
Abstract
Dynamic motion primitive has been the most prevalent model-based imitation learning method in the last few decades. Gaussian mixed regression dynamic motion primitive, which draws upon the strengths of both the motion model and the probability model to cope with multiple demonstrations, is a very practical and conspicuous branch in the dynamic motion primitive family. As Gaussian mixed regression dynamic motion primitive only learns from expert demonstrations and requires full environmental information, it is incapable of handling tasks with unmodeled obstacles. Aiming at this problem, we proposed the positive and negative demonstrations-based dynamic motion primitive, for which the introduction of negative demonstrations can bring additional flexibility. Positive and negative demonstrations-based dynamic motion primitive extends Gaussian mixed regression dynamic motion primitive in three aspects. The first aspect is a new maximum log-likelihood function that balances the probabilities on positive and negative demonstrations. The second one is the positive and negative demonstrations-based expectation–maximum, which involves iteratively calculating the lower bound of a new Q-function. And the last is the application framework of data set aggregation for positive and negative demonstrations-based dynamic motion primitive to handle unmodeled obstacles. Experiments on several typical robot manipulating tasks, which include letter writing, obstacle avoidance, and grasping in a grid box, are conducted to validate the performance of positive and negative demonstrations-based dynamic motion primitive.
Keywords
Introduction
Traditional robots have aided humans to accomplish laborious work in factories for several decades. They need merely repeat some preplanned motions in limited or structured environments. In the last few years, the development of deep learning has facilitated substantial progress in the perception abilities of robots. Some challenges once thought unsolvable, such as 3D object recognition and localization, 6D pose estimation, and grasp position prediction, have been solved partly with deep convolutional neural networks. 1 With a stronger perception, the robots can observe and learn skills from human actions actively and directly. That is the skill transfer learning (STL), or imitation learning, of robots.
STL models can be split into three categories 2,3 : motion, policy, and procedural models. Motion models, such as the dynamic movement primitives (DMPs) 4 or hidden Markov model (HMM), 5 treat STL tasks as trajectory encoding and recovering problems. Once the analytical and structured task configuration is available, either predefined manually or fed via additional independent perception modules, motion models are able to learn skills from a few or even only one demonstration. By contrast, policy models, 6,7 such as behavior clone or generative adversarial imitation learning, handle STL tasks as sequential decision problems. Policy models output commands for the actuators (joint angles, Cartesian position, or servo torques) at each control step. Policy models have a superior capability in feature expression and generalization and can produce end-to-end policies. Nonetheless, they rely on numerous demonstrations and a long learning time. Procedural models represent 2 the task structure and configuration at a higher level of semantics, making them more suitable for logical inference in complex tasks. A perfect STL model should possess all abilities and advantages of all three models. Motion models, on the other hand, are most likely to be widely used shortly soon.
DMP 8,9 is the most prevalent motion model nowadays. With a second-order damp-string system that is driven by a virtual force term, DMP encodes the demonstrations first and transfers the shape information to new tasks. DMP and its improved variants, such as Gaussian mixed regression (GMR) DMP (GMRDMP) 4 and compliant parametric DMP (CPDMP), 10 have been thoroughly demonstrated to be capable of extracting and transferring shape information with a few expert demonstrations. When coping with unexpected obstacles, a compensatory force associated with the obstacle can be introduced into the damp-string system to adjust the recovered trajectory. However, the structured representation for unexpected obstacles is not always available in practice, which the DMP methods cannot handle. Could we address this issue through human intervention?
GMRDMP is a very typical and practical member of the DMP family. It draws upon the strengths of both the motion model and the probability model to deal with multiple demonstrations. Thus, we have chosen GMRDMP as the basic method to be improved. Because the optimization problem behind GMRDMP is to recover the demonstration as much as possible, there is no space for the user to modify the recovered trajectory by adjusting hyperparameters. It means that GMRDMP lacks a flexible interaction channel for the user to adjust the recovered trajectory.
Aiming at this problem, we extend GMRDMP with negative demonstrations to improve its flexibility, that is, the positive and negative demonstration-based DMP (PNDMP). Positive demonstrations are the original expert demonstrations, whereas negative demonstrations are failed executions by either the experts or the robot itself. Positive ones highlight what the student robot should perform, while negative ones indicate what it cannot. In supervised learning and reinforcement learning, negative samples are necessary for providing specific annotation information or reward value. Particularly, some researchers have utilized them to filter the nonexpert demonstrations as a preprocessing step for motion models. 11,12 However, to the best of the authors’ knowledge, few studies have sought to directly improve DMP with negative demonstrations.
PNDMP consists of three essential extensions to GMRDMP: A new log-likelihood function is defined for PNDMP to balance the probabilities on positive and negative demonstrations. With it, we can establish an adjusting mechanism for the recovered trajectories. A positive and negative demonstrations-based expectation–maximum (PNEM) algorithm is proposed to solve the optimization problem with respect to the new log-likelihood function. A new Q-function and its lower bound are deduced to obtain an iterative solution. PNDMP is applied in the data set aggregation (DAgger)
13
framework to tackle unmodeled obstacles. In the PNDMP DAgger framework, negative demonstrations implying unmodeled obstacles are gathered and annotated during the training process, and then used to retrain the Gaussian mixed model (GMM). DAgger is a fundamental paradigm designed primarily for policy models, however, it has not been applied to motion models yet.
The rest of the article is organized as follows. The second section reviews recent developments of DMP. The third section introduces some prerequisite knowledge and arise the optimization problem of PNDMP. The fourth section presents the main algorithms. Experimental results are analyzed in the fifth section. At last, some conclusions are drawn in the sixth section.
Related work
DMP uses a spring-damping dynamic system to fit the evolution of the observed states. 8,14 The dynamic system is driven by a nonlinear force term that is encoded in the form of a weight vector and a group of Gaussian basis functions. Typically, the weights are optimized via some regression methods such as linear weighted regression, 15 linear weighted projection regression, 16 and Gaussian process regression (GPR). 17 DMP can ensure that the system converges to a new target state theoretically. To consider the random characteristics of multiple demonstrations, probabilistic models have been introduced into the DMP framework. With an appropriate probabilistic model, such as GMM, 18 HMM, 10 hierarchical Bayesian model, 19,20 and kernel model, 21 the spatial and temporal correlations among demonstrations can be represented by a few parameters. A typical probabilistic DMP framework can be summarized as three steps. First, the virtual force terms of all demonstrations are extracted via the dynamic equation of DMP. Second, force trajectories are encoded with a probabilistic model. Finally, the virtual force is retrieved via the probabilistic model for a new task, based on which the motion is then evolved via the dynamic equation of DMP. A recent comprehensive survey about the DMP family can be referred to in the study of Saveriano et al. 22
Many trajectory encoding methods have been proposed to improve the adaptability of probabilistic DMP. GMRDMP, 4 which adopts the expectation–maximization (EM) algorithm to obtain a GMM of the virtual force and the GMR algorithm to recover the force trajectories, is a prevalent probabilistic DMP method. Gribovskaya et al. 18 used a one-order nonlinear multivariate system to replace the spring-damping system, and this system can ensure robustness to external spatial-temporal perturbations through online adaptation of a motion. Colome and Torras 23 proposed a probabilistic dimensionality reduction method to decrease the computation burden of probabilistic movement primitives and extended it to learn the joint couplings. Tanwani and Calinon 24 designed a semi-tied GMM to associate or tie the covariance matrices of the mixture model with a common latent space to cope with perturbations. Lioutikov et al. 25 segmented the demonstrations and established a primitive library, which can be reused in different tasks. Li et al. 26 introduced a dynamic time warp into the GMRDMP 4 to ensure that the sampling time is identical.
Meanwhile, some researchers are devoted to enhancing the robustness when the new task is beyond the demonstration regions. Considering that some shape information would be lost when the target state is not covered by the demonstrations, Calinon 27 proposed the multi-coordinate GMRDMP. Huang et al. 28 introduced confidence weights for each frame of multi-frame GMRDMP and designed an iterative algorithm to choose the frames highly relevant to a task. Pervez et al. 29 encoded the force term of visual demonstrations directly with a convolutional neural network and changed the traditional discriminative model to a generative model 30 to solve the extrapolation problem. The model was trained with synthetic demonstrations to improve its generalization capability. Mei et al. 31 developed a continuous DMP to track dynamic targets, which was referred to as an online navigation method. Karlsson et al. 32 proved the exponential convergence of temporally coupled DMP which is used to solve perturbations. Yang et al. 33 proposed a framework that considers the trajectory tracking module and DMP simultaneously.
Some methods for establishing the relationship between task variables and encoding parameters have also been proposed. Akgun and Thomaz 34 designed a framework to estimate the actions and goals from demonstrations, which can serve for acquiring the relationship. Alizadeh et al. 35 proposed a partial GPR algorithm for the situation that task parameters are partially observed. Liu et al. 36 designed an approximation regression approach to learn the relationship and proposed a post-correction algorithm to improve accuracy.
Safe learning control has attracted considerable attention for a long time, especially in those fields which concern safety extremely. For different tasks, the safety criteria are different. There are four widely used criteria which include the stability of dynamic systems, 37,38 obstacle avoidance, 39 robustness to noise, 39 and the gap between the training set and real tasks. 40 The safety of learning control can be improved in three manners. The first is to utilize an external safety module 39 or manual intervention 41 to abort or modify dangerous motions. The external module requires full obstacle information to evaluate the risk probability and generate a control command on the learning process with an independent algorithm, while the manual intervention requires the framework owns a channel of interaction. The second is to modify the learning process. 42 Guidance or regulation about the safe region is introduced into the learning strategy based on a specific safety model. Although this manner has been used in policy models, it has not yet been used in any motion models directly. The third is to modify the learning goal according to the safety criterion. 43,44
For DMP, the safety criteria should be contained in the spring-damping system in the form of another additional force term. Pervez and Lee 30 combined a generative model with DMP to learn the relation between external configuration and the model parameters, while Liu et al. 36 used GPR to learn the relation. Uger and Girgin 10 extended the nonlinear shaping function to a parametric form using a parametric hidden Markov instead of a weighted sum of radial basis functions. Park et al. 45 added the gradient of a potential field centered on the obstacle, that is, a repellent force, to the dynamic equation. Ginesi et al. 46 proposed some super-quadric potential functions that include the velocity in the form of the potential of obstacles. As all these methods require full information about obstacles, they are unsuitable for tasks in which the structured representation of obstacles is not available.
Preliminaries and problem description
DMP can extract the shape information from one single demonstration, and GMRDMP is developed to learn from multiple demonstrations to improve the generality. In this section, discrete DMP and GMR are introduced first. Then, the reversibility and continuity of DMP and GMRDMP are discussed. At last, a formal representation of the model of PNDMP is presented.
In all figures of this article, “circle,” “X,” and “square” markers represent the starting, end, and target points of a trajectory, respectively.
Dynamic movement primitives
DMP models the kinematics of a demonstration as a spring-damping system and enforces a nonlinear virtual force to it to make the state converge to a target. Up to now, a variety of DMPs have been investigated. 22 In this article, we have considered a basic but relatively well-developed one. 47 The dynamic system can be represented as

where x and

s will decrease from 1 to 0 as the state moves from the starting point to the endpoint, and the decreasing speed is determined by the coefficient

where
For a multi-degree of freedom (DOF) system, each DOF corresponds to an independent spring-damping model, and all DOF share one canonical system. DMP can transfer the shape feature of trajectory from the source task to the target task based on its time and special invariance.
Gaussian mixture regression
GMR provides a probabilistic retrieval of movements or policies with a GMM based on the theory of marginal and conditional distribution. Recovering a trajectory can be formalized as a regression problem. GMR computes the next action on the fly with a computation time independent of the number of data points that are used to train the model.
A GMM with K components is written as

where S is the multidimensional variable,
For a regression task, S,

where the superscripts I and O represent the input and output blocks, respectively.
When given a GMM model

where

In contrast to other regression methods such as locally weighted regression, locally weighted projection regression, or GPR, GMR models the regression function indirectly. It models the joint probability density function of data points and derives the regression function from the joint density model. The estimation of the model parameters is thus achieved in an offline phase that depends linearly on the number of data points. One advantage of GMR is that its regression is independent of this number and can be computed very rapidly. The other advantage is that any variables can be chosen as the input freely without modification of the model. For example, once a GMM about the joint probability
In GMRDMP,
Reversibility and continuity of DMP and GMRDMP
Denote the set of recovered trajectories as S
2 which is obtained from a given set of demonstrations S
1, that is,
Reversibility of DMP
In this test, a DMP model with parameters

DAgger based on PNDMP. (a) Whole trajectories, (b) first half trajectory, and (c) second half trajectory.
Reversibility of GMRDMP
In this test, two demonstrations are given. Their starting and end points are generated randomly from two regions. The starting region is
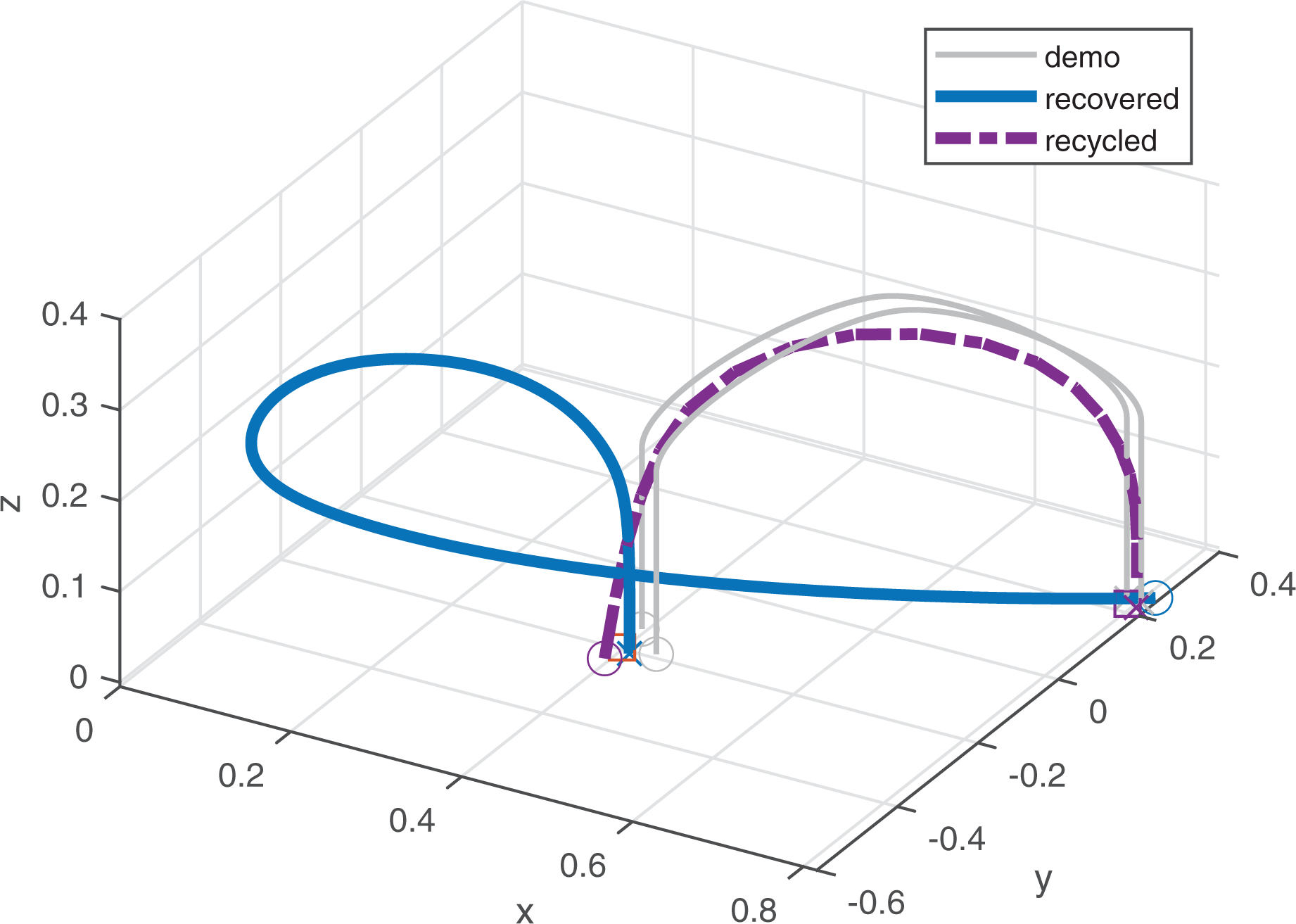
Reversibility of GMRDMP. GMRDMP: Gaussian mixed regression dynamic motion primitive.
Continuity of DMP
In this test, the starting and end points of the demonstration are at

Continuity of DMP. DMP: dynamic motion primitive.
Continuity of GRMDMP
In this test, only one demonstration is given. The targets of the new tasks vary from

Continuity of GRMDMP. GMRDMP: Gaussian mixed regression dynamic motion primitive.
The above tests illustrate that DMP has good reversibility but poor continuity while GMRDMP is just the opposite. The discontinuity of DMP and the reversibility of GMRDMP can be solved by coordinate transformation or normalization. 27 However, different transformation or normalization methods may produce very different results. Many other members of the DMP family also suffer from this problem. This kind of uncertainty is not allowed in industrial applications. Thus, some manual intervention, such as DAgger, is necessary for the application of GMRDMP. As GMRDMP lacks flexibility for interactive adjustment, we intended to utilize the negative demonstrations to improve flexibility.
Problem description
PNDMP is an improved version of GMRDMP with negative demonstrations. Without loss of generality, this study considers the typical motion planning task of the end effector of a robot manipulator. The methodology can be extended to other tasks easily.
Denote the set of demonstrations as

where Np and Nq are the number of demonstrations in each set, M is the length of demonstrations. The sampling point is

With equation (1), the virtual force for the ith demonstration in the x direction can be calculated as

Then, we can obtain the new positive and negative sets of virtual force as below

For the convenience of the following expression, we can rewrite them as
The pipeline of GMRDMP can be summarized as follows: Obtain Optimize Retrieve the force trajectory For a new task, subject the recovered force trajectory and the new starting and end points into equation (1) to recover a new motion.
In PNDMP, the optimization of

where
Because the difference between discrete and rhythmic GMRDMP lies in the calculation of
Main algorithms of PNDMP
In this section, we developed a new PNEM algorithm to maximize the log-likelihood function (12). In addition, we devised a new positive and negative demonstration-based Kmeans (PNKmeans) algorithm for determining the initial value for PNEM. The DAgger framework of PNDMP is then put forward at last.
PNEM
In GMRDMP, EM algorithm
48,49
provides an iterative solution for
In this subsection, we mainly focused on the procedure from the optimization problem

where
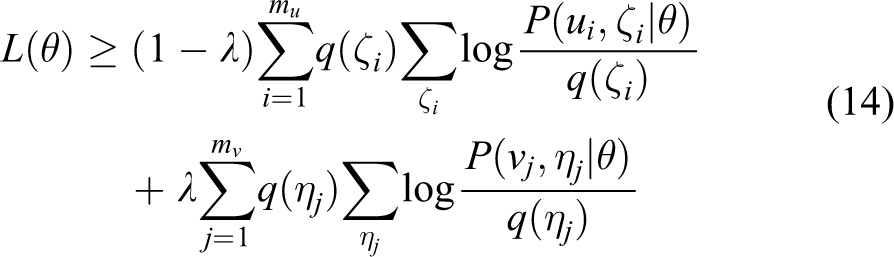
When

With the new PNQ-function, we can obtain the posterior probabilities of the latent variables in the E-step


And in the M-step, we can obtain
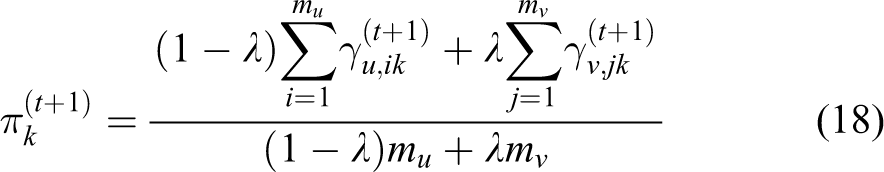


where

In the E-step,
PNKmeans
EM is sensitive to the initial value. Thus, Kmeans is often adopted to generate a preferable initial value
Given the point data sets U and V defined as before and K to-be-calculated center points as

The sample space can be divided into K subspace
The optimization objective is to minimize J which is defined as

where

Extrapolation strategy for PNDMP
From equations (18), (19), and (20), we can find that the results of PNEM are functions of the weight

where
Considering that

This strategy can make the demonstrations act on the adjustment continuously and smoothly, as shown in Figure 5.
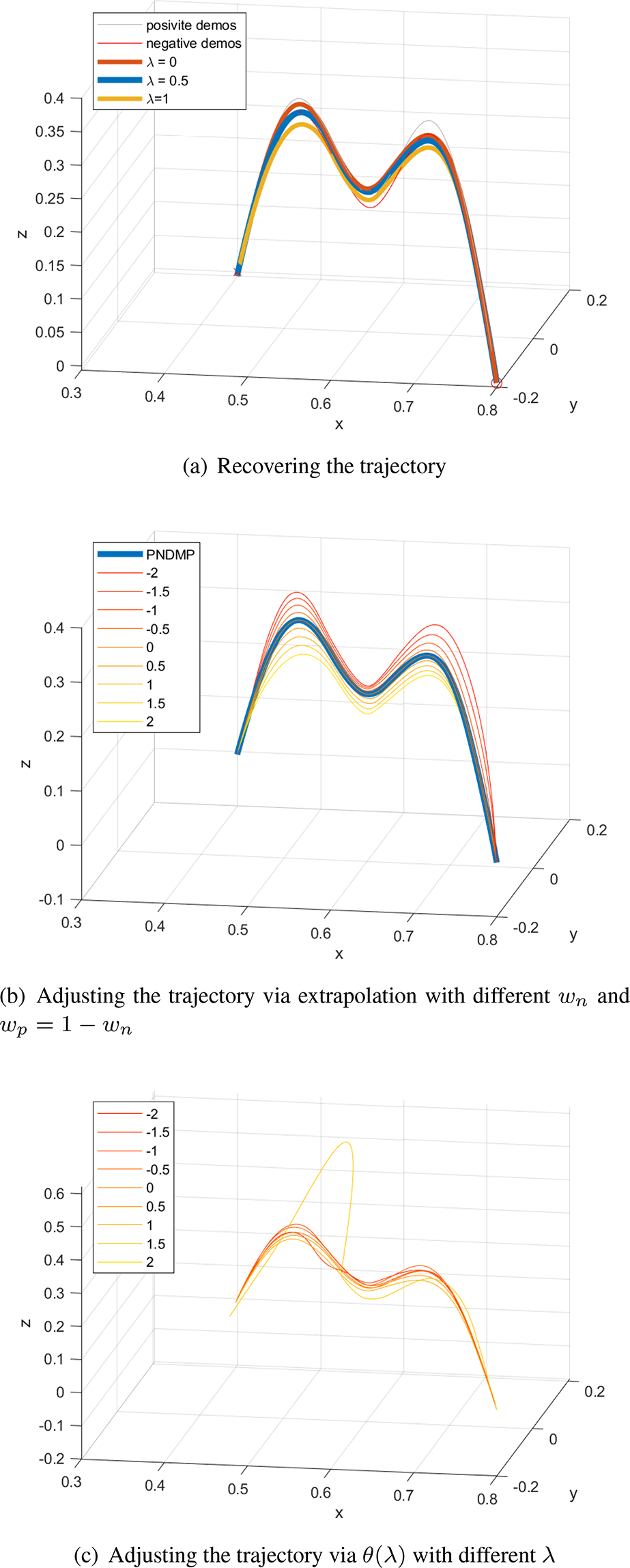
Adjustment of the recovered trajectory based on extrapolation. (a) Recovering the trajectory. (b) Adjusting the trajectory via extrapolation with different wn
and
DAgger framework of PNDMP
Unexpected situations are very common in the industrial field. For instance, some new sensors added into the manipulator’s workspace render preprogrammed trajectories unsafe, yet the operator cannot model the obstacle. In that case, DAgger is an effective solution. DAgger is one of the fundamental incremental learning methods for sequential decision tasks, as well as an efficient method to cope with unexpected situations. In DAgger, new samples are collected and annotated by experts and then added to the training data set during the iterative training process. In the DAgger framework of PNDMP, the user can treat the recovered trajectory as a negative demonstration and re-train the GMM model.
Experiments
To validate the advantage of PNDMP, we have conducted experiments on three typical robot manipulating tasks. The first task is 2D letter writing, 24 with which we analyzed the properties of PNEM and PNKmeans. The second one is obstacle avoidance. 10 The last one is the grasping task in a grid box, which is conducted on a Franka Panda robot. Experiments on the last two tasks illustrate the usage and performance of PNDMP.
Letter writing tasks
In the letter writing task, we have selected the letters B, E, Q, T, and X as the samples to learn. Ten positive and two negative demonstrations of each letter are gathered, with each demonstration including 200 sampling points.
The hyperparameters of PNDMP are
It is difficult to evaluate the recovered letters quantitatively. Thus, we have repeated the experiment 100 times and analyzed the statistical difference between

Patterns of recovered motion of letters. (a) Pattern 1 of B, (b) pattern 2 of B, (c) pattern 3 of B, (d) pattern 4 of B, (e) pattern 1 of E, (f) pattern 2 of E, (g) pattern 3 of E, (h) pattern 4 of E, (i) pattern 1 of Q, (j) pattern 1 of T, (k) pattern 1 of X, and (l) pattern 2 of X.

Marginal distributions of the GMM. GMM: Gaussian mixed model.
Statistical results of different patterns of the letter writing task.

It is worth noting that PNDMP fails to adjust the trajectory in some tasks. The scope of PNDMP is important for workers with little knowledge about the learning control of robots, but it is still challenging to estimate whether PNDMP is appropriate for a task.
Although calculating
Average iterations of 100 executions.

PNEM: positive and negative demonstrations-based expectation–maximum; EM: expectation–maximization.

Comparison of iterations of four methods with GMM5. GMM: Gaussian mixed model.
The searching process of one component of
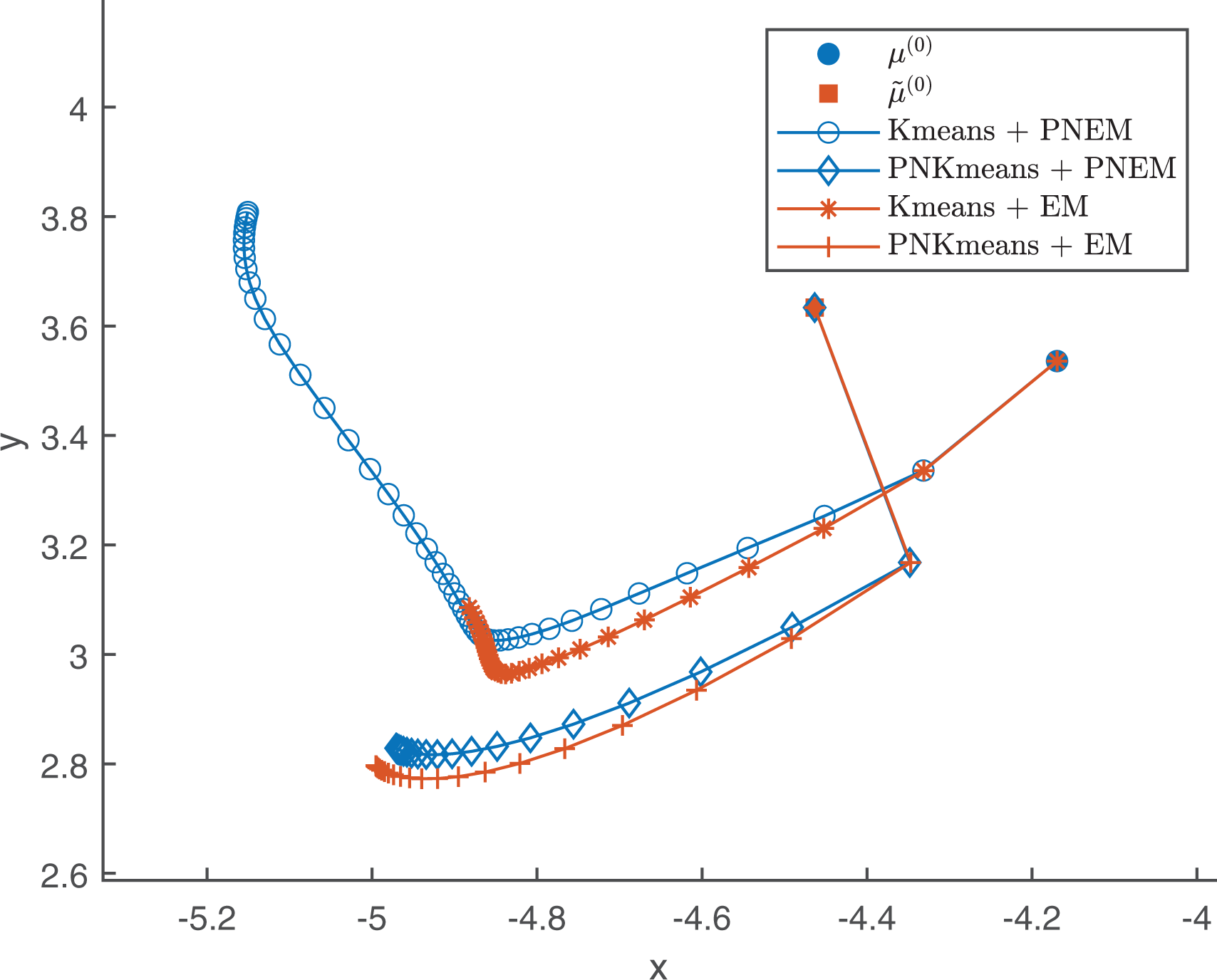
Iteration process of one component for letter B.

Iteration process of one component for letter Q.
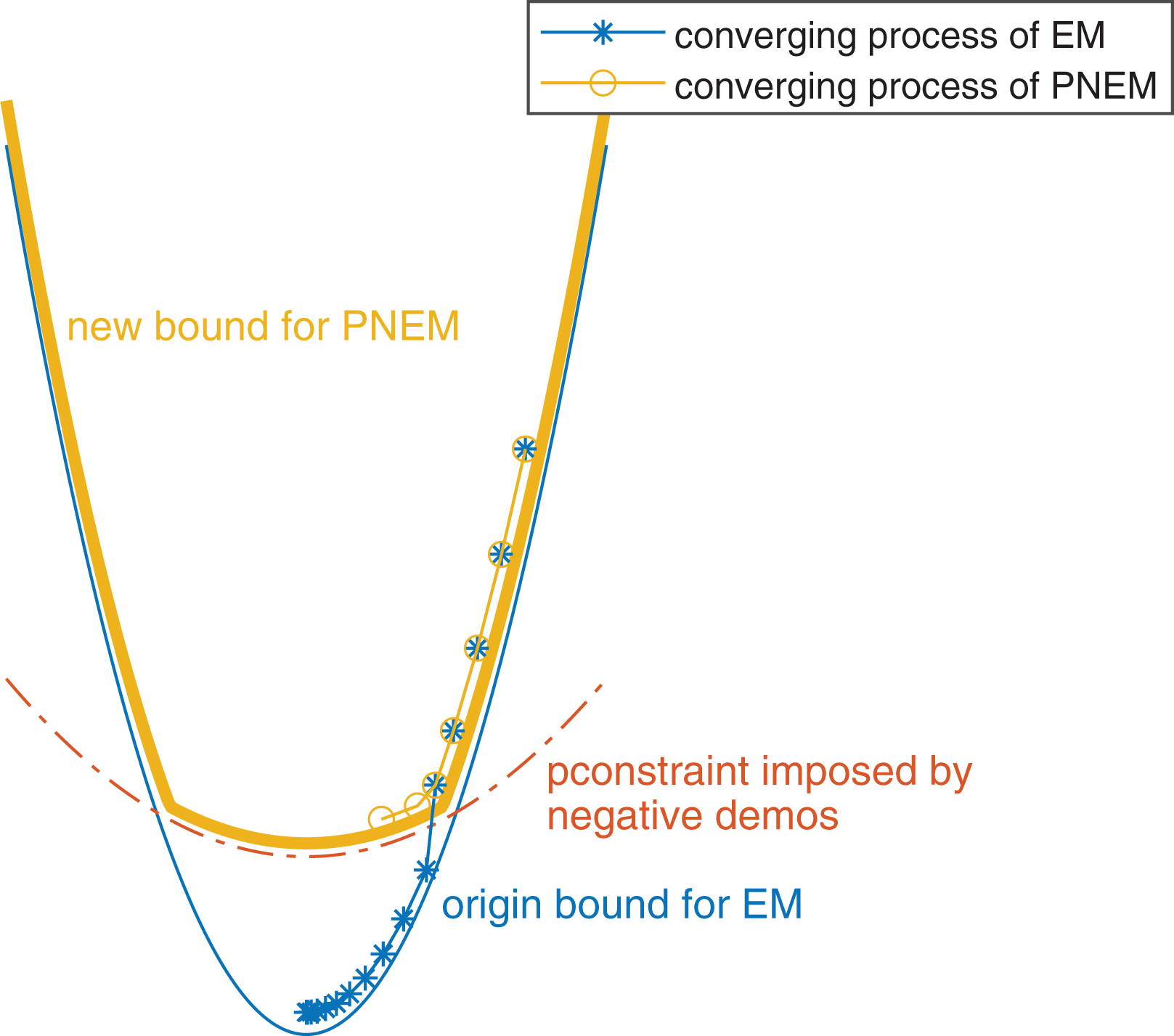
Sketch diagram of the search path.
To analyze the performance of PNKmeans, another clustering task of letters is conducted. In this task, the demonstrations are clustered with a

Distribution of the difference between Kmeans and PNKmeans.

Effect of PNKmeans on PNDMP. PNDMP: positive and negative demonstrations-based dynamic motion primitive
Obstacle avoidance task
In this task, the recovered trajectories of

Recovered trajectories for obstacle avoidance task.
Grasping task
In the grasping task, we need to control the Franka Panda robot to grasp a bottle from one square to another of the grid box, as shown in Figure 15(a). To focus on the PNDMP algorithm, we have chosen a bottle with a red cap and sticker as the object and designed the simple pipeline in Figure 16 to detect it. As depicted in Figure 15(b), the end effector of Panda is large, and it often collided with the box when we collected the demonstrations. Because the geometrical collision volume of the grid box is very hard to be described with a few parameters, neither task-parameterized DMP (TPDMP) 27 nor CPDMP is suitable for this task.

Grasping task by Franka Panda. (a) The Franka Panda robot. (b) Camera above the grid box.

Detection of the bottle. (a) Original RGB image. (b) Red channel. (c) Contours of the cap and sticker. (d) Position and attitude of the bottle.
In the world coordinate, the bottom centers of the squares are

Recovered trajectories for grasping task in a gird box.
Conclusion
By introducing negative demonstrations, we developed PNDMP from GMRDMP with the new log-likelihood function, the PNEM algorithm, and the DAgger framework. PNDMP provides interactive flexibility for the user to adjust the recovered trajectories. Experiments on three typical robot manipulating tasks have been conducted to validate the performance of PNDMP from different aspects. Besides that, another experiment shows that PNEM and PNKmeans converge faster than standard EM and Kmeans when
Although PNDMP can handle unexpected obstacles in many tasks, there are still several works to be done in the future. The first issue is to clarify the scope of PNDMP, which is of great significance for industrial practice. The second one is to identify the task parameters based on positive and negative demonstrations. Similar to PNEM, the negative demonstrations would provide a definite boundary to improve the accuracy and speed of parameter identification. The last one is to extend the DAgger framework to combine the motion model and policy model task, which means that we can cope with the path planning task and sequential decision task with a uniform model.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received financial support for the research, authorship, and/or publication of this article: This work is supported by National Natural Science Foundation of China (62002053), Natural Science Foundation of Guangdong Province (2021A1515011866), Guangdong Basic and Applied Basic Research Projects (2019A1515111082, 2020A1515110504), Social Welfare Major Project of Zhongshan (2019B2010, 2019B2011, 420S36), Achievement Cultivation Project of Zhongshan Industrial Technology Research Institute (419N26), Science and Technology Foundation of Guangdong Province (2021A0101180005), and Young Innovative Talents Project of Education Department of Guangdong Province (2018KQNCX337, 2019KQNCX186).