
Abstract
This paper introduces an efficient feature learning framework via sparse coding for no-reference image quality assessment. The important part of the proposed framework is based on sparse feature extraction from a sparse representation matrix, which is computed using a sparse coding algorithm. Image patches extracted from salient regions of unlabeled images are used to learn a dictionary of sparse coding. The ℓ1-norm of the sparse representation is taken as a sparse penalty term in the process of learning the dictionary and computing the sparse representation. A feature detector adopts the ℓ1-norm together with the max-pooling results of the sparse representation matrix as the output sparse features to obtain the objective quality scores. Sparse features of salient regions are evaluated using the LIVE, CSIQ and TID2013 databases, and result in good generalization ability, performing better than or on par with other image quality assessment algorithms.
Introduction
Nowadays digital images have a significant effect on representing and communicating information. Since digital images are often distorted in the procedure of image acquisition and image processing, the question of how to accurately measure image quality becomes a popular and challenging issue in computer vision and image processing. According to whether image quality assessment (IQA) requires the participation of people, it can be classified into objective IQA and subjective IQA. Subjective IQA requires that image quality evaluation results are provided by human visual identification, and is difficult to employ in real time image processing because of its strong randomicity. Correspondingly, objective IQA can be automatically implemented by computing devices running IQA algorithms; therefore, studying efficient and reliable IQA algorithms has enormous practical significance. Recently, lots of objective IQA algorithms have been proposed. Based on the availability of a reference image, we can classify objective IQA algorithms into three categories: full-reference (FR), no-reference (NR) and reduced-reference (RR) methods. 1 Although many FR and RR methods which also achieve satisfying results have been proposed, 2 –5 NR methods that do not need any pristine reference knowledge to measure the quality scores have more room for improvement and practical value. Usually, NR-IQA methods aim to measure the objective quality scores of images with specific distortion types. 6 –8 However, methods which estimate the quality scores of overall images are more useful in practical applications and are called distortion-generic methods. In this work we focus on distortion-generic NR-IQA methods.
Most of the distortion-generic NR-IQA methods estimate the image quality by measuring the deviations from the Natural Scene Statistic (NSS) model that captures the statistical ‘naturalness’ of non-distorted images. 9 The BIQI and DIIVINE metrics are two-stage frameworks based on the NSS model for estimating quality, adopting a Gaussian scale mixture model to extract features from the wavelet coefficients of images. 10 , 11 The BRISQUE metric used scene statistics of locally normalized luminance coefficients to evaluate possible losses of naturalness in images, and then applied the losses to achieve the prediction of image quality. 12 The BLIINDS-II method, given an input image, used an NSS model to extract a set of features from Discrete Cosine Transform (DCT) coefficients of this image, then a Bayesian inference approach adopted the features to predict quality. 13 The M3 model utilized the joint statistics of two local contrast features, including the gradient magnitude map and the Laplacian of Gaussian response, to predict image quality. 14 Recently, some NR-IQA approaches used machine learning to construct a quality assessment model. Tang et al. defined a radial basis function integrating with a deep network to predict the perceived image quality. 15 First, the network was pre-trained in an unsupervised manner and labeled data was used to fine-tuned the network; then, the image quality scores were predicted by exploiting a Gaussian process regression. Bianco and Celona investigated the use of deep learning for distortion-generic NR-IQA. 16 They used Convolutional Neural Network (CNN) as a feature extractor and then exploited an Support Vector Regression (SVR) machine to predict the perceived quality scores.
Ye et al. presented an efficient unsupervised feature learning approach called CORNIA, which adopted several training and encoding methods, including K-means, sparse coding (SC), hard-assignment and soft-assignment (SA), amongst others. 17 Its experimental results show that SA encoding slightly outperformed SC encoding if using max-pooling to extract features. Ye et al. have achieved good generality and evaluation results. Theoretically, SC whose basis vectors resemble the receptive field of simple cells in the mammalian primary visual cortex (also known as the striate cortex and V1) is more suitable for obtaining the representation of images. 18 The reasons why SA encoding achieves better results compared with SC encoding in the approach of Ye et al. are that SA encoding adopts the max-pooling method to extract features and SC encoding ignores the sparsity of the coefficient matrix. Inspired by overcompleteness and sparsity of SC, 19 we propose a feature extraction framework in which a sparse representation matrix of salient patches is converted to a fixed-length feature vector for NR-IQA. More precisely, a spectral residual (SR) approach, that is an approach of saliency detection, is adopted to locate image salient regions where image patches are extracted. 20 In addition, to learn the overcomplete dictionary of SC and calculate the sparse representation matrix of salient image patches, the ℓ1-norm of sparse representation replacing ℓ0-norm is introduced. Then, the ℓ1-norm integrating with the max-pooling act as a feature detector to extract sparse features of salient regions (SFOSR) from the sparse representation matrix. And we adopt SFOSR, which can describe the sparsity of salient image patches over the overcomplete dictionary, to train a SVR machine and predict the quality scores. Lastly, the reason why we introduce saliency detection to NR-IQA is that sparse features of salient patches can achieve more satisfying performance in predicting the quality scores when we fix the size (the number of basis vectors) of the dictionary; that is, a small size dictionary learned from salient patches replacing a large size dictionary learned from original patches can also result in better performance, and this is proved in Section 3.2.
The LIVE, CSIQ and TID2013 databases are used to test the performance of our proposed approach. And experimental results prove that the SFOSR framework, as compared with other IQA algorithms, achieves excellent performance in terms of estimating image quality in cross database trials.
The rest of this paper is structured as follows. We first describe the quality estimation approach via SFOSR in Section 2. Section 3 provides the experimental results and corresponding analysis. Section 4 concludes the paper.
Proposed approach
There are four parts to the process of calculating the SFOSR of an image: extracting image patches from salient regions, learning an overcomplete dictionary, calculating sparse representation and performing sparse feature extraction.
Image patches of salient regions extraction
Usually, the human visual system (HVS) pays more visual attention to pixels from the salient regions of images. In other words, visual saliency captures more attention. Engelke et al. have shown that including information about visual saliency can improve the performance of the IQA metrics.
21
Based on this, we apply a SR approach to detect the salient regions.
20
Representing the information of saliency regions, SR is obtained by log-spectrum subtracting the averaged log spectrum. If

where F and
Considering that the output saliency map

The larger the saliency value, the more visual attention is given to a patch.
Patches whose saliency value si satisfy equation (3) are vectorized and arranged as rows of a matrix


The left column displays the original images. The middle column displays the saliency maps via SR. The right column displays salient image patches from the original gray images.
Dictionary learning
With the ability of explaining the most important part of the HVS, SC is suitable to achieve perceptual quality prediction, and its sparsification of natural images well describes the representation pattern of the HVS. This step involves learning an overcomplete dictionary from unlabeled learning images. Feng et al. have provided the process of adopting image patches to learn an overcomplete dictionary via SC.
23
Similarly, an overcomplete dictionary can be learned from a set of learning images to represent the local structures of the images. And salient image patches with

From
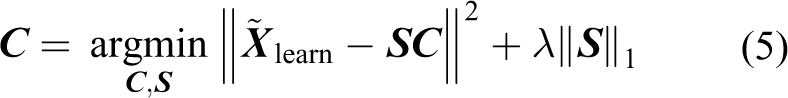
This problem can then be transformed into an unconstrained optimization problem, and we can adopt (5) to learn an overcomplete dictionary

The process of learning an overcomplete dictionary via SC. (a) is the projection map of the dictionary.
Sparse representation
Given an overcomplete dictionary

The process of obtaining the sparse expression for a tested image. (a) is the projection map of the dictionary, and (b) indicates the three-dimensional scatter plots of the sparse representation matrix S'.
Sparse feature extraction
We now have the sparse representation
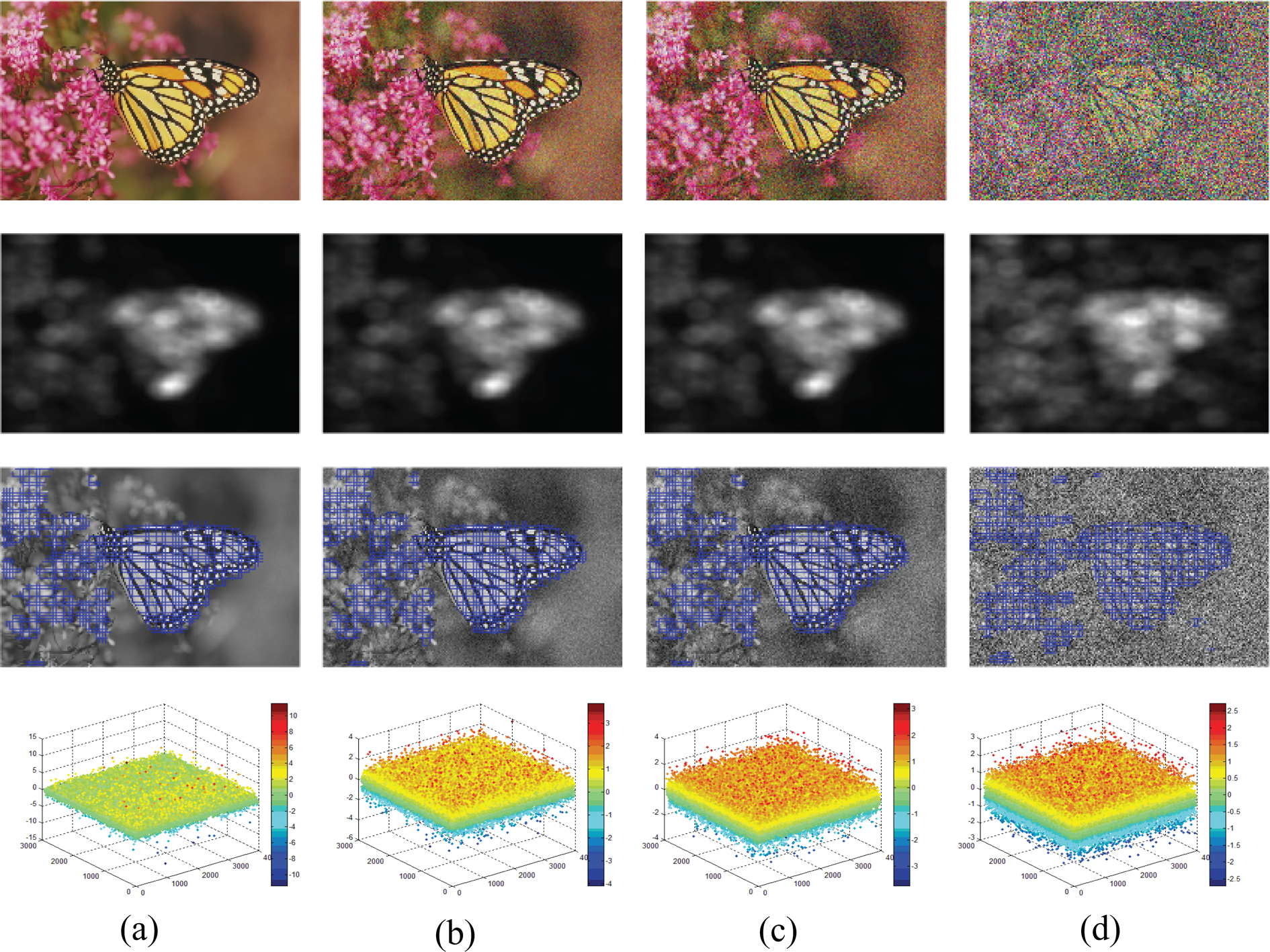
The three-dimensional scatter plots of sparse expression matrices for four images with white noise distortion, the degree of distortion is more and more serious from left to right, and the difference mean opinion score (see Section 3.1) values which indicate subjective scores for these images are 0, 41.17, 49.09 and 65.73 from left to right. The second row displays the saliency maps via SR. Image patches which will be extracted are coloured in blue in the third row. The last row shows the three-dimensional scatter plots of sparse expression.
Considering that the L1-norm is taken as a sparse penalty term to calculate the sparse representation, we add the L1-norm of the sparse representation acting as a part of the last output features. The sparse representation

where symbol vectors
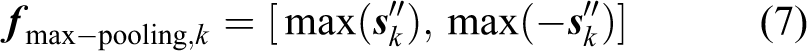
Experimental results
Databases and evaluation criteria
To evaluate the performance of SFOSR framework for NR-IQA, three subjective image quality evaluation databases, LIVE, CSIQ and TID2013, have been used for our experiment. The values of difference mean opinion score (DMOS) or mean opinion score (MOS) for images in these databases are provided as objective scores. To illustrate the performance of IQA metrics, four evaluation criteria are used, Spearman rank order correlation coefficient (SROCC), Pearson linear correlation coefficient (LCC), root-mean-squared error (RMSE) and mean absolute error (MAE). The prediction accuracy is measured by LCC, RMSE and MAE, and the prediction monotonicity is measured by SROCC. The closer to 1 that SROCC and LCC criteria score, the better the performance of IQA methods. The smaller the RMSE and MAE, the better performance of IQA methods. SROCC and LCC can be calculated by equations (8) and (9)

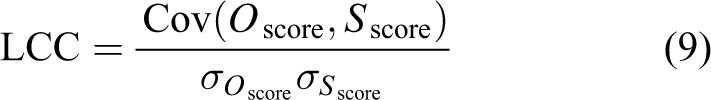
In these formulas,
In our experiments, 80% of samples were selected randomly as a training set for training the SVR model and the remaining as a testing set. In addition, there were 1000 train–test iterations for each experimental result in this section. The overcomplete dictionary was obtained from 240 images consisting of some reference images and images with all types of distortions from the LIVE and CSIQ databases fixing the size of image patches to 7×7 (w = 7,h = 7). In addition, the number of salient patches was decided via the corresponding saliency map for an image. In total, 618,188 salient patches were extracted from the 240 learning images to learn the overcomplete dictionary.
Impact of algorithm modules and parameters
In the SFOSR framework, some modules and parameters influence the performance. Here, we discuss two algorithm modules, which include saliency detection methods and feature extraction methods, and the parameter of the size of overcomplete dictionary. Results shown were conducted on the LIVE database with all types of distortions under consideration (80% samples for training and the rest for test).
Impact of saliency detection methods
Figure 5 shows that there are 12 groups of non-distortion-specific experimental results for evaluation measures (SROCC, LCC, RMSE and MAE) of saliency detection methods via SR, Shannon’s entropy and a method without saliency detection. Each group has six experimental results for different dictionary sizes including 200, 500, 1000, 2000, 3000, 4000. Through comparing this experimental data, we can conclude that adopting SR in NR-IQA can achieve better results when compared with Shannon’s entropy and with the method without saliency detection when the size of dictionary is fixed from the figure. In addition, a small sized dictionary learned from salient patches via SR can replace a large size dictionary learned from patches without using saliency detection. That a small sized dictionary can also result in good image assessment results is one of this framework’s advantages as compared with that presented by Ye et al. 17

Median LCC (a), SROCC (b), RMSE (c) and MAE (d) across 1000 train–test random splits of the LIVE database, with respect to the size of dictionary. Three modules (SR, Shannon’s entropy and a method without saliency detection) are taken into consideration; for each of the modules, the results of evaluation criteria for different dictionary sizes (200, 500, 1000, 2000, 3000, 4000) are provided.
Impact of dictionary size
Here we pay our attention to the effect of different overcomplete dictionary sizes on evaluation measures. It is obvious that the experimental results of this framework get better as the number of basis vectors in the dictionary increase, as shown in Figure 5, and that satisfying results can be obtained when the dictionary size is 4000.
Impact of feature extraction from sparse matrix method
In addition to feature extraction via the ℓ1-norm integrating with max-pooling, we also tried using feature extraction via max-pooling and the ℓ1-norm in our experiment. We tested these three feature extraction methods over the dictionary with 4000 basis vectors in the LIVE database, and the results are displayed in Figure 6. In conclusion, the feature extraction method via the ℓ1-norm integrating with max-pooling results of sparse representation can improve overall performance in NR-IQA.

Median SROCC of different feature extraction methods fixing the size of dictionary to 4000.
Performance of SFOSR
The LIVE, CSIQ and TID2013 databases were utilized as the benchmark databases to test the performance of our approach, and the overcomplete dictionary with 4000 basis vectors was used for our experiment. The median values of SROCC and LCC across the 1000 iterations are chosen as the performance evaluation criteria of IQA metrics. The full-reference metrics – PSNR, SSIM – and the blind metrics – BIQI, DIIVINE, BLINDS-II, BRISQUE, M3, CORNIA – are compared with the proposed SFOSR framework. The results of SROCC and LCC obtained using the LIVE, CSIQ and TID2013 databases for IQA metrics are given in Tables 1–5, and best results are marked in bold.
Median Spearman rank order correlation coefficient (SROCC) across 1000 iterations on the LIVE database.

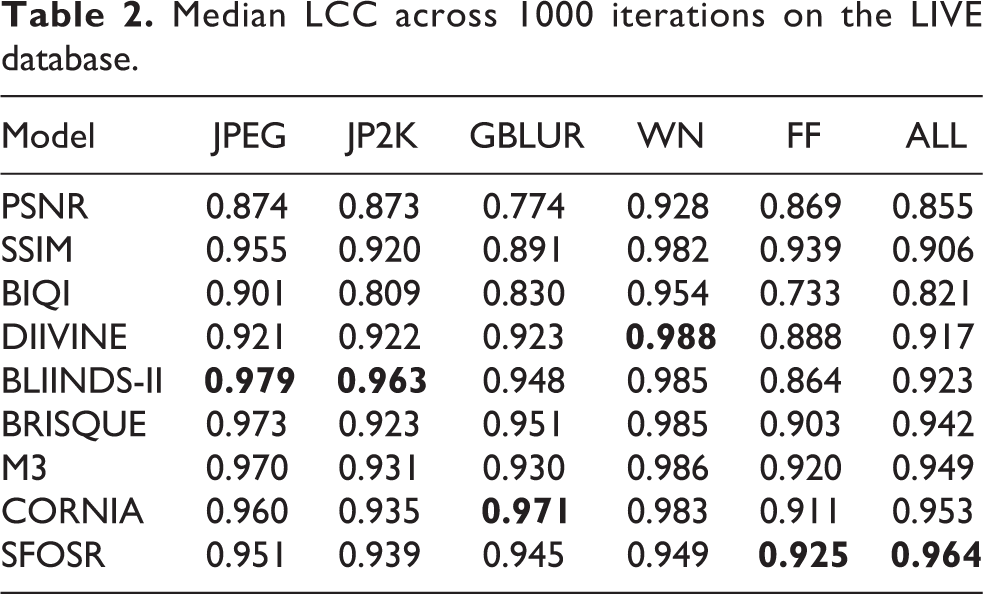
Median LCC across 1000 iterations on the LIVE database.
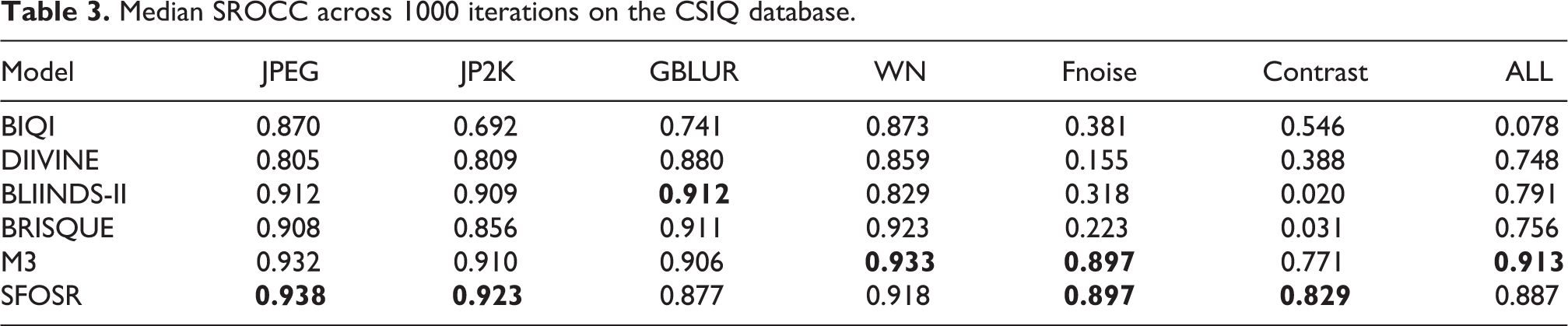
Median SROCC across 1000 iterations on the CSIQ database.
Median LCC across 1000 iterations on the CSIQ database.

Median SROCC across 1000 iterations on the TID2013 database.

Results from the LIVE database are shown in Tables 1 and 2. From these tables, it is obvious that our IQA metric via the SFOSR framework is better than that of the other general purpose IQA methods in the experiment including all samples. Besides this, our proposed method also achieves good performance for distortion-specific samples. In addition, Figure 7 – the scatter plots that the predicted DMOS versus the subjective DMOS – roughly illustrates the performance of SFOSR, and these plots also demonstrates that our algorithm framework can achieve stable and good performance across different distortions and the entire LIVE database.
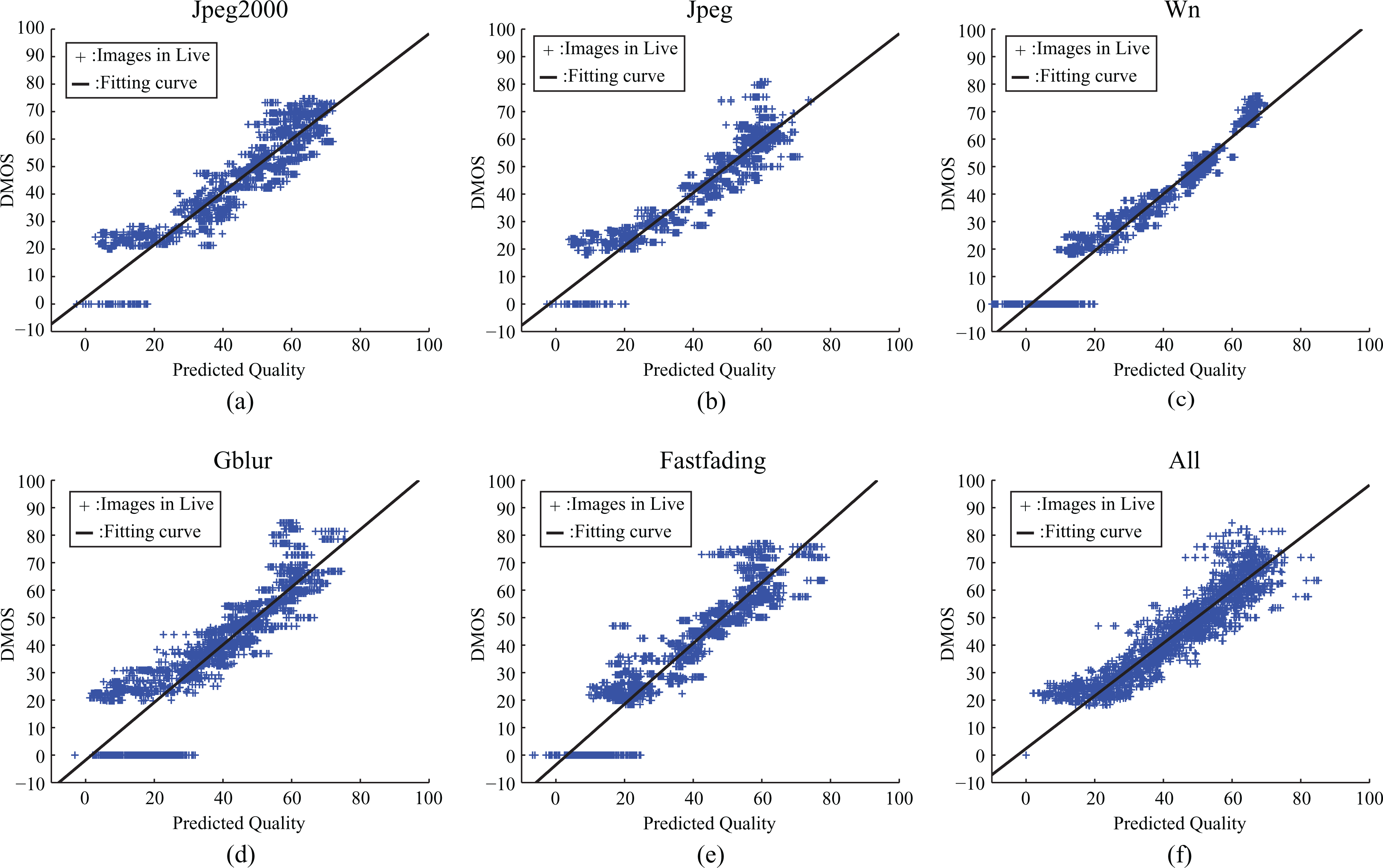
The scatter plots of subjective scores (DMOS) versus predicted quality scores obtained by SFOSR on the LIVE database. In each plot, plus signs (+) colored in blue represent the values (predicted quality score, DOMS) of images, and the black line represents the fitting curve of these values by using the least-squares method.
Results from the CSIQ database are shown in Tables 3 and 4, where we tested BIQI, DIIVINE, BLINDS-II, BRISQUE, M3 and our proposed framework. It is clear that SFOSR and M3 significantly outperform most of the other methods. Compared with M3, SROCC and LCC in the distortion type named ‘global contrast decrements’, there is a considerable improvement using SFOSR. Table 5 displays the SROCC tested on TID2013 adopting BRISQUE, M3 and SFOSR. Although the SROCC of SFOSR in some distortion types, such as mean shift, contrast change and change of color saturation, are not satisfying, SFOSR achieves superior performance in most distortion types compared with the other two methods. For most of distortion types in the TID2013 database, the SROCC results in Table 5 illustrate that the dictionary learned from images in the LIVE and CSIQ databases does possess a certain generalization ability.
Cross-database test
In order to illustrate the cross-database performance of our metric, we conduct a database independence experiment for our approach by training on the LIVE database and testing on the CSIQ database. We chose CSIQ as the test database because the scenes of samples in CSIQ are very different from scenes in the LIVE database. There are four distortions in common between the two databases, including JPEG2k, JPEG, WN and GBLUR, and we only test SROCC and LCC on these four common distortions. For every distortion type or non-distortion test, the SVR model is trained on features from the LIVE database, then predicts the assessment results of samples in the CSIQ database. Table 6, which shows the SROCC in the cross-database test, illustrates that our approach has good database independence.
Database independence test: trained on LIVE and tested on CSIQ.

LCC: Pearson linear correlation coefficient.
Conclusions
This paper presented a feature extraction framework named SFOSR for NR-IQA. This algorithm utilized a sparse representation matrix as the coefficient matrix to extract sparse features. We detailed the sparse feature extraction framework. Additionally, we discussed the impact of dictionary size and two algorithm modules for NR-IQA performance. Further, we compared the performance of SFOSR with other general purpose IQA metrics in the LIVE, CSIQ and TID2013 databases. The experiments conducted show database independence and show that the proposed algorithm has good generalization ability and performs better or on par with some general purpose IQA algorithms.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.