
Abstract
In this article, a point-wise normal estimation network for three-dimensional point cloud data called NormNet is proposed. We propose the multiscale K-nearest neighbor convolution module for strengthened local feature extraction. With the multiscale K-nearest neighbor convolution module and PointNet-like architecture, we achieved a hybrid of three features: a global feature, a semantic feature from the segmentation network, and a local feature from the multiscale K-nearest neighbor convolution module. Those features, by mutually supporting each other, not only increase the normal estimation performance but also enable the estimation to be robust under severe noise perturbations or point deficiencies. The performance was validated in three different data sets: Synthetic CAD data (ModelNet), RGB-D sensor-based real 3D PCD (S3DIS), and LiDAR sensor-based real 3D PCD that we built and shared.
Introduction
As the usage of point cloud data (PCD) continues to increase, it has been shown that not only PCD’s representation (x, y, z) but also PCD’s properties such as normal and intensity make significant contributions in various applications. 1 –3 Among those properties, this article focuses on the normal property of PCD, which is an orthogonal direction of a local planar patch constituted by multiple points.
Although there are a variety of conventional methods, 4 –7 their substantial layer is principle component analysis (PCA), which generates a local planar patch by sampling a few points in the nearest neighbor sense. As PCA is weak against noises, several variations that adaptively tune the algorithm parameters have been proposed. 8 –11 In the authors’ point of view, these approaches do not pinpoint the essential factors of normal estimation, as their performances drastically drop with increasing noise levels.
An alternative approach is to adopt the deep neural network designed for PCD, such as VoxNet, 12 ShapeNet, 13 DeepPano, 14 OctNet, 15 and PointNet 16 , as a substantial layer. All of the above networks, except PointNet project 3-D PCD to low-dimensional primitives (such as volumetric representations, 12,13,17,18 octree representations, 15 2-D image projection representations, 14,19 and multiple data representations 20 ), and this projection, in return, makes point-wise normal estimation unavailable. In contrast, PointNet handles 3-D PCD as they are, and we adopt it as a substantial layer of our method.
However, PointNet only extracts local features using multilayer perceptron, which does not use neighboring information. In other words, PointNet has a deficiency in extracting local features. Considering this weakness of PointNet, several variations utilizing neighboring information have been proposed. 21,22
As a normal vector is a type of local information, we need to extract robust and informative local features. Therefore, we adopt the advantages of several methods 4,21 –23 to utilize neighboring information. The proposing network module, “multiscale K-nearest neighbor (K-NN) convolution module,” is shown in Figure 1. The multiscale K-NN convolution module is specially designed for normal estimation. In addition, we adopt the PointNet architecture as the basis model and utilize our proposing module into PointNet. The overall proposed network, NormNet, is shown in Figure 2. This network is trained by a 3-D PCD data set with labels of point-wise segmentation and normal. Here, note that each label of point-wise normal is not the ground truth but an estimation result by the automatic PCA method. This is a natural consequence of the huge amount of points (e.g. one of our data sets consists of 100 million points), and that is why we adopt automatic annotations at the sacrifice of accuracy.

Multiscale K-NN convolution module. K-NN: K-nearest neighbor.
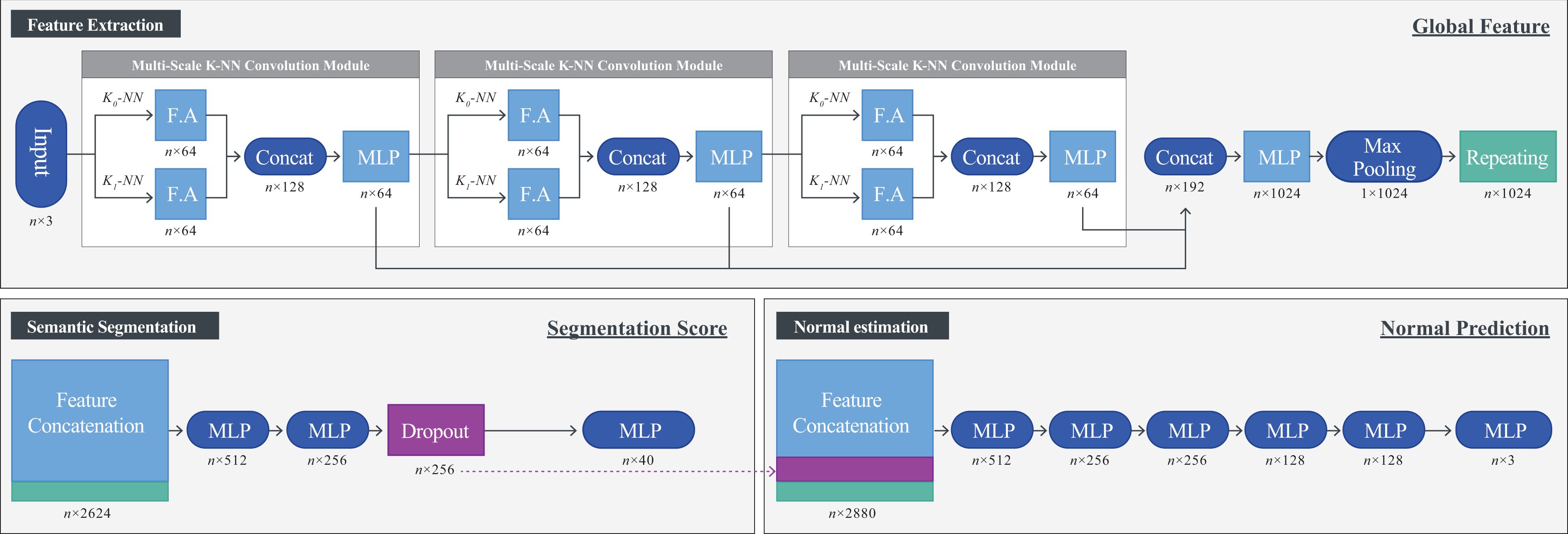
Architecture of the point-wise normal estimation network for 3-D PCD: NormNet. PCD: point cloud data.
The design principle of NormNet is to hybridize local, global, and semantic features simultaneously. The local feature corresponds to a point feature (sky-blue layers in Figure 2) of which the parameters are trained by estimated normal from the multiscale K-NN convolution module. The multiscale K-NN convolution module only use local feature like PCA methods, and it also contains weakness of the local feature that degrade performance near edges. We redeem this problem by using a global feature (the green layer in Figure 2). Also, the problem that local feature-based methods (PCA methods) are weak against noises can be handled by considering semantic information(such as floor and rounded ball) supported by a segmentation feature (the purple layer in Figure 2).
For comparison, the K-NN technique,
4
PointNet,
16
PointNet++,
21
DGCNN,
22
and PCPNet
24
were selected. The K-NN technique
4
is the most popular one (
For training and testing, three data sets were used: a synthetic data set (ModelNet 13 ), a RGB-D sensor-based real dat aset (S3DIS 25 ), and a LiDAR sensor-based real data set (PERL) that we built and shared on a web page. 26
The evaluation results show that the proposed method outperforms K-NN, PointNet, PointNet++, DGCNN, and PCPNet in ModelNet data set and tends to estimate more consistent normal in the S3DIS and PERL data sets. Furthermore, it appears that the proposed method captures more essential features than these methods, as its performance is far more robust.
The rest of this article is organized as follows. The proposed method is explained in the second section. Details of data sets are given in the third section. The evaluation results are analyzed in the fourth section, and the conclusion follows.
Methodology
Multiscale K-NN convolution module
Normals are local information, involving relations of neighboring features. Therefore, existing methods 4 –7 utilize K-NNs and PCA algorithm to compute relations of neighboring features. However, PointNet adopts basic multilayer perceptions for local feature extraction. In other words, PointNet only utilizes a point-wise feature as a local feature, so it does not contain information about the neighborhood. However, as a local feature, not only point-wise information but also neighbor information is very important for normal estimation.
To utilize relations of the neighboring information, we propose the multiscale K-NN convolution module which acts like the existing K-NN and PCA methods. The concepts are shown in Figure 1.
To implement our multiscale K-NN convolution module, we used pyramid pooling module, 23 multiscale grouping, 21 and edgeConvolution 22 as guidelines.
Our multiscale K-NN convolution module aggregates different scale of features, which is similar to PointNet++. 21 We use multiscale feature aggregation because local features from different scale generate more robust and more informative than using only one scale. 21,23
For feature aggregation, there are many methods that can be used



where xi is a central pixel, xj : (i, j) ∈ κ is a K-nearest neighbor points around it, θj are weights of each parameter, and function f indicates multilayer perceptrons.
Here, equation (1) denotes the weighted sum of features. Although PCD are unstructured and unordered data, the weighted sum causes difficulty in training, and not appropriated for a pointcloud data set. Equation (2) is a special case of equation (1), where every weight is equal to one divided by the number of points. Equations (2) and (3) are symmetric functions that resolve problems of pointcloud data set (unordered, unstructured). In particular, PointNet 16 adopts equation (3) so as to extract global features.
In the proposed multiscale K-NN convolution module, we adopt edgeConvolution introduced in DGCNN 22 for feature aggregation. The edgeConvolution is given by
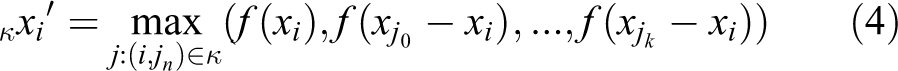
Thus, given an F-dimensional point cloud with n points, edgeConvolution produces an F′-dimensional point cloud with the same number of points.
Combining multiscale feature aggregation and edgeConvolution as a local feature extraction, our multiscale K-NN convolution module is given by

where a function ⊕ denotes the feature concatenate operator.
The multiscale K-NN convolution module aggregates multiscale neighboring features, which enables it to utilize relations of the neighboring information.
Network architecture
The PointNet 16 is an appropriate deep learning network for unordered, unstructured PCD. PointNet combining local feature (point feature) and global feature to predict point-wise classes. This approach is suitable for our problems, so we adopt PointNet as a substantial layer of our method. We integrate Pointnet with our proposed module (multiscale K-NN convolution module).
The proposed network, NormNet is shown in Figure 2, where “F.A” denotes the “feature aggregation” mentioned in the multiscale K-NN convolution module. Specifically, we adopted edgeConvolutions for feature aggregation. We adopt multilayer perceptrons with layer size 64 for the feature aggregation. “Conncat” denotes the feature concatenation that simply concatenates two or more features. “MLP” denotes the multilayer perceptron. “Repeating” denotes tiling the output of “Max Pooling” feature.
The network takes n-point clouds as input. This input passes into three multiscale K-NN convolution modules, one after another. This serially connected module extract local feature hierarchically. After this module, three outputs are concatenated from each multiscale K-NN convolution module, followed by the multilayer perception, and then the features are aggregated by max-pooling. We term this feature as a global feature same as in PointNet. The global feature contains global information of the input data. All of the sky-blue layers in feature extraction are termed local features.
In the semantic segmentation network, all of the local features and global features (sky-blue layers and green layer in Figure 2) are concatenated, followed by multilayer perceptrons and dropout layer, as shown in Figure 2. We term the output of dropout layer (purple layer in Figure 2) as a semantic feature because this feature contains semantic information of input.
Similar to the normal estimation network, concatenate not only all the local and global features but also the semantic feature, followed by multilayer perceptrons to predict normal.
Here, every layer used batch normalization with rectified linear unit (ReLu).
Objective function
In NormNet, a loss function is designed in a way that performs the original task of PointNet (semantic segmentation) as well as normal estimation. For the semantic segmentation, we adopted the cross entropy loss, which gives class-wise segmentation scores in K classes, defined as
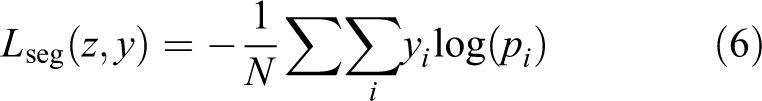
with
For the normal estimation, we designed a loss function of

with
Combining the above two losses, our total loss for our network is as follows.

Now, let us describe the physical meaning of these loss functions. The first term Lang contains cosine distance, which gives low values when the predictions are similar to the ground truth. However, as its derivative tends to drastically decrease from a tipping angle of 30°, an additional term that derives the loss to zero is needed. Thus, we add L 1, the derivative of which is −1, from the tipping angle to zero. In addition, we adopt a normalization factor Lnorm, so that multiple loss values can evenly contribute.
Data set
For the training and validation of networks, we made use of three data sets, including a synthetic CAD data set (ModelNet40 13 shown in Figure 3), and a real 3-D PCD acquired by RGB-D sensor (S3DIS 25 shown in Figure 4). As there is no indoor data set from LiDAR sensor, which is as popular as RGB-D in the robotics field, we built our own data set called PErecptional Robotics Lab (PERL shown in Figure 5). All of these data sets can be downloaded from the web page 26 as used in this article.

Sample images of synthetic data sets: ModelNet40, and generated Pointcloud..

Sample image of RGB-D data set: Matterport 3-D scanner and S3DIS data set.

Sample image of 3-D LiDAR data set: sensor system with two LiDARs (Velodyne VLP-16), 9-DoF IMU (3DM-GX3-45), and 360 Camera (Ladybug 5).
Synthetic data set: ModelNet40
ModelNet data set was introduced in 3-D ShapeNet, 13 the purpose of which is 3-D shape recognition and reconstruction. This data set follows the standard CAD format and consists of edges and vertices. It contains 12,311 models with 40 labels.
However, as there is neither a point cloud nor its normal, we manipulated ModelNet in such a way that 4096 points are uniformly sampled from CAD model. The normals of each point were calculated by the cross product of edges of a face. As this is an ideal data set, we intentionally added Gaussian noise with its mean and standard deviation (σ) of 0 and 0–0.02, respectively. In addition, to minimize the effect of wide range of object’s size (from small chair to huge airplane), we normalized all objects’ size into a unit sphere.
RGB-D data set: S3DIS
The S3DIS data set was introduced by Armeni et al., 25 the purpose of which is a point-wise semantic parsing of 3-D PCD. This data set was constructed using a Matterport scanner which is assembled of multiple RGB-D sensors. It consists of six subsets that cover 271 rooms with 13 categories.
For NormNet, we modified S3DIS in such a way that 4096 points were randomly sampled from a block. Here, a block covers 1 × 1 m2, of which half overlaps to the previous block and the other half to the next one.
LiDAR data set: PERL
As there is no publicly available Indoor LiDAR PCD data set, we built our own using a sensor system, as shown in Figure 5. This system is composed of two LiDARs (Velodyne VLP-16), 9-DoF IMU (3DM-GX3-45), and 360 Camera (Ladybug 5).
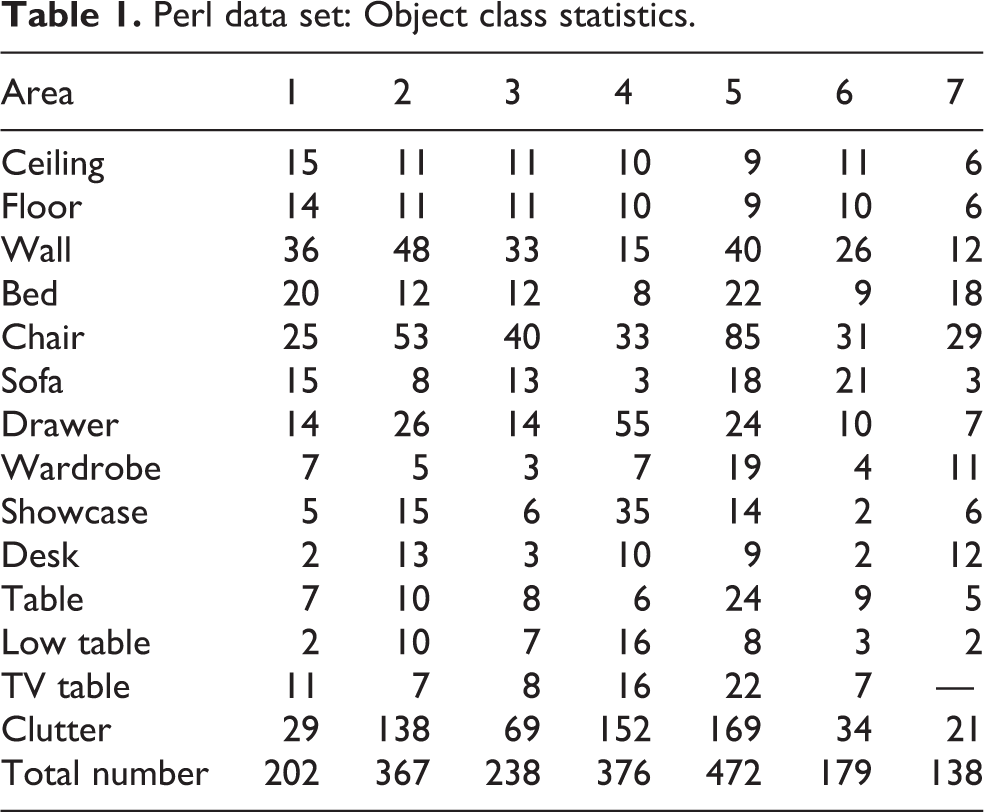
As our interest is objects, we set our target place to furniture exhibition shops. Using the sensor system, we scanned seven shops and conducted pose-optimization with our SLAM algorithm. 27 We manually segmented each object in 14 categories, the details of which are presented in Figure 6 and Table 1.

Images of PERL data set: seven areas with 1972 obejcts in 14 categories.
Perl data set: Object class statistics.
Experiments
For experiments, three sets of data are used: one synthetic and two real data sets. Considering that labeling point-wise ground truth cannot be realized for the real data set (due to huge amount of points), the synthetic and real data sets are in a complementary relationship as follows. Quantitative analyses can be conducted for the synthetic data (as there is the ground truth), while only qualitative interpretation is available for the real data. By contrast, the effects of the real noises cannot be evaluated for the synthetic data, while those with RGB-D and LiDAR sensors can be verified in the real S3DIS and PERL data set, respectively.
Synthetic data set: ModelNet experiments
In this section, we use K-NN method 4 PCPNet, 24 PointNet, 16 PointNet++, 21 and DGCNN 22 for comparisons. Here, the K-NN method 4 and the PCPNet 24 only use local patches, which estimate normals without global information. However, PointNet, 16 PointNet++ 21 and DGCNN 22 can estimate normals with global information (including segmentation feature). To compare with the same conditions, we applied the same loss function and architecture, aside from the local feature extraction module. PointNet uses multilayer perceptions, PointNet++ uses multiscale grouping (MSG), and DGCNN uses edgeConvolutions for local feature extraction.
As the performance of the K-NN-based method depends on the value of k, the physical meaning of which is the number of points to use for local feature extraction, we first conducted a performance test for various k values, as shown in Figure 7. Here, the solid and dashed lines indicate percentages, the estimated angle errors of which are within 25° and 15° (‘accuracy #’ from now on) relative to the ground truth, respectively. Based on this test, k was set to be 27, where the accuracy 25° hits the maximum.

Accuracy of K-NN as k value varies, where k = 27 shows the best performance. K-NN: K-nearest neighbor.
With these k values, accuracies for various angles (from 25° to 1°) were evaluated as in Table 2. Here, it can be noted that as the judging criteria become strict, NormNet outperforms the K-NN based method, PointNet, PointNet++, DGCNN, and PCPNet. This result is illustrated in Figure 8, which shows a relative accuracy enhancement of NormNet as the judging criteria become strict. Some experimental examples are shown in Figure 9.
ModelNet40 result: Percentage of points of which the estimated angle error is within a certain bound for K-NN, PCPNet, PointNet, PointNet++, DGCNN, and NormNet.
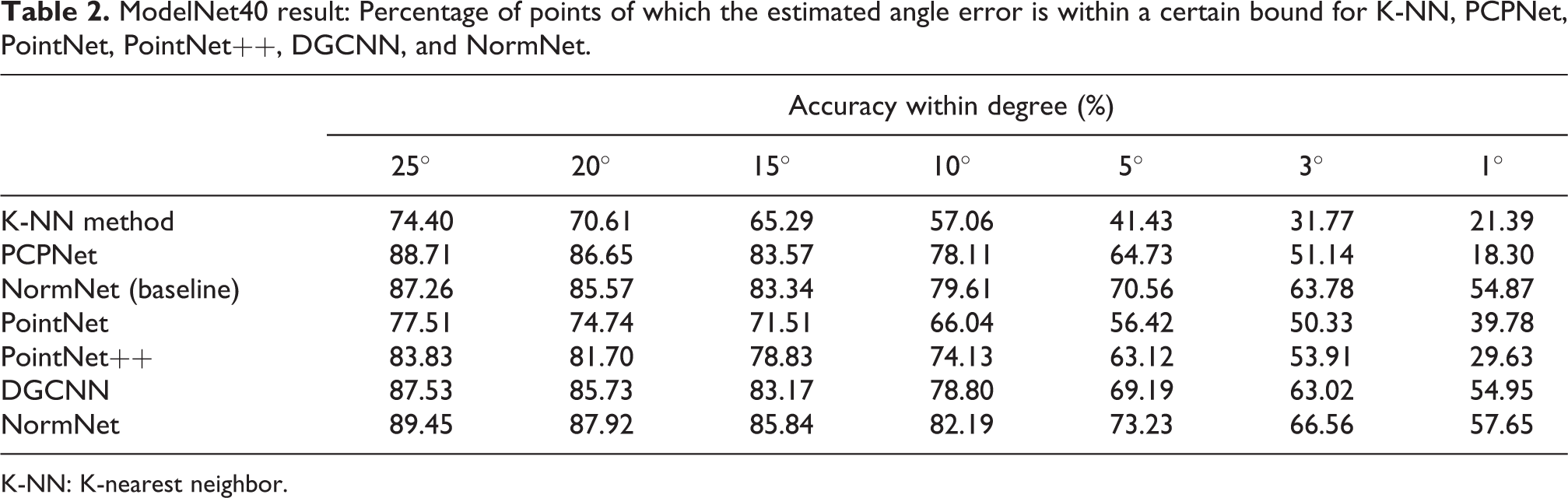
K-NN: K-nearest neighbor.

Accuracy enhancements of PointNet (purple), PointNet++ (yellow), DGCNN (green), PCPNet (blue), and NormNet (red) relative to K-NN as degree of judging criteria decreases. K-NN: K-nearest neighbor.

Point normals of ground truth (left), K-NN (center), and NormNet (right) for ModelNet40. Here, green, blue, and red arrows indicate that each normal estimation error is <15°, <25°, and >25°, respectively. K-NN: K-nearest neighbor.
Comparing NormNet with the K-NN-based method, the relative accuracy enhancement is drastic (Figure 8). This result is natural because the K-NN-based method only uses local patch (local information) for normal estimation. This means that K-NN-based methods do not consider the overall shape of features. As a result, point clouds on the edge or sharp inflection points estimate the normal smoothly. Also there exists various estimated normals despite point clouds on the same plane due to noises or effect of points on the neighbor planes. However, NormNet uses not only local feature but also global feature for prediction. As a result, point clouds on the edge or sharp inflection points estimate the normal sharply.
PCPNet also estimates normals without global information. PCPNet extracts local patches and estimates normal using learned features. However, PCPNet contains some problems. First, PCPNet is deeply based on PointNet network, which cannot estimate essential local features. This result is illustrated in Figure 8, which shows PCPNet shows similar accuracy in 25% but shows poor performances when judging criteria become strict. Second problem is computation complexity. PCPNet estimates normal by extracting local patches at every pointclouds, and this takes a lot of time. PCPNet takes 11,626 s for evaluating every ModelNet40 test data set. However NormNet only takes 502.53 s.
Comparing NormNet yield with PointNet, PointNet++, and DGCNN, NormNet estimates more accurate normals than these methods, as represented in Table 2. This result indicates that the multiscale K-NN convolution module captures more essential features than multilayer perceptron, multiscale grouping, and edgeConvolution.
We also evaluate effect of semantic features for normal estimation. We estimate normals using NormNet without segmentation feature. This result is shown in Table 2, under the name of NormNet (baseline). This result shows that segmentation features increase the accuracy about 2%.
Regarding the robustness, two realistic scenarios need to be considered. The first is to consider sensor noises as dynamic factor. By the term dynamic, we mean that even though one tunes a noise level after many trial and errors, it may vary with distance or as the surface materials of the target change. Thus, it needs to be considered that noise levels of training and testing data set could differ.
To test the robustness in this scenario, we first set a reasonable range of sensor noise from σ = 0.00 to σ = 0.02 by referring several research papers. 28 –30 We then trained PointNet, PointNet++, DGCNN, PCPNet, and NormNet for four cases(σ = 0.00, 0.004, 0.01, 0.02) and found the best k values for the K-NN-based method in each case as we did in Figure 7. After these preparations, we tested robustness against different noise levels as they vary in the reasonable range as in Figure 10.

Accuracy of K-NN (black), PointNet (purple), PointNet++ (yellow), DGCNN (green), PCPNet (blue), and NormNe t(red) for their accuracy 25° (solid) and 15° (dashed) as test noise σ varies. Here, training noise σ was set to be 0.0, 0.004, 0.01, 0.02 for (a) to (d), respectively. K-NN: K-nearest neighbor.
Figure 10(a) is a result of training with zero noise. This result properly shows our intuition work. The NormNet’s graph is similar to the K-NN’s, which means that our multiscale K-NN module extract local features like the K-NN.
Figure 10(b) is a result of training noise σ = 0.004. Figure 10(b) shows that NormNet outperforms K-NN, PointNet, PointNet++, and PCPNet within the 4σ (4 times training noise), and DGCNN within the 3σ (3 times training noise). In other words, NormNet outperforms K-NN, PointNet, PointNet++, DGCNN, and PCPNet in the RGB-D sensor noise level.
Figure 10(c) and (d) shows the results of training noise σ = 0.01, 0.02, respectively. Figure 10(c) and (d) shows that NormNet outperforms not only K-NN but also PointNet, PointNet++, DGCNN, and PCPNet within the RGB-D sensor and LiDar noise level.
The second scenario is to consider that practical users tend to sample a part of PointCloud due to the huge amount of points. Thus it needs to be verified whether normal estimation methods still work well under this point deficiency. For this, for the same four σ and k values as before, accuracies were tested as the missing points increase, as shown in Figure 11. In this test, NormNet consistently works well with up to 85% missing points.
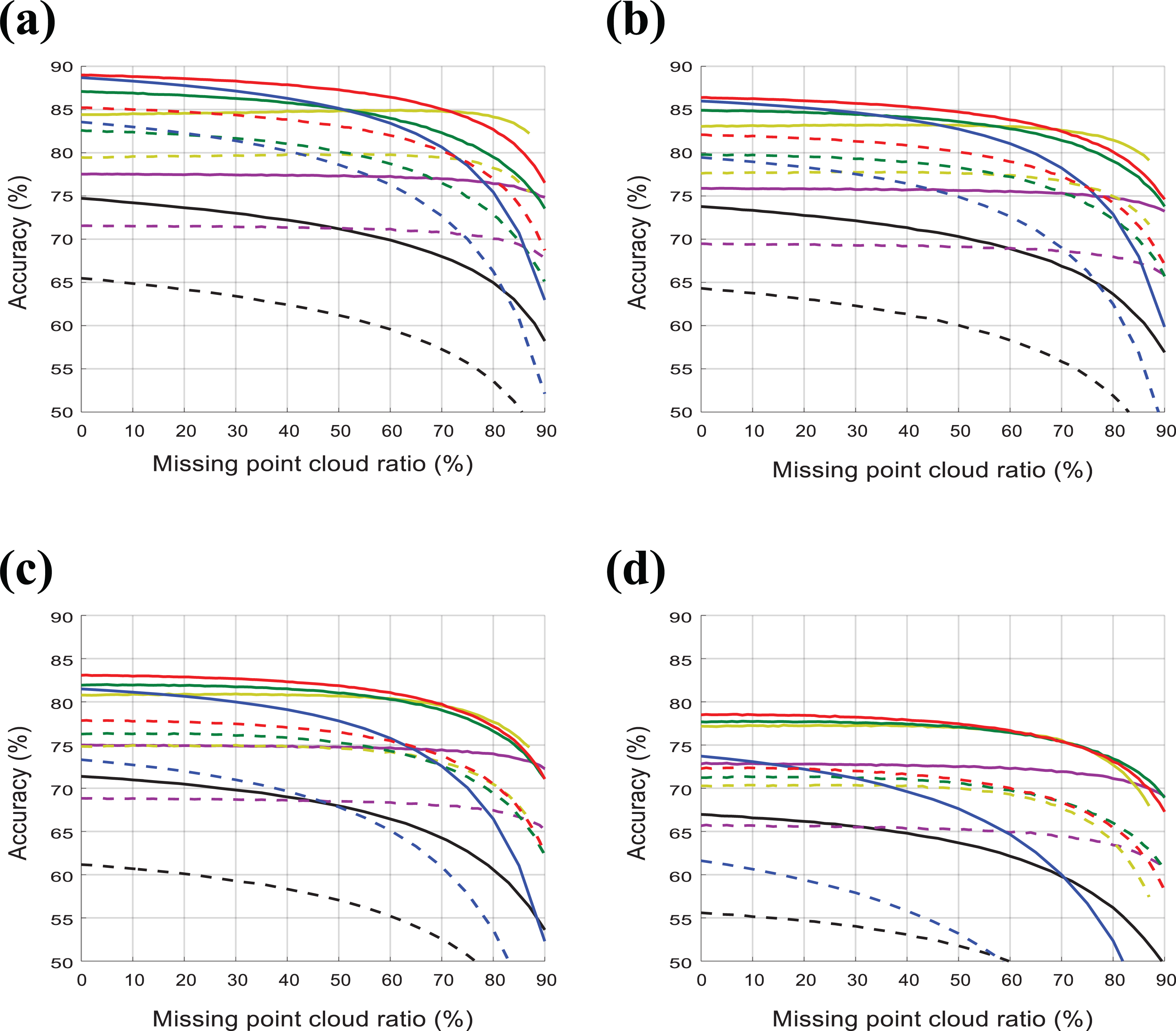
Accuracy of K-NN (black), PointNet (purple), PointNet++ (yellow), DGCNN (green), PCPNet(blue), and NormNet(red) for their accuracy 25° (solid) and 15° (dashed) as test PCD density varies. Here, training noise σ was set to be 0.0, 0.004, 0.01, 0.02 for (a) to (d), respectively. K-NN: K-nearest neighbor.
From this result, we carefully insist that the contributions of the global and the semantic feature are significant as the performances are still consistent in the ranges of up to 85%, where the contribution of local features mostly diminishes.
Real data sets: S3DIS and PERL experiments
For the real data set, we trained the proposed network with two kinds of annotations: point-wise segmentation and normals. Considering the ground truth of these, the segmentation can be manually labeled while that of the normal is beyond human’s labor (as there are billions of points). This indicates that a quantitative comparison can be applied for the segmentation and that we need to adopt a qualitative comparison for normals.
First, as the synthetic analysis in Table 2 shows segmentation features enhances the estimation of normal. Thus, we can implicitly insist that better segmentation yields better normal estimation. The segmentation results are presented in Table 3. Here, the S3DIS result is the mean of a threefold evaluation, as in the original paper, and the PERL result is the mean of a sevenfold evaluation with six areas for training and one area for testing.
S3DIS and PERL result: segmentation accuracy and mean Intersection over Union values for PointNet, PointNet++, DGCNN, and NormNet.

mIoU: mean Intersection over Union; K-NN: K-nearest neighbor
Second, regarding the qualitative comparison for normals, we set the result of K-NN-based method as a pseudo-ground truth and trained each method using the same pseudo-ground truth. A qualitative approach that examines tendencies of irregular normals of which estimations from K-NN, PointNet, and NormNet are quite different is adopted. Examples are shown in Figures 12 and 13 for S3DIS and PERL data, respectively. Here, for places of which normals are evident, irregular normals are shown in red arrows. As it can be observed NormNet outperforms than K-NN and PointNet.

Given S3DIS data set, point-wise normals were estimated using K-NN (top), PointNet (middle), and NormNet (bottom). Here, blue and red arrows indicate point normals within 25° and >25° differences between K-NN respective to NormNet, PointNet respective to K-NN and NormNet respective to K-NN estimations, respectively. Here, red arrows are shown on the surface of corridor (the first column), angled chair (the second column), shiny floor (the third column), rounded desk (the fourth column), and irregular objects (the fifth column). K-NN: K-nearest neighbor.

Given PERL data set, point-wise normals were estimated using K-NN (top), PointNet (middle) and NormNet (bottom). Similar to the result of S3DIS, red arrows appear either on edges or irregular surfaces. K-NN: K-nearest neighbor.
We attribute the enhancement to three reasons. The first is that the global and semantic features correct locally distorted normal directions. The second is that the multiscale K-NN convolution module extracts essential local features well. The third is that the robustness against a wide range of noise levels enabled consistent estimation for carpets and floor (as shown in the second and fourth row from the top in Figure 12) and sharp edges (Note that time-of-flight sensors such as RGB-D sensor and LiDAR are sensitive on edges where reflection energies significantly drop due to light scatterings.).
Conclusions
This article proposed a NormNet which estimates surface normals. The NormNet not only successfully segments 3-D PCD (as does PointNet) but also accurately estimates normal direction better than the previous method K-NN. 4 The key contributions are the design of local feature extraction module and the extraction of a surface normal in a hybrid way: global and semantic features from PointNet architecture and local feature from the proposed module, multiscale K-NN convolution module. Although analytic proof is not available due to the complex network structure, the experimental results implicitly support our claim that those three features mutually support each other. As a consequence, normal estimation became not only more accurate but also quite robust against noise perturbations or point deficiencies. In addition, the segmentation performance, which is the main role of PointNet, is increased. Finally, it is worth noting that we for the first time built and shared a LiDAR sensor-based 3D indoor PCD PERL data set.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Brain Korea 21 Plus Project in 2019, National Research Foundation of Korea (NRF) Grant (No. NRF-2011-0031648) funded by the Ministry of Science and ICT (MSIT), a Korean Evaluation Institute of Industrial Technology (KEIT) Grant (No. 10073166) funded by the Ministry of Trade, Industry and Energy(MOTIE), and a Grant (No. 19NSIP-B135746-03) from National Spatial Information Research Program (NSIP) funded by Ministry of Land, Infrastructure and Transport of Korean government.