
Abstract
Argument mining is a subfield of argumentation that aims to automatically extract argumentative structures and their relations from natural language texts. This article investigates how a single large language model can be leveraged to perform one or several argument mining tasks. Our contributions are two-fold. First, we construct a multi-task dataset by surveying and converting 19 well-known argument mining datasets from the literature into a unified format. Second, we explore various training strategies using Meta AI’s Llama-3.1-8B-Instruct model: (1) fine-tuning on individual tasks, (2) fine-tuning jointly on multiple tasks, and (3) merging models fine-tuned separately on individual tasks. Our experiments show that task-specific fine-tuning significantly improves individual performance across all tasks. Moreover, multi-task fine-tuning maintains strong performance without degradation, suggesting effective transfer learning across related tasks. Finally, we demonstrate that model merging offers a viable compromise: it yields competitive performance while mitigating the computational costs associated with full multi-task fine-tuning.
Introduction
Argumentation theory aims to model, analyse, and automate argumentative reasoning by relying on formal representations of arguments and their relationships. In his seminal paper, Dung
1
introduced the concept of abstract argumentation frameworks
Building on Dung’s framework, researchers have massively explored extensions of this abstract model with additional expressive components (such as support relations4,5 or sets of attacking arguments6,7) or the development of new semantics (e.g. to assess the strength of arguments in a more gradual manner beyond binary acceptability8,9).
These research efforts enhance the expressivity of the original framework and also contribute to more diverse applicability in real-world domains such as legal reasoning and political analysis. 10
However, a key limitation of approaches based on Dung’s AAFs lies in their reliance on the assumption that both arguments and their relations are explicitly extracted/specified. While manual formalization may be feasible at small scale in expert-driven systems, the automatic extraction of arguments and their interrelations from large-scale, unstructured data remains an open research challenge. Furthermore, even when arguments are extracted, it has been demonstrated that humans do not always reach a consensus on the directionality of attacks between arguments. 11
In recent years, argument mining (AM), the task of automatically identifying and extracting argumentative structures from natural language texts, has received growing attention in the natural language processing (NLP) community. 12 In more details, this task involves detecting argumentative components (such as claims and premises) and the relations between them. Given the pervasive role of argumentation in both written and spoken communication, the development of computational models capable of parsing and evaluating arguments has promising applications in downstream tasks such as decision-making, persuasion, fact-checking, and misinformation detection.13,14
Early approaches to AM relied on models such as support vector machines (SVMs) and recurrent neural networks (RNNs). 15 However, the development of deep-learning and transformer-based architectures, allowed AM systems to gradually improve their performance. For instance, Mayer et al. 16 applied transformer-based models to mine arguments in healthcare-related texts, demonstrating that domain-adapted language models can capture argumentation patterns in specialized corpora. Moreover, with the recent development of large language models (LLMs), recent work has demonstrated the potential of prompting or fine-tuning LLMs specifically for argument mining.17–20 For instance, Cabessa et al. 17 showed that appropriately fine-tuned LLMs can outperform traditional architectures in extracting argumentative structure from natural language texts and Stahl et al. 20 developed Arginstruct, which fine-tuned LLMs using argumentation instruction tuning to enhance model performance in argumentative tasks.
However, we argue that these previous approaches mainly focused on individual AM tasks (such as argument component or argument relation classification) limiting their applicability to more end-to-end or open-ended argumentative tasks. Furthermore, while instruction tuning methods, such as the one used in Arginstruct, Stahl et al. 20 show promise for improving LLMs’ performance in argumentative contexts, it largely depends on synthetic, LLM-generated instructions as training data, rather than leveraging real-world, human-annotated argumentation data. This may, in turn, limit the generalizability of the models’ argumentative capabilities in real-world settings.
Thus, this work aims to explore the potential of a single LLM to perform one or several argument mining tasks.
In doing this, we explore two central research questions: “To what extent does fine-tuning improve the performance of an LLM on argument mining tasks?” “Can an LLM obtain good performance in multiple argument mining tasks? If yes, how?”
Our several contributions aimed at answering these two questions. Namely, we first surveyed and collected 19 real-world AM datasets from the literature and converted them into a standardized format suitable to train LLMs. Next, we fine-tuned and evaluated Meta AI’s Llama-3.1-8B-Instruct LLM on eight identified AM tasks. Lastly, to explore the capabilities of LLMs to perform multiple AM tasks, we explored (1) a model merging approach to combine the previously fine-tuned models and (2) fine-tuning jointly on multiple AM tasks.
Our experiments show that task-specific fine-tuning significantly improves individual performance across all tasks. Moreover, multi-task fine-tuning maintains strong performance without degradation, suggesting effective transfer learning across related tasks. Finally, we demonstrate that model merging offers a viable compromise: it yields competitive performance while mitigating the computational costs associated with full multi-task fine-tuning.
This report is structured as follows. In Section 2, we introduced the background and related work on LMMs and argument mining. In Section 3, we describe the refinement of the existing dataset and the creation of our multi-task dataset. In Section 4, we explain the training regiment for the several LLMs in the context of AM and their evaluations. Finally, we conclude in Section 5.
In this section, we begin with a brief overview of prior work on LLMs and their connection to AM. We then narrow our focus to recent studies that specifically apply LLMs to AM tasks. Finally, we present the various AM datasets available in the literature, which serve as the foundation for our experiments in the following sections.
Large language models
A language model is a computational system designed to generate or understand human language by estimating the probability of word sequences. This allows the model to predict, complete, or generate coherent text based on a given context. Early language models were purely statistical, relying on methods such as
Nowadays, we call large language models, generative language models with many parameters (usually in billions) and trained on a vast amount of textual data to perform a wide range of natural language tasks. The release of OpenAI’s GPT-3 23 further demonstrated that increasing model scale improved zero-shot and few-shot performances. This led to the development of various open-source/closed-sourced models such as Meta AI’s Llama models, 24 Mistral-7B, 25 Alibaba’s Qwen2.5, 26 and OpenAI’s GPT-4 27 among plenty of others which further improved performance and exhibited improved alignment and reasoning capabilities. Further improvement can be seen in models such as Claude, 28 which integrated architectural changes to support extended thinking and Cogito, 29 which explores human-inspired reasoning architecture. This race to better reasoning has been seen in other models such as DeepSeek-R1 30 and Deepseek-V3, 31 which emphasize reasoning through reinforcement learning training, and Alibaba’s QwQ model, 32 designed for code generation and theorem proving.
As LLMs became more ubiquitous, controlling their performances for specific tasks became essential. On the one hand, research on prompt engineering, such as Chain-of-Thought (CoT) prompting, 33 which enhances reasoning by guiding an LLM to generate intermediate steps, has been shown to enhance accuracy on reasoning-intensive tasks. This was followed by more structured techniques like Graph-of-Thought (GoT) 34 and Thread-of-Thought (ToT), 35 which aim to improve interpretability and robustness. On the other hand, supervised fine-tuning (SFT) and instruction tuning have also emerged as powerful methods to improve LLM performances. Chung et al. 36 have shown that scaling instruction tuning improves generalization and task transfer, while PEFT (performance effective fine tuning) techniques such as LoRA 37 (and its many variants) achieve performance comparable to full fine-tuning with greatly reduced computational cost.
AM and LLMs
AM is a field of computational argumentation that aims to automatically identify and structure argumentative discourse in natural language texts. The main AM tasks include the detection of argumentative components (e.g. claims or premises) or the classification of relations between them. 12 Note that in this work, we also study argument quality assessment, which is one of the major related AM tasks. It consists in assessing the quality of claims and their revisions. 38 Other variants are post quality 39 and overall quality assessment. 40
Early work in AM relied on structured prediction methods and neural architecture, such as structured SVMs and RNNs for component identification and relation prediction 15 and a relation-based approach to capture argumentative structure. 41 We also note that relation classification can also be improved via the use of argumentation scheme and formal logic. 42 More recent approaches leverage transformer-based architecture, which demonstrate strong performance across a range of argument mining tasks, with applications in domains such as healthcare, 16 political debates analysis, 43 and fallacy detection.44,45
End-to-end frameworks, which perform multiple AM tasks on natural language texts, have also been explored. For example, Lenz et al. 46 introduce a system that automatically transforms natural language text into an argument graph while Morio et al. 47 and Schulz et al. 48 propose models trained via multi-task learning to perform AM in low-resource settings. To help reduce the need for a large amount of data, cross-corpora and training in low-resource settings have also been studied, with methods using generalizability and transfer learning.39,49,50
Generative approaches have also been in argumentation as a text-to-text generation task 51 or to perform structured extraction of complex argumentative structure, like argument quadruplet extraction. 52 We refer the interested reader to the seminal paper by Chen et al. 53 on the potential of LLMs in computational argumentation. However, in this work, we restrict the scope of our investigation and purposely do not put our focus on generative tasks.
The use of LLMs in AM has shown progress across core tasks (such as argument component identification, relation classification, fallacy detection and quality assessment). Initial explorations have demonstrated the potential of LLM in capturing argumentative structures, while recent evaluations have assessed their performance across precise sub-tasks.19,54,55
However, LLMs showed several limitations, such as difficulties in reliably detecting argumentative fallacies in natural settings 56 or logical inconsistency in generated fallacy annotation. 57 As a solution, fine-tuning and in-context learning have been explored to adapt LLMs to AM. Cabessa et al.17,58 showed that fine-tuned models improve in the task of argument component classification and relation classification. An instruction-tuned variant such as ArgInstruct Stahl et al., 20 further enhances LLM capabilities by aligning them more closely with the reasoning requirement of argumentative tasks. However, they only use synthetic LLM-generated instructions to perform their instruction tuning. We argue that this may limit the generalizability of the models’ argumentative capabilities in real-world settings. In our approach, we make use of real datasets from the literature which we introduce in the next section.
Survey of datasets in AM
In the following, we present the 19 datasets collected in the literature, which we will convert and use for fine-tuning LLMs. They are presented in alphabetical order, with illustrative examples provided for only a subset for the sake of brevity.
AbstRCT
Proposed by Mayer et al., 16 this dataset targets AM in healthcare. It includes 500 medical texts annotated for argumentative component (major claim, claim and premises) and argument relations (attack or support). The dataset highlights challenges like domain-specific vocabulary, evidence scarcity and interpretability.
AQM
Guo et al. 52 presented AQM as a dataset for their Argument Quadruplet Extraction (AQE) task, which involves identifying four elements in a statement: the topic, stance, opinion and rationale. The data consist of 34,369 sentences from 801 articles annotated for three argument components: claim, evidence and stance.
ArgSum
Li et al. 59 introduced ArgSum as a comprehensive multi-task dataset designed for end-to-end argument summarization and evaluation. It contains user-generated discussions with associated stances, generated summaries, and human or model-generated quality judgments. The dataset supports carrying out tasks such as argument component extraction, stance detection, summarization and summary evaluation. Its structure supports joint training across those tasks, enabling multi-task learning.
ComArg
Boltužić and Šnajder 60 developed this dataset by extracting data from online debate forums and social platforms. It includes 2,436 comments annotated for stance and argument recognition. This dataset focuses on short, user-generated responses to controversial questions. This dataset supports tasks such as argument relation classification and stance detection.
CoCoLoFa
Yeh et al. 57 introduced CoCoLoFa as a dataset containing 7,706 news comments from 648 news articles annotated for eight common logical fallacies (each comment is annotated with one fallacy among the eight selected fallacies), which were verified with the help of an LLM and human annotators. It covers various fallacy types and is situated in real-world opinionated discussions, such as reader comments on a news article.
Dagstuhl-15512 ArgQuality
Wachsmuth et al. 40 proposed this dataset to assess argument quality in natural language across several dimensions such as clarity, cogency, sufficiency and effectiveness. The dataset consists of 320 arguments rated by human annotators over the different quality dimensions. This dataset helps quantify what makes an argument ‘good’ and ‘persuasive’.
FEVER
Thorne et al. 61 compiled a dataset consisting of 185,445 claims for fact verification by pairing claims with evidence from Wikipedia. Though primarily designed for factual verification, the dataset’s structure overlaps with tasks in AM. Each claim is annotated as ‘supported’, ‘refuted’ or ‘not enough information’ based on the retrieved evidence.
IAM
Cheng et al. 62 presented IAM, a large-scale dataset designed for multiple tasks of AM, including argument component identification, relation classification and stance detection. It includes 69,666 sentences spanning multiple domains and having extensive annotations. IAM supports both individual and multi-task learning. It is one of the most comprehensive datasets currently available for training and benchmarking AM models.
IBM claim-polarity
Bar-Haim et al. 63 proposed this dataset of 2,394 claims associated with 55 topics annotated for stance classification. The claims are labelled for polarity (support, oppose and neutral) and contextual dependency.
IBM type
Aharoni et al. 64 introduced this dataset with claim and evidence annotations across 33 controversial topics, including 2,883 arguments across 586 documents from Wikipedia. The focus is on distinguishing argument components and associating claims with relevant evidence.
IBM claim
Levy et al. 65 constructed this dataset, consisting of 2500 claims, by extracting data from web sources associated with 50 distinct topics. It focused on claim detection and aims to bridge the gap between large, noisy web data and structured argumentative search.
IBM evidence
Shnarch et al. 66 presented this dataset of 5,785 sentences annotated for evidence (either supporting or contesting the topic) across 83 topics.
IBM argument
Shnarch et al. 67 proposed this dataset to address the challenge of domain adaptation in AM. The datasets enable models to generalize to unfamiliar domains while retaining interpretability. The dataset includes 700 sentences annotated as to whether they contain an argument for the given topic. The sentence annotations span across 20 topics, and the rules provide insight into how argument patterns across multiple domains.
MAFALDA
Helwe et al. 45 released MAFALDA as a benchmark dataset for logical fallacy detection and classification, covering over 30 fallacy types. It contains a mix of real and synthetic texts, annotated by experts and LLM-assisted crowd-workers. It includes 200 texts in which sentences have been with one or more fallacies. We give a single entry of this dataset in Example 1.
MAFALDA entry identifying two fallacies (false dilemma and hasty generalization) from a post claiming that because a bar in Thurles wasn’t attacked over an ad showing Jesus with a pint, Christians are not as sensitive as Muslims.

Microtext part 1
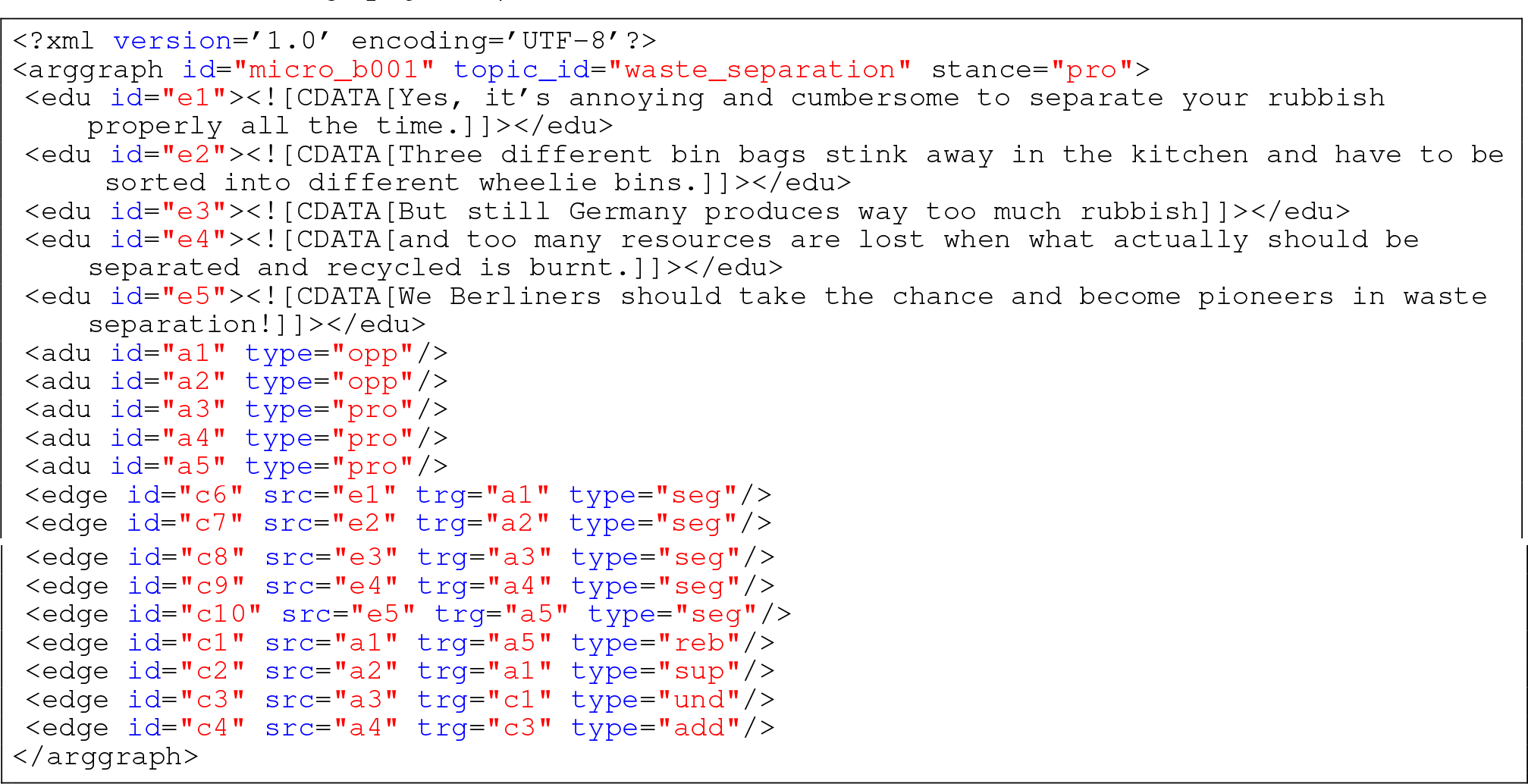
Peldszus and Stede 68 released a structured dataset composed of 112 microtexts, each containing a full argument annotated (claim and premises) and their relations (attack and support). We give a single entry of this dataset in Example 2.
Microtext part 1 entry about the topic of waste separation. Five elementary discourse units (edu) are identified and associated with argumentative discourse units (adu). Relations between argumentative discourse units and their relations are specified in
Representation of the micro-level argument graph on the topic of waste separation from Microtext part 1.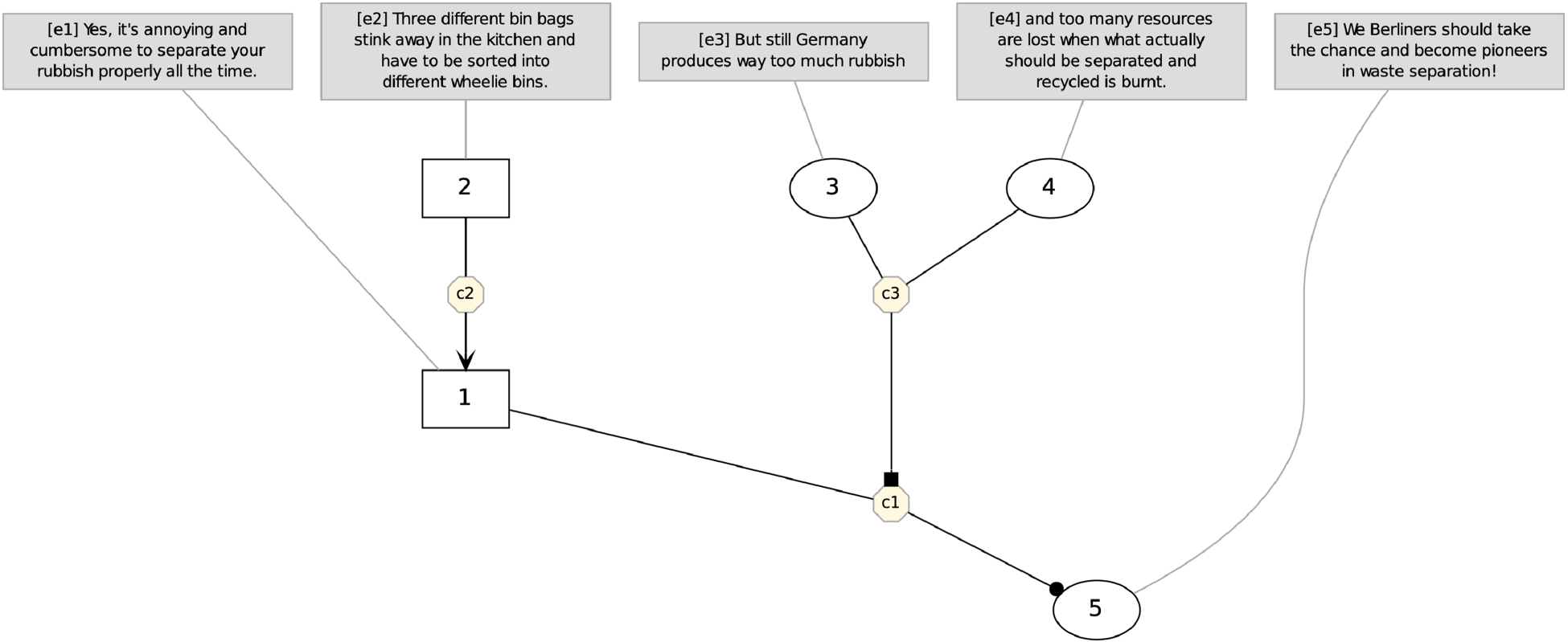
Microtext part 2
Skeppstedt et al. 69 extended Microtext part 1 with 171 texts by crowd-sourcing new argumentative texts under controlled prompts. The goal was to enlarge the original dataset while maintaining its clarity and consistency in argument structure.
Nixon-Kennedy debates
Menini et al. 43 curated and annotated the 1960 US Nixon-Kennedy presidential debates with a focus on argumentation strategies in political speech. The dataset includes 1,907 argument pairs covering five topics annotated for argumentative relations and rhetorical patterns, enabling analysis of persuasive techniques and discourse dynamics.
Node
Cabrio and Villata 70 introduced the Node dataset, comprising 260 arguments extracted from online and encyclopedic sources. Each argument is annotated with acceptability judgments based on its coherence and logical structure.
Persuasive essays
Stab and Gurevych 71 provided a dataset containing persuasive essays annotated with argument components (major claim, claim and premise) and their relations (support and attack). It includes 402 essays written by students and annotated by three annotators (two non-expert and one expert annotator), offering a consistent structure and real-world argumentative writing.
Corresponding

The 19 datasets identified in Section 2.3 cannot be directly used for training as they possess widely different specificities and formats. In this section, we explain our approach to unify (Section 3.1) and exploit these datasets for eight AM tasks we consider (Section 3.2).
Unifying existing AM datasets
To facilitate the fine-tuning and testing of LLMs (as well as reproducibility), we first unify each of the datasets under a handcrafted
Beyond structural unification, we also harmonize the annotation labels across datasets belonging to the same task. For most tasks, this process only involves minor renamings (e.g. ‘Anecdotal Evidence’ to
Three tasks required more substantial adjustments based on the definitions of the original labels and the specific phenomena each task aims to detect:
To preserve the original datasets, these label modifications are not applied during the
We now introduce the argument mining tasks considered in the article.
AM tasks considered
All the studied tasks (in light red boxes) and associated datasets (in white boxes) are represented in Figure 2. We selected those AM tasks by surveying the literature on AM and restricting ourselves to tasks which can be converted into classification tasks. Note that some datasets (e.g. AQM) are reused for different tasks in different ways.
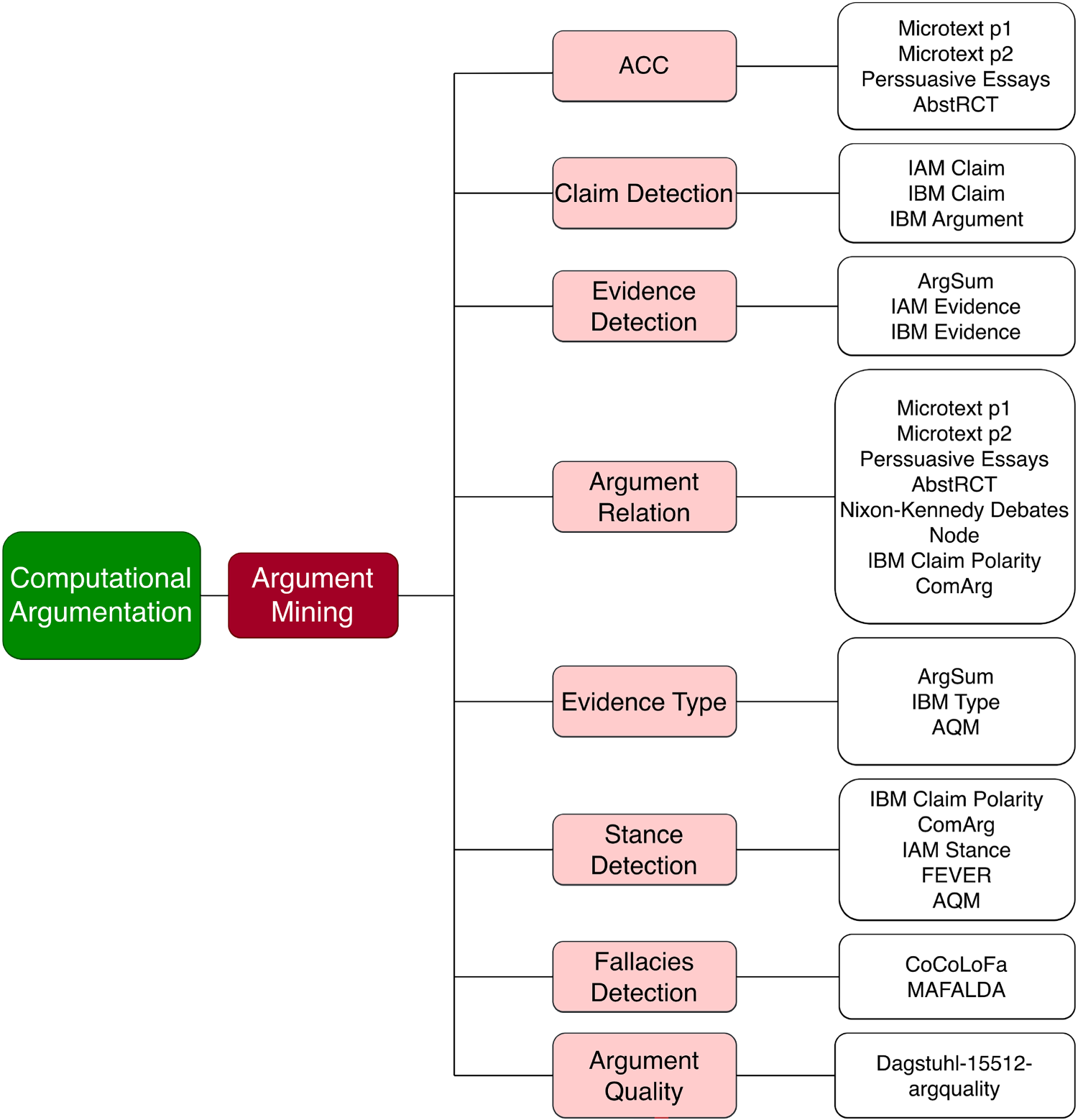
Graph of the different argumentation tasks and the associated datasets.
In the rest of this section, we will describe and formalize each of those tasks.
Argument component classification (ACC)
Argumentative discourse units represent the smallest components within a text that contribute to its argumentative structure. ACC is the task of classifying argument component as either ‘premises’ or ‘claim’. This classification task does not address the distinction between argument and non-argumentative materials. We formalized this task as follows:
We fine-tuned and evaluated this task on datasets including Microtext parts 1 and 2, Persuasive Essays, and AbstRCT. Example 4 shows an example of input/output for the ACC task from Microtext part 1.
Consider this example from Microtext part 1.
The sentence
Claim detection (CD)
A claim is a statement that asserts something to be true or false. In AM, a claim serves as a central component that forms the basis of reasoning and debate. The CD task aims to identify and extract claims relevant to a given debate’s topic from texts. We formalized this task as follows:
We fine-tuned and evaluated the CD task on datasets including IAM Claim, IBM Claim, and IBM Argument. Example 5 shows an example of input/output for the CD task from IAM Claim.
Consider this example from IAM Claim.
Despite being an opinionated sentence,
Evidence detection (ED)
An evidence refers to any information or data that either supports or challenges a claim. In AM, the task of evidence detection focuses on the identification and extraction of relevant pieces of text that help validate or refute claims. We formalized ED as follows:
We fine-tuned and evaluated the evidence detection task on the ArgSum Evidence, IAM Evidence, and IBM Evidence datasets. Example 6 shows an example of input/output for the ED task from ArgSum Evidence.
Consider this example from ArgSum Evidence.
Here,
Argument relation (AR) classification
The objective of AR classification is to determine whether a given pair of arguments is connected through an argumentative relationship. Given a pair of arguments (a source argument and a target argument), the task is to classify the relationship from the source argument to the target argument as either ‘attack’, ‘support’ or ‘no relation’. Formally, this task is described as follows:
We fine-tuned and evaluated the argument relation classification task on datasets including Microtext parts 1 and 2, Persuasive Essays, AbstRCT, Nixon-Kennedy Debates, Node, IBM Claim-polarity and ComArg. Example 7 shows an example of input/output for the AR task from node.
Consider this example from Node.
Evidence type (ET) classification
The ETs refer to the different categories of evidence that can either support or challenge a claim. Common types of evidence include anecdotal, expert opinion, explanation and study. Formally, this task is described as follows:
This task was fine-tuned and evaluated on datasets including ArgSum Evidence Type, IBM Type and AQM. Example 8 shows an example of input/output for the ET task from AQM.
Consider this example from AQM.
Here, the evidence
Stance detection (SD)
A stance reflects a point of view on a debated subject, expressed as either support or opposed. The task of SD is to determine whether an argument supports or opposes a specific topic. Formally, this task is described as follows:
We fine-tuned and evaluated the SD task using datasets such as IBM Claim-Polarity, ComARg, IAM Stance, FEVER and AQM. Example 9 shows an example of input/output for the SD task from IAM Stance.
Consider this example from IAM Stance.
The sentences
Fallacies detection (FD)
A fallacy is an argument where the premises do not entail the conclusion. The goal of fallacy detection is to identify whether a given argument contains a fallacy or not. In the latter case, the output is
We fine-tuned and evaluated the fallacy detection task on two datasets CoCoLoFa and MAFALDA. Example 10 shows an example of input/output for the FD task from CoCoLoFa. Since MAFALDA includes instances with multiple ground-truth fallacies, we define two sub-tasks, denoted as
This task is considered more challenging than other AM tasks considered due to the larger variety of fallacy categories (as opposed to many binary/ternary distinctions in the other tasks).
Consider this example from CoCoLoFa.
The sentence
Argument quality (AQ) assessment
Argument quality refers to how good an argument is; it indicates the degree to which an argument is considered strong and effective. This quality is evaluated based on 15 different quality dimensions: overall quality, local acceptability, appropriateness, arrangement, clarity, cogency, effectiveness, global acceptability, global relevance, global sufficiency, reasonableness, local relevance, credibility, emotional appeal, and sufficiency. The goal of argument quality assessment is to evaluate an argument by rating it as low, average or good across each of the 15 quality dimensions. Formally, this task is described as follows:
We fine-tuned and evaluated this task using the Dagstuhl-15512 ArgQuality dataset. Example 11 shows an example of input/output for the AQ task from Dagstuhl-15512 ArgQuality Corpus.
Consider this example from Dagstuhl-15512 ArgQuality Corpus.
Here,
We created task-specific dataset for each of the eight tasks identified in Section 3.2 by extracting the corresponding input/output from several datasets (as shown in Figure 2) using a specific methodology.
First, we divided each of the 19 datasets into three splits: training (
Then, we perform a sampling on each of those three split to obtain the data needed to fine-tuned, validate, and test the model for our eight tasks. More precisely, the sampling was performed on each corresponding split of each dataset corresponding to a specific task. Given the disparities in dataset size and class distribution, the sampling procedure was designed to ensure an equal number of instances per class within each task, mitigating class imbalance. Additionally, the sampling preserved the original proportion of each dataset split, maintaining the original proportion of examples contributed by each dataset.
More formally, let us consider a task
To retain the original dataset contributions, we compute for each dataset
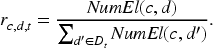
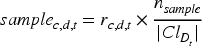
This sampling method was used to generate
Table 1 shows an example of sampling the IAM Claim (69,666 elements), IBM Claim (2500 elements) and IBM Arguments (700 elements) datasets used for the Claim Detection (CD) task. We can notice that the train, validation, and test datasets are balanced but keep the same proportion of elements from each dataset.
Sampling example for the task of claim detection. The validation and test split have the same number of instances.

Sampling example for the task of claim detection. The validation and test split have the same number of instances.
In this section, we describe the experiments to answer our two research questions and our results.
Experiment setup
For all of our experiments, we further fine-tuned Llama3.1-8B-Instruct, an already fine-tuned version of the base Meta AI’s Llama 3.1-8B for instruction following. Llama 3.1-8B-Instruct was selected for all experiments because it strikes a strong balance between performance, efficiency, and accessibility. The open-source model is large enough to capture complex reasoning and language patterns, making it suitable for tasks that require nuanced understanding, while still being lightweight enough to run reliably with reasonable computational resources. Its instruction-tuned design ensures consistent and helpful responses across diverse prompts, which was essential for maintaining reproducibility and comparability across experiments. Using a single, well-established model throughout also guarantees methodological consistency and avoids confounding effects from model variation.
Moreover, a uniform prompt format for each task was used for both fine-tuning and inference; this format consists of a task description and an explicit specification of the expected output format. We used the special token
You are an expert in argumentation. Your task is to determine whether the given [SENTENCE] is For or Against. Utilise the [TOPIC] as context to support your decision.
Your answer must be in the following format, with only For or Against in the answer section:
[TOPIC]: <topic>
[SENTENCE]: <sentence>
All experiments were conducted on an Ubuntu machine equipped with an AMD EPYC 7443 24-core CPU, an NVIDIA A40 48 GB GPU, and 65 GB of RAM. All fine-tuning performed in this work spanned two epochs with a batch size of 32. We employed Low-Rank Adaptation (LoRA) 37 with a rank of 16 to mitigate computational costs and memory requirements while ensuring sufficient parameters to accommodate diverse tasks.
As the baselines for our evaluation, we employed the Llama3.1-8B-Instruct model in both zero-shot and few-shot settings, along with a DeBERTa model. 72 For the few-shot setting, we provided one example per label of the diverse tasks. This resulted in two examples for ACC, CD, ED and SD, three examples for AR, five for ET, 20 for FD and three examples for each of the quality dimensions for AQ.
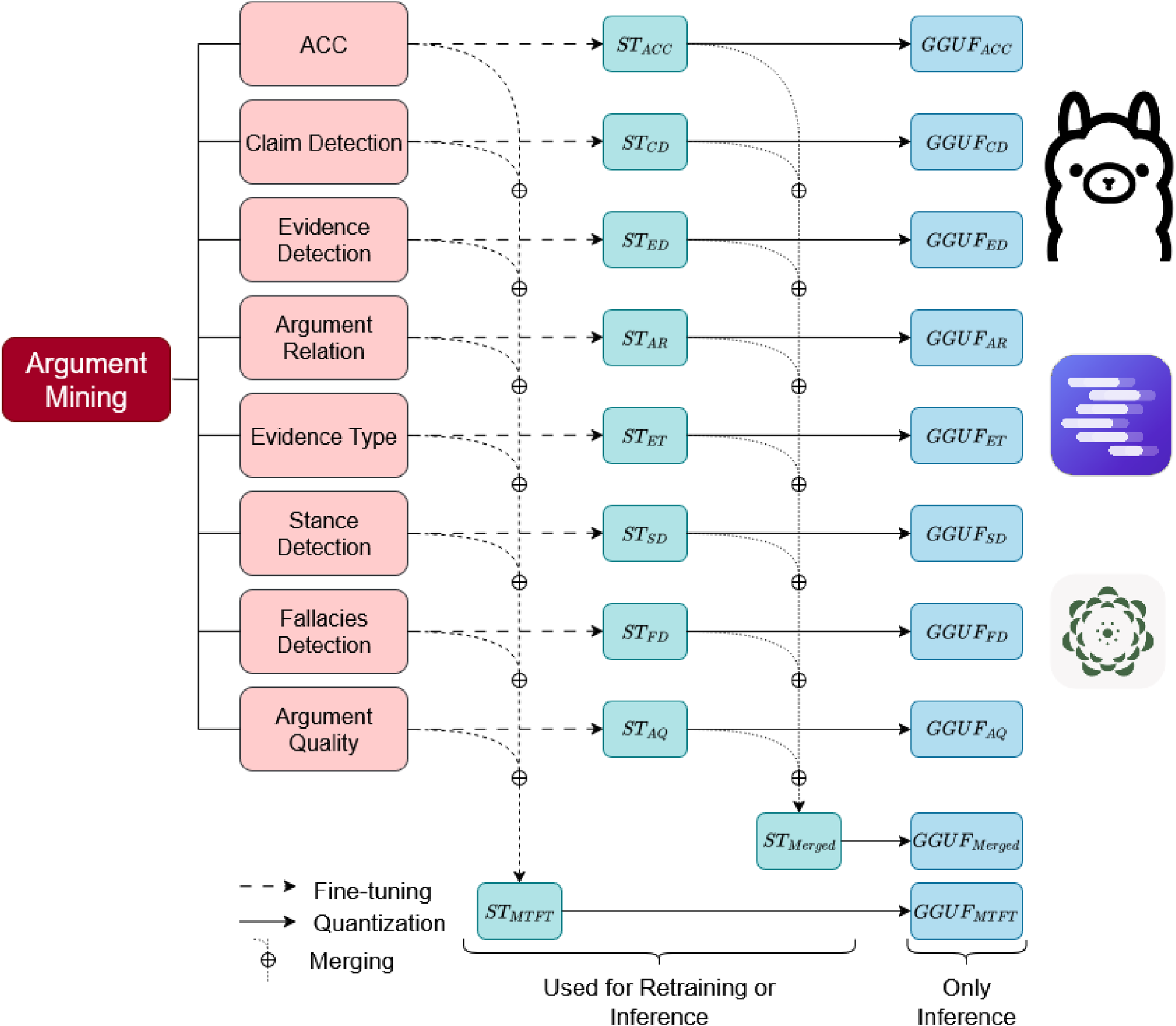
In this section, we explain how we exploit model merging to create a multi-task AM LLM. The three-steps pipeline for this model (illustrated as We first created a collection of eight models, each fine-tuned for a specific AM task, and released them in two formats: Safetensors and GGUF (GGML Universal File). The Safetensors versions enable accurate reproduction of our evaluation results and support potential retraining, while the GGUF format (a compact binary representation that stores both tensors and metadata in a single file) is optimized for efficient local inference on platforms such as Ollama and LM Studio. Both formats are available on Hugging Face (Our trained LLM collection is accessible at https://huggingface.co/collections/brunoyun/amelia-collection-68518343bf75869b53d0d8bd.). We categorized the different argumentation tasks into three levels of difficulty: hard, medium, and easy. This categorization was based on the performance of the various fine-tuned models across the tasks (see Table 2 in the subsequent section). Specifically, a task is considered easy if most fine-tuned models – including those not specifically trained for that task – achieve over Subsequently, we merged the eight finely tuned models using the mergekit library.
73
Although there are numerous merging approaches,74–77 we evaluated different configurations for two of them: DARE
77
and DELLA.
74
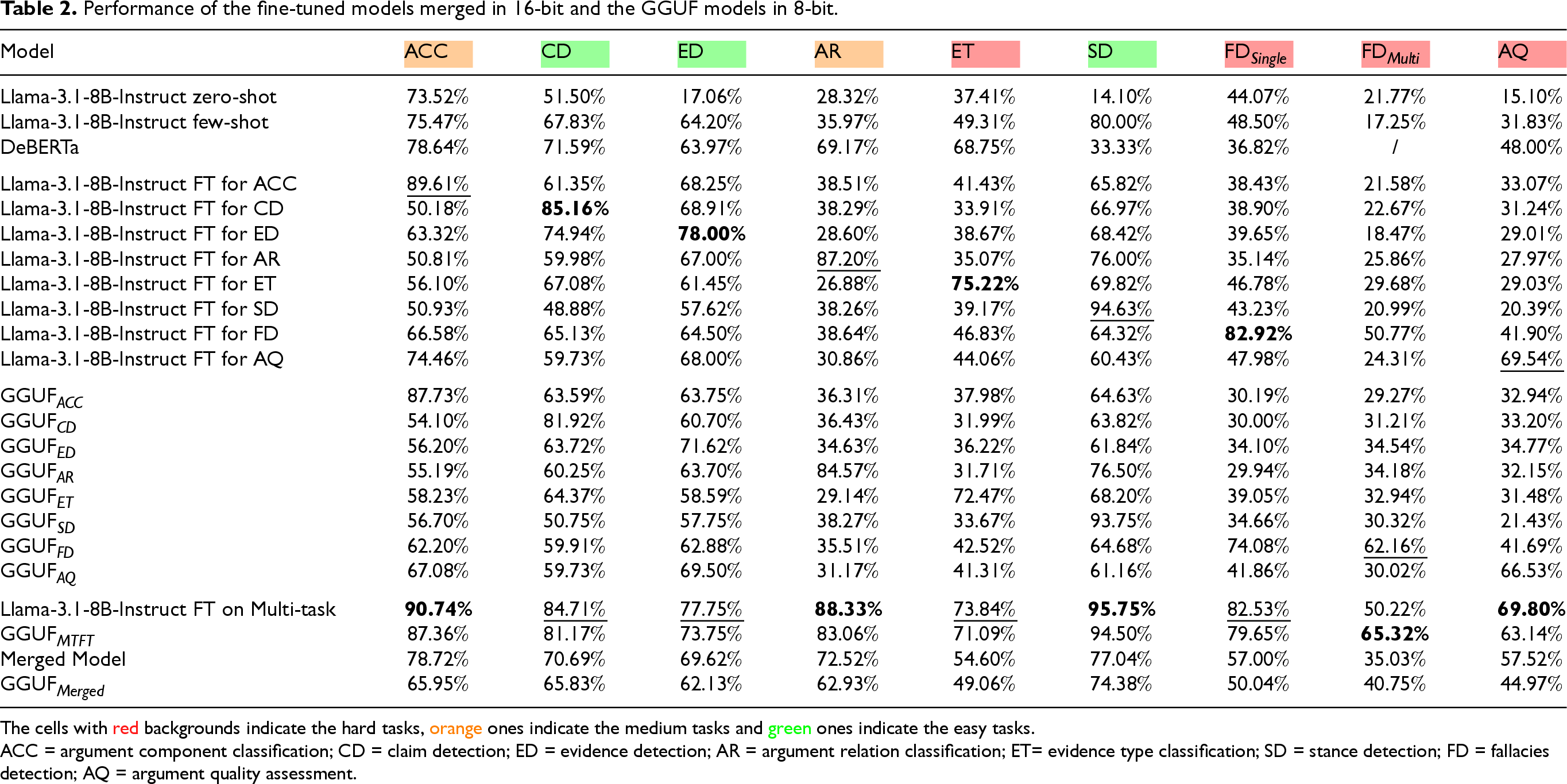
On the one hand, the former performs a random pruning on the task vectors, followed by a rescaling method to match the performance of the original model. The latter, on the other hand, enhances DARE using magnitude-based adaptive pruning, which assigns higher probabilities to parameters with larger magnitudes, followed by DARE-like rescaling. This method is designed to preserve significant modifications while minimizing interference between task vectors. Representation of the merging pipeline. All fine-tuned models are available in our Hugging Face collection. Performance of the fine-tuned models merged in 16-bit and the GGUF models in 8-bit. The cells with red backgrounds indicate the hard tasks, orange ones indicate the medium tasks and green ones indicate the easy tasks. ACC = argument component classification; CD = claim detection; ED = evidence detection; AR = argument relation classification; ET= evidence type classification; SD = stance detection; FD = fallacies detection; AQ = argument quality assessment.
Parameters for the diverse merging configurations.
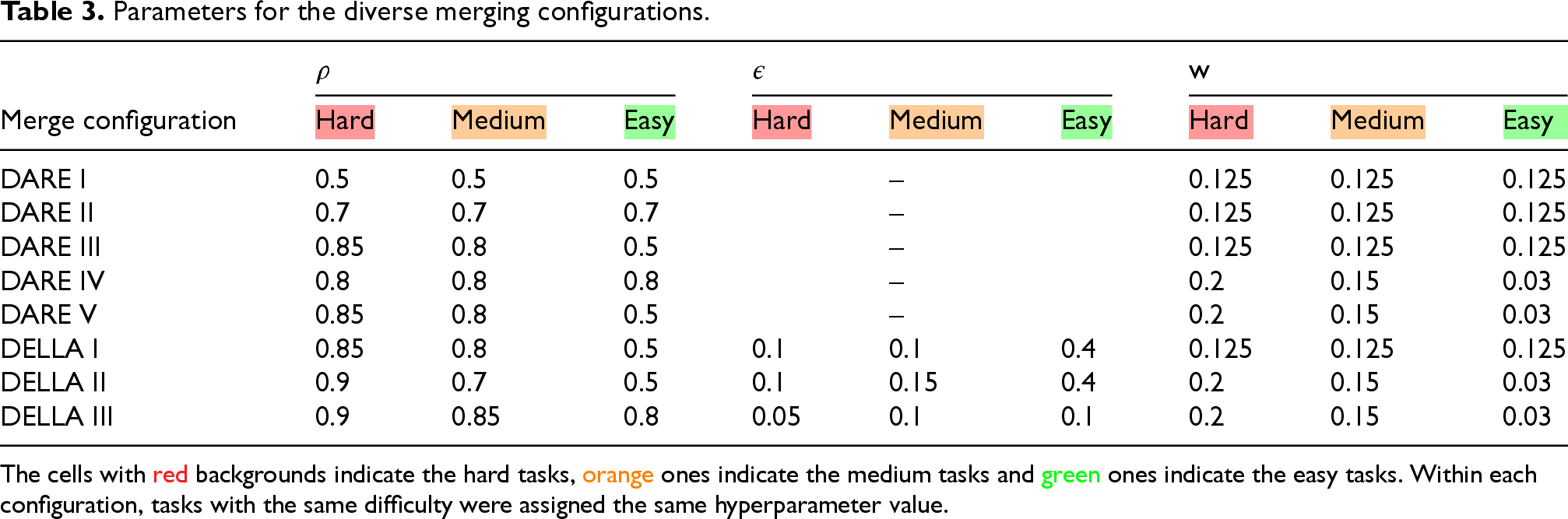
The cells with red backgrounds indicate the hard tasks, orange ones indicate the medium tasks and green ones indicate the easy tasks. Within each configuration, tasks with the same difficulty were assigned the same hyperparameter value.
Performance (F1 score) of the merge configurations.
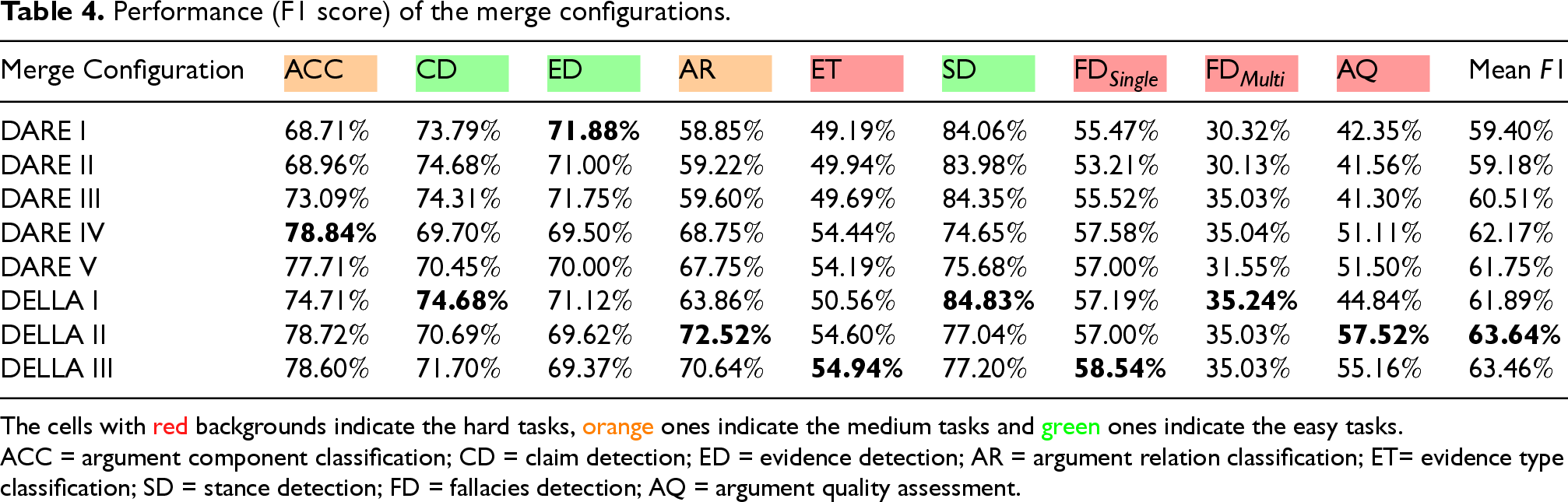
The cells with red backgrounds indicate the hard tasks, orange ones indicate the medium tasks and green ones indicate the easy tasks.
ACC = argument component classification; CD = claim detection; ED = evidence detection; AR = argument relation classification; ET= evidence type classification; SD = stance detection; FD = fallacies detection; AQ = argument quality assessment.
We make the following observations:
The fine-tuned models on individual tasks consistently outperform the base model in both zero-shot and few-shot settings, as well as the DeBERTa baseline. Notably, the fine-tuned model for the ACC task achieves an F1 score of
DARE IV and DELLA II achieve high mean F1 scores (61.75% and 63.64%, respectively). In particular, DELLA II offers the best overall trade-off, with superior performance across multiple categories, including the challenging tasks such as AR and AQ tasks. This suggests that the introduction of non-uniform hyper-parameter values (especially different weights
DARE I and II, where all tasks share identical hyperparameters, tend to underperform in terms of mean F1 (59.40% and 59.18%). While these models perform consistently, they fail to exploit task-specific adjustments, particularly struggling on harder tasks such as AR, AQ and ET. This supports the intuition that hard tasks require stronger density and adjusted weight to avoid being overshadowed during merging.
DELLA variants outperform most DARE configurations in mean F1 scores. DELLA I and DELLA III perform comparably, but DELLA II benefits the most from balancing relatively high
Overall, the DELLA merging method, especially DELLA
We also fine-tuned the Llama 3.1-8B-Instruct model on our multi-task dataset (composed of the training split of all eight AM tasks). This fine-tuned model used
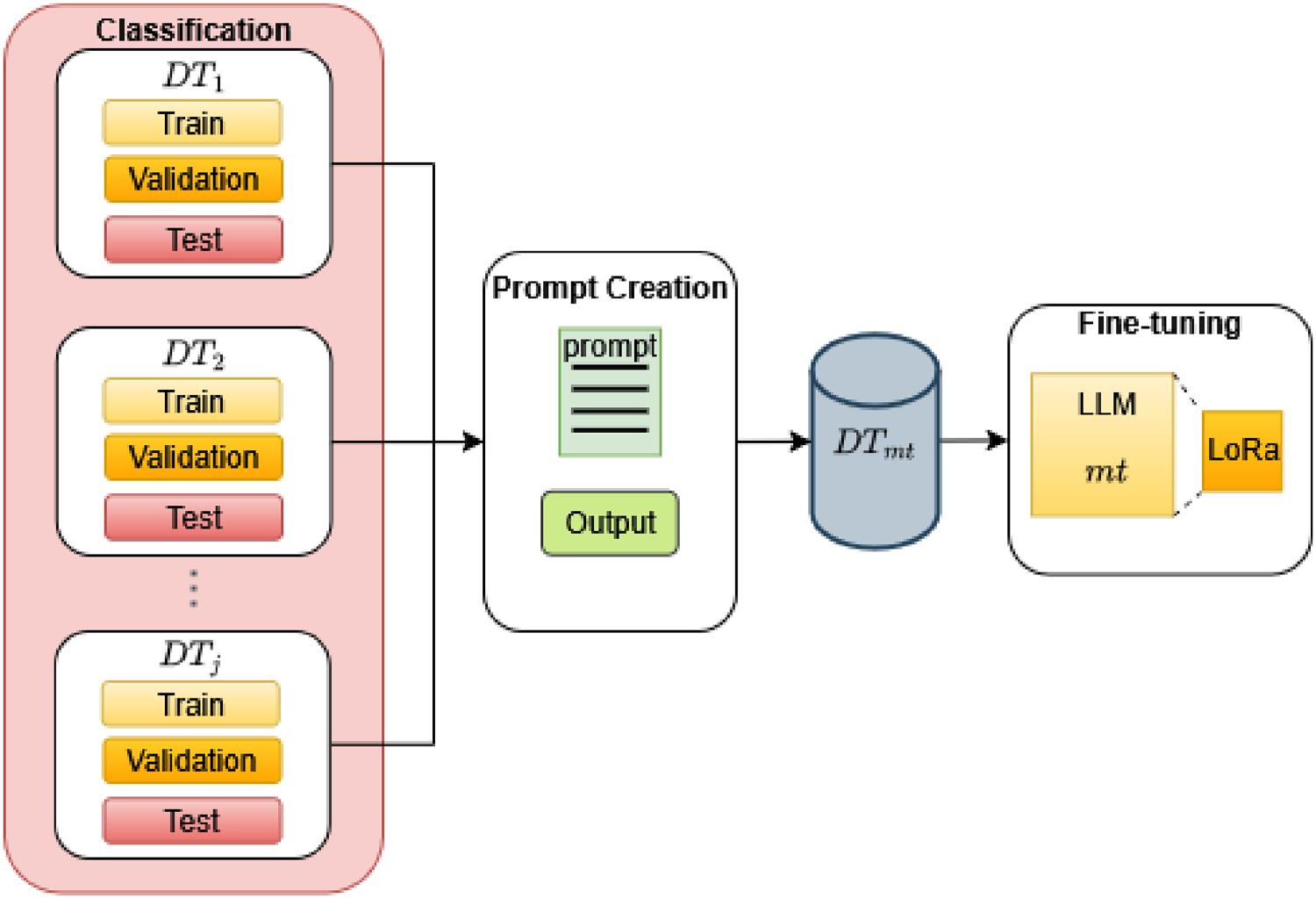
Representation of the multi-task fine-tuning.
This multi-task fine-tuned model achieves the best overall performance, outperforming all other trained models on most tasks. It obtains state-of-the-art results on ACC (
While the multi-task fine-tuned model achieves superior overall performance compared to the merged model, the latter also offers notable advantages. Model merging provides a flexible and lightweight alternative that does not require joint training on all tasks, making it especially useful when task-specific data is scarce, computational resources are limited, or continual updates are needed. In addition, merging preserves the strengths of task-specialized models without the risk of overfitting to a combined dataset, and allows new tasks to be incorporated incrementally without re-training the entire system. Thus, although multi-task fine-tuning yields the best aggregate results, model merging remains a valuable approach in scenarios where efficiency, modularity, and adaptability are prioritized.
In this work, we introduced AMELIA, a family of (multi-task) end-to-end language models for AM. Our contributions are three-fold. First, we consolidated and unified 19 widely used AM datasets into a common format, thereby providing a large, standardized resource that enables reproducibility and facilitates the application of LLMs to diverse argumentative tasks. Second, we conducted an extensive evaluation of fine-tuning strategies using Meta AI’s Llama-3.1-8B-Instruct model, demonstrating that task-specific fine-tuning substantially improves performance across all tasks, while multi-task fine-tuning preserves strong results without degradation, thus confirming the potential of transfer learning across closely related tasks. Third, we explored model merging techniques as a resource-efficient alternative, showing that methods such as DELLA can yield competitive results while maintaining modularity and adaptability.
Our experiments highlight several important insights. Multi-task fine-tuning consistently outperforms both zero-shot and few-shot baselines as well as traditional architectures, establishing a new state-of-the-art on multiple tasks. At the same time, model merging offers a practical compromise when computational or data constraints prevent joint training, making it a promising strategy for scalable deployment. Together, these findings underline the flexibility of LLMs for AM and provide evidence that both fine-tuning and merging can be leveraged to address different application scenarios.
Looking ahead, several promising research directions emerge. First, while our study focused primarily on classification-based tasks, extending this framework to generative AM tasks – such as automatic argument graph construction or debate summarization – would substantially broaden its scope. Pursuing this avenue would require the development of more sophisticated evaluation metrics beyond conventional NLP measures (e.g. ROUGE,
78
METEOR,
79
or BERTScore
80
) and the integration of human or LLM-based evaluations via online platforms to better capture argumentative dimensions that may escape automatic scoring. Second, incorporating explainability mechanisms and formal argumentation semantics into LLM-based systems would help bridge the gap between high predictive performance and interpretability. This step is critical for deployment in sensitive domains such as law, healthcare, and policy-making, where transparency and accountability are essential. Third, to further enhance performance, we plan to explore hyperparameter optimization and prompt engineering. In particular, we will experiment with varying the
Our work demonstrates that LLMs, when carefully adapted through fine-tuning and merging strategies, offer a powerful foundation for advancing AM. By releasing the AMELIA models and datasets publicly, we aim to provide the community with both methodological insights and practical tools to accelerate research in computational argumentation.
Footnotes
Acknowledgements
This work was carried out as part of the AMELIA project, funded by the Computer Science Department of Université Claude Bernard Lyon 1.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.