
Abstract
Existing sparse representation-based visual tracking methods detect the target positions by minimizing the reconstruction error. However, due to complex background, illumination change, and occlusion problems, these methods are difficult to locate the target properly. In this article, we propose a novel visual tracking method based on weighted discriminative dictionaries and a pyramidal feature selection strategy. First, we utilize color features and texture features of the training samples to obtain multiple discriminative dictionaries. Then, we use the position information of those samples to assign weights to the base vectors in dictionaries. For robust visual tracking, we propose a pyramidal sparse feature selection strategy where the weights of base vectors and reconstruction errors in different feature are integrated together to get the best target regions. At the same time, we measure feature reliability to dynamically adjust the weights of different features. In addition, we introduce a scenario-aware mechanism and an incremental dictionary update method based on noise energy analysis. Comparison experiments show that the proposed algorithm outperforms several state-of-the-art methods, and useful quantitative and qualitative analyses are also carried out.
Introduction
As a subtask of computer vision, visual target tracking has always drawn many attentions for decades, and many advanced methods have been explored. However, complex situations such as occlusions, target deformation, rotation, scale changes, and cluttered background, and so on, make visual target tracking still a challenging task and the existing methods cannot always track the targets precisely. The current trackers can be typically divided into two types, that is, generative methods 1 –5 and discriminative methods. 6 –17 They usually sample a set around the target object to describe the appearance characteristics, and search for candidate targets by maximizing the similarity or find the decision boundaries of the target and the background.
To get the satisfied tracking performance, two key issues need to be addressed. First, since the appearance of the target changes frame by frame throughout the video sequence, the most discriminating samples in the current frame may not last for a long time and tend to result in a model overfitting. So, the improvement of long-term tracking performance is an important issue. Second, Unpredictable target deformation and background clutter in the sampling region cause a negative impact on the selection of candidate samples. Thus, the elimination of these obstacles to advance tracking performance in the case of small target samples is also an important issue.
To address both issues, sparse representation-based tracking solutions have been proposed, such as L1 tracker. 5 Because of insensitivity to the target noise, this kind of methods has a strong tracking robustness when target deformation occurs. However, single-feature and the initial discriminative dictionary do not satisfy complex tracking scenarios. Moreover, the object localization under the frequent online updating often brings drift-away problems as some negative samples are mis-tracked. These problems remain difficult in the literature of sparse representation-based trackers. Hence, a natural question is how we can augment positive samples in the feature space to capture target appearance variations in the temporal domain.
In this work, we take advantage of the recent progress in discriminative dictionary learning method label consistent K-SVD (LC-KSVD) 18,19 to facilitate the dictionary learning and to propose a novel tracking method with weighted dictionaries incremental learning and pyramidal feature selection strategy. In summary, this work has the following main steps. Firstly, we model the discriminative dictionaries from positive and negative samples based on two feature descriptors, where different features correspond to different dictionaries. Secondly, according to the center distance from the training samples to the target, we assign Gaussian weights for each basis vector in different feature dictionaries, which are used to measure the similarity of spatial structure to improve the accuracy of sparse feature selection. Finally, we select the best sample region by similarity measurement and fusion of the multiple features reconstruction error of candidate samples.
The article is organized as follows. We introduce the research background in the “Introduction” section and review the related work in the “Related work” section. Afterwards, the “Proposed method” section describes the proposed method in detail, including dictionary representation and construction, incremental dictionary updating, and adaptive feature fusion strategy. The experiments are given in “Experimental results and comparison.” We conclude the article and discuss future work in the “Conclusion and future work” section.
Related work
In this section, we briefly review the relevant literature of object tracking algorithms in recent year, including deep learning-based tracking methods 11 –17,20,21 –23,24 and sparse representation-based tracking method. 1,3,5,6,25 –28,30,31
The main advantage of deep learning-based tracking methods lies in their powerful characterization of depth features. It brings a new research direction for solving various challenges in visual tracking. Wang and Yeung 20 proposed deep learning tracker and performed unsupervised off-line depth pretraining on large-scale natural image data sets. The idea of transfer learning reduces the requirement of training samples and improves the performance of the tracking algorithm. Then, they propose structured output-deep learning tracker 11 and use convolutional neural network (CNN) model to solve the sensitivity of model updating. Qi et al. 12 proposed a novel CNN-based tracking method, which considers the features from all CNN layers and hedge these features into a single stronger one. Furthermore, they propose a hedging deep feature-based tracking framework 13 which use correlation filters to feature maps of each CNN layer to construct a weak tracker and design a Siamese network to define the loss of each weak tracker. The tracker achieves favorable performance on challenging image sequences.
To solve the imbalance between positive and negative samples in video tracking, Zhang et al. 14 proposed an attribute-based CNN with multiple branches, where each branch is responsible for classifying the target under a specific attribute. The tracker reduces the appearance diversity of the target under each attribute and thus requires fewer data to train the model. Qi et al. 15 proposed to integrate the point-to-set/image-to-imageSet distance metric learning (DML) into visual tracking. The point-to-set DML is conducted on CNN features of the training data, and the tracking result is located by the minimal distance to the target template. Because the methods based on matching tracking cannot deal with the problem of target rotation in the plane very well, Zhong et al. 16 proposed a hierarchical tracker that learns to move and track by a coarse-to-fine verification. The coarse level utilizes a recurrent CNN-based deep Q-network to learn data-driven searching policies. The idea of learning target position from coarse to fine is helpful to deal with target scale change and improve the accuracy of tracking target border. The authors also apply this idea to multi-person tracking and propose a deep alignment network-based multi-person tracking method 17 with occlusion and motion reasoning which achieves good performance. Wang et al. 24 proposed a deep learning-based hybrid spatiotemporal saliency feature extraction framework for saliency detection from video footages.
Sparse representation-based tracking methods show strong robustness in some tracking scenarios. Therefore, many visual tracking methods 5,25,27,31,32 based on sparse representations have been proposed. Local sparse representations are widely used in visual tracking. 28,29,33 Zhang et al. 30 summarized and evaluated some classical tracking methods based on sparse representation. The process of sparse representation-based trackers can be roughly divided into two stages. The first stage acquires a sparse sample set around the target, and the second stage uses a classifier to classify each sample as a target or background. However, the positive samples obtained from the first frame of video are far from meeting the requirement of label data volume in classifier training, and the positive and negative samples are imbalanced greatly, which makes it impossible to capture the rich appearance changes of the target. These limitations are also reflected in some deep learning-based trackers 21 –23 that use this two-stage framework.
In the target tracking process, a good model update strategy can improve the tracking effect and tracking ability. Lu et al. 26 used incremental subspace learning methods to reconstruct a new template and then utilized it to replace the old one. However, the updated base vector will gradually degrade in the scene where noise or occlusion exists. In addition, Mei and Ling 5 replaced the least important template with the current template based on the frequency of use of the dictionary template. Han et al. 27 updated the dictionary template in a random replacement manner.
The combination of multiple features enhances the characterization capabilities of the model and is applied to many different classification tasks. From the perspective of visual attention saliency, Yan et al. 34,35 used Gestalt rule to guide the saliency detection by characterizing human visual system (HVS) features and forming targets and proposed a method to cognitively detect and track salient objects from videos by combining red-green-blue (RGB) image and thermal image. The proposed fusion-based approach can successfully detect and track multiple human objects in most scenes regardless of any light change or occlusion problem. Lan et al. 25 used an unreliable feature detection method to detect unreliable features. However, the representation of reliable features is still suppressed by the joint sparse framework, and different features are limited to similar sparse patterns. Mai and Ling 5 fused multiple features for appearance modeling and detect the outlier particles. The same sparse pattern is used for all features of the non-outlier particles.
In this article, we propose a novel multifeatures dictionary-based sparse tracking method, where a specific feature dictionary is built upon hybrid features with the ability of independently maintaining. Then an incremental dictionary update strategy is proposed to reduce the redundancy of sparse dictionaries while increasing the diversity of positive samples. The output of these dictionaries responses in a different sparse pattern for the final comprehensive decision during the tracking process.
Proposed method
In this section, the proposed method including three modules is introduced. The main framework of our method is shown in Figure 1. We maintain two sets of samples (positives and negatives) to construct weighted feature dictionaries. In the tracking process, the samples are sparsely decomposed by the weighted dictionaries, and the weights of the samples can be obtained and used to select candidate samples. By comparing the reconstruction errors of these candidate samples, we can select the most similar sample as the tracking result.
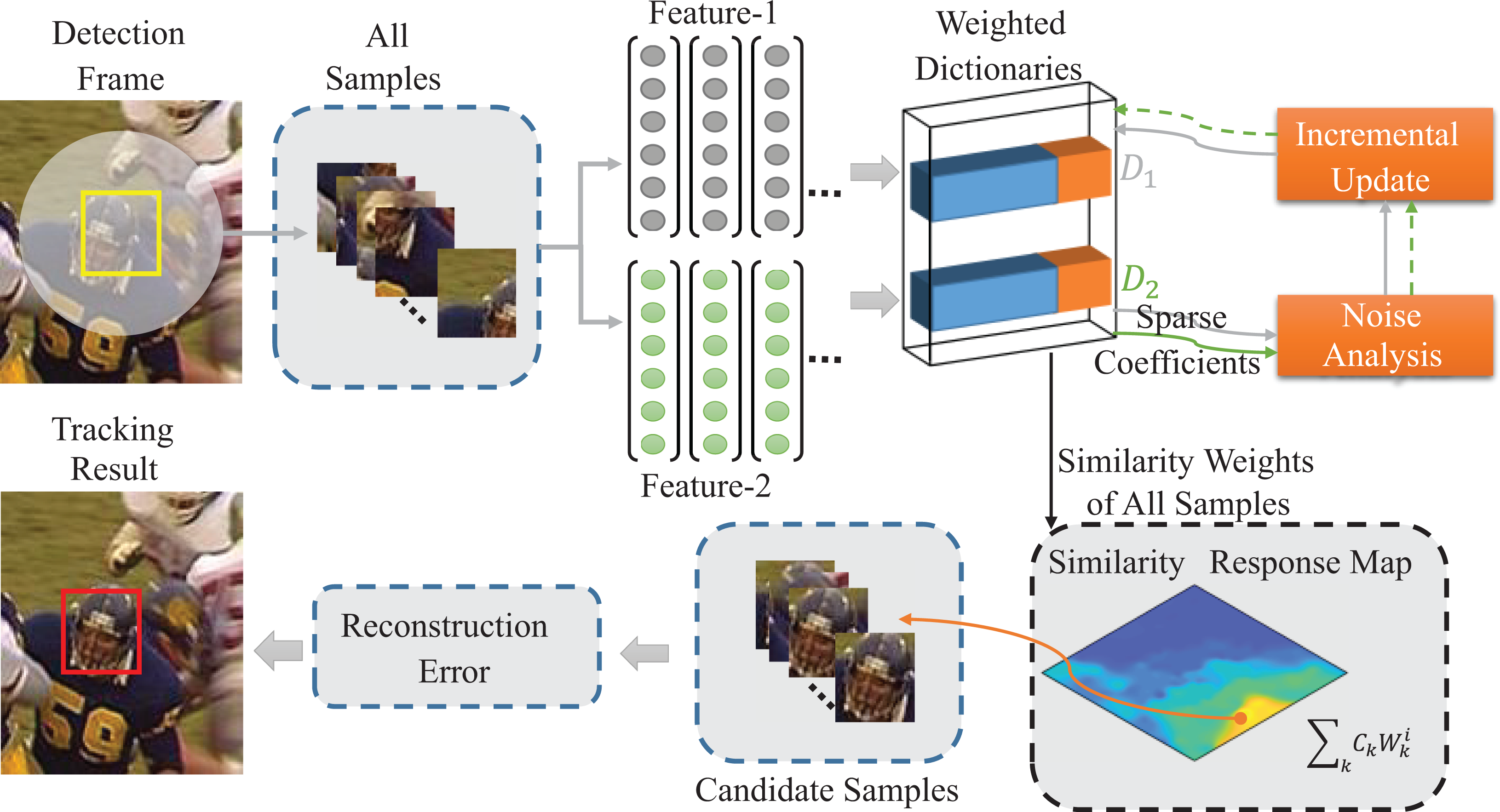
The main tracking process of the proposed approach.
Dictionary representation and construction
In sparse representation theory, dictionary is composed of super-complete base vectors to obtain a more concise representation of the appearance of the target. For this purpose, three types of sets, that is, the positives T, the backgrounds B, and the noise L are integrated together. The initial dictionary D of the samples at the first frame can be represented as

where D is the discriminative dictionary, z is the target coefficient, v is the background coefficient, e is the noise coefficient, and γ is the sparse coding. In this article, the LC-KSVD 18 method is used to unify dictionary learning and classification labeling.
Figure 2 shows the construction process of the initial dictionary. The center of the initial target is set as the center of the circle, pixels in the range of radius r 0 are sampled as positive samples, and pixels in the range of radius between r 1 and r 2 are dense sampled to obtain negative samples which contain the background context around the target.

Initial dictionary learning and the structure of multiple dictionaries.
For the positive and negative samples sampled in the first frame, we extract two kinds of features to form two initial dictionaries respectively. After that, we utilize the correspondence between the sample template and the dictionary base vector and assign the Gaussian weight to each base vector by calculating the center distance d(i) between sample templates and the target center. The weight of the ith base vector is defined as follows
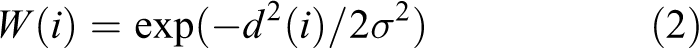
where α is the standard deviation of normal distribution. This weight reflects the similarity between the target and the samples. Finally, we get the weighted discriminative dictionaries, and each discriminative dictionary corresponds to a weight table.
Incremental dictionary updating
In many existing tracking methods, the appearance model of target is often updated to reduce the negative impact of target and background changes in the frames. In the sparse decomposition, the coefficient γ of sample contains the most representative information, where the noise factor indicates the situation of target occlusion and tracking drift to some extent. To this end, an incremental dictionary updating strategy is proposed to measure the change of target or scene by analyzing the noise energy u (the sum of the noise coefficients e). The larger the noise energy is, the more significant the deformation of the target or the greater the change of the scene causes.
In the frame t, the average noise energy expression for all samples can be represented as

where
In scene detection, we use the dynamic threshold of noise energy to judge the intensity of the scene change. Based on the target noise energy and the average noise energy, we can determine whether to perform a dictionary update. If the update condition is met, we use the samples of the first frame and the samples of the detected frame to obtain a new weighted dictionary Dk′. The new dictionary will be used for the next frame tracking task.
The incremental dictionary update trigger mechanism is shown in Figure 3(a). We divide the positive samples into two categories: static samples and dynamic samples. The samples obtained in the first frame are static samples, and the samples obtained in the trigger update mechanism are dynamic samples. When the number of positive samples is larger than that of current negative samples, we use a new positive sample set to randomly replace one group of the dynamic samples to reduce the impact of sample imbalance and maintain the efficiency of dictionary learning.

Discriminative dictionary incremental update (a) and noise analysis (b).
Figure 3(b) shows the changes of threshold curve and noise energy curve in sequence David 3. Five frames with large changes of target pose and background are selected as examples for illustration. It can be seen that the selected examples occur when the noise energy value is higher than the threshold value. Hence, our updating strategy can detect and reduce the impact of the background change in real time through the analysis of noise energy for better tracking performance.
Adaptive feature fusion strategy
In this section, we introduce the pyramid feature selection strategy to locate the target tracking position, as shown in Figure 4. We use a pyramidal selection strategy in the feature selection. First, we select WN groups of samples with the largest similarity weights as candidate samples CS j (j is the tag of the candidate samples). The sample similarity weight can be obtained in the sparse decomposition process. Then, we compare the comprehensive reconstruction error of the candidate samples to select the best sample as the tracking result.
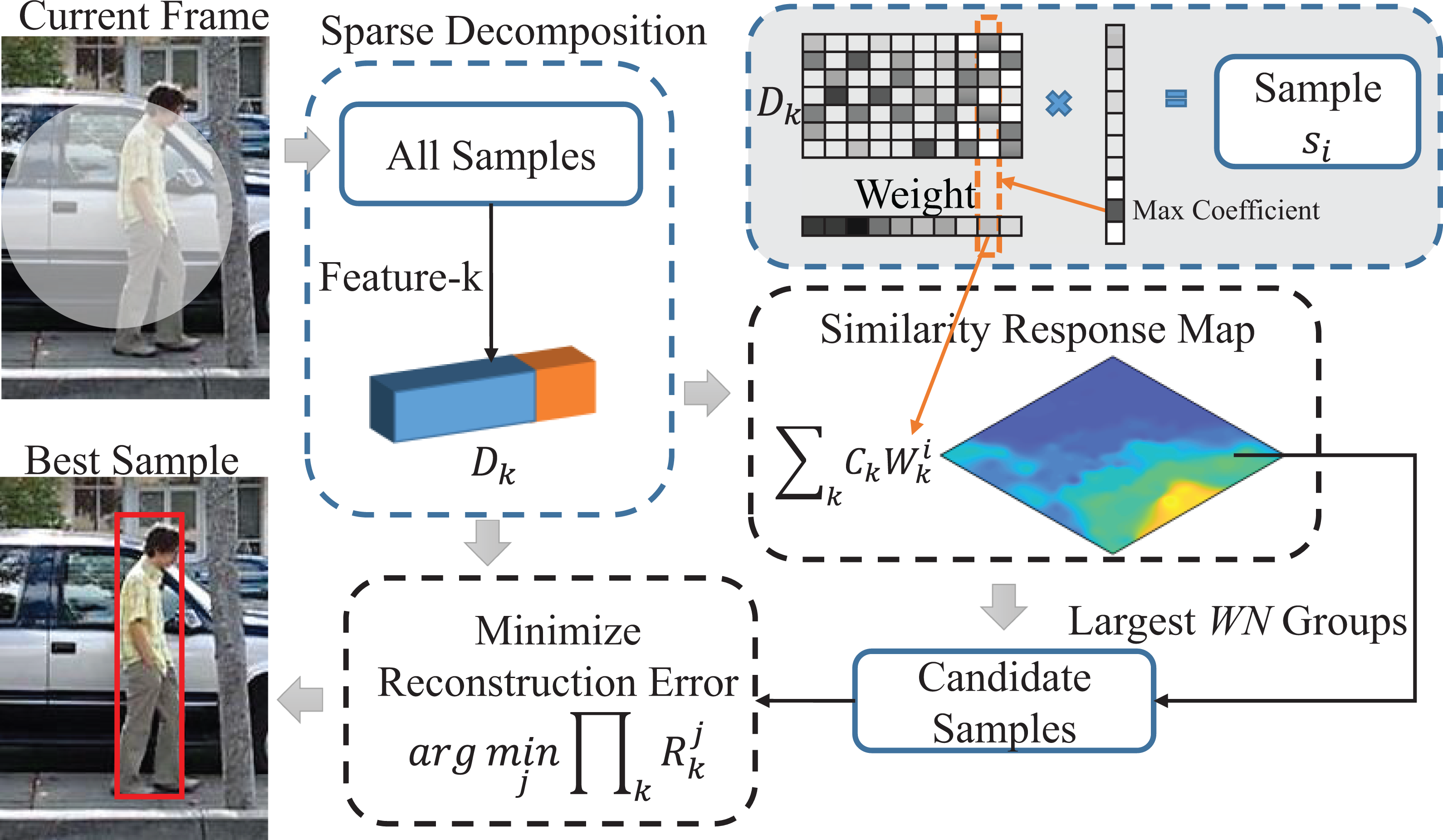
Feature selection process.
In the current frame, all samples Si
(i = 1, 2,…, n) are sparsely resolved by different feature dictionaries Dk
(k = 1, 2) to obtain sparse coefficients
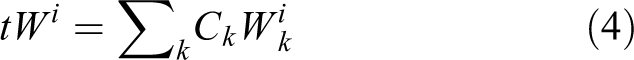

In equation (4), we set the dynamic feature weight parameters Ck
based on the feature reliability. Then we select a few candidate samples CS
j
which have the largest synthetic weights among all samples and the maximum value of synthetic weights is denoted as WN. When the noise energy is relatively large, the feature weight Ck
is relatively small. The definition of Ck
is shown in equation (5).
Then we use the synthetic reconstruction error to select the best sample from candidate samples. The expression of the synthetic reconstruction error is as follows

where
Experimental results and comparison
In this section, the public sequences of VOT2017 36 and OTB100 37 are used for the parameter setting and tracking performance evaluation of our method, respectively. Firstly, we experiment with eight RGB sequences of VOT2017, 36 analyze the parameter settings in the feature selection, and discuss the optimal combination of features. Then all 74 RGB sequences on the OTB100 37 are used for tracking performance evaluation. The experiment tracking results of other benchmarking methods are primarily derived from publicly available results data on the author’s homepage and OTB100 37 homepage. The computer environment used by our method is Intel (R) Core (TM) i3-3.7 GHz, RAM-12 GB, and MATLAB R2017a.
Implementation details and analysis
The method of this article adopts uniform parameter settings. The number of all samples obtained by Gaussian sampling during the tracking process is 500 and the sampling radius is 25. The sampling parameter of the training sample is set to: r 0 = 4, r 1 = 7, r 2 = 15. The Haar-like 38 feature dimension is set to 150, and the histogram bin of a single color channel is set to 36. Correspondingly, the color feature dimension of an RGB frame is set to 108. The update time interval must be greater than m = 6 frames, and the noise energy threshold parameter is α = 0.2.
Feature selection
Two types of features (noncolor features and color features) are used in our proposed model. In this section, the performance of different feature fusion strategy on eight RGB sequences (ball1, blanket, butterfly, crossing, godfather, pedestrian1, sheep, and wiper) in VOT2017 32 is investigated and useful analysis is also carried out.
Table 1 shows the performance of different feature fusion strategies in terms of average center location errors (CLEs). The CLE is the Euclidean distance between the tracking result and the standard target position. In general, dual feature fusion always outperforms single feature. Feature CIE L*a*b* (LAB) performs poorly in combination with other non-color features. It is worth noting that histogram of orientation gradient (HOG) + hue-saturation-value (HSV) has the best performance in the sequences of blanket, crossing, and wiper, but the average performance is the second best which is 3.1 lower than the best one, that is, Haar-like + HSV. Therefore, Haar-like + HSV is selected as feature fusion strategy for our following experiments.
The average CLEs for different dual feature combinations.a

CLE: center location error.
a Bold data represent the best results of single video tasks.
Candidate samples selection
In this section, we need to select a small number of candidate samples to narrow the scope of the target searching. These candidate samples are obtained by the composite similarity weights, where the optimal similarity weight values need to be determined. In this section, we discuss the influence of the maximum value of synthetic weights WN on the tracking effect. The experimental results are shown in Table 2.
The average CLEs with different WN values.a
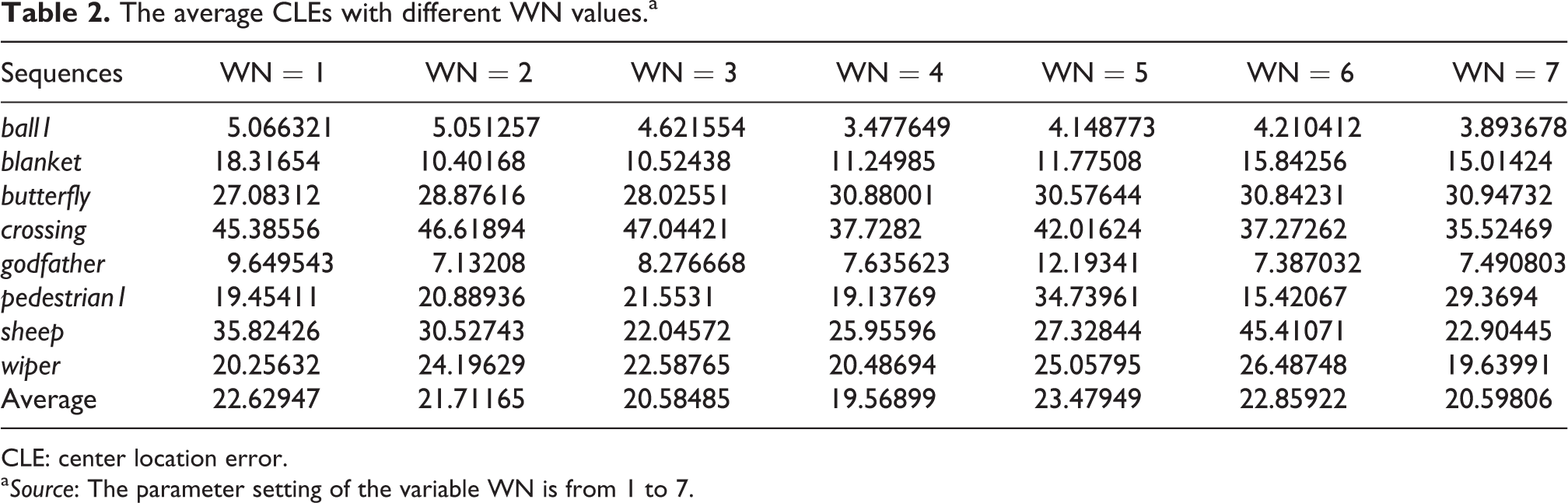
CLE: center location error.
a Source: The parameter setting of the variable WN is from 1 to 7.
In order to ensure the rationality of the experiment, we do not adopt the dictionary update strategy here. Based on the above experimental data, we can obtain the curve of CLE versus WN (Figure 5).

The average CLE variation for eight sequences. CLE: center location error.
In Figure 5, the broken line indicates the change in the effect of a single video tracking. The histogram shows the average tracking effect of all videos. As shown in Figure 5, the average value is significantly increased when WN is greater than 4 and the tracking results of some sequences are also significantly changed, such as pedestrian1, sheep, and so on. In the method evaluation experiment, we set WN to 3 in the experiment.
Experimental evaluation
In the performance evaluation section, we mainly compare the proposed method against eight state-of-the-art methods including adaptive local sparse appearance model-based tracker (ASLA 1 ), incremental learning-based tracker (IVT 2 ), L1 sparse tracker using APG (L1APG 3 ), compress tracker (CT 6 ), context tracker (CXT 7 ), online robust image alignment tracker (ORIA 9 ), online boosting tracker (OAB 8 ), and tracking learning-detection tracker (TLD 10 ). The qualitative and quantitative experimental results are carried out with a useful analysis. All 74 RGB sequences on OTB100 37 are used as evaluating sequence set, and the distribution of all challenging attributes in the evaluating sequence set is shown in Table 3.
The distribution of 11 challenging attributes in the evaluating sequence set: IV, SV, OCC, DEF, MB, IPR, OPR, OV, BC, LR, and FM.

IV: illumination variation; SV: scale variation; OCC: partial or full occlusion; DEF: non-rigid object shape deformation; MB: motion blur; IPR: in-plane rotation; OPR: out-of-plane rotation; OV: out of view; BC: background clutters; LR: low resolution; FM: fast motion.
Quantitative analysis
In this section, the tracking results based on precision plots and success plots are used to comprehensively evaluate the performance of different methods on OTB100. 37 The legend of precision plots shows the values at the error threshold of 20 pixels, and the legend of success plots show the area under curve (AUC) values. The overlap score is a measure of the overlap range of the tracking result and the ground truth tracking box, defined as OS = intersection area/union area, where intersection area and union area are the intersection and union of two regions, respectively.
Figure 6 shows the overall tracking precision plots and success plots of all nine methods on 74 RGB sequences of OTB100. 37 The precision score and success score of our approach are ranked first, higher than the second methods by 10.6% and 7.4%, respectively. As can be seen from the precision plots of one-pass evaluation (OPE), as the location error threshold increases, the precision of other trackers grows slowly, and our algorithm improves a lot. In the precision plots of OPE, the success score of our method is significantly higher than the other methods.
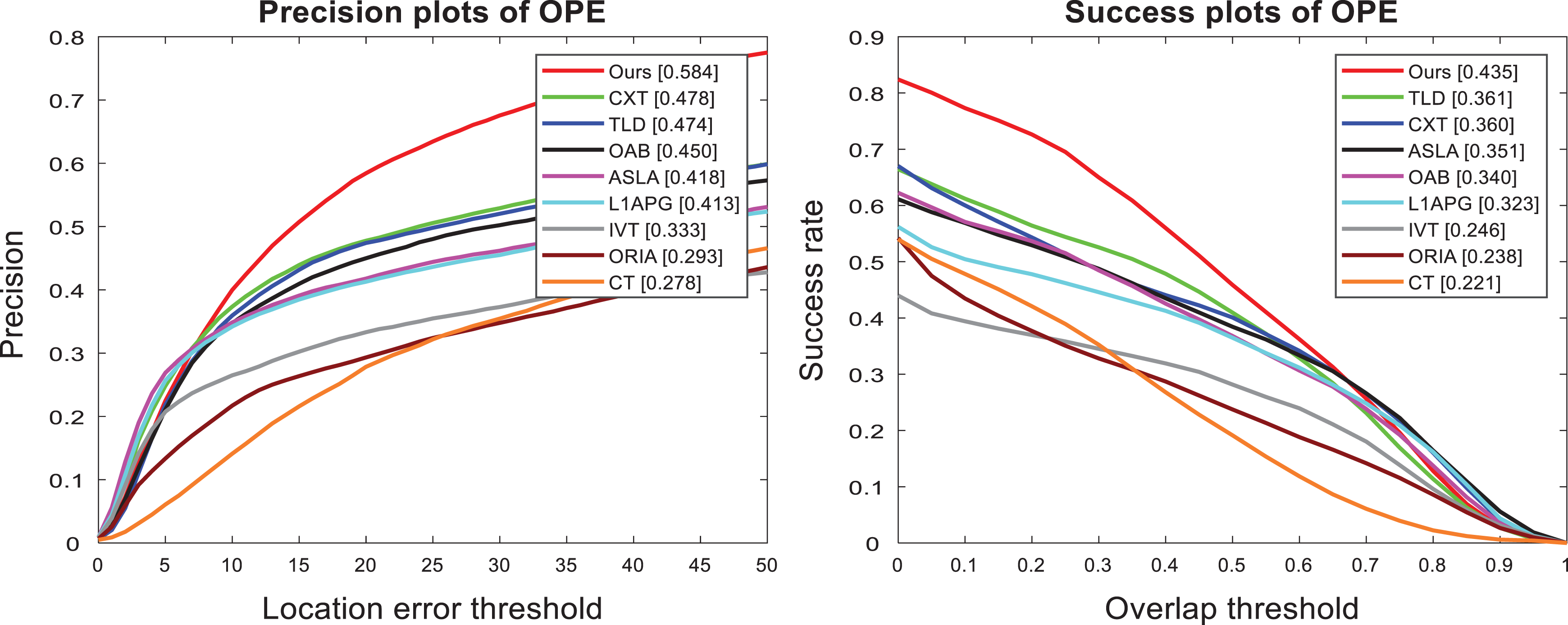
The comprehensive precision plots (left) and success plots (right) of comparison methods on 74 RGB sequences of OTB100. 37
Table 4 shows the performance of our method and eight benchmarking methods in terms of success plots and AUC scores on different attributes. The average AUC value of our method, TLD and CXT trackers are top 3 on 11 attributes. TLD and CXT trackers perform well on attributes of fast motion (FM), motion blur (MB), out of view (OV), and low resolution (LR) due to dense sampling. ASLA tracker performs better on occlusion (OCC), scale variation (SV), and non-rigid object shape deformation (DEF) attributes by its local representation.
The AUC value of all trackers in different attributes.a

AUC: area under curve; ASLA: adaptive local sparse appearance model-based tracker; IVT: incremental learning-based tracker; OAB: online boosting tracker; L1APG: L1 sparse tracker using APG; TLD: tracking learning-detection tracker; CT: compress tracker; ORIA: online robust image alignment tracker; CXT: context tracker; IV: illumination variation; OPR: out-of-plane rotation; SV: scale variation; OCC: partial or full occlusion; DEF: non-rigid object shape deformation; MB: motion blur; FM: fast motion; IPR: in-plane rotation; OV: out of view; BC: background clutters; LR: low resolution.
a Bold data indicate the AUC scores are top three.
Figure 7 shows the ranking of success plots of all benchmarking methods on the 11 challenging attributes. On challenging attributes of SV, OCC, out-of-plane rotation (OPR), DEF, FM, MB), OV, in-plane rotation (IPR), and LR, the success plot of our method ranks the first. Despite the lack of a scale-changing mechanism, our method still has the best performance with 0.390 score on SV attribute. In similar methods, ASLA using local information also has a good score on SV attribute, but its score is lower than our method by 3%.
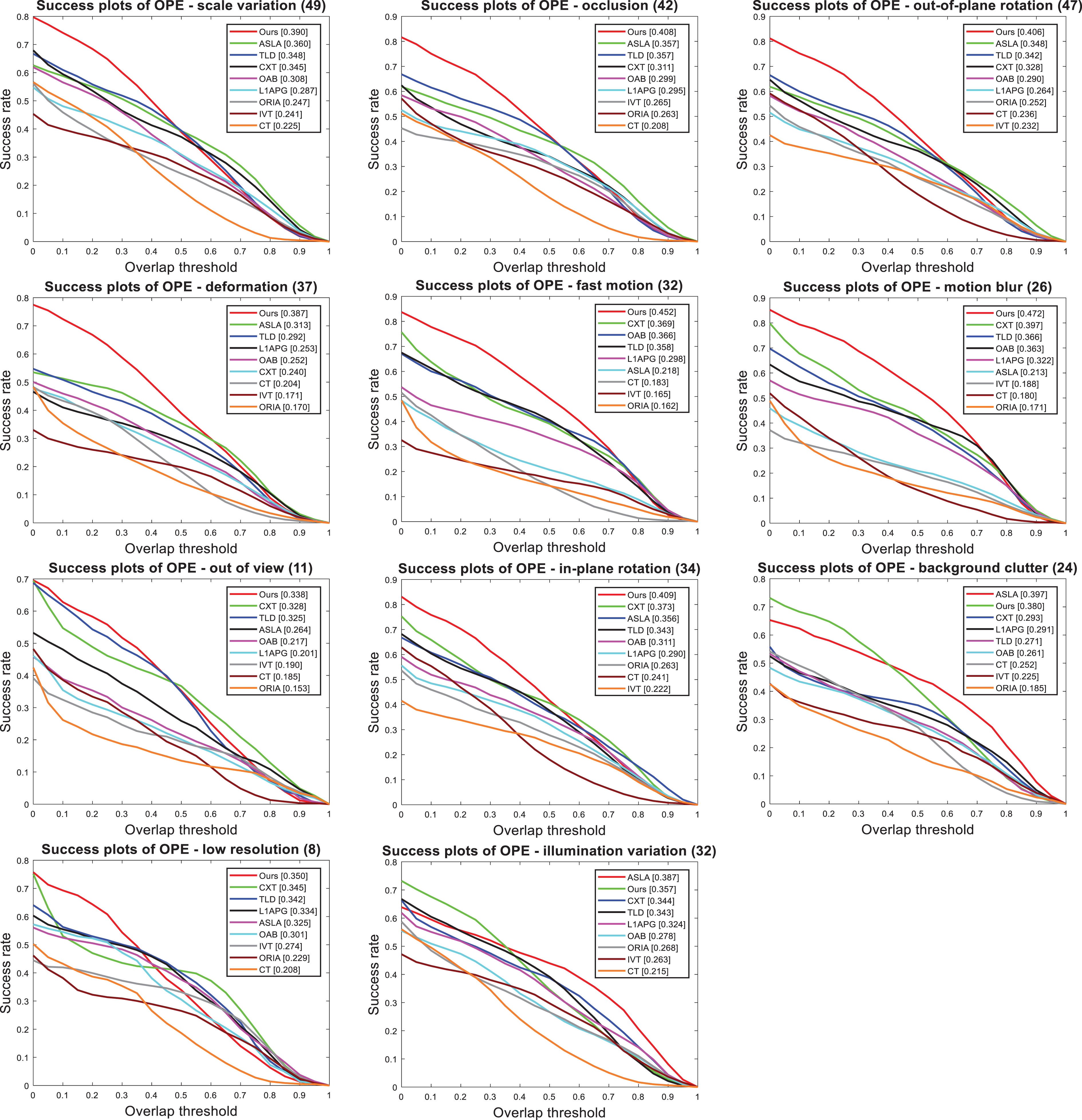
Success plots of 11 challenging attributes on all 74 RGB sequences of OTB100. 37
The AUC scores of our method are higher than the second method ASLA by 5.8% and 7.4% on the attributes OPR and DEF, respectively, which shows the effectiveness of our feature selection mechanism in the target appearance change. ASLA and TLD trackers use local information and have good scores on OCC attribute, which are 5.1% lower than our method. On attributes FM and MB, our method is 8.3% and 7.5% higher than the second method CXT, respectively. The ASLA tracker used local information and had the best results on background clutter (BC) and illumination variation (IV) attributes, and the success rate score of ASLA is 0.397 which is better than other similar methods.
Qualitative analysis
Figure 8 shows the tracking process of eight similar trackers and our method in the several RGB sequences. In Figure 8, our method has good tracking performance on the attribute of MB and FM. In sequences Deer and BlurOwl, although tracking drift sometimes occurs, our approach can readjust the tracking position through the positive and negative templates when drifting is not severe. In general, OAB has a good tracking effect in these two videos, but it is prone to have tracking drift problems when the target moves fast, as shown by #0025 of Deer and #0390 of BlurOwl. CXT tracker can well recognize the target information in these sequences, but when the target blur and FM occur, the scale of the tracking will be abnormal.

Comparison of the proposed approach with eight benchmarking methods ASLA, IVT, OAB, L1APG, TLD, CT, ORIA, and CXT. ASLA: adaptive local sparse appearance model-based tracker; IVT: incremental learning-based tracker; OAB: online boosting tracker; L1APG: L1 sparse tracker using APG; TLD: tracking learning-detection tracker; CT: compress tracker; ORIA: online robust image alignment tracker; CXT: context tracker.
Sequences bolt, bolt2, and basketball are typical of the target DEF. CT tracker is a tracking method based on compressed sensing and has good performance in target DEF, as shown in sequence bolt2. However, it appears that many tracking failures occur in sequences deer and BlurOwl, which indicates that CT tracker suffers from target FM easily. Our method performs well in the challenges of target DEF, but not in IV. As shown in #0700 of sequence basketball, our method shows significant tracking drift when there is a noticeable illumination change.
In sequence David3, most trackers suffer from OCC and BC, but our method can effectively deal with short-term occlusion of a large area because the adaptive dictionary update strategy minimizes occlusion interference. From the sequences David3 and couple in Figure 6, we can see that OAB, CT, and the proposed approach have good tracking performance in the background changes. TLD has the problems of tracking drift and target lost. Both ORIA and CXT trackers are affected by small-range occlusion, which causes to tracking failure. In sequence David3 #0146, a wide range of occlusions also leads to tracking failures of CT and OAB. Our method effectively identifies the target location in these cases and does a good job for the rest of tracking tasks.
In the last two sequences, Lemming and DragonBaby contain multiple challenge attributes such as SV, OCC, rotation (IPR or OPR), and OV. It can be seen in Figure 6 that the tracking drift is easily occurred when the target fast rotation, SV, and BC occur simultaneously. In #1010 and #1078 of sequence Lemming, TLD, CXT, and CT trackers have obvious tracking drift due to fast rotation, while OAB and our method do not suffer from that and perform better results. In #0084 and #0096 of sequence DragonBaby, our method performed well for target fast rotation and background interference. CXT tracker has tracking scale anomalies, and other methods have repeatedly experienced tracking drift and tracking failure. In sequence human8 #0054 and #0070, most trackers have tracking failures when both illumination and scale changes occur. At the #0101 and #0126 frames of sequence human8, the true scale of the target is significantly smaller, and the result area selected by our method contains a large amount of background information. This situation makes the performance of our tracker unstable and prone to tracking failure.
Conclusion and future work
This article proposes a novel visual tracking method based on the weighted discriminative dictionaries and a pyramidal feature selection strategy. We utilize color features and noncolor features of the training samples to build multiple discriminate dictionaries. Then, we use the position information of samples to assign weights to the base vectors in dictionaries. These weights are used to optimize the process of target searching for selection of candidate samples, so that the frequency of abnormal samples can be effectively reduced. In the tracking process, for reducing the introduction of interference information in the dictionary and improving the tracking efficiency, we gradually update the dictionary based on noise analysis of the sparse coefficients. During the incremental update process, we sample the pool to maintain the appearance change of the target and obtain the current foreground and background information. The positive sample pool also uses a random replacement maintenance strategy to maintain the class balance of the samples. Experimental results on the all RGB sequences on OTB100 37 show that the proposed method is effective to deformation, occlusion, and other challenges in object tracking.
We will further investigate this work. First, in the video scene with cluttered background, the target is easy to be misjudged. We plan to increase the fusion of three or more features to enhance the accuracy of the target representation. Secondly, when the target scale changes, it is easy to drift away even though there are different scales of sampling. So, the mechanism of dealing with the change of target scale should be further studied.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Natural Science Foundation of China (grant numbers 61772144 and 61672008), Guangdong Provincial Application-oriented Technical Research and Development Special Fund Project (grant number 2016B010127006), Foreign Science and Technology Cooperation Plan Project of Guangzhou Science Technology and Innovation Commission (grant number 201807010059), the Scientific and Technological Projects of Guangdong Province (grant number 2017A050501039), Innovation Team Project (Natural Science) of the Education Department of Guangdong Province (grant number 2017KCXTD021), Innovation Research Project (Natural Science) of Education Department of Guangdong Province (grant number 2016KTSCX077), and Foundation for Youth Innovation Talents in Higher Education of Guangdong Province (grant number 2018KQNCX139).