
Abstract
In order to enhance the performance of image recognition, a sparsity augmented probabilistic collaborative representation based classification (SA-ProCRC) method is presented. The proposed method obtains the dense coefficient through ProCRC, then augments the dense coefficient with a sparse one, and the sparse coefficient is attained by the orthogonal matching pursuit (OMP) algorithm. In contrast to conventional methods which require explicit computation of the reconstruction residuals for each class, the proposed method employs the augmented coefficient and the label matrix of the training samples to classify the test sample. Experimental results indicate that the proposed method can achieve promising results for face and scene images. The source code of our proposed SA-ProCRC is accessible at https://github.com/yinhefeng/SAProCRC
Keywords
Introduction
Image recognition remains one of the hottest topics in the communities of computer vision and pattern recognition. During the past decade, sparse representation has been successfully applied in various domains. In face recognition, the pioneering work is the sparse representation based classification (SRC). 1 Concretely, SRC employs all the training samples as a dictionary, and a test sample is sparsely coded over the dictionary, then the classification is performed by checking which class yields the least reconstruction error. SRC can achieve promising recognition results even when the test samples are occluded or corrupted. To further promote the robustness of SRC, Wang et al. 2 proposed a correntropy matching pursuit (CMP) method for robust sparse representation based recognition. CMP can adaptively assign small weights on severely corrupted entries of data and large weights on clean ones, thus reducing the effect of large noise. Wu and Ding 3 presented a gradient direction-based hierarchical adaptive sparse and low-rank algorithm to tackle the real-world occluded face recognition problem. Gao et al. 4 developed a robust and discriminative low-rank representation method by exploiting the low-rankness of both the data representation and each occlusion-induced error image simultaneously. Keinert et al. 5 designed a group sparse representation-based method for face recognition which introduces a non-convex sparsity-inducing penalty and a robust non-convex loss function.
Apart from classifier design, feature extraction is also a crucial stage in image recognition. The most classic subspace learning-based approaches are principal component analysis and linear discriminant analysis. Motivated by the recent development of sparse representation, Qiao et al. 6 presented a dimensionality reduction technique called sparsity preserving projections. To make SRC efficiently deal with high-dimensional data, Cui et al. 7 proposed an integrated optimization algorithm to implement feature extraction, dictionary learning, and classification simultaneously. To tackle the corrupted data, Xie et al. 8 explored a dimensionality reduction method termed low-rank sparse preserving projections by combining the manifold learning and low-rank sparse representation.
Recently, sparse representation has been applied to a wide range of tasks. Zhang et al. 9 developed a structural sparse representation model for visual tracking. Liu et al. 10 introduced the convolutional sparse representation into image fusion. Guo et al. 11 proposed a sparse and dense hybrid representation-based target detector for hyperspectral imagery (HSI).
Another critical issue in sparse representation is how to solve the
Akhtar et al.
13
revealed that sparseness explicitly contributes to improved classification. And they proposed a sparsity augmented collaborative representation based classification (SA-CRC) which employs both dense and sparse collaborative representations to recognize a test sample. However, collaborative representation based classification (CRC)
14
utilizes all the training samples to represent the input test sample, which neglects the relationship between the test sample and each of the multiple classes. To overcome the drawback of SA-CRC, first we obtain a dense representation by probabilistic collaborative representation based classification (ProCRC),
15
then we augment the representation of ProCRC with a sparse representation to further promote the sparsity of ProCRC. Moreover, different from conventional representation based classification methods that use class-wise reconstruction error for classification, we utilize the label matrix of training data and the augmented coefficient of a test sample for final classification. The proposed method is termed as sparsity augmented probabilistic collaborative representation based classification (SA-ProCRC). In summary, our contributions are as follows:
We promote the sparsity of ProCRC by augmenting the representation of ProCRC with a sparse representation. We employ an efficient classification rule to recognize the test sample, in which the explicit computation of residuals class by class is avoided. Experimental results on diverse datasets validate the efficacy of our proposed method.
Related work
Given n training samples belonging to C classes, and the training data matrix is denoted by
Sparse representation based classification
In SRC,
1
a test sample

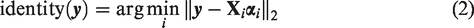
Collaborative representation based classification
SRC and its extensions have achieved encouraging results in a variety of pattern classification tasks. However, Zhang et al.
14
argued that it is the collaborative representation mechanism rather than the

CRC has the following closed-form solution


Probabilistic CRC
Inspired by the work of probabilistic subspace approaches, Cai et al.
15
explored the classification mechanism of CRC from a probabilistic perspective and developed a probabilistic collaborative representation based classifier (ProCRC), and the objective function of ProCRC is formulated as


SA-ProCRC
In our proposed SA-ProCRC, the dense representation of ProCRC is augmented by a sparse representation computed by OMP,
16
and the optimization problem for sparse representation is given by
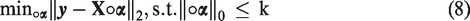
The augmented coefficient

Let
Our proposed SA-ProCRC has the following procedures. First, the dense coefficient and sparse coefficient are obtained by solving equations (6) and (8), respectively. Second, the dense coefficient is augmented by the sparse coefficient. Finally, the test sample is recognized according to the augmented coefficient vector and the label matrix of the training data. Algorithm 1 presents our proposed scheme.
1. Compute the coefficient 2. Obtain the sparse coefficient 3. Compute the augmented coefficient 4. Compute
Analysis of SA-ProCRC
In this section, we present some experimental results on the Extended Yale B database to illustrate the effectiveness of SA-ProCRC. The Extended Yale B database contains 38 individuals and there are about 64 images for each individual. We randomly select 20 images per subject as the training data; therefore, the dictionary contains 760 atoms. We select a test image which belongs to the first subject, and the sparse coefficients and corresponding residual for each class are plotted in Figures 1 and 2. It can be seen from Figure 1 that coefficients belong to the first class are prominent. From Figure 2, we can clearly see that the first class has the least residual, which indicates that the test sample is correctly classified by SRC. Figure 3 shows the coefficients derived by ProCRC, and we can see that the coefficients are rather dense. Figure 4 presents the residual of ProCRC, one can see that the 26th class has the least residual, thus the test sample is wrongly classified to the 26th class. Coefficients obtained by SA-ProCRC are shown in Figure 5, and we can see that coefficients from the first class are dominant. Figure 6 plots the score of SA-ProCRC for each class, it can be seen that the first class delivers the largest value. As a result, the test sample is designated to the first class by SA-ProCRC. From the above experimental results, we can find that the dense representation of ProCRC may lead to misclassification. By augmenting the dense representation with a sparse representation, the misclassification can be alleviated. This validates the superiority of our proposed SA-ProCRC.

Coefficients obtained by SRC.

The residual of SRC for each class, and the first class has the least residual.

Coefficients computed by ProCRC.

The residual of ProCRC for each class, one can see that the 26th class has the minimal residual.

Coefficients obtained by SA-ProCRC.

The score of SA-ProCRC for each class, it is evident that the first class has the largest value.
Experiments
In this section, we conduct experiments on four benchmark datasets: the Yale database, the Extended Yale B database, the AR database, and the Scene 15 dataset, the details of these datasets are listed in Table 1. We compare the proposed method with state-of-the-art representation based classification methods and several dictionary learning approaches, such as SRC, 1 CRC, 14 ProCRC, 15 discriminative K-SVD (D-KSVD), 17 label consistent K-SVD (LC-KSVD), 18 fisher discrimination dictionary learning (FDDL), 19 dictionary learning based on commonalities and particularities (COPAR), 20 joint discriminative Bayesian dictionary and classifier learning (JBDC), 21 and SA-CRC. 13 For SRC, we solve the problem in equation (1) as in Wright et al. 1 For CRC, LC-KSVD, FDDL, COPAR, JBDC, and SA-CRC, we use the publicly available codes. We adapted the code of LC-KSVD to implement D-KSVD. For SA-CRC and our proposed SA-ProCRC, OMP is utilized to obtain the sparse representation. We utilize the same value of sparsity level (k = 50) as in SA-CRC. 13 All experiments are run with MATLAB R2019a under Windows 10 on PC equipped with 3.60 GHz CPU and 16 GB RAM.
Details of datasets used in our experiments.
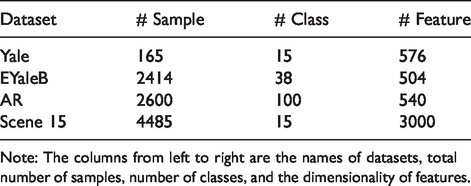
Note: The columns from left to right are the names of datasets, total number of samples, number of classes, and the dimensionality of features.
Experiments on the Yale database
There are 165 images for 15 subjects in the Yale database, each has 11 images. These images have illumination and expression variations, Figure 7 shows some example images from this database. All the images are resized to 24 × 24 pixels, leading to a 576-dimensional vector. In our experiments, six images per subject are randomly selected for training and the rest for testing. The error tolerance ε of SRC is 0.05, and the balancing parameter λ of CRC is 0.001. The sparsity level and number of atoms for D-KSVD and LC-KSVD are 30 and 60, respectively. Sparsity level k and λ of SA-CRC are set to be 50 and 0.002, respectively. Experimental results are summarized in Table 2, in which the best result is highlighted by bold number. It can be observed that SA-ProCRC achieves the highest recognition accuracy, with a 17% reduction in the error rate of ProCRC, and 12% reduction in that of SA-CRC.

Example images from the Yale database.
Recognition accuracy on the Yale database.
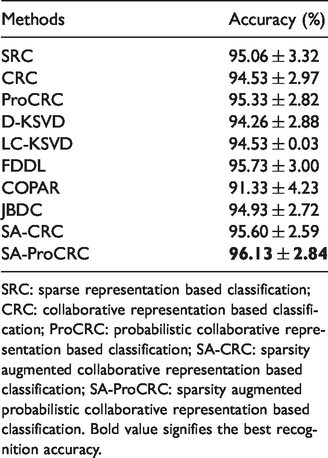
SRC: sparse representation based classification; CRC: collaborative representation based classification; ProCRC: probabilistic collaborative representation based classification; SA-CRC: sparsity augmented collaborative representation based classification; SA-ProCRC: sparsity augmented probabilistic collaborative representation based classification. Bold value signifies the best recognition accuracy.
Experiments on the Extended Yale B database
The Extended Yale B face database is composed of 2414 images of 38 individuals. Each individual has 59–64 images taken under different illumination conditions, example images from this dataset are shown in Figure 8. In our experiments, each 192 × 168 image is projected onto a 504-dimensional space via random projection. Twenty images per person are selected for training and the remaining for testing. We use the error tolerance of 0.05 for SRC, and the regularization parameter λ = 0.001 for CRC. The sparsity level and number of atoms for D-KSVD and LC-KSVD are 50 and 400, respectively. Sparsity level k and λ of SA-CRC are set to be 50 and 0.005, respectively. Table 3 lists the recognition accuracy of the comparison methods. It can be seen that our proposed SA-ProCRC is superior to its competing approaches.

Example images from the Extended Yale B database.
Recognition accuracy on the Extended Yale B database.

SRC: sparse representation based classification; CRC: collaborative representation based classification; ProCRC: probabilistic collaborative representation based classification; SA-CRC: sparsity augmented collaborative representation based classification; SA-ProCRC: sparsity augmented probabilistic collaborative representation based classification. Bold value signifies the best recognition accuracy.
Experiments on the AR database
The AR database has more than 4000 face images of 126 subjects with variations in facial expression, illumination conditions, and occlusions, Figure 9 shows example images from this database. We use a subset of 2600 images of 50 male and 50 female subjects from the database. Each 165 × 120 face image is projected onto a 540-dimensional vector by random projection. Ten images per person are randomly selected for training and the remaining for testing. The error tolerance of SRC is 0.05, and the balancing parameter of CRC is 0.0014. The sparsity level and number of atoms for D-KSVD and LC-KSVD are 50 and 600, respectively. Sparsity level k and λ of SA-CRC are set to be 50 and 0.002, respectively. Experimental results are shown in Table 4. We can see that the best classification result is achieved by our proposed SA-ProCRC, with a 23% reduction in the error rate of ProCRC.

Example images from the AR database.
Recognition accuracy on the AR database.

SRC: sparse representation based classification; CRC: collaborative representation based classification; ProCRC: probabilistic collaborative representation based classification; SA-CRC: sparsity augmented collaborative representation based classification; SA-ProCRC: sparsity augmented probabilistic collaborative representation based classification. Bold value signifies the best recognition accuracy.
Experiments on the Scene 15 dataset
This dataset contains 15 natural scene categories including a wide range of indoor and outdoor scenes, such as bedroom, office, and mountain, example images from this dataset are shown in Figure 10. For fair comparison, we employ the 3000-dimensional scale invariant feature transform (SIFT)-based features used in LC-KSVD. 18 We randomly select 50 images per category as training data and use the rest for testing. The error tolerance of SRC is 1e-6, and the balancing parameter of CRC is 1. Fifty atoms are used for D-KSVD and LC-KSVD. Sparsity level k and λ of SA-CRC are set to be 50 and 1, respectively. Recognition accuracy of different approaches on this dataset is presented in Table 5. Again, SA-ProCRC outperforms the comparison methods.

Example images from the Scene 15 dataset.
Recognition accuracy on the Scene 15 dataset.

SRC: sparse representation based classification; CRC: collaborative representation based classification; ProCRC: probabilistic collaborative representation based classification; SA-CRC: sparsity augmented collaborative representation based classification; SA-ProCRC: sparsity augmented probabilistic collaborative representation based classification. Bold value signifies the best recognition accuracy.
Conclusions
It has been argued that it is the collaborative representation mechanism rather that the sparsity constraint that makes SRC powerful for pattern classification. As a result, sparsity is ignored to some extent in CRC and its extensions. To address this problem, we present a SA-ProCRC method to promote the sparsity in ProCRC. The proposed SA-ProCRC is computationally efficient due to the fact that ProCRC has closed-form solution. Meanwhile, discriminative information containing in the resulting sparse coefficient can be exploited in SA-ProCRC. In essence, SA-ProCRC is a classifier, thus it can be applied to other pattern classification tasks. In our future work, we will evaluate SA-ProCRC with deep features and develop new representation based classification algorithm.
Footnotes
Acknowledgements
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No. 61672265).