
Abstract
This article introduces a text extension to the UN General Assembly Sponsorship Dataset. It consists of a corpus with the full text of draft resolutions presented by member states from 2000 to 2020, which allows conducting content and text-as-data analyses of over 7000 L-documents (or 5000 draft resolutions). We demonstrate the utility of the new data via applications that map the salience of topics, measure sentiment, and identify the effects of changes to the text between revisions on attracting new sponsors. The article concludes by discussing potential uses of the data in future research.
Keywords
Introduction
This article introduces a major update to the UN General Assembly Sponsorship Dataset (Seabra and Mesquita 2022) via the addition of the texts of draft resolutions presented at the UN General Assembly (UNGA). The original dataset concentrated on sponsorship decisions, that is, which UN member states joined which drafts at what moment, thus ignoring the full content of drafts. This release offers the texts of 7110 L-documents (or 5009 drafts) presented at the UNGA between 2000 and 2020 and is available at https://doi.org/10.7910/DVN/MPQUE2.
The empirical value of UNGA texts might seem secondary if compared, for instance, with Security Council resolutions, wherein the slight change from “encourages all parties” to “demands” creates a clear duty (Wood and Sthoeger, 2022). UNGA resolutions are a non-binding, often woolly expression of majority sentiment (Mesquita and Pires, 2023). Even so, diplomats expend skill, ink, and working hours to decide whether “The General Assembly” is “concerned” or “deeply concerned,” and whether a situation is “mutually beneficial” or “win-win.” Skeptic commentators dismiss this is as ritual, 1 but others stress that these “semantic finesses” 2 are not for naught. Ideas and concepts are important products of the UNGA (Jolly et al., 2005), so finding the agreed language is core to this manner of diplomacy, which is concerned primarily with “‘frameworks for action’ and ‘correct’ understandings of an issue” (Laatikainen, 2020: p. 40). Further, soft-law does harden, which is why countries have a keen eye for the footnotes of today that might become treaty articles of tomorrow. Hence, the study of negotiations around these drafts and resulting textual changes can be highly informative of state preferences, strategies, and agendas.
Social scientists have today a vast text-as-data toolkit that allows for the analysis of large corpora (Grimmer et al., 2022). The current release is serviceable in various ways to researchers employing such methods. With UNGA textual data, it is possible to attain goals such as identifying with precision the concepts that states and norm entrepreneurs forward in multilateral arenas, testing how coalition-building strategies impact language choices, and tracking the shifting salience of normative agendas over time. The corpus is unique in its data coverage and density: it comprises drafts—not only final texts or voted resolutions—with repeated observations across document iterations. As such, it can be seen as a complement to other UNGA datasets, for example, votes (Voeten, 2013) or speeches (Baturo et al., 2017). We demonstrate the utility of this resource via three applications: mapping the salience of topics through dictionary search, sentiment analysis, and identifying the effects of textual edits in attracting co-sponsors.
This article has three more sections, where we (1) provide context about the UNGA texts and how the corpus was built, (2) perform the empirical applications, and (3) share concluding remarks.
Structure and processing of UNGA draft resolutions
Proper usage of the dataset requires context about how UNGA resolutions are written and negotiated. Regarding their composition, draft resolutions are published in documents as the one in Figure 1. First page of an L-document. Source: Adapted from the UN Digital Library (https://digitallibrary.un.org/record/425284?ln=en&v=pdf).
The top portion of the page contains information on date, agenda item, and the unique UN Document Symbol that identifies the piece. Further down, the alphabetical list of sponsors and draft resolution title appear in bold font. This information is available as metadata outside the file as part of its entry at the UN Digital Library (https://digitallibrary.un.org/). From “The General Assembly,” on lies the actual text under negotiation. It is divided into two segments: a preambular part, which takes stock of past decisions and other information relevant to the subject-matter, and an operative part. The latter is a list of numbered paragraphs, where the actions to be performed by the UNGA or asked of other parties are spelled out. In both parts, the opening verbs or verb phrases are in italics.
This document is uniquely identified by “A/55/L.12.” It is one of the so-called “L-Documents.” The relation between L-documents and drafts is worth detailing. Following Sebra and Mesquita’s (2022) original article, UN documentation is considered at disaggregated and aggregated levels. The lowest level is that of the individual L-document, such as A/55/L.12. A separate L-document can be issued in the future, containing a revision or an Addendum to a A/55/L.12. An Addendum alters the list of sponsors, and a Revision can alter sponsors and content. 3 These L-documents—that is, the original and the revisions directed towards it—are sequenced together and constitute an aggregated “draft.”
We used the metadata from the original dataset to retrieve the files of all L-documents. After, we applied a combination of R and Linux routines to process the downloaded texts (see Supplemental Materials for details). Processing involved not only cleaning the texts, but also extracting segments based on text formatting. As seen before on Figure 1, some of the text inside the PDF, such as resolution title or list of sponsoring countries, is, in fact, metadata. For some use cases, it is useful to disentangle such parts from the substantive text. Consider, for instance, a query on “Haiti,” a country that is at times a sponsor of resolutions and at times the topic being discussed by the UNGA. The name of sponsoring countries and the title of the resolutions appear in bold at the beginning of the documents. This allows us to use font-type markers to locate the position of the string, erase it, and save a cleaned version of the text. The difference is shown in Figure 2, which presents how often “Haiti” is mentioned in the raw and edited texts. We can be confident that the latter is capturing Haiti as a topic in view of the spike in 2010, the year when the island was hit by an earthquake that was accompanied by relief efforts at the UNGA. Search for keyword “Haiti” in raw and edited texts. Source: elaborated by the authors.
The verbs opening the paragraphs of the preambular and operative parts of the L-document are of special significance, as we will demonstrate further down. These are always in italics, so that we can use the same procedure as above to locate the position of the verbs and copy them to a separate field.
After these procedures, the dataset contained, for every L-document, its raw text, clean text, list of verbs and verb phrases that opened preambular and operative paragraphs. In the next section, we demonstrate how to utilize them in three brief applications.
Applications
Topic salience by keyword search
The dataset can be used for simple dictionary-based search. By counting the frequency of terms and aggregating totals across grouping variables at the dataset, it is possible to monitor the distribution of a subject across time or place.
We provide a demonstration on the salience of the democratization agenda at the UNGA across time. The topic is serviceable given the well-established account of how the UN agenda progressed. At first enthusiastic about universal democratization at the end of the Cold War, the organization eventually settled for a less militant posture. Institutional overstretch and the resurgence of a sovereigntist undercurrent among members are some of the reasons for this abatement, according to the literature (Haack 2011).
To measure salience, we applied two simple dictionaries to the clean text of all L-documents: one with “democracy terms” (“democracy,” “democratization,” and “elections”) and one with “sovereignty terms” (“sovereign,” “non-intervention,” and “non-interference”). In total, 904 L-documents (or 671 drafts) contained at least one term from the democracy dictionary, and 725 (588) from the sovereignty one. The longitudinal distribution is shown in the left pane of Figure 3. It confirms that the early fervor around democratization abated, while the salience of sovereignty, at first unvarying, caught up with democracy at the turn to the 2010s, and has led by a small margin since 2015. The right pane adds nuance by counting co-occurrences of “democracy” and other terms, as a proxy for changes in the meaning of democracy within UNGA output. It shows that the electoral aspect was eclipsed by a peacebuilding component in 2005. Five years later, these two elements would have to share space with more constant allusions to democracy and non-intervention. Salience of the democratization agenda. Source: elaborated by the author.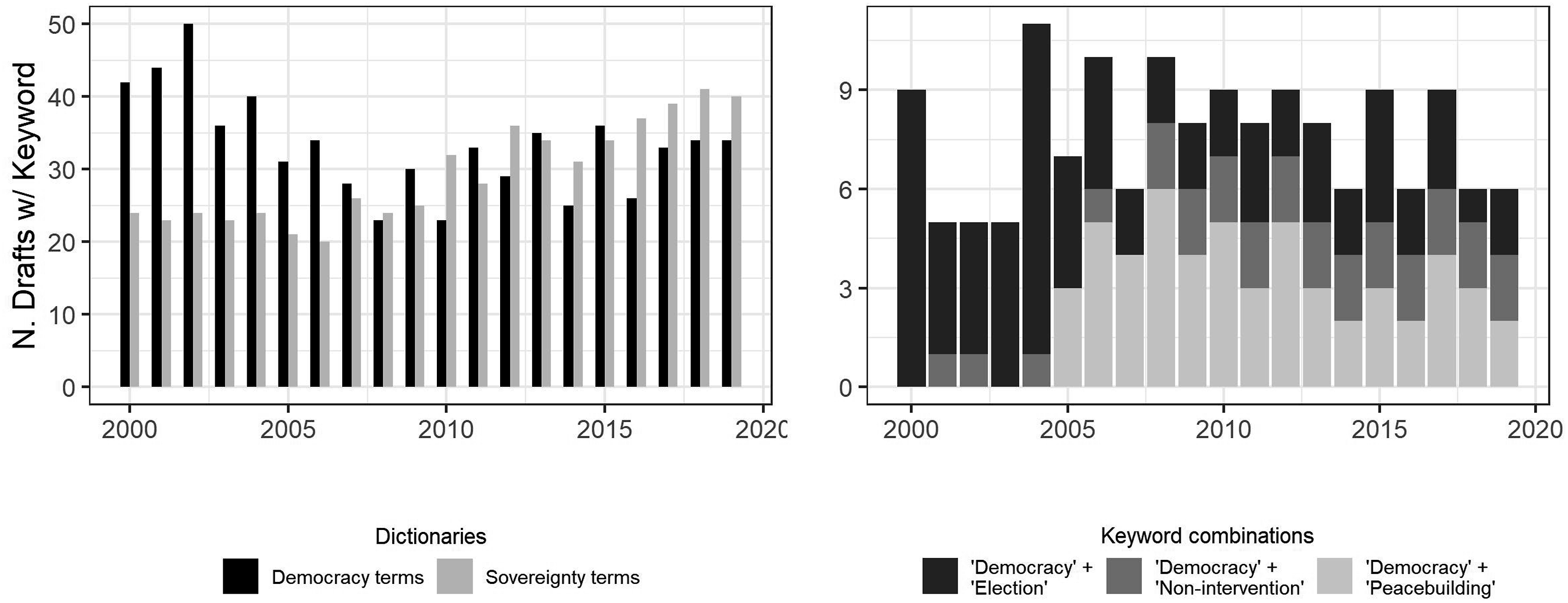
Sentiment analysis
UN texts are challenging for turn-key sentiment analysis, given the peculiar circumstances in which they are produced. 4 Resolutions address topics that by default evoke positive or negative terms—for example, war—so that diplomats’ intent in conveying optimism or condemnation might be obscured by the “overhead” positivity or negativity of the subject-matter.
Overcoming this problem requires discriminating portions of UN text according to their expressive importance, which our dataset permits thanks to its special extraction of italicized verbs. These tokens should contain more information about intended sentiment because, first of all, they are not contaminated by the surrounding terms, and, secondly, this is where stylistic convention allows diplomats to pen their emotions. Deciding that “The General Assembly deplores”—and not only “notes with concern”—is the type of small victory of which the life of a representative to the UN is made.
To demonstrate this, we apply the Lexicoder Sentiment Dictionary to the corpus. This dictionary is traditional for political science and indicates positive sentiment by values above zero (see Young and Soroka 2012). As a unit-level demonstration, L-document “A/C.3/57/L.32” on the “International Convention on the Elimination of All Forms of Racial Discrimination” was scored −0.05 on its full text but 1.36 on its verbs. This is because the full text is replete with nouns that are negative (“racism,” “xenophobia,” among others). Among the verbs, in turn, negative cases (“expresses its concern,” even “profound concern”) and positive cases (“commends,” “expresses its satisfaction”) have a more balanced count.
On the corpus level, Figure 4 compares sentiment scores across the six main committees of the UNGA and the Plenary. It shows that full texts tend to score above zero, whereas paragraph verbs reach negative values more often. For some committees, like the 5th and 6th committees, the gap is significant. Sentiment analysis of full texts versus verbs. Source: elaborated by the author.
The effect of text edits
The UN General Assembly Sponsorship Dataset informs the number of edits undergone by a draft, from tabling until final version. It also names the entrants at each iteration. These within-unit observations reveal successive snapshots of a piece as it moves forward in the negotiation process. The original Seabra and Mesquita (2022) article used this information to test, for instance, whether the early sponsorship of a great power was a signal capable of drawing in more sponsors from the set of countries under the sphere of influence of said power.
For this application, we are interested in exploring how word changes can impact co-sponsorship. This can be estimated indiscriminately, by counting the number of new sponsors per text change for the entire UN membership. 5 It is more interesting, however, to learn which words attract which countries in particular. UN members might have strong preferences that a topic be viewed under a certain light and hence only agree to participate if specific terms are added. Likewise, they might dislike certain concepts and only adhere after the authors agree to delete them. To put it simply, it is as if we asked: “what do I need to say to get you to sign?”
For this test, we restrict our sample to drafts that underwent at most two revisions (“Rev.1” and “Rev.2”) and ignore addenda. We further narrow the sample to drafts from the Third Committee (C.3), which covers most of the human rights debates at the UNGA. By focusing on this policy area, we obtain a more controlled vocabulary for the sake of demonstration, and abide on topic with well-known antagonisms at the UN (Hug and Lukács 2014). This leads to a total of 1038 L-documents (or 514 drafts). The set of tokens of each L-document was then compared to that of its antecessor (or successor) document within the draft. Two set comparisons were possible. Supposing an L-document d
1
is succeeded by a revision d
2
, set difference d
1
– d
2
reveals all tokens that existed in the first text but disappeared in the second. Conversely, d
2
– d
1
shows all tokens that only appeared in the new version of the text. We use the former operation, the “difference from next,” to identify tokens deleted between revisions, and the latter, “difference from previous,” to identify tokens added. Since Seabra and Mesquita’s (2022) original dataset shows whether a given sponsor s chose to join only in d
2
, we can consider the token changes from d
1
to d
2
as the words needed to persuade s, that is, the “ticket” that it cost to bring this country onboard. Because we can assume that the new entrants were not fully pleased with the original text and then became satisfied with the modifications, the token edits in d
2
are shared by all countries that joined then. Once this procedure is applied to all drafts and sponsors, all countries have two lists of words: a list of tokens deleted, and a list of tokens added at the moment of their entry. This is exemplified schematically in Figure 5 for a tokenized draft with 2 L-documents (d
1
, d
2
) and 3 sponsors (s
i
, s
ii
, s
iii
). In the example, d
2
contained stronger language than d
1
, for it dropped the tokens “concerned” and “growing levels,” adding “deploring,” and “unacceptable surge” instead. It will be therefore considered that co-sponsors s
ii
and s
iii
, who only joined the revised d
2
text, have the tokens “concerned” and “growing levels” in their list of deleted words, and “deploring” and “unacceptable surge” in their list of added words. Country s
i
, being an original drafter of d
1
, undergoes no change in its choice of words. Illustration of word choice for draft sponsors. Source: elaborated by the author.
What words are needed to persuade certain countries to join? To find these call signs, we calculate the Term Frequency-Inverse Document Frequency (TF-IDF) of the terms added. TF-IDF is more informative than raw counts because, by adjusting the frequency of a term by its rarity across a corpus, it reveals which terms were distinctive to the word set of one country in comparison to the sets of all other countries (Grimmer et al., 2022: pp. 75–77). In short, it indicates a signature vocabulary that marks a country’s decision to join. Figure 6 shows the TF-IDF for a sample of countries from different regions, revealing that some of the distinctive terms that mattered to Colombia in the Third Committee referred to migration (“undocu,” “irregular”); for Denmark, the global health initiative “UNITAID” as well as aid-related terms (“ODA”); for Ethiopia and Rwanda, the distinctive additions referred to religious discrimination; Russia added stronger language (“unjust,” “denial,” and “abhor”); and, for the US, mentions to “familycentr” were important. Top 10 tokens added prior to sponsorship, based on TF-IDF score. Source: Elaborated by the author.
Figure 7 generalizes this demonstration to all 193 members, divided between democracies and non-democracies, based on their 2015 dichotomous score by Boix et al. (2022). We use a wordfish scaling model to distribute the deleted and added words that were most peculiar to each regime type. The left pane shows that all regime types tended to remove words such as “secretari” and “welcom,” but it was peculiar to non-democracies joining after the words such as “genocid,” “aggres,” and “islamophobia” were removed. Conversely, it was distinctive to democracies adhering after terms like “wealth,” “neonazi,” “arab,” “christian,” and “disarma” were gone. The right pane indicates that common increments were “take_note,” “women,” and “peacekeep”; additions proper to non-democracies concentrated on terms related to racial non-discrimination, whereas those for democracies pointed to violence, voting, and non-governmental actors, among others. Wordfish plot of words deleted and added, by regime type of countries sponsoring after edits. Source: elaborated by the author.
To conclude, we zoom in on one of the terms picked up by wordfish: the International Covenant on Civil and Political Rights (ICCPR) of 1966 (see top-center of right pane). Given the Covenant’s emphasis on political liberties and protection from abuse from authorities, it is expected that references to it provoke opposing reactions among authoritarian and democratic regimes. Figure 8 shows the marginal effects plots for a mixed effects model predicting the probability of sponsorship as a function of the interaction between regime type and the inclusion/removal of references to the ICCPR. The left pane shows that the insertion of references to the ICCPR increases the likelihood sponsorship for both groups, but far more for democracies, while its deletion, as seen on the right pane, improves chances of sponsorship for autocracies and reduces them for democracies.
6
Marginal effects. Source: elaborated by the author. Mixed effects model with random effects on the L-Document level.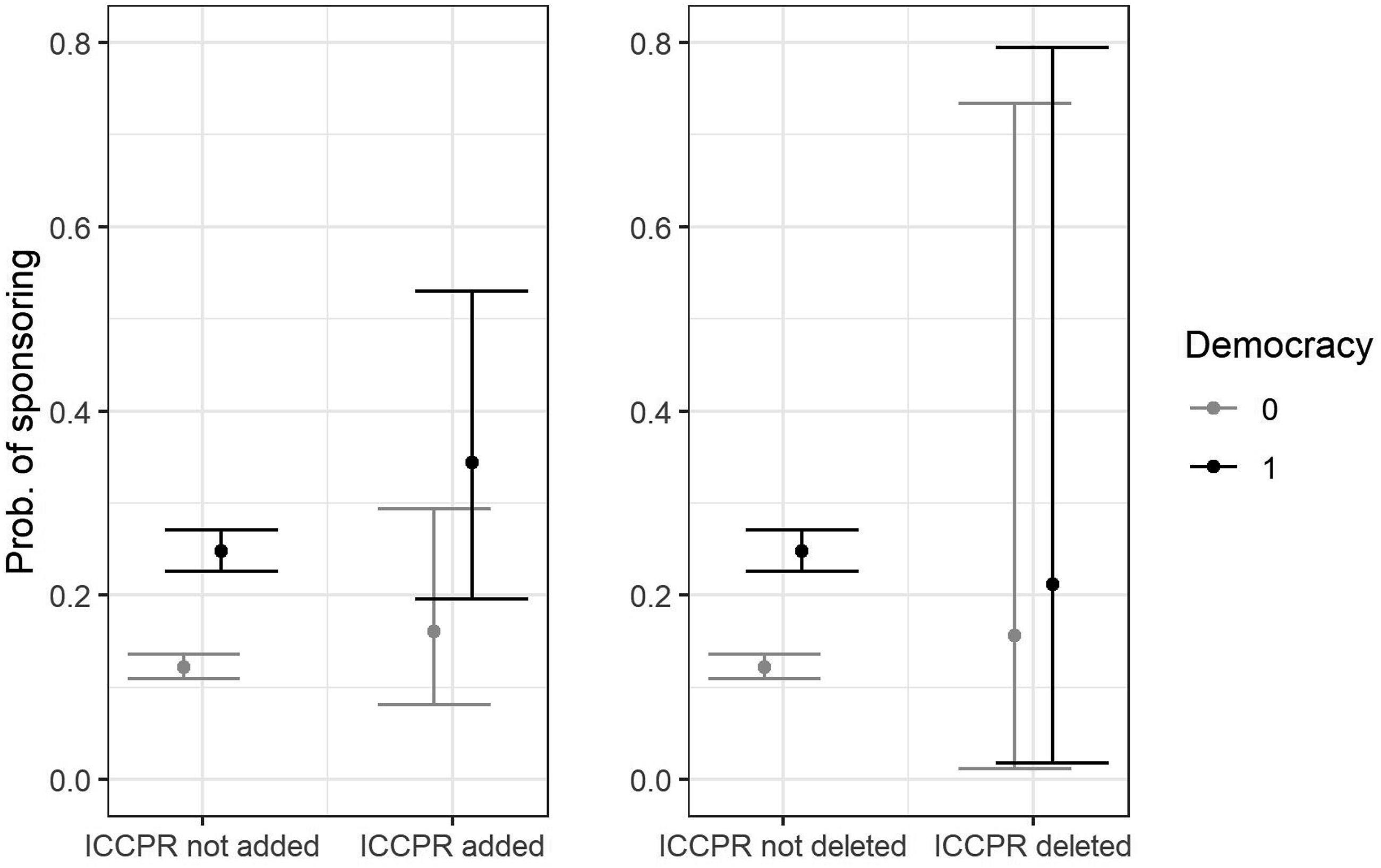
Conclusion
This article introduced an update to the UN General Assembly Sponsorship Dataset. It also provided three demonstrations on how the corpus could be used for measuring topic salience, sentiment, and drawing lexical profiles for individual member states and groups of countries. In closing, we highlight other features not explored and sketch more ambitious uses for this material for future researchers.
First, we have only scratched the surface of the wealth of secondary data that can be mined using text-as-data tools. Techniques, such as topic modeling or text classification, can be used in exploratory research to discern themes, their prevalence, and patterns of country engagement with detected issues. Besides bag-of-word approaches, named entity recognition also holds promise for the construction of knowledge graphs connecting member states, texts, and the entities named in texts (e.g., Glaser et al., 2022).
Beyond this utility for rich description, the dataset can open new paths for causal research that analyzes the multiple iterations of each draft. Text changes as independent variables, for example, have been a missing piece in important research agendas on UN bargaining. Outcomes such as vote switching or the time until co-sponsorship have been hitherto modeled as a function of exogenous, country-level covariates (e.g., aid dependence, Brazys and Panke 2017). This ignores the role that the final form of the negotiated text plays in satisfying or frustrating diplomats. Similar to what has been done in research about trade agreement negotiations (Alschner et al., 2018), scholars will be able to monitor how the changes between revisions affect bargaining dynamics, register items dropped and kept, and gauge which parties prevailed in the final version. Combined with other UNGA datasets, text changes as independent variables can reveal the effects of specific word choices, changes in sentiment, or the length of negotiations on voting (Voeten 2013) or co-sponsorship/withdrawal outcomes (Seabra and Mesquita 2022).
A new research agenda can explore text changes as dependent variables, seeking to explain the determinants of language choice in multilaterally negotiated texts. There is nascent research on whether the geopolitical clout of rising powers translates into molding the language of international organizations (Lam and Fung, 2024). Scholars will be able to use our revision-by-revision records to identify precisely when loaded words were added to drafts, by whom, and what material or symbolic covariates explain success in nudging the text of a draft. Draft texts can be compared to other corpora, such as speeches from the General Debate (Baturo et al., 2017) to verify if ideas from the latter diffuse into the former, or to descriptively measure the consistency between what leaders profess at the debate and the materials they sponsor in the rest of the session.
Supplemental Material
Supplemental Material - What do I need to say to get your signature? Adding draft resolution text to the UN General Assembly Sponsorship Dataset
Supplemental Material for What do I need to say to get your signature? Adding draft resolution text to the UN General Assembly Sponsorship Dataset by Rafael Mesquita in Research & Politics.
Footnotes
Acknowledgments
The author would like to thank the anonymous reviewers and the editors for their input.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Brazilian National Council for Scientific and Technological Development (CNPq) (Grant 420041/2021-4).
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from the Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.
Supplemental Material
Supplementary Material can be found at https://doi.org/10.7910/DVN/MPQUE2. The replication files are available at: ![]() .
.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.