
Abstract
Among the ways to construct experimental designs having been proposed, orthogonal design, uniform design, and D-efficient design are state-of-the-art methods. This article provides detailed comparisons on the efficiency and robustness among these methods with three case studies in multinomial logit and mixed multinomial logit models. ND-error values and the departures of D-errors corresponding to misspecification of prior information are used as measurements of design efficiency and design robustness, respectively. Design methods are described, and designs with various numbers of runs are constructed. The results indicate that (a) when parameter priors are available, D-efficient design method outperforms the other two methods, in terms of design efficiency, while uniform design and orthogonal design methods are comparable with each other; (b) there will be efficiency loss when D-efficient design that constructed for specific model is implemented in other ones; (c) all three methods have comparable robustness against misspecifications in parameter prior values; however, the effect of misspecification in prior distribution is massive when D-efficient design is used in mixed multinomial logit model; and (d) when parameter priors are unknown, uniform design is suggested to be used in the construction of experimental designs.
Introduction
Originally derived by Luce and developed by McFadden and so on, stated choice (SC) models, also known as discrete choice models, have been widely used in traveler behavior analysis and forecasting in transportation studies. For SC models, a good experimental design may yield better SC model parameter estimation with comparable number of observations than bad ones. Thus, experimental designs play a greater role in SC modeling being the base of data obtaining.
The work of experimental design construction is to determine the influence of the design attributes on the choices that are observed to be made by sampled respondents undertaking the experiment.
1
It is convenient to construct an experimental design using full factorial design method that considers each possible choice situation, that is, in case of a design with two alternatives, three attributes having three levels each, a design with 729
Historically, researchers have relied on experimental orthogonal designs (ORDs), in which the attributes of the experiment are statistically independent by forcing them to be orthogonal. 1 However, constrain of orthogonal also restrains the number of runs that can be chosen in ORD. Meanwhile, as SC models are nonlinear, the importance of orthogonality is questioned when ORD is used to construct experimental designs for SC models. Moreover, some scholars have questioned that there might be orthogonality loss when unevenly subsets of the design are conducted. 2
Meanwhile, uniform design (UD) is a kind of space filling design that seeks design points to be uniformly scattered on the experimental domain. 3 Proposed by K-T Fang, 4 it has been popularly used in agriculture, medicine, and chemical industries, 5 however has been little studied or applied to SC experiment designs. In D Wang and J Li, 6 researchers stated that when UD is used, an overall mean model, which is a polynomial function that can approximate any type of model (either linear or nonlinear), is assumed, and the design is arranged accordingly. In D Wang and P Li 7 and P Li and D Wang, 8 researchers studied the statistical properties of UD with a transport mode choice problem using multinomial logit (MNL) model and found out that the efficiency of the parameter estimations of UD is comparable to that of ORD method. These findings intrigued us to conduct further exploration on UD for SC modeling.
However, another fraction of researchers focused on so-called D-efficient designs (DEDs). 9 Unlike ORD and UD methods, DED construct designs with their efficiency directly linking to SC models that are most likely to be estimated. In DED, efforts are made to obtain experimental design with minimization of expected asymptotic standard errors of the design, so that more reliable parameter estimates can be achieved. To do so, prior information on parameters to be estimated is needed. A theoretical basis for DED has been made that mainly involves with three objects: the analytical derivation of asymptotic variance–covariance (AVC) matrix for corresponding SC models,9–11 the algorithms for searching low D-error designs,12,13 and the analysis of misspecification of parameter priors. 14
Given the fact that each method has advantages and limitations in SC experimental designs, how should analysts make trade-offs and select suitable ones for corresponding SC problems? This brings the concern of experimental design efficiency and robustness. The experimental design efficiency measures the statistical performance of a design in parameter estimation. In other words, we say a design is more efficient if it yields parameter estimation that has smaller standard errors than other ones with comparable number of runs. The robustness of a design measures the ability of the design against the prior information bias. A design with stronger robustness may perform more stable in parameter estimation when misspecification of priors occurs. Literatures have been made efforts on the subject with simulation in DS Bunch and colleagues15,16 and empirical data in F Yang et al. 17 and T Li et al. 18 However, there are some limitations in the existing studies. First, to the authors’ knowledge, efficiency is usually compared among designs constructed by different design methods with single number of runs chosen by arbitrary, and little comparisons have been made among designs constructed by different numbers of runs. Meanwhile, despite the work of comparisons having been made on the design methods in the previous studies,2,14–16 the SC models that they have used are mainly MNL. As more advanced models have been implemented in practical work which bring stronger ability of explanatory, studies on the efficiency and robustness of design methods for mixed multinomial logit (MMNL) models are requested urgently. Moreover, when MMNL models are considered, there could be misspecifications in both prior values and prior distributions. Further studies on the misspecification of parameter prior information are needed. This article makes an attempt to answer these questions by comparing the performance of ORD, UD, and DED methods under various choice scenarios. We use the criteria of normalized D-error to evaluate the efficiency of designs constructed with different design methods at various numbers of runs. The departures of D-error values corresponding to prior information (prior value and prior distribution) bias are used to evaluate the robustness of the design methods.
The remainder of this article is organized as follows: In section “Considerations in SC experimental designs,” details on the considerations in SC experimental designs are given, including choice scenarios, SC models, experimental design method, as well as the number of runs. Section “Measurements of efficiency and robustness” elaborates the measures of design efficiency and robustness. In section “Case studies,” three cases are proposed representing a simple and more complex choice scenario, in which experiment designs with different numbers of runs using ORD, UD, and DED methods are constructed for MNL and MMNL models; efficiency and robustness of the design methods are calculated and carefully compared. In section “Results and discussion,” results and discussions are analyzed based on case studies in section “Case studies.” Section “Conclusion” provides conclusions and suggestions for further research.
Considerations in SC experimental designs
SC models
SC models are usually constructed basing on random utility theory. Let


In case a parameter
Following utility-maximizing rule, different SC models could be derived from different assumptions about the statistical form of the unobserved component and parameters.
When the unobserved component is assumed to be uncorrelated across choices and individuals, following type I extreme value distribution, MNL model is derived. 10 The form of the choice probabilities of MNL model is expressed as follows

When one or more parameters of observed component are not fixed, the MMNL model (also known as random parameters logit model) is derived. 19 The form of the choice probabilities of MMNL model is expressed as follows

It can be noticed that the probability expression of MNL and MMNL is quite different and the latter one is far more complex with none-closed form. Draws will be needed when simulating the probabilities in MMNL models. This suggests that there might be differences when experimental designs are conducted for parameter estimation of different SC models under the same choice scenario with the same experimental design methods.
Experimental design methods
Orthogonal design method
A design is said to be orthogonal if it satisfies attribute level balance, and all parameters are independently estimable. In other words, an orthogonal design (ORD) satisfies the property that the correlation matrix of coding values in ORD should be an identity matrix. When orthogonal coding (

where s denotes the runs of the design and
UD method
The main object of UD is to sample a small set of points from a given closed and bounded set

where

From the aspect of sampling, this usually can be estimated by the mean of
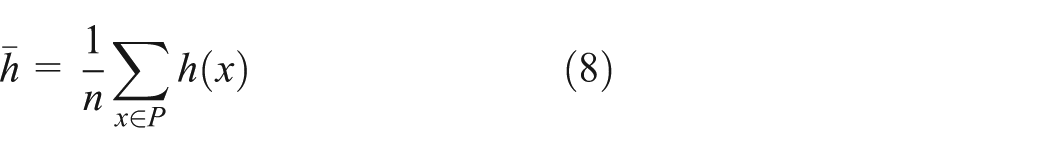
where P is a set with n experimental points over the domain.
Thanks to the Koksma–Hlawka inequality, the upper error bounds of the estimate of

where

where M denotes the calculation of discrepancy for a design,

The centered L2 discrepancy (CD) is considered as the measure of uniformity for its appealing property.
3
JH Fred
20
gave an analytical expression of CD as shown in equation (11), where n denotes the n points in s-dimensional unit cube
To convert the domain into unit cube,

where q is the maximum number of levels that the attributes have. Following the measure of M and the principle in equation (10), UD could be constructed with the help of computer through the optimization way.
DED method
DED method is the kind of design that links the process of design construction to the reduction of asymptotic standard errors of parameter estimation in modeling. The theoretical basis of the DED is to obtain the minimum value of the determinant of the AVC matrix of the model, naming D-error. 17 Smaller values of D-error indicate higher reliability of the estimated parameter results.
Let

If the choice observations from a single respondent over a series of choice situations are assumed independent, then the log-likelihood function can be written as below

where
Thanks to the work of M Daniel
10
and MCJ Bliemer and JM Rose,
12
it can be shown that the outcome Y drop out or could be replaced with probabilities when


In other words, the AVC matrix corresponding to a sample size of N can be derived directly from the AVC matrix from a single respondent using a rate of
In this article, we choose

Thus, a DED could be constructed for specific SC model by solving the following problem

The basic theory to solve the problem is to evaluate each different combination of choice situations from the full factorial. The combination with the lowest efficiency error having a certain number of choice situations is the optimal design. Based on equation (17) and the object function in equation (18), it is obvious that advanced knowledge on the parameter values
The number of runs
The number of runs has influence on the burden that respondents face in terms of the questionnaire. The more runs an experimental design has, the larger burden a respondent may face. The smallest number of runs in design construction depends on the degrees of freedom of the choice scenario, the principle of attribute level balance (over all choice situations, each attribute level should appear an equal number of times) and additional constrains subjecting to design methods, that is, the orthogonality. However, the largest number of runs equals to the runs that corresponding full factorial design has. In this article, designs with different runs were constructed under same choice scenarios with the same design methods, as well as the same SC models, to analyze the effect of runs on the efficiency of design methods.
Measurements of efficiency and robustness
Normalized D-error
As introduced in section “DED method,” D-error is an overall measurement that relates to the standard errors of estimated parameters for SC model. So that it is regarded as the criteria of the efficiency for an experimental design. According to equation (17) in section “DED method,” D-error is related to the runs used. To compare D-errors of designs constructed with different runs, we use the criteria normalized D-error which is proposed by MCJ Bliemer and JM Rose.
21
Let ND denote the normalized D-error, D denote the original D-error, S denote the runs the design has, while the runs that the standard design has is denoted as

Misspecification of priors
In the calculation of D-error and normalized D-error, we have assumed that prior parameter information correspond to the true parameter information in SC models. However, in practice, it is more practical that we can only assume the parameter priors from experience or pilot survey. This may lead to bias between the prior values that analysts set and the real parameter values hold by the population. Thus, the study of robustness of a design against the prior bias can help designers to choose more reliable methods when prior information is uncertain.
There might be two kinds of prior information misspecifications corresponding to the characteristics of attributes. One lies in parameters with fixed value and the other lies in parameters following specific distributions. For the former parameters, fixing the design and varying the parameter estimates over some range provide a way of testing the robustness of different designs to prior information bias by the departures of D-error values. While for the latter kind, we can change the distribution forms to test the departure of D-error values.
Case studies
Based on the considerations specified in section “Considerations in SC experimental designs,” we designed three cases varying in the number of alternatives, the number of attributes, attribute levels, the number of runs, as well as model forms. In this article, the construction of UDs is with the help of DPS software (Version 7.05). In all cases, we have optimized the UDs under the function of mixed attribute level UD with the maximum 2000 iterations or 10 min to run. Meanwhile, the construction of ORDs and DEDs is realized in the Ngene software (Version 1.1.2), which is also used to calculate D-error values. For ORDs, the sequential method is used to ensure the orthogonality across alternatives, and Gaussian quadrature with five abscissas per parameter is used to take draws from the parameter distributions of random parameter in the construction of DEDs.
Case study 1
Case 1 is designed to compare the efficiency of ORD, UD, and DED methods for MNL model in the scenario where respondents face two alternatives. The utility of each alternative is specified as follows

where
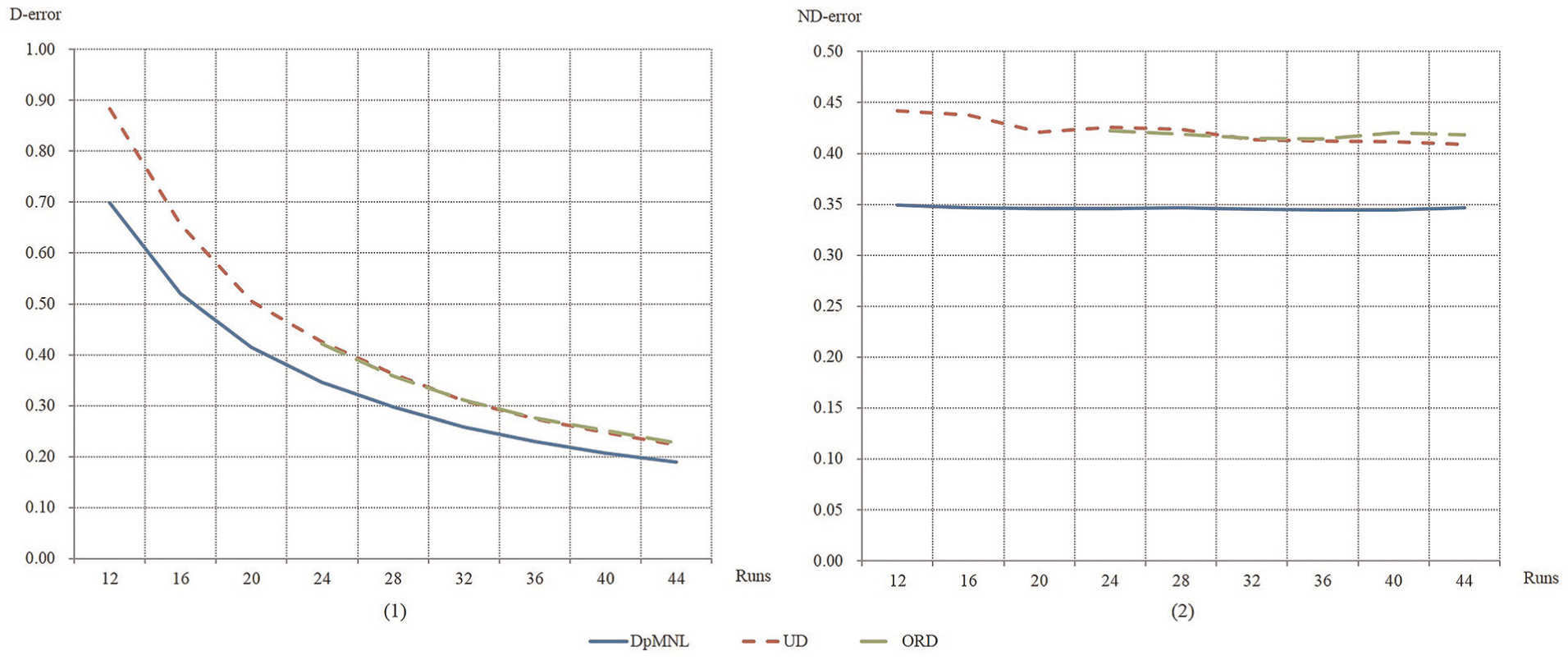
The outcome of D-error values and normalized D-error values is presented in Figure 1. As introduced in section “DED method,” we denote DED for MNL model as DpMNL. ND-errors are normalized based on the design having 20 runs within each design methods. It can be observed from Figure 1 that for all three design methods, D-error values decrease with the rise of run numbers. For example, when the run in DpMNL rise from 8 to 32, the value of D-error decreases from 0.351 to 0.096. This may result from the fact that larger runs bring more information for parameter estimation when only one sample is considered, so that lower standard errors could be achieved, which leads to smaller D-error. Meanwhile, line DpMNL keeps to position at lower parts of the charts than line UD and line ORD. This suggests that designs constructed with DpMNL method turn out to be having smaller D-errors than the ones constructed with UD and ORD methods. Taking designs having 16 runs as an example: The D-error value of DpMNL is 0.18, which is 51.7% of UDs and 52.5% of ORDs. Moreover, line UD and line ORD tend to be overlapped. This consists with the findings in D Wang and P Li 7 that UD and ORD methods have comparable efficiency when utilized in MNL. Besides, within all three design methods, there are little differences in ND-error as the number of runs varies. This implies that for MNL model, the number of runs has little effect on the performance of design efficiency. Analysts may select feasible number of runs at the acceptable burden when MNL model is implemented.

Criteria comparisons of different design methods with different runs in case 1.
Case study 2
Case 2 provides a platform to conduct comparisons on the efficiency of design methods for MNL model with higher complexity in choice scenario, by assuming four alternatives having both generic and specific attributes. Meanwhile, designs with 24 runs are chosen to inspect the effect of misspecifications in prior values. The utility specification for each alternative in case 2 is given as follows

where
The true prior parameter values are assumed as fixed as follows: For generic attributes,
The outcome of D-error values and ND-error values is presented in Figure 2. ND-errors are normalized based on the design having 24 runs within each design methods. The effect of misspecifications in prior values is shown in Figure 3.
Criteria comparison of different design methods with different runs in case 2.

D-error departures with prior value misspecification in parameters in MNL in case 2.
Design efficiency comparisons
In general, the outcome of the comparisons of design efficiency in case 2 mirrors the pattern in case 1. Moreover, with the increase in the complexity of design scenario, we can observe from Figure 2 that the available runs of UD and DED methods are 12, while the minimum runs of ORD method are 24. It implies that UD and DED are more flexible in the choice of run numbers than ORD method. By reading from Figure 2(2), the outcome of ND-error mirrors the finding in case 1 that within all three design methods, ND-errors remain relatively still as the number of runs varies. Along with the analysis on the available runs of UD and ORD methods aforementioned, it indicates that for MNL model, UD may be a potential substitution to ORD as its flexibility in the choice of runs while having comparable ND-error values with ORD. For example, UD16 may load smaller burden of inquiries on respondents than ORD24, by having 16 questions in each questionnaire rather than 24 questions. In the meantime, the comparison of ND-error between UD16 and ORD24 is 0.438 versus 0.422, which are surprisingly close.
Prior value misspecification
Figure 3 plots the departure of D-error values of designs with 24 runs in case 2, when prior value misspecification appears in each parameter. We determine the D-error values when each true parameter independently deviates between −100% and +100% of its prior parameter value. As such, the center of axis x corresponds to original parameter values for design constructions. Vertical axes scale the D-error values of different design methods corresponding to the variation of parameter prior values.
Reading from Figure 3, line DpMNL remains to be the one with smallest D-error values when the parameter prior value varies. Lines in each panel appear to have similar rate of change with the departures of prior values from the original parameter priors values assumed in their construction. This suggests that in this case, UD, ORD, and DpMNL methods have comparable level of robustness against the misspecification in parameter value. Moreover, there are differences in the curvature of lines among the panels, by taking lines in panel 2 and panel 4 as examples: although the original parameter value of the two panels are both 0.6, the lines in panel 4 appear to be flatter than the ones in panel 2. This suggests that attributes may possess different sensitivities to parameter value misspecifications.
Case study 3
Case 3 compares the efficiency of designs constructed in MMNL model, under the same choice scenario as case 2, however being different in parameter specifications. To be specific, we assumed that

Criteria comparison of different design methods with different runs in case 3.

D-error departures with prior value misspecification in parameters in MMNL in case 3.
D-error values with prior distribution misspecification in MMNL model in case 3.
ORD: orthogonal design; UD: uniform design; MNL: multinomial logit; MMNL: mixed multinomial logit.
Design efficiency comparisons
Reading from Figure 4, designs constructed by DpMMNL turn out to be the most efficient designs with the lowest D-error value at each runs. This consists with the outcome in case 1 and case 2 that the DED designs dedicated for specific models perform better than other designs. Meanwhile, line DpMNL, UD, and ORD appear to overlap each other in Figure 4(1) and (2). It implies that SC model is mattered to what the design is constructed for. In other words, there will be efficiency loss when DED that constructed for specific SC model is used in other ones. Moreover, as shown in Figure 4(2), there are more fluctuations in ND-error values than those in case 1 and case 2 when the number of runs varies. This may result from the draws in the process of parameter estimation in MMNL model. However, as the fluctuations are relatively small, we may yet say that the number of runs has little effect on the performance of design methods on design efficiency in MMNL model. Thus, as in case 2, UD may be a potential substitution to ORD as its flexibility in the choice of runs while having comparable ND-error values with ORD for MMNL model.
Prior value misspecification
Figure 5 plots the departures of D-error values of designs with 24 runs, when prior value misspecification appears in each parameter of MMNL model. As in case 2, we determine the D-errors when each true parameter independently deviates between −100% and +100% of its prior parameter value. For parameters following distributions as
Reading from Figure 5, in addition to line DpMNL, lines in each panel of Figure 5 appear to possess similar rate of change with the departures of prior values from the original parameter priors values assumed in their construction. This suggests that in this case, UD, ORD, and DpMMNL methods have comparable level of robustness against misspecification of prior values, when MMNL model is considered. Besides, it can be read from panels 3 to 5 of Figure 5 that there are “∩”-shaped lines representing the D-error value variations of DpMNL. The top of these “∩”-shaped lines happens to have the horizontal ordinates lying close to the center of axis x. This suggests that when the origin prior value is utilized, it is actually the worst scenario for prior setting of DpMNL design in MMNL model. This may explain the efficiency loss when DpMNL is used in MMNL model.
Prior distribution misspecification
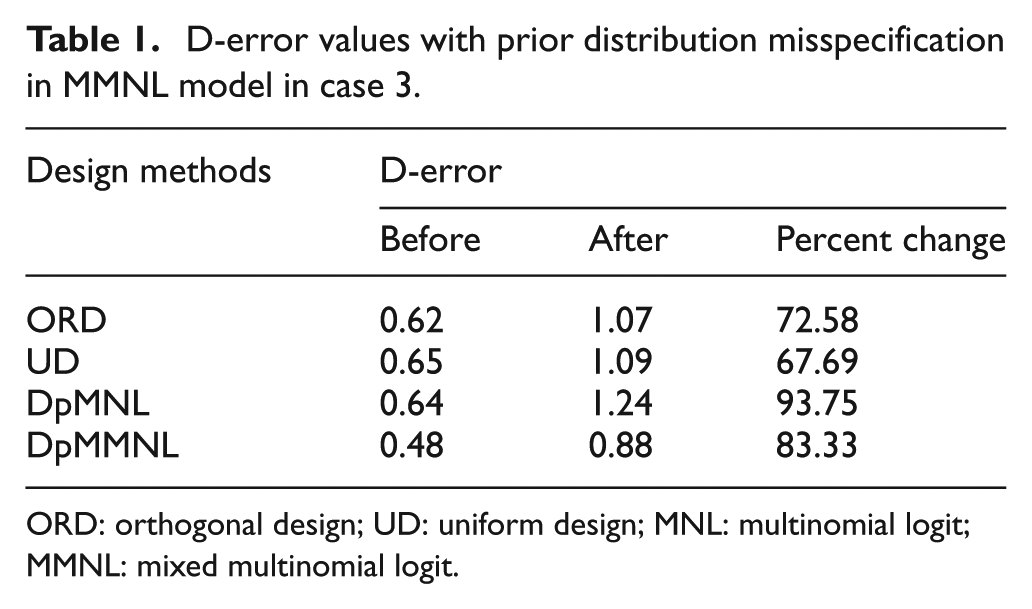
To analyze the effect of misspecification of prior distribution, we keep the values of the fixed parameters the same as they were assumed in design constructions, while parameters that follow distributions are assumed to have misspecifications in distribution forms having the same values of mean and standard deviations. To be specific, we changed the distribution form of
Reading from Table 1, DpMMNL remains to possess the smallest D-error value despite its bad performance (worse than UD and ORD) in D-error robustness with its percent change of 83.33%. This may be explained by the information on the mean and standard deviations of parameter distribution which still enables DED to be the most efficient design among the three. Meanwhile, the value of percent change show that UD and ORD perform better in the robustness to prior parameter distribution than the other two design methods. This may result from the fact that the construction of UD and ORD is not linked to the model form directly. Moreover, the similarity in percent change of ORD and UD indicates that ORD and UD have comparable robustness to misspecification in parameter distribution. Besides, DpMNL becomes the worst design in efficiency with the largest D-error value while having the worst robustness in D-error with the largest percent change of 93.75%. In a word, prior distribution misspecifications have greater effect on D-error of designs in MMNL models.
Results and discussion
We have attempted to show the performance of ORD, UD, and DED methods on efficiency and robustness via the use of three case studies varying in the complexity of choice scenarios, model forms, as well as the number of runs. ND-error values and the departures of D-error values are used to evaluate the efficiency and robustness of experimental designs, respectively.
The comparisons of design efficiency show that (a) when the number of run varies, line DED (line DpMNL in Figures 1 and 2 and line DpMMNL in Figure 4) keep to place at lower part in the panels than lines UD and ORD do. This suggests that DED method outperforms UD and ORD in design efficiency when prior information is available. (b) The outcome of line UD and line ORD overlapping each other in Figure 1, Figure 2 consists with the finding in D Wang and P Li. 7 That uniform design is comparable to orthogonal design in design efficiency for MNL model. Meanwhile, the overlapping of line UD and line ORD in Figure 4 extends the scope of model form to MMNL model where the finding aforementioned stands. Thus, we may say that UD and ORD are comparable in design efficiency in MNL and MMNL models. (c) The lines in Figures 1(2), 2(2), and 4(2) show the effect of run numbers on design efficiency that the lines remain relatively still when the number of runs varies. This indicates that the number of runs has little effect on the efficiency of UD, ORD, and DED methods for MNL and MMNL models. (d) We designed case 3 with the same choice scenario as case 2 so that the designs constructed by DED in case 2 could be implemented in case 3, to inspect the effect of model form on design efficiency in DED methods. The worse performance of DpMNL than DpMMNL and overlapping with UD and ORD in Figure 4 suggests that DED should be implemented to its target SC models, or there will be efficiency loss. This may result from the fact that DEDs are generated by conducting the optimization of minimizing the objective function of D-error, which is the function of SC models. Once deviation in model form exists, efficiency loss occurs.
However, the results of the comparison of robustness to prior misspecifications show that (a) within each panel in Figures 3 and 5, lines appear to have similar rate of change in D-error values with the departure of parameter values from the original values assumed in design construction. This indicates that UD, ORD, and DED methods have comparable level of robustness against misspecification of prior values in MNL and MMNL models. (b) For MMNL model, the percent change of D-error values is larger when the misspecification lies in prior distribution than that lies in prior values. This suggests that prior distribution misspecifications have much stronger effect on the designs in MMNL models.
Conclusion
The high cost of SC survey has been motivated by analysts to find better ways to construct SC experimental designs that are able to provide better parameter estimation with smaller or comparable number of observations. This article compares the efficiency and robustness of ORD, UD, and DED methods to address the issue of how to choose experimental design methods for MNL and MMNL models. We find that in terms of design efficiency, DED method outperforms UD and ORD on condition that parameter priors are available, while the latter two go neck to neck. Meanwhile, SC model form matters. There will be efficiency loss when DED which is constructed for specific model is implemented in other ones. Regarding the robustness of the design methods, all three methods have comparable robustness against misspecifications of parameter prior values. However, misspecifications in parameter prior distributions show larger effect on DED method in MMNL models than misspecifications of parameter prior values. This suggests that extra attentions should be poured when prior distributions are assumed in the construction of DED for MMNL model. Moreover, the number of runs seems to have little effect on the efficiency of designs. Analysts may choose the one under the consideration of the acceptable burden of respondent. Besides, UD method is recommended when prior information is not available for its better flexibility in the choice at run numbers and having comparable values in D-errors to ORD method in both MNL and MMNL models.
However, we have noted that there exist a number of limitations for this article. First of all, the conclusions aforementioned should be treated cautiously; more numerical and empirical cases could be practiced to further verify the results. And one more point we should touch on is that Monte Carlo simulations that mimic the choice process of respondents could be made to check the criteria of goodness of fit in the future work.
Footnotes
Academic Editor: Yongjun Shen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Specialized Research Fund for the Doctoral Program of Higher Education (no. 20130184110020), Technological Research and Development Program of China Railway Corporation (no. 2015G002-N and no. 2014X006-A), Outstanding Innovation Talents Program of Southwest Jiaotong University (no. SWJTU-R-[2014]-1), as well as the Technological Research and Development Program of China Eryuan Engineering Group (no. KYY2015026).