
Abstract
The modeling and solving a transcendental eigenvalue problem are important issues in the transfer matrix method for linear multibody systems. Based on the recursive eigenvalue search algorithm for transfer matrix method for linear multibody system, the distributed parallel approach for assembling overall transfer matrix and searching eigenvalues is proposed. This is achieved based on Message Parallel Interface. The influence of the CPU core number as well as the distributed network environment on the final computational time is analyzed through numerical examples of both a non-uniform beam and a multiple launch rocket system. The results indicate that the computational time is significantly reduced by the proposed parallel computing method, so that the computational efficiency on optimization and design of complex multibody systems can be improved.
Keywords
Introduction
The demand for multibody system dynamics (MSD) computation is increasing in various fields, such as vehicles, ships, aeronautics, and astronautics weapons, while the MSD models become more and more complicated. 1 Typically, the solution of a complex multibody system will cost a plenty of time, thus the conventional static design pattern can hardly meet the requirement of dynamics design. In light of such concern, the computational speed needs to be accelerated. Although this can be achieved by raising the level of hardware, the computational speed of a single-core CPU is limited due to manufacturing process, 2 thus resulting in the emergence of the multicore CPU handling a problem simultaneously. At the same time, the computer cluster system can be constructed using relatively inexpensive computers connected via the high-speed local area network (LAN), which is more cost-effective compared with supercomputers. 3 These provide the foundation for the software technology such as the parallelization of numerical algorithms. 4 To shorten the computing time, many commercial and open source dynamics software including ADAMS, ANSYS, MBDyn, and so on have introduced the idea of parallel computing. A lot of research work in parallel computing4–9 is also investigated by scholars. D Negrut et al. 5 concentrated on the use of commodity parallel computing in many-body frictional-contact dynamics, fluid–solid interaction analysis, and proximity computation. F González et al. 6 evaluated two non-intrusive parallelization techniques for MSD, namely, parallel sparse linear equation solvers and OpenMP. OA Bauchau 7 used domain decomposition techniques to achieve parallel processing of finite element method for flexible multibody systems.
The transfer matrix method for multibody systems (MSTMM) is a rather novel method for MSD. Compared with ordinary dynamics methods, MSTMM has the following characteristics: no global dynamics equation of the system is required, low matrix order is involved, and fast computing speed and highly stylized programming are achieved. 10 Its basic idea is to (1) break up the whole system into several elements, (2) use a matrix representing the mechanical properties of each element, (3) assemble these matrices by applying the automatic deduction theorem of the overall transfer equation of multibody systems, 11 and (4) solve the overall transfer equation of the system.
The solution of the overall transfer equation is one of a key technique in MSTMM. D Bestle et al. 12 proposed a recursive eigenvalue search algorithm for the transfer matrix method for linear multibody systems (linear MSTMM). Although this algorithm has a linear convergence rate, as is the same with those strategies based on sign change, it can solve both real and complex eigenvalue problems of a system and even find double roots. Moreover, this algorithm is more competitive and efficient in choosing step size than other strategies based on sign change.
To further improve the computational efficiency, a parallel algorithm for assembling the overall transfer matrix as well as recursively searching the eigenvalue is proposed in this article, and the distributed parallel computing environment based on the Message Parallel Interface (MPI) is built. A damped non-uniform beam with complex eigenvalues and a multiple launch rocket system (MLRS) with real eigenvalues are taken as numerical examples to verify the proposed method. This article provides a feasible way to further improve the computational speed of linear MSTMM.
Basic idea of linear MSTMM
In the inertial coordinate system,
For clarity, an example with a one-degree-of-freedom (1-DOF) lumped mass connected with a rod is shown in Figure 1.
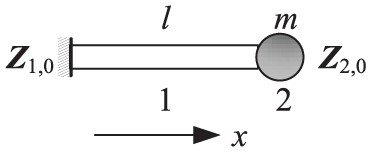
The 1-DOF system with a rod and a lumped mass.
The rod with length l and the lumped mass with mass m are numbered as 1 and 2, respectively. The state vector of the inner connection point between elements 1 and 2 is defined as

where
Then the transfer equation of the system can be obtained as
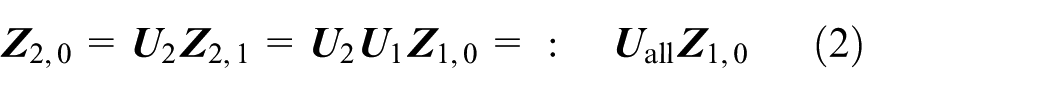
where
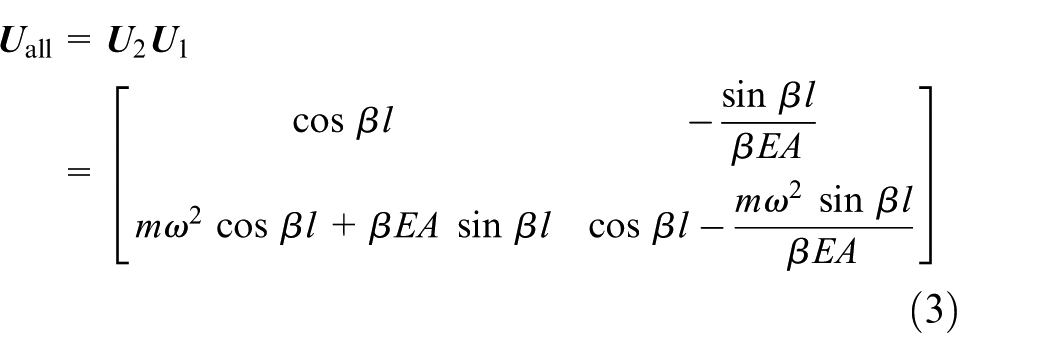
is the overall transfer matrix of the system.
The non-trivial solution of equation (2) leads to system characteristic equation as
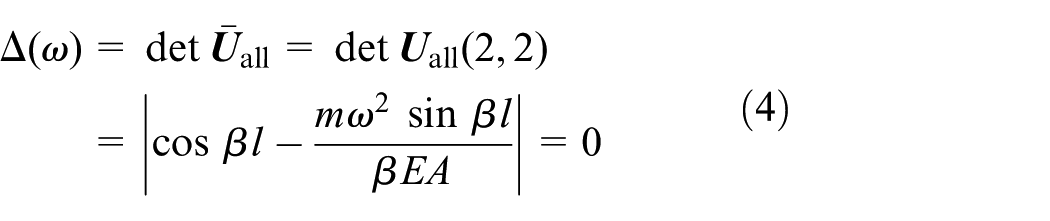
Then the eigenvalue
For a multibody system in a more generic topology, the overall transfer equation and the overall transfer matrix can be obtained by simply following the automatic deduction theorem of the overall transfer equation for multibody systems 11 taking a general form
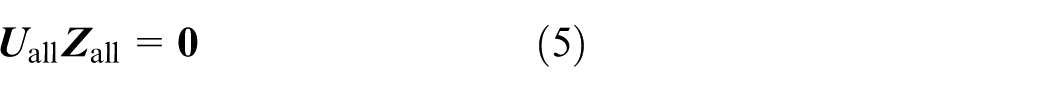
where
By eliminating zero elements corresponding to the known system boundary conditions in

where the coefficient matrix
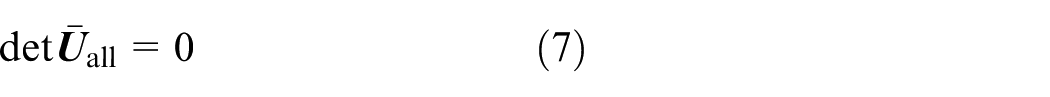
The eigenvalues of a multibody system can be obtained by solving equation (7), which will be discussed in section “Recursive eigenvalue search algorithm.” It is worth mentioning that the order of the coefficient matrix
Recursive eigenvalue search algorithm
For an undamped system, the solution of equation (7) can be achieved by searching the zeros of the equation
The basic idea of the recursive eigenvalue search algorithm for linear MSTMM is switching from zero search for

where 1 means true, while 0 means false. Consequently, the local minimum conditions

Logical arrays of minimization strategy.
For each iteration in the one-dimensional minimum search in Bestle et al.,
12
a user-defined resolution
As discussed in the preceding section, the recursive eigenvalue search algorithm is more competitive in choosing step size than some strategies based on sign change. The following numerical example will provide some insights. If the number of rods and lumped masses in Figure 1 increases to 10, respectively, the system will become as shown in Figure 3, where the masses of the lumped masses are denoted as

The 1-DOF system with 10 rods and 10 lumped masses.
The overall transfer equation of the system can be obtained as

with the characteristic equation

The variation trend of

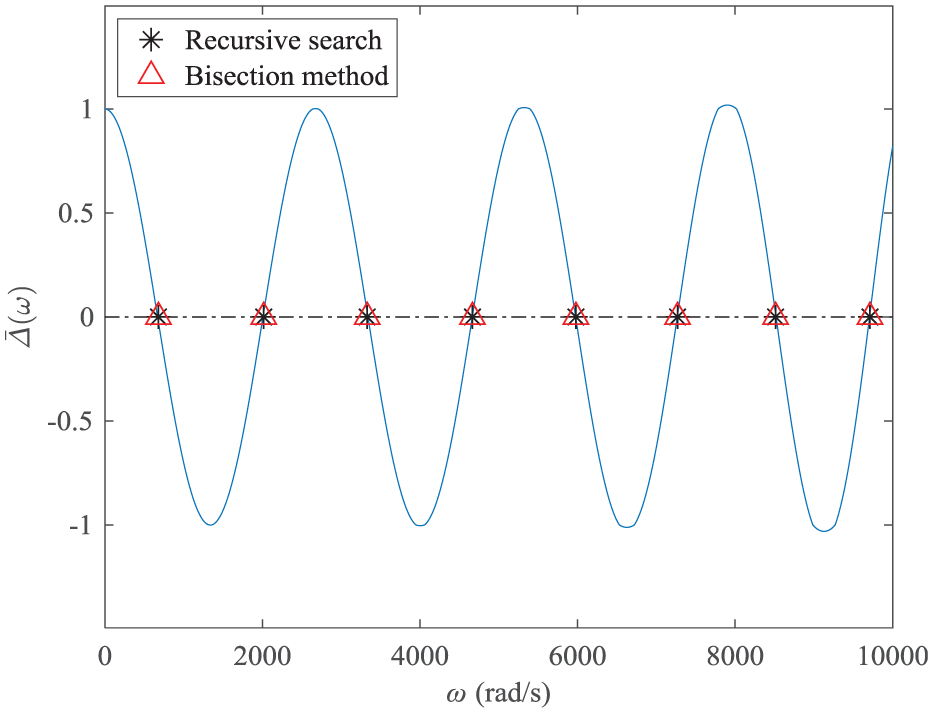
Variation in
If one sets the sampling size
If the lumped masses become different from each other with different mass values shown in Table 1, the variation trend of
Values of lumped masses.

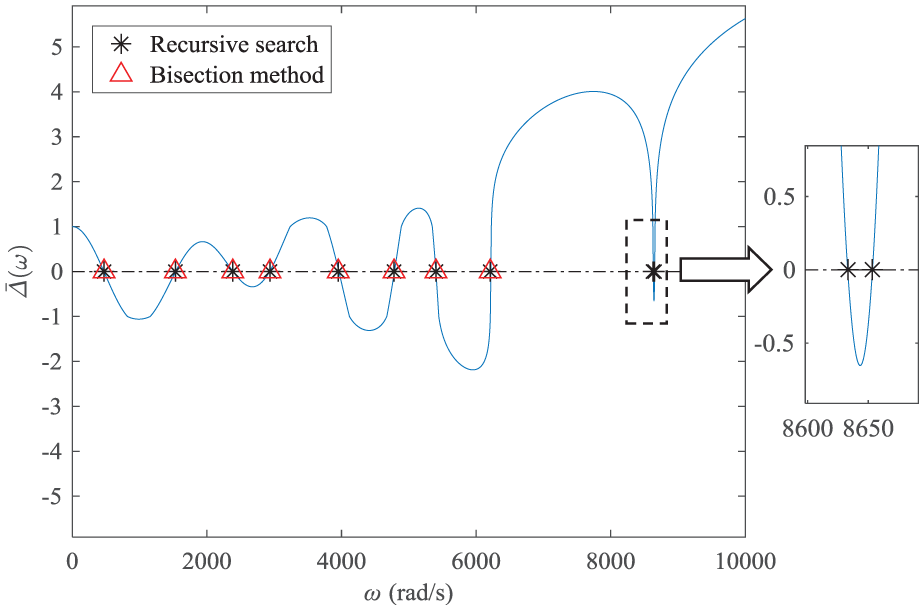
Variation in
Principle and realization of distributed parallel computing technique
The basic idea of parallel computing is to separate a task into several parts and every part is solved by an individual processor parallel to reduce the computational time. 4 Furthermore, the distributed parallel computing technique not only divides the problem into parts but also assigns tasks to multiple computers interconnected by network so that the computers solve the tasks simultaneously. Then each computer uploads the results to the host to get a final result. 13
Construction of distributed parallel computing environment
As shown in Figure 6, to construct an MPI distributed parallel environment is to connect computers to the same LAN via Ethernet switches or other network equipment. In this article, four computers connected by a 100 Mb/s Ethernet switch are used to set up the distributed parallel computing environment. Each computer has an i7 quad-core processor with the frequency of 3.06 GHz. The parallel software used is MPICH2.
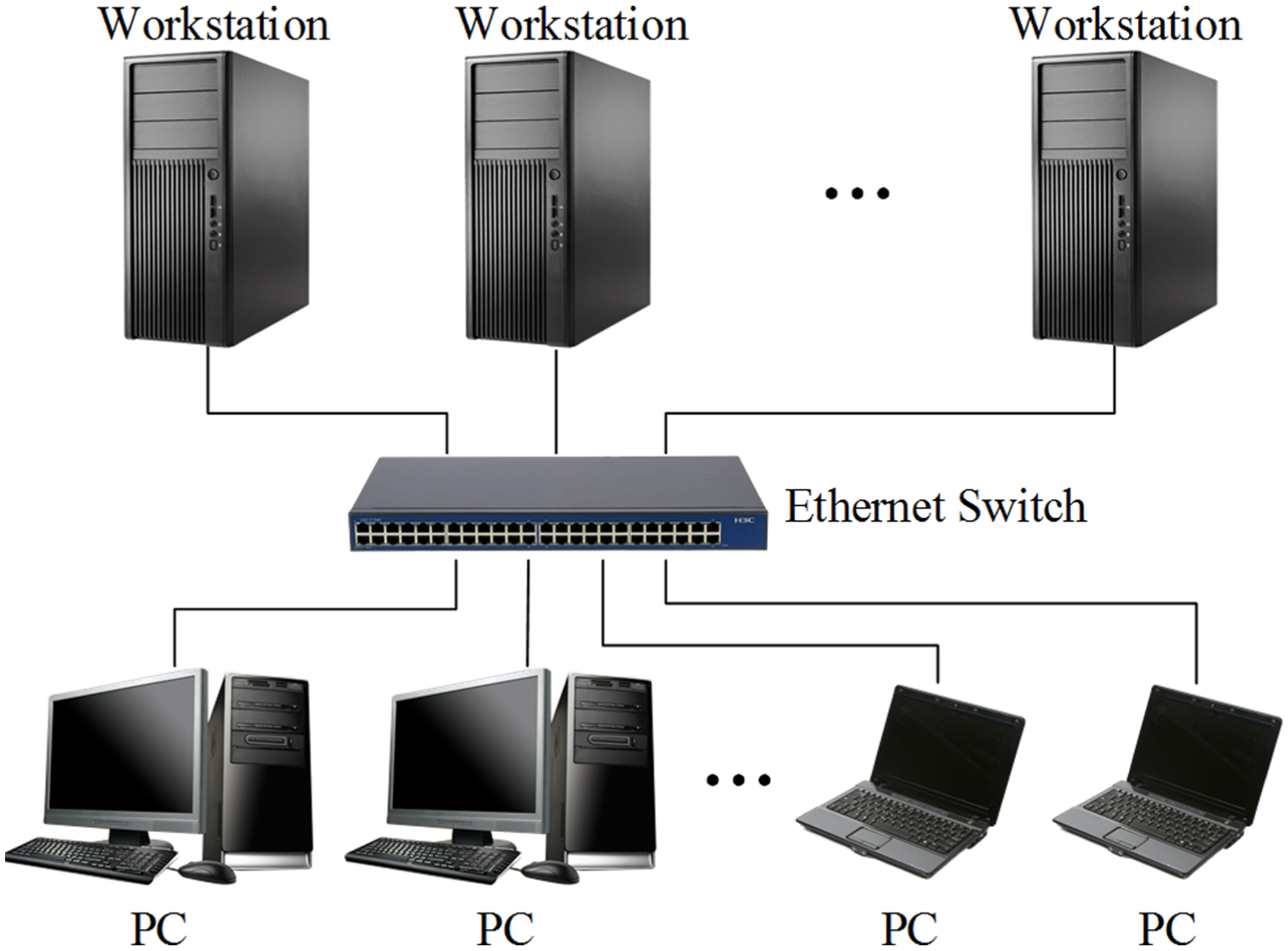
Distributed parallel computing environment.
Parallel computing algorithm for linear MSTMM
The master–slave mode is used as task allocation mechanism in this article. The master process is mainly responsible for the global division of tasks, which sends tasks to the slave processes and receives the results from the slaves. Meanwhile, the slave processes are responsible for computing the tasks assigned by the master process and returning the computational results to the master process. The major task of the eigenvalue computation using linear MSTMM is to assemble the overall transfer matrix and solving the characteristic equation. Thereby, the parallel algorithms can be designed in these two aspects.
Parallel computing algorithm for assembling the overall transfer matrix
Based on the automatic deduction theorem of the overall transfer equation of multibody systems, the assembly of the overall transfer matrix is a reassembling process after multiplying transfer matrices of each element in proper sequence according to the system topology.
As a chain system shown in Figure 7, the overall transfer matrix can be written as

Topology figure of a chain system.
Matrix multiplication assignment.

Multibody systems with general topology could eventually be treated as a tree system. Taking a tree system as an example shown in Figure 8, the overall transfer equation can be obtained as



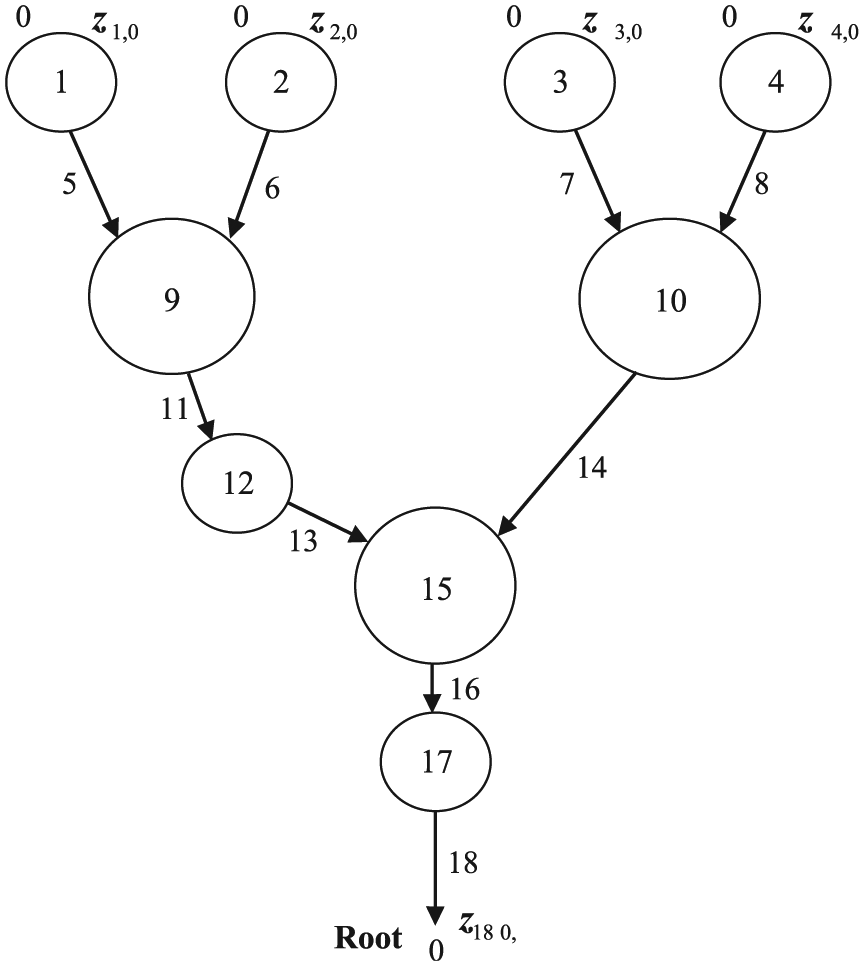
Topology figure of a tree system.
The detailed meaning of the above symbols can be found in Rui et al.
11
As shown in equations (12)–(14), the overall transfer matrix
Matrix computation assignment.

Parallel recursive eigenvalue search algorithm
The first step of the eigenvalue search algorithm is to compute the function value
Function value computation assignments.

After the slave processes return each function value
Assuming there are k local minima
Assignments of subintervals.

The whole process of the eigenvalue search is shown in Figure 9.
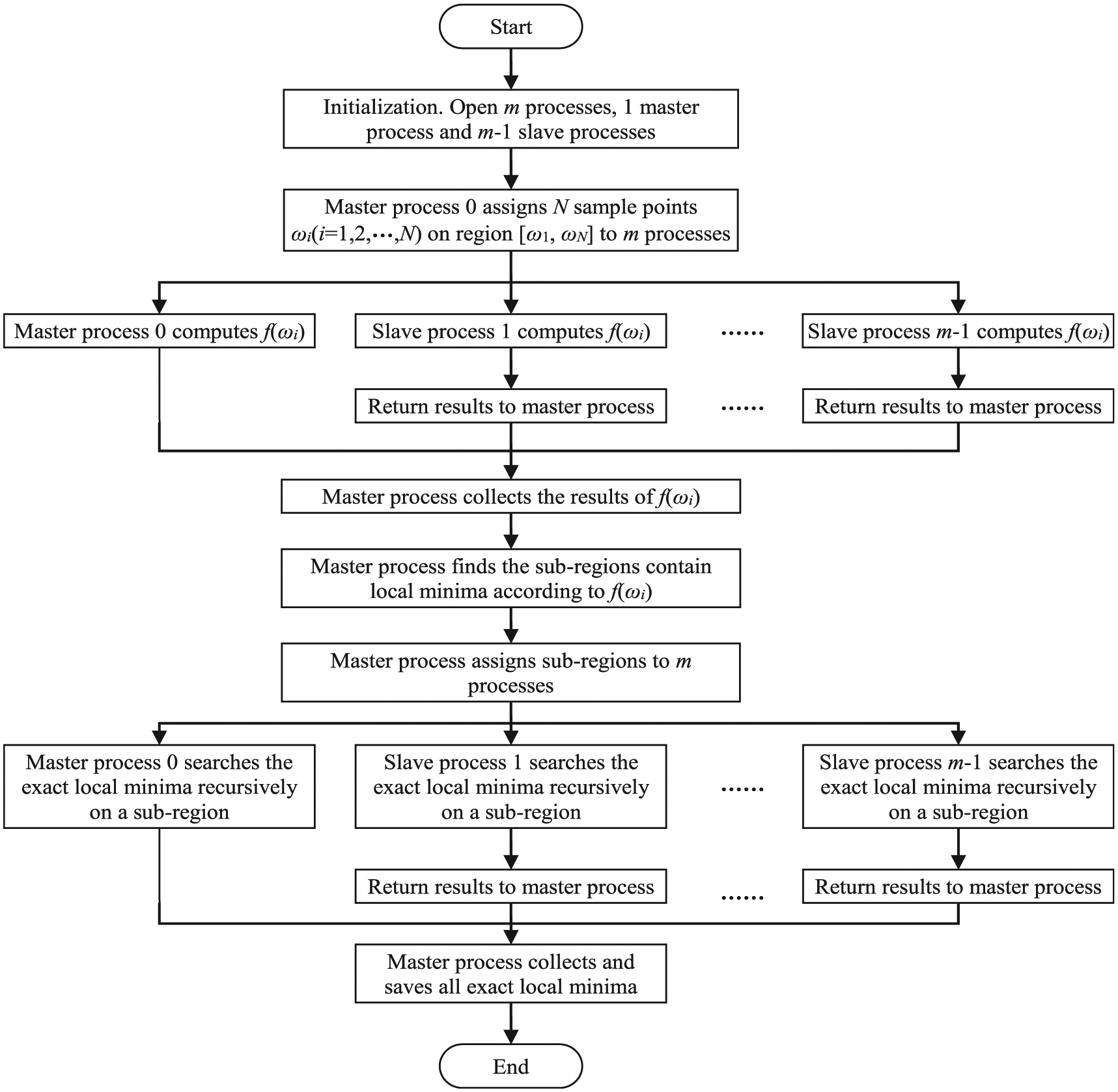
Flowchart of parallel eigenvalue search.
Example of a non-uniform beam
Figure 10(a) shows a non-uniform beam with length L. More detailed geometry parameters of the cross section are marked in Figure 10(a). The cross-sectional area is A(x), and the sectional moment of inertia is I(x), where

A
0 and I0 are the cross-sectional area and the sectional moment of inertia at x = 0, respectively, and
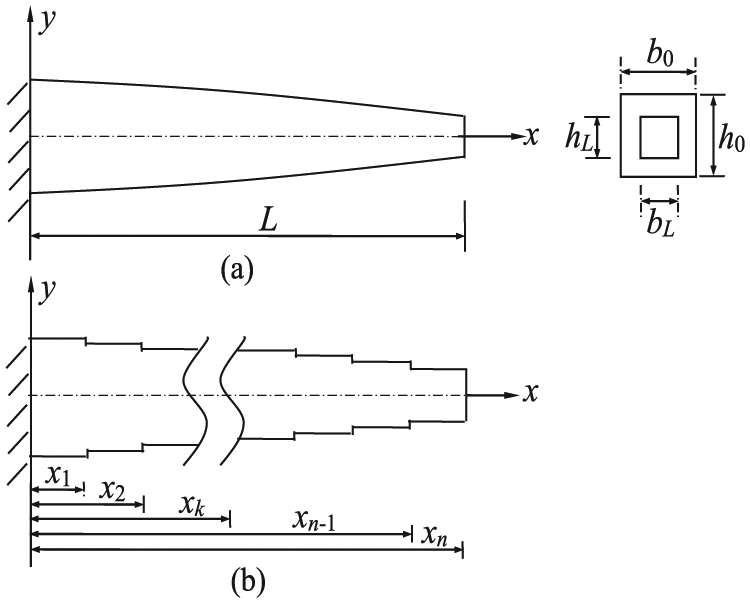
Non-uniform beam model.
The non-uniform beam can be discretized into n segments of uniform beam elements with length
Taking the uniform beam segment as a Euler–Bernoulli beam with free and damped transverse vibration, its dynamics equation can be obtained as 14

where
By applying linear MSTMM, the transfer matrix of the beam can be obtained as

where

If each beam segment from left to right is numbered as 1 to n, respectively, and the transfer direction is defined from left to right, then the overall transfer equation of the non-uniform beam can be acquired as

where

is the overall transfer matrix of the system with the matrix element
By substituting the boundary conditions

where
The proposed method can be applied to solve equation (21). The search accuracy is set to be 10−4, and the dynamics parameters are given as follows: L = 4 m, b0 = 0.04 m, h0 = 0.04 m, bL = 0.02 m, hL = 0.02 m, ρ = 2730 kg/m3, I0 = 2.133 × 10−7 m4, E = 6.9 × 1010 Pa, and
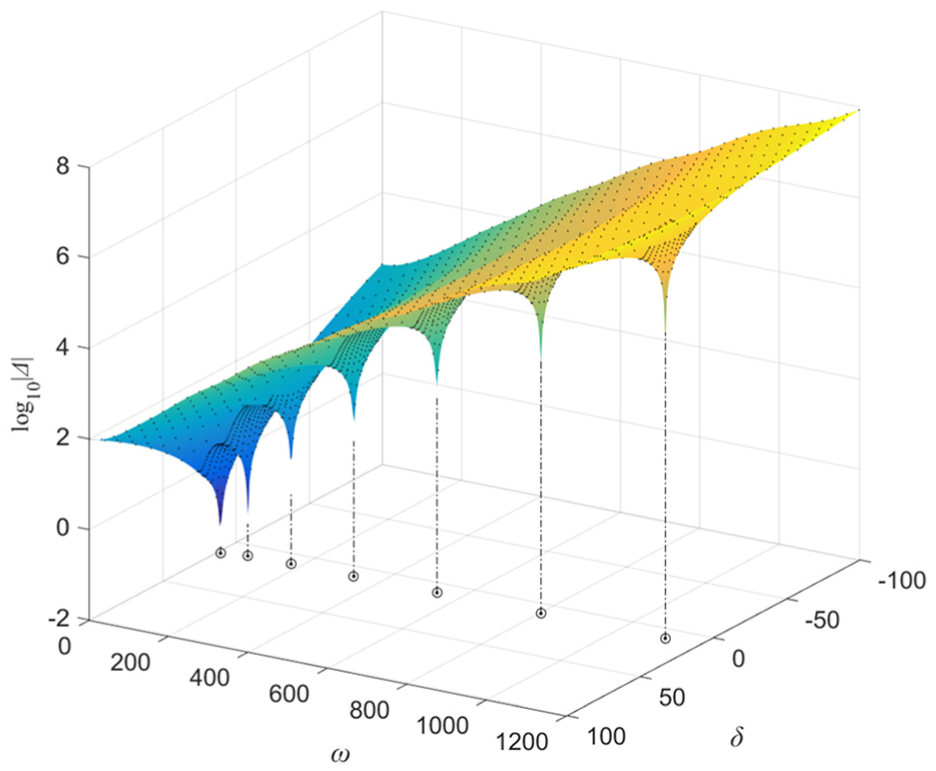
The eigenvalues log10|Δ(s)| of non-uniform beam.
Comparison of the computational results of eigenvalue between MSTMM and DVSM.

MSTMM: transfer matrix method for multibody systems; DVSM: direct variable separation method.
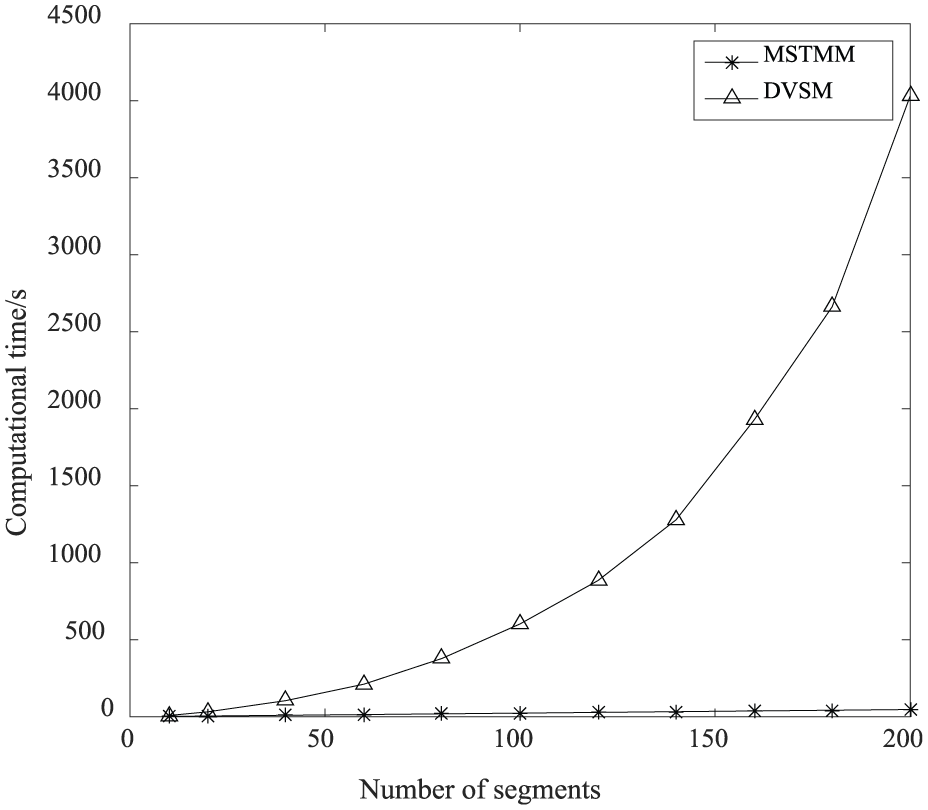
Comparison of computational time.
Typically, there are three indexes to describe the computational efficiency of parallel computing: computational time t, speedup ratio Sp, and parallel efficiency Fp, where Sp is defined as the ratio of the computational time with a single process (T1) to that with p processes (Tp), namely, Sp = T1/Tp and Fp = Sp/p. For a number of segments n = 100, the three indexes obtained by applying the proposed distributed parallel computing algorithm are listed in Table 7. Obviously, the parallel computing can accelerate the computational speed. From scheme no. 2–5 in Table 7, it is known that the computational speed of one PC with dual-core is slightly faster than two PCs with single-core; meanwhile, one PC with quad-core is slightly faster than four PCs all with single-core. This indicates that network delay has an impact on distributed parallel computing. Therefore, good network transmission speed should be ensured when using distributed parallel computing technique. Figure 13 shows how these indexes vary with CPU core numbers. Furthermore, with the increasing number of CPU cores, the computational time t is on the decline, but the trend is leveling off; meanwhile, the Sp increases and Fp decreases. This may be attributed to the increase in the communication overhead between different processes. Although the computation amount of a single process decreases since the number of CPU cores increases, the proportion of communication overhead relative to the computation amount for each process will increase, leading to the decrease in computational efficiency. To clarify, the computation scale is reduced by cutting down the number of segments of the beam to three and reducing the size of sample points. This will result in the preceding three indexes shown in Figure 14 and the proportion of average communication time tc of each process to computational time t shown in Figure 15, respectively, where tc only contains the time for each process to receive and send data using the MPI functions MPI_RECV, MPI_SEND, and MPI_BARRIER. From Figures 14 and 15, it can be found that Sp increases slowly and Fp becomes very low when the number of CPU cores rises. This is because the proportion of the communication time relative to the computational time enlarges and cannot be ignored. Under these circumstances, it has less effect to simply increase the number of CPU cores for improving the computational efficiency.
Parallel computational time, speedup ratio, and parallel efficiency.

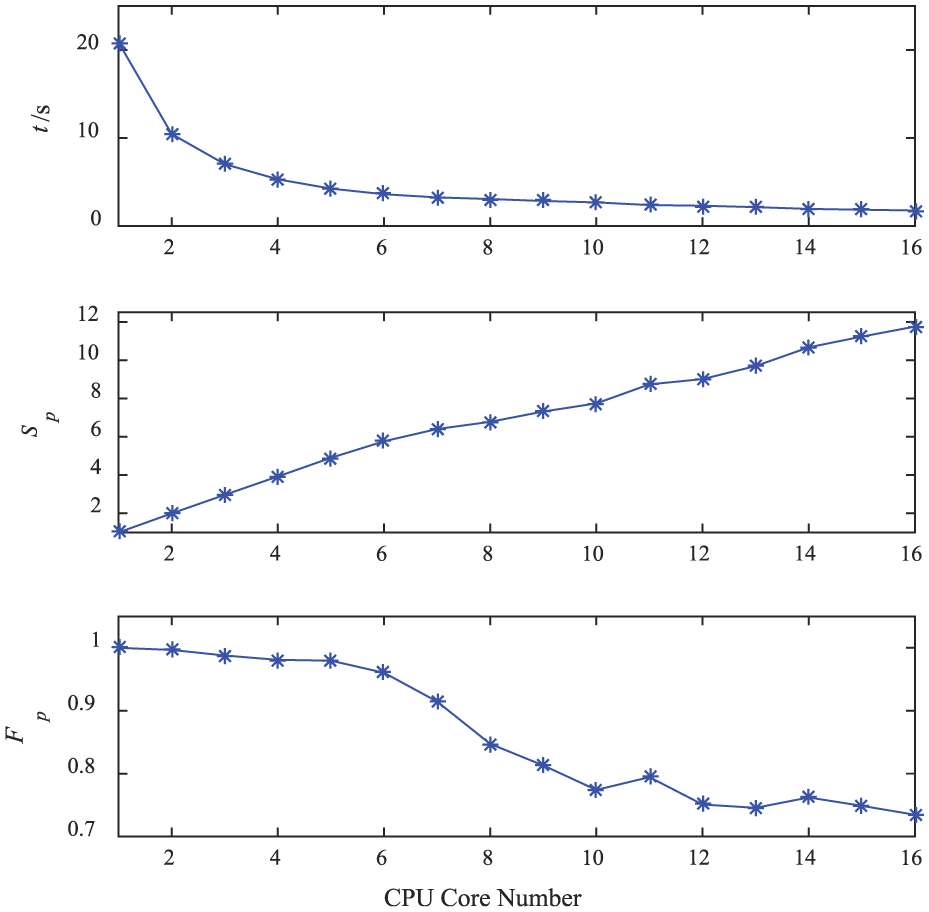
Computational time, speedup ratio, and parallel efficiency with different CPU core numbers.
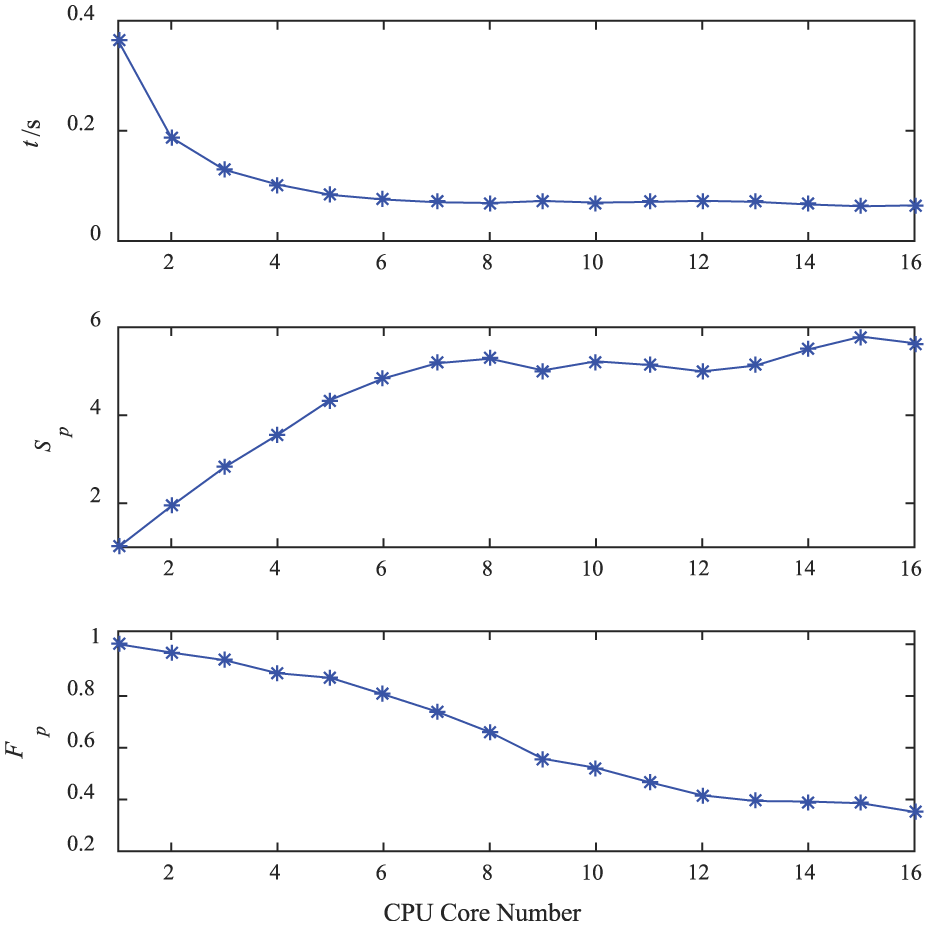
Computational time, speedup ratio, and parallel efficiency of the reduced computation scale.
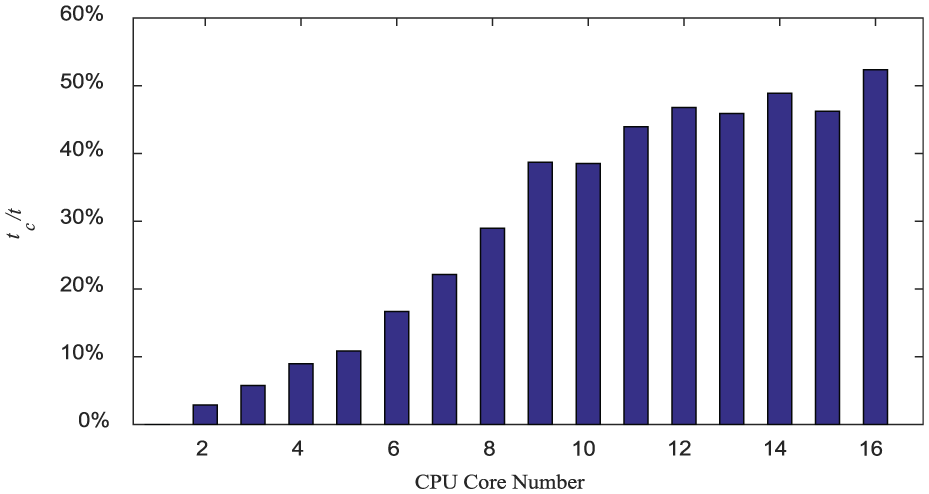
Proportion of average communication time tc to computational time t.
Engineering example of an MLRS
An MSD model of MLRS with 18 launch tubes is shown in Figure 16. According to the natural properties of each MLRS components, these components can be regarded as dynamics elements including lumped masses, rigid bodies, elastic beams, springs, torsional springs, and so on and are sequentially numbered. The corresponding topology figure of the dynamics model is shown in Figure 17. The body elements labeled 2, 5, 8, 11, 14, and 17 are the wheels; 19 the vehicle body; 21 the revolving part; 23 the pitch part; 27 + 5l and 28 + 5l the segments of the launch tube; 26 + 5l the tail of the launch tube, where l stands for the launch tube in the firing state and
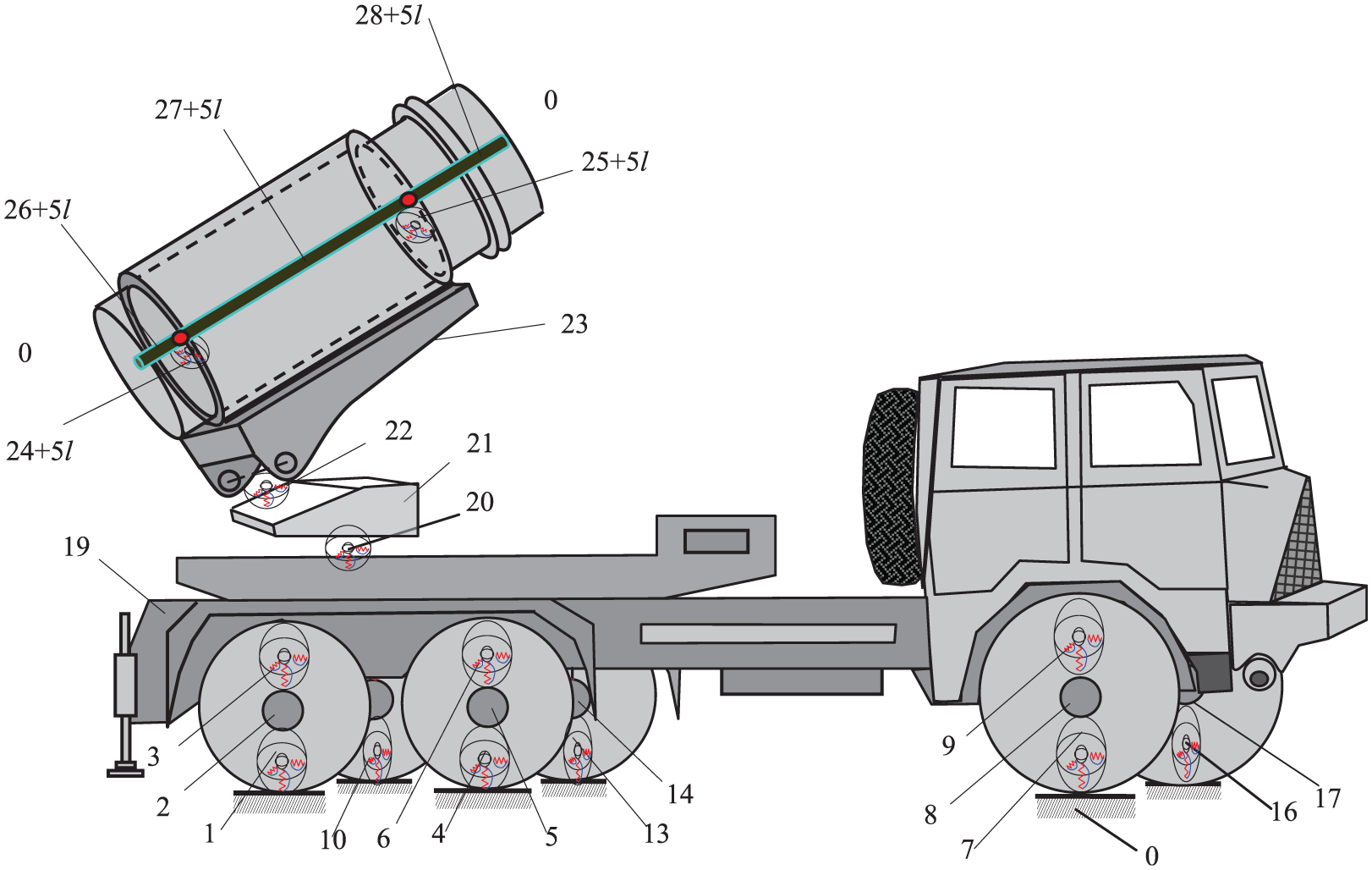
MSD model of MLRS.
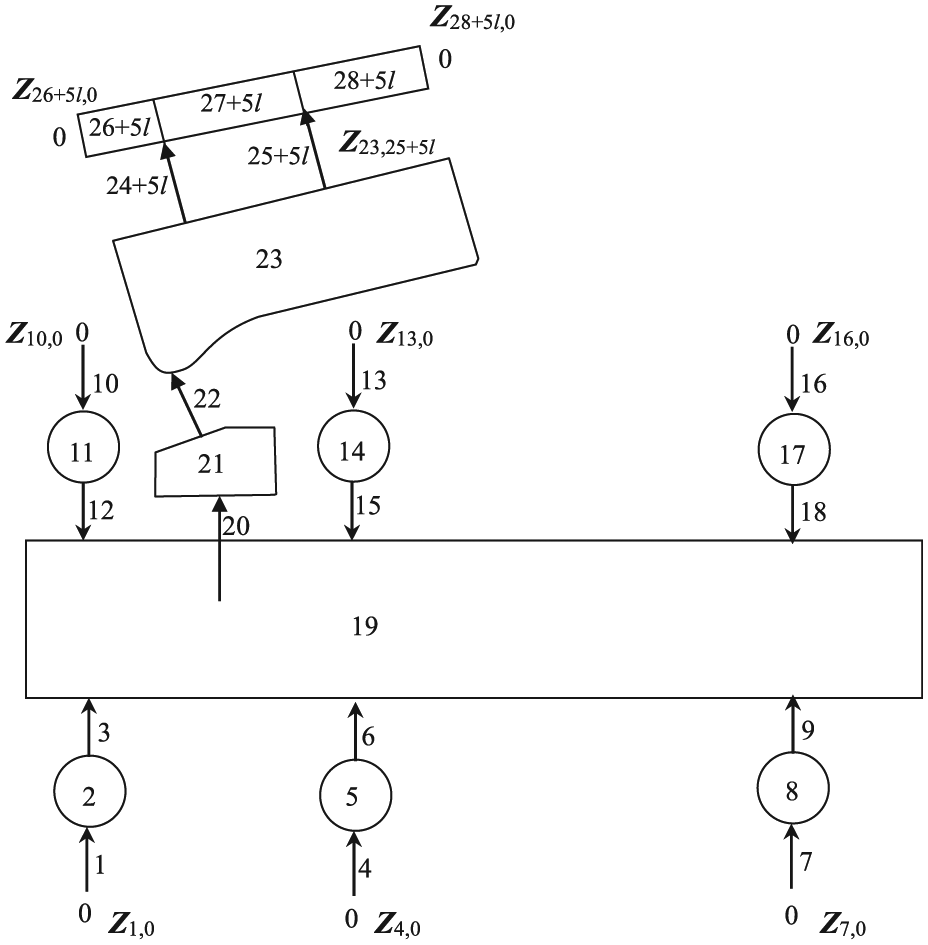
Topology figure of MSD model of MLRS.
Based on the topology of the MLRS dynamics model, the overall transfer equation and the overall transfer matrix of the MLRS given by equations (22)–(24) can be obtained by applying the automatic deduction theorem of the overall transfer equation of multibody systems 11



where
Eliminating all zeros in

The characteristic equation can be obtained as

The eigenvalues of the MLRS can be solved by applying the proposed method in this article. Furthermore, the computational time, speedup ratio, and parallel efficiency of the fully loaded MLRS with its first 50 computed eigenvalues by applying the suggested method are shown in Table 8. Moreover, the corresponding curves with different CPU core numbers are shown in Figure 18. Similar to the non-uniform beam, the parallel computing technique substantially increases the computational speed of the eigenvalues of the MLRS.
Parallel computational time, speedup ratio, and parallel efficiency.

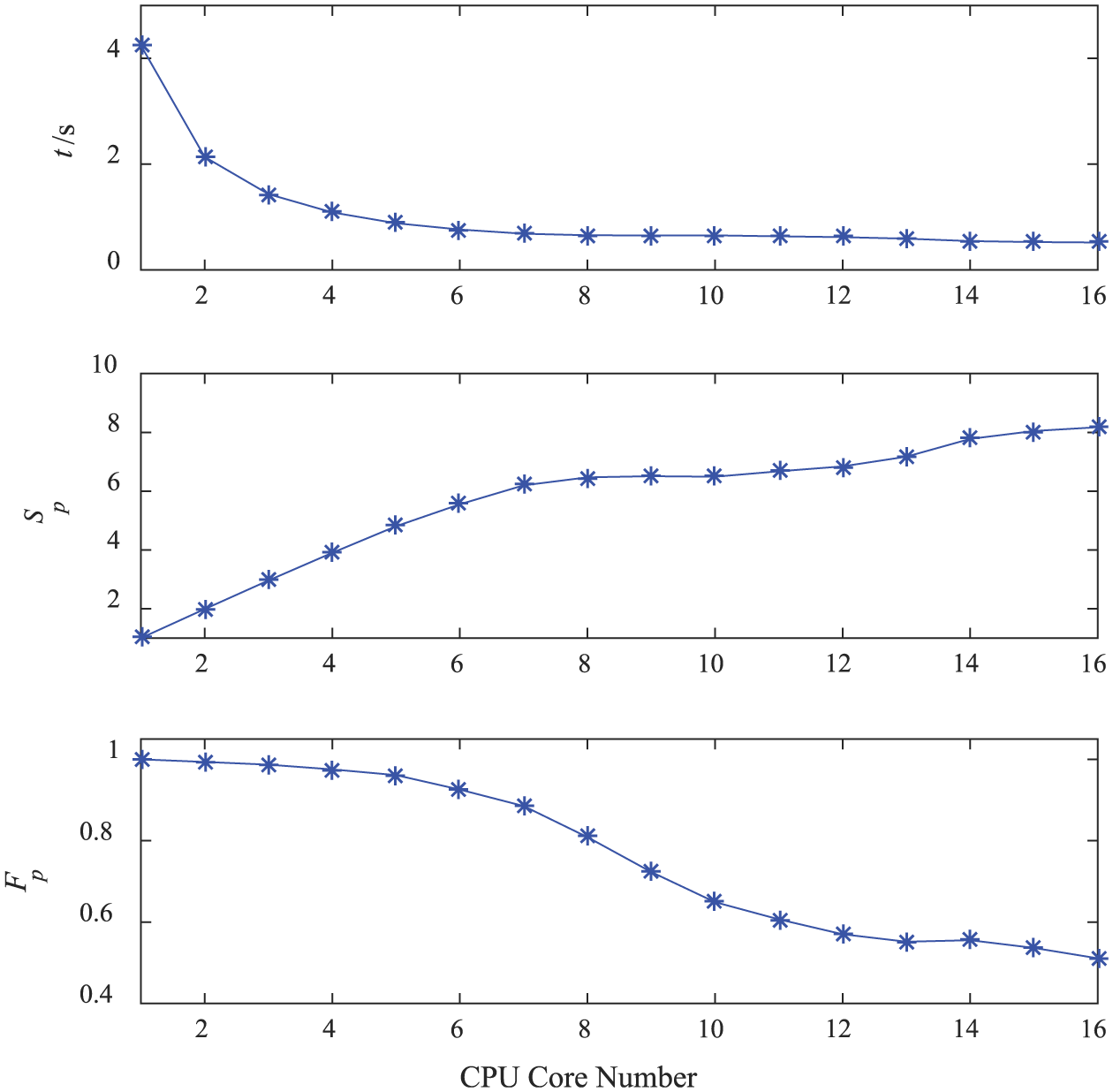
Computational time, speedup ratio, and parallel efficiency with different CPU core numbers.
During the design period, optimization on the parameters of MLRS such as connecting stiffness among MLRS components is an important step of the dynamics design. The firing interval of the MLRS is 0.6 s, namely, the launching frequency is about 1.67 Hz. The natural frequency of MLRS should keep away from the launching frequency to avoid resonances. According to the existing empirical natural frequency of other MLRSs, taking the first 10 eigenvalues of the fully loaded MLRS as optimization objective, and taking the stiffness among components of MLRS as design variables, the genetic algorithm is applied to optimize the dynamics performance of the MLRS. The optimization flow chart is shown in Figure 19. Figure 20 shows the first 10 eigenvalues of the MLRS varying with the genetic generations during the optimization process. The estimation evolution of the best fitness is shown in Figure 21. The eigenvalues obtained by computation and modal test are shown in Table 9. It can be seen that the computational results are in good agreement with those obtained by the experiment.
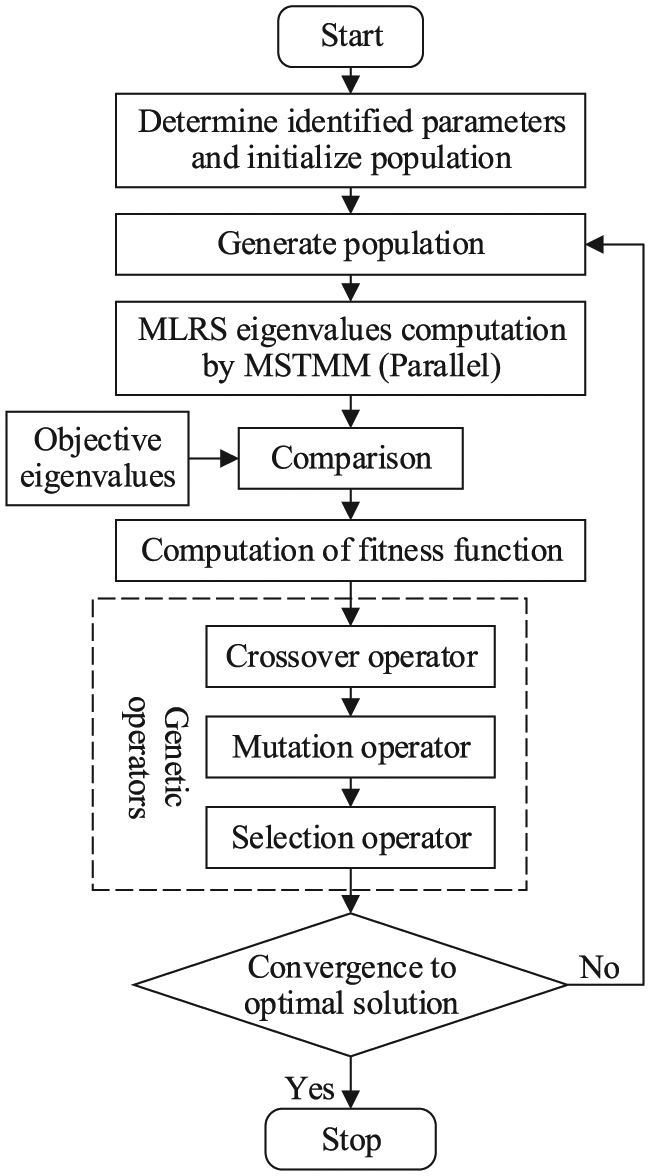
The optimization flow chart of MLRS.
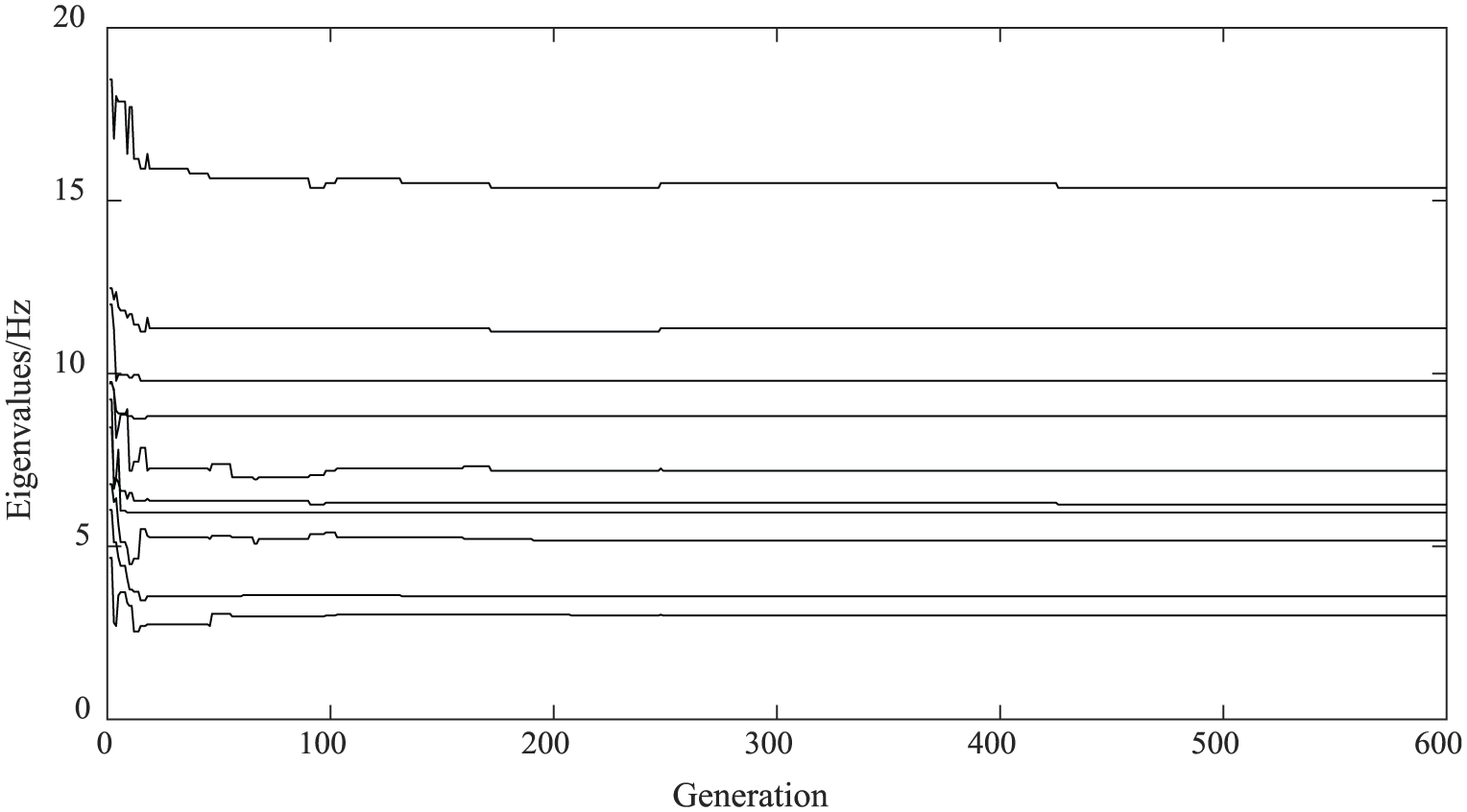
The eigenvalues of MLRS.
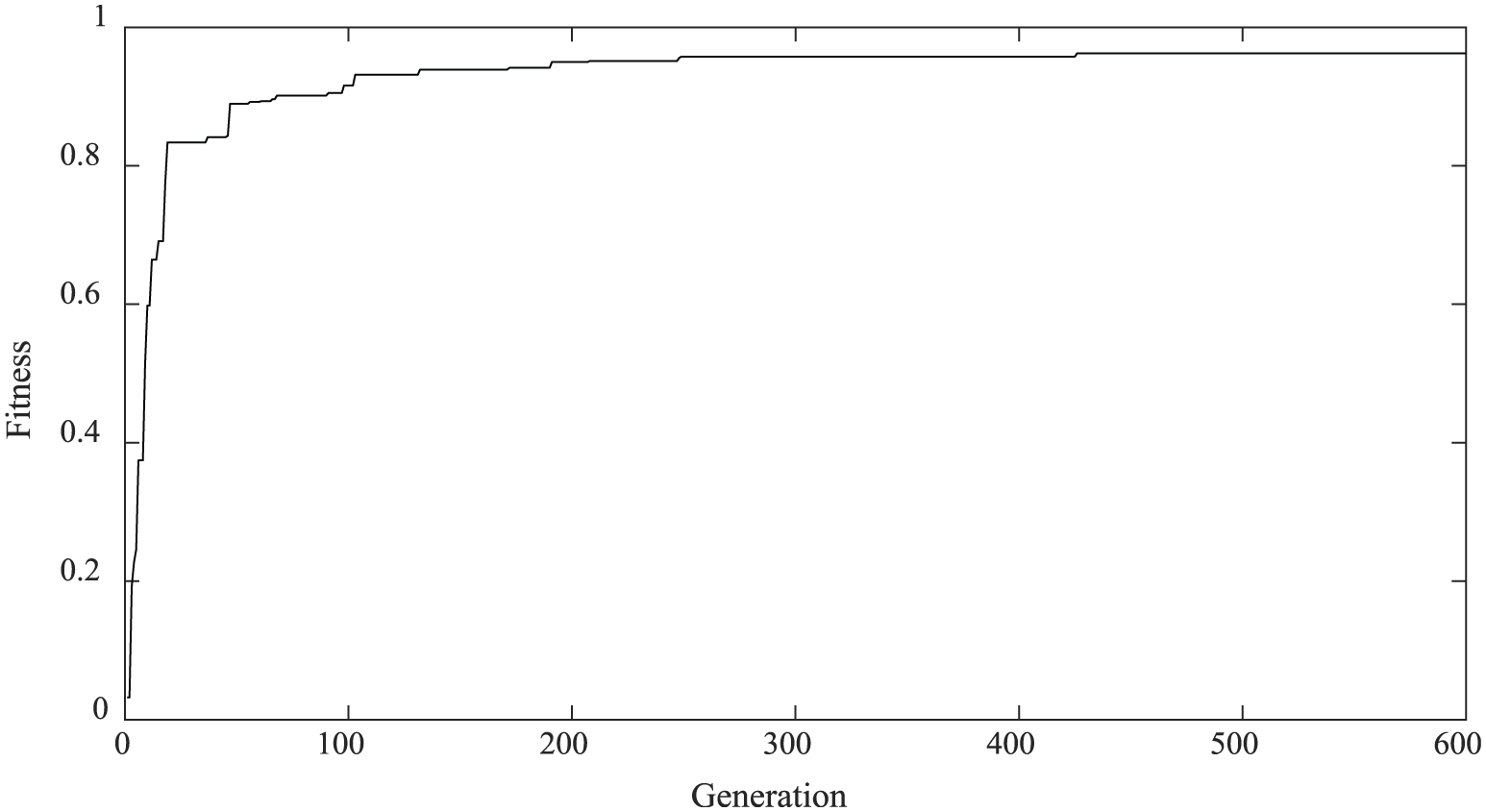
Convergence of the best fitness.
Comparison between the computational eigenvalues and the experimental values of MLRS.

Table 10 shows the computational time by applying the proposed method and by a single process, respectively, which reveals the value of applying the proposed method to the dynamics optimization of complex multibody systems.
Comparison of computational time.

Conclusion
The parallel algorithms for assembling the overall transfer matrix and recursive eigenvalue search are proposed based on MPI parallel computing theory in this article. The eigenvalues of a non-uniform beam and an MLRS are computed using this method. The influence of the CPU core number and the network environment on the computational time is analyzed. This study shows the following points:
The proposed parallel computing algorithm can significantly increase the computational speed to search eigenvalues and efficiently reduce the time cost of the dynamics optimization of complex multibody systems.
The distributed parallel computing environment based on MPI has strong scalability and high performance. It makes it possible to use ordinary computers to construct a computer cluster so that hardware resources can be fully utilized to achieve higher computational efficiency. Moreover, in order to achieve higher computational efficiency, good network environment is essential because the network environment has a certain impact on computational time.
With the increase in the number of CPU cores, the computational efficiency decreases due to the increase in the communication between processes. Therefore, computational time cannot be reduced infinitely by continually increasing the number of CPU cores. Appropriate number of CPU cores should be selected according to the computation scale.
Footnotes
Acknowledgements
The authors owe special thanks to associate professor Bin He, lecturer Wei Zhu, and PhD students Wenbing Tang and Jianshu Zhang for providing important and constructive proposals to this article.
Academic Editor: Mario L Ferrari
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by Research Fund for the Doctoral Program of Higher Education of China (no. 20133219110037), Defense Industrial Technology Development Program of China (no. A2620133008), and Fundamental Research Funds for the Central Universities (no. 30915011326).