
Abstract
Face recognition plays an important role in many robotic and human–computer interaction systems. To this end, in recent years, sparse-representation-based classification and its variants have drawn extensive attention in compress sensing and pattern recognition. For image classification, one key to the success of a sparse-representation-based approach is to extract consistent image feature representations for the images of the same subject captured under a wide spectrum of appearance variations, for example, in pose, expression and illumination. These variations can be categorized into two main types: geometric and textural variations. To eliminate the difficulties posed by different appearance variations, the article presents a new collaborative-representation-based face classification approach using deep aligned neural network features. To be more specific, we first apply a facial landmark detection network to an input face image to obtain its fine-grained geometric information in the form of a set of 2D facial landmarks. These facial landmarks are then used to perform 2D geometric alignment across different face images. Second, we apply a deep neural network for facial image feature extraction due to the robustness of deep image features to a variety of appearance variations. We use the term deep aligned features for this two-step feature extraction approach. Last, a new collaborative-representation-based classification method is used to perform face classification. Specifically, we propose a group dictionary selection method for representation-based face classification to further boost the performance and reduce the uncertainty in decision-making. Experimental results obtained on several facial landmark detection and face classification data sets validate the effectiveness of the proposed method.
Keywords
Introduction
In robotic and human–interaction systems, it is crucial for a computer to know more information of a customer, such as the identity, gender, age, behaviour, emotion and so on. 1 –5 Among these labels/attributes, the identity of a customer might be the most important information for a robot. With this information, the robot could provide customised services thus to improve users’ experiences significantly. To achieve this goal, a facial recognition system can be deployed on the robot or on a cloud server. For example, as shown in Figure 1, a healthcare robot can capture the facial image of a patient and send the image to the cloud server via a high-speed 5G wireless communication network. Then the cloud server can process the received facial image by searching the database and send the identity and other relevant information of the patient back to the robot. With the information delivered by the cloud server, the robot can provide customised advice or service to the patient. For example, the robot can remind a patient with hypertension to take her/his medicine or show the latest diagnosis report to the patient.

Illustration of the workflow of a healthcare robot.
A typical face recognition or classification system has two main steps: feature extraction and face matching. For feature extraction, the use of deep neural networks (DNNs) has become the mainstream in recent years due to their outstanding performance in extracting robust facial features.
6,7
Once we obtain the DNN features of a user, we can perform face matching by comparing its facial features with all the existing users’ facial features in a database. To perform face matching, the sparse-representation-based classification (SRC) method has been widely and successfully used in recent years. SRC has also drawn extensive attention in a variety of signal processing and image analysis applications, for example, signal encoding, image compression, feature representation, video analysis and image classification.
8
–16
For face matching or classification, the key idea of SRC is to obtain the high-fidelity representation of a test sample using a dictionary with sparsity constraints, leading to promising classification results. To be more specific, SRC aims to reconstruct a test sample using a dictionary consisting of all the training samples of all the classes. Meanwhile, the reconstruction coefficients are regularised by the
Despite the success of the aforementioned representation-based classification algorithms, it is still a very challenging task to perform robust face classification under unconstrained scenarios in the presence of a wide spectrum of appearance variations, for example, in pose, expression, illumination and occlusion. To address these issues and further strengthen the representative and discriminative capabilities of a representation-based classification method, a number of approaches have been developed in recent years. For example, Deng et al.
18
proposed an extended SRC method (ESRC) for face classification, in which an auxiliary intraclass variant dictionary is used to address the small sample size problem as well as the difficulties posed by occlusion and illumination variations. Yang et al.
19
and Zhu et al.
20
introduced similarity and distinctive of features to present a more general model of CRC. Xu et al. proposed an efficient SRC by means of an improved norm minimisation.
21,22
Guo et al. proposed two weighted discriminative collaborative competitive representation methods with the
As shown in Figure 2, the proposed framework includes three steps: geometric face alignment, robust deep textural feature extraction and collaborative-representation-based face classification with GDS.

The pipeline of the proposed collaborative-representation-based face classification method with deep aligned feature extraction and group dictionary selection.
The first step, geometric face alignment, is used to address the difficulties posed by geometric appearance variations such as expression, pose and other rigid transformations (translation, scale and rotation). Face alignment, also known as facial landmark detection, plays a very important role in many facial image analysis tasks, for example, face recognition, face tracking, face animation and 3D face modelling (https://www.nist.gov/programs-projects/face-recognition-grand-challenge-frgc). 25 –27 As a preprocessing stage, geometric face alignment influences the performance of a facial image analysis application to a great extent. 6 However, it is still very challenging to perform robust face alignment under unconstrained scenarios in the presence of large pose variations, abrupt illumination changes, extreme facial expressions and heavy occlusions. To improve the accuracy of face alignment, cascaded shape regression has been proposed and has become very popular in recent years. 28 –32 However, cascaded shape regression usually relies on hand-crafted features and weak regression methods, which cannot address the difficulties posed by appearance variations very well. More recently, DNNs have become the trend in face alignment. 33 –38 For example, Feng et al. proposed a Wing loss function for convolutional neural network (CNN)-based face alignment, which improves the performance of regression-based face alignment with CNNs significantly. 39 In this article, we use a modified regression visual geometry group (VGG) architecture to obtain fine-grained geometric facial features in the form of a set of 2D facial landmarks. Those facial landmarks are then used to perform 2D geometric normalisation across different face images, using the piecewise affine warp method.
Apart from geometric facial image alignment/normalisation, robust textural facial image feature extraction methods have also been developed to enhance the performance of representation-based classification algorithms. A number of studies have demonstrated that robust image feature extraction methods can promote the performance of pattern classification significantly. Classical representation-based classification methods, such as SRC, CRC and LRC, are usually based on image intensities thus perform poorly in unconstrained scenarios. To address this issue, many robust image feature descriptors, for example, local binary patterns 40,41 and Gabor, 42,43 have been used in representation-based face classification and demonstrated significant improvements in accuracy. More recently, with the great success of DNNs, CNNs have been proven to be very effective in extracting robust image features for a variety of image classification tasks. 6,44 –46 However, the use of deep image features in the representation-based classification paradigm has been less investigated by the community. Most existing deep-learning-based image classification methods just simply use the nearest neighbour classifier. This motivates us to further explore the use of deep CNN features for representation-based face classification. To this end, we extract deep CNN features from geometric aligned facial images for CRC-based face classification.
Classical representation-based classification methods, such as SRC and CRC, try to find a representation coefficient for a new test sample using a dictionary consisting of all the training samples of all the classes. In this case, all the classes contribute to the reconstruction of the test sample, which brings uncertainty in decision-making. Although the use of geometric face alignment and DNN features is able to reduce the uncertainty to some extent, the information of a dictionary consisting of all the training samples is redundant. To obtain a compact dictionary and reduce the uncertainty in decision-making, we propose a GDS approach. The proposed GDS approach has two steps. In the first step, we use the classical CRC method to calculate the representation coefficients. Then a measure is used to calculate the response of each class and only the ones with higher responses are selected to form a new dictionary for the final decision-making step. Experimental results demonstrate that the use of our proposed GDS method improves the accuracy of face classification further.
To summary, the main contributions of the proposed method include a new collaborative-representation-based face classification framework using robust deep aligned image features; an effective GDS approach that reduces information redundancy and uncertainty in decision-making; promising experimental results are obtained for both face alignment and face classification on several well-known face benchmarking data sets.
In the next section, we first introduce the classical CRC method, which is the foundation of the proposed algorithm. Then the details of the proposed method are presented in the ‘proposed framework’ section. To validate the performance of the proposed method, we report the experimental results obtained on several well-known face alignment and face classification data sets in the ‘experimental results’ section. Last, in the ‘conclusion and future work’ section, we draw the conclusion of the proposed method and introduce our future work plans.
Background
In this section, we introduce the classical CRC method, which is the foundation of the proposed method in the next section.
Given K classes and each class has M training samples, we can form a dictionary

where


where

where μ is a small positive constant controlling the influence of the
Once the coefficient vector is obtained, we can measure the propensity of the kth class to the representation of the test sample
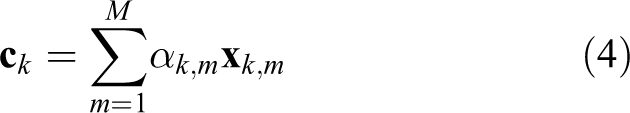
where

which describes the dissimilarity between the test sample and the kth class. Last, the label of the test sample
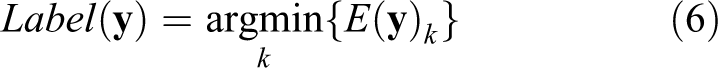
In spite of the success of CRC-based approaches in face classification, there are some issues of the existing CRC methods. One key issue is that a CRC-based face classification method is sensitive to the geometric variations of a human face. To mitigate this issue and further improve the face classification accuracy, we propose a new framework for CRC-based face classification in the next section.
The proposed framework
To improve the performance of the classical CRC-based face classification method in accuracy, we propose a new geometry aligned facial feature extraction method in this section. In addition, we present a novel group feature selection method for a further performance boost. The proposed CRC-based face classification framework using deep aligned features (DAFs) and GDS has three main steps: geometric face alignment, deep textural image feature extraction and CRC-based face classification with GDS. The pipeline of the proposed method is depicted in Figure 2. To perform robust geometric face alignment, we first use a deep convolutional neural network to predict fine-grained 2D facial landmarks. Then the piecewise affine warp method is applied to both training and test images for geometric face alignment using predicted 2D facial landmarks. Next, we use another deep convolutional neural network to extract robust facial features. Last, the deep aligned facial features are used to perform face classification using a novel CRC-based classification method with GDS.
Geometric face alignment
To perform geometric face alignment, we first detect 2D facial landmarks of each training or testing image, using a state-of-the-art deep convolutional neural network, that is, the VGG face model.
47
However, the classical VGG face model is designed for the image classification task, whereas facial landmark detection is a regression task. To meet the requirement of the regression-based 2D facial landmark detection task, we modify the classical VGG network architecture. The classical VGG network has 12 convolution layers, 5 max pooling layers, 3 fully connected layers and a softmax layer. In VGG, each convolution layer is followed by a ReLU non-linear activation layer. We replace the softmax layer and the last fully connected layer by a densely connected regression layer. The architecture of the modified regression VGG network is shown in Figure 3. As depicted in the figure, the input for the network is a
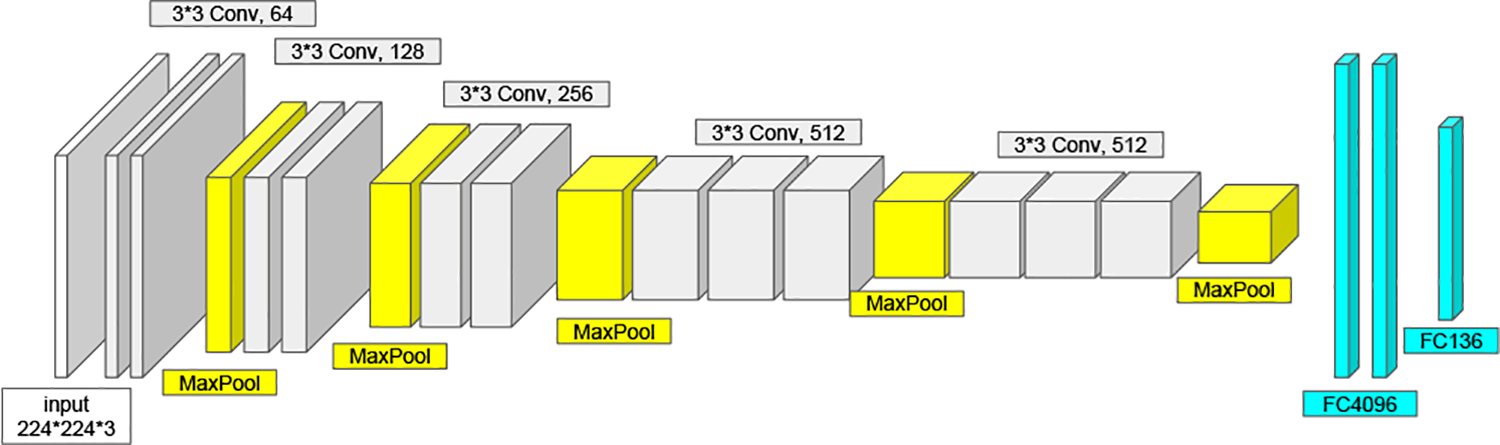
The architecture of the modified regression VGG net for 2D facial landmark detection.
To train the facial landmark detection network, we use the 300 W face data set. 48 Each face image in the 300W data set has 68 manually annotated 2D facial landmarks. More details of the 300W data set is give in Experimental results Section. As the L2 loss function is sensitive to outliers, 33,49 we use the L1 loss function for network training

where
After the training of the facial landmark detection network, we apply it to all the training samples and testing samples. Then we apply the piecewise affine warp method to perform geometric face image alignment/normalisation. For more details of the piecewise affine warp method, readers are referred to Matthews and Baker.
50
To be more specific, we map the texture of an input face image,
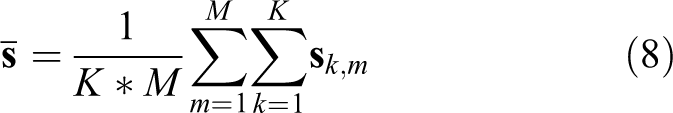
where
Some examples of the face image normalisation step using piecewise affine warp are shown in Figure 4. To maintain the background of an input face image, 4 anchor points are added to the obtained 68 landmarks for piecewise affine warp, as shown in the figure. We use the term

Geometric face alignment/normalisation using piecewise affine warp. The first and third columns are the original input facial images and the detected 68 facial landmarks. Note that, for each image, 4 anchor points are generated around the facial landmarks to preserve background information. The second and fourth columns are the geometric aligned facial images using the piecewise affine warp approach.
DAF extraction
Recently, DNNs especially CNNs have been successfully used for a wide range of image classification tasks. A DNN is able to extract robust facial features for accurate face classification with appearance variations. Instead of the original image intensity feature that has been widely used in many representation-based face classification approaches, we use deep CNN features in our proposed framework. Note that the proposed feature extraction method is applied to a geometric aligned facial image,
In many practical applications, such as access control, we may only have very few or even one gallery image of each subject. In this case, it is hard to train or fine-tune a DNN using gallery images and a pre-trained face classification network is used for robust facial feature extraction. Such a face classification network is usually pre-trained on a large-scale face data set with thousands of identities and it is supposed to generalise well to new identities. To perform face classification for a new subject, the image features of all the gallery images and a probe image are extracted by the pre-trained deep network and the nearest neighbour classifier is usually used to perform face classification. The label of the gallery image with the shortest distance, for example, the cosine distance, to the probe image is assigned to the probe image. However, according to our preliminary experimental results, we found that the combination of cosine distance and the nearest neighbour classifier does not work very well in such a practical application setting. In this article, we propose to use a representation-based classifier, that is, CRC, for image classification.
To extract deep CNN features, we use the well-known VGG face model.
47
Specifically, for each geometric aligned face image in a dictionary,

where
GDS for CRC-based face classification
As discussed in the last two subsections, to perform face classification, we use a pre-trained DNN to extract deep aligned CNN features. The main reason to use a pre-trained DNN is due to the fact that we usually have very few training samples for training or fine-tuning a DNN in many practical applications such as access control. However, one issue to use a pre-trained deep CNN is that the network may not generalise well for a new domain. The extracted facial image features are redundant and the standard nearest neighbour classifier cannot address this issue. To mitigate this difficulty, we propose to use a representation-based face classification method, that is, CRC. However, the classical CRC method still has difficulties in addressing the issues posed by information redundancy. Redundant facial image features may lead to uncertainty in decision-making especially when we have a large number of classes. To be more specific, all the samples of all the classes in a dictionary contribute to the reconstruction of a test sample in CRC. Sometimes, a training sample that does not belong to the same label of the test sample may obtain a high response in CRC, which leads to classification errors. To reduce the information redundancy of the use of a pre-trained deep CNN as well as uncertainty in decision-making, we propose a dictionary optimisation approach, namely GDS.
Given a test image,

which measures the contribution of the training samples from the kth class to the representation of the test sample. Then, we rank the contributions of all the classes and only select a pre-defined proportion of the higher ranking classes to create a new dictionary
CRC-based face classification with group dictionary selection.


Experimental results
In this section, we evaluate the performance of the proposed method in terms of accuracy. To be more specific, we first evaluate the performance of the proposed facial landmark detection network on the 300W data set 48 in terms of accuracy. Then we compare the proposed CRC-based face classification method using deep aligned facial features and GDS with the state-of-the-art approaches on several face classification data sets. In addition, we analyse the effects of each component in the proposed framework, including geometric face aliment, deep CNN feature extraction and GDS, on those face classification data sets. It should be highlighted that the face images from these data sets were captured under a wide spectrum of appearance variations in illumination, pose and expression.
Evaluation on facial landmark detection
As the accuracy of 2D facial landmark detection is crucial for our proposed DAF extraction method, we first evaluate the proposed facial landmark detection network on the 300W face data set, 48 compared with a number of state-of-the-art facial landmark detection methods. The 300W data set has a number of facial images selected from different face data sets, including XM2VTS, 51 LFPW, 52 HELEN, 53 Face Recognition Grand Challenge (FRGC) 54 and AFW. 55 300W has been widely used for benchmarking 2D facial landmark detection algorithms. In this article, we follow the protocol used in Ren et al. 56 This protocol uses AFW, the training sets of LFPW and Helen to create the training set. In total, the training set has 3148 images. The test set of the protocol consists of IBUG, the test sets of LFPW and Helen. In total, the test set has 689 images, which are divided into two subsets: common and challenging subsets. The evaluation metric is the normalised mean error, which is the mean of the Euclidean distance between a predicted landmark and its ground-truth value over all the facial landmarks, normalised by the inter-ocular distance.
We compare the proposed 2D facial landmark detection network with a set of state-of-the-art approaches in Table 1. From the table, we can see that the proposed facial landmark detection network outperforms the state-of-the-art approaches in terms of accuracy on both the common subset and the full set. It achieves competitive results on the challenge set as well, which is only slightly worse than the TR-DRN method. This validates the robustness and accuracy of the proposed method in facial landmark detection. We show some results of the detected 2D facial landmarks on the 300W test set using our proposed facial landmark detection network in Figure 5. We can see that the proposed facial landmark detection method is very robust to a variety of face appearance variations, such as pose, expression, illumination and so on.
Facial landmark detection results on the 300W data set.a
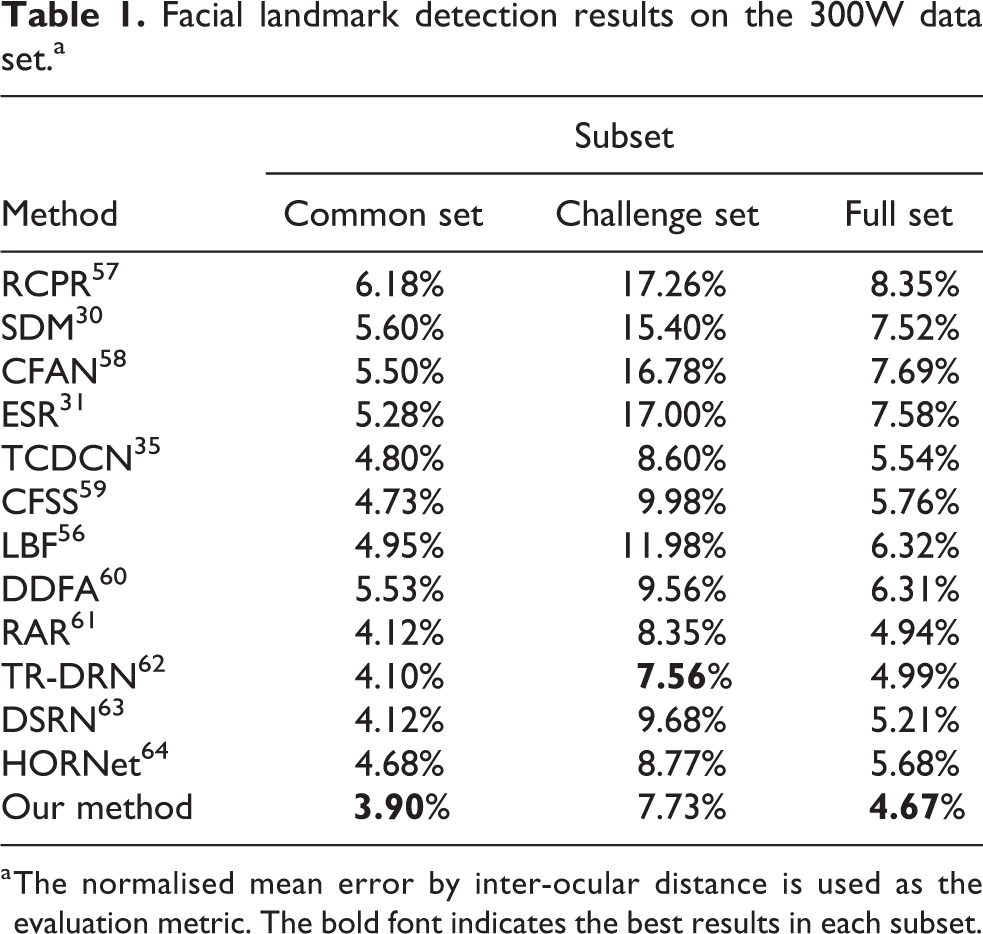
a The normalised mean error by inter-ocular distance is used as the evaluation metric. The bold font indicates the best results in each subset.

Some examples of the detected 2D facial landmarks by the proposed facial landmark detection network on the 300W test set.
Evaluation on face classification
In this part, we first compare the proposed face classification framework with a number of representation-based approaches on several well-known face classification data sets, including FERET, 65 FRGC 1 , LFW 66 and CMU-PIE. 67 Then we conduct an ablation study for the proposed method, in which we analyse each component of the proposed approach, including geometric face alignment, deep CNN feature extraction as well as the proposed GDS method.
Results on FERET
The FERET face database is an output of the FERET program, which was sponsored by the US Department of Defence through the DARPA program. This database has become a widely used benchmarking database for the evaluation of face classification techniques. The proposed algorithm was evaluated on a subset of the FERET database, which includes 1400 images of 200 subjects, each has seven different images. Some example images of the FERET data set are shown in Figure 6. To apply the VGG face model to those images for DAF extraction, we converted each FERET image to a colour image by copying the single channel grey-level image to each RGB channel.

Examples images of the FERET data set.
For the FERET database, we used
As shown in Table 2, we can see that the proposed method consistently achieves much better classification results than the other algorithms, regardless of the number of gallery samples.
A comparison of different face classification methods on the FERET data set, in terms of face classification accuracy.

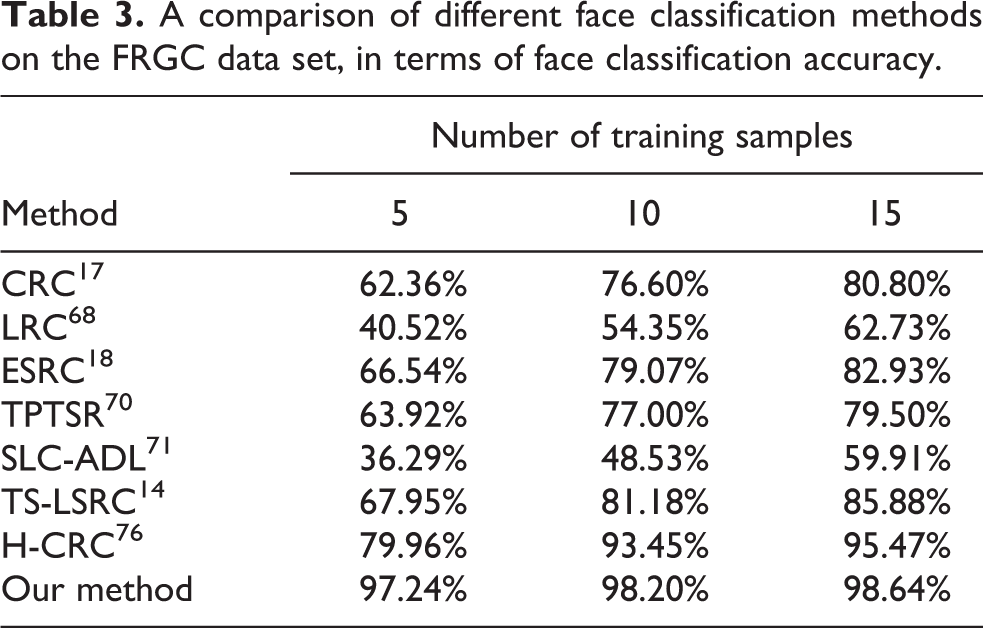
Results on FRGC
The FRGC version 2 database consists of both constrained and unconstrained facial images. The constrained images have good image quality, whereas the low-quality unconstrained images were captured under complex backgrounds. In this article, we select 100 subjects, each with 30 different images, from FRGC to construct our experimental subset. Some example images of the FRGC database are shown in Figure 7.

Examples images of the FRGC data set. FRGC: Face Recognition Grand Challenge.
For the experiments conducted on the FRGC database, we selected
A comparison of different face classification methods on the FRGC data set, in terms of face classification accuracy.
Results on PIE
The CMU-PIE face database consists of 41,368 images of 68 individuals with mixed intraclass variations introduced by three types of interference, including 13 different poses, 43 different illumination conditions and 4 different expressions. This database has also become a benchmark database for the evaluation of a face classification algorithm. In this article, the proposed algorithm was evaluated on a subset of the CMU-PIE database, which includes 6800 images of 68 individuals with 20 different images (10 poses and 10 illuminations) of each subject. Some example images of the CMU-PIE database are shown in Figure 8.

Examples images of the PIE data set.
For the experiment on the CMU-PIE database, we used
A comparison of different face classification methods on the CMU-PIE data set, in terms of face classification accuracy.

Results on LFW
The LFW face database is one of the most challenging data sets which consists of face images captured under unconstrained scenarios in the presence of pose, illumination, occlusion and expression variations. The LFW database includes 13,233 images of 5749 individuals of different gender, ages and so on. The proposed algorithm is evaluated on a subset of the LFW database, which includes 1580 images of 158 individuals with 10 different images of each subject. Some images from the LFW database are shown in Figure 9.

Examples images of the LFW data set.
For the experiment conducted on the LFW database,
A comparison of different face classification methods on the LFW data set, in terms of face classification accuracy.

Analysis of the proposed method
The proposed method performs geometric face alignment/normalisation and deep CNN feature extraction for CRC-based face classification with GDS. To better understand the contribution of each component in the proposed framework to the improvement on face classification accuracy, we conducted a further evaluation on different face data sets. To this end, we use four methodsin the evaluation: (1) the classical CRC method using original face image intensity features (CRC); (2) CRC based on the geometric aligned face images with raw image intensity features (AF-CRC); (3) CRC with deep aligned CNN features extracted from the aligned 2D face images (DAF-CRC); and (4) CRC with deep aligned CNN features extracted from the aligned 2D face images using the proposed GDS method (DAF-CRC-GDS). Experimental results are reported in Table 6. For the FERET and LFW data sets, three samples of each subject were used as the dictionary. For FRGC and CMU-PIE, five samples of each subject were used as the dictionary. All the rest samples of each subject were used as testing images.
Self-analysis of different components of the proposed method, in terms of face classification accuracy.

From Table 6, we can see that 2D geometric face alignment/normalisation is able to improve the face classification accuracy of CRC significantly, AF-CRC v.s. CRC, especially for a data set with pose variations such as FERET and PIE. The main reason is that the geometric normalisation step provides semantic consistency across different face images in pixel level, which is crucial for a representation-based face classification approach. In addition, the use of deep aligned CNN features (DAF-CRC) further improves the performance of CRC in terms of accuracy for face classification. Last, with the proposed GDS method (DAF-CRC-GDS), the face classification accuracy is further improved on all the data sets. This experiment validates the effectiveness of the proposed method as well as different advocated elements in the processing pipeline.
Simulation
To further evaluate the proposed method in practical applications, we simulate a robotic application scenario on a laptop using the YouTube-Faces data set. 77 To be more specific, we select 200 videos of 100 identities from the YouTube-Faces data set. We enrol these 100 identities to our database as the gallery set using the frames of one video of each identity. For test, the other video of each identity is used, which is different from the video used for identity enrolment of our system. Some example faces from the YouTube-Faces data set are shown in Figure 10.

The YouTube-Faces data set. The first row shows some example faces that are used for the enrolment of our database. The second row shows some example faces that are used for the test of the proposed method.
To simulate the proposed face recognition method in practical scenarios using the YouTube-Faces data set, we use the Single Shot multibox face Detector 78 to detect the face in each frame of a test video. Then the proposed VGG-based facial landmark detection method is used to obtain facial landmarks and perform geometric face alignment. Last, the proposed CRC-based face classification method with GDS is used for face recognition. We show the simulation results of the 10th, 20th, 30th, 40th and 50th frames of a video evaluated on the YouTube-Faces data set in Figure 11. According to the simulation, we can see that the proposed method perform well in practical scenarios.

The simulation results of the 10th, 20th, 30th, 40th and 50th frames of a video evaluated on the YouTube-Faces data set. The first, second and third rows of the figure are the results of the face detection, facial landmark detection and face recognition modules of the proposed method.
Conclusion and future work
In this article, we propose a face classification framework using DAFs. The proposed method uses facial landmarks and piecewise affine warp to perform geometric face alignment for robust deep convolutional neural network based facial feature extraction. In addition, a new GDS approach is proposed to further improve the performance of the collaborative-representation-based face classification method. The experiment results obtained on several benchmarking data sets and the simulation results obtained on the YouTube-Faces data set demonstrate the effectiveness of the proposed method. However, based on our simulation results, we find that the proposed method can only perform well when the yaw rotation of a facial image is smaller than around
The other challenge or limitation of the proposed method is the deployment of our system in robotics applications. One main reason is that the proposed method is based on large capacity deep CNNs that require high-performance GPU devices to achieve real-time inference speed in practical applications. This can only be done on a cloud server at the current stage due to the energy costs of GPU devices. In our future work, we aim to address this issue by reducing the computational complexity of the proposed method. For example, we intend to design new lightweight DNNs that perform equally well as a large capacity network in facial landmark detection and face classification. Our ultimate goal is to perform accurate and real-time face classification on lightweight edge computing platforms, such as a robot.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: the National Key Research and Development Program of China (Grant nos. 2017YFC1601800, 2016YFD0401204), the National Natural Science Foundation of China (Grant no. 61876072), China Postdoctoral Science Foundation (Grant no. 2018T110441) and Six Talent Peaks Project in Jiangsu Province (Grant no. XYDXX-012).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.