
Abstract
The value of taking advantage of the participants’ interactions when analyzing focus group data is often stressed. However, there is a lack of detailed descriptions of how focus group data can be merged with interview data, and considered throughout a thematic analysis process. This article describes a systematic way to include focus group interactions in data analysis, using a coding scheme. The aim was threefold: to develop a coding scheme for focus group interactions; to test and describe a process for interaction analysis, merged into the thematic data analysis process, and to test the coding scheme on another dataset. Based on focus group literature a comprehensive coding scheme for analyzing focus group interactions, was developed, including symbols for these interactions. Data from five focus group interviews involving adolescents were subsequently coded using this scheme. Further analysis of the identified interactions was conducted simultaneously with thematic data analysis, using Systematic Text Condensation (STC) as an illustrative method. The coding scheme was then tested on data from a different focus group involving adolescents in another setting. A comparison between the two coders was made, leading to a slight modification of the coding scheme. The resulting coding scheme is a practical tool adding to the previous knowledge on focus group interaction analysis. More specifically, the scheme facilitates focus group interactions to be visible and accounted for thought the thematic analysis process.
Introduction
Focus group interviews are a commonly used method to gather rich data, well suited for qualitative research aiming to explore the participants’ own experiences and thoughts, to answer specific research questions (Kitzinger, 1994, 1995; Kreuger & Casey, 2015; Warr, 2005; Wilkinson, 1998a). Focus group interviews are not just a ]way to gather data from multiple research participants simultaneously but also a way to capture the sharing of experiences and perceptions among these participants (Wilkinson, 1998c). Compared to individual interviews, focus group interviews offer added value to the data by capturing the interactions among participants, including different understandings of the topics discussed in the interview, disagreements and agreements. Therefore, interactions are an essential part of the method when using focus group interviews and should be considered throughout the analytical process (Carey & Smith, 1994; Kitzinger, 1994; Kitzinger & Farquhar, 2011; Warr, 2005; Wilkinson, 1998b).
Research that relies on focus group data often tends to focus solely on the content of participants' statements, neglecting to acknowledge and provide information derived from group interactions (Duggleby, 2005; Kitzinger & Farquhar, 2011; Morgan & Hoffman, 2018; Wilkinson, 1998c). In the literature, several authors suggest descriptions of interactions between participants as relevant in analyzing focus group data (Duggleby, 2005; Kitzinger, 1995; Kreuger & Casey, 2015; Myers, 1998; Stevens, 1996; Wilkinson, 1998c). However, the methodology for analyzing focus group interviews needs to be adapted to the purpose of the study (Duggleby, 2005).
Several researchers have contributed to analysis of focus group interactions (Duggleby, 2005; Kidd & Parshall, 2000; Kreuger & Casey, 2015; Lehoux et al., 2006; Morgan & Hoffman, 2018; Morrison-Beedy et al., 2001). Morgan and Hoffman (2018) have developed a coding system to track transitions in interviews, both between participants and between the participants and the interviewer. The coding system was used to compare speakers’ transitions in dyadic interviews with speakers’ transitions in focus groups. Analyzing participants’ influence on others’ opinions is another way of considering focus group interactions (Kidd & Parshall, 2000; Lehoux et al., 2006)., e.g., by the use of a software tool to “identify any undue influence of the group on any individual participant(s), or vice versa”, as suggested by Kidd and Parshall (2000, p. 299). As support to explore focus group interactions that can impact data quality, Lehoux and colleagues (2006) created a template which supports the comparison of data content derived from the focus group interview with the group process to illuminate data quality. Morrison-Beedy and colleagues (2001) provide examples of how to add data to transcribed focus group data, such as comments about body language and the researchers’ impressions. Further, some researchers have specified different types of interactions to look for in the analysis process, e.g., agreement and disagreement, but without practical guidance on how to implement and report these aspects in the results (Kitzinger, 1995; Kreuger & Casey, 2015; Myers, 1998; Stevens, 1996; Wilkinson, 1998c).
Kreuger and Casey (2015) provide a list of characteristics of conversation in focus group discussions to regard in the analysis, and signs to look for linked to the listed focus group characteristics. They also present a set of questions to help cluster the presence of the characteristics in a content analysis process. However, they do not give examples of more detailed practical descriptions on how to perform the final analysis and report the results.
To summarize, there is an awareness of the importance of group interactions in analyzing data from focus groups and there are some useful tools for interaction analysis. However, there is still a knowledge gap regarding practical tools to help researchers conduct such analyses and to include interaction data during the whole analytical process and presentation of the results (Duggleby, 2005; Kitzinger, 1994; Morgan & Hoffman, 2018; Wilkinson, 1998b).
Aim
The aim of this study was threefold: to develop a coding scheme for focus group interactions; to test the coding scheme and a process for interaction analysis, merged into the thematic data analysis process using Systematic Text Condensation (STC) as an example; and to test the coding scheme on another dataset and with another researcher.
Methods
This section describes the different steps involved in this study, i.e.: 1) Development a of coding scheme for focus group interactions; 2) Empirical testing of the coding scheme and further analysis of the interactions integrated with Systematic Text Condensation, STC, (Malterud, 2012), a form of thematic analysis; 3) Testing of the coding scheme on other data; 4) Finalizing the coding scheme.
Development of the Coding Scheme
The coding scheme for interaction between participants in focus group interviews was developed deductively, based on literature regarding essential interaction elements in focus group interviews (Kitzinger, 1995; Morgan & Hoffman, 2018) and Kreuger and Casey’s (2015, p.142–143) list of features of focus group interactions: “spontaneous comments, inconsistent comments, specific versus general comments, people change their minds, words used differently, people repeat comments, conversations tend to wander, people present a view with intensity or emotion” (Kreuger & Casey, 2015, pp. 142–143).
With that theoretical base in mind, the full interview material was read through and the first author compiled a list of interactions that were relevant, for the current coding scheme: agreement, disagreement, differentiation, change in thought or opinion, different use of words, repetition, engagement, silencing, misunderstanding and development. The latter two were however not included in the final version of the coding scheme, after the coding scheme was tested by another researcher, see the results section below under the heading “Testing of the coding scheme on other data: results”. Symbols were added to mark the interactions in the data. They were selected on the basis that they should be easy to insert, be associated with the interaction they symbolise and not be used as already established symbols in interview transcriptions (Silverman, 2019).
Empirical Testing of the Coding Scheme and Further Analysis of the Interactions Integrated with STC as a Form of Thematic Analysis
The empirical testing of the coding scheme and further analysis was carried out during data analysis in a focus group study conducted by the first, third, fourth and fifth authors. The aim of that study was to describe adolescents’ views on mental health concepts, the prevalence of mental health problems, and related stigma (Hermann et al., 2022a, 2022b). However, the descriptions of the coding of the interactions and the further practical analysis process regarding the focus group interactions has not been previously published. Hence, the current study was based on data and completed thematic analyses of the five focus group interviews on adolescent mental health. In total, 27 adolescents, 15–18-years-old, had participated in semi-structured focus group interviews, conducted face-to-face in October and November 2020 (Sweden had no school closures at this stage of the Covid-19 pandemic). Each focus group was divided into two sessions and lasted, on average, 114 minutes in total. The transcribed data comprised approximately 400 pages. The data was analyzed by the thematic analysis Systematic Text Condensation, STC (Malterud, 2012), which is based on phenomenology. The STC analysis is conducted in four steps. In the first step, all data are read to get an overall impression, and preliminary themes are identified. In the second step, meaning units are identified, which are fragments of content that can include words, sentences, or paragraphs. The meaning units are then categorized into the preliminary themes and further clustered into code groups. In the third step, code group data are sorted into sub-groups, and the content in each code or sub-group is summarized into a synthetic quote, i.e., a condensate. Finally, in the fourth step, an analytical text is formulated and structured around final themes and categories. The results are finally validated by comparing the summarized results with the original data.
Malterud (2012) does not provide specific guidelines on how to incorporate focus group interactions into the analysis process practically according to the STC method. Further, the use of the coding scheme did not provide guidance on how to conduct further analysis of the interactions identified, so it was essential to put words to the interactions coded in the data, as the analysis process proceeded. Therefore, a model was developed to integrate the coding scheme and further analysis of the focus group interactions with the STC analysis.
Figure 1 presents an overview of the activities in each step of the STC analysis process and the activities in the interaction analysis process linked to each of the four steps of the STC. In the STC analysis process, the coding scheme was applied and tested in step two of the STC process. A detailed description of the results of the empirical testing, is given in the results section, under the heading “Empirical testing of the coding scheme and further analysis of the interactions integrated with STC as a form of thematic analysis: results”. Overview of activities for thematic qualitative analysis and interaction analysis in each step of the Systematic Text Condensation (STC) process.
Testing of the Coding Scheme on Other Data
The coding scheme was also tested on another focus group data set. The rest of the interaction analysis process, linked to the four steps in STC, was however not tested on the other material. For this test on other focus group data, we used data from another previously conducted focus group interview, with adolescents born in Somalia but currently living in Sweden (Osman et al., 2020). The second author, who had moderated the focus group discussion, used the coding scheme and instructions, written by the first author, to code the interactions in a section of the transcripts. The first author who also performed a parallel coding of the same data section had not seen the interview data before the coding. There was no discussion between the authors while the coding was conducted. The results of the coding and description of the modifications are presented in the results section “Testing of the coding scheme on other data: results”.
Finalizing the Coding Scheme
After the test of the coding scheme on another focus group data set and by another researcher, the results were discussed between the two coders and the coding scheme was modified. The results of the modifications are presented in the results section “Finalizing the coding scheme: results”.
Ethical Approval
Both studies that generated data used in the current study received ethical approval from the Swedish Ethical Review Board; reg.no. 2014/048/2 and reg. no. 2020/03300 respectively (Hermann et al., 2022a, 2022b; Osman et al., 2020). All participants in both studies gave their written consent to partake in the study.
Results
The Coding Scheme for Focus Group Interactions: Results
Coding Scheme for the Interaction Among Participants in the Focus Group Interviews.

Agreement and disagreement were interactions selected to the coding scheme, based on their central role in focus group discussions (Kidd & Parshall, 2000; Myers, 1998; Wilkinson 1998a, 1998c). In line with Morgan and Hoffman (2018) we refer agreement to an interaction where a participant is reinforcing someone else’s statement by their own statement or by a short expression of agreement like “yes” or “that is true”. To simplify the coding we also regarded distinct expressions of sympathy with another person’s statement as agreement, in contrast to Morgan and Hoffman (2018) who code support separately. Disagreement was, in line with the descriptions from Morgan and Hoffman (2018), regarded as disputing a statement from another participant, formulated by an extensive statement of just a single or few words like, “nor” or “I don’t agree”. The first suggestion for symbols for coding agreement/disagreement interactions was an equal sign (=) and an over crossed equal sign (≠), respectively. In the process of finalising the manuscript, however we changed the symbols to an upward arrow (↑) for agreement and a downward arrow (↓) for disagreement to avoid misunderstandings, as the equal sign is used by Silverman (2019) to note, in transcripts, when there is no gap between two quotes.
Differentiation was added to the scheme, as it was evident in the interview data that participants sometimes responded to a statement with an adjustment, not simply by agreeing, yet not consistent with disagreement. The label differentiation was consistent with Morgan and Hoffman’s (2018) description of differentiation. At first we suggested an approximate sign (⁓) but when an upward arrow was chosen as a symbol for the agreement we decided to use a slanted upward pointing arrow (↗) as symbol for differentiation.
Change in thought or opinion refers to one participant changing opinion or expressing a thought previously stated, from the same participant. It was based on three of Kreuger and Casey (2015, p. 142) features of conversations: a) “Spontaneous comments” which may lead to a change in opinions later in the discussion, b) “Inconsistent comments”, due to change in opinion, previous ambiguous conversation and new insights, and c) “People change their minds”. A bidirectional arrow (↔) was chosen as a symbol for this interaction.
Different use of words was included in the scheme, based on the focus group characteristic “Words used differently” stated by Kreuger and Casey (2015, p.142). It refers to participants using words for essential concepts differently. An exclamation mark (!) was selected as a symbol for this interaction.
Repetition was based on Kreuger and Casey’s (2015) focus group characteristic “People repeat comments”. It refers to a participant repeatedly stating the same thought or opinion. A capital r (R) was chosen as symbol for repetition.
Engagement was based on Kreuger and Casey’s (2015) focus group characteristic “People present a view with intensity or emotion”. This characteristic refers to increased energy or expressed emotions in the focus group, in relation to a statement. A capital e (E) was chosen as symbol for engagement.
Silencing was based on Kitzinger’s (1995) acknowledgement of the risk of dissenting opinions being silenced. It refers to participants silencing a topic, i.e., other participants neglecting a statement, abruptly changing the topic or being all silent as a response to a participant’s statement. A zero (0) was selected as a symbol for this interaction.
Empirical Testing of the Coding Scheme and Further Analysis of the Interactions Integrated with STC as a Form of Thematic Analysis: Results
As described in the method section, the coding scheme was empirically tested within the framework of the thematic data analysis STC, conducted in a focus group study conducted on Gotland, Sweden’s largest island in the Baltic Sea. Figure 1, presented in the Methods section, gives an overview of activities in the interaction analysis process linked to the four steps of the STC process. Below, details of the practical integration of the focus group interaction analysis, linked to each of the steps in the STC analysis process, is described.
The First Step of the STC Process Combined with the Interaction Analysis
Figure 2 presents an overview of the activities in the first step of STC and current interaction analysis activities linked to that step, as an extract of Figure 1. Overview of activities according to STC and for interaction analysis, respectively, in the first step of STC.
Here, the text was read and re-read, and preliminary themes were identified to catch the overall impression of the adolescents’ views on mental health and stigma in the interview data. When the text was read the interactions were reflected upon as a part of the data considered when the themes were formulated. For example, subjects eliciting emotional response, strong agreement or disagreement were regarded as clearly salient to the youth, whereas differentiation on other participants’ statements or use of different words might allude to importance due to these very challenges, thus contributing to themes.
The Second Step of the STC Method Combined with the Interaction Analysis
Figure 3 presents an overview of the activities in the second step of STC and current interaction analysis activities linked to that step, as an extract of Figure 1. Overview of activities according to STC and for interaction analysis, respectively, in the second step of STC.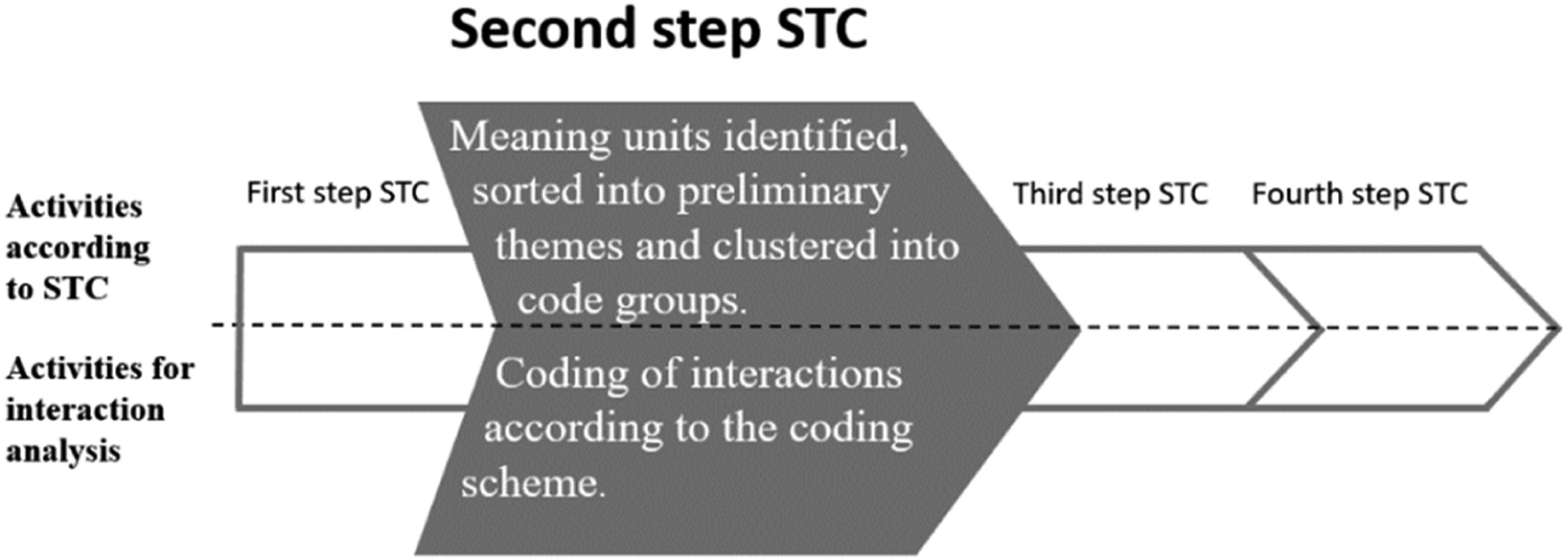
In this step, the coding scheme was used to mark interactions in the interview data.
Meaning units were then identified in the transcripts, i.e., sentences or paragraphs giving different information related to the research questions. The types of interactions listed in the coding scheme were identified in the meaning units and marked with the corresponding symbols. Below are examples of how this was done in practice for each interaction in the coding scheme.
Coding of Agreement
Example of the Coding of Agreement.

Coding of Disagreement
Example of the Coding of Disagreement.

Coding of Differentiation
Example of the Coding of Differentiation.

Coding of Change in Thought or Opinion
Example of the Coding of Change in Thought or Opinion.

Coding of Different Using of Words
Example of the Coding of Different use of Words.

Coding of Repetition
Example of the Coding of Repetition and Engagement.

Coding of Engagement
The code for engagement (
Coding of Silencing
According to the coding scheme, the symbol for silencing (
Sorting of the Meaning Units after Completed Marking of Interaction Symbols in the Interview Data
When the coding was complete, the meaning units were cut out from the transcripts and, according to the STC method, sorted into the preliminary themes and clustered into code groups, sorted by hand, and put up on a clipboard. In step two of the STC method, the marking of the interactions with symbols resulted in the possibility of significantly shortening some of the meaning units. This occurred because agreement or disagreement, in the form of single words or short sentences, not adding more content than the symbol for agreement or disagreement, was marked in the quote the participants agreed upon. Thus, the single affirmatory or opposing words or short sentences which had been replaced by a symbol in the original quote could be omitted when the dialogue was cut out as a meaning unit. It was not unusual that the dialogues between the adolescents were long, with a lot of short affirmative and opposing utterances and repetition of another participant’s statements. Therefore, the shortening of the meaning units without losing information relating to the interaction was possible and contributed to a clear overview of the content in each meaning unit.
The Third Step of the STC Method Combined with Activities for the Interaction Analysis
Figure 4 presents an overview of the activities in the third step of STC and current interaction analysis activities linked to that step, as an extract of Figure 1. Overview of activities according to STC and for interaction analysis, respectively, in the second step of STC.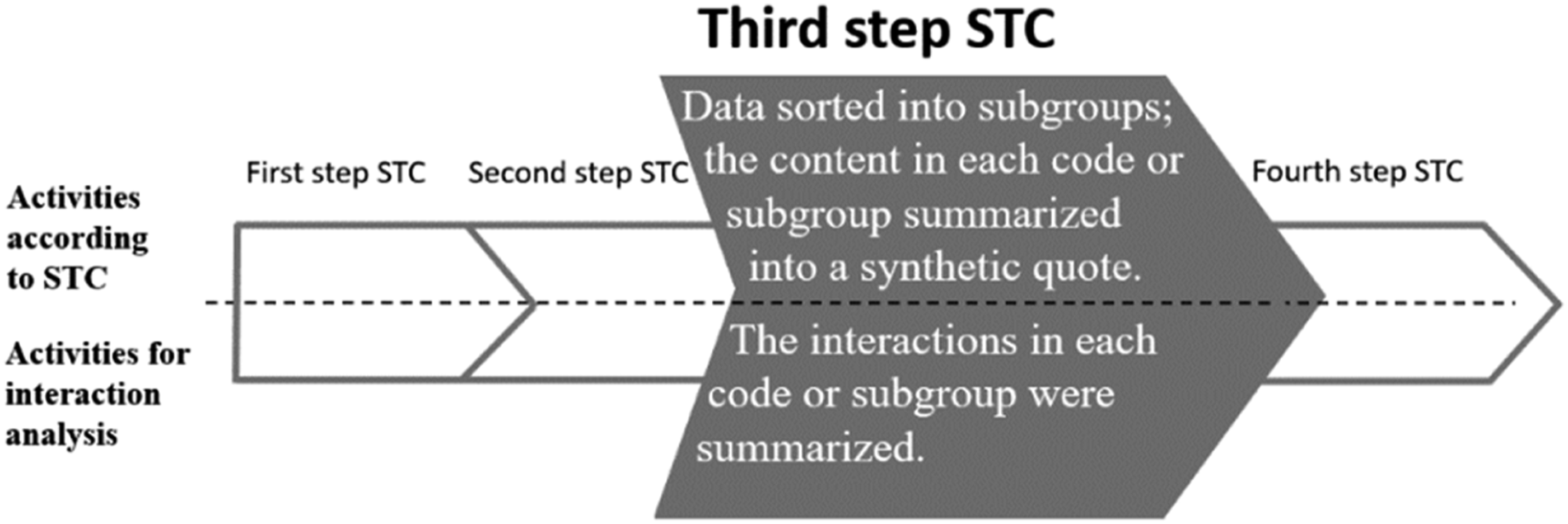
Examples of Meaning Units and Summaries of Interactions From the Current Code Group.

The Fourth Step of the STC Method Combined with Activities for the Interaction Analysis
Figure 5 presents an overview of the activities in the fourth step of STC and current interaction analysis activities linked to that step, as an extract of Figure 1. Overview of activities according to STC and for interaction analysis, respectively, in the second step of STC.
According to the fourth (last) step in the STC method, the results from the condensate were formulated into an analytic text with themes and categories (derived from the code groups) as headlines. Specifics of the participants’ interactions were merged into the description of the results, based on the summation of the interactions. Below, we exemplify the formulation of the content together with the description of the interactions through extracts from the results text from the previous study in Sweden where the coding scheme was used: “The adolescents suggested mental health problems were conditions that anyone could have, and that such problems were caused by many different factors. Mental health problems were issues they had to deal with, and they stressed that no one should be blamed or judged for having such conditions. As an exception, one participant stated that you might be blamed for your mental health problem, if you turn a minor issue into a major issue. There was also an engaged discussion in one focus group that held diverse opinions on whether those with mental health problems could pull themselves together and get well if they were really motivated.” (Hermann et al., 2022b). “Depression was mentioned by most of the adolescents as a severe mental health problem and an illness. However, in one focus group, there was a lively discussion about whether depression is really a psychiatrically diagnosed condition or just a description of ongoing feelings.” (Hermann et al., 2022a). “Stereotypical gender norms were mentioned in the individual interviews and vigorously discussed in each of the focus groups and were highlighted, in consensus, to be a causal factor of mental health problems.” (Hermann et al., 2022b).
Once the result text with selected quotes was formulated, validation of the results was done by comparing it with the original interview data. Practically, this was done by re-reading the interview transcripts and reflecting on whether they were consistent with the summarized results.
Testing of the Coding Scheme on Other Data: Results
The second author found the coding scheme easy to use in some parts and a bit too complicated in other parts. Thus, some modifications in the coding scheme were necessary.
The second author found it easy to code interactions regarding agreement, disagreement and differentiation. The first author, who had developed the coding scheme, also found these interactions in the interview material and the authors’ codings were consistent. Both authors identified and coded change in thought or opinion, but placed the symbol in different places in the text. However, after discussion the two authors agreed on marking the symbol on the two quotes that illustrated the change in thought or opinion, i.e., the first quote and the second revealing the change, as described in the coding scheme. Further, the second author marked some quotes with the symbol for engagement. The first author, who could not identify increased energy from the transcribed text alone, did not note this. However, the two authors agreed on the coding of engagement when the second author could add the actual perceived energy increase in the conversation, at the highlighted quotes. None of the authors found any signs of repetition, different use of words or silencing, in the selected interview excerpts. Still, the second author perceived these interactions as potentially easy to understand and mark had they appeared.
Finalizing the Coding Scheme: Results
In the first draft of the coding scheme, which was tested, the interactions misunderstanding and development were also included. Misunderstanding referred to participants misunderstanding each other and the symbol of a question mark (?) was marked on the first statement and the following statements where the misunderstanding was evident. The coding of misunderstanding was perceived by the second author as difficult to understand. The first author had also not identified a need for the use of that symbol in the previous test of the coding scheme. Thus, the value of the code misunderstanding was discussed and found to be redundant and was therefore removed, as different use of words was already a code in the scheme. Development referred to a series of quotes of the discussion, which were related in a sequence. The purpose was to keep track of which quotes belonged together in a dialogue. The first quote in the sequence was marked with a less-than sign, followed by a specific letter (e.g. <A). All statements that were then connected to the first one were marked with a more-than sign and a specific letter (e.g. >A). The quote in the next connected sequence was marked in a similar way but with a different letter after the more-than and less-than signs. Within each sequence, other interactions that were identified were also marked, according to the coding scheme. Both authors found it too complicated to mark the transcripts for development. After discussion, both authors agreed that this interaction was redundant in the current coding scheme, since it mainly referred to focus group interaction related to transitions between speakers. Moreover, there were already other codes indicating reactions to other participants’ quotes, e.g., agreement, disagreement, and differentiation. After the revision of the coding scheme, the authors perceived the coding scheme, with eight listed interactions, as a useful tool for identifying interactions in the transcribed focus group data.
Discussion
The Coding Scheme and the Description of the Focus Group Interaction Analysis Add to Existing Knowledge
The developed coding scheme was found to be a useful tool for systematically identifying and coding interactions evident in the transcribed focus group data. It is a practical tool which complements previously developed tools for analyzing focus group interactions. Our coding scheme specifically targeted on merging focus group interactions with the interview data to enhance the focus group interactions to be visible throughout the thematic analysis process, and in the reported results.
Although the current coding scheme was not developed as a tool to track transitions between speakers, as described by Morgan and Hoffman (2018), it captures important aspects of transitions, such as agreement and disagreement. The coding scheme was also not developed as a tool to evaluate the quality of the focus group data, as the tool presented by Kidd and Parshall (2000) and Lehoux and colleagues Lehoux et al. (2006). However, as the participants’ interactions are coded according to the scheme, data quality may be evident. If, for instance, the interactions’ change of opinion, and repetition occur frequently in the transcripts, researchers may reflect upon the quality of the data. Such recurring interactions may be linked to the overall conversation climate during the focus group interview, posing a risk of reporting bias, where certain opinions are given preference while others may be overlooked.
The coding scheme presented here was developed as a user-friendly guide for identifying specific interactions in the focus group data and how to code them with symbols. To enhance its usability, it was simplified during the development process, but it still includes interactions essential to acknowledge when leveraging participants’ interactions for focus group data analysis (Kitzinger, 1995; Kreuger & Casey, 2014; Myers, 1998; Stevens, 1996; Wilkinson, 1998c). Marking interactions with symbols allowed them to be a part of the meaning units, enabling a systematic integration of interactions into the data content throughout the thematic analysis and presentation of the results.
The structured process, designed to ensure a thorough analysis of the interactions throughout the STC analysis, required additional work. However, we argue that it is essential to put the necessary time into the analysis and that this structured way of analyzing participants’ interactions strengthened the credibility and dependability of the study. Although tested using the Systematic Text Condensation method, the coding scheme is a tool to identify focus group interactions that might be used with other thematic analysis methods.
Quality Aspects of the Focus Group Data Required when Using the Coding Scheme
The use of the coding scheme requires high-quality transcripts with markings of, e.g., pauses, laughter, and participants interrupting each other, as described by Myers (1998). This is especially important to increase the possibility of identifying the interaction engagement. In the test of the coding scheme on other interview data the first author did not identify the quotes were increased energy consistent with engagement (E) was present. In this case the second author had been present in the focus group discussion and could “hear” the participants’ voices through the transcripts. This emphasize the importance of adding information about increased energy and emotions to the text before coding of interactions are conducted. Additional possibilities to increase the quality of interaction coding are to have transcripts where body language is annotated, having moderated, or observed the focus group discussion oneself, or listening to the original audio files, when uncertainties arise about interactions.
Rich interview material is also a prerequisite for the coding scheme to be useful. When analyzing focus group discussions where respondents are reluctant to share their opinions and the level of interaction is low, the use of the coding scheme may feel redundant. It is also important to consider that the coding scheme should be helpful to researchers and not be perceived as a burden. For example, if the symbols in the coding scheme are perceived as illogical, they can of course be replaced with other symbols or the interaction can be marked in the meaning units with the title of the identified interaction or in any other way that suits the individual researcher. Furthermore, researchers may have already developed their own systems for analyzing focus group interaction. In this case, we hope that our system can inspire further development of systematic coding and analysis. We also think that the current coding scheme can be useful as guidance and inspiration for researchers who are not used to analyzing focus group interactions as too often focus group data are presented as simply a description of their content, not paying attention to the interaction that took place to create that data.
Furthermore, not all interactions in the code scheme may be identified in a focus group interview material, as what emerges depends on the conversation and the interactions in the current group. In the data we used, no case of silencing of any topic was identified. However, we think it is important to include in a coding scheme because it is an interaction of value to carry forward in a meaningful unit, if it occurs. In such a case, it is of interest in the synthesis of results to describe the occurrence of a topic or opinion that other participants actively avoided talking about further. Kitzinger (1995) gives the example of a focus group discussion where older people discussed long term residential care and ”some residents tried to prevent others from criticizing staff—becoming agitated and repeatedly interrupting with cries of ‘you can’t complain’; ‘the staff couldn’t possibly be nicer.’” (Kitzinger, 1995).
In the focus group data that were used to test the coding scheme, there were plenty of interactions, which is a prerequisite for its use. The coding scheme seems to be particularly useful in analysis of focus groups were the transcribed data may contain long sequences of, for example, agreement or disagreement that just are affirmative reactions without any more actual content. With the support of the coding scheme, these parts can be removed when replaced by a symbol for the interaction, thus making the meaning units more compressed and easier to sort. We also think the coding scheme might be useful for focus group discussions that aim to explore complex topics, leading to extensive discussions and interactions between the participants, regarding definitions and requiring differentiating and elaborating others’ statements.
Conclusion
The developed coding scheme provides a systematic method for identifying interactions among participants in focus group interviews. Using symbols to mark the interactions in the text enables researchers to further analyze and report them alongside the participants’ spoken thoughts and opinions. The coding scheme was perceived as useful by the researchers testing it and resulted in a high agreement between the two coders.
Although the coding scheme was tested using the Systematic Text Condensation method, it is a tool for identifying focus group interactions that might be used with other thematic analysis methods.
Supplemental Material
Supplemental Material - How to Analyze Focus Group Interactions – Development of a Coding Scheme
Supplemental Material for How to Analyze Focus Group Interactions – Development of a Coding Scheme by Veronica Hermann, Fatumo Osman, Natalie Durbeej, Ann-Christin Karlsson and Anna Sarkadi in International Journal of Qualitative Methods
Footnotes
Acknowledgements
The authors would like to express their sincere thanks to the young people who participated in the two interview studies from which the data was collected
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was funded by Planeringsrådet Gotland at Uppsala University [19-10-28 §5, 2019], Länsförsäkringar Gotland [19-12-16 #11 §139, 2019] and Region Gotland [RS2020/663, 2020].
Data Availability Statement
Imposed by the Swedish Ethical Review Authority, the authors do not have permission to publicly share data due to ethical restrictions since the data can potentially contain sensitive and identifying information. Data are available upon reasonable request and approval from the Senior Registrar Clerk at Uppsala University. Interested researchers may contact the Uppsala University (
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.