
Abstract
In this research, a statistical classification algorithm based on sparse coding is presented to classify the defects on E-glass fiber fabrics adaptively. First, all images are preprocessed by being convolved with the MR8 filter banks to obtain the filter responses. For the filter response space of each type of image, we will learn a Class-specific dictionary, and all the Class-specific dictionaries are concatenated to form a complete dictionary. Then, the reconstructed contribution rate of each atom of the complete dictionary to the image filter response is counted to obtain two types of histogram features of each image. Finally, the improved sparse representation classification is used to classify test defect images based on the histogram features. The proposed adaptive classification method has achieved an average classification accuracy of 96.67% on the dataset collected onsite. The results validate the superiority of the proposed method to E-glass fiber fabrics.
Keywords
Introduction
Glass fiber is formed when thin strands of silica-based or other formulation glass are extruded into many fibers with small diameters suitable for textile processing. 1 The most common type of glass fiber used in fiberglass is E-glass; E-glass (“E” because of initial electrical application) is alkali free and is the first glass prescription used in continuous filament formation. It now composes most of the fiberglass production in the world. The E-glass fiber fabric is the basic material of the copper clad laminate (CCL), which is the basic material of the printed circuit board (PCB). 2 Any presence of fabric defects in the CCL causes change in the electronic properties that might cause failure to the PCB. Using remedies to repair these defects will increase the processing time and costs. Classifying E-Glass fiber fabric defects is crucial for detecting any undesired defects in the produced part and for avoiding corrective actions. Therefore, early defects classification is critical. 3
In most cases, the quality inspection of fabrics is carried out by visual inspection performed by human inspectors on some appraisal equipment, which will lead to the subjective error of the human inspectors in the classification task, thereby reducing the fabric quality. In recent years, with the development of machine learning, various methods have been applied to the classification of fabric defects. Jing et al. 4 have extracted the texture defect from the regular texture by the Gabor filters and classified defects using local binary patterns and Tamura method, which have a good performance for fabrics with obvious texture. Mottalib et al. 5 focused on classifying fabric defects based on geometric features of defects, which leads to the problem of poor generality. Kang and Zhang 6 have proposed to incorporate the idea of the integral image into the Elo-rating algorithm(IIER), so that various fabric defects can be quickly detected. The generality of the algorithm for the identification of various types of fabric defects was confirmed in the final experimental stage.
Recently, sparse representation has shown great capabilities in handling problems such as audio processing, 7 data expression, 8 column selection, 9 emotion recognition, 10 face recognition, 11 , 12 image compression, 13 image denoising, 14 color image representation, 15 image super-resolution, 16 medical imaging, 17 motion segmentation 18 and data segmentation, 19 image classification, 20 and texture analysis. 21 In these models, an input testing image or signal is encoded as a sparse linear combination of dictionary or training sample. Although sparse representation has a good performance in applications where the primary target is to reconstruct original signals or images as accurately as possible, such as in image expression, denoising, and coding, it is not the final goal in classification tasks as discriminating signals or images is more important here. 22
There is a new type of skill that applies label information in computing coefficients or dictionary, which is called supervised dictionary learning and sparse representation (S-DLSR). 23 According to Gangeh et al., 23 S-DLSR methods can be categorized based on the following six criteria. (1) Learning one dictionary per class. The learning method can be either K-means 21 or metaface. 24 (2) Unsupervised dictionary learning (DL) followed by supervised pruning. 25 , 26 (3) Joint dictionary and classifier learning. 27 In this method, the dictionary and the classifier parameters are learned in a combined optimization problem. (4) Embedding class labels into the learning of dictionary. 28 , 29 (5) Embedding class labels into the learning of sparse coefficients. And (6) learning a histogram of dictionary atoms over signal or image constituents. 21 Wright et al. 11 have proposed a general classification algorithm for face recognition based on sparse representation computed by l1-minimization. Xu et al. 30 have improved the method 11 using the mathematically tractable l2 regularization rather than the l1 regularization, for which almost has a closed-form solution. And it is pointed out in Gangeh et al. 23 that the main drawback of the method in Wright et al. 11 is that they may cause a very large dictionary, as the size of the joint dictionary grows linearly with the number of classes.
The texton-based method31–33 is one of the original methods which compute the histogram of dictionary atoms (textons) to model a texture image based on patches extracted. In this method, first learn a dictionary and then construct the histogram features using the training images. Varma and Zisserman 32 model the image textures by the frequency histogram of filter response cluster centers (textons). In this method, supervised k-means was used to acquire the cluster centers to construct the dictionary. To compute the textons histogram, each patch was represented by the closest atom in the dictionary. This is the possible maximum sparsity as each patch is represented by only one dictionary atom. 23 The method 34 computes the dictionary and the corresponding sparse coefficients over the feature extracted from an image, and the ultimate classification task is to classify the whole image, not the patches in the previous methods. Therefore, the method is suitable for fabric defect classification.
Inspired by above researches, a novel feature extraction and classifier design is developed for effective defect classification. Representative features are extracted from the defect image by computing a histogram of dictionary atoms, and the adaptive sparse representation classification (SRC) classifier is used to classify defect images. The rest of the article is organized as follows: section “Brief introduction of SRC” presents the SRC. Section “The developed classification method for E-glass fiber fabric defects” introduces in detail the classification algorithm of E-glass fiber fabric defects. Section “Experimental evaluation” conducts extensive experiments, and section “Conclusion” concludes the article.
Brief introduction of SRC
SRC is one of the original DL methods used for face recognition, in which all training images of class i are viewed as class-specific dictionary
The SRC method is primarily divided into two steps: sparse coding and classification.
Sparse coding. The unknown test sample y
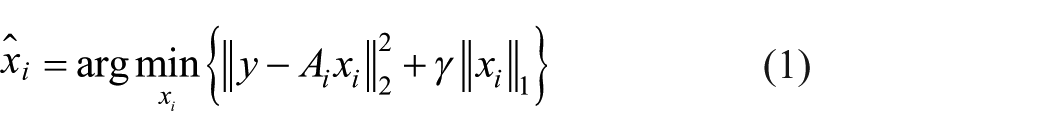
where
2. Classification. Sample y is then assigned to class i by minimizing the residual between y and its approximation

where
The developed classification method for E-glass fiber fabric defects
In this section, we introduce the proposed defect classification method in detail. There are two major components in the proposed approach: image feature acquisition and classification.
Image feature acquisition
The picture collected from cooperative enterprise may be affected by various factors such as the intensity of light, the camera, or the surface of fabrics, and the image should be preprocessed first. All training images are convolved with the MR8 filter banks, and each image will acquire a filter response space where each filter response corresponds to a pixel which makes a large contribution to the defect image. Then, a complete dictionary was constructed by combining all class-specific dictionaries which were learned from filter responses of each defect. Finally, histogram features of each defect image are learned for complete dictionary atoms over filter response. This section mainly includes two parts: class-specific DL and the generation of histogram features.
Class-specific DL. There are only six types of defects in the dataset, and we could learn a sub-dictionary per class (i.e. class-specific dictionary) without considering the problem of large dictionary size. Sparse representation is used to learn class-specific dictionary in our method. Assume there are C defects. C class-specific dictionaries for C defects can be learned, as shown in Figure 1. First, filter responses of each defect are clustered together, and an appropriate dimension reduction processing is performed to obtain a filter response matrix per class. And then the sparse representation of the matrix Yi is used to learn a class-specific dictionary Ai for class i. The DL model is as follows

where
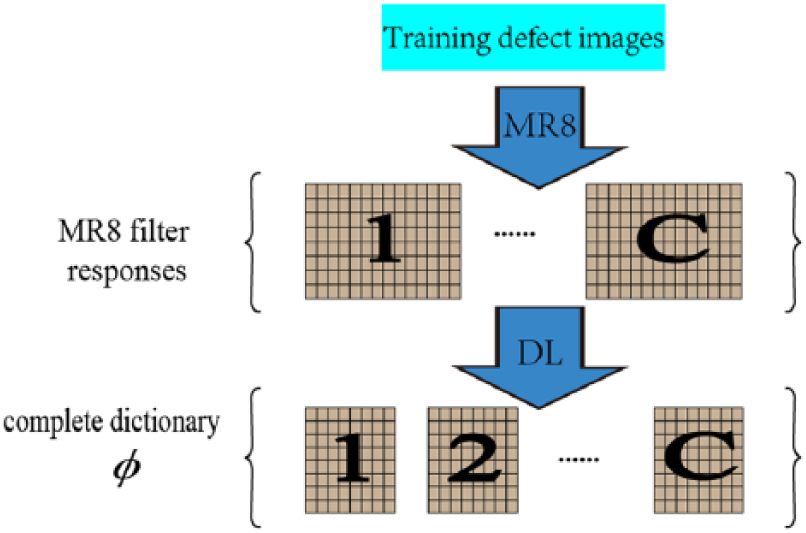
Class-specific dictionary acquisition.
For the DL model, the solving process primarily includes sparse coefficient solution and dictionary updating. The sparse coefficient matrix Xi is obtained using the Matching Pursuit (MP) algorithm, 35 and the dictionary Ai is updated by the K-SVD algorithm 36 to obtain a new dictionary which can express the matrix Yi better, the two processes are iterated until the iteration conditions are met to acquire the final class-specific dictionary.
2. Feature description. A class-specific dictionary can be learned for each defect using the DL model in the previous section, and all class-specific dictionaries are concatenated into a complete dictionary

where
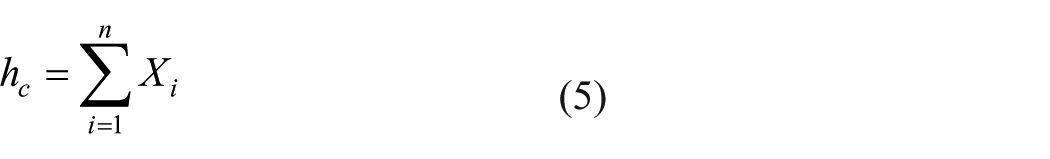
where n is the number of pixels that contribute significantly to the defect image, and the coefficient histogram

where
Two feature histograms of different class defect images are shown in Table 1. We can see that the two histogram features of the same defect images are almost the same; however, the two histogram features of the different defect images are obviously different. In addition, both class feature histograms also differ in the same defect image, which indicates that the two types of histogram features are complementary to the representation of fiberglass defects.
Histogram features obtained from different defect images.

Classification
Two histogram features hc and hr are extracted for all test images. In the SRC, replace all the images with histogram features of all images to complete the classification. In the method by Xu et al.,
30
the robustness and computational efficiency of the l2 regularization-based representation method have been proved. We apply the l2 regularization-based representation method to SRC. In detail, we assume that there are C defects and each defect has w defect images. Histogram features of ith class training sample are used to construct two kinds of class-specific dictionaries

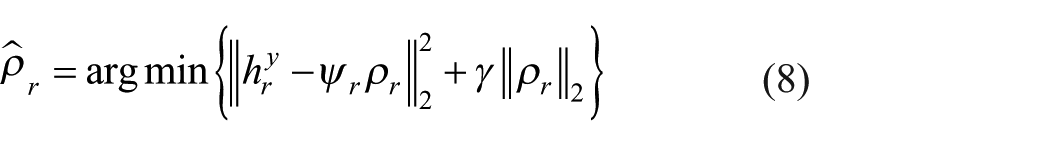
where


Equations (9) and (10) can be written as:
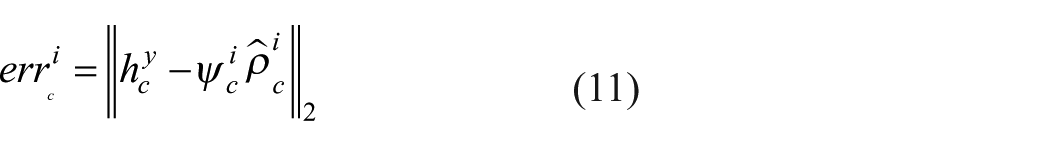

Apply equations (11) and (12) to calculating two reconstruction errors of the histogram feature of the test image y over each class-specific dictionary
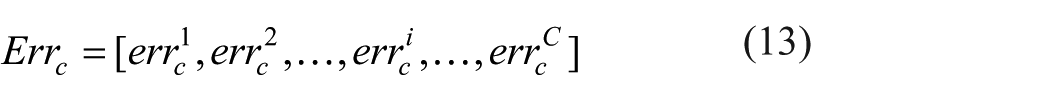
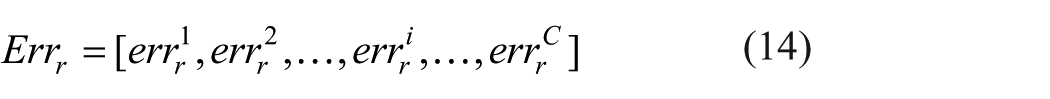
We have found that both histogram features are discriminative and complementary to the image defects from Table 1, therefore the test image y will be classified by the weighting average method


where

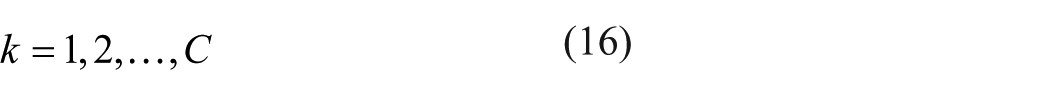
Experimental evaluation
There are few researches on the classification of E-glass fiber fabric defects. The main difficulty for defect classification is the lack of publicly available datasets. We tried to provide a dataset containing the major defects of E-glass fiber fabric in order to facilitate the development of future algorithms. To create the dataset, the ccd camera with 4k pixels is used to actually collect the defect image in the factory. There are four primary types of E-glass fiber fabric defects: edge, broken warp, double weft, and pilling. We conducted a practical investigation on the E-glass fiber fabric defects in the factory and found that the above four defects accounted for about 85% of all defects, and remaining defects were messy and difficult to distinguish. To enhance the effect of the experiment, the shading and defect-free (normal) on the fabric were also considered as two classes. Therefore, the image dataset includes six classes, as shown in Figure 2. In this experiment, there are 120 images for each defect and every image size is set to 220*80.

Six class fiberglass fabric defect images: (a) edge, (b) broken warp, (c) double weft, (d) pilling, (e) shading, and (f) defect-free.
All experiments were conducted in a MATLAB R2014b environment on a desktop PC with a 3.2GHZ quad-core Intel processor and 8G memory. 30, 40, 50, 60, 70, 80, 90, 100, and 110 images are randomly selected to form the training dataset, and for each setting, the experiment was run 20 times and the average classification accuracy is recorded. At the stage of DL and sparse coding, the parameter λ in equations (3) and (4) are both set to 0.5. In the process of adaptive dictionary encoding, the adaptive dictionary atom number is set to 7 because the pixel feature vector is eight-dimensional.
In the process of classification, when 30-110 were used as training sample numbers for each defect, separately, the weight for two reconstruction errors were 0.05, 0.05, 0.05, 0.35, 0.85, 0.25, 0.25, 0.85, and 0.95.
Evaluation of the proposed method
In order to verify again that two types of histogram features are complementary for the expression of defect images, all errors, containing errc, errr, and errf, are used to classify the test defect images. The classification results are shown in Figure 3. It can be seen from the figure that it is obviously much better to classify the test image by

Different reconstruction error classification accuracy.

For images (a) broken warp and (b) defect-free, due to the fact that the defects in the radial direction of the defect image are even hardly distinguished by the human eye, the two types of images are easily misclassified by the proposed method.
Comparison evaluation
The proposed method is first compared with the SRC method. The experiment draws the defect classification accuracy of the two methods by constantly changing the number of training samples. The classification results are shown in Figure 5. The experimental results show that the proposed method is more suitable for E-glass fiber fabric defects than the traditional SRC method, and it is verified that the dictionary obtained from the image histogram feature is better than the dictionary constructed directly from the training image.

Classification accuracy of SRC and proposed method with different training samples.
Then, we compare the proposed method with three popular classification methods: random forest (RF), 37 K-nearest neighbor (KNN), 38 and support vector machine (SVM). 39 As the number of training samples increases, the classification accuracy of each classification method will become higher. All classification methods adopt the histogram features proposed in the paper as image features. The classification accuracy of different classification methods with different training samples is shown in Figure 6. We can see that the proposed method has advantages over the popular classification methods in different training samples.
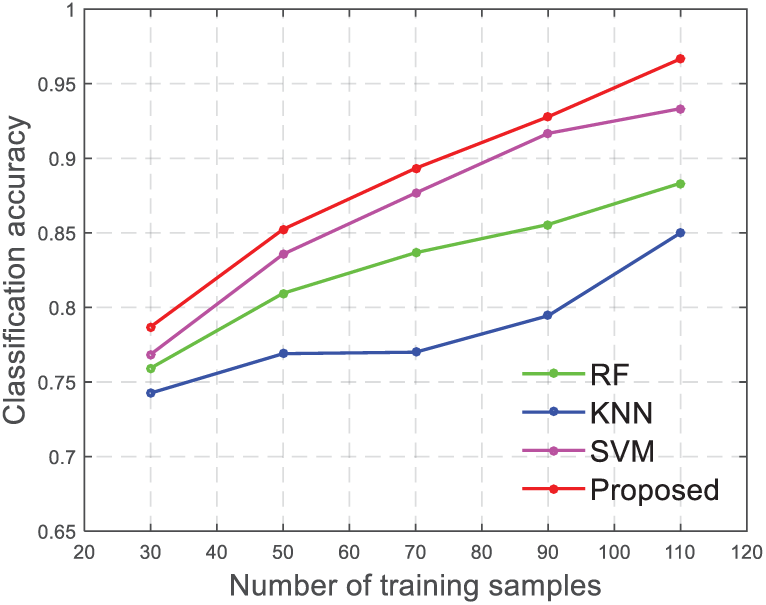
Classification accuracy of different methods in different training samples.
The classification accuracy of all classification methods was listed in the table when the classification sample is 110, as shown in Table 2. Obviously, the application of the proposed method in the classification of E-glass fiber fabric defects shows a very good advantage.
Classification rates by different methods when the number of training samples is relatively large.

RF: random forest; KNN: K-nearest neighbor; SVM: support vector machine.
In the actual factory, the classification speed for image defects is very important and has a serious impact on plant efficiency. We compared the average running time of above methods. All training samples used in the comparison experiment were 110 and the average running time is shown in Table 3. Although the proposed method is not the fastest, the proposed method is adaptable to the classification of E-glass fiber fabric defects due to its good classification accuracy.
The average running time for different classification methods when the training samples number is 110.

RF: random forest; KNN: K-nearest neighbor; SVM: support vector machine.
Conclusion
In this article, we have proposed an improved statistical classification method for the E-glass fiber fabric defects. The actual image is preprocessed by the MR8 filter bank to suppress the large changes that may appear in the image. And the sparse representation is applied to the histogram features acquisition, which enhance the ability of the histogram feature to characterize the defect image. In the classification stage, we have improved the SRC classifier using l2 regularization-based representation method to achieve the classification of the defect image. The experimental results confirm the superiority of the proposed method. At the same time, in order to solve the problem of less available databases, three Basler line array cameras were used to image the fabric with a width of 1.8 m under the transmission of OPT’s line light source when the fabric inspection machine runs at 80 m/min. The camera model is raL4096-24gm with a 35 mm Nikon lens, and the camera is mounted at a height of 0.7 m and the corresponding width of a single camera is 0.574 m. A more consistent dataset was obtained under the device. In future work, we will study how to use a smaller number of training samples to achieve high classification accuracy.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.