
Abstract
In the future artificial intelligence (AI) will have the potential to improve outcomes diabetes care. With the creation of new sensors for physiological monitoring sensors and the introduction of smart insulin pens, novel data relationships based on personal phenotypic and genotypic information will lead to selections of tailored, effective therapies that will transform health care. However, decision-making processes based exclusively on quantitative metrics that ignore qualitative factors could create a quantitative fallacy. Difficult to quantify inputs into AI-based therapeutic decision-making processes include empathy, compassion, experience, and unconscious bias. Failure to consider these “softer” variables could lead to important errors. In other words, that which is not quantified about human health and behavior is still part of the calculus for determining therapeutic interventions.
Keywords
Torture the data and it will confess to anything.
Successful Diabetes Treatment Needs Data
Discussion on use of artificial intelligence (AI) and health specifically is ubiquitous in the medical and lay press reflecting the perception that it has enormous potential to reduce the personal and global burden of many long-term medical conditions. Currently diabetes appears to be the poster child for the application of AI in health care for a number of reasons. 1
Worldwide, the number of adults and children developing diabetes continues to rise in parallel with global access to smartphone technologies.
On a daily basis, personal data from people living with diabetes are continuously created and logged.
Although the main variable of interest is glucose, with the rise in consumer tracking technologies, glucose data are being supplemented with additional information related to nutrition, physical activity, and sleep.
With the increasing availability of additional sensor technologies for physiological monitoring including smart insulin pens, social media, and records of internet searches, the diabetes data pool will continue to grow.2,3 Moreover, other data-generating comorbidities (eg, hypertension and cardiac arrhythmias) plus information from screening tests for complications (eg, retinopathy) are also adding to this “big data” resource.
The anticipated value from this torrent of data is that it can be analyzed and converted into patterns leading to actionable information, that is, a clear opportunity for AI. 4 For clinicians and people with diabetes, examples of actionable information are early prediction of severe hypoglycemia not just in those with hypoglycemia unawareness or the most opportune time for insulin initiation and optimization in type 2 diabetes. Existing large population data sets have already been used to predict the onset of type 2 diabetes, which appear to have better prediction performance than classical diabetes risk prediction algorithms. 5 The use of AI to analyze big datasets comprised of many data streams (not all of which are human sensor data and may be behavioral or geographic in origin) is already becoming a reality. 6 It is important to note that this type of big data is not analyzed as if it is presented on a very large spreadsheet because this type of data is often unstructured (eg, pictures, phone messages, video, email, and text messages) and not amenable to capture, storage, and management by commonly used software tools—analyses of big data typically require distributed computation over a cluster of computers.7,8 The process of assembling a highly detailed set of phenotypic and genotypic data to obtain the most appropriate treatment for individuals with a specific combination of traits is the basis of precision medicine. 9 There is a growing belief that novel data relationships based on phenotypic and genotypic information will lead to powerful predictions and accurate selections of tailored therapies that will transform health care in a very positive way. The diabetes clinic of the future is likely to be unrecognizable from its current format. 10 The anticipated promise from the triumvirate of (1) the internet of medical things, (2) big data, and (3) AI analyzed by way of cloud computing is being welcomed as necessary, inevitable, and beneficial. 11 However, this paradigm may turn out instead to be a modern-day “quantitative fallacy."
Quantitative Fallacies
A quantitative fallacy refers to a flawed decision-making process that is based exclusively on quantitative metrics and that ignores qualitative factors. The most well-known example is the eponymous McNamara Fallacy, named after the US Secretary of Defense during the Vietnam War and summarized as “if it cannot be measured, it is not important.” 12 The genesis of a quantitative fallacy requires four erroneous steps 13 (Table 1).
Four Steps for Creating a Quantitative Fallacy.

In health care, most previous examples of this flawed type of decision process have been based on the mistaken belief that all of clinical practice can be quantified. 14 In consideration of big data analytics and AI in diabetes care difficult to quantify inputs into the therapeutic decision making processes include empathy, compassion, understanding, previous experiences, and unconscious bias. 15 Failure to consider these so-called “softer” variables could lead to important errors in AI when used to solve clinical problems. In other words, that which is not quantified about human health and behavior is still part of the calculus for determining therapeutic interventions. For example, continuous care by the same doctor over time is associated with greater patient satisfaction, improved health promotion, increased adherence to medication, reduced hospital use, and a reduced risk of premature death. 16 The reasons for this beneficial effects of care from the same clinician over time are likely to be multifactorial, but it is also noteworthy that doctors tend to overestimate their effectiveness when consulting with patients they do not know, and underestimate their effectiveness when consulting with patients they know. 17 It remains to be determined whether the same correlation applies to AI-delivered care in the future.
Data Sources: Quantitative and Qualitative
Sources of big data for diabetes include both (1) structured data from electronic health records, population registries, clinical trials, biometric data from an increasingly wide array of physiological and geospatial sensors, as well as (2) unstructured data, from medical images, photos, audio and video recordings, social media content, and consumer search data based on information collated with a smartphone. The diversity of these health care data sources can create methodological challenges for data integration. To date, big data analytics, machine learning, and AI are in their infancies with respect to providing software-generated decision support, but over time these sources of therapeutic recommendations are likely to become increasingly embedded into the health care system. As discussed earlier, unwavering adherence to the mantra of an artificial intelligence “solution” for diabetes care based solely on big data analytics (ie, use of software that learns from patterns in the data) has the potential to create a digital diabetes fallacy if there is sole reliance on the measurable. In addition, there are many methodological challenges to creating useful quantitative datasets, including (1) ensuring data quality especially from electronic health record sources, (2) maintaining data consistency, and (3) standardizing outcomes data from clinical trials. Moreover, the process of clinical decision making is invariably not recorded. 18 Therefore, it is important to consider qualitative factors for affecting decision-making algorithms, which are, at present, difficult to capture but important for diabetes care (Table 2).
Difficult to Quantify Factors That Can Potentially Influence Artificial Intelligence Algorithms.

Low-Quality Quantitative Data
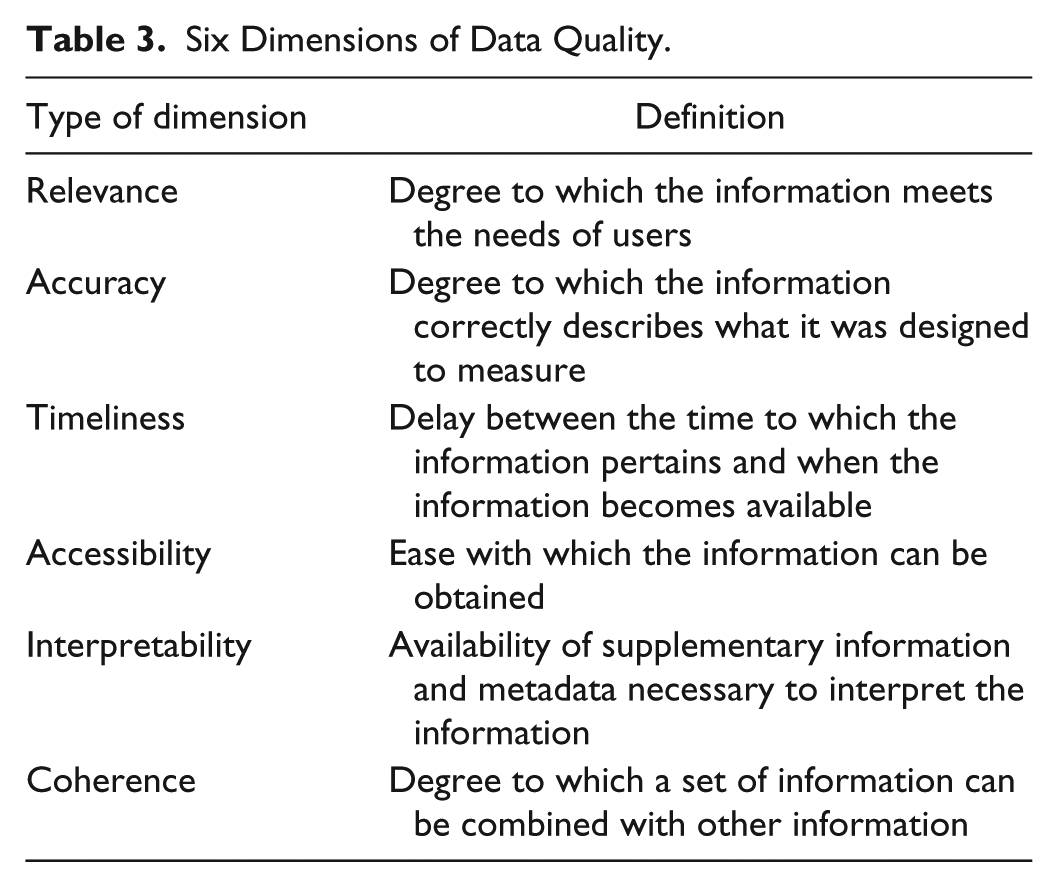
Quantitative biomedical data can be classified according to its quality. Medical decisions based on artificial intelligence depend on the quality of the inputted data—in other words, poor quality of quantitative data can lead to poor decision making. A recent review of the health care quality literature generated 96 terms used to describe data quality concepts. 19 The six most widely recognized dimensions of biomedical data quality are presented in Table 3. 20
Six Dimensions of Data Quality.
The potential limiting factors of big data have been summarized into four features known as the four Vs: volume, velocity, variety, and veracity. 21 Limitations in these areas can lead to misinterpretation of data sources. For example, the hype created at the onset of the digital revolution suggested that real-world data from individuals based on their online activities including social media could supplant traditional approaches to public health. It was suggested that identification of an influenza epidemic or an adverse drug effect could be determined by counting web searches of related topics. This proved to be incorrect as a standalone method; however, this approach can provide useful supplemental information.22-25 In day-to-day clinical practice, patient-generated data are invariably unstructured and highly context-dependent, and the impact of illness on an individual’s behavior and cognitive processing has been underappreciated. 26 Going forward, it will be necessary to find a way to combine quantitative data from traditional health systems with qualitative patient-generated data.
The use of big data analytics to form conclusions can also contain risks of mishandling of the data or inadequate high-quality data to form robust conclusions. Fallacies in the generation of quantitative data from research design, sampling, and instrumentation, statistical analysis, and interpretation can result in unrecognized knowledge gaps27,28 (Table 4).
Potential Risks of Gaps in the Analysis of Quantitative Data.

Mishandling of data also relates to information privacy. A successful doctor-patient relationship is based on the medical practitioner’s ability to keep information confidential—trustworthiness. For AI data are increasingly being deidentified, which works at a population level, but for personalized decision support other safeguards are necessary to protect privacy. 35
Language
For any AI system to work efficiently and effectively, it will need to understand the nuances of the language of health care from the perspective of people with diabetes and not simply the jargon favored by clinicians. 36 Potential confusion could arise with homophones (words that sound the same, but which have different meanings and spellings, such as cabbage and CABG) and homographs (words that are spelled the same, but have different meanings. For example, one man’s emergency department (ED) is another’s erectile dysfunction, and a verbal order for K therapy in the emergency department can result in administration of either potassium or vitamin K). Within a single language, there are also dialectal differences—what would an AI system make of the common Scottish vernacular use of “bampots,” “bevvies,” and “bairns,” or the use of a “stookey” for a broken arm? There is already abundant evidence that many patients encounter barriers to understanding health related information, and that materials and other content created by clinicians often fail in terms of understandability.37,38 Language barriers can also contribute to health disparities. US Latino diabetes patients with decreased English language skills have been shown to be at increased risk of poor glycemic control, however this risk is not present when care is delivered by physicians who speak Spanish. 39 It is also worth noting that AI development itself has highlighted the underrecognized clinical challenge of patients’ and doctors’ different understanding of what is being said. 40 If technology companies are to create useful AI systems, then they will need to access language from a variety of sources. These will include handwritten notes, letters, and emails (ie, medical records), and presumably (and controversially) they will also listen directly to patients talking with their clinicians. 41
Race and Ethnicity
To be ultimately successful, AI requires evidence from clinical trials. In the United States, racial/ethnic minority populations are disproportionately affected by diabetes and the associated complications. 42 However, despite the discriminatory nature of diabetes being self-evident, minority participation in technological interventions such as artificial pancreas development in type 1 diabetes and trials of new therapeutic agents in type 2 diabetes has been consistently low.43,44 Failure to recruit adequate numbers of minorities in clinical trials results in (1) poor trial validity, (2) poor generalizability of the results, (3) magnification of inequalities, and (4) concern about failure to detect harm in certain populations. Structured interventions, tailored to ethnic minority groups by integrating elements of culture, language, religion, and health literacy skills, have demonstrated that these measures can produce a positive impact on a range of patient-important outcomes for individuals with diabetes. 45 Similarly, a review of 34 randomized trials testing culturally tailored interventions to prevent diabetes in minority populations noted that culturally tailored interventions were effective in improving risk factors for progression to diabetes among ethnic minority groups. 46 There is also evidence that the differences in diabetes beliefs (between low- and high-education African American, American Indian, and white older adults) are due to socioeconomic conditions. 47 Translating culturally focused education programs that, in addition, take into consideration changing socioeconomic circumstances are not easily amenable to being generated by computers simply using quantitative data.
Conclusion
Big data and artificial intelligence will be useful tools for treating diabetes in a precision medicine or precision public health paradigm. The nature of the analytic tools to process diverse large datasets is to only use quantitative data. At this time, there are many flaws with total dependence on quantitative data, based on the frequent inadequate quality of this type of data as well on the frequent need to supplement a quantitative approach with a qualitative approach. Going forward, the conversion of unstructured data into digital-processible data is the domain of cognitive computing that is likely to add significant value to AI. 48 Factors besides objective data also go into clinical decision making, such as sentiment, intuition, and a physician’s experience, which have been referred to as judgment or a “gut feeling." Cognitive computing is currently ill equipped to duplicate this subjective part of reaching medical conclusions. 49 There remains a need for human physicians to treat diabetes and other diseases to provide judgment, compassion, and context, which will not be available from computers for the foreseeable future.
Footnotes
Abbreviations
AI, artificial intelligence; ED, emergency department.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.