
Abstract
Background:
The identification of insulin sensitivity in glycemic modelling can be heavily obstructed by the presence of outlying data or unmodelled effects. The effect of data indicative of local mixing is especially problematic with models assuming rapid mixing of compartments. Methods such as manual removal of data and outlier detection methods have been used to improve parameter ID in these cases, but modelling data with more compartments is another potential approach.
Methods:
This research compares a mixing model with local depot site compartments with an existing, clinically validated insulin sensitivity test model. The Levenberg-Marquardt (LM) parameter identification method was implemented alongside a modified version (aLM) capable of operator-independent omission of outlier data in accordance with the 3 standard deviation rule. Three cases were tested: LM where data points suspected to be affected by incomplete mixing at the depot site were removed, aLM, and LM with the more complex mixing model.
Results:
While insulin parameters identified in the mixing model differed greatly from those in the DISST model, there were strong Spearman correlations of approximately 0.93 for the insulin sensitivity values identified across all 3 methods. The 2 models also showed comparable identification stability in insulin sensitivity estimation through a Monte Carlo analysis. However, the mixing model required modifications to the identification process to improve convergence, and still failed to converge to feasible parameters on 5 of the 212 trials.
Conclusions:
The mixing compartment model effectively captured the dynamics of mixing behavior, but with no significant improvement in insulin sensitivity identification.
Introduction
Model-based identification of insulin sensitivity can identify individuals at risk of developing type 2 diabetes. There are a range of modelling approaches, and many test protocols involving the injection of insulin and/or glucose boluses, and subsequent periodic venous or capillary blood sampling.1-4 Various insulin-glycemic models range in complexity. In general, simpler models with few compartments assume concentrations of insulin and glucose are uniform across some or all of the: local injection sites, plasma, the liver, and the interstitium.
Such models assume almost instantaneous mixing of glucose and insulin boluses throughout the plasma volume. The validity of these assumptions is challenged when the bolus results in high concentrations near the injection site over a prolonged length of time. This type of slow mixing can be revealed by data from a suitable sampling protocol.
In particular, if the model does not include mixing dynamics, data indicative of slow mixing is often considered an outlier during parameter identification. As most parameter identification algorithms use least squares objective functions,5-10 doubling apparent model error for a particular datapoint leads to quadruple the influence in the value of the objective function. Points with high model error due to unmodelled mixing dynamics can lead to inaccurate parameter identification.11,12 In cases where parameter identification may be ill posed, appropriate use of penalty functions and/or regularization methods may improve convergence.13,14
One method for dealing with unmodelled mixing behavior is to exclude sampling data for the 5 or 10 minute period following bolus administration as it can be assumed it takes this length of time for glucose and insulin boluses to adequately mix.2,15 Another method adapted the Gauss-Newton gradient-descent parameter identification method to limit the influence of outliers, 12 where subsequent comparison of identified insulin sensitivity estimates to a standard modelling approach showed it effectively captured model parameters typically obscured by unmodelled mixing dynamics.16,17 A third approach is to include an additional local mixing compartment in the model. Caumo et al. 18 showed increasing model compartments could lead to improved parameter identification.
These 3 strategies have never been compared directly. This analysis compares 3 implementations of the same Dynamic Insulin Sensitivity and Secretion Test (DISST) model: 2 (1) the DISST model with an added local mixing compartment, (2) The DISST model identified using the adapted Levenberg Marquardt method of Gray et al., 12 and (3) the DISST model but excluding data sampled immediately (up to 10 min) after the bolus injection. The implementations aim to improve model fit and insulin sensitivity identification through different means. Down-weighting statistical outliers and excluding post-bolus samples tends to remove data that represents the unmodelled mixing behavior to meet the assumptions of the simpler DISST model, whereas adding a local injection site compartment helps capture the post-bolus mixing which occurs on a shorter scale. The comparison of the methods helps determine whether the advantages of accounting for mixing are worth the increased complexity of the local mixing model.
Better models, which remain identifiable, would improve precision and thus increase the ability of such model-based tests to assess differences between cohorts, drug therapies, or other groups. Equally, better precision in identifying insulin sensitivity could further improve understanding of subject-specific metabolism and dynamics. The effect of mixing behavior following glucose or insulin administration has previously been researched with data from the intravenous glucose tolerance test (IVGTT). A two-compartment Minimal Model was used to explain the mechanisms behind assumptions of the single-compartment Minimal Model.1,18,19
Methods
Clinical Protocol
A dietary intervention that measured how dietary fiber affected the metabolic health of females at risk of developing type 2 diabetes yielded 218 DISST tests from 83 individuals. The outcomes of the trial were presented by Te Morenga et al.20,21 Tests were undertaken at weeks 0, 12, and 24. However, only 212 tests provided data suitable for modelling exercises because of participant dropping out from the study, hemolyzed samples or participant non-compliance with the study protocol.
The DISST protocol is described in Lotz et al.
2
The participants attended the clinic in the morning after fasting from 10 pm the night before. For the duration of the test, participants sat in a relaxed position. A cannula placed in their antecubital-fossa (large vein in the inner elbow). The cannula was used to administer glucose and insulin boluses, and draw blood samples. A three-way stopcock was used to ensure boluses were flushed through the cannula after administration to reduce the likelihood of high concentrations of insulin and glucose accumulating in local depots around the cannulation site. Ten grams of glucose (50% dextrose) were administered IV at 6 minutes, and a 1U bolus of insulin (Actrapid®) was administered IV at 16 minutes. Both boluses were numerically considered to occur instantaneously (although they occurred sequentially at the 6 minute time point), and thus were modelled as triangle functions over a period of ∆t
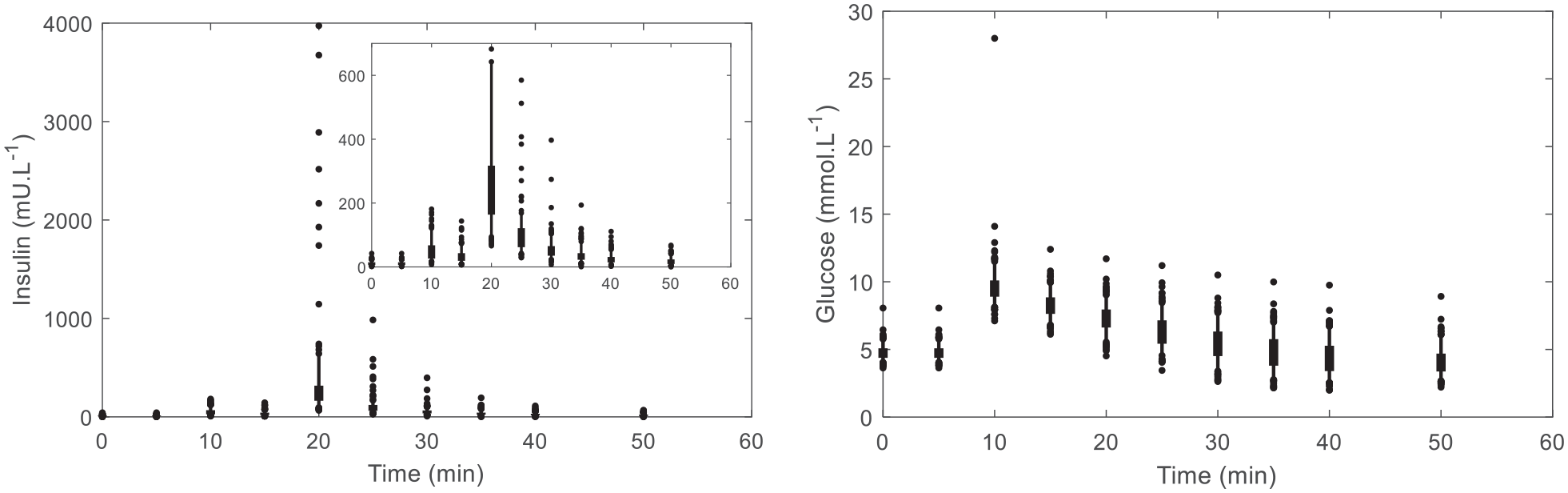
Population summary of insulin and glucose profiles. The thick error bars show the interquartile range, thin error bars show the 5th to 95th percentile range, and the dots show the outlying points. The child plot contained in the top right of the insulin graph crops the y-axis of the original graph to omit outlier samples.
DISST Model
The DISST model defines glucose, insulin and C-peptide kinetics. 2 C-peptide and insulin concentrations are modelled as two-compartment models, while glucose is modelled as a single compartment. These models are defined:
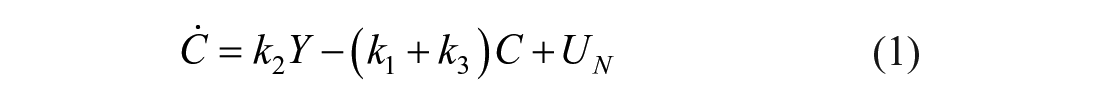

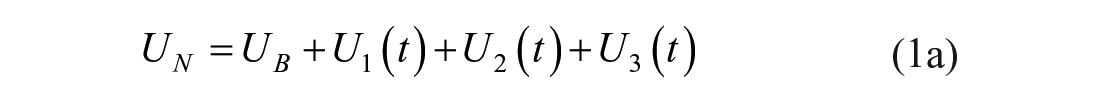

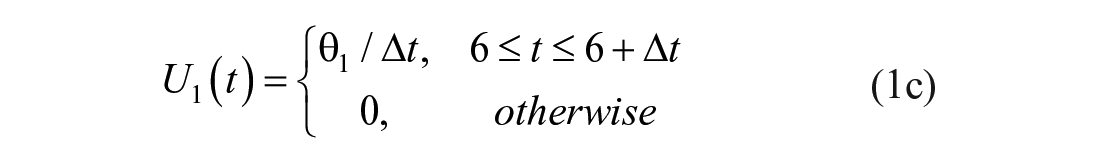
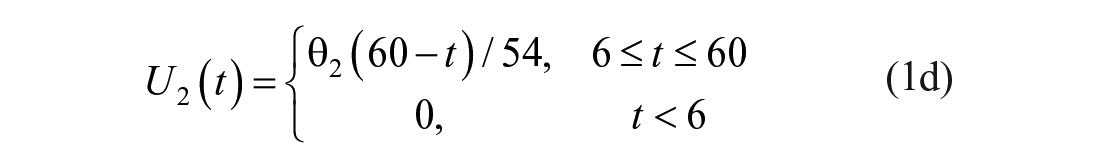
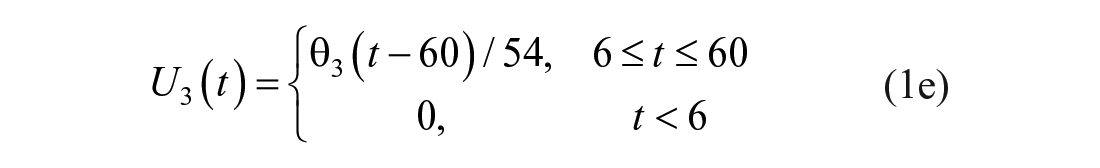
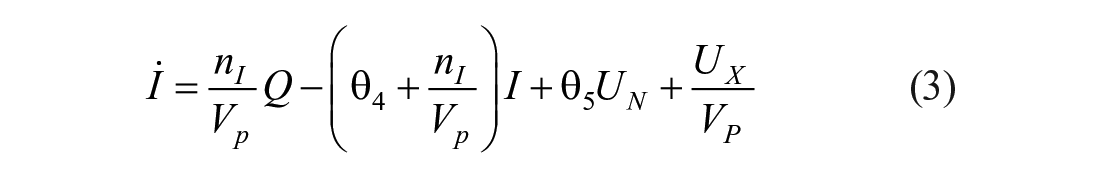
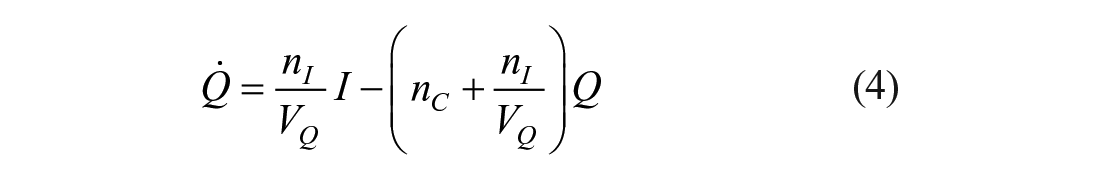
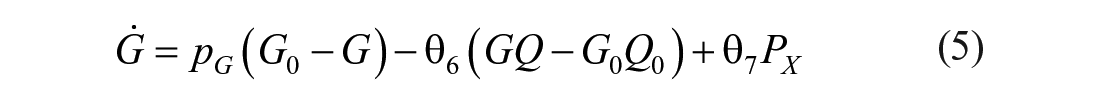
Mixing Model
The mixing model introduced in this paper adds additional (local) mixing compartments for the insulin and glucose concentrations to the DISST model, by modifying equations (3) –(5). The additional compartments aim to model non-instantaneous post-bolus mixing. The modifications to the model are:
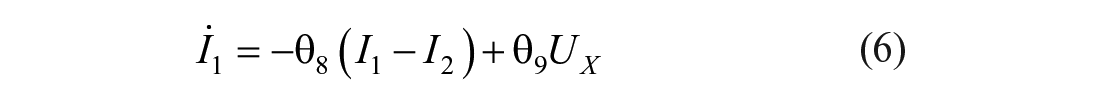
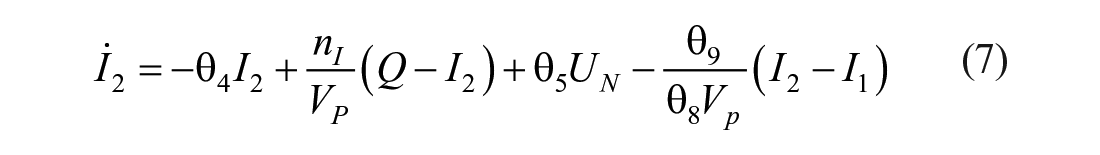
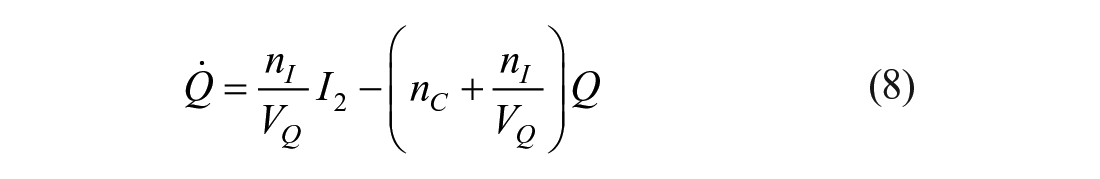
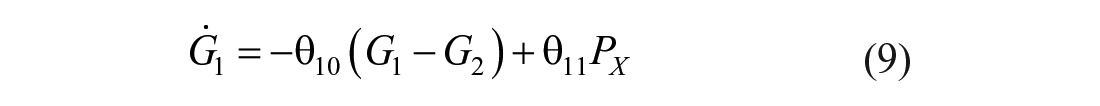
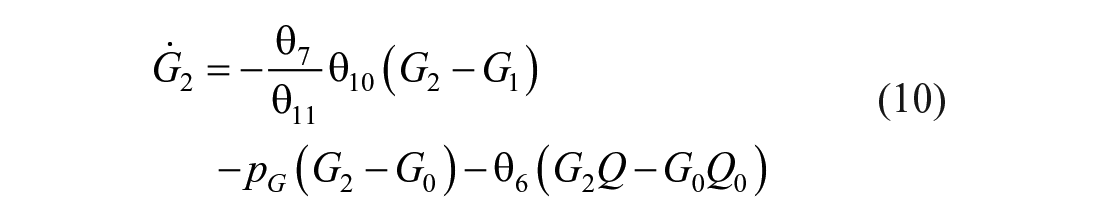
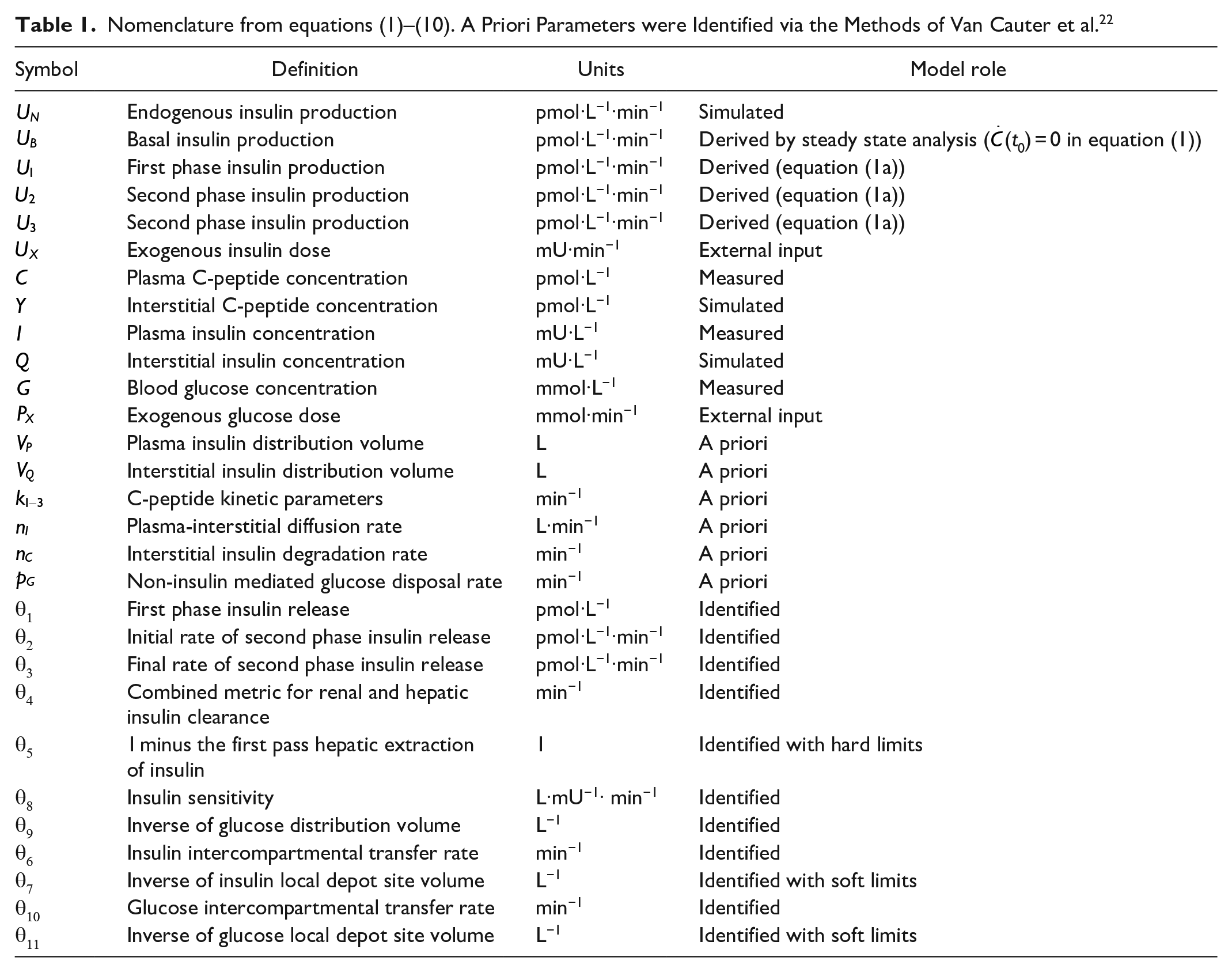
where: equation nomenclature is shown in Table 1.
Nomenclature from equations (1) –(10). A Priori Parameters were Identified via the Methods of Van Cauter et al. 22
Parameter Identification Methods
This analysis compares and contrasts the identified model values and residuals from 3 implementations of the DISST model identification. The first implementation uses the typical Levenberg-Marquardt identification method (LM) with a downsampled data set (DS). In this downsampled dataset, the insulin data point immediately after the insulin bolus is ignored during identification and the 2 glucose data points that occur immediately after the glucose bolus are also ignored during identification. The DISST model of equations (1)–(5) are used in this analysis.
The second method utilizes a simple LM method with the mixing model additions to the simple DISST model. In particular, equations (1) and (2), (6)–(10) are used for the mixing model analysis (LcM). In initial analysis, the model yielded parameter values indicative of practical non-identifiability. 23 These values are shown in Appendix A. The Differential Algebra for Identifiability of SYstems (DAISY) software tool 24 was used to establish that the model of equations (1) and (2), (6)–(10) was structurally identifiable.
During parameter identification, the
Finally, the adapted Levenberg Marquardt method (aLM) is used with the original DISST model of equations (1)–(5). The original Levenberg-Marquardt parameter identification approach iterates towards the optimal parameter set (
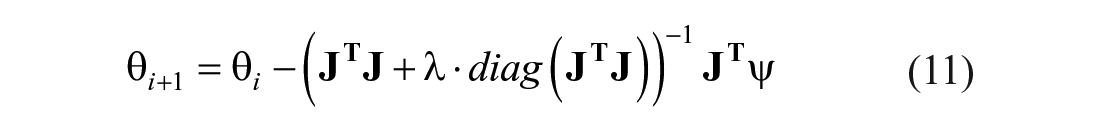
where:
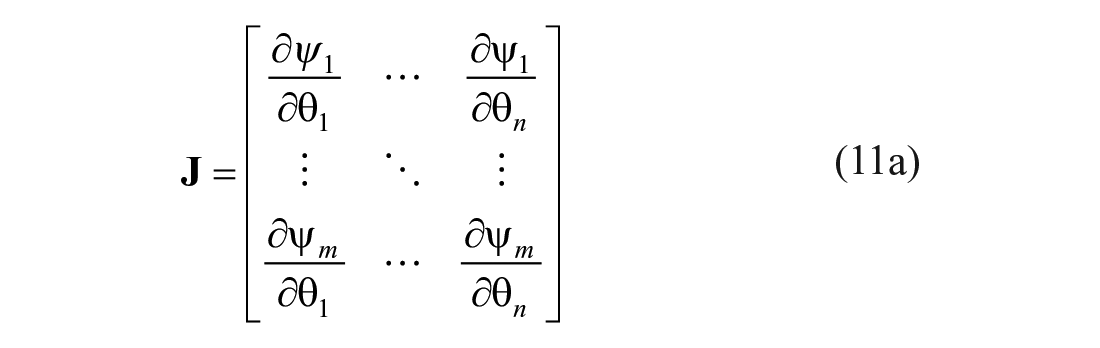
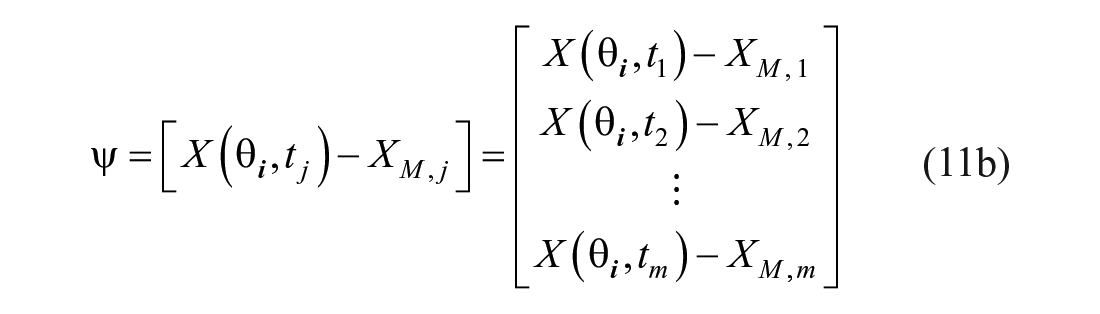
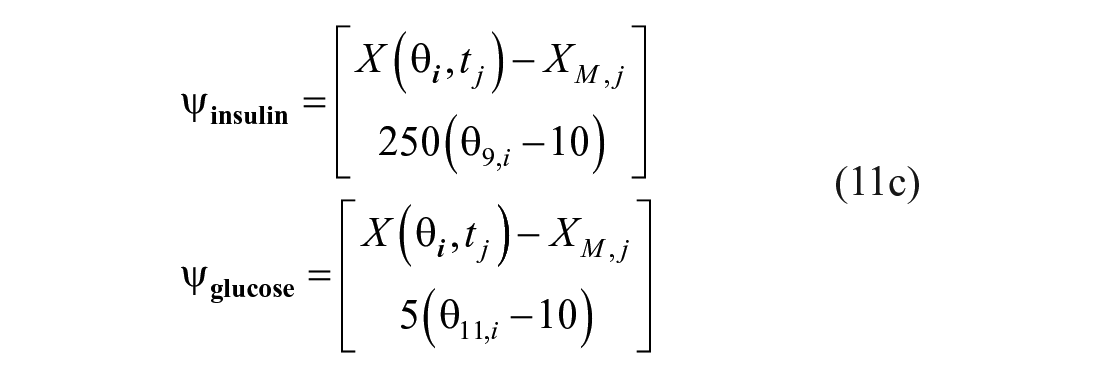
and
The aLM method was designed to dissipate the contribution of outlying data on the identification of
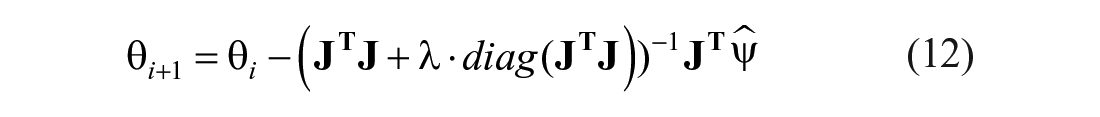
where:
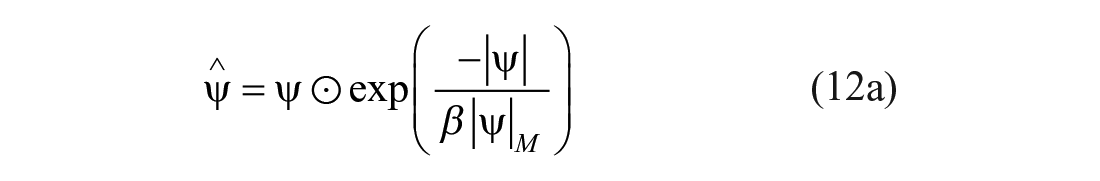
and
All implementations of the model were identified in segments.
Parameters
Parameters
Parameters
Analyses and Performance Evaluation
The 3 implementations are qualitatively compared using model residuals. Since each model optimises a different residual
For each model implementation, a Monte Carlo analysis 30 was performed on all trials as follows:
Measurements were simulated from the given trial’s identified parameter values.
Normally distributed relative error (
Model parameters were identified for each noisy dataset, yielding 100 parameter estimates.
The coefficient of variation (CV) for each parameter was calculated.
Summary statistics of the CV values from all 212 trials are presented. These values are indicative of practical parameter identifiability and stability for the given implementation.
Results
Correlations between the identified parameter values across the different model implementations are presented in Table 2. The aLM parameters and DS parameters correlated well. The LcM parameters did not correlate well with either the aLM or DS parameters, with the exception of the insulin sensitivity parameter
Summary Statistics of Parameter Correlations. Note the Common Parameters between the DISST and Mixing Models (

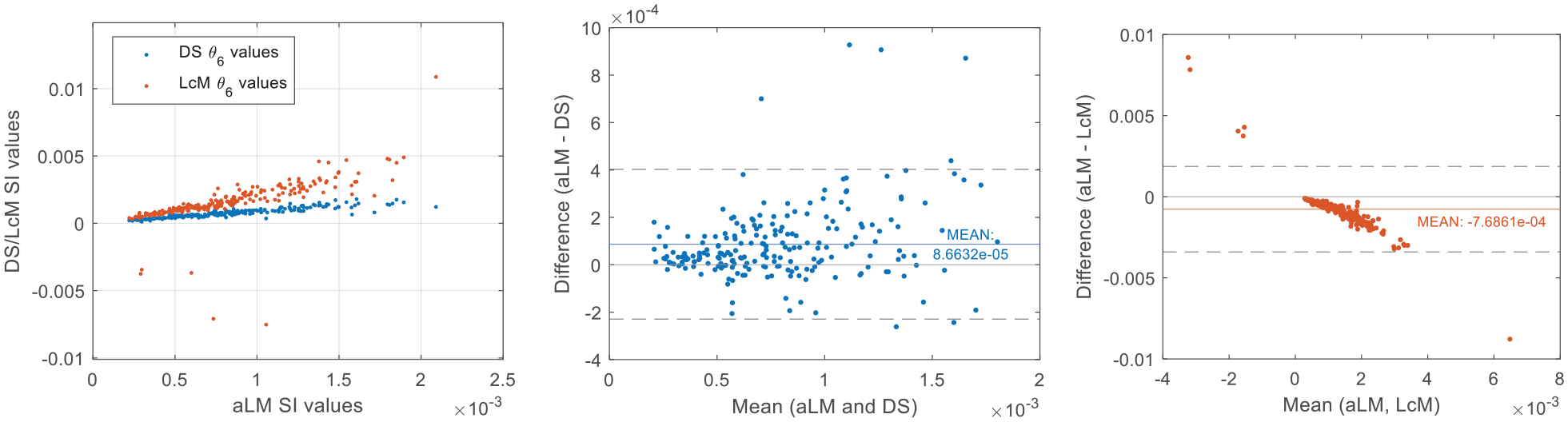
Comparison of insulin sensitivity (SI) values identified by each implementation and Bland Altman plots showing agreement across implementations.
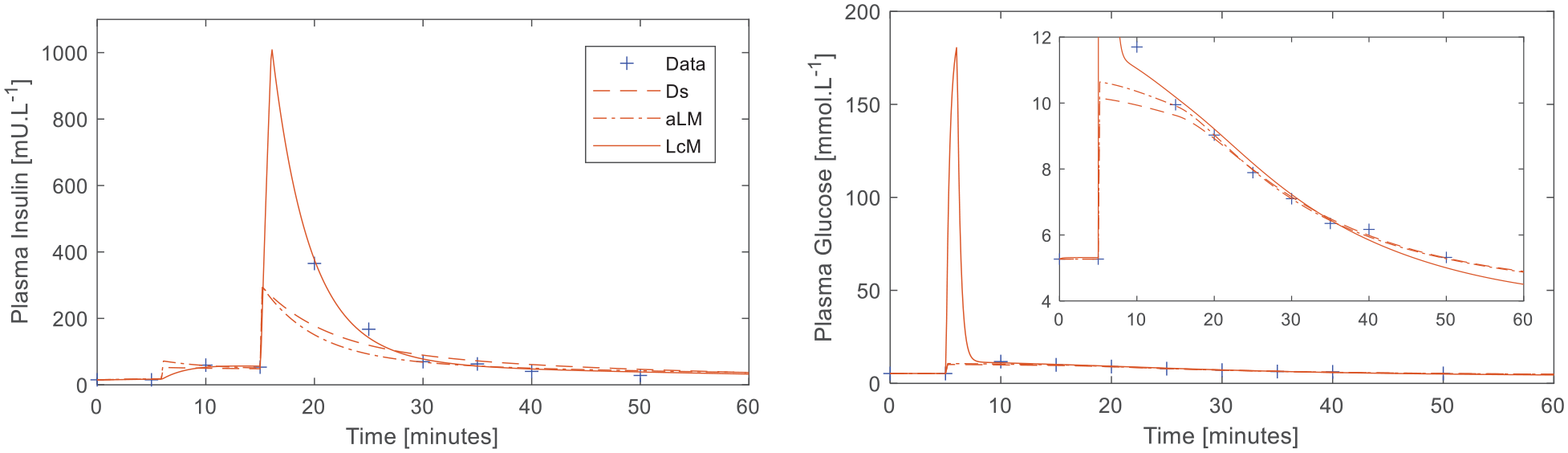
Plasma insulin and glucose responses to the DISST test with moderate outliers to the simple model in the insulin (t = 20, and 25 minutes) and glucose data (t = 10 minutes). Child plot displays parent plot with cropped y-axis for clarity.
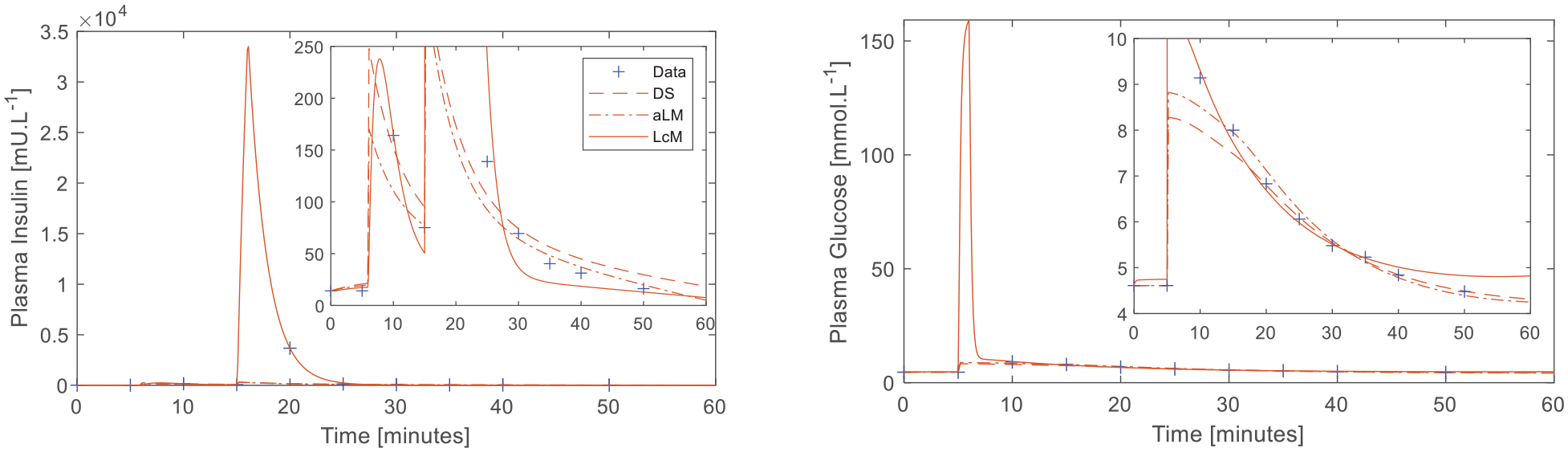
Plasma insulin and glucose responses to the DISST test with significant outliers in the insulin data and moderate outliers in the glucose data. The inset plots display parent plots with cropped y-axes for clarity.
Summary statistics of absolute residuals
Summary Statistics of Absolute Errors across All Trials. Note that the Errors in DS and aLM Include Errors for Full Dataset to Enable Direct Comparison.
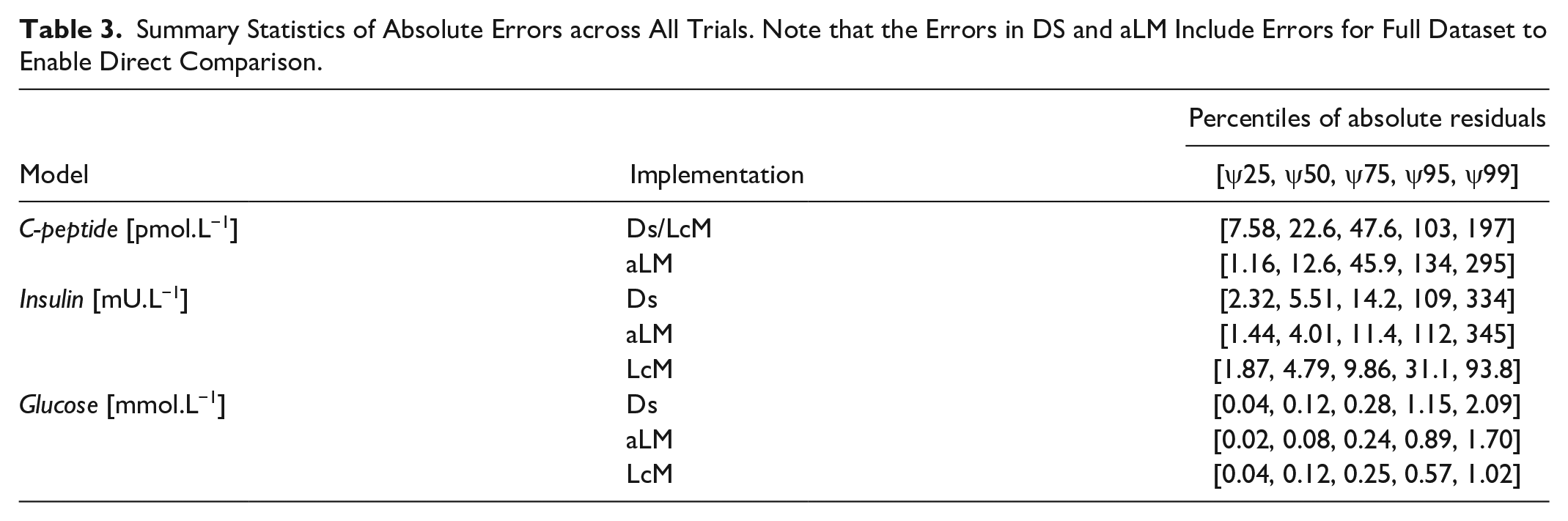
Figure 5 shows the distribution of the residuals. C-peptide samples are relatively well-centered about zero and follow a seemingly normal distribution across the samples. In contrast, both insulin and glucose residuals were sporadic showing biases during the mixing phases at t = 20 minutes for insulin, and t = 10 minutes for glucose. The LcM is well centered around the immediate post-bolus point for insulin, but exhibits bias at the surrounding samples. The glucose data are well centered with the LcM except for a small bias on the final sample.
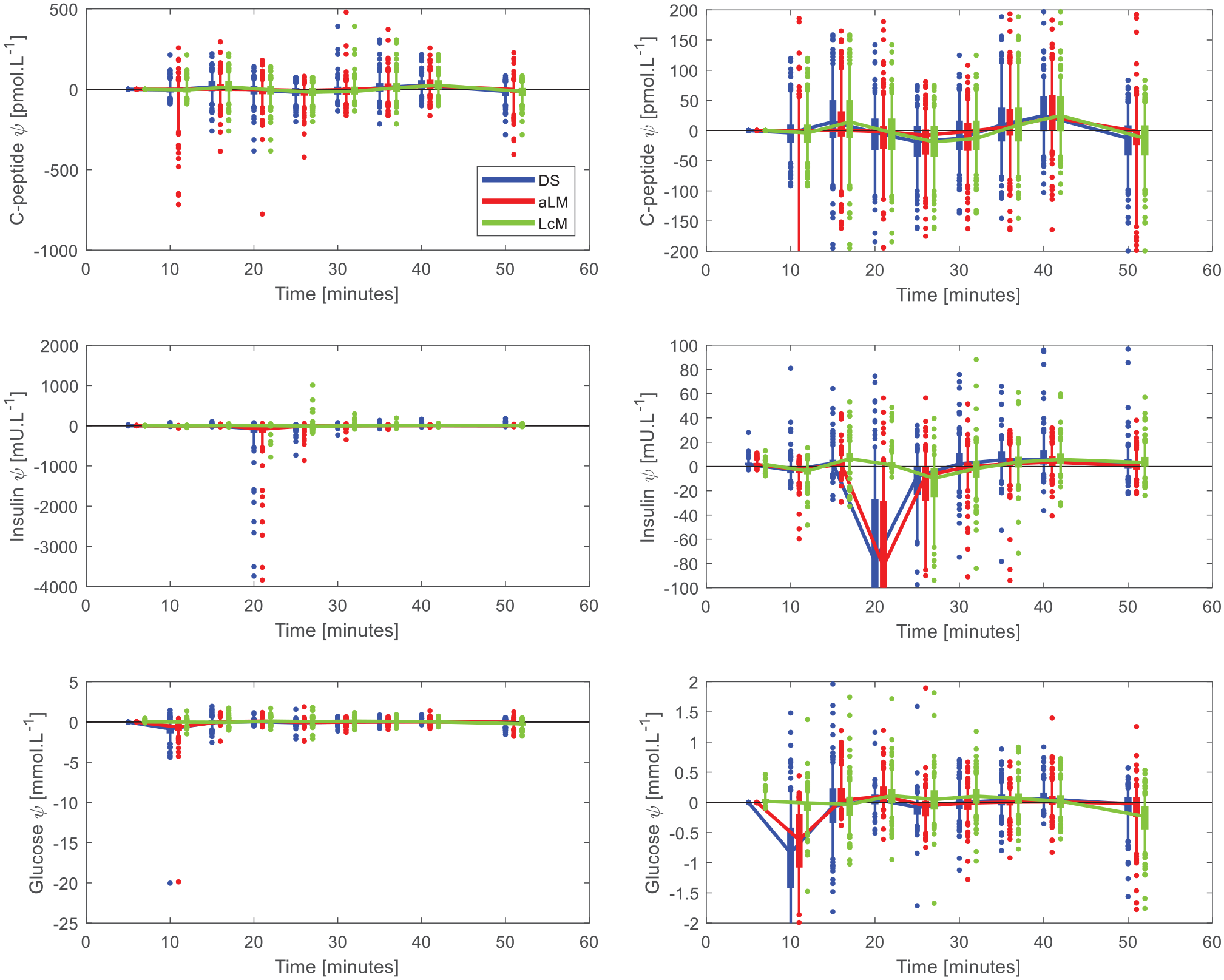
Residual plots for C-peptide, insulin, and glucose. The plots on the right are cropped to show the general behavior. The thick error rs show the interquartile range, thin error bars show the 5th to 95th percentile range, and the dots show the outlying points. The time points are offset for aLM and DS to enable clearer observation.
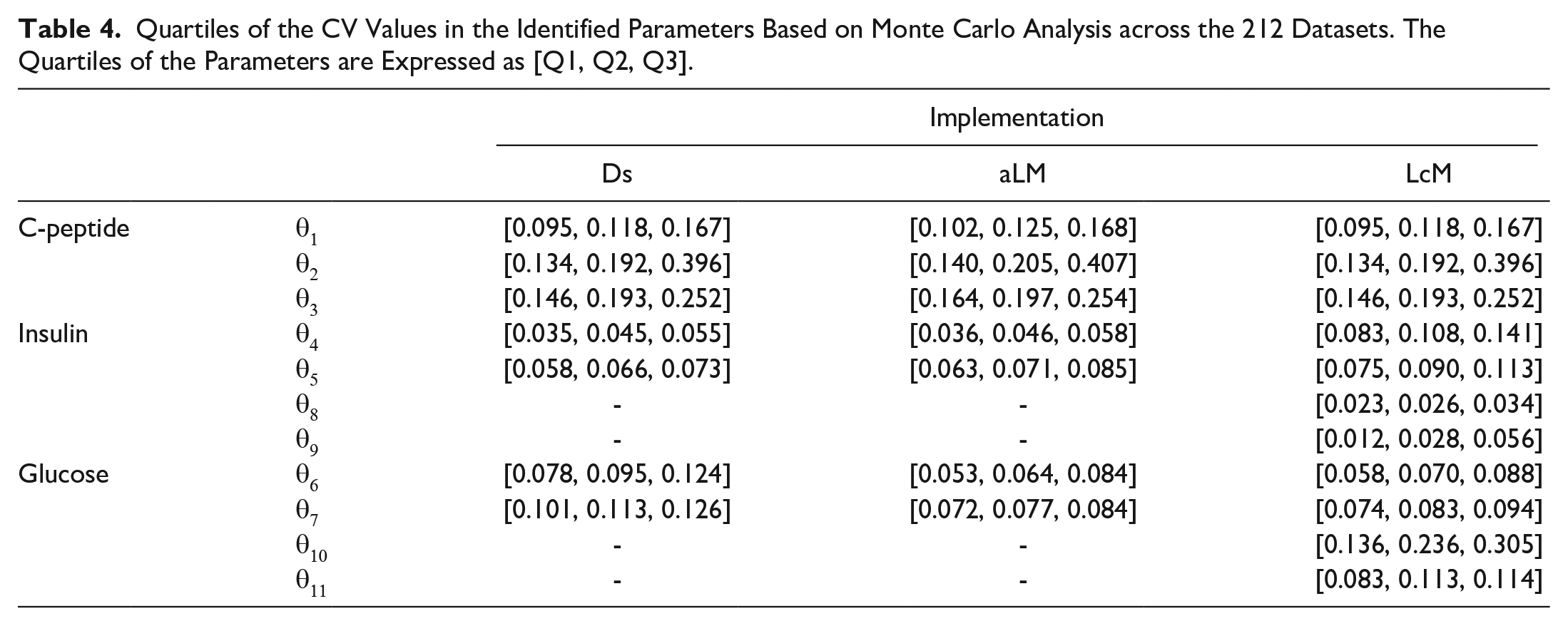
Finally, Table 4 summarizes the Monte Carlo analysis of the 3 implementations. The additional parameters introduced by the mixing model had relatively low CV values in the insulin model of equations (6)–(8), but high values for the glucose model of equations (9) and (10). For parameters comparable to the DISST model, the mixing model had increased CV values for insulin, relative to the DS and aLM implementations. The comparable glucose parameters identified by the mixing model had CV values slightly greater than aLM, but lower than DS.
Quartiles of the CV Values in the Identified Parameters Based on Monte Carlo Analysis across the 212 Datasets. The Quartiles of the Parameters are Expressed as [Q1, Q2, Q3].
Discussion
Figure 5 shows the LcM was able to capture the mixing behavior in glucose and insulin data. In particular, the residuals of the LcM for both insulin and glucose surrounding the bolus are smaller and less biased than those of DS and aLM. Both DS and aLM typically missed the post-bolus data points. However, this was the intended outcome of the DS implementation, and the aLM was specifically designed to miss such aberrant points.
In terms of model simulation, Figure 5 also shows the DS and aLM implementations performed in roughly the same way. This indicates the manual removal of isolated data points that are affected by unmodelled mixing yields proximal results to the aLM implementation. Since the aLM implementation is based on the statistically justified implementation of declaring data 3 standard deviations from the mean as outliers, the DS implementation may assume a similar justification by proxy of the parameter and residual outcomes.
Despite the relative homogeny of the test cohort, the DS and aLM implementations achieved high correlations (ρ ~0.9) between most parameters (Table 2). Of note, the LcM had lower correlations for most parameters except the insulin sensitivity term (
In particular, all implementations must conform to the data between t = 20 to 50 minutes with much the same modelled dynamics. The trend visible in Figure 2 indicates with an empirical scaling equation, such as a linear fit, the mixing model could identify the primary metric of interest in glycemic modelling1,31,34,35 despite its difference in insulin identification.
In the typical case shown in Figure 3, the LcM was able to capture the data affected by mixing dynamics as well as the other stages of the test. However, for the case shown in Figure 4, the large insulin outlier at approximately t = 20 minutes had a disproportionate effect on the model, and thus the simulation failed to fit the data appropriately after the mixing phase. The LcM residual plots in Figure 5 show the mixing model exhibits low error in the immediate post bolus data, but higher error for samples outside of mixing data time periods. This outcome indicates more cases fit the behavior shown in Figure 4, which is a less desirable result.
The residuals described in Table 3 also demonstrate the general agreement between DS and aLM, although there are some minor differences. For insulin, aLM exhibited a larger range between residual percentiles then DS, indicating further outlier down-weighting occurred for samples other than the t = 20 minute sample. Glucose residuals for aLM were lower than DS across all percentiles, which indicates un-modelled mixing behaviour in glucose is not always outlying for both the t = 10 and t = 15 minute samples. The mixing model’s ability to capture mixing behavior was demonstrated through the relatively low LcM residuals in the higher percentiles.
Table 4 shows the DS and aLM identified insulin model parameters with approximately half the variance as the LcM. This difference quantifies the risk of increased parameter trade off with increased parameterization.
36
In contrast, the glucose model parameters show an almost reversed trend, where the LcM had similar CV values for insulin sensitivity and volume (
The contrast between these results can be explained with the difference in the nature of the outliers in insulin and glucose. The mixing points in insulin are much greater relative to the surrounding points, exhibiting strong mixing behavior captured by the mixing terms in the LcM. However, the mixing dynamics added can overtly influence the identification and miss the insulin dynamics contained in later samples. This trade off led to poor parameter stability for
The comparable stability of
This study modified the adapted GN algorithm of Gray et al. 12 to include the more sophisticated Levenberg-Marquardt algorithm. While the DS and aLM methods were stable with the GN and adapted GN algorithms, respectively, the more complex LcM was susceptible to instability due to its higher dimensionality and more extreme behavior in capturing mixing. Hence, the Levenberg Marquardt algorithm was used as a basis for all implementations to allow more consistent and comparable results.
In addition, further adjustments were required to ensure the mixing model obtained results in a feasible parameter region. These adjustments necessitated the use of a penalty function to restrict the mixing volume parameters and a boundary to prevent
The foundational DISST model assumes first order hepatic clearance of glucose2,38 and also defines the more complex insulin/glucose dynamic as a secondary glucose clearance pathway. Other models contain further complexity. However, the complexity of these models are not well suited to the low sampling frequency of the DISST protocol.23,39
It should also be noted this LcM implementation was phenomenological, rather than explicitly mechanistic. Complex physiological mixing mechanisms were simplified into a local mixing compartment with a diffusion-driven mixing rate. With the limited data available from the DISST tests, this phenomenological explanation for mixing behavior can mitigate the risk of over-parameterization and also yields a stable insulin sensitivity (
There is some difficulty comparing LcM results with those of the simple DISST model implementations. While agreement between the down-sampled and adapted methods indicates consistency with the estimation of insulin sensitivity, the values obtained may not accurately reflect those obtained through an alternate testing protocol, such as the hyper-physiological, gold-standard hyperinsulinemic-euglycemic clamp. However, the agreement between the DISST model and mixing model in insulin sensitivity estimation shows sufficient agreement of methods to determine the relevance of modelling mixing behavior, despite the lack of a reference model.
Overall, modelling data exhibiting mixing behavior in the DISST model and method does not provide significant benefits. While there is a potential for improved robustness in identification of insulin sensitivity, there are drawbacks in model implementation due to increased model complexity. This analysis was also undertaken on the 50 minute DISST, which is more intensive than the more recent and equally accurate 30 minute DISST protocol.40,41 The 30 minute DISST would not have sufficient post-bolus data to enable identification of mixing parameters without significant reliance on a-priori information.
Furthermore, the LcM presented in this research requires further direct comparison and adjustment with respect to a well-established metric, such as the hyperinsulinemic-euglycemic clamp technique, for results to be considered reliable for clinical use. Unless such a study is conducted, the foundation DISST model presented in equations (1)–(5) remains a strong candidate for use due to its relative ease of implementation and robustness, provided an appropriate method is used to handle outlier data influenced by mixing.
Conclusions
This analysis compares the performance of a mixing model with a simpler model, where outliers were either manually removed or detected with an adapted LM method. These methods were tested on noisy data containing varying levels of mixing behavior. The mixing model effectively captured mixing behavior and showed consistency in identifying insulin sensitivity at the cost of increased calibration and complexity in the parameter identification process. While a mixing model could potentially identify some glucose metabolism parameters more accurately while also capturing mixing behavior, the foundation DISST model with an outlier handling process achieves greater consistency at a lower operational cost, and sufficiently captures behavior outside of the outlier points.
Overall, this analysis showed data affected by mixing in intravenous metabolic tests, or similar clinical tests, can be modelled through a mixing compartment model. However, this more complex implementation currently offers minimal benefit over a simpler model with outlier detection. This paper demonstrates the merit of adding mixing compartments to the existing DISST model is primarily in capturing the dynamics of mixing behavior, rather than significantly improving the identification of clinically important parameters. In the context of the DISST, this justifies removal of data in the immediate period after the boluses, though it is worth noting that other models based on tests with less sparse sampling protocols could benefit from the implementation of a local mixing compartment.
Footnotes
Appendix A
Figures A1 and A2 show the parameters identified across the 212 trials with and without constraints on the L-M method. Parameters are ranked from lowest to highest to give a general indication of parameter spread. One trial failed to converge in the unconstrained process due to numerical instability.
Acknowledgements
None
Abbreviations
aLM, adapted Levenberg Marquardt; CV, Coefficient of variation; DAISY, Differential Algebra for Identifiability of SYstems; DISST, Dynamic Insulin Sensitivity and Secretion Test; DS, downsampled; IVGTT, intravenous glucose tolerance test; LcM, Local mixing; LM, Levenberg-Marquardt.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.