
Abstract
Background:
Machine learning methods have emerged as a promising approach to prevent drug-induced nephrotoxicity.
Objective:
This review evaluates the quality and highlights recent advances of machine learning algorithms for predicting drug-induced nephrotoxicity.
Eligibility criteria:
Studies on machine learning models to predict drug-induced acute kidney injury, acute kidney disease, or both published between January 2014 and August 2024 were eligible.
Sources of evidence:
A comprehensive search was conducted by using PubMed, Embase, Web of Science, Cochrane Library, and Scopus.
Charting methods:
A standardized charting form was developed based on CHARMS, TRIPOD+AI, and PROBAST tools to assess the quality and risk of bias across studies.
Results:
From the initial 5,179 articles searched, 24 studies were included in this review. All studies achieved good area under the receiver operating characteristic curves (AUROCs) above 0.75, with boosting machines being the most frequently outperforming algorithms (n = 7, 29.17%), and neural networks showed the highest median AUROC of 0.90 (0.86–0.92). Two-thirds of studies (n = 16; 66.67%) predicted acute kidney injury, whereas only 5 (20.83%) focused on acute kidney disease. Estimated glomerular filtration rate, blood urea nitrogen, serum creatinine, hemoglobin, and albumin emerged as the most utilized features by 10 (41.67%), 9 (37.5%), 9 (37.5%), 8 (33.33%), and 8 (33.33%) studies, respectively. Diabetes, heart failure, diuretics, and non-steroidal anti-inflammatory drugs were frequently selected features by 7 (29.17%), 5 (20.83%), 5 (20.83%), and 4 (16.67%) studies, respectively. The 2025 PROBAST+AI risk-of-bias assessment indicated that 7 (29.17%) studies had a low risk of bias. A high risk of bias was observed in 20 (83.33%), 18 (75%), and 17 (70.83%) studies due to insufficient performance evaluation, small sample sizes, and lack of external validation.
Conclusion:
Recent machine learning studies have demonstrated great performance using clinically obtainable features. Incorporating acute kidney injury and disease, methodological enhancement, and guideline adherence can facilitate clinical applicability in preventing drug-induced nephrotoxicity.
Plain language summary
Introduction
Utilizing machine learning to predict drug-induced nephrotoxicity is increasingly essential in modern healthcare. Common causal agents include antibiotics, contrast agents, and chemotherapeutic drugs. 1 Strategies such as temporary drug discontinuation, 2 hydration for cisplatin-induced toxicity, 3 and administering sodium bicarbonate for contrast-related nephrotoxicity, 4 cannot entirely prevent drug-induced nephrotoxicity. Advanced machine learning technologies can identify intricate patterns to predict drug-induced nephrotoxicity with higher accuracy than conventional clinical approaches. 5 For patients at extremely high risk of drug-induced nephrotoxicity, clinicians can avoid the selection of nephrotoxic drugs at the onset of prescribing. For patients treated with nephrotoxic agents, continuous monitoring by machine learning techniques can predict any impending drug-induced nephrotoxicity, allowing clinicians to intervene before significant kidney damage occurs. 6 The patient’s clinical outcomes, long-term mortality, 7 and healthcare costs 8 can thus be improved by machine learning-based predictions of drug-induced nephrotoxicity.
Understanding the pathophysiology and progression patterns of drug-induced nephrotoxicity is vital for developing and designing machine learning algorithms. Renal damage may present as rapid acute kidney injury (AKI) in the initial days after use of a nephrotoxic agent. Traditionally, clinicians rely on standardized diagnostic frameworks, such as the Kidney Disease: Improving Global Outcomes (KDIGO) or the Risk, Injury, Failure, Loss of kidney function, and End-stage kidney disease (RIFLE) criteria, to stage these conditions. Some patients then progress to acute kidney disease (AKD), a transitional phase toward chronic kidney disease (CKD), 9 with or without the presence of AKI. Continuous and careful follow-up, even after AKI resolution, can prevent the occurrence of irreversible CKD. Detecting patients at risk of AKD provides an opportunity to utilize the critical window period to rescue kidney function. 10 The machine learning-based application meets the need for proactive approaches before the onset of acute renal damage and moderate ongoing kidney injury, thereby making long-term renal care strategies possible.
Machine learning has rapidly emerged as a transformative force in nephrology, enabling early risk stratification to improve patient outcomes. The mainstream predictive applications of machine learning in nephrology are to identify and mitigate the risk of high-mortality or morbidity conditions, including AKI and CKD, across different patient populations or time periods, such as post-COVID-19. 11 Halder et al. developed an intelligent web-based application for CKD prediction utilizing several machine learning algorithms, which demonstrated robust predictive accuracy. 12 The machine learning prediction model can further leverage Electronic Health Records (EHRs) to proactively identify patients at elevated risk prior to clinical presentation.
Predicting drug-induced nephrotoxicity by machine learning algorithms holds great promise but requires careful optimization for clinical implementation. Limited sample sizes, 13 a lack of external validation, 14 overfitting, improper missing data management, 15 and a restrained explanation may reduce the utility of such models. Employing quality assessment tools to guide the design and development of machine learning-based models for drug-induced nephrotoxicity facilitates clinical application. Existing tools such as CHARMS, PROBAST, APPRAISE-AI, and TRIPOD+AI are very extensive but general for all kinds of predictive models.15–18 The unique aspects and current progress of predictive models for drug-induced nephrotoxicity require specific evaluation metrics to expedite their clinical implementation.
This review aims to address the notable progress in recent machine learning studies that specifically focused on drug-induced nephrotoxicity. Available machine learning reviews were conducted for AKI and sepsis-associated AKI,19–23 and no literature has comprehensively evaluated the machine learning studies for drug-induced nephrotoxicity. This review also seeks to analyze innovative data-mining methods and algorithms currently available in the literature, identify the most frequently selected predictive features, and evaluate model performance, in order to provide constructive guidance to enhance the methodological rigor and clinical relevance of machine learning models for drug-induced nephrotoxicity.
Methods
Study design and search strategy
This review analyzed studies that used machine learning models to predict drug-induced nephrotoxicity, published in English, between January 1, 2014 and August 31, 2024. It was conducted in accordance with the PRISMA-ScR guidelines for scoping reviews 24 (Supplemental Table 1). This review considered a range of machine learning algorithms, including neural networks (NNs), boosting machines (BMs), random forests (RFs), decision trees (DTs), support vector machines (SVMs), naïve Bayes, and logistic regressions. Original studies of machine learning models to predict drug-induced AKI, AKD, or both were eligible. The nephrotoxicity definitions used in each study varied and are summarized in Supplemental Table 2. Exclusion criteria applied to review articles, conference papers, case reports, non-journal sources, animal or in vitro research, studies predicting multiple adverse drug reactions (ADRs) as a composite outcome, without separating nephrotoxicity and other ADRs, those not using creatinine or the estimated glomerular filtration rate (eGFR) to define drug-induced nephrotoxicity, and model updating studies. The predefined protocol for paper selection is outlined in Supplemental Figure 1.
A thorough search was performed across PubMed, Cochrane Library, Embase, Scopus, and Web of Science. To focus on recent advances in the clinical field, the IEEE Xplore was not used. The initial search strategy was adapted from Li et al. and further refined. 21 Key terms included “artificial intelligence,” “machine learning,” and “deep learning,” as well as kidney injury-related terms such as “acute kidney injury,” “acute kidney disease,” and “nephrotoxicity.” Additional targeted keywords included “prediction,” “prognosis,” “diagnosis,” and “risk assessment.” The finalized search strategies for each database are detailed in Supplemental Table 3. All results were exported to EndNote, with duplicates removed both automatically and manually.
Two reviewers initially screened a subset of publications, refined the data analysis process to ensure consistency, and independently assessed the titles, abstracts, and full texts of all identified studies. The items collected for each study are listed in Supplemental Figure 2. Baseline conditions (e.g., age, comorbidities/medical history) were collected as features used in each study, as shown in Supplemental Table 4. Any disagreements during the study selection, data charting, and quality assessment were resolved through consensus with a third reviewer.
Analysis of study characteristics and features
Studies were first grouped by drug and year. A timeline plot was used to visualize the trend of the machine learning studies published during the study period. Data were presented using both absolute values and proportions to represent the core characteristics of the studies. Frequency of study types, validation methods, sample sizes, and machine learning algorithm were calculated to reveal the current development of machine learning studies for drug-induced nephrotoxicity. Key features in establishing machine learning models were grouped by drugs, and their frequencies of selection are illustrated with a bar plot.
Comparison of model performances
Model performance metrics, including the area under the receiver operating characteristic curve (AUROC), area under the precision-recall curve (AUPRC), accuracy, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and F1-score, were summarized to reveal the performance of the published machine learning models in predicting drug-induced nephrotoxicity. The performance of these metrics was compared by drug type and algorithm, using box plots to demonstrate the model’s predictive ability. The frequencies of each metric employed in the studies were calculated to reveal their utility. Supplemental Table 5 showed the definitions of the metrics. An independent t test or Mann–Whitney U test was used to perform a comparative analysis, depending on the data distribution (Table 2). Statistical significance was determined using a two-tailed test with p < 0.05. The statistical test and data visualization in this review were performed using Python v3.12.12 (Python Software Foundation, Beaverton, OR, USA).
Quality assessment of the machine learning studies
Two tools were employed to assess the quality of current machine learning research for drug-induced nephrotoxicity. The 2025 PROBAST+AI tool was first utilized, and results are summarized in a stacked bar plot. 25 Four subdomains—analysis, outcome, predictor, and participants—were assessed alongside the overall assessment. The study also developed a standardized charting tool by adapting important quality criteria supported by CHARMS, PROBAST, APPRAISE-AI, and TRIPOD+AI15–18 (Supplemental Table 6). The author team discussed, selected, and rephrased 12 criteria to form a quality assessment tool to evaluate studies on drug-induced nephrotoxicity. Each criterion was rated using scores of +0, +1, or +2. The quality rate of each study was defined as the sum of scores divided by the maximum score of 48 points. The rate was, respectively, classified into low, moderate, and high quality as <40%, 40%–59%, and ⩾60%, as adapted from APPRAISE-AI.
Results
Characteristics of drug-induced nephrotoxicity in machine learning studies
In total, 3,710 unique citations were identified through database searches, and 2,695 studies not meeting specific inclusion criteria were excluded (Supplemental Figure 1). There were 982 reviews/meta-analyses/non-journal articles, six animal/in vitro studies, one study examining multiple ADRs, and two studies that did not define nephrotoxicity by serum creatinine or eGFR, which were excluded. The main study design and methods of the 24 studies are summarized in Supplemental Table 2.26–49 Most studies utilized a short prediction window (⩽7 days), specifically within 7 days (n = 8, 33.33%), 72 h (n = 5, 20.83%), and 48 h (n = 3, 12.50%), while the remaining studies either employed longer timeframes or did not specify a prediction window (Supplemental Table 2). Figure 1 illustrates evolving trends in the included studies. The number of publications significantly increased in 2023 and 2024 (n = 14, 58.33%), marking a notable rise compared to earlier years (2017–2022). RFs led the way (n = 3, 12.5%) before 2022. BMs emerged as the most frequent model (n = 6, 25%) in 2023 and 2024.
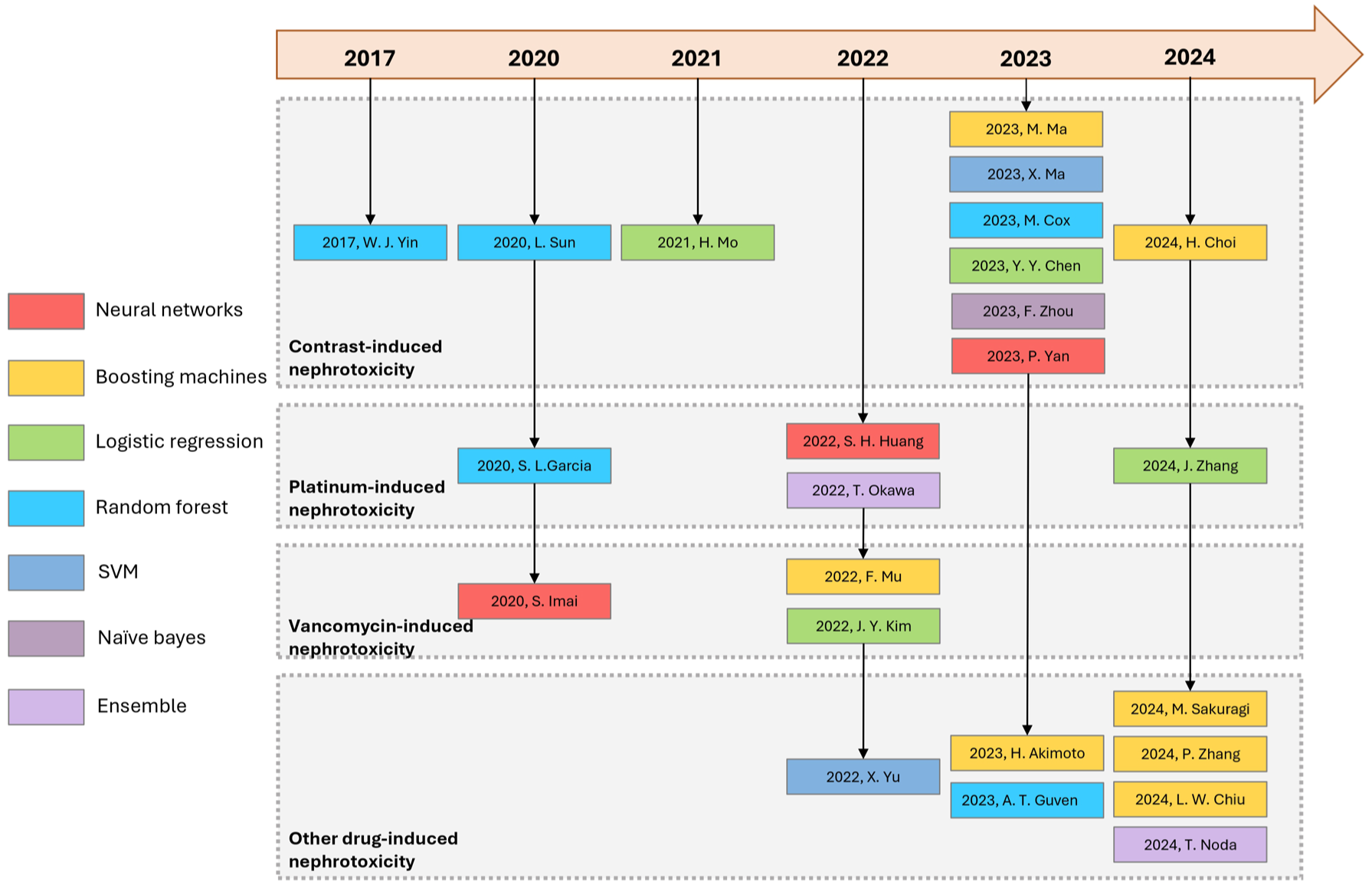
Timeline plot of drug-induced nephrotoxicity machine learning studies. A chronological overview of studies on drug-induced nephrotoxicity is illustrated in a timeline plot. Each study is organized by year and its clinical focus (type of nephrotoxicity). Colors represent the machine learning algorithm employed.
Most studies were conducted in East Asia, particularly in China (n = 10, 41.7%), Japan (n = 6, 25.0%), Taiwan (n = 3, 12.5%), and South Korea (n = 2, 8.3%). Three studies were conducted in North America/Europe, including in the United States (n = 1, 4.17%), Denmark (n = 1, 4.17%), and Turkey (n = 1, 4.17%; Table 1). All studies employed retrospective designs, with two studies also adding prospective validation. Twenty-two (91.67%) studies conducted internal validation with 7 (29.17%), 11 (45.83%), 3 (12.50%), and 1 (4.17%) using cross, both cross and split, split, and unspecified validation, respectively. External validation was performed in only 7 (29.17%) studies. Eleven (45.83%) studies included patient numbers ranging from 100 to 1,000, while only 4 (16.67%) studies exceeded 10,000 participants. The number of studies that focused on contrast-, platinum-, and vancomycin-induced nephrotoxicity was 10 (41.76%), 4 (16.67%), and 3 (12.5%), respectively. Two-thirds (n = 16, 66.67%) of the studies predicted AKI, with 5 (20.83%) focusing on AKD.
Summary of included studies.

AKD, acute kidney disease; AKI, acute kidney injury; AUPRC, area under the precision-recall curve; AUROC, area under the receiver operating characteristic curve; NPV, negative predictive value; PPV, positive predictive value; SHAP, SHapley Additive exPlanations; SVM, support vector machine.
Analysis of feature selection
Figure 2 and Supplemental Table 4 show distributions of the most frequently selected features across studies in predicting drug-induced nephrotoxicity. Laboratory tests, including eGFR, serum creatinine, (SCr), Blood Urea Nitrogen (BUN), hemoglobin, and albumin, were selected by 10 (41.67%), 9 (37.5%), 9 (37.5%), 8 (33.33%), and 8 (33.33%) studies in all drug categories, respectively. Diabetes and heart failure were the most common comorbidities selected by 7 (29.17%) and 5 (20.83%) studies, respectively. The concurrent use of diuretics and NSAIDs was noted by 5 (20.83%) and 4 (16.67%) studies, respectively. The most frequently selected features for contrast agent-induced nephrotoxicity included eGFR, age, BUN, serum creatinine, hemoglobin, and diabetes. At least 50% of studies that focused on platinum agents selected eGFR, age, albumin, and sex as features. Notably, all vancomycin studies selected the drug’s blood concentration, and two of them (66.67%) selected creatinine clearance as a feature.

The most selected features of drug-induced nephrotoxicity machine learning studies. The proportional use of various clinical predictors in drug-induced nephrotoxicity studies is illustrated in bar plots. Columns represent causative drug classes, the y-axis represents features, the x-axis represents proportion, and colors represent categories.
Comparison of model performances
Table 1 shows the frequency of each metric employed by the 24 studies. All studies (n = 24, 100%) reported model performance using the AUROC, while accuracy, sensitivity, and specificity were also widely reported by 19 (79.17%), 20 (83.33%), and 18 (75%) studies, respectively. The metric for imbalanced data, AUPRC, was reported in only 6 (25%) studies.
Figure 3(a) presents the model performance for different algorithms. All studies reported AUROC values exceeding 0.75, with the NN algorithm achieving the highest median AUROC of 0.90. Sensitivity values of 0.84, 0.75, and 0.67 were recorded for NNs, BMs, and RFs, respectively, while specificity values were 0.89, 0.77, and 0.80 for those corresponding models. F1-scores, which balance precision and recall, were 0.67 for NNs, 0.32 for BMs, and 0.45 for RFs. NNs demonstrated the narrowest variability across all evaluated metrics. BMs exhibited wide variations in performance across several metrics, particularly sensitivity, PPV, and F1-score. RFs also demonstrated pronounced variations in the PPV, NPV, and F1-score.

Model performances of drug-induced nephrotoxicity machine learning studies across different metrics. (a) The box plot compares performance distributions of various machine learning algorithms. The x-axis represents key evaluation metrics, the y-axis represents the corresponding scores, and colors represent the machine learning algorithms employed. (b) The box plot compares the performance score distributions for predictive models of different drug-induced nephrotoxicity. Colors represent inducing drug agents.
Figure 3(b) shows the performance metrics of studies across different drug categories. AUROC scores ranged 0.75–0.85. Notably, median AUROC scores were 0.82 and 0.85 for vancomycin- and other drug-induced nephrotoxicity models, respectively, while they were 0.81 and 0.76 for contrast- and platinum-induced models, respectively. Median accuracy ranged 0.74–0.89, with 0.89, 0.79, 0.76, and 0.74 for vancomycin-, other drug-, contrast-, and platinum-induced nephrotoxicity, respectively. Supplemental Table 7 shows the performance metrics of each study.
Table 2 presents selected deeper comparative analyses for a few specific comparisons. Models with and without age showed no statistically significant difference in AUROCs (mean AUROC ± SD: 0.811 ± 0.092 vs 0.840 ± 0.058). Excluding diabetes resulted in a statistically insignificant increase in AUROC, from 0.810 ± 0.095 (diabetes) to 0.834 ± 0.067 (no diabetes). Including eGFR yielded an AUROC that was not statistically different from that when it was excluded (0.815 ± 0.065 vs 0.844 ± 0.088). A statistically insignificant difference in AUROC was observed between with and without diuretics (0.878 ± 0.054 vs 0.813 ± 0.075, p = 0.087). Models that underwent external validation reported an AUROC that was statistically insignificant from those that did not (median AUROC (IQR): 0.817 (0.063) vs 0.827 (0.096), p = 0.105). Studies employing appropriate missing data handling achieved a significantly higher AUROC than those using inappropriate handling (0.825 (0.069) vs 0.729 (0.074), p < 0.001). Only 9 (37.5%) studies used SHapley Additive exPlanations (SHAP) as the explainability approach, while none used attention visualization (Table 1).
Comparative analysis of model performance for selected features or study methods.
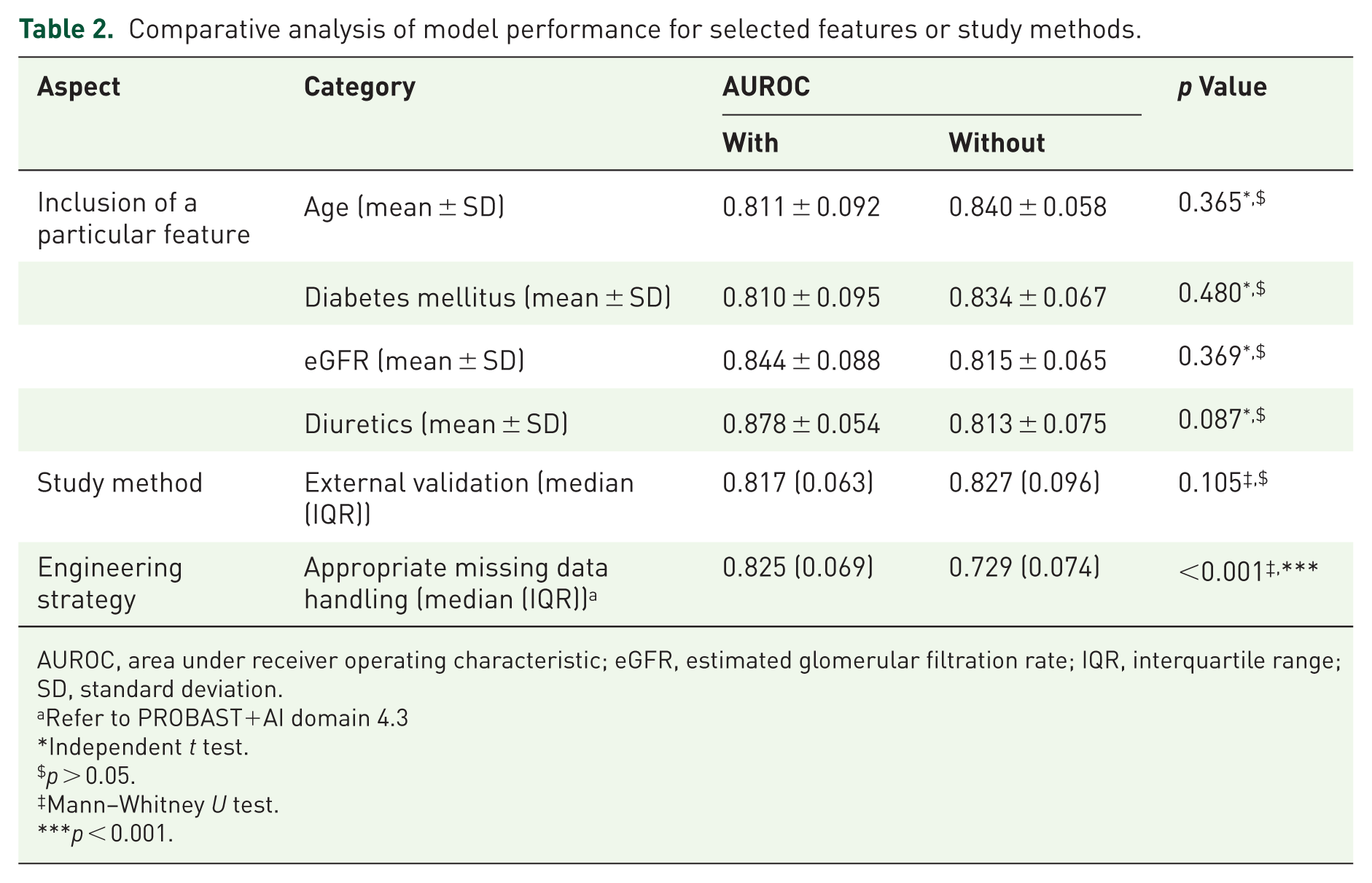
AUROC, area under receiver operating characteristic; eGFR, estimated glomerular filtration rate; IQR, interquartile range; SD, standard deviation.
Refer to PROBAST+AI domain 4.3
Independent t test.
p > 0.05.
Mann–Whitney U test.
p < 0.001.
Quality assessment of the machine learning studies
Figure 4 displays the 2025 PROBAST+AI risk-of-bias results, indicating that 11 (45.83%) studies had a high risk of bias in the overall assessment. The predictor and outcome domains had the lowest risk of bias, with 19 (79.17%) and 22 (91.67%) studies, respectively, rated as low risk. The participant domain had 9 (37.5%) studies with unclear risk and 4 (16.67%) with high risk. The highest proportion of studies at high risk of bias was observed in the analysis domain (n = 9, 37.5%; Supplemental Table 8). Figure 5 further showed that, within the analysis domain, the subdomains of performance evaluation and sample size had relatively high proportions of studies rated as high risk, with 20 (83.33%) and 18 (75.00%), respectively. In contrast, all studies were rated as having a low risk of bias in the three subdomains of data source, uniform definition/assessment for predictors, and outcomes (Supplemental Table 8).

Proportions of drug-induced nephrotoxicity machine learning studies rated using 2025 PROBAST+AI. The risk-of-bias assessment is summarized in the stacked bar plot. Each horizontal bar corresponds to a study domain, and its colored segments illustrate the proportion of studies rated as having high, unclear, or low risk. The risk of bias of each domain was determined by answers to signaling questions, where a low-risk rating was assigned if all responses were affirmative. An unclear risk rating was assigned due to insufficient information, while any negative response required reviewers to apply their judgment to determine a final rating of low, high, or unclear risk.
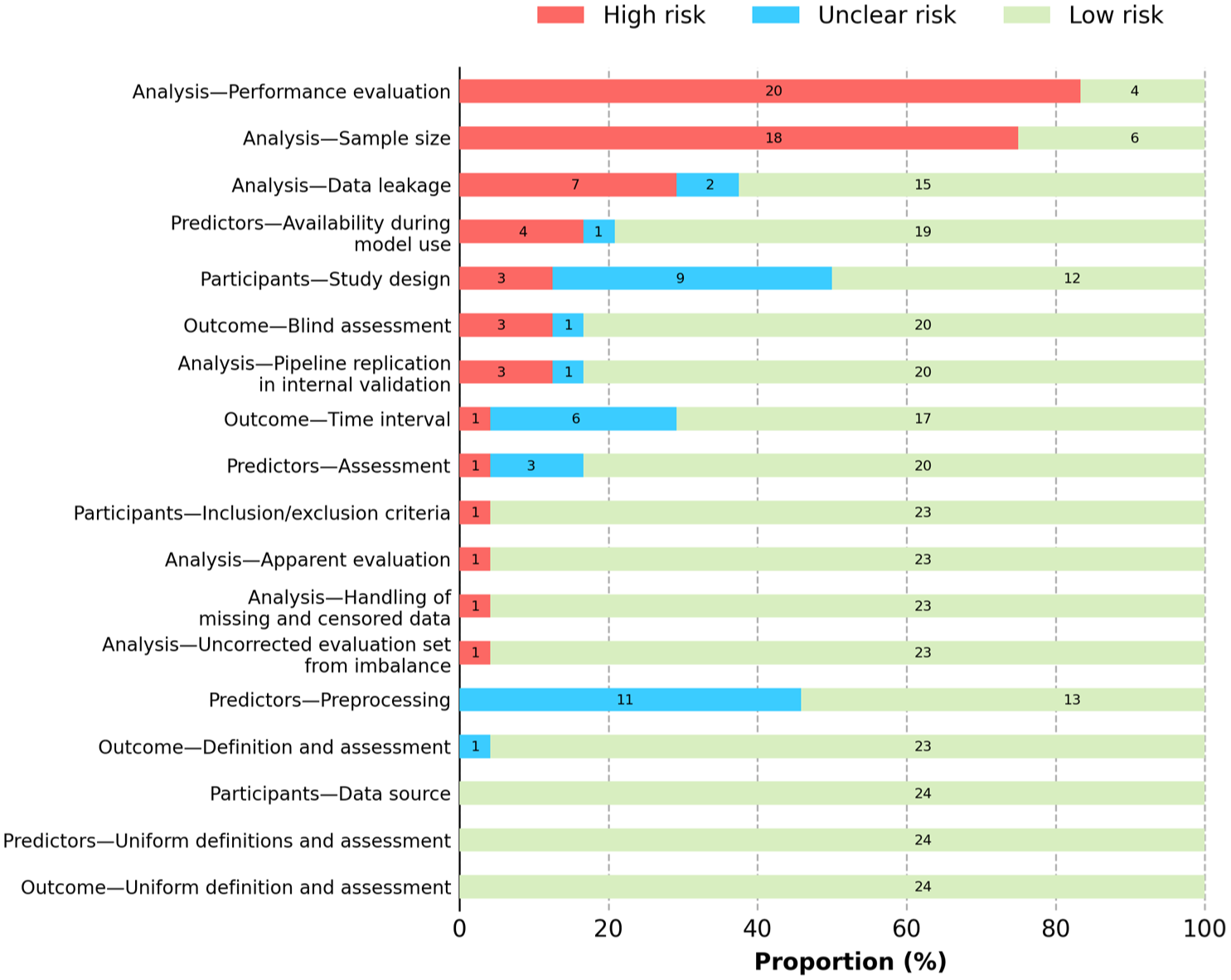
Frequencies of aspects with high and unclear risk of bias in drug-induced nephrotoxicity machine learning studies. Details of the risk-of-bias assessment are illustrated in the stacked bar plot, similar to the overall risk-of-bias assessment. Each horizontal bar represents a specific methodological subdomain.
Figure 6 illustrates the overall quality of the studies evaluated using 12 criteria specifically designed to assess machine learning studies of drug-induced nephrotoxicity prediction. Five (20.83%) studies had high overall quality, while 14 (58.33%) and 5 (20.83%) had moderate and low overall quality, respectively. Criteria achieving a quality rate of over 60% were predictive time for nephrotoxicity, handling of continuous features, feature definition, feature selection, and reporting of final features, with respective rates of 83.33%, 83.33%, 75%, 79.17%, and 87.5%. In contrast, criteria with low quality rates included reporting the number of participants with missing data, performing external validation, and using multicenter data sources, with respective quality rates of only 18.75%, 29.17%, and 33.33% (Supplemental Table 9).
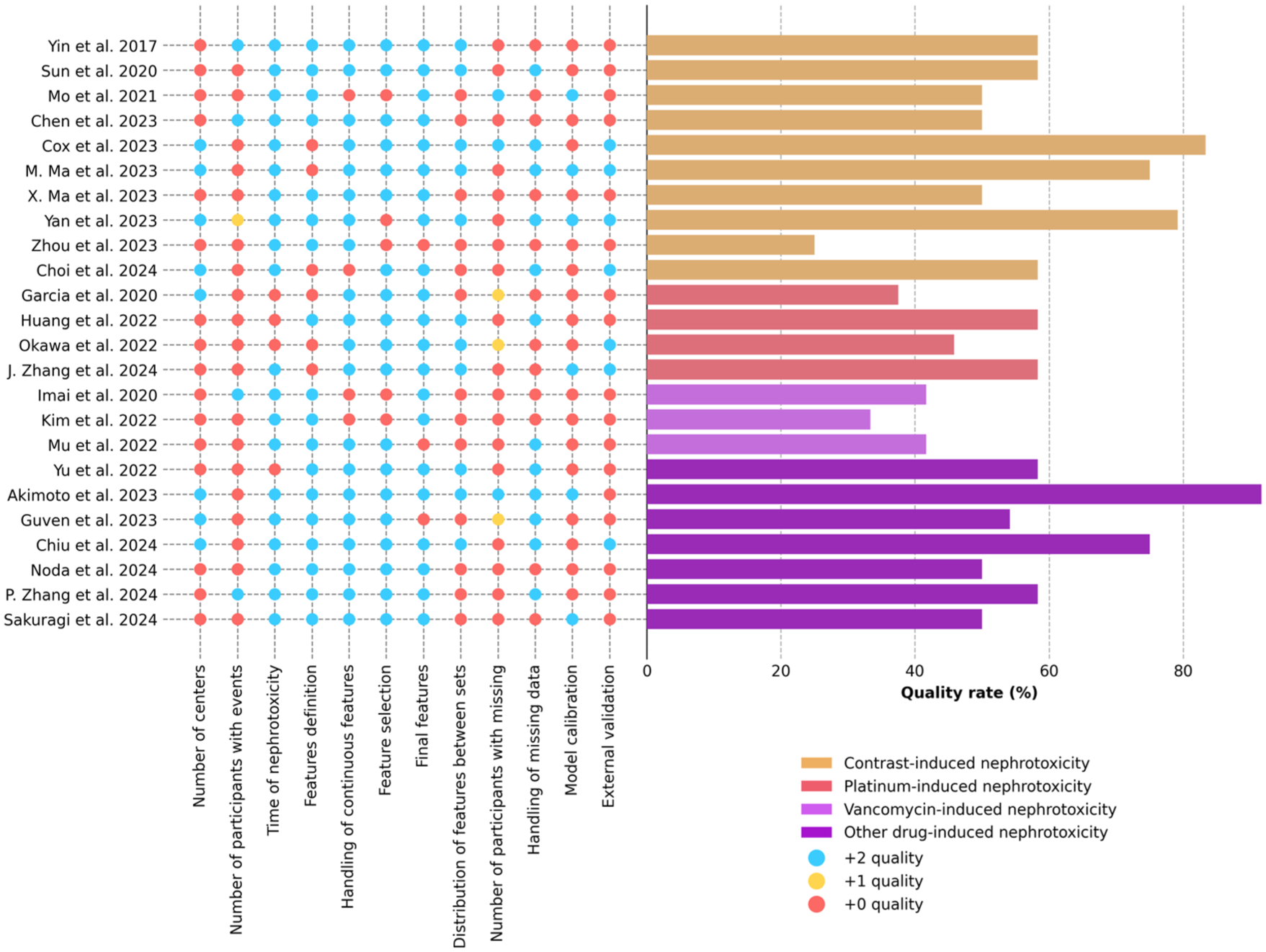
Quality assessment of drug-induced machine learning studies. The quality assessment of each study is summarized in the summary plot. The x-axis on the dot matrix on the left represents individual criterion scores, the y-axis represents the quality of each study, and the x-axis on the bar chart on the right represents aggregated quality scores. Colors represent either drug classes or quality points.
Discussion
This review revealed several key findings on the current progress of machine learning development in predicting drug-induced nephrotoxicity. The number of publications has significantly increased over the last 2 years, underscoring the importance of applying innovative prediction methods to prevent drug-induced nephrotoxicity. A clear evolution in selecting algorithms was also observed. A notable overlap in predictive features was also identified across different types of drug-induced nephrotoxicity. NNs and BMs consistently demonstrated superior predictive performances in predicting drug-induced nephrotoxicity. The present study applied integrated tools to assess the included studies for providing a balanced clinical appraisal. The frontline innovations of current machine learning models for predicting drug-induced nephrotoxicity, with further methodological improvements, hold high potential for clinical application in the near future.
The risk-of-bias analysis using integrated tools in the current study highlighted the methodological strengths and weaknesses of current studies for predicting drug-induced nephrotoxicity. The comparative analyses in Table 2 showed that appropriately handling missing data substantially enhanced model performance. Most studies carefully performed the process of defining and selecting features, handling continuous features, and determining final features. However, very few studies calibrated models to assess the accuracy and reliability of predicted probabilities.15,50 Only a limited number of studies incorporated model explanation techniques, such as SHAP or attention visualization, to elucidate how predictions were derived. This lack of transparency can hinder clinicians’ trust and understanding of the models, potentially limiting their adoption in clinical decision-making and compromising the interpretability needed for safe and effective integration into practice. The issue of small sample sizes observed in several studies can lead to model overfitting and performance overestimation.51,52 External validation and multicenter data sources to increase sample size and generality will be necessary to strengthen current drug-induced nephrotoxicity models. Utilizing an international database or a shared database through collaborative research can be useful to enhance the robustness of the models.
The study showed that drug-related nephrotoxicity was highly associated with the patient’s baseline condition. Age was one of the most commonly selected features, and its associated declines in glomerular filtration rate and renal reserve were supported by epidemiological and meta-analytic studies. 53 Diabetes mellitus, the primary comorbidities identified, reflect their established contributions to preexisting renal impairment and heightened susceptibility to drug toxicity. On the other hand, the comparative analyses in Table 2 revealed that including age, diabetes, eGFR, or diuretics does not significantly affect model performance. The results indicated that the feature selection methods employed in each study helped build robust models to reduce the complex confounding effects and causal relationships among factors.
Additional frequently selected dynamic features included SCr, BUN, hemoglobin, and albumin. The inherent antioxidant properties of albumin may help attenuate contrast-induced nephrotoxicity, a condition partially mediated by oxidative stress.54,55 Low hemoglobin levels can precipitate AKI, presumably by causing renal hypoxia, thereby compromising essential oxygen delivery to the kidneys. 56 A high trough concentration of vancomycin was a consistently strong predictor of AKI. 57 Diuretic use was a commonly selected feature, which agrees with pathophysiologic and pharmacologic mechanisms. These rapidly changing laboratory data or modifiable medication use provided an opportunity for actionable strategies to interrupt the AKI progression.
The differences in the features selected by individual models can be explained by the pharmacologic mechanisms underlying those models. Nephrotoxicity associated with vancomycin, cisplatin, and contrast media involves distinct but some overlapping pathophysiological pathways. While all three primarily target the renal tubules, their mechanisms differ in how they initiate injury. The primary mechanism of vancomycin-induced nephrotoxicity is excessive oxidative stress that targets tubular cells. 58 Cisplatin-associated nephrotoxicity is highly related to DNA damage and also related to the organic cation transporters (OCT2) in the kidney. 59 However, contrast media induced nephrotoxicity by direct contact with the high-osmolality, high-viscosity molecules. 60 These differences in pharmacological mechanisms led to distinct features in each model.
The drug-induced nephrotoxicity models included in this review mostly predicted AKI, which can be extended to long-term outcomes for leading comprehensive renal care. The continuum of renal impairment is initiated at the occurrence of AKI. Should renal function not fully recover during this initial period, the patient then enters the AKD phase. 61 Preventing AKD is of paramount importance as this critical window determines whether the kidney enters into either full recovery or permanent CKD. Most studies lack explicit modeling of temporal dynamics, with risk predictions largely confined to predose assessments. Consequently, these models offer limited insight into temporal risk evolution or the optimal timing for postdose interventions. However, a shorter prediction window (e.g., within 7 days) remains crucial for identifying patients at high risk of immediate progression and guiding prompt intervention or change in drug therapy. A longer prediction window (e.g., up to 90 days) provides a comprehensive risk assessment for the development of sustained AKD or subsequent CKD. The machine learning model design for drug-induced nephrotoxicity should accommodate the concepts of AKI and AKD to reinforce long-term renal care strategies and provide a comprehensive framework for prevention.
The current study found that more complex methods, such as BMs and NNs, performed better than algorithms created by RFs, DTs, and SVMs. Despite that, tree-based BMs possess inherent capabilities for variable selection, causal effect estimation, and sophisticated handling of missing data. 62 This review showed that NNs, by capturing complex, non-linear relationships, had better and more balanced positive and negative predictions in all of the performance metrics.63,64 The most significant capacity of these advanced algorithms is to model time-series data. The simultaneous prediction of kinetic changes can timely reflect the progress of disease which is more practical for clinical use. However, high computational requirements may limit clinical deployment in resource-limited settings. A feasibility analysis should be carefully conducted to determine whether the clinical settings have adequate technological support to implement models with high computational requirements.
Selecting machine learning algorithms to predict and support clinical practice highly depends on data type and the needs of clinical specialties. Convolutional neural networks excel in oncology and pathology by analyzing complex medical images to aid in diagnosis and determine cancer stage. 65 On the other hand, long short-term memory networks can be used in intensive care medicine or in medical conditions that require analyzing sequential physiological data to predict outcomes or identify risk. 66 Other algorithms, such as NNs and BMs, are common in nephrology in utilizing EHR data to predict acute disease diagnoses or chronic disease progression and to stratify risk. Recent studies reported that gradient BMs and extreme gradient BMs achieved good predictive performance for vancomycin and amikacin, respectively.67,68
Incorporating machine learning models into clinical decision support systems (CDSSs) 69 is highly feasible as current models use clinically obtainable features but it requires overcoming barriers. The machine learning-based CDSSs 70 can provide clinicians with simultaneous patient-specific recommendations, serving as a tangible strategy for preventing drug-induced nephrotoxicity. However, potential barriers to clinical practical applications include the computational capacity of the EHR system, regulatory oversight of AI/software-assisted medical devices (SaMD), and model interpretation. Training on machine learning or AI-assisted CDSSs is essential before clinical implementation to address prediction errors, the circumstances under which a model might fail, or the criteria for determining when model outputs are reliable. 71
Limitations
This review has several limitations. Literature searching was limited to published articles and did not encompass potential unpublished studies. This approach introduces the possibility of publication bias, as studies with null or negative findings may have been underrepresented. The preponderance of studies conducted in East Asian and North American/European populations limits the generalizability of the findings, particularly concerning African populations, which had higher CKD prevalence. The variability in diagnostic criteria for nephrotoxicity and the aggregation of data by drug class in some studies, rather than individual agents, constrain the interpretation of these results and limit the specificity of the findings. While most research has focused on contrast-induced nephrotoxicity, interpreting results from different drug-induced nephrotoxicity models should be done carefully. A significant limitation was that many articles included in this review did not undergo external validation. Internal validation, regardless of the method used, can be very similar to the training set and generate overly optimistic predictions. The actual performance of these algorithms on new, independent patient data remains mainly unknown and unverified.
Future studies
Future studies should prioritize the cohorts with a high prevalence of CKD, such as in African countries, given the disproportionate burden of kidney disease. 72 Standardized nephrotoxicity criteria and drug-specific analyses should be applied to yield more robust and reliable results. Given the scarcity of studies benchmarking machine learning models against established clinical guidelines—such as KDIGO or RIFLE—future prospective trials are warranted to evaluate the comparative effectiveness of machine learning-integrated care versus routine clinical practice. Lastly, reasonable clinical actions to avoid drug-induced side effects should be taken while balancing the pharmacologic effects. Since dose attenuation may compromise the cytotoxicity of antineoplastic agents or the bactericidal activity of antibiotics such as vancomycin, the risk of treatment failure remains a significant concern. Consequently, future research should prioritize the development of clinical actionability frameworks that include extensive hydration protocols or switching therapeutic agents, effectively balancing nephrotoxicity mitigation with optimal therapeutic outcomes.
Conclusion
Recent advancements in machine learning algorithms for predicting drug-induced nephrotoxicity indicate the high potential for clinical implementation in the near future. The feasibility analysis of the computational resources required to analyze time-series data and the optimal selection of algorithms should be carefully assessed, depending on the specific data types and the actual needs of clinical settings. These models of drug-induced nephrotoxicity utilizing clinically obtainable features have achieved excellent AUROCs and revealed that drug-related nephrotoxicity is profoundly associated with a patient’s baseline condition. To ensure a comprehensive scope of prevention, future study designs and algorithms should accommodate the concepts of both AKI and AKD, thereby reinforcing long-term renal care strategies. Methodological rigor, including performance evaluations, sufficient sample sizes, and external validation, must be thoroughly considered and applied to ensure the validity and reliability of the results. Embracing multicenter or multicountry datasets and adhering to standardized guidelines, such as PROBAST+AI and TRIPOD+AI, can further enhance the validity and generalizability of predictive models for drug-induced nephrotoxicity. Future studies must prioritize clinically-actionable frameworks in the prediction model that balance nephrotoxicity mitigation with therapeutic outcomes. Integrating these models into CDSS is highly feasible; however, successful deployment requires overcoming implementation barriers to provide timely estimates, enabling the proactive prevention of drug-induced nephrotoxicity.
Supplemental Material
sj-docx-1-taw-10.1177_20420986261430234 – Supplemental material for Machine learning studies of drug-induced nephrotoxicity: a scoping review
Supplemental material, sj-docx-1-taw-10.1177_20420986261430234 for Machine learning studies of drug-induced nephrotoxicity: a scoping review by Mawardi Ihsan, Shu-Ting Chang, Wei-Kai Chan and Hsiang-Yin Chen in Therapeutic Advances in Drug Safety
Footnotes
Acknowledgements
The authors thank Taipei Medical University for providing the library resources and the National Science and Technology Council for supporting this work through research grants.
Declarations
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.