
Abstract
I examine the abilities of large language models (LLMs) to accurately classify topics related to immigration from Spanish-language newspaper articles. I benchmark various LLMs (ChatGPT and Claude) and undergraduate coders with my own codings. I prompt models to label articles with either an 8 label scheme—directly analogous to the assignment of the undergraduate coders—or a 4 label scheme—aggregating the 8 labels into broader themes. In my analyses, a Few Shot ChatGPT 4o model with 8 labels emerges as the most reliable LLM classifier and comes close to the undergraduate coders, with models using 8 labels generally outperforming their 4 label counterparts. I also find that LLMs tend toward false positive errors. This application provides practical methodological guidance for applied researchers using LLMs in data coding. Overall, I demonstrate how LLMs can be effective supplements to human coders, as well as the continued value of human coding as a benchmark for text classification.
Keywords
Introduction
Text classification of media frames is a challenging task for machine coding, as it requires detecting subtle, implied cues rather than more straightforward features like positive or negative sentiment or the primary subject matter (Nicholls and Culpepper 2021; Zhu et al., 2023). This difficulty is compounded when working with non-English sources, where these large language models (LLMs)—which I also refer to as generative artificial intelligence (AI) models—perform worse due to a lack of high-quality training data (Nicholas and Bhatia, 2023).
In this article, I compare the performance of AI models and undergraduate researchers in classifying Spanish, immigration-focused, newspaper articles into a series of thematic, predefined labels with my own codings as the benchmark. This task involves multi-label classification, where each article can be assigned multiple labels simultaneously rather than being restricted to a single category. These articles are coded with either a 4 label scheme capturing the more fundamental dimensions of immigration discourse or an 8 label scheme better distinguishing specific types of frames—a comparison that illuminates the trade-offs between breadth and specificity in text analyses. With this application, I contribute to the evolving fields of text analysis and machine coding by assessing LLM performance beyond English-language contexts 1 and offering practical methodological guidance for applied researchers using these tools in other disciplines and tasks.
I assess the text classification abilities of three popular AI models—ChatGPT 4 Turbo, ChatGPT 4o, and Claude Sonnet 3.5—across two primary characteristics: 4 versus 8 labels and Zero versus One versus Few Shot prompts. 2 Existing work shows meaningful differences in model performance based on the provision of accurate examples (Chae and Davidson, 2024), highlighting the need to evaluate varying prompt specifications. I compare these LLMs in particular based on their abilities to analyze Spanish texts (Colombian national newspapers covering Venezuelan immigration), large context windows, 3 and ease of access to researchers.
My case provides a hard test for a growing consensus in existing research—that LLMs are useful tools comparable to humans—in two ways. First, the identification of news frames requires a thoroughly validated coding scheme because identifying frames relies on more subjective and nuanced, rather than concrete and deterministic, interpretations of text. Second, I use non-English documents, which are underrepresented in the majority of similar studies. 4 Traditionally, cutting-edge LLMs have been designed using English. English is currently the highest resourced language, meaning that it has the largest amount of high-quality digitized text on which models can train (Nicholas and Bhatia, 2023). Languages with less digitized text are less supported by these models; as a result, non-English researchers have been excluded from these advances. This article evaluates the performance of these LLMs using non-English texts in a more subjective task, bridging a methodological gap between English and non-English LLM applications.
There exist trade-offs for using LLMs versus human coders. Human coding is highly valuable, because these coders (1) can accurately classify texts given some set of instructions, (2) can explain their decision-making process, and (3) are often students gaining useful research experience, constituting a social good. On the other hand, human coding is expensive, slow, and requires fluency in the language of interest. Many researchers also face a lack of institutional resources or short time horizons that leave them unable to utilize human coding. As such, it is important to understand how LLMs and human coders compare. 5
I conclude that the Few Shot ChatGPT 4o model with 8 labels performs best, showing an average hamming loss 6 of 0.18 across labels. Digging deeper, I uncover that AI models using 8 labels are generally more reliable than their 4 label counterparts and that the Few Shot GPT 4o model performs worse than the undergraduate coders (hamming loss = 0.15) by 0.03 points on average. Finally, mistakes across the AI models were non-random and biased toward false positives.
My project establishes several practical guidelines for working with AI models in applied research. First, researchers need not be fluent in the language of interest—only proficient enough to give appropriate examples to the model—as I show that prompts with English instructions and Spanish examples have very similar outputs to those fully in Spanish. 7 Second, more detailed instructions can optimize model performance (even without changing the substantive content). Third, the order of labels within AI prompts does not sway model performance. 8 These findings show how researchers can more effectively use AI models for text classification tasks while maintaining high reliability.
My work demonstrates the opportunities and limitations of using generative AI models to analyze immigration frames in Spanish-language media, contributing to our understanding of their capabilities beyond English-language contexts. 9 In my application—tasking LLMs to identify frames in non-English texts—these models are not yet equivalent to human coders, as they display worse accuracy in multi-label tasks and non-random errors. While this study focuses specifically on Spanish-language immigration frames, the methodological insights uncovered—about prompt language choices, label order, coding scheme granularity, and model biases—offer valuable starting points for researchers working with LLMs across disciplines and contexts. Future research can systematically test whether these findings generalize across other languages and tasks. On this point, I encourage authors and publishers to consider regular meta-analyses of AI performance, as it is important to archive progress in this rapidly evolving field and better understand the generalizability of these tools.
Setting the scene
The author
To establish a benchmark, I classify a random sample of 590 Colombian newspaper articles focused on Venezuelan immigration from 2012 to 2023 using a set of predefined labels, each of which outline substantive frames. Since these underlying concepts are not mutually exclusive, I assign articles to all relevant labels instead of choosing a single label that fits best.
4 Label framework for coding articles.

8 Label framework for coding articles.

The distinctions in these 4 and 8 label schemes are substantively important. The 4 label scheme captures the more fundamental, generalizable dimensions of immigration discourse—for example, identifying the prevalence of threat-focused news coverage—but sacrifices specificity about the nature of these patterns. The 8 label scheme provides greater descriptive leverage to understand how these frames occur in the media environment—for example, how disease threat became a prevalent frame during the COVID-19 pandemic—albeit with higher costs, greater coding complexity, and difficulties distinguishing similar categories. 10 This trade-off extends to other applications where researchers balance breadth versus specificity, such as coding political discourse (broad ideological positions versus specific policy stances) or hate speech (generally prejudiced language versus specific rhetoric such as dehumanization or calls for violence).
I parsed each newspaper article for the 8 labels, coding articles that contained the label as 1s and those that did not contain the label as 0s. If the primary topic of the article was not immigration-related, I set all labels to 0. The output of this coding exercise is a dataset where each row represents a newspaper article and each column represents a label.
The undergraduates
In Spring 2024, I led a team of three undergraduate researchers—chosen based on their advanced Spanish skills—to scale up the coding task. 11 I initially worked with these undergraduates to refine both the instructions and content of the codebook. Once finalized, I made no substantive changes to the label definitions.
Since this task involved three independent coders, it inevitably produced disagreement. Because each undergraduate read and coded many of the same articles, there were multiple opportunities for said disagreement. Reassuringly, only 3% of all label-article cells disagreed. To resolve these disagreements for the purpose of assigning final labels, I join these three output datasets together based on agreed values. Then, for cells with disagreement, I default to responses from the two coders with the highest intercoder reliability metrics. 12 I first fill in disagreed values with output from the coder in this pair with the most research experience and Spanish fluency. Then, I fill in additional disagreed cells with the second coder in this pair. For any remaining disagreed cells, I use the output from my third coder.
The AI models
I compare the output of my undergraduate coders to three generative AI models: OpenAI’s ChatGPT (models: 4 Turbo and 4o) and Anthropic’s Claude (model: Sonnet 3.5). I compare multiple models so that I may (1) identify systematic differences and biases across models, establishing the generalizability of these patterns in AI architectures and (2) display the variety of existing options to applied researchers, providing practical guidance for those with different tasks or resource constraints. Thus, I employ these AI models within my analysis to uncover which is the best classifier, whether it can sufficiently replicate human coding, and how its outputs might differ from the other AI models, undergraduates, and the author.
I choose these AI models specifically, because they (1) were trained on Spanish-language texts, (2) have large context windows, and (3) are comparatively accessible. The first two characteristics are necessary for comparability between undergraduates and AI, as both sets of coders must understand the language of the texts and make their decisions using the entirety of the data.
I focus my classification exercises in a non-English context. Recent attempts to train LLMs on multiple languages at once—dubbed multilingual language models—have expanded language support (Nicholas and Bhatia, 2023). These multilingual AI models are increasingly proficient in less resourced languages, diversifying the field by allowing scholars from non-English backgrounds to employ cutting-edge models in their native languages. ChatGPT and Claude respond well to Spanish language prompts, so my project explores their text classification capabilities as compared to undergraduates who also know Spanish. (Spanish is less resourced than English, though it is still highly digitized and broadly used; thus, this is an easier test for the capabilities of these models in a non-English language than, say, Quechua or Welsh).
Furthermore, each model has a large context window, meaning that it can fully incorporate information from longer prompts. Some newspaper articles in my dataset are over 10,000 tokens 13 (over 5000 words), and earlier LLMs could not have processed these larger texts due to their smaller context windows. 14 Since undergraduate coders can read and incorporate all of the text into their decision-making, the machine coding models in question should be able to do the same.
Finally, these ChatGPT and Claude models do not require any large downloads, computational power, or fine-tuning on the side of the researchers, making them more accessible to those less familiar with LLMs. I gear the insights and analysis of this paper toward applied researchers using LLMs as tools, rather than those looking to build their own models. However, recent research challenges the replicability of these closed-source models (Spirling, 2023).
To create the prompts that I send to each AI model, I take the substantive content directly from my codebook and follow the best practices in prompt engineering 15 to elicit appropriately structured responses. 16 I then combine the prompts with each newspaper article and send my requests to the model API. Throughout the course of this project, I iteratively refined the instructions within my prompts to maximize model performance and obtain workable outputs.
Comparative analysis
I evaluate model performance by comparing the output of my AI models and undergraduates to my own codings. 17 In the main analyses, I use hamming loss to determine the reliability of these models. Hamming loss is best suited for multi-label classification tasks in which labels are not mutually exclusive. Unlike aggregate measures such as F1 or accuracy, hamming loss evaluates each label separately while maintaining an interpretable overall error rate. Models with hamming loss values closer to zero are better, as they predict fewer incorrect labels as a proportion of all labels. For example, a hamming loss of 0.25 indicates that 25% of labels in an article were incorrectly classified compared to the benchmark.
My analysis includes 18 LLM specifications in total: models from Claude Sonnet 3.5, ChatGPT 4 Turbo, or ChatGPT 4o; models with 4 labels or 8 labels; and models with Zero Shot, One Shot, or Few Shot prompts.
While I write my prompt instructions in English, I incorporate examples for the One Shot and Few Shot models in Spanish. I find no notable differences across models with both Spanish instructions and examples versus those with English instructions and Spanish examples. This suggests that the language of the prompt instructions is not hugely influential, making it easier for researchers to conduct text analyses in languages which they are not fluent. 18
How do LLMs compare to undergraduates and the author?
Figure 1 contrasts the hamming loss, pooled across labels, for each AI and undergraduate model specification.
19
Hamming loss (x-axis) across LLM models (y-axis). Models are ordered by performance from best (top) to worst (bottom). Lighter gray points refer to 8 label models, while darker gray points refer to 4 label models. Undergraduate coder values are shown separately at the top, and the author’s codings are used as the benchmark.
While the undergraduate coders perform best, 20 the Few Shot ChatGPT 4o model with 8 labels has the lowest average hamming loss across LLMs. 21 The mean hamming loss for the undergraduate coders is 0.15, meaning that they incorrectly predict 15% of labels on average. The Few Shot ChatGPT 4o model with 8 labels has an average hamming loss of 0.18, incorrectly predicting 18% of the labels on average. 22 A hamming loss of 0.18 falls short of recent classifiers (e.g., El Rifai et al. (2022) find hamming loss metrics ranging from 0.12 to 0.02 in a subject detection task in Arabic); however, media frames are more difficult to systematically identify than topic or sentiment, explaining this poorer performance (Nicholls and Culpepper, 2021).
ChatGPT 4 Turbo is slightly worse than 4o across the board and more expensive to run than 4o or Claude Sonnet 3.5. Sonnet 3.5 performs worse than 4o and 4 Turbo, though it has less variation between its 4 and 8 label specifications. Additionally, Sonnet’s Few Shot model does not improve over its Zero and One Shot models to the same degree as 4o and 4 Turbo.
Figure 2 breaks this analysis down by label and model specification, where values closer to zero indicate greater similarity to my codings. Model performance varies widely across labels. The undergraduate coders hover around a hamming loss of 0.10, except for the Vulnerable and P & I labels. In the 8 label specification, the AI models identify the Economic Threat and Economic Benefit labels quite well—with hamming loss scores around 0.10—while they struggle to identify other labels, such as Vulnerable, Instability, and P & I. In the 4 label specification, the Economic Benefit label performs best, and the P & I label shows the greatest variation in hamming loss metrics. In the next two sections, I explore what might be contributing to these differences in LLM performance via prompt structure and classification errors. Hamming loss (x-axis) by label and across model specifications (y-axis), separated into 8 label (left) and 4 label (right) models. Models are ordered by performance from best (top) to worst (bottom) and color-coded. Black dotted lines indicate undergraduate coder values.
How does prompt structure affect LLM outputs?
In Figures 1 and 2, the 8 label models outperform their 4 label counterparts. This begs the question of how prompts—and more specifically, the structure of information within prompts—influence LLM output. The 8 label models may perform better because they have more clearly structured information and more closely resemble the original task of the undergraduates than the 4 label prompts. Note, however, that the 4 label specifications contain the same information and examples as the 8 label specifications. 23 For example, Economic Benefit in both the 4 and 8 label AI prompts is the exact same. Likewise, Humanitarian in the 4 label specification contains the same information as Vulnerable and Refugee (combined) in the 8 label specification. While the underlying content is identical, the AI models benefit from having the information parsed into more specific subcategories in the 8 label prompt rather than combined into broader themes in the 4 label prompt.
Moreover, the One Shot and Few Shot models—by employing correctly identified examples of each label—display better metrics than the Zero Shot models, as more detailed sets of information can improve AI performance across the board (Chae and Davidson, 2024).
These findings have notable implications for the best practices of text classification tasks. There are trade-offs in the instruction of undergraduate coders: codebooks must be balanced in terms of length, structure, and detail, as undergraduates will (1) become fatigued if the instructions are too long or (2) be unclear as to their assignment if the instructions are ill-defined. I disaggregated my original conception of four overarching themes into eight more specific labels in my codebook to balance detail, structure, and cognitive load. Given that my 8 label models perform best, I provide additional evidence that more structured information improves classification performance. Writ large, one might be optimistic about using Few Shot LLMs to supplement undergraduate coders.
LLM classifiers are prone to false positives
I now explore how the outputs of my AI models may systematically differ from my own codings, finding a persistent bias toward false positives.
To quantify these classification errors, I take the difference between the proportion of articles coded as 1s by each model (undergraduate and AI) and the proportion of articles I coded as 1s. In this metric, positive values indicate false positive errors, negative values indicate false negative errors, and zero indicates perfect agreement with my codings. I depict these results in Figure 3, which reveals an overwhelming tendency toward false positives in the AI models. On average, the 8 label models show a weaker false positive bias than the 4 label models. Those models that previously displayed worse performance metrics—that is, higher values for hamming loss—simultaneously exhibit the false positive bias more egregiously (e.g., the Zero Shot ChatGPT 4 Turbo model). False positive rates (x-axis) by label and across model specifications (y-axis), separated into 8 label (left) and 4 label (right) models. Models are ordered by performance from best (top) to worst (bottom) and color-coded. Black dotted lines indicate undergraduate coder values.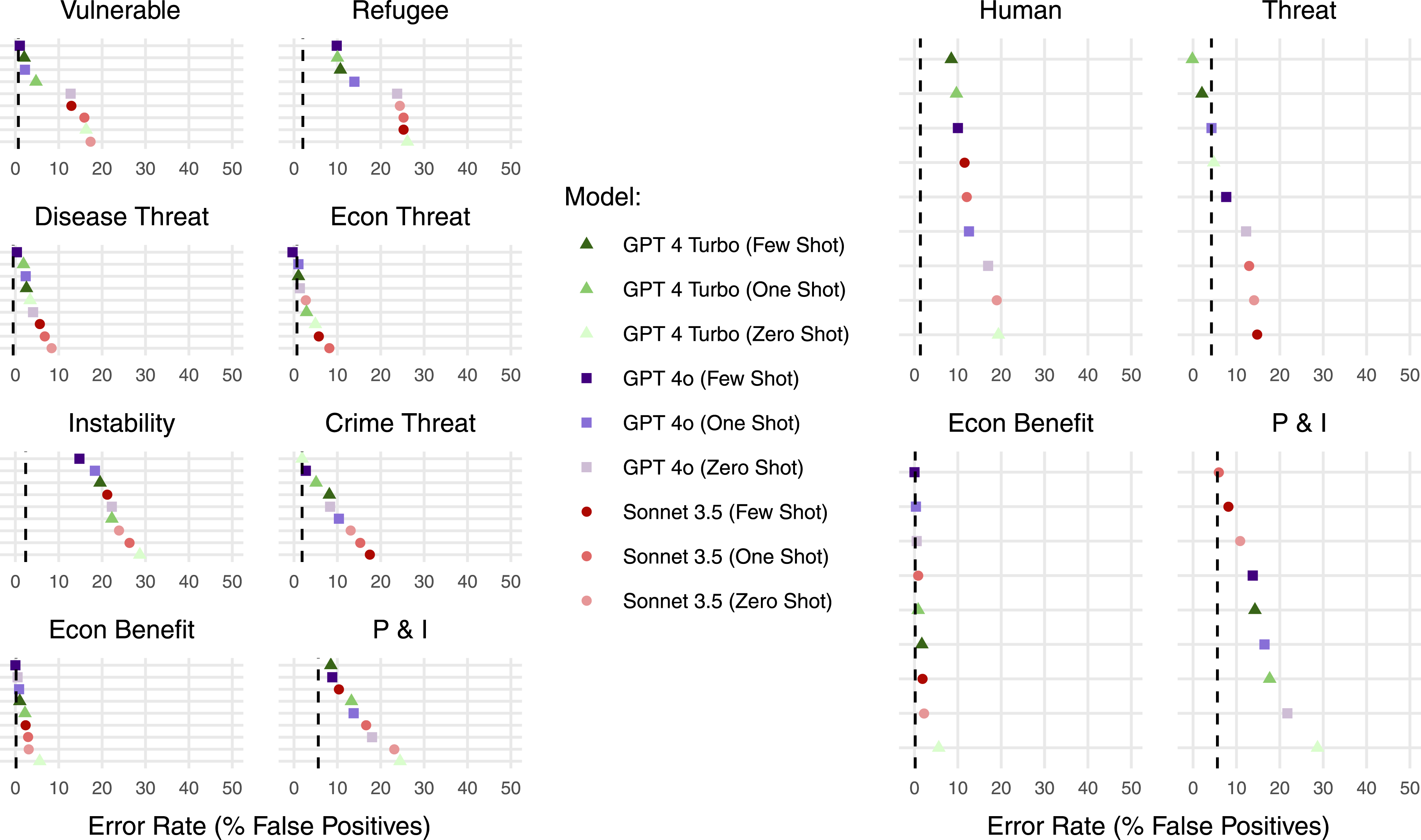
I investigate the frequency and predictors of this false positive bias in Appendix H. The AI models make false positive errors at twice the rate of false negative errors, while undergraduates make these errors at equal rates. Furthermore, regression analyses show that when my undergraduates reached consensus on article labels, AI models were significantly less likely to code those article labels as 1s. This suggests that machine coding may make stronger inferences from more limited informational cues, while human uncertainty serves as a natural guard against false positives—presenting researchers with both an important validation tool and potential avenue for training LLMs in what not to code positively. Relatedly, I find no evidence that the order of label presentation in AI prompts (fixed versus random ordering) contributes to this bias. 24
To further pursue what may contribute to this bias, I conducted close readings of several newspaper articles that the AI models coded as 1s but the undergraduates and I coded as 0s. 25 The AI models seemed to pick up on more subtle label cues than the human coders did, but they had trouble differentiating certain labels, such as Vulnerable and Refugee. The LLMs were also more likely to make multiple coding errors within the same article, as opposed to mistakenly coding just one label and getting the others correct.
While existing literature notes the problematic, black-box nature of LLMs (Bisbee et al., 2024; Spirling, 2023), I am unaware of any existing work that explains this false positive bias, thus suggesting an important area of future research.
Discussion and conclusion
In this note, I analyze the reliability of LLMs in comparison to undergraduates and the author’s codings, providing evidence that a Few Shot ChatGPT 4o model with 8 labels is the most reliable classifier. The application of my study—Spanish-language immigration media—importantly extends existing work beyond English texts and supplies rich data on how AI model performance varies based on topic (e.g., Vulnerable versus Instability) and label structure (4 versus 8 label schemes).
I offer three additional takeaways to practitioners and the burgeoning literature on LLM classifiers. First, LLMs using prompts with a greater number of more detailed labels perform better than those using prompts with fewer, broader labels. If researchers are substantively interested in broader categories, they should still code using more discrete labels and then aggregate the output into broader labels. Second, in comparison to the author’s codings, the Few Shot ChatGPT 4o model (hamming loss of 0.18) performs slightly worse than the undergraduate coders (hamming loss of 0.15). However, there is minimal performance variation across these AI models, indicating that—rather than being artifacts of a single model—my findings are robust across a variety of model architectures and specifications. Third, these LLMs are systematically biased toward false positive errors.
I also contribute a series of effective strategies for using these models. I demonstrate that researchers do not need to be fluent in the target language to effectively use these models—only acquainted enough to give appropriate examples for model training—as prompts with English instructions fared just as well as those with Spanish instructions. Additionally, more detailed instructions improve model performance, but randomizing the label order does not.
Use cases for social science applications of LLMs vary in their difficulty and complexity. While AI models have recently approached human abilities on some tasks, they still struggle with others. For example, ChatGPT performs well in sentiment analysis and other more objective tasks but struggles with tasks that (1) require nuanced contextual understanding or (2) involve less accessible information or recent events (Zhu et al., 2023). This project tackles both of these more challenging tasks for LLM classification: identifying newspaper frames—which requires nuanced contextual judgments—and analyzing non-English texts—which have less accessible information. In this setting, the best performing AI model lags slightly behind undergraduate coders and displays a systematic bias toward false positive errors.
While these figures are likely to change as AI models improve, this article provides a framework for assessment of their performance as compared to both undergraduates and researchers. I encourage publishers to incentivize meta-analyses and researchers to conduct regular tests of LLM performance across a variety of social science tasks. A centralized meta-analysis hub, for instance, might aggregate research such as this article and contribute more broadly to understandings about the generalizability of LLMs across languages and tasks, as well as the reliability and replicability of their results over time.
Supplemental Material
Supplemental Material - Benchmarking AI and human text classifications in the context of newspaper frames: A multi-label LLM classification approach
Supplemental Material for Benchmarking AI and human text classifications in the context of newspaper frames: A multi-label LLM classification approach by Alexander Tripp in Research & Politics.
Footnotes
Acknowledgments
I thank James Bisbee and Cindy Kam for their helpful feedback on this project. I also thank Celeste Dorantes, Anthony Rodas, and Anthea Walker for research assistance.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
My data will be made available on the Research & Politics Harvard Dataverse repository.
Supplemental Material
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from the Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.