
Abstract
Do parties target individuals or groups? Although this question is fundamental to understanding clientelism, the literature does not offer an answer. This paper argues that, depending on certain conditions, brokers target individuals when they are identifiable, and groups when brokers need to rely on the spillover effects of clientelism. Both identifiability and spillovers depend on individual poverty, group poverty, and political competition. Though the theory I outline focuses on targeting, I also argue that structural factors, such as the density of the poor, should be considered in the vote-buying literature. Structural factors are one of the few observables upon which brokers can base their decision regarding investing in clientelism. Using survey and census data from Brazil, the paper exploits variations in personal incomes within contexts of differing levels of municipal poverty. I find that political parties engage in segmented or ad-hoc strategies, targeting individuals when identifiability is high, and groups when there are economies of scale. Importantly, non-poor individuals can also be offered clientelism.
There is no agreement on when, how, and why parties choose to aim clientelist practices at individuals or groups. 1 The distributive politics and vote-buying literatures have traditionally pursued one of two approaches. The former has mostly focused on group targeting, usually districts or provinces (Dixit and Londregan 1996; Khemani 2015; and Calvo and Murillo 2004), showing that incumbent parties deliver public-sector jobs or construction projects contingent on the support of groups of people. The latter has typically focused on individuals and their characteristics, such as their socio-economic or electoral profiles. Substantively, however, it is not clear when or why clientelist brokers use either strategy.
I am grateful to Robert Kaufman, Daniel Kelemen, Richard Lau, Paul Poast, Geoffrey Wallace, Douglas Jones, Ezequiel González-Ocantos, Juan Pablo Luna, Jorge Bravo, Eric Davis, Adam Cohon, Edwin Camp, Luciana Oliveira Ramos, Giancarlo Visconti, William Young, Johannes Karreth, and the reviewers and editor of JPLA. I also thank participants of the Latin American Studies Association 2014 conference, the Southern Political Science Association 2015 meeting, the Western Political Science Association 2015 meeting, and the 2014 Graduate Conference at the Political Science Department, Rutgers University. Any errors that remain, of course, are my responsibility. This work was partially funded by the Center for Latin American Studies at Rutgers University. I am grateful to the School of Arts and Sciences and the Department of Political Science for their travel grants.
In fact, the decision to investigate group-based and/or individual-based targeting seems to be attributable to distinct research designs and agendas, rather than theory. For example, ethnographers generally focus on individuals, while others have traditionally focused on groups (Scott 1972; Auyero 2000; Szwarcberg 2013; Weitz-Shapiro 2012; and González-Ocantos et al. 2012). 2
I wish to thank Ezequiel González-Ocantos for this suggestion.
What is most concerning, however, is that it is relatively assumed or implied that individual and group clientelist targeting strategies are interchangeable, when they are clearly not. Individuals pertaining to groups and individuals by themselves have different incentives to defect to the incumbent. For instance, individuals belonging to larger groups have greater incentives to defect (Stokes 2005), while individuals who are personally targeted have fewer incentives to defect (Auyero 2000). Anticipating this, brokers adjust their strategies accordingly. In the first instance, brokers deal with low-informational environments that increase principal-agent problems. In the second instance, brokers – who know their clients better – are able to leverage this knowledge, reducing the probability of defection. However, these differences have not been sys tematized in the literature. In the present paper, I propose a framework that explains when it is more efficient to target groups or individuals.
Particularly, by focusing on brokers, the paper advances an argument about the decision process regarding whom to target. The crux of the argument is that this decision is a function of three factors: individuals’ discount factors explained by income levels, the incentives of clientelist brokers to rely on spillover effects caused by the nesting structure of individuals (that is, whether individuals are nested in poor or non-poor contexts), and brokers’ incentives to engage in clientelism explained by higher electoral pressures and political competition.
Overall, I share Carlin and Moseley's (2015: 14) opinion that “[e]xisting research looks almost exclusively at individuals’ socio-economic and, specially, electoral profiles [and] [y]et our knowledge of who parties target remains incomplete.” The present paper seeks to contribute to this issue by incorporating both structural and individual factors that foster clientelism in the same theory. Analytically, the structure of the argument (and the empirics) allows for disentangling the effects of “being poor” and “living in a poor area.” Another important implication of the argument is that I am able to suggest why parties that adopt clientelism as a strategy, target their resources to both poor and non-poor individuals, an empirical regularity that, to the best of my knowledge, has been unexplored so far.
Perhaps the area in which there is the most agreement among scholars is on the relationship between poverty and vote-buying (Calvo and Murillo 2004; Weitz-Shapiro 2012; Kitschelt 2000; and Kitschelt and Altamirano 2015). For example, Brusco, Nazareno, and Stokes (2004), Stokes et al. (2013), and Nazareno, Brusco, and Stokes (2008) explained that since the poor derive more utility from immediate transfers than the uncertain returns associated with future policy packages, clientelist political parties only target the poor. In fact, Weitz-Shapiro explained that “[a]lmost universally, scholars of clientelism treat and analyze [this] practice as an exchange between politicians and their poor clients” (Weitz-Shapiro 2014: 12; my emphasis).
However, this canonical predictor has recently been contested (Hicken 2007: 55). Szwarcberg (2013: 32) “challenges the assumption [that brokers] with access to material benefits will always distribute goods to low-income voters in exchange for electoral support,” while González-Ocantos et al. (2012) and Holland and Palmer-Rubin (2015) found that income (measured at the individual level) had little or no effect on vote-buying. In fact, Figure 1 shows that non-poor individuals in Brazil did receive clientelist offerings. Why would brokers target non-poor individuals?
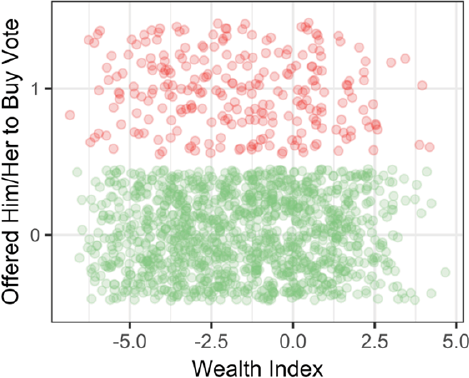
Individual Wealth and Vote-Buying in Brazil
And relatedly, why does contemporary scholarly work report null findings for poverty, traditionally the most important predictor of vote-buying? I present an argument where individual income alone is not relevant (similarly, see Weitz-Shapiro 2012: 568). What matters is how noticeable individuals are. Wealthier individuals living in poor contexts and poor individuals living in non-poor contexts are more identifiable, increasing their respective probabilities of being targeted. I also contend in this article that, in low-information environments, brokers use these kinds of observables to reduce the probability of defection of their clientele.
Another often-considered contextual factor in the literature is the size of the community in which clientelism takes place. Large-sized communities impose severe principal-agent problems. Stokes (2005: 323) explained that the “community structure” mediates the incentives to defect. Large communities make voters more anonymous, increasing their probability of defection. In fact, Rueda (2017: 164) found that in Colombia vote buying is more effective in contexts of small polling places.
Several scholars have then argued that brokers prefer smaller groups because individuals nested in small communities should defect less (Brusco, Nazareno, and Stokes 2004; Kitschelt and Wilkinson 2006: 10; and Magaloni 2008: 67. See also Bratton 2008, for Nigeria, and Gingerich and Medina 2013: 456, for Brazil). Yet, even when brokers might prefer to target small communities (with fewer voters relative to large communities), it is not clear how political parties gain enough electoral returns, especially considering that clientelism is expensive.
Vote-buying is an expensive strategy (Zarazaga 2014: 35), and more so when clients are individually targeted. 3 Stokes (2005: 317) argued that brokers develop skills that allow them to infer whether individual clients in small-sized communities voted for their party by looking at them in the eyes. Gay (1993, 1998) documented similar findings for the Brazilian case. This strategy requires brokers to sustain close relationships over time with their clients in a personal and individualized way. Knowing the clients’ needs, delivering them benefits, monitoring their political behavior (and punishing them in case of defection), all in an individualized fashion, makes this strategy an extremely expensive choice – and it becomes even more expensive as more individuals are added to the broker's portfolio.
Dixit and Londregan (1996: 1147) explained that brokers track “constituents’ likes and dislikes, compulsively participating in a spectrum of events [such as] baptisms and bar mitzvahs, weddings and funerals [and even, holding] daily meetings with constituencies [even] after nine o'clock [hearing] what anyone wished to tell [them]” (My emphasis).
The cost of individual targeting increases linearly with the size of the targeted population (Hicken 2007: 56). This intuition is important because the brokers’ production-possibility frontier cannot be shifted upwards either. Since the number of brokers is a depletable resource, at some point party machines run out of brokers, implying that monitoring capacities are bounded. In fact, Auyero (2000: 74) explained that the capacity brokers have to deliver benefits is “finite,” and “only for a restricted number of people.” However, and despite this constraint, brokers still have incentives to secure a large number of votes. Yet, the literature explains that clientelism should decrease in large communities. However, it is hard to conceive that brokers will stop being clientelist just because the size of the population is large. A priori, it seems a missed opportunity for brokers to let go of a large number of votes. In fact, survey data for the Brazilian case indicate that inhabitants of large, medium, and small municipalities are targeted in virtually the same proportion (Speck and Abramo 2001: 2). This article explains that when brokers need to secure large amounts of electoral support, especially when political competition is high, they turn to group-targeting strategies, relying on the spillover effects of clientelism. In these contexts, clientelism mobilizes electoral support from “actual” and “potential” beneficiaries, minimizing the costs of clientelist targeting while maximizing electoral benefits, a mechanism that I explain later on in the paper.
Civic associations might help solve some of the challenges largesized groups present to brokers. As low-information environments prevent brokers from really observing individual electoral behavior (Zarazaga 2014: 35), they usually resort to alternative methods that allow them to make safer inferences. For example, Schaffer and Baker (2015: 1094) argued that clientelism is “socially multiplied” as party machines target individuals “who are opinion-leading epicenters” in informal situations, or “partisan networks” (Calvo and Murillo 2013), in what has been called “organization buying” (Stokes et al. 2013: 250-251). 4 If parties buy “turnout” (Nichter 2008), then they will most probably target associations too, as “citizens immersed in clientelist networks […] have a higher probability of voting than the rest” (Carreras and Castaneda-Angarita 2014: 7). I acknowledge the positive relationship between group membership and clientelism. However, what has not been explored yet is whether clientelism is explained by association membership itself, or by the fact that poor individuals usually address their problems as a group, since otherwise it would be too costly to solve them individually. If this is the case, group membership should be spuriously related to clientelism. While I find that group membership does have a positive effect on clientelism, I find that structural contexts that foster group-targeting have even more explanatory power. 5
Holland and Palmer-Rubin (2015: 16) explained that when “parties lack their own brokerage networks [they seek] to capitalize on organizational networks instead.” Similarly, Rueda (2015: 13) argued that parties tend to target very specific civic associations of “seniors and associations of single mothers, organizing trips to recreational centers outside the city where all their expenses are covered.” Paradoxically, the stronger the civic society (that is, the more organized it is), the more clientelism there is.
These results are presented in Figure A4.
Moving forward, Weitz-Shapiro's (2012) important paper found that in several Argentine municipalities, higher levels of political competition and low socioeconomic levels fostered higher levels of clientelism. In her paper, losses are conceptualized in terms of “moral costs.” Evidence for these types of costs has been presented in the literature very recently. For example, Carlin and Moseley (2015) argued that citizens endowed with more democratic values feel more “moral repugnance” to clientelism. Vicente (2014) showed that vote-buying practices have an “immoral/illegal connotation,” while González-Ocantos et al. (2012) found that individuals wanting to avoid social stigma usually do not give truthful answers when asked directly about clientelism. Building on this literature, I contend that when political competition is high, clientelism will be higher in contexts where poor individuals live in poor economic contexts.
When Do Parties Target Individuals and When Groups?
Table 1 presents four ideal types in four quadrants; cases where individuals are highly identifiable; that is, non-poor individuals living in poor areas (Q1), and poor individuals living in non-poor areas (Q4). Identifiability in these cases reduces the cost of defection, permitting clientelist brokers to closely target individuals. While individual targeting is more expensive, it is also safer (compared to group targeting). The table also shows cases where individuals are hard to identify; that is, poor individuals living in poor areas (Q2), and non-poor individuals living in non-poor areas (Q3). In these cases, voters are more anonymous, making direct individual-based targeting and monitoring more costly. Since brokers still have incentives to seek electoral support, they engage in group targeting by relying on the spillover effects of clientelism. In these cases, the effects of vote-buying disseminates by mobilizing targeted voters and latent untargeted (but potential) clients. This form of targeting is cheaper but more uncertain.
Strategy Set: Group versus Individual Targeting

Source: Author's compilation.
Individual Targeting
This is the safest bet a broker can make, but also the most expensive one, as it requires brokers to have sustained closed relationships with their clients. For instance, Zarazaga (2014: 26) stated that “brokers have detailed information about their neighborhood and clients’ needs.” Keeping track of every single client (and their respective needs) is an expensive strategy. After all, as Auyero (2000: 73) put it, brokers are “problem solvers.” Importantly, the kind of care given ranges from material needs to symbolic and immaterial necessities, making clientelism a relationship based on “trust, solidarity, reciprocity, caring, and hope.” Such broker-client symbiosis is both material and personal-intensive, making it very costly. As an investment, however, it pays off electorally. The same detailed information brokers have about their clients’ needs is then used to infer coercively (or know directly) the electoral behavior of their respective clientele, administering punishments or rewards accordingly (Stokes 2005: 317).
The transaction costs of clientelism are reduced by targeting identifiable clients. In 2009, Luna et al. (2011) made extensive participant observations in several campaigns, accompanying a number of candidates for several months in their campaigns for the legislative election in Santiago de Chile. With one incumbent, we spent considerable time on the ground, traveling in her district. On several times, as we drove throughout the district in her personal car, the candidate was able to recall who the head of household was (including his/her name), what her district office had contributed to solve their needs, and whether the household members were on good terms with her. 6 Importantly, the economic diversity of the district provided a number of useful observables. In non-poor areas, poor houses with an unpainted wall, a rusty front yard fence, a two-story house with a bodega market on the first, a household with a broken window, or a junk diesel truck aground in the front yard, among others, provided distinctive points of reference. Identifiability, as an observable, made these receivers less anonymous, raising their cost of defection and making them more prone to cooperate. Table 1 portraits individuals living in these heterogenous contexts in Q4.
The actual gender of the candidate might have been changed for confidentiality purposes.
Households in Q4, being more noticeable, stand out in their respective contexts, making it easier for brokers to notice whether they need construction materials, whether there are wakes to which they could contribute flowers or birthday parties to which they could bring cakes. In addition, it makes their possible defection more obvious and memorable for the brokers. In summary, higher levels of visibility supply brokers with good-quality information about their clients. 7 In addition, when political contestation is low, the demand for votes is less astringent, shaping brokers’ incentives to target in a more accurate, less massive fashion, identifiable and particularized individuals, not groups.
Importantly, poor households do not need to be close to each other, but visible enough.
The capacity brokers have to identify potential clients not only comes from third-party sources, as the “organization buying” proponents explain (Holland and Palmer-Rubin 2015; Rueda 2015 and Stokes et al. 2013). In a similar account, others have pointed out that brokers are also “reliable neighbors” (Zarazaga 2014: 38); that is, members of the same community of targeted individuals. Acknowledging this approach, the argument presented in this article contends that brokers have incentives to expand their immediate local networks by colonizing visible targets outside of their own proximate neighborhood. By conceptualizing brokers as active political entrepreneurs who seek new supporters outside of their immediate context, the proposed framework complements other accounts, as presented in Szwarcberg (2013: 32) or Zarazaga (2016: 681), where brokers are neighborhood party agents. Clientelist entrepreneurship can be performed directly or indirectly. For instance, Auyero (2000: 65–66) described the situation of Cholo, a member of the inner circle of one of the brokers in Buenos Aires, Argentina, who visited “other poor neighborhoods of the area adjacent to” the place where the broker (and himself) lived, to spread news about some government plan, the governor, and the Peronist party, but importantly, also reporting to the broker any unattended material needs he had noticed. This illustrates how, via different channels, brokers expand their client portfolio outside of their immediate community.
An important implication is that individual poverty does not play a role by itself. Non-poor individuals living in poor areas (Q1) are also noticeable, and consequently, possible targets as well. Political competition shifts the demand for votes upwards. As elections become more contested, brokers need to secure even higher levels of electoral support. Since newly elected representatives are more likely to bring new people to their machines, brokers are also interested in seeing their candidates elected. Consequently, brokers will have even more incentives to engage in clientelism when political competition is high. In these cases, political competition is high enough to even mobilize non-poor individuals in a clientelist way. Since these votes are more expensive to purchase (given decreasing marginal utility from income, see Stokes 2005: 321), this strategy is less preferred. However, costly clientelism is worth the investment given the risk of losing the election.
Group Targeting
This is the least accurate targeting strategy, but also the cheapest one available to brokers. It leverages the spillover effects provided by larger concentrations of individuals who share the same socio-economic backgrounds. This strategy is less accurate because it mobilizes electoral support from “actual” clients (individuals who have actually been targeted), and “potential” clients (individuals who have not received benefits yet). It is preferred when poor individuals are nested in poor areas (Q2), or vice-versa (Q3). In these cases, individuals are masked by their environments, which means that identifiability is hard to achieve. As explained before, identifiability facilitates individual targeting, an important factor in reducing the probability of defection of targeted clients. When individuals are hard to identify, however, individual targeting becomes prohibitively expensive. Yet, brokers who still need to secure electoral support do not opt out of clientelism and instead turn to group targeting.
Auyero (2000: 65) described the case of Alfonsina in Argentina. Alfonsina was part of the broker's inner circle and got a job as a cleaning lady in a public school. As the broker explained to her, before getting the job, Alfonsina had to be patient because as a member of “the circle,” she was in the pool of potential beneficiaries; it was only a “matter of time” until she could get the job. The idea of expectations and hope are important. Auyero explained that the
hope of a job serves as important glue within the inner circle. Although not everyone is employed at the municipality, the fact that someone gets [a] job has an important demonstration effect. (Auyero 2000: 65; my emphasis)
Building on this intuition, two ideal types are suggested: actual and potential beneficiaries. The former receive particularistic benefits “today” and vote for the broker's candidate “tomorrow,” while the latter do not receive benefits “today” (in the expectation of receiving them in the future) but still vote for the broker's candidate “tomorrow.”
Group targeting is cost-effective because it mobilizes two types of voters at the cost of investing in just one (i.e. the “actual”). Actual beneficiaries want to remain actual beneficiaries since they want to keep receiving benefits; thus, they keep supporting the broker's candidate. In turn, potential beneficiaries want to become actual beneficiaries, but are uncertain when that might happen; as a result, they also support the broker's candidate. In this sense, from the broker's perspective, this strategy reduces the sunk costs by half, multiplying the gross benefits by two. In other words, the broker's reputation of a “problem solver” disseminates twice as fast relative to individual targeting. It is in this sense that this is a massive (but less precise) form of clientelist targeting.
Given that potential clients support the broker's candidate in the absence of current inducements, brokers need to effectively calibrate the timing when potential beneficiaries become actual beneficiaries. In other words, brokers need to infer the discount factors of their potential clients, making it expensive for them to defect. Reputation, as a form of capital, is fundamental for brokers since “voters prefer to support [brokers] with a reputation for delivering because they are a more reliable source of future rewards” (Zarazaga 2014: 24). However, potential clients are also interested in investing in their reputation. From their perspective, they know that the flow of resources is dependent on the brokers’ electoral success. Also, they do not know whether new brokers might have access to fewer resources or distribute them to other people. For them, the cost of switching brokers (or defecting) is very high since it also involves building relationships of confidence with another broker from scratch, which is costly. Hence, the incentives are for the broker to deliver benefits before it is too late, while the incentives for the potential client are to support the broker's candidate.
Since it does not matter what type an individual is, both actual and potential beneficiaries keep voting for the broker's candidate. While cost-effective, group targeting is less accurate since brokers hope to mobilize potential beneficiaries only indirectly; that is, by targeting actual beneficiaries. This makes this strategy a fragile one. However, besides the reputation costs described above, low-income voters have additional incentives to support the broker's candidate. This is described in Q2. Given that the poor are risk-averse, potential beneficiaries are better-off waiting (and voting for the broker's candidate) than defecting. In the same vein, but on a slightly different subject, Magaloni (2008: 20) posited that the Mexican PRI lasted as long as it did not because of electoral fraud but because voters supported the “known devil.” Economic underdevelopment played a fundamental role in this equilibrium as well. Finally, higher levels of electoral contestation force brokers to engage in this less accurate, but massive form of clientelist targeting, leveraging (1) the incentive structure of potential clients to support the candidate even in the absence of current inducements, and (2) the higher levels of risk aversion poor individuals have.
Importantly, vote-buying is also targeted to non-poor individuals nested in non-poor groups (Q3). Vote-buying has decreasing returns to scale in non-poor individuals. That is, wealthier individuals derive fewer advantages from a bag of rice relative to poorer individuals (Kitschelt 2000). Anticipating this, brokers will not offer the same benefits to wealthy individuals, but will customize the type of offerings. This distinction is important, since most of the literature assumes that clientelist practices decrease when individual incomes rise. However, that approach does not explain the counterintuitive empirical regularity depicted in Figure 1; that is, non-poor individuals get targeted too. Why are non-poor individuals targeted? This article seeks to contribute to the literature by explaining that brokers make their offers more attractive to non-poor individuals by offering goods that are relatively more expensive. This is more likely when districts are wealthier.
While buying votes from non-poor individuals costs more, brokers in non-poor areas have more resources to spend. Along the same lines, Hicken (2007: 55) questioned the implicit assumption that the broker's vote buying funds remain fixed; stating that “a candidate's capacity to buy votes increases commensurate with increases in average incomes.” In other words, higher levels of economic development not only raise personal incomes, but also shifts the broker's vote-buying capacities upwards. Similar evidence has been found in the Philippines (Schaffer 2004). The link between higher incomes and vote buying is particularly relevant for Brazil, since its electoral laws allows political parties to get unlimited funds (Abramo and Speck 2001: 14), enabling brokers greater capacities to buy more expensive votes.
Besides having more resources to spend, brokers in politically uncontested districts have fewer political constraints, facilitating the spending of expensive clientelism. In Q3 it is suggested that lower levels of political contestation allow brokers to spend on more expensive means of clientelism. Uncompetitive districts lack proper de facto mechanisms of checks and balances, giving local incumbents more “room to move,” allowing them to divert local resources into more expensive means of targeting. I call this “embezzlement clientelism.” Given these relatively more expensive costs, however, I expect this form of clientelism to be less frequent. In a dynamic similar to Q2, potential clients also support the broker's candidate, hoping to become actual beneficiaries. However – and unlike poor clients in Q2 – non-poor clients in Q3 (both actual and potential) have smaller discount factors. That is, non-poor individuals – given their relatively higher incomes – have more “patience.” This is especially important for brokers. In practice, potential clients’ timing constrains are more elastic, putting less pressure on brokers to deliver benefits in the short run.
Case Selection, Research Design, and Data Analyses
This section empirically tests the theoretical proposition stated in Table 1 – that is, the combined effects of individual income, of being nested in poor/non-poor communities, and being exposed to different levels of political competition – on receiving clientelist benefits. Brazil is a good case because its poverty structure is such that it is possible to find low-income individuals nested in non-poor areas (and vice versa). This case is also interesting from an institutional perspective. The Brazilian electoral system incentivizes clientelism. Several factors such as multimember districts with open lists, and the institution of the candidato nato, 8 “clearly [makes] Brazil one of the most personalistic systems of democratic governance” (Kitschelt and Altamirano 2015: 257), which might foster higher levels of clientelism. In fact, Gingerich (2014: 290) found that vote-buying drastically changed electoral results, concluding that “[v]ote brokerage can still pay electoral dividends in contemporary Brazil.”
“[R]ule that removed parties’ control over the nominations process and let an electoral legislator decide to run on any party ticket.” See Kitschelt and Altamirano (2015: 257).
To test this hypothesis, I use survey data from 2010 from The Latin American Public Opinion Project (LAPOP) (2010). 9 Though the LAPOP survey provides a question for income, people who are somewhat better off than their neighbors but live in poor areas may not “feel” poor. If this is the case, it could confound the results. Additionally, when answering the questioner, individuals might not want to reveal their true incomes (either because they are too low or too high). Following the advice of Córdova (2008) and Córdova and Seligson (2009, 2010), a relative wealth index (RWI) was constructed (see also Santos and Villatoro 2018). Using principal component analyses, the index measures wealth based on actual assets weighted by how common these assets are. Different indices were constructed for urban and rural contexts. Figure 1 plots the distribution of the index.
“I thank the Latin American Public Opinion Project (LAPOP) and its major supporters (the United States Agency for International Development, the United Nations Development Program, the Inter-American Development Bank, and Vanderbilt University) for making the data available.” The sample consists of five strata representing the five main geographical regions of Brazil. Each stratum was further sub-stratified by urban and rural areas.
To measure economic development at the group level, I constructed a variable that I call “the density of the poor” following a strategy similar to that of Weitz-Shapiro (2012). The variable, which is plotted in Figure 2, measures the degree of poverty at the municipal level. Using information from the 2010 Brazilian census, 10 a semi-continuous variable was constructed to measure the percentage of individuals who live on less than half of the minimum wage in a given municipality. Given that the municipality of residence for each individual in the LAPOP survey is recorded, I was able to merge the census percentage with the LAPOP dataset. It is important to stress that the unit of analysis is the individual, and that this variable captures the economic context in which each individual lives. Just like other scholars in the past have tested the effect of being nested in rural areas, 11 this paper focuses on another class of contextual variable. Although the density of the poor group was originally a semi-continuous variable (that is, a percentage), it had to be dichotomized at the median (29 percent) to be able to construct a matched sample, which I justify and explain below. Figure 2 shows the continuous distribution dichotomized at the median (dotted line).
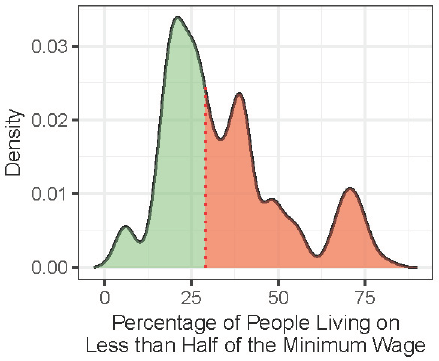
Distribution of the Density of the Poor
Official data comes from the Bureau of Statistics of Brazil IBGE.
See, for example, Brusco, Nazareno, and Stokes (2004) and Stokes (2005). Both studies used the log of population, which is a proxy for urban/rural.
Finally, to measure political competition, I again follow Weitz-Shapiro (2012). Using official electoral data from the 2008 municipal elections, 12 I constructed a variable that measures the percentage of seats that are not controlled by the mayor's party in a given municipal council.
Data from the Tribunal Superior Eleitoral.
There is a built-in lack of relationship between “being poor” and “living in a poor municipality,” confirming that Brazil is in fact a good case to test this theory. Figure A1 in the Appendix shows that the unmatched/ raw dataset already has embedded low levels of correlation between these two variables (r = −0.44). 13
The figure shows that, for both the matched and raw datasets, “being poor” and “living in a poor municipality” are not confounded, as it is possible to find poor individuals living in non-poor areas, and vice versa.
I was able to break this relationship down further using matching methods. Matching is a two-stage process. In the first stage, the analyst “preprocesses” the data, seeking to break any systematic relationship between, in this case, the density of the poor and the relative wealth index RWI (Ho et al. 2011). Matching does so by deleting observations for which similar observations cannot be found. 14 The idea is to obtain a good covariate balance, as in Figure A3 (in the Appendix), to then estimate any appropriated statistical model. 15 From a statistical standpoint, preprocessed datasets are less model-dependent (Ho et al. 2007), 16 and prevent analysts from making extreme counterfactuals. 17 The preprocessed data used in the matching approach has 54 municipalities, while the raw data used in the generalized propensity score (GPS) approach (which I explain below) also has 54. Figure 3 lists the municipalities and shows which ones are considered “high” or “low” in terms of the density of the poor after the dichotomization process. The figure also shows that there is considerable variance in income/RWI in both high- and low-poverty density conditions (bubbles). 18
The final procedure matched 761 individuals living in the low-density poverty condition with 676 individuals living in the high-density poverty condition.
The idea is that the propensity of being exposed to the “high” density of the poor condition (or “propensity score”) has a similar distribution in both “treated” and “control” groups. It is important to note that, despite the language, I do not claim any causal relationship in this paper.
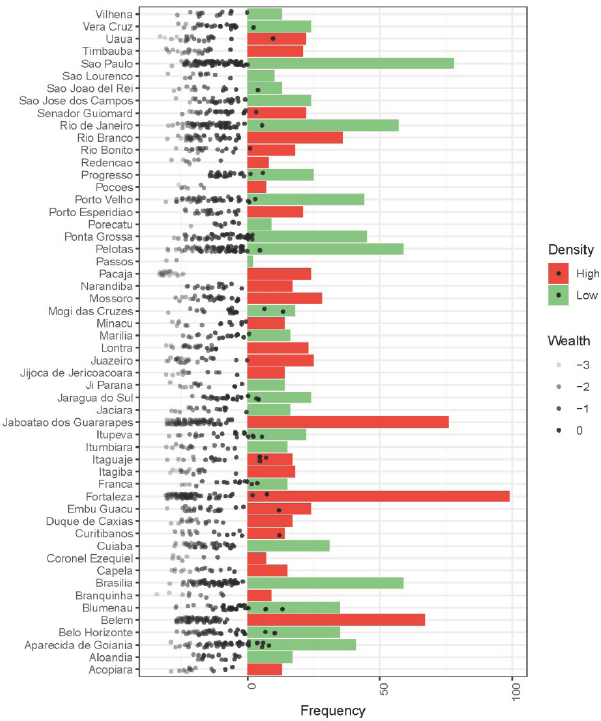
Distribution of Observations by Municipality, Wealth Index and Density of the Poor
Table A2 and Table A1 in the Appendix provide summary statistics for both the matched and raw datasets. Tables were generated using the stargazer R package. See Hlavac (2015).
King and Zeng (2005). The matching routine used was the full matching routine (Hansen 2004; Rosenbaum 2010), via the MatchIt R package (Ho et al. 2011).
Figure A2 in the Appendix shows the frequency of individuals by municipality in both raw and matched datasets.
One could argue that dichotomizing the density of the poor variable at the median is an arbitrary decision. While there have been theoretical advances regarding general treatment effects regimes for continuous or semi-continuous response doses (Imai and Dyk 2004; and Hirano and Imbens 2004), algorithms with the ability to match on continuous treatment variables are not common. In order to obtain covariate balance in a non-parametric way (as matching does) but without dichotomizing the density of the poor, I also use the original (that is, continuous) density of the poor variable to construct a generalized propensity score GPS (Imbens 2004; Guardabascio and Ventura 2014; and Imai and Ratkovic 2014). 19 The score is used to weight each observation in the model. 20
To generate the weighting vector, I used the CBPS R package (Fong et al. 2018).
Besides matching on and weighting by the RWI index, I also included the following variables to match on/weighting by: municipal opposition, municipal population and individual involvement in civic associations.
The dependent variable is clientelism. To measure it, I use the question that asks if a candidate or someone from a political party offered the respondent something, like a favor, food, or any other benefit or tiling in return for her/his vote or support. Subjects could answer that this had happened often, sometimes, or never. Carreras and Irepoglu (2013) and Holland and Palmer-Rubin (2015) used the same dataset and outcome variable. As they explained, the question did not ask whether respondents took the offer, hence it should not be an important source of social desirability bias (González-Ocantos et al. 2012). For statistical and substantive reasons, I dichotomized this variable, combining the alternatives often (n = 91) and sometimes (n = 150), leaving never (n = 1,196) unchanged. 21
These numbers come from the matched dataset.
The following control variables were considered in the statistical analyses. Perception of corruption was included to hold constant the effect of respondents who declared clientelist activity when in reality they were referring to corruption scandals. 22 Brokers usually target civic associations. Following Holland and Palmer-Rubin (2015: 28), an additive index to measure civic participation (Political Involvement) was created. 23 Some studies have also found group size to be important (Stokes et al. 2013). A variable to measure population size at the municipal level was constructed using Brazilian census data.
I thank Cesar Zucco for this suggestion.
This variable was constructed by adding the frequency of attendance at religious meetings, community improvement meetings, and political party meetings (variables cp6, cp8 and cp13, respectively).
Following the convention in statistical studies of clientelism, an urban/ rural dummy was also included. Some have argued that parties target their own supporters (Dixit and Londregan 1996, and Cox and Mccubbins 1986), moderate opposers (Stokes 2005), or unmobilized supporters (Nichter 2008). To keep these effects constant, a variable to capture party identification (Political Id.) was included. Higher levels of democratic support should be negatively associated with clientelism. To control for that, a variable measuring democratic support was included. González-Ocantos, Kiewiet de Jonge, and Nickerson (2014) found that schooling plays a negative role on clientelism; hence, I control for education too.
Observations are clustered on a number of important factors such as levels of municipal political competition, municipal poverty, and municipal population size. In order to account for these clustering effects, I use a “generalized estimating equations” approach. GEE were introduced by Liang and Zeger (1986) to fit clustered, repeated (that is, correlated), and panel data. This method is especially efficient when the data are binary (Hanley et al. 2003). GEE models are similar to random effects models (Gardiner, Luo, and Roman, 2009), in that they allow observations to be nested in hierarchical structures. This method requires analysts to parameterize the working correlation matrix. While Hedeker and Gibbons (2006: 139) stated that “the GEE is robust to misspecification of the correlation structure,” 24 Hardin and Hilbe (2013: 166) pointed out that “[i]f the observations are clustered (not collected over time), then […] the exchangeable correlation structure” is the most appropriate working correlation matrix. Given that the data do not follow a panel but rather a clustered structure, the “exchangeable” correlation matrix was specified in all models.
Carlin et al. (2001: 402) argued that “[r]elatively minor differences in estimates may arise depending on how the estimating equations are weighted, in particular within the generalized estimating equation (GEE) framework.” Westgate and Burchett (2017) and Gardiner, Luo, and Roman (2009, 227) made the same point.
While this method is very flexible, GEE estimates remain uninterpretable in practice (Carlin et al. 2001), making regression tables useless from a substantive standpoint. In this case, the problem is even more severe due to the interactive nature of the hypothesis being tested in this paper, which is a parameter for the multiplicative term between the variables wealth index, political competition, and density of the poor. 25 Methodologists agree about “not interpret[ing] the coefficients on the constitutive terms,” as they lack substantive meaning (Brambor, Clark, and Golder 2006: 77). These problems become more complex when it comes to generalized models, as a number of challenges arise. 26 Given that cross-partial derivatives are not advisable either, simulation methods are required (Zelner 2009). In particular, I follow the simulation approach introduced in King, Tomz, and Wittenberg (2000). This procedure samples via simulation from the point estimates, generating a new and larger distribution. In more detail, taking the single estimated parameters (that is, the regression coefficients), I constructed a distribution of estimated values for each coefficient. Relying on the central limit theorem, with enough sampling draws, the new simulated distribution is a transformation that approximates with a great degree of precision the (uninterpretable) coefficients. Subsequently, means and uncertainty measures can be constructed for each of these distributions. From a substantive standpoint, simulation methods also allow for the sampling of new distributions at different values of the independent variables. This will be important in simulating the expected value of clientelism for different “profiles,” such as non-poor individuals nested in high-poor dense municipalities in contexts of high political competition, among other profiles.
Brambor, Clark, and Golder (2006: 74) offer the same advice.
As Ai and Norton (2003) explained, “(1) the interaction effect could be nonzero, even when the estimation says it is zero, (2) the statistical significance of the interaction effect cannot be tested with a simple t-test on the coefficient of the interaction term, (3) the interaction effect is conditional on the independent variables, […] and (4) the interaction effect may have different signs for different values of covariates.”
Since it is “impossible to evaluate conditional hypotheses using only the information provided in traditional results tables” (Brambor, Clark, and Golder 2006: 76), I have focused instead on the substantive results from the simulation methods. However, I still present the raw results in Table A3 in the Appendix. 27 Analogous to Table 1, in Figure 4 I simulate the predicted probabilities of being targeted using both the matched and weighted/GPS models. The horizontal panel depicts simulations for the “upper” (“non-poor,” 75 percent) and “lower” (“poor,” 25 percent) quartiles of the wealth index. In turn, the vertical panel shows the simulated values for the maximum (100 percent) and minimum (43 percent) values of the municipal opposition index. Each quadrant shows simulations for individuals nested in poor municipalities (high density of the poor), and non-poor municipalities (low density of the poor). Each profile shows two simulated probability distributions (with 95 percent confidence intervals): one for the matched sample, and one for the weighted/GPS model. 28 The idea is to show that the decision of dichotomizing the density of the poor variable at its median gives substantively exact results than using the continuous version of that variable via the GPS analysis.
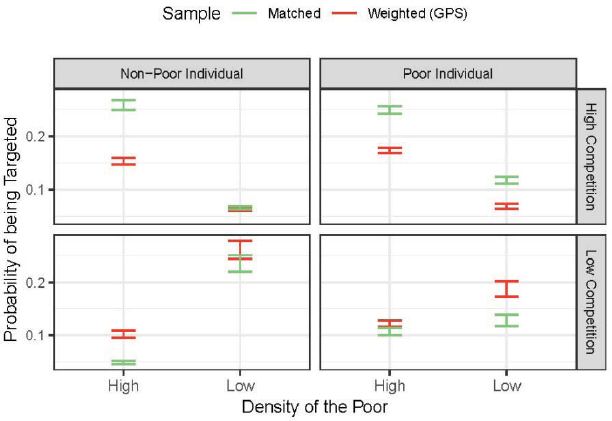
Simulated Expected Values of Clientelism
Table generated via the texreg R package. The first column shows the estimates for the matched dataset, while the second column shows the results for the GPS-weighted model. Virtually all coefficients have the same size and sign.
In the case of the weighted/GPS model, which does not use the dichotomized variable, I use the continuous version of the size of the poor variable, where “low density” represents the lower quartile while “high density” represents the upper quartile.
All quadrants in Figure 4, regardless of the approach used, 29 suggest that brokers engage in individual targeting when individuals are identifiable, and in group targeting when brokers need to rely on the spillover effects of clientelism.
Although there are statistical differences, the differences across datasets are proportional.
In Q1, clientelism is more likely (with a 26 percent probability) in situations where non-poor individuals are nested in poor groups (i.e. where the density of the poor is “high”) 30 and living in electorally contested municipalities. As I have argued, these types of individuals are still targeted because they are more identifiable. For instance, a similar individual (same quadrant) who is nested in a non-poor group (“low” density of the poor), and consequently harder to identify, has a much lower probability of being targeted (7 percent). Similarly, individuals in Q4, such as poor individuals nested in non-poor areas (“low” density of the poor), and living in lowly contested municipalities, are more likely to be targeted (13 percent) relative to harder-to-identify individuals who live in poor areas (11 percent). In Q1, higher levels of electoral competition put heavier pressure on brokers to mobilize more expensive ways of clientelism. These pressures decay when incumbents face lower levels of electoral contestation (Q4).
Matched sample.
Figure 4 shows in Q2 that clientelism is more likely (25 percent) in situations where poor individuals are nested in poor groups (“high” density of the poor). As I have argued here, brokers will have incentives to engage in group targeting, taking advantage of the spillover effects of clientelism, leveraging the electoral support of potential clients by mobilizing actual clients. This is especially the case when the incumbent is seriously contested. Individuals that are similar (same quadrant), but nested in a non-poor group (“low” density of the poor), have a much lower probability of being targeted (12 percent). Individuals in Q3, who are non-poor individuals nested in non-poor areas (“low” density of the poor), and those living in lowly contested municipalities, are more likely to be targeted (24 percent) than similar individuals nested in non-poor areas (5 percent). Areas with higher levels of economic development also allow brokers to have more resources to distribute in what it was called “embezzlement clientelism.” Lowly contested municipalities give brokers and political incumbents more room to allocate and distribute more expensive goods. However, and as theoretically expected, given that the net costs of this form of clientelism are higher, this is the least likely form of clientelism (reflected in the lower probabilities).
Discussion
This paper has argued that when poor individuals live in poor areas, brokers engage in group targeting relying on the spillover effects of clientelism. This strategy mobilizes targeted and untargeted clients by disseminating the broker's reputation of delivering benefits among potential beneficiaries. In a similar way, non-poor individuals clustered in non-poor areas are also targeted. In these cases, higher levels of economic development not only raise personal incomes, but also shift the broker's vote-buying capacities upwards. Lower levels of political contestation allow these more expensive forms of clientelism. However, in heterogeneous areas, brokers adapt their strategies and execute clientelism in a different way, relying on how identifiable individuals are. Identifiability raises the cost of defection by making their households more memorable, making receivers more likely to cooperate.
Incentives to offer or take clientelist offerings are not guided solely by structural or individual factors. This paper has suggested that both are necessary to understand clientelism better. Clearly, pressures to partake in clientelism, an expensive and uncertain strategy, rise as political competition raises (from 18 percent to 25 percent). 31 However, the outcomes of this strategy differ largely depending on whether brokers face homogeneous or heterogeneous groups of individuals. Each one provides a different cost/benefit structure for both clients and brokers. Finally, I hope that the literature considers that groups and individuals provide different incentives to both brokers and clients, and hence, this distinction should be incorporated to better understand clientelism.
Grand mean considering the most likely scenarios only.
Footnotes
Appendix
Figure A4 shows a plot divided in two panels. Panel