
Abstract
Low-Rank Representation (LRR) and Sparse Subspace Clustering (SSC) are considered as the hot topics of subspace clustering algorithms. SSC induces the sparsity through minimizing the
Introduction
The past few decades witnessed the data explosion, we have entered the era of big data, and an overwhelming amount of data is generated and collected every day. This poses a great challenge to process such large datasets, especially the datasets are usually very high-dimensional, even though the computer processing speed becomes faster and faster. The high-dimensionality of data not only increases the computing time but also decreases the performance due to the noise and insufficient samples in ambient space.1,2 However, the intrinsic dimension of these data is often much smaller than the dimension of the ambient space. This has motivated a variety of techniques to find the low-dimensional representations of high-dimensional data.
Subspace clustering is the problem of clustering data according to their potential low-dimensional subspaces. Is has been widely used in many fields, such as motion segmentation and face clustering in computer vision, hybrid system identification in control, community clustering in social networks. Many algorithms have been proposed, such as GPCA,
3
Spectral Curvature Clustering (SCC),
4
Low-Rank Representation (LRR)5,6 and its noisy variant LRSC,
7
Sparse Subspace Clustering (SSC).8,9 Among them, SSC and LRR are considered as the state-of-the-art techniques, which are based on minimizing the nuclear norm and
Sparse subspace clustering (SSC) uses
Liu et al. 5 recently presented an LRR algorithm for subspace clustering that relies on the same principle of representing a sample as a linear combination of others. LRR finds the lowest-rank representation of high-dimensional data. In addition to capturing the global structure of the data, LRR solves the convex optimization problem of nuclear norm minimization, which is considered as a surrogate for rank minimization. Several efforts have been made to improve the robustness of LRR. Chen and Yi 11 extended the original LRR algorithm by integrating a symmetric constraint condition into the low-rank representation, thus avoiding the post-processing symmetrization step of constructing an affinity matrix. Yin et al. 12 proposed a Laplacian regularized LRR to take into account the intrinsic geometrical structure of the data.
Although these methods are efficient and effective for solving specific clustering problems, an important shortcoming is that both LRR and SSC build an affinity matrix by using the techniques from low-rank or sparse representation. They assume that a point in a union of multiple subspaces admits a low-rank or sparse representation with respect to the dictionary formed by all the other data points, this is known as the Self-Expressiveness Property (SEP), i.e.,
Motivated by the above research works, in this paper, we propose a low-rank sparse subspace clustering method with a clean dictionary named as LRS2C2. The experiments conducted for different types of vision problems prove the effectiveness of the proposed LRS2C2 method. The contributions of this paper can be summarized as follows:
(1) We integrate the low-rankness and sparsity constraints into a unified framework in order to get a better subspace clustering performance (2) In the general optimization framework, we try to decompose a data matrix as a self-expressive, noise-free data matrix and a noise matrix and use the noise-free data matrix as a clean dictionary. Consequently, the introduction of a clean dictionary to low-rank and sparse subspace clustering enriches the relationship between high-dimensional data samples corrupted by gross errors and provides more robust subspace clustering performance.
The rest of this paper is organized as follows. In section 2, we briefly review SSC and LRR algorithms. In section 3, we present the proposed LRS2C2 method and its implementation by using the alternating direction method of multipliers (ADMM). 13 The experimental results are shown in section 4. Finally, we conclude this paper in section 5.
Related works
In this section, we briefly introduce sparse representation, low-rank representation subspace clustering algorithm. For a given data matrix
Sparse subspace clustering
SSC was recently proposed as a solution to the subspace clustering problem.
9
SSC finds the sparsest representation of the data by solving the following optimization problem

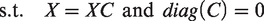


In the case of data corrupted by noise and sparse outliers, SSC assumes that each corrupted point can be represented by a linear combination of other corrupted points plus an outliers’ vector and a noise vector. In particular, SSC solves the following optimization problem

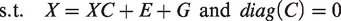
Low-Rank representation
Different from SSC, LRR finds the lowest-rank representation. LRR is formulated as the following rank minimization problem






Therefore, in a post-processing step, one can use the coefficient
Low-Rank sparse subspace clustering with a clean dictionary
Motivation
It is well known that the corruptions and noise are ubiquitous in real-world data, meaning that certain observation may be arbitrarily corrupted. We cannot expect high dimensional data to always capture in well-controlled environments. Therefore, when using the original noisy data as a dictionary, the clustering performance may be seriously limited by a lack of robustness to corrupted observations. The importance of learning the dictionary from noisy data for classification and clustering has been shown in many studies.14–16
As there are many complex variations to the noise encountered in observation, it is difficult to choose an appropriate strategy for removing all types of noise from real-world data. Different low-rank matrix recovery and completion techniques are suitable for different types of noise. PCA determines the best low-rank approximation when the original data are only mildly corrupted by Gaussian noise with small variance. The RPCA can be used to recover the discriminative low-rank dictionary from data corrupted by sparse noise. The objective function of RPCA is as follows


In this paper, we assume that given a corrupted data matrix
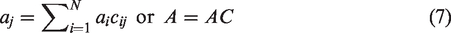
The proposed approach, which we call Low-Rank and Sparse Subspace Clustering with a Clean dictionary (LRS2C2), is based on solving the following optimization problem


The proposed method combines the LRR and SSC, the first item of Eq.6 encourages
Optimization for LRS2C2
In this subsection, we derive a computationally efficient algorithm to solve the proposed objective function.
When 2. When
where each entry of

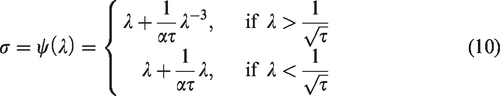


This equation has a closed-form solution
3. When




The augmented Lagrangian is

By fixing two of the variables, we can alternately update



The detailed optimization procedure is summarized in Algorithm 1. The three sub-problems in the corresponding steps are convex and have closed-form solutions. The second step can be solved by the singular value thresholding operator. 17 The third step can be solved by the shrinkage thresholding operator.
After we get the coefficient matrix
While not converged do
Compute Fix the other two variables and update Fix the other two variables and update Fix the other two variables and update Update the multipliers:
Update the parameter Check the convergence conditions
End while
Compute



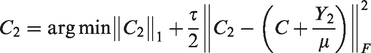
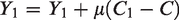


Experiments
In this section, we evaluate the performance of LRS2C2 on two computer vision tasks: motion segmentation and image clustering. For the motion segmentation problem, we consider the Hopkins 155 dataset. For the image clustering problem, we consider the Extended YaleB dataset, AR dataset and MNIST datasets.
In the experiments, we use the subspace clustering error as a measure of performance, we compare LRS2C2 to state-of-the-art subspace clustering algorithms based on spectral clustering, such as LRR, 5 LRSC, 7 SSC 9 and LSA. 18 We choose these methods as a baseline because they have been shown to perform very well on the above tasks.
Experiments on motion segmentation
Motion segmentation refers to the problem of clustering a set of 2D point trajectories extracted from a video sequence into groups corresponding to different rigid-body motions. Here, the data matrix D is of dimension
We use the Hopkins 155 motion segmentation database to evaluate the performance of LRS2C2 against that of other algorithms. The database consists of 155 sequences of two and three motions, where 120 of the videos have two motions and 35 of the videos have three motions. On average, in the dataset, each sequence of two motions have N = 256 feature trajectories and F = 30 frames while each sequence of three motions has N = 398 feature trajectories and F = 29 frames. For each sequence, the 2 D trajectories are extracted automatically with a tracker and outlier are manually removed. Figure 1 shows some sample images with the feature points superimposed.

Motion segmentation: given feature points on multiple rigidly moving objects tracked in multiple frames of a video (top), the goal is to separate the feature trajectories according to the moving objects (bottom).

Sample images from the dataset (a) extended Yale B (b) AR (c) MNIST.
The results of applying subspace clustering algorithms to the dataset when we sue the original 2 F-dimensional feature trajectories and when we project the data into a 4n-dimensional subspace (n is the number of subspaces) using PCA are shown in Tables 1 and 2, respectively.
Clustering error (%) of different algorithms on the Hopkins 155 dataset with the 2 F-dimensional data points.

Clustering error (%) of different algorithms on the Hopkins 155 dataset with the 4n-dimensional data points obtained by applying PCA.

From Tables 1 and 2, we can find that, in both cases, LRS2C2 obtains a small clustering error, outperforming the other algorithms. On the other hand, the clustering performance of different algorithms when using the 2 F-dimensional feature trajectories or the 4n-dimensional PCA projections are close. This comes from the fact that the feature trajectories of n motions in a video almost perfectly lie in a 4n-dimensional linear subspace of the 2 F-dimensional ambient subspace preserves the structure of the subspaces and the data; hence, for each algorithm, the clustering error in Table 1 is close to the error in Table 2. However, due to the fact that the Hopkins 155 dataset has a relatively low-noise level, the improvement of the LRS2C2 is relatively minor.
Experiments on images clustering
In this subsection, we conduct the experiments on images clustering problems. We use three image datasets including the extended YaleB, AR and MNIST to test the performance of LRS2C2. Figure 2 shows some sample images of the three data sets. The brief information of the three datasets are summarized as follows:
The extended Yale B database contains 38 human subjects and around 64 near frontal images under different illuminations per individual, the face images of each subject correspond to a low-dimensional subspace. In this paper, we select the first 10 classes of extended Yale B database to form the test dataset which contains 640 images in total and each image is resized to
AR database contains over 4000 face images of 126 individuals. For each individual, 26 pictures were taken in two sections (separated by two weeks) and each section contains 13 images. These images include front view of faces with different expressions, illuminations and occlusions. In this paper, we took a subset of the AR dataset containing five male subjects and five female subjects.
MNIST database has 10 subjects, corresponding to 10 handwritten digits, namely 0–9. We select a subset which consists of the first 100 samples of each subject’s training dataset.
We first applied the proposed algorithm to the full original images without any artificial corruption or missing entries. Some example images from the extended Yale B database are given in Figure 3(a). Next, we considered artificial occlusion, namely random pixel corruptions. To simulate random pixel corruptions, we replaced a certain percentage of pixels in the matrix of the image with uniformly distributed random values in the range [0, 1]. To ensure that the noise was sparse, the corrupted location and pixels were selected at random and were unknown to the algorithms. The percentage of corrupted pixels was varied from 5 to 20% in steps of 5%. Figure 3(b) shows some examples of the images with random pixel corruptions. For a fair comparison, we preprocessed the images for the other algorithms by removing noise using the RPCA 19 algorithm. Figure 3(c) shows some representative examples by applying the RPCA algorithm to face images with random pixel corruptions.

Representative examples in the extended Yale database B: (a) sample images under different illumination conditions, (b) sample images with random pixel corruptions, (c) sample images after using RPCA.
We executed each algorithm 10 times and report the mean clustering error and standard deviation in Tables 3 to 5.
Clustering error (%) of different algorithm on the extended YaleB dataset by random pixel corruptions (the parameters for LRS2C2 are
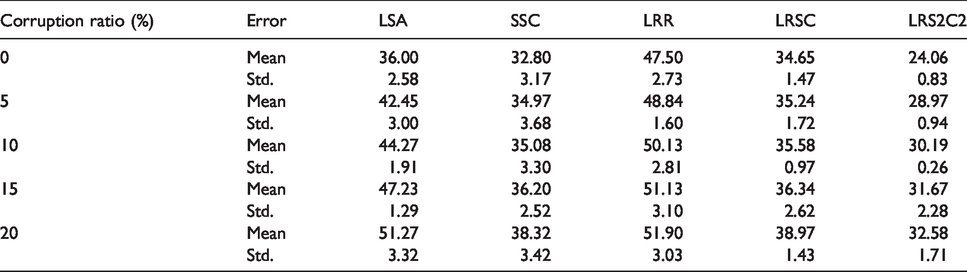
Clustering error (%) of different algorithm on the AR dataset by random pixel corruptions (the parameters for LRS2C2 are

Clustering error (%) of different algorithm on the MNIST dataset by random pixel corruptions (the parameters for LRS2C2 are

From the experimental results, it is clear that the proposed LRS2C2 method achieves the lowest clustering error in the three datasets. The clustering results confirm that the LRS2C2 can significantly improve the accuracy of image clustering. In these experiments, we adopt many low-rank based methods, the results also show low-rank based method outperformed other methods. For the original dataset without artificial corruption, as the LRS2C2 can recovery a clean dictionary from the input data matrix, it has the advantage than other methods, it achieves the lowest clustering error. Among the compared methods, LRSC also has the ability to use a clean dictionary, however, it only reveals the low-rankness of the data, LRS2C2 combines the low-rankness and sparsity of the representation of the data matrix, the solution is able to benefit from both the better separation induced by the
When the dataset was corrupted, the experimental results show that LRS2C2 consistently outperformed all the other methods, particularly for larger percentages of corrupted pixels. And as the increase of the percentage of the corruption, the proposed LRS2C2 method also has a relative advantage than other methods. These results clearly imply that LRS2C2 is more robust than the other algorithms.
Convergence analysis
In this section, we examine the convergence of our algorithm. The penalty parameter

Value of objective function versus iteration.
Conclusion
To effectively solve the subspace clustering problem in the case of data corrupted by noise, in this paper, we propose the LRS2C2 method, which decomposes the given data matrix to a clean data dictionary and a noise matrix. We also combine the low-rank representation and sparse representation in a unified framework to efficiently obtain the clustering results. Experiments conducted on motion segmentation and image clustering problems showed the effectiveness of our algorithm and its superiority over the state-of-the-art methods.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China (Grant No. 61902160, 61806088), the Natural Science Foundation of the Jiangsu Higher Education Institutions of China (Grant No.19KJB520006) and the foundation of Changzhou Science and Technology Plan (Applied Basic Research) (Grant No. CJ20190076).