
Abstract
With the emergence of artificial intelligence, deepfakes have rendered it possible to manipulate anyone’s and anything’s audio-visual representation, adding fuel to the discussion about the believability of what we hear and see in the news. However, we do not know yet whether deepfakes can actually impact (1) the credibility attributed to audio-visual media in general, as well as (2) the perceived self-efficacy to discern between real and fake media. Furthermore, it remains unclear if different deepfake formats can affect citizens to differing degrees. This study employs a 3 × 2 × 2 between-within-subjects experiment (N = 951) with the between-subjects factor format (audio vs. video vs. 360°-video) and facticity (real vs. fake) and the within-subjects factor reveal (pre vs. post-reveal). We explore what happens after revealing to a sample of German participants that they have been deceived by a deepfake. Our findings show that credibility of media drops across all formats after revealing the stimulus was fake, whereas the control group is not affected. On the other hand, self-efficacy is impacted even for people who were exposed to authentic news media. This shows that deepfakes may have far-reaching societal implications that go beyond deception, whereas modality seems to matter little for such effects.
Introduction
Deepfakes are considered a dangerous form of visual disinformation because they can display situations that never actually happened, thus misrepresenting public figures and causing misperceptions (Dobber et al. 2021; Vaccari and Chadwick 2020). As such, they have sparked fundamental debates amongst political actors, legislators, and media practitioners, who suspect them to become a game changer in a high-choice media environment where misinformation proliferates and agreement on facts and evidence appears increasingly difficult (Van Aelst et al. 2017). In line with this, research has started to investigate the deceptive potential of deepfake videos of politicians and celebrities (Dobber et al. 2021; Hwang et al. 2021; Shin and Lee 2022). However, little is known about what happens after one has been deceived. It is suspected that with deepfakes in the picture, people may no longer believe what they see in the news (Chesney and Citron 2019; Hancock and Bailenson 2021). This notion, however, requires empirical investigation. Furthermore, research has thus far concentrated on 2D deepfake videos (e.g., Hameleers et al. 2022; Lee & Shin, 2021). However, the range of forms through which media can deceive evolves rapidly on the visual and auditory level (Paris and Donovan 2019). Yet, we do not know whether different deepfake formats also have differing effects.
While recent research points toward deepfakes as being not more or less deceptive than false information in textual form (Hameleers et al. 2022), a remaining concern is that they mean that seeing is no longer believing, that is, that people may lose faith in all visual material when processing information (Barnes and Barraclough 2020). This could be the case for two reasons: First, if people see isolated incidents of false visuals which they at some point believed to be true, they may transfer this experience to their overall trust in visuals. In other words, they might believe audio-visual media artefacts do not tell the truth altogether. Second, because deepfakes are considered the most advanced and lifelike form of visual disinformation, they may even trick those who are normally confident in spotting a fakery.
Being deceived by them could then lead anyone to questioning their ability to spot manipulations, leading to a decline in self-efficacy (Bandura 1982; York et al. 2020). This would signify a shift in the way media is consumed in today’s information environment, where not only the authenticity of sources and statements can be questioned, but the very thing that usually counts as a universal truth: pictorial evidence.
Moreover—even though image forgery is certainly not a new phenomenon—recent advances in manipulation techniques stand out because of their sheer variety. Deepfake technology has rendered it possible to not only manipulate photographs but facilitates faking the facial movements of a person, the imitation of a human voice, and altering objects in a video (Paris and Donovan 2019). As such, they add an unexplored level of complexity to the study of manipulated media: they can be deceptive on multiple sensory levels and are thus expected to be particularly powerful drivers of false information (Brown et al. 2023). Rich media formats such as audio, moving images or even 360°-videos hold certain affordances, which can trigger certain heuristics (Sundar 2008). Because of their close resemblance with the real world, they are expected to be evaluated as especially credible and trustworthy. Yet, communication research has only recently started to investigate the deceptiveness of visuals over text and is unable to offer conclusive findings on the distinctive role media richness may play in credibility evaluations (Weikmann and Lecheler 2022).
In a media environment characterized by an ever-increasing uncertainty about the authenticity of information, citizens are increasingly challenged to fact-check and tell real from fake (Chia et al. 2022). However, failing to do so—and learning about it—can have repercussions (Bachmann and Valenzuela 2023; van der Meer et al. 2023). In this study, we first expose participants to different versions of a deepfake, namely an audio, video, and 360°-video version. Then, we inform them of this deception, and record their responses to it. Each deepfake version was contrasted with a control group consisting of authentic auditory and/or visual material. Participants in the control group did not receive a revelation of manipulations, but instead neutral and true information on the origin of the news report.
All deepfakes were evaluated as equally credible as their real counterparts. We did not find any difference in credibility evaluations between the different deepfake versions (audio vs. video vs. 360°-video), suggesting that media richness matters little for deceptiveness. However, our results show that in the post-test all participants found audio-visual media formats less credible, especially those who were exposed to a fake. The perceived self-efficacy to discern between real and fake declined significantly for all participants, also those who saw an authentic news report. We discuss what these findings mean for the study of media credibility and media richness, as well as their wider implications for the impact of deepfakes on society.
Deepfakes as a Game Changer in Mis- and Disinformation Research?
A deepfake uses real media footage of an environment or a person to learn how to imitate it almost perfectly. Representing visual manipulations on the highest possible technological level, they have been classified as a potentially dangerous form of disinformation that may be used to deliberately deceive the public (Weikmann and Lecheler 2022). We define deepfakes as synthetically created media that employ machine learning to present a scenario contrary to reality (Hameleers et al. 2022; Westerlund 2019). In recent years, several deepfake instances involving politicians, like one where Barack Obama appears to insult Donald Trump, have garnered media attention (Vaccari and Chadwick 2020). Yet, systematic empirical research on their frequency is lacking. Currently, deepfakes seem to have limited impact in political contexts (Brennen et al. 2021), but frequently surface as revenge porn (Ajder et al. 2019). Simultaneously, deepfake software is continuously advancing, rendering them increasingly accessible and convincing over time. This has prompted intensified research efforts aimed at comprehending their effects. Experimental studies confirm that deepfakes can be deceptive and may impact attitudes toward news on social media as well as toward political actors (Dobber et al. 2021; Lewis et al. 2022; Vaccari and Chadwick 2020). However, research also suggests that deepfakes are not necessarily more deceptive than if the same falsity is presented as text (Appel and Prietzel 2022; Barari et al. 2021), whereas comparisons within different forms of visual manipulations are lacking.
One of the most pressing questions in regard to deepfakes seems to be their wider implications for trust and authenticity (Gregory 2021). In particular, fears are expressed that the sheer existence of deepfakes brings large-scale confusion about what is real and fake in a high-choice media environment. That is, because deepfakes have entered the media landscape, people may no longer believe what they see (Wagner and Blewer 2019). We argue that this apprehension is two-fold: first, people may no longer believe that audio-visuals in general represent reality. Second, people may no longer believe in their subjective ability to discern between real and fake visuals. While the deceptiveness of deepfakes—mistaking a fake for real—can be considered a primary outcome of exposure, no longer believing in visuals, in general, may be considered a secondary outcome (Weikmann and Lecheler 2022). This consequence, however, has thus far been neglected in empirical research.
General Credibility of Audio-Visuals
The digitalization of the photographic process and increased accessibility of photo editing software such as Photoshop have in the past caused societal and scholarly concerns regarding the trustworthiness of news photographs (Puustinen and Seppänen 2013). These fears have only become more pronounced with the emergence of deepfakes. From a philosophical stance, deepfakes are considered an epistemic threat, as they are suspected of undermining the value of photographs and videos as reliable testimony (Fallis 2021). Geddes (2021) expects the end of ocularcentrism, meaning privileging the visual sense over the others. In line with this, journalists are worried that deepfakes will contribute to an erosion of trust in the news, as audiences might just dismiss reports as fake, especially if they do not align with held opinions (Wahl-Jorgensen and Carlson 2021).
The idea that the ascribed credibility of something is affected when learning that one has fallen for a fake, taps into the literature of fact-checking. Fact-checkers have become essential in today’s media environment, who have started to contribute techniques to detect visual manipulations (Graves and Mantzarlis 2020; Weikmann and Lecheler 2023). Besides providing verifications, modern fact-checking also entails educating the public on how to detect false information itself, resulting in an omnipresence of interventions and literacy education attempts (van der Meer et al. 2023). In such an environment, people are frequently challenged to spot false information whilst also receiving feedback on whether they were successful in doing so. This feedback is not always provided by fact-checkers, but sometimes through friends or family, or other internet users (Chia et al. 2022). For instance, in March 2023, an artificial intelligence (AI)-generated photograph of Pope Francis wearing a stylish white puffer-coat went viral, quickly lending him the label of a fashion icon. Internet users were informed hours later through a multitude of channels that the photo was completely fake (Vincent 2023).
While some studies find that receiving such corrections can be successful in lowering credibility evaluations of false news reports, others find evidence for backfiring effects (Walter et al. 2020). For instance, fact-checks can lead to the perception that news outlets are incompetent or share false information often, thus leading to a decline of trust in news media (Bachmann and Valenzuela 2023). Also, van der Meer et al. (2023) show that misinformation warnings can trigger deception bias, resulting in a decline of news credibility in general. In sum, this suggests that learning about a falsehood can have further-reaching consequences than simply the cognitive correction of it: it might also impact how audiences evaluate authenticity in general. The same can be expected for deception through a deepfake, as it may affect the ascribed credibility to whatever people see and hear. We operationalize this variable as general credibility of audio-visual media, and hypothesize the following:
H1: Revealing deception through deepfakes negatively affects the perceived credibility of audio-visual media formats in general.
Self-efficacy to Detect Visual Disinformation
Next to a decline in the general credibility of audio-visual media, a second layer of believing may be affected when being deceived through a deepfake: the perceived capability to discern between real and fake. This would signify a lack of faith in one’s own abilities to perform a certain task, described by Bandura (1982) as self-efficacy. Self-efficacy is not considered a fixed trait, but can decline, particularly through the experience of failure: if an individual fails to perform a certain task that was previously done successfully, this can diminish one’s self-confidence. Hopp (2021) argues that Bandura’s concept of self-efficacy plays an important role in the credibility assessment of fake news stories: if people are more confident in correctly identifying misinformation on social media, they are also more successful in doing so. Pingree et al. (2014) connect the experience of task failure to political information-seeking, or the confidence to yield the truth behind political issues. The authors find that if people are informed through a fact-check that they have falsely believed a factually wrong news report, it can negatively impact their epistemic political efficacy.
We expect the same effect to set in for exposure to fake audio-visuals. Here, research shows that people ascribe a high degree of credibility to videos by default, as they fail to question their authenticity (Kasra et al. 2018). Similarly, 360°-formats are considered particularly truthful and are expected to provide the most accurate and objective representations of events (Aitamurto 2019). Therefore, failing the task of recognising a deepfake can be expected to negatively affect someone’s deepfake self-efficacy. Based on the available literature, we formulate the following hypothesis:
H2: Revealing deception through deepfakes negatively affects the perceived self-efficacy to discern between real and fake media formats.
The Deceptive Potential of Rich Media Formats
The digital media environment is characterized by communication through a variety of audio-visual formats. Messenger services such as WhatsApp facilitate sending short audio snippets (Kischinhevsky et al. 2020), the social media app TikTok is popular for its 45-second video clips (O’Connor 2022), and Facebook’s metaverse invites users to communicate in virtual environments (Brown et al. 2023). Simultaneously, possibilities of counterfeiting such formats emerge. Besides the relatively easy creation of deepfake videos through apps such as Reface, it is now possible to make audio deepfakes, also called voice synthesis. Here, recordings of a human voice are used to train AI to imitate it (Galyashina and Nikishin 2021). Moreover, it has become technically possible to create immersive deepfakes (Aliman and Kester 2020), though concrete examples of their malicious use are lacking. Still, they are considered dangerous, as they hold the potential of creating mis-experiences: It is argued that virtual reality (VR) may be used to foster false beliefs by displaying an entirely false reality, although being inherently meant to display the truth (Aitamurto 2019; Brown et al. 2023). Especially in light of the growing attention given to immersive journalism and immersive social media such as the metaverse, those forms appear more relevant than ever (Greber et al. 2023a, 2023b).
Because deepfakes can constitute manipulations on the auditory, visual, and immersive level, they are considered particularly rich forms of visual disinformation. This, according to Daft and Lengel’s (1986) media richness theory, increases their capacity to convey sensory cues. Sundar (2008) connects the richness in cues of digital media formats with their perceived credibility in the so-called MAIN model. It suggests that these cues are transmitted via technological affordances that differ across media and trigger a heuristic-based judgment about a media format’s credibility. Amongst other factors, modality matters for such affordances. While text-only formats are narrower, audios or visuals are considered richer. Thus, they have a closer resemblance with the real world, cueing the so-called realism heuristic: a richer medium does not only have a higher resemblance with the real world but is also evaluated as more credible and trustworthy.
Following this, audio can be considered less rich than video, as only the sensory cue of hearing is addressed. Still, the human voice is considered an important carrier of not only information but also affect (Belin et al. 2004). Receiving information in audio form increases levels of perceived presence and connection amongst humans, particularly in comparison to text-based communication (Keil and Johnson 2002). Sundar et al. (2021) provide evidence that video is perceived as more credible than audio when presenting misinformation on WhatsApp. Moreover, while audio and video contain the affordance of cueing the realism heuristic, an immersive 360°-video has additional affordances, such as the heuristic of being there, a psychological experience that translates into the concept of presence (Cummings and Bailenson 2016). This mechanism has been observed in experimental research concerned with the effect of immersive storytelling technologies in journalism (e.g., Nikolaou et al. 2022). Here, studies stress that because richer forms such as 360°-videos cue the feeling of being there, they can also appear as more credible to news audiences (Kang et al. 2019; Sundar et al. 2017; Vettehen et al. 2019). A second affordance of 360°-videos is interactivity, cueing the control heuristic: 360°-videos allow the users an omnidirectional view of a scene they can actively explore (Aitamurto 2019). Through this active involvement, 360° can appear more transparent to users, as they do not need to rely on the frame a journalist would select to show a certain scene. In line with this, Sundar et al. (2017) found that VR news outperforms text-based journalism in source credibility.
Communication research has only recently started to investigate the deceptiveness of manipulated visuals over text and little is known about the distinctive role media richness may play for credibility evaluations. Based on existing findings, we hypothesize:
H3a: Exposure to a 360°-deepfake leads to higher credibility evaluations of the stimulus than exposure to a deepfake video and deepfake audio.
H3b: Exposure to a deepfake video leads to higher credibility evaluations of the stimulus than exposure to a deepfake audio.
Moreover, we formulate the following research question:
RQ1: Does the level of media richness moderate the effect of revealing deception through a deepfake on general credibility and deepfake self-efficacy?
Method
Design and Stimuli
The pre-registered experiment (view-only link available here 1 ) is set up as a 3 × 2 × 2 between-within-subjects design with the between-subjects factor media format (audio vs. video vs. 360°-video) and facticity (real vs. fake), and the within-subjects factors reveal (pre vs. post). The research design is visualized in Figure 1.
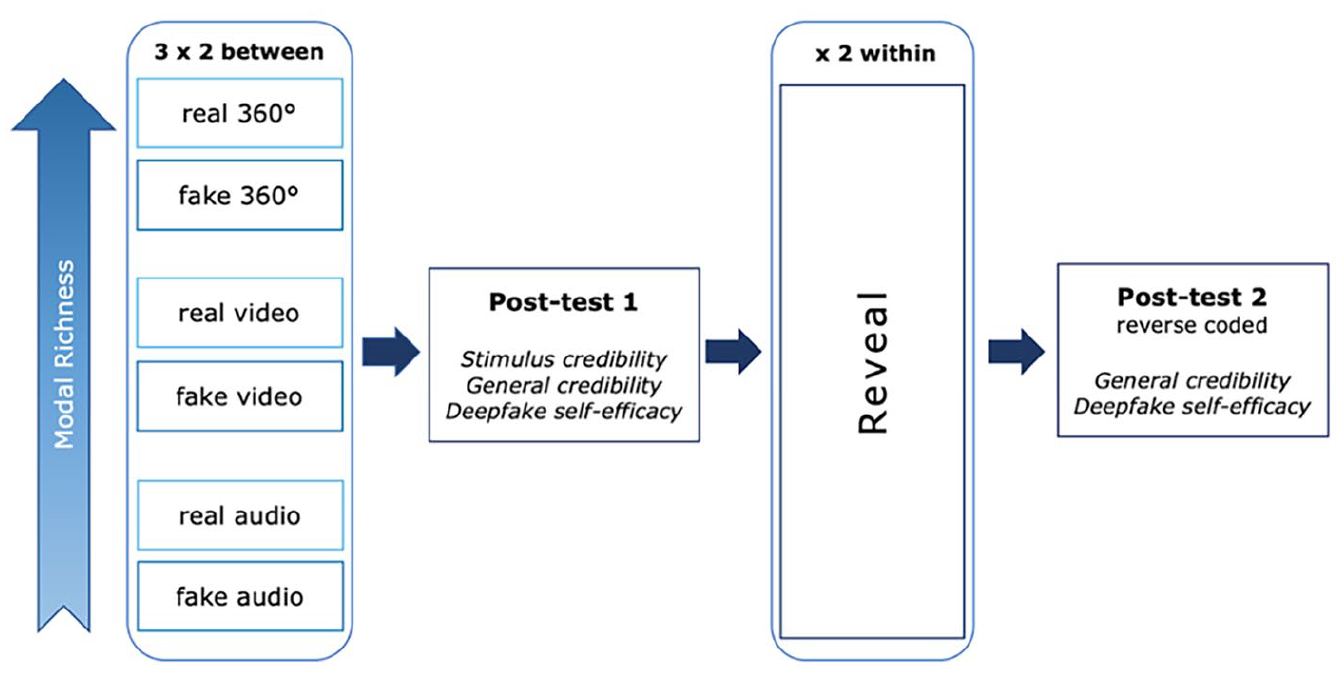
Research design.
To create the stimulus material, we used a 360° immersive journalistic report by the Austrian newspaper Wiener Zeitung entitled “eXodus 360°” about a Syrian refugee camp in Lebanon. 2 The original report shows life in an overpopulated refugee camp called Moussa Taleb near the Syrian border. To create our stimuli, we took the original 360° scenes of the report and shortened it. For the fake version, we used an existing version of the same 360°-video that was used in a different study (Nikolaou 2022), in which the people who were originally visible had been edited out. Therefore, the fake 360°-video depicts the same refugee camp as empty (see Table 1). Based on this, we fabricated a storyline about refugees that have left the camp to find work in bigger cities in Lebanon, such as Beirut—which is completely false according to recent news reports (The New Arab Staff; Langlois 2022). The fake storyline had maximal possible resemblance with the authentic script, touching upon the same overall themes and using the same camera angles. To create the 2D-video versions, we edited the 360°-video in Final Cut Pro and chose suitable 2D perspectives from the clip. The fake 2D-video and 360°-video were then paired with a synthetic female AI-voice created with the text-to-speech software murf.ai. Although the voice sounded quite realistic, it was paired with atmospheric sound to make it appear even more natural. For the real 2D- and 360°-video, we used a voiceover recorded by a professional female German journalist reading an authentic report about the people living in the camp. The respective standalone AI-generated and journalistic voiceovers served as the audio-only conditions (Table 1).
Overview of Experimental Conditions and the Factors “Facticity,” “Modality,” and “Reveal.”.

Taken together, the visual deepfake-stimuli including either a 2D or 360°-video constitutes a visual performance and, as such, the richest form on the deepfake spectrum (see Paris and Donovan 2019). Moreover, since it is completely fabricated with the intent to deceive, we regard it as (audio-)visual disinformation. The real condition, in contrast, only contains accurate and authentic information. Notably, it differs from the fake condition on the audio-visual level, regarding the storyline and in the “reveal.” However, we kept the story and audio-visual material as constant as possible between the subjects and primarily manipulated the facticity and modality of the stimulus. Thus, this design is robust for testing the effect of fabricated content versus real content. The exact differences between the factor facticity, the different stimulus modalities, and the reveal per condition are visualized in Table 1. 3
After being exposed to one of the six possible stimuli, participants answered a number of questions concerning the credibility of the stimulus itself, the general credibility of different media formats, as well as their self-efficacy to detect manipulated media. Following this, all participants in the fake condition were told that what they had just heard or seen was a factually incorrect story produced with the help of AI-driven software. The content correction included detailed information on which aspects of the story were factually wrong and how the fake stimulus was created, by referencing the software and including a side-by-side depiction of the same scene similar to the one in Table 1. The exact reveal with translations can be found in Supplemental Appendix F. Participants who were exposed to factually authentic information also received a brief message. However, instead of a reveal, we simply stated that they were shown a news report created for an Austrian audience, which is the truth (see within-subjects factor “reveal” in Table 1). Subsequently, participants were asked some distraction questions regarding the topic migration. Next, they answered the same questions concerning their evaluation of the credibility of media formats and self-efficacy to detect audio-visual fakes, albeit negatively formulated, in an attempt to mitigate potential learning effects. After finalizing the questionnaire, participants were exposed to a thorough debrief. This study was ethically approved by our university’s Institutional Review Board (ID: 20220726_038).
Dependent Variables
All items were measured on a seven-point scale. To measure the extent to which participants perceived the stimulus itself as credible, we used items of message credibility by Appelman and Sundar (2016), asking participants about the extent to which they found the piece “accurate,” “authentic,” “believable,” and “trustworthy” (M = 5.10, SD = 1.24, α = 0.95). We refer to this measure as stimulus credibility throughout the manuscript. In case participants scored low (≤4) in at least one of these items, they were directed to an open-ended question asking how they reached their conclusion (see Dobber et al. 2021). This was done to explore why people were doubtful of the stimulus, and whether it had to do with its content or if they suspected image forgery. Accordingly, this measure also serves as a manipulation check 4 (a robustness check including only participants ≥5 can be found in Supplemental Appendix G). We also measured the realism heuristic based on items by Sundar et al. (2021) to check if perceived realism of the report is indeed higher as the richness of the stimulus increases (M = 5.07, SD = 1.26, α = 0.90).
To measure how participants evaluate the credibility of audio-, video-, and 360°-formats in general, we draw from Kohring and Matthes’ (2007) scale of trust in news media, particularly the trust in the accuracy of depictions, which is similar to the media credibility scale by Kiousis (2001). Thus, we asked participants to what extent they found that audio, video, and 360°-video formats were “accurate” or “truthful” (before reveal: M = 4.68, SD = 1.20, α = 0.96; after reveal: M = 4.1, SD = 1.28, α = 0.96). This measure is called general credibility in the manuscript, as it does not refer to the stimulus, but all audio-visual media formats.
To measure deepfake self-efficacy (see Hopp 2021), the items were “I am confident in my ability to spot when news media has been manipulated” and “I am confident in my ability to distinguish between legitimate and fake news media formats (before reveal: M = 4.24, SD = 1.19, α = 0.92; after reveal: M = 3.64, SD = 1.26, α = 0.93).” To minimize the testing effect due to similarly phrased questions, in the second post-test, the general credibility and self-efficacy items are negatively formulated and reverse-coded (Weijters et al. 2009). Media literacy, specifically functional consumption of digital media (Koc and Barut 2016), is measured as well to ensure randomization (M = 5.25, SD = 1.05, α = 0.89).
Randomization
For the randomization test, ANOVAs were conducted reporting Bonferroni adjusted p-values. Random allocation to the modality conditions (audio vs. video vs. 360°) and the facticity conditions (fake vs. real) was successful. There was no significant difference between the facticity and modality groups concerning gender (facticity: F = [1, 949] 0.54, p = .46; modality: F = [1, 949] 0.223, p = .637), age (facticity: F = [1, 949] 0.005, p = .945; modality: F = [1, 949] 3.82, p = .051), media literacy (facticity: F = [1, 949] 3.03, p = .082; modality: F = [1, 949] 0.103, p = .748), and education (facticity: F = [7, 941] 0.1.067, p = .382; modality: F = [7, 941] 1.5, p = .163).
Sample Size Rationale
A simulation-based power analysis was conducted to determine the required sample size (Lakens and Caldwell 2021). For hypotheses 1 and 2, which test the effect of the reveal on credibility and self-efficacy evaluations, a SESOI (smallest effect size of interest) was set at a mean difference of 0.25 based on a seven-point Likert scale, constituting a medium effect (Cohen’s f = 0.21). For hypotheses H3a and b, which test the difference of the modalities on credibility evaluations, the SESOI was set at a mean difference of 0.5 (Sundar et al. 2021; Vettehen et al. 2019). The assumptions we made led us to a required sample size of 166 per experimental group based on an assumed power of 90 percent. This goal was almost reached, resulting in N = 951 after data cleaning (complete power analysis reported in Supplemental Appendix C).
Sample
After pre-testing (Supplemental Appendix D), data was collected via Dynata in Germany (October 17, 2022–October 21, 2022), resulting in N = 1022. Extreme-duration responders (beyond QR3 + 3xIQR or below QR1 − 3xIQR) were removed to ensure data quality (Kassambara 2023), leaving N = 951. Average response time: M = 9 minutes, SD = 3.9 minutes. Average age: 33.6 years (SD = 15.5), 48.5 percent female (0.2% other). Education: vocational certificate (32.7%), university degree (27.4%), secondary level 2 (16.5%), higher secondary/vocational diploma (12.3%), secondary level 1 (6.6%), no completed education (3.5%).
Analysis Strategy
We used ordinary least squares (OLS) regressions using dummy variables (generally: fake = 1, real = 0) with clustered standard errors to account for the within-subject design. To ensure that a significant effect of the reveal on general credibility (H1) and self-efficacy (H2) can be only explained by revealing deception through a deepfake, we included factually correct control conditions. By including the counterfactual, we can understand how people would behave were they not deceived. Any additional explanation for the difference between the pre- and post-test, such as the learning effect (Knapp 2016), would be constant between the two facticity conditions. Consequently, only if there is a significant interaction between facticity and reveal we can determine that any effect can only be due to our factor of interest in H1 and H2, namely revealing deception through a deepfake.
Manipulation Check 1: Credibility of the Fake Stimulus
In order to examine what happens after deception, we had to make sure participants were deceived. Thus, we checked whether the real and fake stimuli presented in each modality were evaluated as equally credible by conducting an OLS-regression to assess the overall impact of facticity (fake vs. real) on stimulus credibility. The combined fake stimuli were evaluated as slightly less credible than the combined real stimuli (b = −0.181, p = .02) (Supplemental Table A1). However, this overall effect disappears when focusing on each modality individually. That is, neither the real audio (b = −0.180, p = .22), real video (b = −0.224, p = .09), nor real 360°-video (b = −0.14, p = .30) were evaluated as more credible than their respective deepfake counterparts. Based on this, we conclude that participants in the fake groups were sufficiently deceived.
Manipulation Check 2: Realism Heuristic
We checked whether the cued realism heuristic would increase with modal richness. However, while the realism of the combined video conditions is significantly higher than that of the combined audio conditions (b = 0.20, p = .043), there is no significant difference between combined audio and 360° conditions (b = −0.12, p = .23), as well as the combined 360° and video condition (b = 0.07, p = .403). Moreover, we observed no significant interaction between the modality and facticity conditions. Based on this, we cannot assume that modal richness triggered the realism heuristic (Supplemental Table A2).
Results
Effect of the Deepfake Reveal on General Credibility
Hypothesis 1 stated that revealing deception through deepfakes decreases the perceived credibility of those media formats in general. As indicated by Figure 2, overall, hypothesis 1 can be confirmed: the perceived credibility of media formats decreases significantly after revealing deception to participants (Supplemental Table A3).
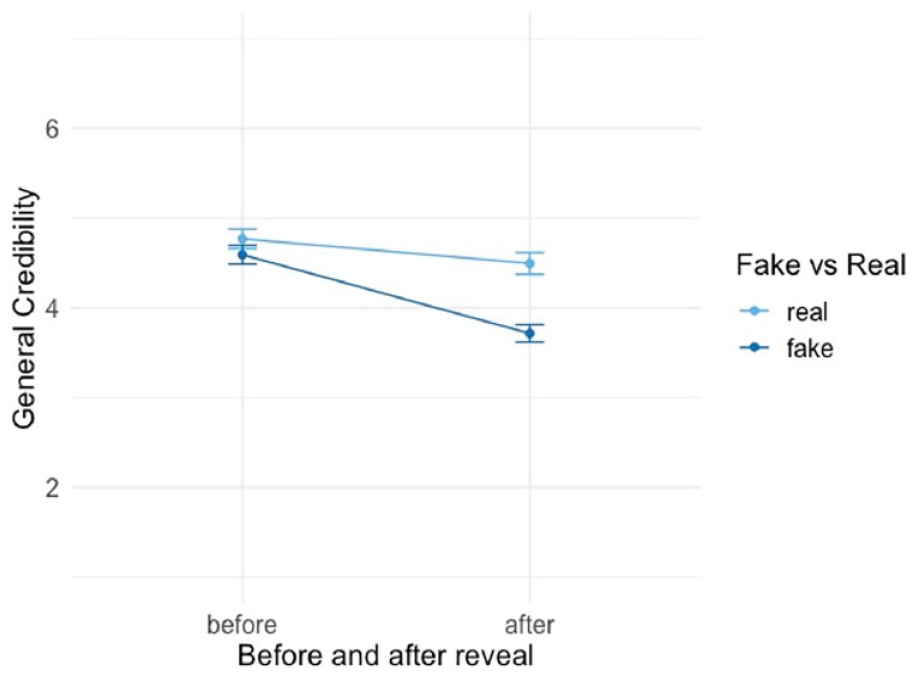
Effect of reveal on general credibility of media formats, hypothesis 1.
This main effect (η2 = 0.05) reveals that participants evaluate general credibility as substantially lower after the reveal (b = −0.576, p = .001), and when they have experienced a deepfake, regardless of modality (b = −0.479, p = .001) (Supplemental Table A3, Model 3). A moderation analysis further indicates a substantive and significant interaction between the facticity (real vs. fake) of the production and the timing of the reveal (before vs. after) (b = −0.60, p = .001; η2 = 0.01) (Supplemental Table A3, Model 4). Specifically, for participants who experienced a deepfake, the credibility evaluations dropped significantly after the reveal compared to those who experienced a real condition. The average general credibility evaluation of the format dropped from M = 4.59 (SE = 0.05) to M = 3.71 (SE = 0.05) after the reveal for those who experienced a deepfake, while it dropped from an average of M = 4.77 (SE = 0.05) before the reveal to M = 4.49 (SE = 0.06) after the reveal for those who experienced a real production.
Concerning the effect of the reveal on credibility of the different modalities, the identified tendencies largely remain the same across the between-subjects factor modal richness (Figures 4–6; Supplemental Table A4). For the audio condition, there is a significant and substantive interaction between the reveal and the facticity condition (b = −0.53, p = .001), which means that the average drop of the credibility of audio before the reveal M = 4.52 (SE = 0.095) down to an average of M = 3.79 (SE = 0.0851) after the reveal (Figure 3) is more significant for participants who heard the AI-generated voiceover. Similarly, in the video condition (Figure 4), there is a significant interaction effect (b = −0.40, p = .01), as the general credibility of the deepfake video dropped from an average of M = 4.40 (SE = 0.089) down to an average of M = 3.73 (SE = 0.08) after the reveal. Lastly, there is a significant interaction effect between facticity and reveal (b = −0.88, p = .001) for the 360° condition (Figure 5), again showing that credibility of 360°-videos dropped more for participants in the deepfake condition, from an average of M = 4.86 (SE = 0.09) to an average of M = 3.63 (SE = 0.086) after the reveal. These results confirm hypothesis 1.
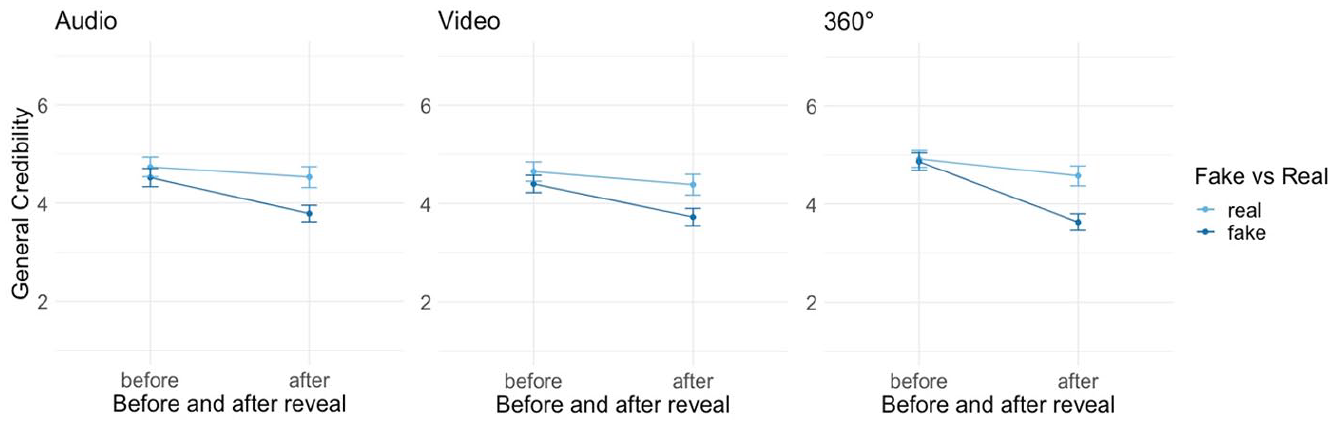
Effect of reveal on general credibility per modality (audio, video, 360°), hypothesis 1.
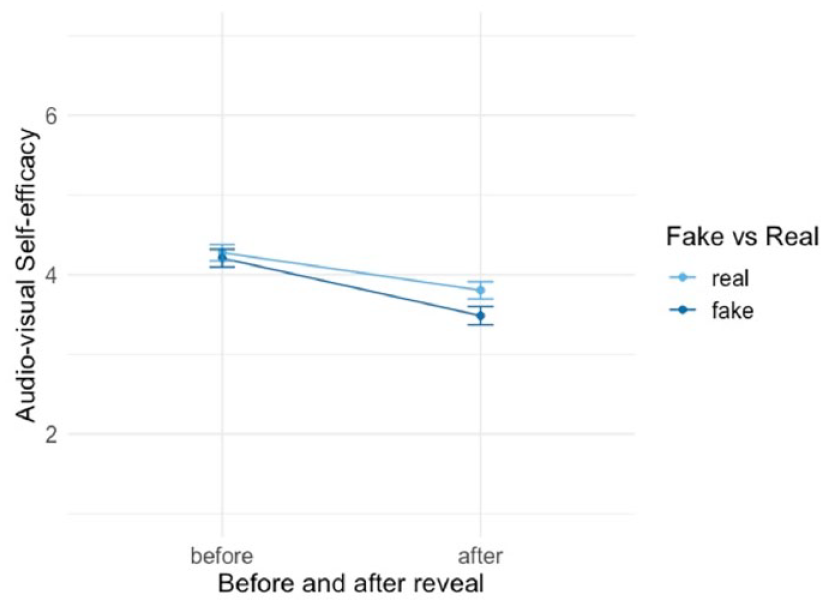
Effect of reveal on self-efficacy to detect audio-visual deepfakes, hypothesis 2.
Effect of the Deepfake Reveal on Audio-Visual Self-Efficacy
As specified in hypothesis 2, we are interested in whether being deceived through a deepfake also decreases one’s self-efficacy to detect audio-visual deepfakes. Here, our results are mixed: while we find that overall, participants who were exposed to a deepfake production showed lower deepfake self-efficacy ratings, the effect size is small. Additionally, when examining the different modalities, the interaction becomes insignificant.
As illustrated in Figure 6, the analysis of the main effect shows that participants’ self-efficacy to detect deepfakes is significantly lower after the reveal (b = −0.598, p = .001), and for those who experienced a deepfake (b = −0.195, p = .001), constituting a medium effect (η2 = 0.06) (Supplemental Table A5, Model 3). Furthermore, the moderation analysis revealed a negligible (η2 = 0), yet significant moderation effect (b = −0.25, p = .002), indicating that participants who were exposed to a deepfake evaluated their self-efficacy to detect fakes as slightly lower than those, who experienced an authentic production (Supplemental Table A5, Model 4). More specifically, the self-efficacy to detect deepfakes decreases from an average of M = 4.21 (SE = 0.05) to an average of M = 3.48 (SE = 0.06) for participants who experienced a deepfake, while for those who experienced a real production, the self-efficacy decreased from an average of M = 4.28 (SE = 0.05) before the reveal to an average of M = 3.80 (SE = 0.05) after the reveal.
However, as can be read from Figures 8 through 10, when interested in whether this tendency holds true for each modality, we find no significant interaction between the facticity condition and reveal (Supplemental Table A6). That is, neither in the audio condition (b = −0.32, p = .07, Figure 7), nor the video condition (b = −0.24, p = .06, Figure 8) nor the 360° condition (b = −0.25, p = .22, Figure 9) is there a significant interaction between the reveal and the facticity condition. Based on this, we conclude that there is an overall small decrease in self-efficacy to detect audio-visual deepfakes when people learn that they have been deceived in contrast to people who have not been deceived; however, this effect is small and disappears when we look at each modality individually. Therefore, these results lend partial support for hypothesis 2.
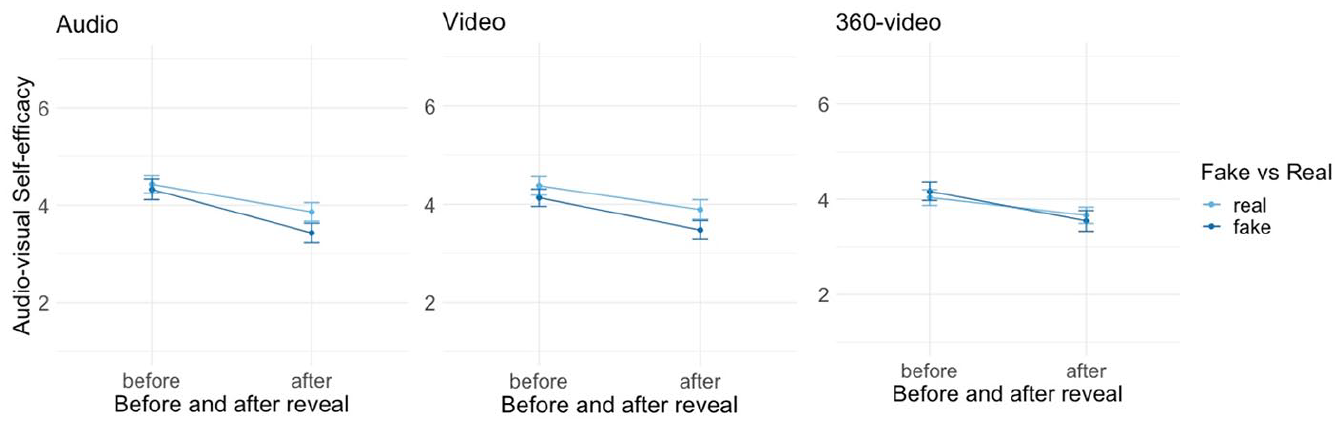
Effect of reveal on self-efficacy to detect deepfakes per modality (audio, video, 360°), hypothesis 2.
Effect of Modal Richness on Stimulus Credibility
In H3ab, we assume that a higher modal richness of a deepfake production results in a higher credibility evaluation of the stimulus. More specifically, we assume that a 360°-deepfake is evaluated as more credible than a deepfake video, which is evaluated as more credible than a deepfake audio; the same is expected for the authentic modalities. As Figure 10 shows, however, our OLS-based regression analysis does not support this hypothesis. A deepfake 360°-deepfake was not evaluated as significantly more credible than the deepfake video (b = −0.01, p = .913) and deepfake audio (b = 0.036, p = .8). In turn, video was not evaluated as more credible than the deepfake audio (b = 0.05, p = .70) (Supplemental Table A7). Similarly, there are no significant differences between the authentic modalities and their credibility evaluation. More specifically, the real 360°-video was not evaluated as significantly more credible than the real video (b = −0.09, p = .475) and real audio (b = 0.00, p = .985). In turn, video was not evaluated as more credible than audio (b = 0.09, p = .52) (Supplemental Table A8). Thus, hypotheses 3ab are rejected.
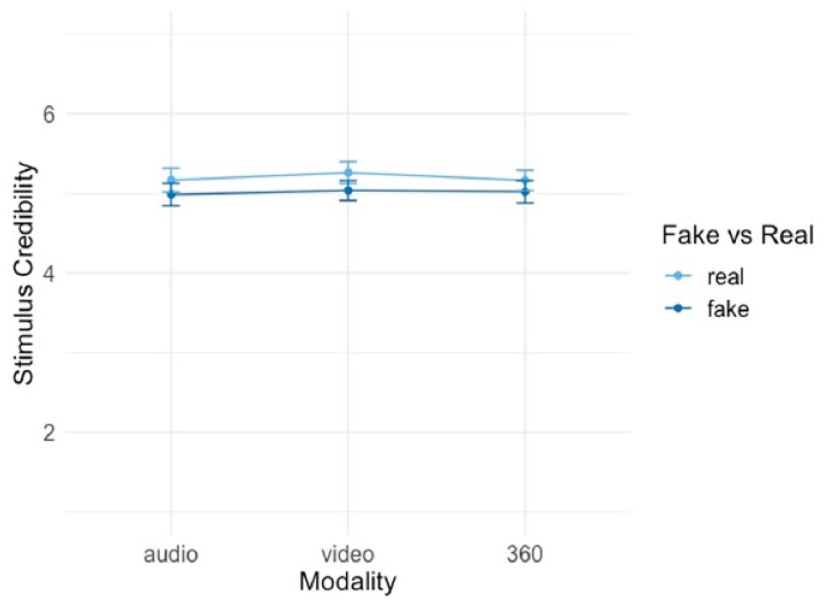
Effect of increasing modal richness on stimulus credibility, hypotheses 3ab.
Discussion
This study investigated the perceived credibility of deepfakes differing in media richness and the broader implications of being deceived through them. Participants across both between-subject factors—facticity (real vs. fake) and modality (audio vs. video vs. 360°)—were significantly more uncertain in the post-test regarding their ability to spot a deepfake as well as their general belief in audio-visual media. This significant drop was more pronounced for people exposed to a deepfake when investigating the variable general credibility: participants who saw the deepfake attributed less credibility to audio-visual media in general after the reveal in comparison to the control group (H1). We did not observe the same interaction effect for the outcome variable deepfake self-efficacy: all participants expressed less self-efficacy in the post-test, also those in the control conditions (H2). Moreover, we did not find any differences in credibility perceptions between an audio, video, and 360°-video deepfake (H3ab/RQ1). These findings contribute to the literature by showing that (1) deception through deepfakes can have further-reaching consequences than simply being deceived, (2) “seeing is believing” is an ambivalent concept that may be measured through the variable general credibility of media and deepfake self-efficacy, and that (3) media richness may play a smaller factor for the credibility of media formats than previously anticipated.
First, our study shows that the concern that, as deepfakes become more common, people no longer believe in what they see (Barnes and Barraclough 2020; Chesney and Citron 2019; Geddes 2021; Wagner and Blewer 2019), is to an extent justified. The effects we find in this study are substantial, especially regarding the deepfake reveal: both general credibility and self-efficacy were substantially affected after it. These findings align with fact-checking research that has found backfiring effects on trust in news outlets that reported falsehoods (Bachmann and Valenzuela 2023), or news credibility in general (van der Meer et al. 2023). In a high-choice media environment, concerns about being exposed to misinformation and its negative consequences on citizens’ trust in institutions are more prevalent than ever. If people feel increasingly uncertain about what they see and hear in the media, this may further fuel their skepticism towards journalism and politics (e.g., Vaccari and Chadwick 2020). However, it could also mean that people will be more cautious in the future, and that they think more carefully about whether a mediated message is believable. This could also alleviate some of the pressure on journalists and fact-checkers, as citizens may feel more empowered to critically assess visual content themselves, thus applying healthy skepticism toward what they see in the news. We suggest that future research shall take into account a broader range of dependent variables, such as willingness to engage in media literacy education.
Second, our study is one of the first to operationalize “seeing is believing” for empirical research, showing that this concept is multidimensional. We used two sets of dependent variables: believing in the media artefact and believing in one’s own ability to discern between real and fake. As our findings show, each outcome was impacted differently post-reveal. While we did find an interaction effect of our factor “reveal” in both cases when looking at all modalities combined, we found that the reveal mattered only for general credibility when looking at audio, video, and 360° in isolation. This means people revise how credible they find different media in general, specifically after they have been deceived by a deepfake. For those in the control group, general credibility remained somewhat stable. The effect on self-efficacy paints a different picture: post-reveal, people in the control groups also revised their level of confidence in their own skills. Self-efficacy is not a stable construct, but depends on cognitive processing and can vary per situation. Especially challenging experiences can lead to a higher level of analytical thinking, which then can lead to a revision of self-judgment (Bandura 1982). Thus, it might be the case that self-efficacy was questioned more critically in the second post-test, even when participants were exposed to authentic media. In contrast, the general credibility of audio-visual media is not as easily compromised, perhaps because pictures are generally thought of as telling the truth (Kasra et al. 2018). Overall, we consider the operationalization successful and hope it will inspire future research.
Third, we were unable to replicate the findings by Vettehen et al. (2019), who found differences in credibility evaluations between 360°-video versus video, and Sundar et al. (2021), who found that misinformation in the form of a video was rated more credible than when presented as audio. This is surprising, as the mentioned studies found large differences between the modalities, which they were able to explain through heuristic-based judgments (Sundar 2008). In contrast, we did not find that the realism heuristic increased substantially for the richer stimuli. A possible explanation is the difference in study design, such as conducting a survey-embedded experiment as opposed to Vettehen et al. (2019), who gave participants a head-mounted display in a laboratory setting. This might have limited the experience of presence in our setup, leading to equal credibility evaluations of the 360°-video and the other conditions. Moreover, our stimulus lacked any source cues and utilized non-sensationalist language commonly found in disinformation messages. While we acknowledge that many existing deepfakes exhibit glitches, it is essential to recognize that our stimulus surpasses the technical standard of most audio-visual disinformation prevalent today. However, the primary objective of this research was to create entirely fabricated content, to investigate precisely what happens after deception. For future studies, it would be valuable to explore combinations of fake and real content, such as a manipulated video paired with authentic audio, varying in technical quality.
Several other limitations should be mentioned. The fact that there was little time between the reveal and post-test could mean that we are dealing with a so-called learning effect (Charness et al. 2012). Participants might have answered differently in the post-test, simply because they were asked the same question again (although reverse-coded). Moreover, including reverse-coded items to limit learning effects (Weijters et al. 2009) only to the post-test might have biased the response pattern from pre- to post-test negatively. Still, we are confident in the overall interpretation of our results, as we found a small but significant interaction effect of the factors facticity and reveal, and the reverse coding remained stable over the between-factors. Moreover, this study did not use a traditional fact-check to reveal the fakery, but instead a generic reveal without source cue. Misinformation corrections are nowadays no longer bound to a fact-checking outlet, but may be communicated privately or by random social media users (Chia et al. 2022). Future research may investigate whether the way in which deception is revealed matters for the secondary effects of visual disinformation (see Vraga et al. 2020). Finally, we tested our hypotheses exclusively within the context of Syrian refugees in Lebanon. This topic has gained significant prominence in Germany (Heidenreich et al. 2019), and the effects could vary if the stimulus had revolved around an issue less familiar to participants. Furthermore, Germany is one of the countries that display high resilience to online disinformation (Humprecht et al. 2020). We suggest that our hypotheses should be tested in various contexts and media environments.
Despite the above-mentioned limitations, we hope future research will be inspired by the within-subjects design of this study, as it facilitates the exploration of a broader range of consequences manipulated media may have. In addition, we encourage the investigation of the role media richness plays for deception, especially given the ongoing evolution of techniques for creating audio-visual forgeries.
Supplemental Material
sj-docx-1-hij-10.1177_19401612241233539 – Supplemental material for After Deception: How Falling for a Deepfake Affects the Way We See, Hear, and Experience Media
Supplemental material, sj-docx-1-hij-10.1177_19401612241233539 for After Deception: How Falling for a Deepfake Affects the Way We See, Hear, and Experience Media by Teresa Weikmann, Hannah Greber and Alina Nikolaou in The International Journal of Press/Politics
Footnotes
Acknowledgements
We would like to thank Jana Laura Egelhofer, Loes Aaldering, and Sophie Lecheler for their guidance, support, and thoughtful feedback on our manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Research Award from the Department of Communication at the University of Vienna to finance the data collection for their study. Hannah Greber received the DOC stipend of the ÖAW (Austrian Academy of Sciences), under grant No. 26419.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.