
Abstract
Background:
Despite the importance of early identification and treatment, postpartum depression often remains largely undiagnosed with unreported symptoms. While research has identified several factors as prompting help-seeking for postpartum depression symptoms, no research has examined help-seeking for postpartum depression using data from a multi-state/jurisdictional survey analyzed with machine learning techniques.
Objectives:
This study examines help-seeking among people with postpartum depression symptoms using and demonstrating the utility of machine learning techniques.
Methods:
Data from the 2016–2018 Pregnancy Risk Assessment Monitoring System, a cross-sectional survey matched with birth certificate data, were used. Six US states/jurisdictions included the outcome help-seeking for postpartum depression symptoms and were used in the analysis. An ensemble method, “Super Learner,” was used to identify the best combination of algorithms and most important variables that predict help-seeking among 1920 recently pregnant people who screen positive for postpartum depression symptoms.
Results:
The Super Learner predicted well and had an area under the receiver operating curve of 87.95%. It outperformed the highest weighted algorithms which were conditional random forest and stochastic gradient boosting. The following variables were consistently among the top 10 most important variables across the algorithms for predicting increased help-seeking: participants who reported having been diagnosed with postpartum depression, having depression during pregnancy, living in particular US states, being a White compared to Black or Asian American individual, and having a higher maternal body mass index at the time of the survey.
Conclusion:
These results show the utility of using ensemble machine learning techniques to examine complex topics like help-seeking. Healthcare providers should consider the factors identified in this study when screening and conducting outreach and follow-up for postpartum depression symptoms.
Introduction
Approximately 13% of individuals in the United States are estimated to experience postpartum depression (PPD), 1 which presents as a major depressive episode beginning during the postpartum period. 2 Symptoms include problems with sleep unrelated to care for the infant, anxiety, irritability, excessive worry about health and care of the infant, and in some instances suicidal ideation and thoughts of harming the baby. 3 PPD results in a wide range of negative outcomes for mothers, children, and the mother–child relationship.4–6
Longer and more severe PPD episodes are linked to poorer outcomes for infants and children highlighting the importance of early diagnosis and treatment. 6 Untreated PPD has been shown to result in poorer outcomes for mothers when compared with treated mothers.7–9 Despite the importance of early identification and treatment, PPD often remains largely undiagnosed 10 with symptoms unreported by patients.11–13
In addition to research that has identified factors related to diagnosis of PPD,5,14–16 several factors have been identified as prompting help-seeking.17–28 Demographic factors such as income, education, and race or ethnicity can function as facilitators or barriers to care. Pregnant people with lower incomes may not be able to afford care because of lack of insurance coverage, less paid leave from work, childcare coverage, or transportation costs.17,23–26 Race and ethnicity are associated with social barriers such as lack of trust in the healthcare system, lack of culturally sensitive care, or cultural beliefs that stigmatize help-seeking.19,20,23–28 Education and mental health literacy are also germane. If a person or a family member has sought help in the past, they usually have a better understanding of symptoms and the benefits of mental health services and how to access them.17–27
A 2009 study used Pregnancy Risk Assessment Monitoring System (PRAMS) data from Utah to examine factors associated with help-seeking among 337 people who had PPD symptoms. 19 They report that help-seeking during pregnancy, living in a rural setting, and having an infant in neonatal intensive care were associated with postpartum help-seeking. Variables that decreased likelihood of help-seeking included non-White race, Hispanic ethnicity, and reporting experiencing emotional abuse.
More recently, a 2020 analysis was conducted using PRAMS data from New York City to explore help-seeking among 618 people who had PPD symptoms. 20 They found help-seeking was associated with a mental health history, being an Asian Pacific Islander, and having visited a health care provider for chronic illness.
No research has examined help-seeking for PPD using data from a multi-state/jurisdictional survey analyzed with machine learning techniques to address the many potential factors that may influence help-seeking. However, prior work, using electronic health records,29–31 survey data,32–36 and social media, 37 has demonstrated the utility of machine learning techniques to create algorithms to assist with PPD screening and prediction. For example, Natarajan et al. 32 used survey data and discovered that a large number of weak predictors interact to strongly predict presence of PPD symptoms—demonstrating that PPD symptoms can be predicted from sociodemographic survey data. A recent study by Shin et al. 33 demonstrated that PPD symptoms can be predicted from a large, national survey using machine learning techniques. Using data from the 2012–2013 PRAMS data set, they developed nine machine learning models and identified a set of common variables across all the models. Machine learning algorithms may be useful to predict outcomes beyond PPD screening, such as help-seeking. 38 Calls have been made to address psychiatric topics in ways that can integrate the workings of the brain with psychosocial influences, and data-driven machine learning can provide one way to address this complexity. 39 Traditional analysis methods may be unable to adequately model and address the complexity of factors that influence behaviors around topics such as help-seeking for PPD. Identifying the key variables related to help-seeking can provide important information related to clinical practices as well as prevention efforts.
In this study, we use data from a multi-state/jurisdictional survey matched with birth certificate data to assess a wide range of risk factors to identify the most important variables to predict help-seeking behavior for participants with PPD symptoms.
Method
Measures
This study used cross-sectional data from a sample of individuals from six US states/jurisdictions with a recent birth (2–4 months postpartum) who participated in the 2016–2018/Phase 8 data collection period of the Centers for Disease Control and Prevention (CDC)-sponsored PRAMS. 40 The PRAMS data set shared with researchers includes a set of core (required for all participating states/jurisdictions) self-report questions, 41 standard (optional), 42 and state-specific questions and linked birth certificate data. 43 Multiple items and outcomes contained in the PRAMS questionnaires have demonstrated acceptable validity evidence, including PPD measures; 44 participation in Special Supplemental Nutrition Program for Women, Infants, and Children (WIC); use of Medicaid to pay for delivery; and breastfeeding initiation. 45
Some of the questions from the questionnaire and/or birth certificate data used in this study include race; ethnicity; smoking or drinking before, during, or after pregnancy; maternal weight gain; prenatal and postnatal care; complications during pregnancy; delivery experiences; pregnancy outcomes (e.g. birth weight, gestational age at delivery, length of hospital stay); insurance status before, during, and after pregnancy; and maternal mental health before, during, and after pregnancy. The outcome, help-seeking, was based on the following question: “Since your new baby was born, have you asked for help for depression from a doctor, nurse, or other healthcare worker?” and coded “0” for no and “1” for yes. 42 PPD symptoms were assessed by the PRAMS questionnaire using two items: (1) “Since your new baby was born, how often have you felt down, depressed, or hopeless? Always Often Sometimes Rarely Never” and (2) “Since your new baby was born, how often have you had little interest or little pleasure in doing things you usually enjoyed? Always Often Sometimes Rarely Never.” 41 Individuals who respond “always” and/or “often” for either question are considered to screen positive for PPD.46–48 A full list of variables and corresponding coding used in the current analysis is contained in the Supplemental Materials, Table 1.
Data are publicly available for researchers and were obtained upon approved application via the CDC’s formalized PRAMS proposal process. 40 This research was approved by the first author’s university institutional review board under protocol number 20-005 as exempt, secondary research for which consent was not required.
Sample
Using birth certificates, each state/jurisdiction participating in PRAMS provides a random, stratified sample of between 100 and 250 individuals who have given birth in the past month. 49 Certain populations are oversampled based on the needs of the state/jurisdictions; most oversample for low birth weight deliveries and some create stratified samples based on race, ethnicity, geographic location, or other factors. 49 The total annual sampling frame for each state/jurisdiction ranges between 1000 and 3000 participants. 50 Currently, only Connecticut, Nebraska, New Hampshire, New York, Texas, and New York City include the optional, standard item which assesses the help-seeking outcome variable. The full sample was 14,570 individuals who completed the assessment in those locations. Given we are examining help-seeking among individuals with PPD symptoms, our sample was further limited to only include those who screen positive for PPD symptoms in these locations (n = 2054) (see Figure 1). The sample was further reduced to 1920 to only include individuals who (1) had a live birth and whose infant was alive at the time of data collection and (2) those 18 or over at the time of data collection. This final sample represented 13.2% of the total number of individuals who completed the assessment in the six states/jurisdictions.

Sample selection and PRAMS data preparation steps.
Data analysis
Means, frequencies, and bivariate tests were conducted using the PRAMS complex survey weighting with Stata 15.1. 51 Several steps were followed to clean, preprocess, train, and test the data (Figure 1).
Data preprocessing
Stata version 15.1 51 was used to clean the data and the R recipes package 52 was used for preprocessing. We started with 551 variables in our data set (see Figure 1). We cleaned our data by removing string variables and variables that had missing data due to skip patterns or were not asked by all six states/jurisdictions included in the analysis. Next, we examined variables with missing data. Most variables had less than 10% missing data, which has been suggested as a cut off for concern with regard to bias. 53 Four variables related to paternal factors (race, education, Hispanic ethnicity, and acknowledgment of paternity) and one related to poverty line status had missing data greater than 10%. Further examination revealed these patterns of missingness were not random and were removed from the analysis as it would be inappropriate to impute the missing data. 54 We then imputed missing data for the remaining variables using k-nearest neighbors, which used all the remaining variables to impute missing values with the k-nearest neighbors algorithm. Following this step, we removed sparse variables with little to no variance. Sparse variables were defined as (1) having a frequency ratio of greater than 95:5 for most prevalent to second most prevalent value, and (2) percent of unique values divided by the sample size below 10. Finally, we tested for multicollinearity, using correlation or Cramer’s V as appropriate, and removed redundant variables that correlated with other variables greater than 0.6. However, some variables with correlations greater than 0.6 were retained based on theory. Our final data set was reduced to 63 variables. Data were separated randomly into training and test data sets, with 70% of the data used to train the model and the remaining 30% used to test model performances.
Training
An ensemble method, Super Learner 55 in R, was used. Super Learner uses a v-fold cross-validation with a library of algorithms and arrives at a final, best fitting weighted combination of those algorithms.56,57 We included the following algorithms in the Super Learner ensemble library: stepwise logistic regression, random forest, bagged classification and regression trees (bagged CART), stochastic gradient boosting (GB), conditional random forest, neural networks, model averaged neural network, Bayesian additive regression trees (BART). After training, we tested the Super Learner ensemble on the remaining test data. We examined the area under the receiver operating curve (AUC) for each individual algorithm plus the Super Learner model, which is the combination of the algorithms. AUC is a measure of discrimination between the classes of the outcome and provides a measure of the method’s ability to distinguish between observations with and without the outcome of interest. Relative to other measures such as accuracy, F1 score, and precision, the AUC has been demonstrated to be better in terms of consistency and discrimination even with imbalanced classes 58 and invariant to class proportion changes.59,60 We also examined the variable importance for the highest weighted algorithms.
Results
Of the 1920 participants included in the analysis, most were White (59.3%), followed by Black (19.7%) and then Chinese, Japanese, Filipino, or other Asian (11.6%) (see Table 1 for the weighted percentages). Almost a third of participants (30.0%) were Hispanic/Latino (30.0%). The majority were married (55.6%), between the ages of 25 and 34 (52.9%), and had 12 or more years of education (83.6%). A little over half of the participants had their delivery paid for by Medicaid (54.0%). Most (83.5%) attended a maternal postpartum visit. Only 25.3% reported seeking help from a healthcare provider for depression symptoms after the delivery of their baby despite experiencing depression symptoms.
Full sample participant characteristics (n = 1920).

PPD: postpartum depression.
Table 2 provides the results of the Super Learner model. The highest weighted algorithms, or those that contributed the most to the final model, were conditional random forest and stochastic gradient boosting. The AUC for the overall model was 87.95% with AUC for the algorithms ranging from 84.18% (bagged CART) to 87.52% (BART).
Super Learner weights and AUC’s for full sample (n = 1920).
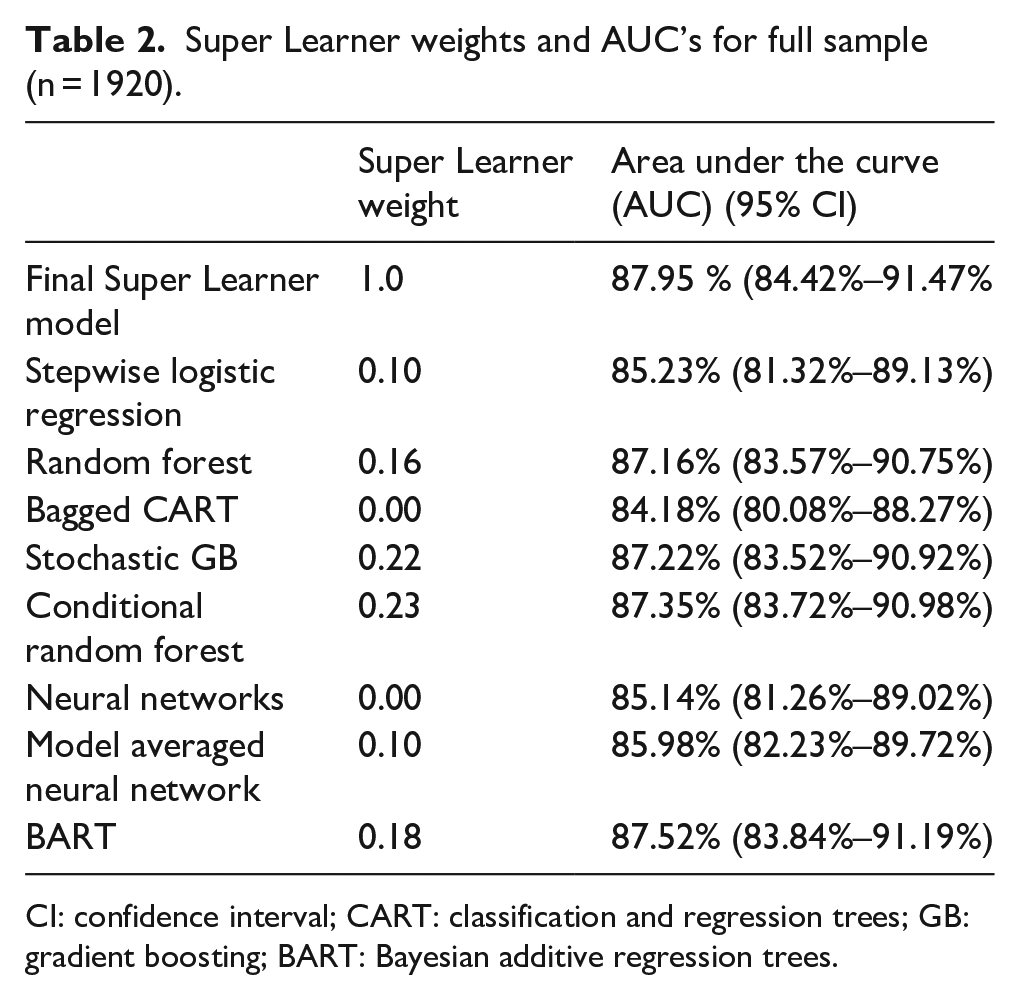
CI: confidence interval; CART: classification and regression trees; GB: gradient boosting; BART: Bayesian additive regression trees.
The variables with the 10 highest importance or coefficient estimates were examined for the highest weighted models (conditional random forest and stochastic gradient boosting) as reported in Table 3. The variables are listed in order of overall importance in the models and weighted frequencies and percentages (or means and standard deviations for interval-level data) are reported for each variable by help-seeking status. Although there was some variability in the variable rankings, receiving a PPD diagnosis was the most important variable in both algorithms in predicting help-seeking. Only 17.4% of participants who did not report receiving a PPD diagnosis sought help for PPD compared to 61.2% of those who had received a PPD diagnosis. Similar results were found for depression during pregnancy—those who reported having been told they were depressed during pregnancy were much more likely to seek help for PPD than those not experiencing depression during pregnancy (54.6% versus 13.8%). Interestingly, maternal body mass index (BMI) when the questionnaire was completed also appeared as a top predictor, with those with higher BMI more likely to seek help. Other variables ranking in the top 10 importance/size across the three algorithms included (1) the state in which the mother lives (those in Connecticut, Nebraska, and New Hampshire were most likely to seek help), (2) maternal race (white individuals, Native American people, and those reporting mixed race were most likely to seek help), and (3) depression 3 months prior to pregnancy.
Full sample (n = 1920) selected algorithms’ top 10 important variables: means/frequencies, bivariate tests, and algorithm rankings.

GB: gradient boosting; OR: odds ratio; CI: confidence interval.
Bold indicates top 10 variables across all three algorithms, italics indicates top 10 variables across at least two algorithms.
Test unable to be calculated because stratum with single sampling unit.
Variable did not rank as one of the top 10 important variables in this algorithm.
Sensitivity analysis
Given the high number of participants who attended a postnatal visit for themselves (83.5%), we repeated the analysis with only the individuals who attended the visit. This permitted the inclusion of a previously removed variable (removed due to skip patterns) which asked, “During your postpartum checkup, did a doctor, nurse, or other health care worker do any of the following things . . . Ask me if I was feeling down or depressed.” We included this question as a proxy for PPD screening to examine whether it was related to help-seeking. This new model included 1656 cases with 503 (27.7%) individuals reporting help-seeking. The highest weighted algorithms for this model were neural networks and random forest. The AUCs for the overall model and the individual algorithms (Table 4) were similar to those reported in the full sample (see Table 2). The AUC for the overall model was 87.08% with the AUC for the algorithms ranging from 84.66% (random forest) to 88.96% (stepwise logistic regression).
Super Learner weights and AUCs for postpartum visit attendees only sample (n = 1656).

CI: confidence interval; CART: classification and regression trees; GB: gradient boosting; BART: Bayesian additive regression trees.
The variables with the highest importance or coefficient estimates were examined for the highest weighted models (neural network and random forest) (see Table 5 for ranking of top 10 variables and survey weighted bivariate analyses).
Postpartum visit attendees only sample (n = 1656) selected algorithms’ top 10 important variables: means/frequencies, bivariate tests, and algorithm rankings.

OR: odds ratio; CI: confidence interval.
Bold indicates top 10 variables in both algorithms.
Test unable to be calculated because stratum with single sampling unit.
This analysis permitted inclusion of additional variable which assesses if participant was asked by health care provider if they are “depressed or down.” This variable was included in this list to serve as a proxy for “PPD screening” to examine relationship with help-seeking.
Variable did not rank as one of the top 10 important variables in this algorithm.
Similar to the full data analysis, receiving a PPD diagnosis was the most important variable in both algorithms in predicting help-seeking. Three other variables were among the most important in both algorithms in predicting help-seeking: (1) depression during pregnancy, (2) the state in which the mother lives, and (3) maternal race. Bivariate trends for these variables were similar as to those for the full data set. Finally, while having been asked whether they were down or depressed was significantly related to help-seeking, this was not among the most variables in predicting help-seeking.
Discussion
The current research answers important questions about help-seeking among patients with PPD symptoms. First, while all 1920 participants screened positive for PPD symptoms, only 25.3% of participants sought help from a health care provider for PPD symptoms. Next, this research demonstrated the utility of an ensemble machine learning algorithm, Super Learner, to develop a best fitting model weighted by algorithm to identify the key variables associated with help-seeking. The AUCs for the overall model and the individual algorithms were high (87.95 % for the overall model). The most important variables were receiving a PPD diagnosis, depression during pregnancy, maternal BMI at the time the survey was completed, the state in which the mother lives, maternal race, and depression 3 months prior to pregnancy. When we reran the analysis with only those who attended a postpartum health care visit for themselves, the AUC remained high (87.08% for overall model). The most important variables in these algorithms were similar to the previous analysis, with variables related to depression history among the most important. Although most participants reported having been asked whether they were down or depressed (80.4%) and this variable had a significant bivariate relationship with help-seeking, this was not a top 10 variable in predicting help-seeking.
Similar to previous research with help-seeking among those with PPD, in this study, variables related to personal depression history were also among the most important predictors for help-seeking for PPD symptoms.19,20,24–27 Factors such as low mental health literacy, negative attitudes toward help-seeking, and low emotional clarity have all been demonstrated to be related to lack of personal and family experience with depression.18,21,24–27 Increased levels of mental health literacy have been found to be related to more positive attitudes toward professional mental health help-seeking among recently pregnant individuals. 27 Recent research suggests that recently pregnant individuals and the public have misperceptions regarding perinatal mental health disorders in terms of symptoms, severity, risk, difference from “the baby blues,” and treatment, and these misperceptions can influence help-seeking. 24 For example, believing perinatal mental health disorders are the same as “baby blues” can minimize the experience and discourage help-seeking. This research also suggests that most individuals experiencing perinatal mental health disorders prefer to seek informal help through friends and family believing it is effective treatment, rather than seek formal treatment, which is often necessary. 24 The current research reinforces the need to promote PPD education among individuals, families, and the public.
Also similar to previous research, we found that maternal race was an important predictor for help-seeking,19,20,23,25,26 with lowest help-seeking for Asian American people followed by Black individuals. Cultural differences have a large impact on the manifestation of mental health concerns, help-seeking, provider interpretation of symptoms, and the relationship formed between the provider and patient. 61 Indeed, research has consistently demonstrated that mental health help-seeking is low among Asian American individuals.23,62,63 Some reasons for this disparity include stigma and discrimination, 64 negative attitudes toward mental health services, 64 preference for informal (e.g. friends and family) rather than formal assistance (e.g. health care provider), 65 and internalized stereotypes about the experience of mental health concerns among those who are Asian American. 66 In addition, barriers to help-seeking and mental health utilization include a lack of culturally and ethnically relevant mental health services and providers.23,65 Help-seeking may be lower among Black individuals experiencing PPD symptoms due to stigma related to depression,61,67 a lack of trust for providers as a result of historical oppression and trauma,61,68 as well as systematic discrimination and racism. 61 However, the impact of racism on help-seeking is unclear, as Bossick and others found that emotional upset due to racism was associated with greater PPD symptoms but not with decreased help-seeking. 28
As noted above, when analyses were replicated with only those who attended a postpartum maternal health provider visit, depression before, during, and after pregnancy remained among the most important variables for predicting help-seeking. This revised analysis also permitted the inclusion of the variable “Asked by health care provider if they are depressed or down” that can serve as a proxy for PPD screening. Although reporting having been asked whether depressed or down demonstrated a significant positive relationship with help-seeking, interestingly, it was not among the most important predictors. While not a top predictor for help-seeking behavior in the current research, research demonstrates screening for PPD is critical, as it has shown an absolute risk reduction in PPD prevalence ranging between 2% and 9%. 69 Recent efforts in the United States to increase screening for PPD include Medicaid coverage of maternal screening during child well visits. This represents an important step in increasing maternal screening since Medicaid currently covers nearly half of all pregnancies in the United States. 70 Under Medicaid fee-for-service policies, currently, 43 states and Washington D.C. recommend, require, or allow coverage for screening; 71 with only 8 of those states requiring PPD screening. In addition, some governing bodies specify screening should occur a minimum of one point in time, 72 while others such as the American Academy of Pediatrics suggest a more robust PPD screening schedule at 1, 2, 4, and 6 months during well-child visits. 73 More robust screening schedules provide additional opportunities to catch PPD symptoms when they are occurring.
Ensuring appropriate screening is only the first step to increase help-seeking for PPD symptoms. The provider response to screening is critical, as is the relationship between the provider and patient, and provider attitude and response to the individual’s disclosure.74–76 For example, feeling like one’s concerns are being dismissed or minimized will prevent individuals from further disclosure, while feeling encouraged or taken seriously will increase comfort and willingness to share. Having established and supportive relationships with providers will also facilitate help-seeking. 75 Furthermore, provider outreach and follow-up is critical to increase patient help-seeking and treatment initiation. 75
Benefits and limitations of machine learning ensemble methods
This analysis also demonstrated the utility of machine learning ensemble methods with data sets with many variables. These data-driven methods can successfully address the nonlinear and complex relationships that influence mental health-related behaviors like help-seeking. 39 Machine learning models, such as random and conditional forest, are effective at handling multidimensional and complex data.77,78 Ensemble models typically include techniques that are nonlinear and nonparametric and therefore are flexible and robust to many different data types, yet can still find good fitting models. 78 Instead of using a single model or method, we can improve model accuracy by gathering models into ensembles; the Super Learner improves model accuracy by combining several algorithms into a weighted average resulting in typically better performance than any single model.57,78,79 A strength and recommendation for implementing the Super Learner is to include a mix of various algorithms in the Super Learner and to evaluate not only the final model but each algorithm.57,79 Using a mix of algorithms in the Super Learner allows for confidence in overall performance since even though an individual algorithm may do well on some observations’ predictions, the individual algorithm’s overall performance could be worse than the Super Learner’s. 57
Furthermore, machine learning models, including those that use ensemble methods, are good at creating models that can generalize to new data. Machine learning techniques include the random division of the data set into a training data set to develop the model and then a test data set to test the model with new data. If the pool of data is small, data splitting is a critical decision as a small test set’s ability to judge performance is limited. 60 However, for large data sets, the size of training and test sets is less critical. A typical split in the data might be 80% for training and 20% for testing. 60 Vabalas et al. 80 showed that the train/test split approach produces robust and unbiased performance estimates regardless of sample size. However, the higher the ratio of predictors to the number of observations, the more likely the machine learning algorithm will overfit the data and lead to poor performance on test data. 80 In our analysis, since we have a relatively low number of predictors, our use of the 70% training and 30% testing split is justified. In addition, our test data set did a good job with prediction (e.g. AUCs in range of 0.8), suggesting our model would also predict well to a new data set that contained similar variables. 59 Finally, the Super Learner is also adaptive and robust for small samples while controlling for overfitting. 57
There are, however, limitations associated with ensemble methods. Ensemble models are more complex and can often lack of interpretability at the expense of having a very accurate predictive model. 78 Compared to single-method models such as linear regression or random forest, more accurate prediction comes at the expense of model complexity; it is more challenging to determine the exact nature of relationships or to see which variables are important.78,79 This necessitates examination of bivariate relationships and comparison of variable importance across the different methods to help interpret relationships and findings. In addition, ensemble methods including the Super Learner are computationally intense requiring greater computing power and time compared to more traditional or single algorithm methods.78,79
Limitations and future research
This research is not without limitations. The item assessing the outcome, help-seeking, was only included in six states/jurisdictions, hindering our ability to generalize to the rest of the United States or other countries. After limiting our sample to those with PPD symptoms and other inclusion criteria (e.g. live birth/live infant during survey and participant is 18 or over), our sample comprised 13.2% of the total sample, which matches the current population prevalence estimates of PPD. 1 Given the random sampling methods used by PRAMS, our findings should be representative for the six locations where this topic is assessed, hence providing the most comprehensive possible examination of this topic in the United States. This limitation of our research also highlights the need for greater systematic data collection and reporting on this topic.
An additional limitation includes the loss of variables during data preprocessing including variables with low variability, items that were missing as a result of skip logic, or because they were not asked by all locations. These items may have important implications for help-seeking among participants with PPD but could not be assessed in this study. Future research may examine these potentially related topics using smaller samples that have asked the relevant questions or are not missing data due to skip logic.
In addition, while much of the PRAMS data are based on birth certificate information, in this study, the outcome was a single, self-reported item from the questionnaire. As such, the outcome is subject to the limitations associated with self-report data including recall bias, or the inaccurate or incomplete memory of an experience, which may have influenced the quality of the data reported in this study. 81 However, maternal recall of pregnancy-related behaviors, pregnancy outcomes, and postpartum behaviors such as breastfeeding have been found to be highly accurate when compared to patient charts, even as much as 30 years postpartum.82–84
In this study, among those who attended a postpartum visit for themselves, we do not know when their postpartum visit occurred, how many times the participant may have been asked about their own depression, nor when their present symptoms may have started. While PPD symptom onset typically occurs in early postpartum, or within 4 weeks of birth, late symptom onset (weeks 5–12 postpartum) can occur.85,86 Consequently, it is possible that participants’ symptoms may have started after their provider visit. Future research should replicate and confirm the results of this study using medical records rather than self-reported data.
Finally, this research was conducted using data gathered just prior to the start of the COVID-19 pandemic. Compared to before the pandemic, the prevalence of PPD symptoms has been generally found to have increased, with estimates ranging from 7% to 80.8% among recently pregnant people. 87 Risk factors such as lockdown, isolation, job loss, reduced access to healthcare, loss of childcare services, and fear of the baby contracting COVID-19 generally contributed to the increase in symptoms. 87 While there has been an increase in need for mental health services during the pandemic, 87 research has just started to examine the prevalence of help-seeking among individuals with PPD symptoms during and post-pandemic. 88 Qualitative work suggests that reduced access and concerns about in-person appointments may have prevented in-person help-seeking for maternal mental health concerns and virtual alternatives were unable to adequately fulfill these needs. 89 It will be important to replicate this research using data collected after the start of the pandemic.
Conclusion
This study demonstrates that machine learning techniques can assist providers in identifying individuals who might be hesitant to ask for help for PPD symptoms. Specifically, findings suggest that having a history of depression before or during pregnancy increases the likelihood of asking for help from health care providers for depression and supports previous research which proposes that people of color may be less likely to seek help for PPD. Healthcare providers should be cognizant of these factors when screening for PPD and conducting outreach and follow-up for PPD symptoms.
Supplemental Material
sj-docx-1-whe-10.1177_17455057221139664 – Supplemental material for Using machine learning to predict help-seeking among 2016–2018 Pregnancy Risk Assessment Monitoring System participants with postpartum depression symptoms
Supplemental material, sj-docx-1-whe-10.1177_17455057221139664 for Using machine learning to predict help-seeking among 2016–2018 Pregnancy Risk Assessment Monitoring System participants with postpartum depression symptoms by Rebecca Fischbein, Heather L Cook, Kristin Baughman and Sebastián R Díaz in Women’s Health
Footnotes
Acknowledgements
This research would not be possible without the PRAMS Working Group, Centers for Disease Control and Prevention (CDC), as well as the PRAMS participants.
Declarations
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.