability to adopt an innovation: it may be the result of a deliberate calculation and strategy’. The adoption of these telematics systems was carried out within the framework of ‘experiments’. The entire production chain of the insurance product is tested. However, the results of these tests alone do not determine the decision to adopt the product: ‘the question of what competitors are doing (…) is also important’ (Francois and Voldoire, 2022: 3).
A few moral and social considerations
Francois and Voldoire (2022: 3) reference Zelizer’s (1979) work on the moral and political dimensions of insurance activities to highlight ‘moral and political preventions’ that hinder the individualization of coverage, sometimes driven by opportunism as well (Bénéplanc et al., 2022). But what is true today is not necessarily true tomorrow. Zelizer (1978) showed in an earlier article that changes in moral, religious and political considerations can lead to the development of insurance products hitherto rejected for the same moral reasons, in this case, life insurance.
Gollier (2015) raises the question of whether a strong segmentation of coverage could lead to socially intolerable pricing differentials if it were discovered that they are correlated with individuals’ wealth. In France, both the regulator and mutual insurers may resist any changes to the principle of mutualization, which is at risk of being ‘killed’ 20 (Dixneuf, 2018). In general, the fear of excluding certain individuals, either partially or completely, from insurance coverage is perceived as unacceptable.
Meyers (2018: 117–118) reports that in November 2015, a Belgian insurer distributed 500 smartwatches to some of its clients. This gesture was interpreted as a test of pricing based on lifestyle habits. The Belgian Minister of Finance immediately responded by stating: Setting premiums is a contractual freedom between the insurer and the insured. Yet, from the moment I observe that the solidarity mechanism is being hollowed out, I will intervene. The premiums and tariffs have to be affordable for every citizen. From a privacy-perspective, the consumer has to always have the opportunity to explicitly consent with the sharing of his or her data.
Furthermore, insurers are hesitant to engage in practices that could lead to discrimination based on variables that are more challenging to understand and identify than protected personal data (such as gender, race, religion, etc.) (McFall et al., 2020). Some of these variables are combinations of other variables that do not have practical meaning (e.g. the combination of age, gender, and residence).
Moreover, the question arises of whether to consider elements that are not chosen by the insured (genetic makeup, gender, etc.) as opposed to those resulting from deliberate behaviours. Is it legitimate to take these factors into account when pricing an insurance policy (Steiner, 2018)? As the head of innovation at Swiss Re noted in 2015 (Meyers, 2018: 124): For example, we are not allowed to use genetic testing because you are born like that. You have no say in it. No matter what you eat, you have no influence at all on your genetics. So in the long run the regulator and consumer interest groups will probably shut down the use of things that people have no control over. Now, the one thing people have clear control over, is their behaviour.
Finally, the sheer reputational risk makes some insurers hesitate. Barry and Charpentier (2020: 9) take as an example the case of a driver considered ‘aggressive’ even though he has not caused any accidents.
The individualization of the premium therefore presupposes the ability to convince citizens and regulators of the fairness of such a practice and its compatibility with the principles they have collectively chosen. There is, however, a tendency among some drivers to ask that the premium paid should depend on their actual driving habits and not on membership of a group sharing certain criteria with them: ‘Don’t judge me based on everyone else, (…) Judge me based on me’ (Hill, 2024).
Conclusion
In health insurance as well as in automobile insurance, AI has not, to date, had the ‘disruptive’ effect that was anticipated. Insurance in 2023, supposedly ‘boosted’ by Big Data and the latest AI techniques like deep learning, closely resembles that of the early 21st century when these techniques were still confidential. The main reason for the gap between the promises of AI in insurance and the reality of the insurance industry lies, in part, in the inherently collective nature of insurance, which is diametrically opposed to the individual risk approach promised by AI. Other reasons, related particularly to the inertia of industry players, their culture or the practices of data specialists, as well as the opaque nature of AI often perceived as an inscrutable ‘black box’, also explain this gap. Are these reasons enough to conclude that AI in insurance has failed? It's far from certain. The search by policyholders for products and services tailored to their needs, in insurance as in many other fields, could profoundly change industry practices.
The question is whether the new European Union Artificial Intelligence Act will change things. This regulation classifies ‘AI systems intended to be used for risk assessment and pricing in relation to natural persons in the case of life and health insurance’ as high risk submitting these systems to stringent risk management, data governance, record keeping, transparency, human oversight, accuracy, robustness and cybersecurity obligations. Although a study will have to be carried out to see if this regulation does not further set back AI in health insurance, it does not classify car insurance as ‘high risk.’ This raises the question of whether this will encourage the development of AI in this sector of insurance, unlike health insurance. Further investigation is required to assess the impact of the new European regulations.
In their successful book, blending fiction and foresight, Lee and Qiufan (2021) envision a world in which AI allows real-time adjustment of coverage and premiums for policyholders based on factors like their activities or lifestyle choices. For an individual whom AI determines is at risk of developing diabetes, the insurer would offer coverage with a premium tied to physical activity or dietary habits. Another individual's health or life insurance premium might fluctuate based on the social rating of the people they associate with or the safety of the neighbourhoods they frequent. Every decision or action taken by a policyholder and shared with the insurer through increasingly sophisticated connected devices would correspond to entirely personalized premiums. Of course, a world like the one Lee and Qiufan envision may not be suitable for everyone, for ethical or social reasons, for example. It would then be the responsibility of legislators or regulators to oversee the use of AI in the insurance sector and beyond. AI demonstrates (unfortunately?) every day that technology advances faster than the legal framework that should apply to it. The last-minute inclusion of general-purpose AI systems – or generative AI – in the European AI Regulation adopted by the Parliament on 14 June 2023, is a stark illustration of this fact.
Footnotes
Contribution
The authors wish to thank the Chaire PARI (ENSAE/Sciences Po) and the SCOR Foundation for Science for their contribution.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.