
Abstract
The use of artificial intelligence in medicine is rapidly expanding. Large language models, such as ChatGPT, have the potential to enhance perioperative medicine through education and clinical practice. However, concerns remain regarding the accuracy of these models, particularly the risk of hallucinations, generating factually incorrect outputs. This feasibility test explores the use of a large language model–enabled platform to assist in case-based education in perioperative clinical cases.
Methods:
Five perioperative cases addressing core topics were developed and uploaded to a custom large language model platform. The large language model platform allows free-text questions to be asked to the artificial intelligence, which then uses the derived cases to provide answers. Anaesthetic trainees engaged with the artificial intelligence, asking questions to obtain information regarding history, examination, and investigations. Artificial intelligence question-and-answer pairs were then evaluated independently in duplicate for the presence of inappropriate responses, including hallucinations.
Results:
The large language model responded appropriately to nearly all questions, with no hallucinations observed. The proportion of questions that were answered appropriately was 99.3% (543/547). In the four instances of inappropriate responses, the large language model declined to provide information in the case description rather than hallucinate.
Conclusion:
The large language model appears capable of supporting the delivery of case-based perioperative medicine content with a high degree of accuracy.
Keywords
Introduction
Artificial intelligence (AI) has the potential to significantly impact perioperative medicine and healthcare professional education (Chan et al 2025). Large language models (LLMs), such as the widely known ChatGPT, could increase the interactivity of medical education through chatbot interfaces. One such circumstance in which interactivity could be improved with LLM is case-based learning (Stretton et al 2024). However, concerns regarding the veracity of the presented information remains, particularly in a healthcare education setting.
AI medical education perioperative applications occur in the broader context of AI, increasingly being applied to preoperative risk stratification, intraoperative decision support and postoperative outcome prediction. For example, machine learning algorithms that ingest large perioperative data sets can forecast major complications and mortality with greater accuracy than traditional scores, enabling clinicians to tailor and improve management based upon individual risk (Ren et al 2022). Similarly, real-time deep-learning monitors have also been shown to effectively detect nociceptive events and hemodynamic instability during surgery (Abdel Deen et al 2025). Multiple narrative reviews now map how AI methods stand to reshape every phase of perioperative medicine (Maheshwari et al 2023, Nathan 2023).
LLMs are rapidly being explored for medical education. Systematic reviews indicate that LLM chatbots can supply personalised explanations, generate practice questions, and simulate clinical scenarios for both undergraduate and postgraduate learners (Li et al 2024, Xu et al 2024). Classroom studies further suggest that interacting with an LLM tutor improves both learner engagement and perceived preparedness for future clinical encounters (Zhou et al 2025).
LLMs, however, are prone to generating distorted ‘hallucinations’. Hallucinations are plausible sounding but factually incorrect outputs. In evaluations of scientific-writing tasks, ChatGPT fabricated references in up to 30% of outputs (Chelli et al 2024). Likewise, medical trainees show limited ability to detect hallucinated clinical details in LLM-generated answers (Zhou et al 2025). Any educational deployment must therefore incorporate expert oversight, authoritative grounding, explicit instruction on limitations of the technology, and a robust scientific evaluation.
Previous research has suggested that LLMs can be effectively used to deliver case-based content in medical specialties like neurology (Gim et al 2025). However, it has also been shown that LLMs may underperform in medical domains that are less well represented in presumed training corpora (Asiedu et al 2024). Given the developing nature of the field of perioperative medicine, it is uncertain whether LLMs would be more likely to underperform in this specialty.
Therefore, the aims of this study were to explore the accuracy of AI-generated responses, and to record any problematic hallucinations when cases were delivered in an interactive question-and-answer format with LLMs from curated case descriptions.
Materials and methods
Overview
Case descriptions (‘screenplays’) were developed using LLMs, prior to being edited by trainees and medical education consultants. They were subsequently delivered through an online LLM-enabled platform (see Figures 1–3). These cases were then questioned by investigators, and the question-and-answer response pairs evaluated for hallucinations in duplicate.
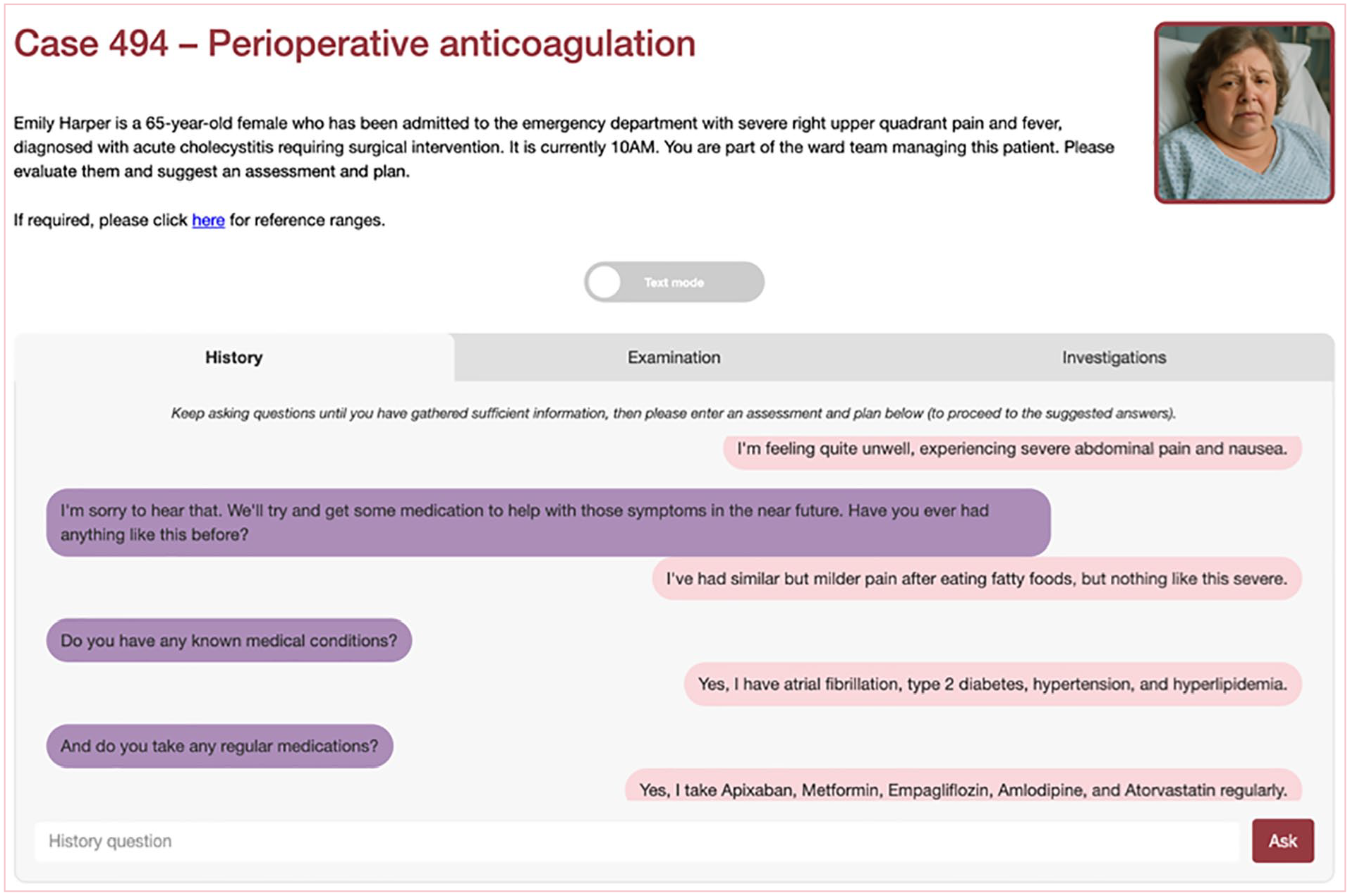
Online platform demonstrating history

Online platform demonstrating examination
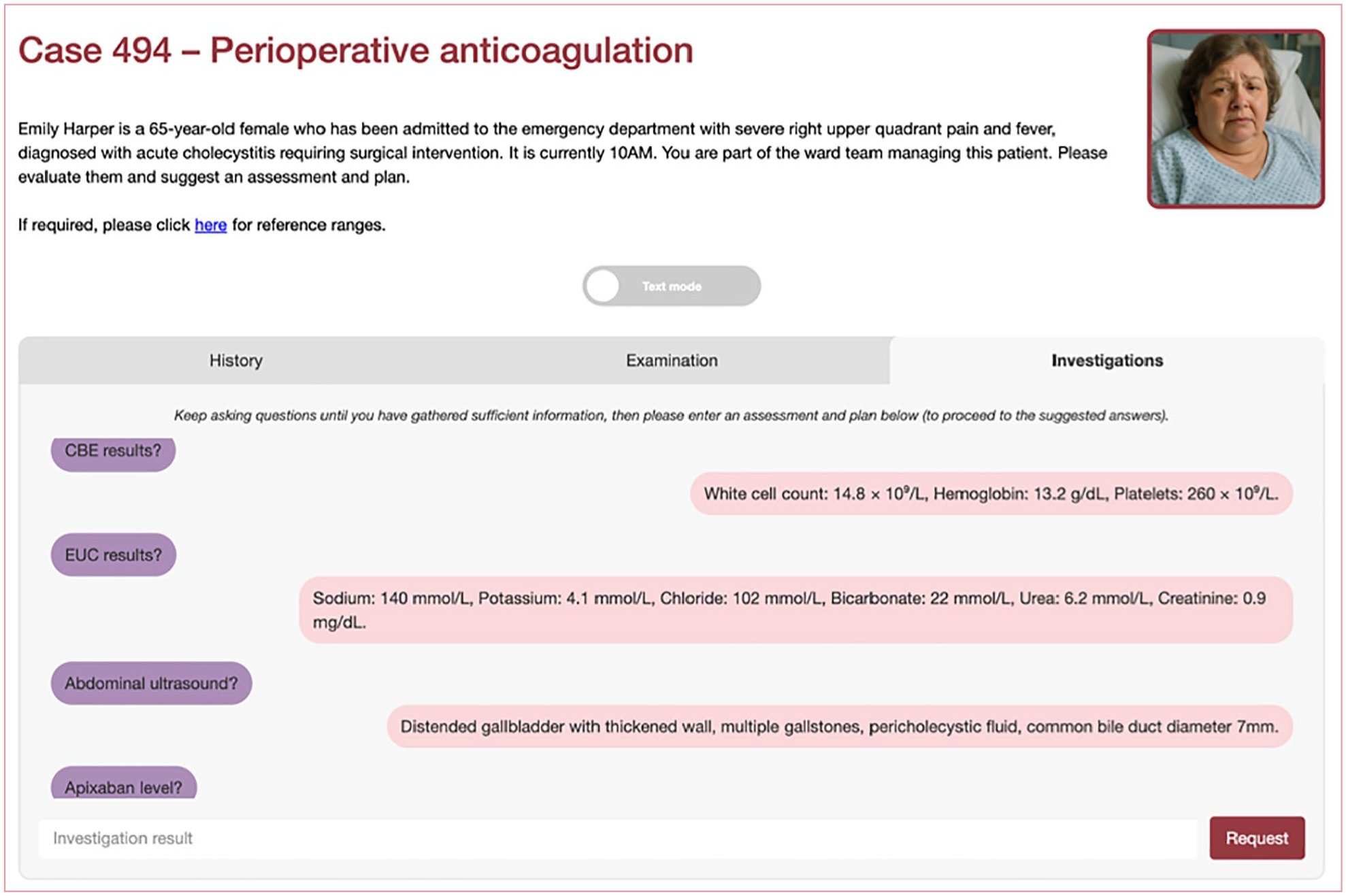
Online platform demonstration investigations
Case generation
Five perioperative cases were produced for this study. The five topics selected were based on medical student curricula pertaining to perioperative management issues and included anticoagulation management, fluid management, insulin management, prophylactic antibiotics, and being nil by mouth with time critical medications (e.g. medications for Parkinson’s disease). Case outlines were generated using the LLM Claude 3.7 Sonnet from Anthropic. The prompts that were used to generate these cases were based on the structure included in Supplementary Information 1.
After cases were generated by the LLM, they were reviewed by an intensive care unit trainee and a medical education consultant. This process involved independently reading the cases and manually editing aspects that were felt to be incongruent with medical practice, or adding content that was felt likely to be required in the real-world evaluation of such patients. The finalised screenplays that were used are included in Supplementary Information 2.
Case delivery
When the screenplays were finalised, they were uploaded to a custom online interface. This online platform provides the entire screenplay to a second LLM (GPT-4o) which then enables users to interact with it in a question-and-answer format as if they were evaluating a patient (or in physical examination and investigations, requesting them from another clinician). This second LLM was used both because of developer familiarity and its performance based on trends in sycophancy and online leaderboard rankings at the time of development.
Four anaesthetic trainee investigators then independently evaluated each of the cases with questions as if they were evaluating a patient. An unlimited number of questions and time was allowed, with the intent to evaluate each case until they had sufficient information to develop an assessment and plan. These investigators all had the opportunity to trial the online platform on at least one case prior to evaluating the perioperative cases in this study.
LLM evaluation
Question-and-answer pairs were then downloaded from the online platform and evaluated. This evaluation was conducted in duplicate by the intensive care unit trainee and medical education consultant who developed the screenplays. This evaluation included reviewing each investigator question and associated LLM answer, and categorising the response in a number of ways, namely:
(a) whether the LLM answered the question (with an example of a non-response being ‘I don’t have that information at the moment’) and, if it declined, if this was an appropriate response (i.e. if the information was not present in the screenplay, then declining to answer would be considered appropriate);
(b) if the question was answered whether the answer was on the screenplay (as opposed to an unanticipated question);
(c) if the question was not on the screenplay, to which part of the patient evaluation did the question refer (i.e. history, examination, or investigations);
(d) if the answer was not on the screenplay, and the LLM provided a response (i.e. ‘made up’ new content), was the content medically congruent and reasonable (i.e. if the answer was no, then this would be a problematic hallucination).
Following categorisation, question-answer-pairs were evaluated with descriptive statistics. The primary outcome was the proportion of medically appropriate LLM answers to investigator questions. This is the converse of the number of problematic ‘hallucinations’ or inappropriately declined answers. We deemed hallucinations in this study to be defined as unfounded fabrication and or factual errors. Unfounded fabrication describes instances where the system generates information, such as facts, data, or opinions, without sufficient evidentiary support or reliable references. Factual errors involve incorrect or inaccurate representations of objective information or empirical data presented in the system’s output (Sun et al 2024).
Ethical approval
This study involved the evaluation of a publicly available LLM using investigator-generated content and did not require ethics approval. The project was undertaken as an educational innovation initiative to explore the feasibility of LLM-assisted case-based learning in perioperative medicine. As such, it aligns with institutional guidelines for educational improvement activities that do not constitute human research.
Results
There were a total of 547 question-and-answer pairs obtained in the study. This equates to a mean of 136.8 questions per investigator who undertook the cases, and a mean of 109.4 questions per case.
Overall, the proportion of questions that were answered appropriately was 99.3% (543/547). All instances of inappropriate answers were instances in which the LLM did not provide information that was available in the screenplay when asked. In all four of these questions, the LLM instead inappropriately declined with a response similar to ‘This information is not available’. The questions pertained to results from an electrocardiogram, ketone levels, a patient’s height and weight, and evidence of injuries to aspects of the patient other than that requiring surgery.
With respect to possible hallucinations, there were 0% (0/547) responses that involved the introduction of inappropriately fabricated content. There were 14.4% (79/547) questions in which the LLM answered content that was not present in the screenplay. In other words, the LLM introduced or added content beyond that which was in the screenplay. In these questions, and in every instance, the information generated was medically appropriate. Examples of these instances are summarised in Table 1, with a complete list available in Supplementary Information 3.
Examples of answers provided by LLM that were not included in screenplay
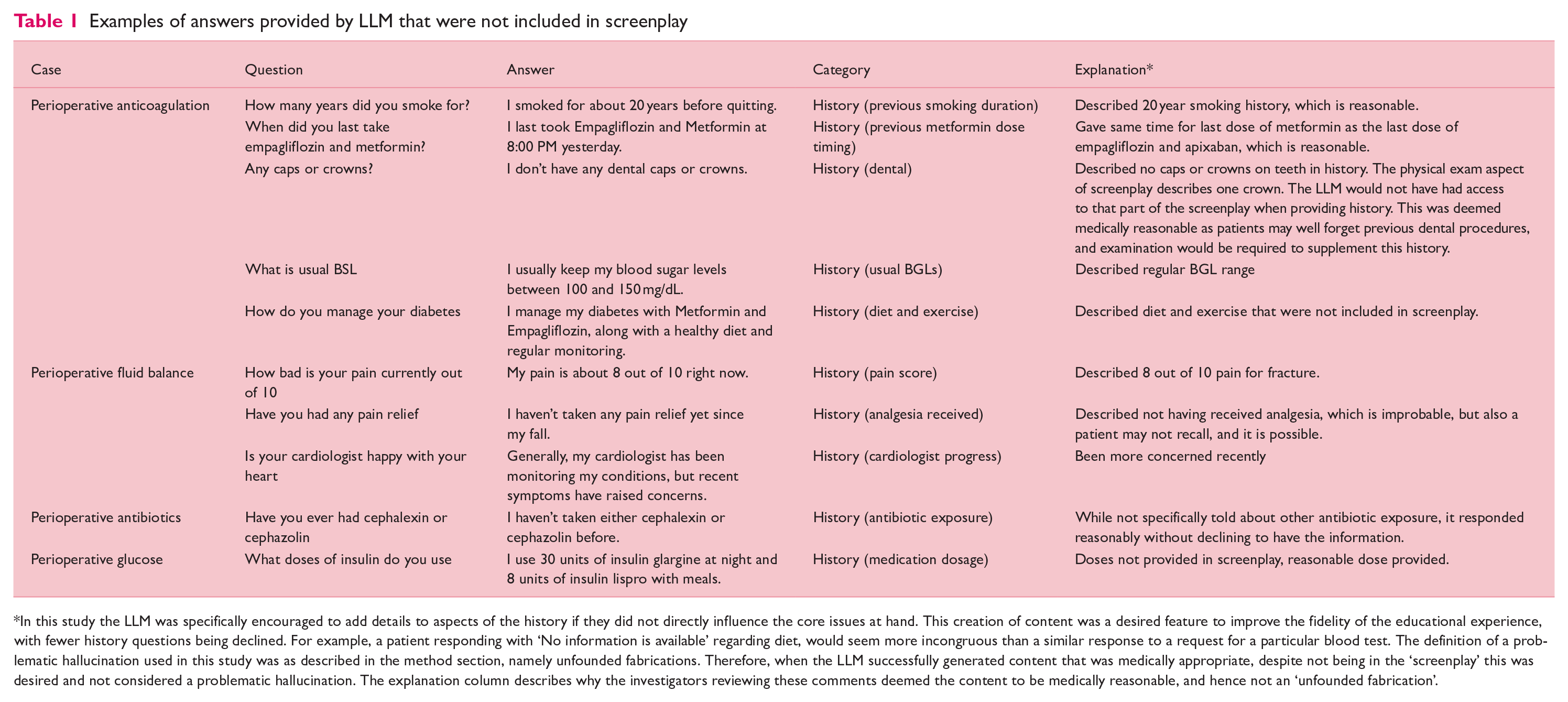
In this study the LLM was specifically encouraged to add details to aspects of the history if they did not directly influence the core issues at hand. This creation of content was a desired feature to improve the fidelity of the educational experience, with fewer history questions being declined. For example, a patient responding with ‘No information is available’ regarding diet, would seem more incongruous than a similar response to a request for a particular blood test. The definition of a problematic hallucination used in this study was as described in the method section, namely unfounded fabrications. Therefore, when the LLM successfully generated content that was medically appropriate, despite not being in the ‘screenplay’ this was desired and not considered a problematic hallucination. The explanation column describes why the investigators reviewing these comments deemed the content to be medically reasonable, and hence not an ‘unfounded fabrication’.
Discussion
These results suggest that the LLM can be used to accurately represent written case descriptions in an interactive question-and-answer format for learners. There was a very low rate of inappropriate responses, and when they did occur, it was due to the lack of provision of information by the LLM. Importantly, there were no instances of inappropriate hallucination.
An important distinction in this study is the use of LLMs in an educational setting, and not for clinical decision making. In this educational context, ‘unfounded fabrication’ merited classification as an inappropriate hallucination. Given the educational focus of portraying a patient case, plausible generation of content beyond that contained in the screenplay was not only acceptable, but designed and desired. For example, in the history section, the LLM was deliberately deployed in a manner to allow it to generate plausible content that did not change core content relating to the medical issues in the case. This utilisation of the generative components of LLM may allow for more fluent case interactivity and were not adjudicated as hallucinations if medically appropriate.
This educational application is in sharp contrast to clinical applications of LLMs. If a LLM were applied to a clinical setting, such as scribe applications and audit activities, the generation of plausible content (that was encouraged in this educational setting) could be directly harmful to patient care or unit activities (Goh et al 2024, Kleinig et al 2024). In such a clinical context, any production of plausible content not explicitly described would be considered an ‘unfounded fabrication’. At the core of this distinction lies the intent of the LLM application (i.e. providing a realistic educational patient case vs completing a clinical task such as documentation), and this highlights the importance of use-case specific LLM deployments and prompting. Clinical applications of LLMs require different structures, verification methods, and benchmarking to those in educational settings like that in this study.
This study adds perioperative medicine to the growing list of disciplines in which LLMs can accurately deliver interactive case-based learning. Our zero-hallucination rate in this sample of five cases when the model was anchored to a curated screenplay parallels the high factual concordance reported when ChatGPT answered standardised medical examinations (Kung et al 2023) and supports findings that careful prompt design and content grounding can curb error generation in educational settings (Zhou et al 2025).
Educationally, AI-driven virtual cases can furnish unlimited, on-demand deliberate practice while standardising exposure to core perioperative scenarios. Reviews of LLM use in medical training highlight benefits such as individualised feedback, improved engagement, and scalability to resource-limited settings (Xu et al 2024). Embedding such tools into curricula could therefore extend experiential learning beyond operating-room schedules and faculty availability, expanding traditional education practices to enhance readiness for an evolving healthcare landscape (Cadman et al 2025). However, scientific evaluation of these tools is necessary before widespread deployment.
If LLMs are not used carefully, problematic hallucinations can still occur and responses may perpetuate historical biases or race-based misconceptions present in training data (Omar et al 2025, Omiye et al 2023). The opaque reasoning of transformer models further complicates error detection and accountability. Ongoing supervision, routine content validation, and bias-mitigation strategies are therefore essential before widescale educational adoption. The findings of this study support the existence of approaches that could enable the delivery of such AI supported content for healthcare professional education with negligible hallucinations.
The interactivity of LLMs demonstrated through this online educational platform also raises the potential for similar interfaces as a tool to support clinical activities. The nature of hallucinations and LLM deployment in clinical settings differs to that of the demonstrated educational setting. For example, the creation of information on diet and exercise in case 1 (anticoagulation), in a clinical setting could mislead triage process for prehabilitation, and inaccurate information on insulin dose regimens could lead to inappropriate insulin prescription. Preliminary studies in the clinical domain show encouraging results with similar online interfaces, enabling the collection of information as a medical officer may conduct (Gao et al 2025). Future evaluation of LLMs for clinical applications will require different methods of evaluation to this type of educational application. For example, there is currently an increasing focus on the evaluation of clinical applications of LLMs as similar to that of the credentialling of medical professionals (Rajpurkar & Topol 2025). The potential of LLMs to assist in collection of data from patients, and in assisting decision making, in an era of shortages of medical personnel, is significant, but in such clinical applications the eradication of hallucinations will be vitally important.
As a feasibility analysis, this research has several limitations. While five cases spanning multiple perioperative topics is a strength, generalisability would be further supported by the inclusion of more, and more diverse, cases. In addition, determining the incidence of events in the absence of an observed event is challenging, and accurate estimates would be supported by such future studies. Furthermore, all cases were written and evaluated in English. While this study has demonstrated that the content can be delivered successfully with this method, improvement in educational outcomes have not yet been demonstrated.
To integrate AI into medical education for perioperative patient assessment and management plan formulation, further research is needed to align AI with existing teaching methods. AI may enhance adult learning by fostering problem-solving and decision-making case scenarios rather than just delivering content (Mehigan et al 2023). In the future, AI cases can be linked to specific curriculum objectives, providing personalised feedback on students’ patient assessments and management plans, which could support targeted skill development. For clinicians unfamiliar with AI, this approach may contextualise the technology within familiar educational frameworks. Combining AI with traditional methods, such as in-person learning, would create a blended environment that enhances education across diverse learning styles, supporting deliberate practice in clinical decision-making and patient care (Sameen et al 2022).
The role of LLM in tasks adjacent to the delivery of question-and-answer case-based content should also be explored further, including the ability of the models to provide learners with feedback and automated scoring (Qian et al 2025). Now we have shown accuracy of an LLM with no hallucinations in an interactive case delivery, determined by detailed assessment by expert clinicians, we can further assess accuracy within a blinded clinical review format to develop a more robust assessment of the model.
Conclusion
LLMs, a type of AI, can be used to successfully deliver case-based perioperative medicine content based on a high degree of accuracy. This has the potential to provide high-quality learning with low reliance of human input. Further studies examining the effect of such resources, including the future use in supporting clinical care, are required.
Supplemental Material
sj-docx-1-ppj-10.1177_17504589251346634 – Supplemental material for Artificial intelligence in perioperative medicine education: A feasibility test of case-based learning
Supplemental material, sj-docx-1-ppj-10.1177_17504589251346634 for Artificial intelligence in perioperative medicine education: A feasibility test of case-based learning by Timothy Trewren, Nicholas Fitzgerald, Sarah Jaensch, Olivia Nguyen, Alexander Tsymbal, Christina Gao, Brandon Stretton, Stewart Anderson, D-Yin Lin, Dario Winterton, Galina Gheihman, Guy Ludbrook, Kelly Bratkovic and Stephen Bacchi in Journal of Perioperative Practice
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: S.B. is supported by a Fulbright Scholarship.
Ethical approval
Artificial intelligence statement
ChatGPT-o3 was used to assist with readability and clarity. The authors have reviewed and take responsibility for the work.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.