
Abstract
Deepfakes dominate discussions about manipulated videos, but other forms of visual disinformation are more prevalent and less understood. Moreover, deception is often assessed through measuring credibility, overlooking cognitive effects like misperceptions and attitude changes. To address these gaps, an online experiment (N = 802) examined visual disinformation’s effects on credibility, misperceptions, and perceptions of a politician. The study compared a deepfake (machine learning manipulation), a cheapfake (rudimentary manipulation), and a decontextualized video (false context), all portraying the same politician and false message. Despite low in credibility, the deepfake and cheapfake caused a misperception, with the deepfake harming perceptions of the politician.
Keywords
In recent years, concerns about visual disinformation generated using artificial intelligence (AI) have been growing (e.g., Adami, 2024), especially with the rise of deepfakes (Dan et al.,2021; Wahl-Jorgensen & Carlson, 2021). These videos are produced by training machine learning models to mimic a person’s appearance and voice (Maras & Alexandrou, 2019), allowing for the manipulation of a politician’s statement by literally putting words into their mouth. Despite growing concerns about such sophisticated manipulations, recent research suggests that most visual disinformation available in the public domain right now is produced without requiring any advanced technology, such as AI (Brennen et al., 2021; Yang et al., 2023). However, the comparative deceptiveness of these less sophisticated formats has received relatively little attention. In addition, despite previous studies addressing the issue of credibility—whether individuals can discern a deepfake from authentic media—little is understood about the extent to which misleading images can genuinely alter beliefs or cause misperceptions, and how this outcome may differ from credibility perceptions.
Deepfakes have put visuals on the agenda of mis- and dis-information research, which shows that they can have detrimental consequences regarding their effect on political attitudes and trust in news on social media (Dobber et al., 2021; Vaccari & Chadwick, 2020). Next to deepfakes, decontextualized videos and photographs, which have been unaltered but instead put in a different context, are frequent forms of visual misinformation fact-checkers come across (Brennen et al., 2021; Weikmann & Lecheler, 2023a). Moreover, “cheapfakes” (sometimes called “shallow fakes”) that employ simple manipulation techniques are suspected to be spread more often than actual deepfakes, as they are still easier to create (Paris & Donovan, 2019). These forms differ from deepfakes in prevalence and the sophistication required for their creation. A decontextualization uses entirely authentic material, while a cheapfake only makes slight changes to audio-visual material. An AI-based deepfake, however, has the powerful capacity to forge a message completely. In light of this, it appears plausible that these different techniques are also perceived differently, all while assuming that the false information they convey is identical.
A key concern about visual disinformation is its potential to deceive individuals, leading them to mistake fabricated content for genuine information (Peng et al., 2023). According to the realism heuristic, visual media convey richer sensory cues than textual information. This triggers heuristic-based judgments, leading them to be evaluated as especially realistic and true-to-life (Sundar, 2008). Following this, most studies concerned with the effects of deepfakes have disproportionately focused on the extent to which they are evaluated as credible (e.g., Dobber et al., 2021; Hameleers et al., 2022, 2023; Lee & Shin, 2021; Shin & Lee, 2022; Weikmann et al., 2025), while fewer studies chose a focus on misperceptions (Lee & Hameleers, 2024; Lee et al., 2023). However, in this article, we argue that it is crucial to differentiate between initially assessing something as credible and genuinely believing a falsehood. Manipulated (audio-)visuals can influence our belief system to the extent that they overwrite existing memories of real events (Johnson et al., 1993). Moreover, even when content is perceived as not credible, it may still have an impact on perceptions. Even low-credibility content, including fiction, can shape an individual’s beliefs (Gerbner et al., 2002). Thus, it is essential for research on visual disinformation to examine its effects on credibility perceptions and potential misperceptions simultaneously.
To address these gaps, we conducted an online experiment (N = 802) investigating the effects of the discussed forms of audio-visual disinformation. We exposed a varied sample of Austrian participants to a social media post including either (a) an authentic video of politician Ursula von der Leyen; (b) a decontextualization of it—including a misleading caption, thus misusing the video as evidence for a false claim; (c) a cheapfake video—edited with simple techniques to strengthen the false claim, or (d) a deepfake video—edited with the help of a deepfake app, thus explicitly stating a false claim. We test to what extent the different forms of audio-visual disinformation affected participants’ credibility perceptions, considering issue-congruent attitudes as a moderating variable. In addition, we tested whether the videos led to misperceptions regarding von der Leyen and how perceptions of her integrity as a politician were affected. By doing so, we enhance our understanding of the impact of various types of visual disinformation beyond AI-generated deepfakes and credibility evaluations.
Different Forms of Visual Disinformation
While deepfakes have received increased attention in recent years, studies stress that visual disinformation is multifaceted in form (Peng et al., 2023; Yang et al., 2023) and can be categorized according to its (a) modal richness and (b) manipulative sophistication (Weikmann & Lecheler, 2023b). First, either still or moving images may be employed, that is, photographs or videos. Second, the techniques used for manipulation may be more or less advanced. Simply adding a false caption conveys false information through text, while manipulating the image directly offers the means to make a falsehood appear convincing through visual elements. Using the term disinformation implies that the creation of misleading visuals is usually a deliberate act, often with intent. Naturally, visuals can also constitute misinformation, for instance, when they are inadvertently disseminated because they are believed to be authentic (Weikmann, 2025). Since this article examines deceptive visuals that differ in their intentional manipulation, we use the term “visual disinformation.” Furthermore, we focus on audio-visual content, particularly videos, representing the richest form.
The most rudimentary way a video can be used for deceptive purposes is by decontextualizing, where an authentic video remains unchanged but is paired with misleading text, falsely professing it shows something it does not (Hameleers et al., 2020). For example, videos have been claimed to show military attacks in Russia’s war against Ukraine when, in fact, they stemmed from a completely different conflict (García-Marín & Salvat-Martinrey, 2023). Cheapfakes involve basic editing techniques like speeding up, slowing down, or cutting parts to distort the video’s meaning. In 2018, a newly cut-together BBC news report led people to believe in a false nuclear escalation (Paris & Donovan, 2019). Because no complicated technology is needed for their creation, these techniques are considered low in sophistication (Weikmann & Lecheler, 2023b). In contrast, deepfakes are more advanced, as their creation relies on AI, particularly a machine learning technique known as deep learning, which uses generative adversarial networks (Paris & Donovan, 2019). This AI-driven process involves training an algorithm on authentic audio-visual material of an individual (e.g., a politician), enabling it to replicate their facial expressions and speech patterns (Hameleers, 2024a). As a result, deepfakes present seemingly limitless potential for manipulation (Maras & Alexandrou, 2019). While early instances of deepfakes required expertise in machine learning, such as the one where Barack Obama seemingly uses crude language, smartphone apps now allow their creation without specialized skills (Maras & Alexandrou, 2019; Paris & Donovan, 2019). Due to the complex underlying technology, deepfakes are classified as highly sophisticated (Weikmann & Lecheler, 2023b). The discussed formats signify a gradual increase in sophistication, as can be seen in Figure 1.
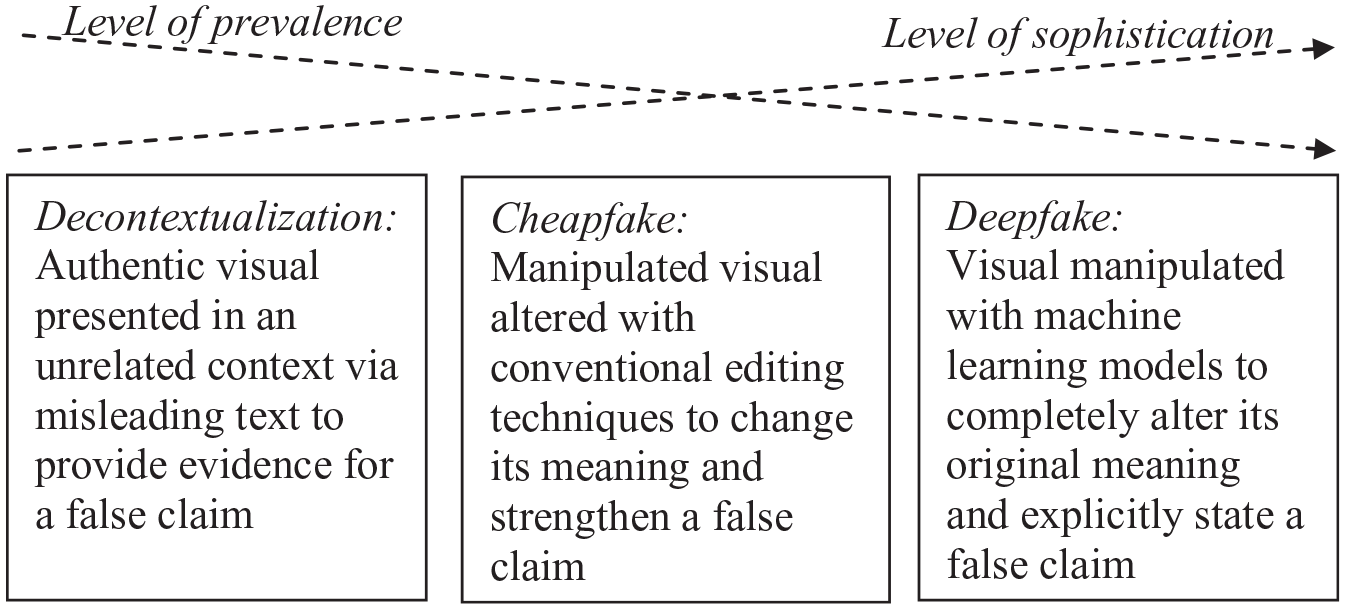
Overview of Different Visual Disinformation Formats.
Initial research indicates varying degrees of online prevalence for these different formats. For instance, Yang et al. (2023) discovered that 20% of Facebook images related to U.S. politics contained misinformation, primarily in the form of memes, digitally altered photos, and decontextualized images. Similarly, an analysis of fact-checking articles suggests that most false information about COVID-19 was spread using manipulated and mislabeled images (Brennen et al., 2021). A content analysis of debunked visual disinformation related to Russia’s war against Ukraine predominantly identified decontextualized images (García-Marín & Salvat-Martinrey, 2023). This implies that most false visual content involves basic forgeries rather than deepfakes. Decontextualization appears to be the most common, followed by cheapfakes and deepfakes, indicating a decrease in prevalence and likelihood of encountering them online (see Figure 1). Given these differing levels of sophistication and prevalence, we present participants with a decontextualization, cheapfake, and deepfake featuring the President of the European Commission, Ursula von der Leyen.
Deception Through Visual Disinformation
Visual disinformation has the ability to deceive people. Most studies to date have explored this issue by measuring the perceived credibility of visual disinformation, such as deepfakes, compared to authentic videos (e.g., Dobber et al., 2021; Hameleers et al., 2023; Ternovski et al., 2022) or disinformation in text form (e.g., Hameleers et al., 2022; Lee & Shin, 2021). However, we argue that only measuring message credibility is not sufficient to understand the full extent to which individuals can be deceived by (audio-)visual disinformation. Here, we build on Chadwick and Stanyer’s (2022) conceptualization of deception as a bridging concept. The authors stress that deception in disinformation research not only encompasses the intentions of those who aim to deceive but also the degree to which they succeed. Deception, they argue, is only reached when false or distorted beliefs are adopted (Chadwick & Stanyer, 2022). Therefore, in this study, we not only study the extent to which different forms of audio-visual disinformation compare in terms of their perceived credibility but also the extent to which they may elicit misperceptions. While previous research has investigated the effect of deepfakes on misperceptions (see Lee & Hameleers, 2024; Lee et al., 2023), our study is one of the first to investigate these effects in tandem. In addition, we are interested in the effects on attitudes, that is, how perceptions of the portrayed politician are affected.
Credibility Perceptions of Visual Disinformation
The capacity of visual disinformation to be perceived as particularly credible is often explained through Sundar’s (2008) MAIN model, which refers to digital media’s affordances’ influence on judgments of credibility. Certain media affordances dictate the triggering of heuristics, that is, mental shortcuts that shape the interpretation of a message. An essential affordance in this context is modality, referring to the structure of a medium. Audio-visual media, in particular, exert a significant influence on the so-called realism heuristic, positing that “people are more likely to trust audio-visual modality because its content has a higher resemblance to the real world” (Sundar, 2008, p.80). The MAIN model offers a straightforward approach to measuring the believability of audio-visuals. By inquiring about the extent to which individuals find a message accurate, authentic, and believable, such as one conveyed by a deepfake, it becomes possible to evaluate its message credibility (Appelman & Sundar, 2016; Metzger et al., 2003; Sundar et al., 2021).
In line with this, a growing body of studies has investigated the extent to which individuals find (audio-)visual disinformation credible, hereby comparing deepfakes to other formats. Experiments testing the perceived credibility of deepfakes of politicians over textual disinformation do not find significant differences (e.g., Barari et al., 2021; Hameleers et al., 2022, 2023). Authentic videos are frequently evaluated as more credible compared to deepfakes (Dobber et al., 2021; Hameleers et al., 2022; Vaccari & Chadwick, 2020). However, using high-quality deepfake stimulus material leads to no difference in credibility perceptions (Jin et al., 2023; Weikmann et al., 2025). Importantly, while the MAIN-model addresses how modality affects credibility, it is unable to explain the effects of different manipulation techniques across (audio-)visuals. Yet, the way in which a video is edited appears to matter for the degree to which individuals find it believable. While few studies have directly compared different manipulation techniques, Hameleers (2024a) finds that a cheapfake is more credible than a deepfake. Moreover, audio-visual malinformation, meaning an unaltered video including a particularly controversial statement by a politician, is more credible than a deepfake (Hameleers et al., 2023). In both cases, the visual disinformation was rated lower in credibility compared to an authentic video.
This suggests that, next to modality, features related to the visual disinformation’s content play an important role for credibility perceptions. This is in line with message credibility research, from which we know that message quality and content fluency—referring to how easily a message can be processed—influence believability (Metzger et al., 2003; Ou & Ho, 2024). Message quality can be related to visual disinformation’s technical manipulation. Through an increase in sophistication and the application of a more complicated technique, individuals may be more capable of recognizing technical flaws (unless the deepfake is of very high quality). Moreover, content fluency relates to the degree of falsehood of visual disinformation. This can be enhanced by the visual clarity of a message’s presentation, referring to the display quality of a video (Alter & Oppenheimer, 2009). Moreover, a deepfake and cheapfake showing a false claim in both video and caption may be less credible than a decontextualized video, which contains no false statement on the visual level and is at least partially true. In line with this, research shows that textual misinformation is evaluated as more credible when it is only partially, but not completely, false (Hameleers et al., 2021; Staender et al., 2021). Overall, this leads us to pose the following hypotheses:
An important factor to take into account when studying the effectiveness of misinformation is citizens’ prior beliefs. According to motivated reasoning theory, individuals tend to believe information that aligns with their political beliefs (Kunda, 1990). Therefore, it is sensible to assume that predispositions about the topic covered in visual disinformation might make it more believable. Previous studies show this in the context of deepfakes. For instance, Shin and Lee (2022) find that preexisting attitudes toward topics such as abortion and legalization of drugs can make a deepfake about these topics more believable. Similarly, Hameleers et al. (2022) find that the stronger people’s anti-immigration beliefs, the more likely they find a deepfake covering this topic credible. Building on these findings we hypothesize:
Misperceptions Through Visual Disinformation
In this article, we argue that there is a conceptual difference between assessing a form of visual disinformation as believable (i.e., credible) and believing in what it portrays. Specifically, testing deception through visual disinformation by measuring credibility perceptions only addresses the mental shortcut an individual makes when initially evaluating a message (Sundar, 2008). However, deception also pertains to how someone subsequently interprets or thinks about a specific issue, that is, the extent to which knowledge perceptions are affected (Chadwick & Stanyer, 2022). If an individual is exposed to false information, a potential outcome is the formation of opinions and beliefs in alignment with that information, commonly referred to as misperceptions, that is, “factual beliefs that are false or contradict the best available evidence in the public domain” (Flynn et al., 2017, p.128).
Different drivers can lead to the adoption of misperceptions, as research on text-based disinformation shows. In this context, credibility is regarded as a contributing factor rather than merely an outcome, reinforcing the need to distinguish it from misperceptions (Ecker et al., 2022). Deceptive (audio-)visuals hold a high potential of contributing to misperceptions. Specifically, in addition to enhancing credibility, photographs and videos play a pivotal role in belief formation, as they can significantly influence the construction of memories. We reason this based on the source monitoring framework, which posits that human memories draw from various sources, including books, conversations, and visual materials like photographs (Johnson et al., 1993; Pena et al., 2017). If such a source provides false evidence, it may foster false memories in individuals. Research shows this is particularly true when it comes to manipulated images (Nash et al., 2009; Sacchi et al., 2007), and can even be the case when a photograph is poorly doctored (Nash, 2018). Different mechanisms may be at play here: incorrect evidence provided by a false visual may make it difficult to differentiate between a lived experience and the image, increase the perceived plausibility that an event happened, or simply lower the bar for what is considered a memory (Nash et al., 2009). In line with this, a study by Murphy and Flynn (2022) demonstrates that deepfakes can overwrite existing knowledge if their content is deemed plausible. However, the exact mechanism explaining this effect is context-dependent, and largely unclear when studying deepfakes (Newman & Schwarz, 2024). At a very basic level, research indicates that deepfakes can elicit misperceptions, for instance, about health-related topics (Lee et al., 2023), and that their visual modality may be a key contributing factor (Lee & Hameleers, 2024). In addition, we know that individuals form opinions and beliefs even based on audio-visual sources they know are not representations of reality, such as fictional television shows (Gerbner et al., 2002).
In sum, while it may be plausible to assume that credibility perceptions translate into the elicitation of misperceptions, we argue that they do not necessarily go hand in hand. Our study, therefore, explores both effects in parallel. Because we do not know to what extent misperceptions may arise through various forms of visual disinformation, we state the following research question:
Visual Disinformation’s Effect on Perceptions of Politicians
Thus far, we have established why visual disinformation has the potential to deceive individuals into believing false information. Connected to this is its impact on attitudes toward the person portrayed: if a falsehood is believed, this can change how people perceive and feel about that individual. Extant research has already established the influence of mis- and disinformation on citizens’ perceptions of political actors. Studies show that belief in disinformation can impact voting behavior by diminishing support for the governing party and swaying opinions toward right-wing populism (Zimmermann & Kohring, 2020). Moreover, misinformation can increase cynicism toward individual politicians (Balmas, 2014). Political actors are frequent targets of visual disinformation, as images are often used to discredit or defame them (Brennen et al., 2021). Deepfakes have received particular attention as a potential tool for doing so, resulting in a number of conjectured scenarios. For instance, it is often imagined that deepfakes will be used to make a political actor say something derogatory, questionable, or right-out dangerous, which could diminish public support for them or lead to political upheaval (Chesney & Citron, 2019).
Although deepfakes may not inherently possess more or less credibility than text-based disinformation (e.g., Hameleers et al., 2023), research indicates that their influence on shaping negative attitudes toward politicians depicted in them is worrisome. Dobber et al. (2021) exposed participants of an experiment to a deepfake discrediting Christian politician, which led them to evaluate him more negatively (see also Barari et al., 2021). A recent study by Dan (2025) tested the effects of cheapfake versus different deepfake conditions on attitudes toward a fictitious politician, showing that reputational damage can happen irrespective of the manipulation technique. As the mentioned studies all use slightly different operationalizations and falsification techniques for the deepfake and cheapfake stimuli, and given that the effects of a decontextualized video, cheapfake, and deepfake have not been tested vis-à-vis, we pose the following research question:
Additionally, we hypothesize:
Method
Stimuli
The preregistered 1 online experiment is set up as a between-subjects design with four conditions: (a) authentic video, (b) decontextualized video, (c) cheapfake video, and (d) deepfake video. Participants were either exposed to (a) an unaltered video of European Commission President Ursula von der Leyen embedded in a Facebook post with an accurate caption, (b) the same authentic video taken out of context through the caption (= decontextualization), (c) a cheapfake version of the video that is combined with other audio footage of Ursula von der Leyen and (d) a deepfake based on the authentic video changing the words von der Leyen actually said. Von der Leyen was selected, as she is a former intra-German and current European Union (EU) politician, thus well-known in Austria. However, she does not have direct influence over Austrian political affairs. Hence, we expect preexisting attitudes toward her to be less pronounced. The manipulated videos all make the same false claim, which is supported by the video in differing ways: that von der Leyen primarily welcomes Christian refugees to Europe. The four conditions are visualized in Figure 2.

Overview of Experimental Conditions.
To create the stimuli, we took an authentic video clip from an interview von der Leyen gave to Vatican News in May 2021, in which she stresses the importance of Christian values in Europe (Galgano, 2021). The control condition saw this video with the caption “Ursula von der Leyen on the importance of Christianity for peace in Europe.” In the decontextualized condition, this clip is misused as evidence for the false claim that von der Leyen only welcomes Christian refugees from Ukraine in Europe, which is stated in the caption: “Ursula von der Leyen openly admits that only Christian refugees from Ukraine are welcome!” The same caption was used for the cheapfake video, which was intercut with audio footage from other interviews she gave a German public broadcaster (ZDF, 2022). Here, she actually uses the words “Christian refugees are welcome, and we do everything we can to protect them.” The deepfake was accompanied by the same misleading caption. Its audio track was recorded by German voice imitator Antonia von Romatowski, mimicking the voice of von der Leyen. In this condition, she explicitly states, “refugees from Ukraine who belong to this religion are particularly welcome and we do everything we can to protect them.” We used the app Reface to change the lip movements in the original video and match them to the false audio recorded for the deepfake. All stimulus clips visualized in Figure 2 do not exceed 25 s. Transcripts of the different conditions can be found in Appendix A. Watermarked versions of the stimuli are available as part of the preregistration on OSF. 2
Our goal in selecting these stimuli was to ensure high ecological validity. To achieve this, we designed them to closely resemble real-world cases of visual disinformation (see also Hameleers, 2024b). Examples include a decontextualized video of German politician Annalena Baerbock expressing support for Ukraine (StopFake, 2022), a cheapfake of British politician Keir Starmer omitting part of an interview statement (Full Fact, 2019), and the well-known deepfake of Volodymyr Zelenskyy “surrendering” to Russia. Additionally, our stimulus was based on a real and timely news story—discrimination against People of Color (POC) at EU borders during the Ukraine war—reinforced by having a Christian politician deliver the false message. This alignment with actual disinformation patterns strengthens the ecological validity of our stimuli.
Thorough consideration was given to potential ethical concerns during the design of this study, especially given Ursula von der Leyen’s active political role and the possibility that our stimulus could evoke negative sentiments toward a specific group of refugees. However, we deemed this manipulation necessary to ensure the relevance of our experiment to real-world situations. Moreover, including naturalistic stimuli is common practice when seeking to understand the cognitive processes of disinformation exposure (Greene et al., 2023). We implemented various precautions to prevent any unintended dissemination of the stimulus and designed a thorough and educational debrief. Our reflection on the stimuli’s content and the safety measures taken are further explained in Appendix B. Importantly, our study’s ethical framework adhered to peer recommendations and received approval from the Institutional Review Board (IRB) of the University of Vienna (Antrag 2022; 1123_064), where this research was conducted.
Procedure
Upon providing their consent, participants answered a set of demographic questions. Next, they solved a sorting task, where they were presented with six different German female politicians or journalists, one of them being Ursula von der Leyen. The objective was to check whether they recognized von der Leyen on a basic level by correctly sorting her in the category “politician” (other options for the sorting task included “journalist,” “actor,” and “don’t know”). A total of 83.5% (n = 670) of participants correctly identified her as a politician, and 16.5% (n = 132) did not. After that, we measured our moderators and asked participants distracting questions about their social media use, which were disregarded in the analysis. Then, they were required to listen to an audio file to ensure that the audio on their device was working. Next, they were randomly presented with one of the four stimuli described above. Following this, we conducted a manipulation check regarding the content of the video to see if participants understood the main message of the authentic condition versus the manipulated conditions. Then, we measured our dependent variables. At the end of the questionnaire, we conducted a “fabrication check,” investigating whether participants were able to recognize which element of the video they had just seen was fake. Finally, participants received an extensive debrief where they were shown the real video and the webpage of Vatican News the stimulus is based on Galgano (2021), were given advice on how to spot manipulated visual media, and declared they understood that von der Leyen never made the statement shown in the manipulated conditions.
Sample
To estimate how many participants are needed to test the hypotheses for the main effect on credibility perceptions, a power analysis was conducted through simulation in R, an approach inspired by Johannes (2022). We simulated a linear regression, including post-hoc comparisons with 200 runs to model the main effect of the four categorical predictors on the expected mean scores for the variable “credibility perception,” based on previous research by Hameleers et al. (2022) and Dobber et al. (2021; see Appendix C for exact scores and power plot). The p-value for the post hoc contrast was set to .05. The power plot showed that N = 600 participants are needed for 80% power and N = 800 for 90% power. We aimed for 90% power to minimize the possibility of committing a Type 2 error.
A diverse sample of Austrian citizens (N = 802) was recruited through the panel agency Dynata, approximately matching the demographic characteristics of the general Austrian population (Sample details: Aged 18 and older; M = 48.53, SD = 17.22; Gender: female = 50.9%, male = 48.9%, nonbinary = 0.2%; Education: low = 35.4%, medium = 27.7%, high = 36.9%; Political orientation, measured on a scale from 0 = “extreme left” to 10 = “extreme right”: M = 5.01, SD = 1.95; median response time = 8.6 min). The survey was in field between April 28, 2023, to May 12, 2023. Analysis of variance (ANOVA) was conducted to investigate whether the allocation of participants regarding their age and political orientation was random across the four experimental groups, which was successful (Age: F (1, 800) = 0.529, p = .47; Political orientation: F (1, 800) = 0.648, p = .42). Pearson’s Chi-square tests were conducted to check randomization of genders, education, and recognition of Ursula von der Leyen across the experimental groups, which was also successful: (Gender: χ² (6, N = 802) = 6.496, p = .37; Education: χ² (18, N = 802) = 10.162, p = .93; Recognition: χ² (3, N = 802) = 5.418, p = .14).
Manipulation Checks
To investigate whether participants successfully recalled the central themes of the stimulus, we asked them about the extent to which they thought the post included the statements (a) “Ursula von der Leyen sees Christianity as a central aspect of Europe” and (b) “Ursula von der Leyen only welcomes Christian refugees from Ukraine” (1 = not at all; 7 = absolutely). We conducted OLS-based linear regressions with dummy coded variables (0 = “Authentic video”; 1 = “Fake conditions combined”) to check whether there was a difference between the authentic video and the manipulated video conditions. While this analysis and follow-up ANOVA revealed differences between the groups (see Appendix D for a detailed analysis report), the mean for the perceived presence of the statement “Ursula von der Leyen sees Christianity as a central aspect of Europe” is M ≥ 4.80 in all conditions, suggesting that participants registered the statement in all conditions. Regarding the second statement, that von der Leyen only welcomes Christian refugees from Ukraine, OLS-based linear regressions showed that participants who saw one of the manipulated videos (decontextualized [M = 3.60, SD = 2.14], cheapfake [M = 4.03, SD = 2.09] or deepfake [M = 4.22, SD = 2.05]) were significantly more convinced that the video entailed this statement than those who saw the authentic video (M = 2.31, SD = 1.65), β = 1.6287, t (800) = 9.945, p < .001. This means that the same disinformation was registered across the three disinformation conditions.
In addition, participants were asked at the end of the questionnaire to what extent they recognized the different elements of the post that were fabricated, specifically the accompanying text, the audio track, whether it was intercut with different footage or digitally manipulated (1 = Does not apply at all; 7 = Fully applicable). Overall, these fabrication checks indicated that participants recognized if a certain aspect of the video they saw was manipulated and also which one, showing that the manipulation of the different sophistication levels of visual disinformation was successful (see Appendix D).
Measures
All dependent variables were measured on 7-point Likert scales unless explicitly stated. The exact wording of all items can be found in Appendix E.
Perceived credibility of the stimulus was measured based on three items of message credibility by Appelman and Sundar (2016), asking participants about the extent to which they found the social media post “factually correct,” “authentic,” or “not believable,” which was reverse-coded. As the Cronbach’s alpha was questionable at α = .66, we performed stepwise item deletion, which revealed that the alpha would improve to α = .74 if the reverse-coded item “not believable” is removed. Thus, it is not included in the main analysis. Robustness checks, which can be found in Appendix E, show that the results remain stable even if the item is included (M = 3.29, SD = 1.66, r = .59; α = .74 after stepwise item deletion).
Misperceptions were measured through four incorrect statements regarding von der Leyen and the EU. Our focus was on the specific misperceptions that our stimulus could elicit. Therefore, we crafted false statements concerning the alleged double standards applied by the EU toward refugees from Ukraine (Deutsche Welle, 2022). Participants indicated the extent to which they considered these as accurate: “In the EU, church and politics are clearly separated” (M = 3.97, SD = 1.88; reverse-coded), “Most EU politicians oppose the admission of Muslim refugees” (M = 3.46, SD = 1.72), “Ursula von der Leyen is in favor of giving preference to Christian refugees in the EU” (M = 3.90, SD = 1.89) and “Refugees from Christian countries enjoy special benefits according to EU directives” (M = 3.41, SD = 1.81).
While it was indeed temporarily made easier for Ukrainian refugees to enter the EU without a visa, this allowance was not based on their Christian identity. Moreover, in February 2022, several media outlets reported on discrimination against POC escaping from Ukraine. However, such actions were never enacted by EU-officials (Deutsche Welle, 2022). Thus, the statements run counter to evidence provided by fact-checkers, and believing in them would constitute a misperception (Flynn et al., 2017). As they all tap into different dimensions—addressing either EU politicians in general, von der Leyen in particular, or general EU guidelines—each is treated as a separate measure.
Perceptions of Ursula von der Leyen were measured based on the semantic-differential candidate integrity scale as used by Boomgarden et al. (2016) (four items: fairness, honesty, friendliness, and corruptness; M = 3.80, SD = 1.75, α = .94).
The moderator, anti-immigration attitude, was measured with four items similar to Pellegrini et al. (2021), asking participants about the number of people that should be allowed to live in the EU (people of a different ethnic group or religion/people from poorer countries outside of Europe), and whether migrants culturally undermine/economically strengthen the EU (M = 4.36, SD = 1.44, α = .79).
Results
To map out the differences between the three experimental conditions and our control group, we rely on one-way ANOVA with Bonferroni-corrected pairwise mean score comparisons. Regarding our first set of hypotheses (H1a/b/c), the overall ANOVA revealed a significant main effect of the conditions, authentic video (M = 3.78, SD = 1.61), decontextualization (M = 3.36, SD = 1.55), cheapfake (M = 3.28, SD = 1.66), and deepfake (M = 2.37, SD = 1.69), on perceived credibility F (1, 800) = 39.6, p < .001, η² = .05. Post hoc comparisons show that participants who were exposed to a deepfake found this video to be significantly less credible compared to any of the other videos, namely the authentic video (p < .001; 95% CI [0.62, 1.48]; Cohen’s d = 0.63), the decontextualized video (p < .001; [0.21, 1.05]; Cohen’s d = 0.39) and the cheapfake (p = .01; [0.12, 0.98]; Cohen’s d = 0.32). Moreover, participants who saw the cheapfake perceived it as significantly less credible than the authentic video (p = .02; [0.06, 0.94]; Cohen’s d = 0.31), but not less credible than a decontextualized video (p = 1.00; [−0.34, 0.52], Cohen’s d = 0.05). Lastly, the decontextualized video was evaluated as less credible compared to the authentic video. While this difference is not statistically significant (p = .06; [−0.01, 0.84]), it constitutes a small effect (Cohen’s d = 0.26). Overall, these results partially support H1a, which stated that an authentic video is evaluated as more credible compared to a manipulated video. H1b—stating that a decontextualized video is evaluated as more credible compared to a cheapfake or deepfake—is partially supported. H1c—A cheapfake is evaluated as more credible compared to a deepfake—is supported. These results are visualized in Figure 3.
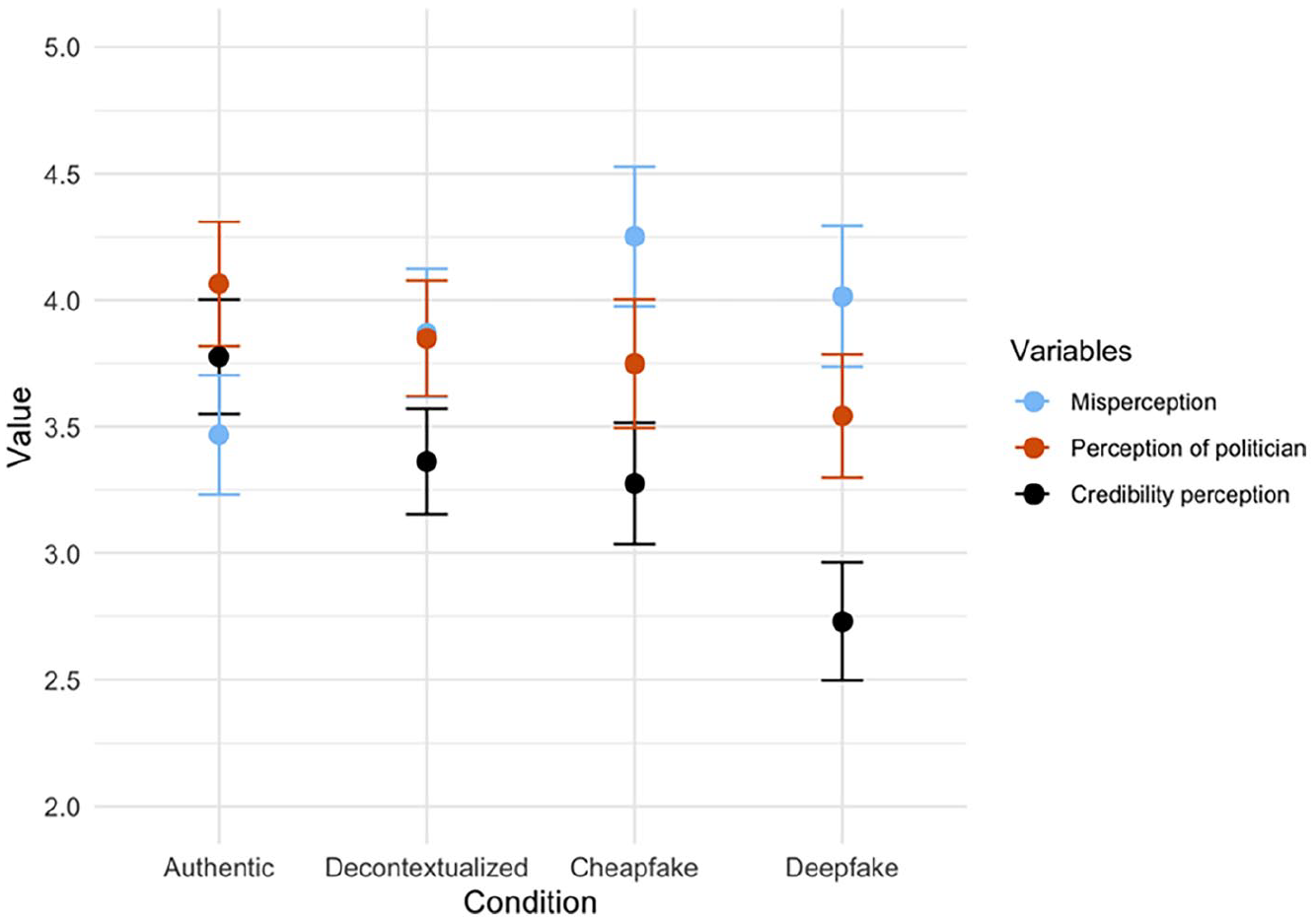
Combined Interval Plots for Perception-Related Variables.
To test the second hypothesis, whether anti-immigration attitudes moderated the effect on credibility evaluations, we conducted OLS-based linear regressions using dummy variables with the authentic/control condition serving as the reference group R² = .05, F (7, 794) = 6.57, p < .001. Contrary to our expectation, we did not find support for H2, which stated that evaluations of manipulated videos are moderated by issue agreement. Participants with stronger issue agreement did not show higher credibility evaluations of the visual disinformation (see regression tables in Appendix F, Tables 1–3).
RQ1 asked if there is a difference in the degree to which different forms of manipulated videos (decontextualization, cheapfake, deepfake) cause misperceptions. We did not find any significant differences regarding the following items: “In the EU, church and politics are clearly separated,” “Most EU politicians reject the admission of Muslim refugees,” “Refugees from Christian countries enjoy special advantages according to EU directives.” However, the analysis revealed a significant main effect of condition on misperceptions regarding Ursula von der Leyen, F (1, 800) = 11.33, p < .001, η² = .02. We followed up with a post-hoc test with Bonferroni correction, which showed that participants who were exposed to a deepfake (M = 4.01, SD = 2.00) believed more strongly that Ursula von der Leyen is in favor of giving preference to Christian refugees in the EU compared to participants who saw an authentic video (M = 3.47, SD = 1.68) (p < .001; 95% CI [−1.04, −0.05], Cohen’s d = −0.30). In addition, people who saw a cheapfake (M = 4.25, SD = 1.91) held a significantly stronger misperception than participants who saw an authentic video (p = .02; [−1.29, −0.28]; Cohen’s d = −0.44). While the misperception level is slightly higher in the cheapfake condition compared to the deepfake, this difference is not significant (p = 1.00; [−0.27, 0.74]; Cohen’s d = 0.12). Lastly, there are no significant differences between those who saw a decontextualized video (M = 3.87, SD = 1.88) and any of the other groups, as can be seen in Figure 3. Yet, the differences between the decontextualized video and the authentic video (Cohen’s d = −0.23) and the cheapfake (Cohen’s d = −0.20) constitute small effects.
RQ2 asked whether there is a difference in attitude toward the politician after stimulus exposure. Indeed, we found a significant main effect of condition on attitude toward von der Leyen, F (1, 800) = 9.231, p = .03, η² = .01. Post hoc comparisons revealed that participants who saw a deepfake of von der Leyen (M = 3.54, SD = 1.75) had significantly more negative attitudes toward her compared to those who saw an authentic video (M = 4.06, SD = 1.75; p = .02; 95% CI [0.06, 0.98]; Cohen’s d = 0.30), supporting H3. However, there were no significant differences in regard to those who saw a decontextualized video (M = 3.85, SD = 1.69) or cheapfake (M = 3.75, SD = 1.76) and any of the other conditions (see Figure 3).
Additional Analyses (Non-preregistered)
To contextualize our findings and enhance their interpretation, we conducted exploratory (nonpreregistered) analyses, detailed in Appendix A. Since we found no interaction between anti-immigration attitudes and credibility perceptions, we tested for interactions with our other dependent variables. Based on multiple regression analysis, we found no significant interaction with the misperception item, but a significant interaction emerged with deepfake exposure and attitudes toward von der Leyen (β = −.237, SE = 0.111, p = .033): participants with stronger anti-immigration attitudes evaluated her more negatively after viewing the deepfake. This suggests that while preexisting attitudes did not affect credibility or the misperception, they did reinforce negative judgments of her, as she was shown supporting Ukrainian refugees.
In addition, we conducted a mediation analysis (Hayes’ PROCESS Model 4, 5,000 bootstrap samples, 95% CI) testing credibility as a mediator for the misperception item across disinformation conditions versus the control group, to further examine the relationship between the two outcome variables. The results show no significant indirect effect: exposure to different forms of visual disinformation (vs. the control group) reduced credibility and increased misperceptions, but credibility does not mediate this effect. This hints at the possibility that these effects may arise independently of each other. The full details of our moderation and mediation analyses are reported in Appendix A.
Discussion
In an information environment characterized by elevated uncertainty about what is true and false, the proliferation of various types of deceptive visual content has sparked concerns about the state of an informed public (Peng et al., 2023). However, there was a lack of research regarding the distinct effects of different forms of visual disinformation. In this study, we show that different formats—decontextualization, cheapfake, and deepfake—affect citizens to differing degrees in terms of credibility perceptions (H1a/b/c), the misperceptions they elicit (RQ1), and regarding perceptions of the portrayed politician (RQ2, H3). Participants’ political attitudes did not moderate the effect on credibility perception (H2). While sophisticated deepfakes are evaluated as least credible, they led to a misperception regarding the portrayed politician and a more negative evaluation of her compared to an authentic video. Similarly, the rudimentary forgery of a cheapfake was evaluated as less credible than an authentic video but resulted in a higher level of misperception regarding the politicians’ viewpoint. Lastly, the simple decontextualization was regarded as equally credible as an authentic video and significantly more credible than a deepfake. However, it did not impact participants’ attitudes toward the politician or their misperceptions about them.
Our study contributes to political communication research by showing that visual disinformation (a) has distinct effects depending on the level of sophistication applied to its creation and (b) can contribute to a misperception and negative perceptions of political actors regardless of credibility perceptions.
First, our findings suggest a difference in the effects between formats that allow for the explicit presentation of falsehood through spoken words and pictures—cheapfakes and deepfakes—compared to decontextualization, which contains falsehood only in the accompanying written text (see Figure 1). The latter was perceived as more credible than a deepfake, slightly more credible than a cheapfake, and hardly distinguishable from our control condition in terms of perceived credibility. This finding aligns with previous studies that have shown authentic videos to be more credible than deepfakes (e.g., Dobber et al., 2021; Hameleers et al., 2023). It also corroborates research indicating that deepfakes have no additional credibility over textual disinformation (Barari et al., 2021; Hameleers et al., 2023). Additionally, malinformation—similar to decontextualization—has previously been found to be more credible than a deepfake (Hameleers et al., 2022). Moreover, unlike other experiments (Hameleers et al., 2022; Shin & Lee, 2022), we did not find any interaction effects with pre-existing attitudes on credibility perceptions. One possible reason for the lack of an interaction effect is statistical power. While we precisely simulated the main effect on credibility perceptions using prior research, no existing findings informed a simulation for the interaction effect. However, a G*Power analysis (ANOVA, four groups, including interactions, f = 0.15, 90% power) indicated that N = 634 would be sufficient to detect an effect. This suggests that the absence of significant findings may instead stem from the measure’s association with anti-Muslim attitudes (Kentmen-Cin & Erisen, 2017), while our stimulus focused on Christian refugees to avoid priming participants. As a result, our moderator captures general immigration attitudes but does not explicitly reflect feelings toward Ukrainian refugees, potentially explaining the null results. However, participants with stronger anti-immigration attitudes evaluated the politician more negatively after deepfake exposure. This suggests that while preexisting attitudes may not have made the visual disinformation more credible, they did amplify negative evaluations of the politician, thus reinforcing existing biases.
Second, we demonstrate that formats that can explicitly convey audio-visual falsehoods have the potential to induce a misperception about a claim directly reflected in the stimulus, even if they are not considered credible. Participants concluded that von der Leyen favors Christian refugees after seeing and hearing her make this statement, as enabled by the cheapfake and deepfake. The stimuli did not trigger misperceptions about the EU and its politicians, which is plausible when considering that the misperception item related to von der Leyen was the only one we directly manipulated. Participants in the deepfake condition also evaluated von der Leyen’s integrity more negatively, which is in line with experiments that found that deepfake exposure led to negative attitudes toward displayed politicians (Barari et al., 2021; Dan, 2025; Dobber et al., 2021) (see Figure 3). Importantly, these findings introduce a new perspective on how visual disinformation’s impact has been studied thus far. While the frequently employed realism heuristic (Sundar, 2008) is valuable for explaining the initial mental shortcut people use to assess the accuracy of information, our study reveals a second cognitive effect: the development of false beliefs and more negative attitudes based on manipulated audio-visuals unrelated to their credibility. We contend that this is connected to visuals’ distinct role in molding our memory even if the visual source is incorrect (Johnson et al., 1993). As such, hearing and seeing the words come out of von der Leyen’s mouth appears to have lingered in the memory of participants in such a way that it overruled their initial credibility judgment. In the case of the cheapfake, this was possible because of intercutting audio footage that explicitly references Ukraine. The AI-powered deepfake enabled us to change the lip movements entirely, offering even more potential for manipulation (Maras & Alexandrou, 2019). Thus, participants in these conditions had a different experience, which may have led to a different pattern of memory retrieval (Johnson et al., 1993). This finding aligns with previous research showing that even poorly crafted manipulations of photographs can result in misremembering (Nash, 2018). However, we acknowledge that our study is unable to identify the underlying mechanism responsible for this effect, and further research is needed to explore this in more detail. Our finding may be further explained when considering the sleeper effect, according to which individuals may initially not be persuaded by a noncredible message but forget about its inaccuracy later and only redeem its content (Kumkale & Albarracín, 2004). Our additional mediation analysis provides tentative evidence that credibility perceptions and misperceptions may arise independently: we did not find a mediating effect of credibility on the misperception item. Importantly, however, our cross-sectional study can only suggest this effect, and a longitudinal design is needed for definitive conclusions. We encourage future research to examine this effect over time, perhaps through a two-wave experiment with surveys spaced a week apart.
An important limitation to address is the measurement of misperceptions regarding Ursula von der Leyen with only one item which was somewhat similar to the manipulation check item, asking about her stance on refugees from Ukraine. To reduce bias, we placed this measure at the end of the survey and embedded it within a broader set of potential misperceptions. For example, participants might have falsely believed that Christian refugees receive special EU benefits. This approach aligns with previous studies (Stubenvoll & Matthes, 2022) and ensured we assessed actual false beliefs rather than simple recall of the stimulus content.
In addition, it is crucial to reflect on the nature and limitations of our stimulus material. While the disinformation conditions displayed the exact same false information in the accompanying text, they naturally differed on the visual level. This was a conscious choice, as the different forms of disinformation under investigation in this study—by definition—hold different manipulative qualities and were thus operationalized as such. The decontextualized condition uses only genuine imagery, heightening its message credibility. The cheapfake and deepfake, on the other hand, have the capacity to underpin the false claim in the video footage, perhaps at the expense of audio-visual quality. For instance, the voice differed in the deepfake, as it was spoken by a voice imitator, which may have impacted the low credibility perception. While the applied manipulations made both cheapfake and deepfake less credible—given that both do not look and sound exactly lifelike—they allowed for a visual processing of the false claim, which explains the adoption of a misperception. However, our study cannot determine what would have happened if both cheapfake and deepfake were of higher quality. Our deepfake was generated using an openly accessible app (Reface), resulting in a decent but not flawless outcome. Deepfakes crafted by skilled programmers or AI-artists tend to be much more convincing than the one we used (e.g., Hameleers et al., 2022; Jin et al., 2023; Weikmann et al., 2025). A high-quality deepfake could have increased their credibility and perhaps even heightened the elicitation of the misperception. Future research should explore this mechanism more closely, especially considering that the creation of AI-generated (audio-)visual disinformation is becoming increasingly easy and accessible (Böswald et al., 2022).
Moreover, the cheapfake and deepfake examples used in our study represent just a fraction of the various forms of visual disinformation that can be taken (Paris & Donovan, 2019; Weikmann & Lecheler, 2023a). We edited the cheapfake by intercutting it with audio from another interview, but other techniques, such as slowing down the video, are also possible. Future research should consider a fuller range of possible formats. Lastly, our stimulus is inherently limited by its specificity to a single context and the delivery by one female politician. Research indicates that citizens may be more susceptible to misinformation targeting women politicians, particularly in contexts where female leaders are subject to heightened scrutiny (Ahmed et al., 2025). Moreover, it is plausible that participants’ familiarity with the real controversy surrounding the discrimination of refugees from Ukraine played a significant role in shaping their perceptions. As such, our stimulus displayed a somewhat plausible scenario, given that it depicted a former Christian democrat expressing favoritism toward Christian refugees. We recommend that future research should diversify the topics and contexts under investigation.
Despite these limitations, our study underscores the critical importance of investigating visual disinformation in its multifaceted nature. Both its form and effects are complex, and the field of communication scholarship has only begun to explore ways of comprehending them. In addition, rapid technological advancements suggest that AI-generated visual disinformation may play an increasingly significant role in the future (Adami, 2024). Overall, given the ever-increasing significance of (audio-)visuals in the modern media landscape, it is crucial that mis- and disinformation scholarship understands visual disinformation as a manifold phenomenon that manifests in various forms, which yield distinct consequences.
Supplemental Material
sj-docx-1-jmq-10.1177_10776990251357299 – Supplemental material for Beyond Credibility: The Effects of Different Forms of Visual Disinformation
Supplemental material, sj-docx-1-jmq-10.1177_10776990251357299 for Beyond Credibility: The Effects of Different Forms of Visual Disinformation by Teresa Weikmann, Jana Laura Egelhofer and Sophie Lecheler in Journalism & Mass Communication Quarterly
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.