
Abstract
This mixed methods study investigates the use of natural language processing (NLP) to analyze sentiment and predict interpretation errors in bilingual court interpreting, focusing on Mandarin-English remote hearings. We assembled a dataset of 3,250 minutes of courtroom recordings and 192,465 utterances, annotated for sentiment and error types. Our methodology combines transformer-based sentiment analysis with Conditional Random Fields and Support Vector Machines for error prediction, leveraging linguistic features such as discourse markers, hedging devices, and textual tonal cues. Sentiment analysis reveals that domain-specific fine-tuning of transformer models captures subtle emotional shifts in lawyer questioning with high accuracy, yet interpreters frequently omit critical markers and tonal signals, diluting intended rhetorical force, particularly during cross-examination. Error prediction shows that simultaneous interpretation incurs significantly higher omission and distortion rates than consecutive interpreting, and that aggressive questioning markedly increases error likelihood. This research integrates quantitative NLP modeling with qualitative discourse analysis, offering insights into cognitive and pragmatic factors that affect interpretation fidelity. By highlighting patterns of sentiment shift and interpreter error, our findings inform targeted training and technological interventions aimed at promoting linguistic equity and procedural fairness in multilingual judicial contexts. This article contributes to mixed methods methodology by (i) specifying an explanatory sequential design in which quantitative error metrics and sentiment modeling purposively inform reflexive thematic analysis of interpreter accounts, and (ii) offering a joint display that integrates Quantitative patterns (e.g., omission rates by mode × tone) with Qualitative themes (e.g., cognitive load management and discourse-marker decisions), thereby illustrating how integration at interpretation yields inferences unattainable by monomethod designs.
Keywords
Introduction
Language serves as the cornerstone of legal systems, shaping every aspect of judicial processes, from legislation to courtroom interactions. In multilingual societies, effective language interpreting services become essential to ensure procedural fairness, the fundamental right of all participants to access and engage with legal proceedings equitably. However, interpreting legal discourse is fraught with challenges, particularly in high-stakes courtroom settings where language is not only a medium of communication but also a tool of persuasion, strategy, and power (Berk-Seligson, 2017; Hale, 2004). This study investigates the integration of natural language processing (NLP) techniques in legal interpretation, focusing on sentiment analysis and error prediction as tools to address these challenges and enhance fairness in multilingual judicial systems.
Language interpreting services in legal settings extend beyond the mere translation of words; it requires preserving the pragmatic intent, emotional tone, and cultural nuances embedded in the original discourse (Eades, 1995, 2008, 2010; Yi, 2026b). A lawyer’s carefully calibrated questioning, for instance, may include skepticism, confrontation, or persuasion to achieve specific rhetorical goals (Gibbons, 2003, 2018; Olsson, 2008; Solan, 2010; Solan & Tiersma, 2005, 2012). Any misrepresentation or omission of these elements by interpreters can distort the intended meaning, potentially influencing the outcome of a trial. This issue is particularly pressing in technology-empowered remote hearings, where interpreters face additional challenges, such as managing audio-visual limitations and heightened cognitive loads.
The Context of the Study
Language diversity is a hallmark of human civilization, yet it remains under threat in many institutional contexts, including legal systems. Protecting linguistic diversity while ensuring equal access to justice is not merely an ethical obligation but also a legal mandate enshrined in international treaties such as: • •
In Australia, the right to a fair trial is a cornerstone of the legal system, supported by both statutory and common law provisions. The
Courtroom interpreting is uniquely challenging due to the high-stakes nature of legal discourse. Interpreters must navigate complex linguistic and pragmatic demands, including:
Emotional and Pragmatic Accuracy
Legal discourse often involves emotionally charged language, such as skeptical cross-examinations or persuasive closing arguments (O’Barr, 2014; Mikkelson, 2000; Morris, 1998). Interpreters must accurately convey these tones to maintain the original speaker’s rhetorical intent (Liu, 2020; Yi, 2025).
Cultural and Linguistic Nuances
Terms like “probable cause” or “subpoena” often lack direct equivalents in other languages, making it challenging for interpreters to preserve their legal and cultural significance (Hale, 2007; Lee, 2015). Such nuances are further complicated in multilingual settings where multiple legal traditions intersect.
Advancements in NLP offer transformative potential for addressing the challenges of courtroom interpretation. In this study, “error prediction” refers specifically to the automatic identification of errors made by human interpreters, such as omissions, distortions, or misalignments during courtroom interpretation, rather than prediction errors from the NLP models themselves. Sentiment analysis and error prediction, as applied in this study, represent two critical areas where technology can support interpreters and enhance procedural fairness:
Sentiment Analysis
By analyzing emotional tones in lawyer questioning, NLP tools can help interpreters identify and preserve pragmatic elements such as skepticism, persuasion, and confrontation. For example, transformer-based models like BERT and RoBERTa, fine-tuned on bilingual courtroom transcripts, can detect discourse markers and tonal shifts that are critical to the speaker’s intent.
Error Prediction
Machine learning models, including conditional random fields (CRFs) and support vector machines (SVMs), enable identification of interpreter errors. These tools can flag omissions, distortions, and cultural misalignments, providing interpreters with dynamic feedback to improve accuracy during live proceedings.
Sentiment analysis and error prediction, as applied in this study, represent two critical areas where technology can support interpreters. The integration of these tools into interpreter training programs and courtroom systems holds significant promise for improving legal interpreting practices. By offering data-driven insights and automated support, NLP technologies can contribute to reducing trial delays, enhancing the fidelity of interpretations, and supporting procedural fairness in multilingual judicial settings.
Research Aims and Objectives
This study builds on foundational research in discourse analysis and NLP, combining theoretical insights with practical applications to advance the field of legal interpreting. The key objectives are to:
Examine Sentiment Shifts in Bilingual Courtroom Discourse
By analyzing interpreted lawyer questioning, the study sheds light on how emotional tones are preserved, amplified, or neutralized during interpretation. This analysis provides critical insights into the role of sentiment in shaping courtroom dynamics and influencing jury perceptions.
Identify Patterns and Predictors of Interpreter Errors
Through error prediction analysis, the study explores the linguistic and pragmatic factors contributing to omissions, distortions, and other errors in courtroom interpretation. The findings inform targeted interventions to enhance interpreter training and performance.
By highlighting the practical dimensions of deploying NLP tools in judicial contexts, this research aligns with global efforts to promote equitable legal systems. It calls for interdisciplinary collaboration between linguists, technologists, and legal professionals to create solutions that are not only technologically advanced but also culturally and ethically informed. As legal systems increasingly adopt remote hearings and other technology-mediated processes, the need for robust interpreting solutions becomes ever more urgent. This study situates itself at the forefront of this evolving landscape, demonstrating how NLP can enhance interpreter performance, reduce errors, and uphold the principles of justice and equity. By bridging the gap between linguistic theory and technological innovation, the research offers a roadmap for integrating NLP into legal interpreting, ensuring that procedural fairness and linguistic diversity remain central to the administration of justice.
The Study
Setting the Scene: Literature Review
The integration of artificial intelligence (AI), particularly natural language processing (NLP) and machine learning (ML), has significantly advanced the field of Legal Sentiment Analysis and Opinion Mining (LSAOM), enabling nuanced insights into the emotional and opinion dynamics within legal discourse. Alarie et al. (2016, 2018) illustrate how machine learning optimizes regulatory systems by refining legal decision-making. Similarly, Wyner, Mochales-Palau, and Moens (2010) demonstrate how text mining and context-free grammars can be applied to extract arguments from legal cases, showcasing the potential of automated reasoning in legal contexts. Liu and Chen (2018) introduce a two-phase sentiment analysis approach tailored for judgment prediction, illustrating how precedents can be systematically analyzed to predict legal outcomes. Conrad and Schilder (2007) emphasize the utility of opinion mining in legal blogs, providing early baselines for understanding subjective and objective expressions in legal narratives. Moreover, Zhong et al. (2018) leverage topological learning for legal judgment prediction, underscoring the role of advanced algorithms in modeling complex legal structures. Collectively, these advancements demonstrate the transformative potential of AI in augmenting LSAOM capabilities, paving the way for more robust applications in areas like e-discovery, judicial decision-making, and regulatory compliance.
Additionally, the integration of AI has illuminated biases in legal practices, including jury selection. O'Brien et al. (2017) adapted conversation analysis (CA) to analyze voir dire transcripts, revealing how racial bias influences juror questioning and decision-making. By adapting the Roter Interaction Analysis System (RIAS) for the legal context, the study analyzes 792 potential jurors in twelve death penalty trials, identifying racial disparities in how potential jurors are questioned and assessed. Methodologically, every utterance during voir dire was coded for tone, content, and interaction type. Findings reveal systematic differences in how potential jurors of different races are questioned and assessed, with Black jurors more likely to face leading questions or conflict-laden exchanges. These disparities, whether conscious or unconscious, highlight how voir dire may perpetuate racial bias in jury selection, undermining fairness and impartiality. This aligns with Vidmar and Hans’s (2007) emphasis on systemic structures influencing jury compositions. Tools like RIAS allow researchers to quantitatively and qualitatively explore nuanced conversational dynamics, uncovering implicit biases in legal processes and advancing systemic equity. Together, these findings underscore the transformative potential of combining computational and qualitative methods to address systemic inequities in the legal system (Roter & Larson, 2002).
Moreover, recent advancements in AI also resonate with the concept of affective arrangements (Slaby et al., 2019), offering a framework for analyzing relational dynamics in legal texts. Studies such as Bens (2020), Richardson and Schankweiler (2019), and Bacchus et al. (2018) explore how courtroom dynamics are influenced by non-human witnesses, such as video evidence or textual artifacts, and how these affective elements shape legal narratives. For example, Schirmer et al. (2023) demonstrate the utility of combining NLP, sentiment analysis, and qualitative methods to analyze genocide-related witness statements, identifying critical differences in how detainees and interrogators recount torture experiences pertaining to speech patterns, emotional content, and contextual references. Using transcripts from the Khmer Rouge Tribunal, the study focuses on the testimony of two distinct groups: detainees who experienced torture and interrogators who applied it. The findings highlight that detainees primarily focus on personal emotional experiences, while interrogators adopt a factual and technical tone in their accounts. Another example is ethnographic research conducted by Bens (2020) who explores how affect operates in courtroom witnessing, redefining it as a relational dynamic that extends beyond traditional human testimony to include non-human entities, such as video evidence or textual artifacts. The study focuses on understanding how courtroom participants modulate affective arrangements to shape legal narratives. Using ethnographic observations from international criminal trials, the research highlights the strategic use of unemotional presentations by prosecutors to manage the legitimacy of evidence and the incorporation of cultural narratives by defense attorneys to challenge the prosecution’s affective framing. The analysis underscores that affective dynamics and sentiment analysis are not just peripheral but central to the process of truth-making in legal proceedings, extending beyond conventional displays of emotion. This approach complements findings from Ciorciari and Heindel (2016), who examine the psychological challenges of recounting trauma in legal settings. These studies show how computational methods can complement qualitative insights, paving the way for more comprehensive analyses of complex legal testimonies, particularly in sensitive contexts such as genocide tribunals.
Despite these advances, human interpreter-mediated courtroom interactions remain under-explored. Legal interpreters engage in complex meaning negotiation activities between linguistic accuracy and pragmatic fidelity, affecting how jurors or the judge perceive tone, intent, and power dynamics (Yi, 2024).
Sentiment analysis and error prediction have emerged as essential tools for understanding and improving courtroom dynamics, particularly in bilingual and multilingual legal environments. These methods are grounded in theories of language use, such as Speech Act Theory (Searle, 1969) and Relevance Theory (Sperber & Wilson, 1986), which emphasize how utterances function beyond their literal meanings, especially in high-stakes legal contexts.
Sentiment analysis, widely used in marketing and customer feedback studies, has gained traction in legal NLP for its ability to uncover emotional undertones and strategic intent in lawyer questioning. Legal discourse is characterized by diverse sentiment markers embedded in adversarial tones, skepticism, and directive speech acts, all strategically employed to influence witness credibility and jury perception (Wagner & Matulewska, 2023). In particular, research into court proceedings mediated by human interpreters (see Yi, 2024) indicates that emotional variability during cross-examinations, particularly the use of heightened tones, correlates with strategic courtroom outcomes. However, the challenge of accurately capturing these sentiments and tones in multilingual contexts remains largely unexplored.
Similarly, error prediction analysis has been applied in machine translation and automated transcription to identify systemic issues in linguistic output. In legal settings, interpreting errors such as omissions, substitutions, and distortions can significantly alter the trajectory of a trial (Berk-Seligson, 2017). Studies on courtroom interpreting emphasize that simultaneous interpreting (SI), due to its constraints, is more prone to cognitive overload and linguistic inaccuracies than consecutive interpreting (CI) (Pöchhacker, 2022). Despite these insights, there is limited research on using NLP models to identify and address interpreter errors dynamically.
Emerging technologies, particularly Transformer-based models like BERT and RoBERTa, have shown promise in sentiment analysis by capturing contextual embeddings with high precision (Devlin et al., 2019). These models have been fine-tuned for domain-specific tasks, including legal text classification and semantic role labeling. On the other hand, conditional random fields (CRFs) and support vector machines (SVMs) are widely recognized for their effectiveness in sequence labeling and feature-based classification, making them suitable for error prediction tasks in interpreting studies (Lafferty et al., 2001).
The Emergence of Prompt Engineering in Legal NLP
While much of the prompt-engineering literature targets sentiment or task-specific factuality, legal questioning often turns on textual tone (pragmatic coloring) signaled by discourse markers, hedges, intensifiers and stance verbs. We therefore treat textual tone as a text-based construct (not acoustic) that can be made legible to models through engineered features and, by analogy, through prompt components. Recent advances in natural language processing (NLP) have significantly expanded the methodological landscape for legal discourse analysis. In particular, Transformer-based architectures, such as BERT and RoBERTa, have enabled domain-adapted models to capture context-sensitive linguistic patterns within legal texts, ranging from statutory interpretation to courtroom questioning. Numerous reviews have consolidated progress in this area.
However, a notable gap in prior literature involves the under-representation of prompt engineering, a rapidly developing subfield that has proven critical for optimizing interactions with large language models (LLMs). Prompt engineering refers to the design of input queries that guide LLMs toward producing more accurate, context-sensitive, and task-relevant outputs. While this technique has received limited attention in legal NLP, its importance is underscored by recent meta-analyses and technical studies across disciplines.
For example, Ye et al. (2023) demonstrate how LLMs can dynamically tutor users to iteratively improve prompts, effectively transforming the model into a learning facilitator for prompt optimization. Chen et al. (2023) provide a structured taxonomy of prompting strategies, such as zero-shot, few-shot, and chain-of-thought prompting, that enhance LLM reasoning and task alignment across diverse NLP domains. Marvin et al. (2024) further emphasize the cognitive and structural design considerations of prompt engineering, offering detailed insights into how prompt format, semantic clarity, and output framing directly influence model behavior and explainability, factors highly relevant in the interpretative nuances of legal texts.
In applied contexts, Ronanki et al. (2025) develop domain-specific prompt templates for requirements engineering tasks, underscoring the reproducibility and consistency of outputs through prompt calibration. This methodology aligns with structured annotation and classification tasks often found in legal domains. Similarly, Velásquez-Henao et al. (2023) propose the GPEI (Goal, Prompt, Evaluation, Iteration) framework, which formalizes iterative refinement strategies in engineering applications and can be adapted for domain-specific NLP systems.
Prompt engineering has also been used to address fairness and bias detection. For instance, Siino and Tinnirello (2024a) apply prompt strategies to identify sexism in English and Spanish tweet corpora, showing that prompt structure, such as embedding explicit task instructions and few-shot examples, can improve classification performance. This significantly improves classification accuracy. Wang et al. (2024) complement these findings by showing how prompt design can enhance consistency and factual grounding in evidence-based clinical NLP tasks, reinforcing the role of prompt engineering in contexts like legal argumentation, where interpretive precision and evidence alignment are crucial.
Moreover, prompt engineering has been successfully applied to hallucination detection. In fact-checking settings, Siino and Tinnirello (2024b) use a few-shot prompting strategy with a prompt-engineered input format to select the hallucinated hypothesis in a paired-output setup, improving reliability in identifying nonsensical or ungrounded content. These mechanisms are especially valuable in legal contexts where factual errors may have high-stakes consequences.
Beyond purely linguistic applications, prompt engineering has also shown utility in hybrid reasoning tasks. For instance, Siino and Tinnirello (2024c) apply prompt-driven interfaces to schedule residential appliances for energy cost optimization by integrating LLMs with external solvers. This approach highlights how LLMs can be adapted through prompts to interact with formal rule-based systems, a paradigm that may be extended to statutory compliance checking or regulatory inference in legal NLP.
Although the present study does not directly employ generative LLMs, our methodological approach shares core design principles with prompt engineering. Specifically, our models were guided using task-specific linguistic features (e.g., discourse markers, hedging) that function analogously to handcrafted prompts in LLM workflows. Future extensions of this work could explore integrating prompt calibration and iterative feedback loops to further optimize model performance in legal sentiment classification and interpreter error detection.
Although our study does not employ generative prompting, the handcrafted features (marker/hedge templates, stance lexicons) we use to model textual tone correspond to prompt components: task definitions (“flag omission-risk when marker and hedge co-occur under SI”), few-shot exemplars (paired source–rendition snippets), and constraints (prefer functional equivalence of discourse markers). This mapping clarifies how current findings can seed prompt templates for downstream, LLM-assisted decision support in court interpreting. Accordingly, prompt engineering is discussed here not as a method employed in the present study, but as a downstream design space for which the feature-based findings reported below offer empirically validated building blocks.
Gaps in the Literature
While significant progress has been made in sentiment analysis and error prediction, key gaps remain, particularly in the context of legal discourse and multilingual communication. First, existing sentiment analysis studies rarely focus on the adversarial nature of lawyer questioning or its strategic implications for courtroom dynamics. Emotional tones embedded in questioning, such as skepticism, aggression, or persuasion, are often diluted in interpreted discourse, yet the impact of these shifts remains under-researched.
Second, error prediction models in legal NLP predominantly address written texts, overlooking the nature of courtroom interpreting. Interpreters face unique cognitive and linguistic challenges, including managing overlapping speech, maintaining pragmatic fidelity, and navigating culturally specific terminology. Few studies have examined how NLP tools can dynamically identify and address these challenges during live interpretation.
Third, while cultural and linguistic differences are known to influence interpreting outcomes, their effects on sentiment shifts and error patterns in bilingual courtroom settings have not been systematically explored. For example, terms like “subpoena” or “probable cause” lack direct equivalents in many languages, leading to potential distortions in meaning and legal intent. The absence of robust multilingual datasets further limits the scope of cross-linguistic sentiment and error analyses.
Prior research in legal discourse has identified the strategic use of tone, particularly aggressive or skeptical questioning by lawyers, as a powerful rhetorical tool that can influence courtroom dynamics and affect how testimony is interpreted (e.g., Eades, 2010; Liu & Wang, 2023; Yi, 2023, 2026a). However, the ways in which these tonal features are preserved, distorted, or neutralized in courtroom interpretation, particularly in high-stakes multilingual settings, remain underexplored. This gap is especially salient given the increasing reliance on remote interpreting and the cognitive strain it imposes. Although studies in interpreting studies have acknowledged the impact of speech style on interpreter performance, few have quantitatively modeled such effects using linguistic and computational tools.
Furthermore, existing NLP approaches to legal discourse have largely focused on propositional content rather than the pragmatic or emotional layer of communication. As such, this study addresses a critical intersection: how emotional and pragmatic dimensions of legal questioning (e.g., tone, alignment) affect interpreter performance, and how these can be analyzed using sentiment analysis and error prediction models.
Research Questions
Building on the pragmatic concerns raised by Liu and Wang (2023) regarding how interpreters handle tonal intensity in courtroom questioning, we formulate the following research questions to investigate how such features may correlate with sentiment shifts and interpreter error patterns in bilingual courtroom discourse. To address these gaps, this study investigates the intersection of legal NLP, sentiment analysis, and error prediction in courtroom interpreting. The research is guided by the following questions:
This research contributes to the broader field of speech communication by combining theoretical insights from discourse analysis with cutting-edge NLP methodologies. By addressing the emotional and pragmatic dimensions of bilingual courtroom discourse, it bridges the gap between linguistic theory and practical applications in legal interpreting. The study also underscores the ethical implications of deploying NLP tools in judicial contexts, emphasizing the need for transparency, fairness, and cultural sensitivity.
In the following sections, the methodology outlines how the research questions are addressed through a combination of sentiment analysis and error prediction workflows.
Methodology
This section outlines the methodological framework for conducting sentiment analysis and error prediction in lawyer questioning and interpreter performance. By emphasizing precision, transparency, and reproducibility, we integrated annotated legal datasets, advanced NLP models, and robust evaluation metrics in this section. Our mixed methods design employed an explanatory sequential approach, where quantitative findings regarding interpreter accuracy in rendering the manner of speech (e.g., sentiment shifts, discourse marker fidelity) were initially collected and analyzed. These quantitative results then informed the subsequent qualitative analysis, which involved in-depth thematic coding of interpreter self-reflections and post-task interviews to explore the underlying cognitive processes and contextual factors influencing observed performance. Data integration occurred at the interpretation phase, where qualitative insights provided a nuanced explanation for the quantitative patterns, particularly regarding the challenges of cognitive load management and the impact of specific discourse markers on pragmatic transfer. For instance, quantitative analyses revealed a higher incidence of sentiment shift errors in audio-only simultaneous interpreting, which was further contextualized by qualitative data highlighting interpreters’ self-reported struggles with processing paralinguistic cues in the absence of visual input, leading to a reduced capacity for nuanced pragmatic rendering. This triangulation of quantitative performance metrics with qualitative experiential data provides a more comprehensive understanding of the phenomenon (Hastie et al., 2009; Murphy, 2012).
Data Preparation
Corpus Selection
We selected a subset of 3,250 minutes of courtroom recordings based on three primary criteria: (1) case type, focusing on criminal trials where adversarial exchanges are prevalent; (2) linguistic complexity, including sessions with rich pragmatic markers, indirect speech acts, or sentiment-laden turns; and (3) the presence of salient interactional patterns such as interruptions, turn-holding strategies, and speaker alignment, which are critical for the pragmatic analysis pursued in this study.
The linguistic characteristics of legal discourse and courtroom interaction have been extensively documented in legal linguistics (Tiersma, 1999). These courtroom recordings were derived from a purpose-built simulated trial conducted as part of a controlled simulation scenario. Unlike recordings from naturally occurring legal proceedings, this mock trial was designed by the research team in collaboration with legal professionals (judges, barristers) and NAATI-certified interpreters. The objective was to mimic authentic courtroom dynamics while maintaining control over the linguistic and pragmatic features presented. This setup allowed for ecological validity, capturing the adversarial, high-stakes nature of courtroom exchanges, while ensuring that elements like hedging, interruption, and emotional tone were systematically embedded into the source materials. All of the bilingual transcripts and annotated discourse samples used in this study were generated from this controlled simulation, providing a consistent and analytically rich dataset for subsequent sentiment and error analysis.
The dataset draws from three primary sources. First, interpreter scoring sheets provided numeric evaluations across dimensions such as accuracy, fluency, and neutrality, serving as the ground truth for supervised learning models. Second, bilingual transcripts of English-Mandarin courtroom exchanges offered sentence-aligned data rich in pragmatic markers. These transcripts captured spontaneous speech phenomena critical for our analysis. Third, we incorporated manually annotated discourse samples, labeled for sentiment polarity (positive, neutral, negative) and interpretation error types (omissions, substitutions, distortions). These three components collectively ensured both linguistic diversity and analytical depth.
Unlike conventional NLP pipelines that often discard fillers, discourse markers, and hedging expressions as noise, we retained these features as analytically salient, in line with broader discourse-analytic traditions in computational linguistics (Jurafsky & Martin, 2021). English markers such as “well,” “so,” or “now,” and Mandarin particles like “啊 (a),” “吧 (ba),” and “啦 (la)” were treated as integral data points. These markers often signal stance, speaker alignment, or discourse shifts, pragmatic phenomena that are particularly salient in courtroom interaction.
Aligning bilingual transcripts was a critical but complex step due to legal discourse’s syntactic and semantic intricacies. In this context, “alignment” refers to the process of segmenting and temporally matching the source language utterance (e.g., a Mandarin lawyer’s question) with its corresponding interpreted response (e.g., the English rendition by the interpreter) at the utterance level. This utterance-level pairing is crucial for ensuring that sentiment analysis and error prediction are grounded in precise speaker-to-interpreter mappings. We initially employed BLEU scoring and statistical alignment principles derived from machine translation research (Och & Ney, 2003) to estimate sentence-level alignment quality and then manually corrected alignments to preserve contextual and legal accuracy. Terms like “probable cause” required both precise translation and contextual fidelity to retain their legal implications in Mandarin.
Annotation Scheme
Definitions and operationalization of specialized terms used in this study
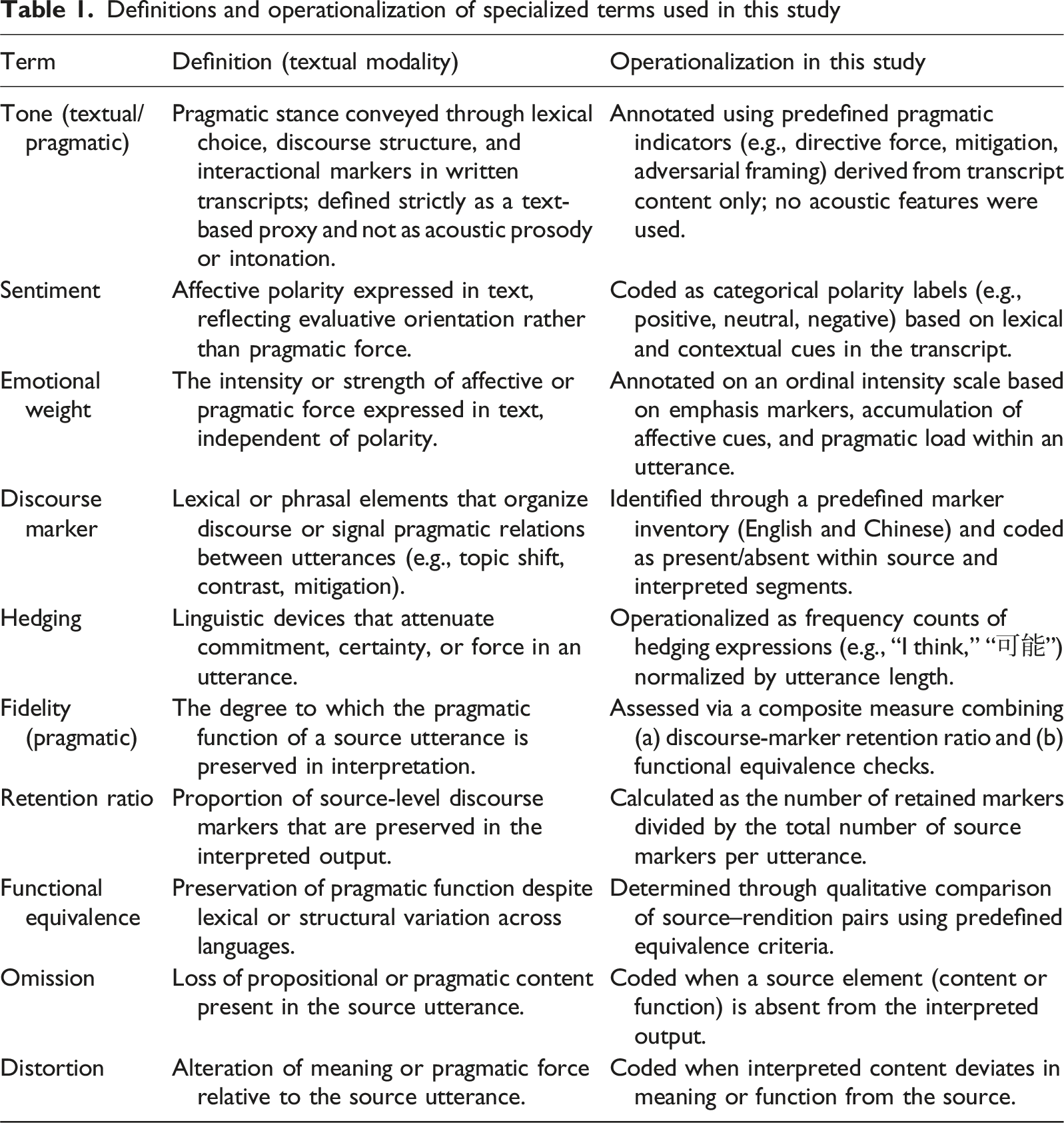
The sentiment annotation covered a range of categories beyond the standard “Positive,” “Negative,” and “Neutral” labels. We incorporated a multi-class sentiment scheme that included pragmatically salient nuanced categories such as “Skepticism,” “Overt Aggression,” “Hesitation,” and “Conciliatory.” These categories were defined in our annotation guidelines and supported by pilot training sessions. Annotators labeled utterances with a single dominant sentiment category, enabling the downstream model training task to be framed as multi-class classification.
The annotation scheme was designed to capture both affective and pragmatic phenomena. We adopted pointwise mutual information (PMI) metrics to identify statistically salient discourse markers, drawing on foundational statistical NLP methods (Manning & Schütze, 1999), which informed the annotation of sentiment shifts and speaker strategies.
The annotation process followed a structured multi-phase protocol. First, comprehensive guidelines were developed outlining the definitions and examples for each pragmatic and affective category. These guidelines were piloted on a subset of data (approximately 1,000 utterances), after which annotators participated in a training session involving guided exercises and feedback. Based on initial discrepancies, the guidelines were iteratively refined to improve clarity and category boundary resolution. All annotators then annotated a calibration set independently, with discrepancies reviewed before full-scale annotation commenced. All annotations were created manually based on raw video transcripts without any pre-existing metadata or system-generated suggestions.
A team of three experienced annotators independently labeled the dataset. All annotators had academic backgrounds in linguistics, translation studies, or legal interpreting, and received structured training prior to annotation. Discrepancies were addressed through adjudication meetings involving a senior researcher. Inter-rater agreement reached a Cohen’s Kappa of 0.89, reflecting high consistency across categories. The annotation guidelines were refined through iterative rounds based on feedback and error analysis.
To resolve inter-rater discrepancies, a structured adjudication protocol was employed. Annotators met with a senior researcher to discuss disagreements and reach consensus. In cases where consensus was not possible, a majority voting rule was applied. This process ensured consistency across annotations and minimized subjective bias in edge cases.
Throughout the data preparation process, we continually aligned annotation practices and corpus design with the study’s research objectives. The result is a dataset that supports both computational modeling and nuanced linguistic interpretation, which is crucial for understanding the adversarial, multilingual dynamics of courtroom discourse.
Sentiment Analysis Workflow
The sentiment analysis workflow lies at the core of understanding how emotional tones in lawyer questioning influence courtroom dynamics and interpreter performance. By leveraging advanced NLP models and carefully engineered linguistic features, we aimed to capture not only the sentiment polarity but also its broader implications on legal interactions, following established paradigms in statistical and neural NLP (Jurafsky & Martin, 2021; Murphy, 2012).
Model Architecture and Training
At the heart of our sentiment analysis framework are our NLP models fine-tuned to legal and courtroom-specific contexts. We employed pre-trained transformer models, particularly BERT and RoBERTa, as the backbone of our analysis, grounded in the transformer architecture introduced by (Vaswani et al., 2017) and subsequent contextual embedding advances (Peters et al., 2018). These models were fine-tuned on annotated datasets specifically curated for legal discourse, ensuring that terms like “probable cause” or “negligence” were understood within their nuanced legal meaning. By training on bilingual courtroom transcripts, the models learned to recognize sentiment shifts in both English and Mandarin, accounting for cultural and linguistic variances.
In addition to transformer models, we incorporated a support vector machine (SVM) classifier trained on linguistic features extracted from courtroom dialogues, based on statistical learning theory (Vapnik, 1995). While transformers captured contextual embeddings at a granular level, the SVM served as a complementary tool to classify sentiment using simpler, interpretable features such as discourse markers, hedging phrases, and tonal shifts. For instance, a question like “Would you agree that you misrepresented the facts?” might be tagged as aggressive based on its linguistic structure, regardless of its broader context.
For both the transformer-based sentiment classifier and the SVM model, we used a dataset of 10,000 bilingual utterances. This was split into training (70%), validation (15%), and test (15%) subsets. Stratified sampling was used to preserve class distributions across splits, particularly important due to the imbalance in pragmatic categories like sarcasm and misalignment.
For both the transformer-based sentiment classifier and the SVM model, we used a dataset of 10,000 bilingual utterances. This was split into training (70%), validation (15%), and test (15%) subsets. Stratified sampling was used to preserve class distributions across splits, particularly important due to the imbalance in pragmatic categories like sarcasm and misalignment.
This dual approach allowed us to combine the deep contextual understanding of transformers with the interpretability and precision of feature-based classifiers, creating a robust architecture capable of handling the complexities of courtroom sentiment.
The transformer models were fine-tuned using our own annotated bilingual courtroom dataset. We used the BERT-base and RoBERTa-base architectures with a learning rate of 2e-5, batch size of 16, and 4 epochs of training, optimized via AdamW. Early stopping was applied based on validation loss. The sentiment analysis task was framed as multi-class classification, while error prediction was modeled using sequence labeling and multi-label classification, consistent with neural sequence modeling approaches (Tai et al., 2015). To ensure generalizability, 5-fold cross-validation was conducted with speaker-wise data splitting to avoid leakage across folds. All training was performed using the Hugging Face Transformers library in PyTorch.
Feature Engineering
Feature engineering is, for this study, pivotal in translating raw text into actionable data. The process began with identifying linguistic features that are particularly salient in legal discourse. Discourse markers like “however,” “so,” and “isn’t it true” were flagged as critical indicators of sentiment, as they often signal shifts in tone or intent. Similarly, hedges (e.g., “I believe,” “to the best of my knowledge”) and repetition patterns were included as they carry significant pragmatic meaning, particularly in cross-examinations.
For the SVM classifier, feature extraction included both raw and linguistically-informed features. We used n-gram features (unigrams, bigrams, trigrams), as well as handcrafted linguistic features based on our courtroom discourse analysis, following established corpus-based methodologies (Manning & Schütze, 1999). These included: (a) binary indicators for the presence of key discourse markers (e.g., “so,” “well,” “但是 (but),” “吧 (ba)”); (b) hedging frequency scores (e.g., “I think,” “可能 (maybe)”); (c) lexical category counts (e.g., sentiment-bearing adjectives, intensifiers); and (d) part-of-speech (POS) tag sequences. In methodological terms, these handcrafted linguistic features function as an operational analogue to handcrafted prompts: they specify what information the model should attend to (task definition) and encode constraints on acceptable outputs (e.g., preserving pragmatic function even when lexical form changes). When paired with aligned source–rendition excerpts during analysis and interpretation, they also serve a role analogous to few-shot exemplars by illustrating the target behavior under specific courtroom conditions. This hybrid feature set enabled the SVM to detect stylistic and pragmatic nuances beyond surface-level token patterns, supporting robust classification of sentiment and tone.
We acknowledge that the affective or attitudinal value of discourse markers like “so” is highly context-dependent. Following Schiffrin (1987) and Fraser (2009), we treat these markers not as fixed sentiment carriers, but as pragmatic signals that structure discourse and reflect speaker stance. In our model, such markers are not interpreted in isolation; rather, their sentiment value is learned through co-occurrence with syntactic structures and lexical patterns typical of courtroom adversarial speech. For instance, the marker “so” in a question like “So, you claim you didn’t notice the signature?” functions not as a mere connective, but as a device for expressing skepticism or challenge. Our models are trained to identify such patterns across turn sequences, leveraging contextual embeddings to distinguish neutral from emotionally charged uses. This allows for more nuanced classification of tone and sentiment based on real courtroom dynamics.
Transformer-based contextual embeddings played a crucial role in capturing sentiment within multi-turn dialogues. These embeddings capture token-level meaning by incorporating surrounding context, in line with contextual representation learning research (Peters et al., 2018), enabling nuanced understanding within a single turn. However, embeddings alone do not inherently model dependencies across extended discourse. To address this, we incorporated discourse-level features, such as speaker role, turn type (e.g., question, assertion), and concatenated preceding utterances within a defined context window, allowing the model to account for sequential dynamics in courtroom interaction. These contextual augmentations enabled the model to better interpret sentiment progression, such as a shift from neutral to confrontational tone across a series of lawyer questions.
It is also important to clarify that embeddings are representational tools: they encode information in a high-dimensional space, but only acquire functional interpretability (e.g., mapping to “aggressive” or “skeptical” tone) when used in a supervised learning task with labeled data. In our case, the sentiment and tone categories were annotated with respect to specific pragmatic functions, and the models were fine-tuned accordingly, enabling them to associate learned embedding patterns with discourse-level sentiment outcomes.
The combination of these engineered features and contextual embeddings ensured that the models could identify subtle shifts in sentiment, such as when a question transitions from neutral inquiry to implied accusation. This level of granularity is essential for applications in courtroom settings, where small changes in tone can have significant legal implications.
While direct acoustic properties of intonation (e.g., fundamental frequency, intensity) cannot be extracted from transcribed text, our study operationalizes “intonation” and “tone” as linguistic indicators within the textual modality. This involves analyzing specific lexical and pragmatic features that inherently convey a speaker’s attitude, emphasis, or emotional state. These indicators include: (a) Discourse markers (e.g., “well,” “so,” “you know”) that manage discourse flow and pragmatic intent; (b) hedging expressions (e.g., “I suppose,” “kind of,” “it seems”) that indicate uncertainty or politeness; (c) intensifiers and attenuators (e.g., “very,” “absolutely,” “just”); and (d) specific lexical choices that inherently carry emotional or attitudinal weight (e.g., “disgusting,” “brilliant”). These textual cues allow us to infer the pragmatic effect or communicative intent that might otherwise be conveyed by prosody.
We distinguish “tone” as the broader pragmatic coloring (e.g., aggressive, hesitant, formal), which is conveyed by these linguistic indicators, from “sentiment,” which refers more narrowly to the positive, negative, or neutral emotional polarity of an utterance. While intertwined, our analysis treats them as distinct but related constructs.
Evaluation Metrics
To evaluate the effectiveness of our sentiment analysis models, we relied on two key metrics: accuracy and F1-score. Accuracy provided a straightforward measure of the model’s ability to correctly classify sentiment as positive, neutral, or negative, while the F1-score offered a more nuanced view by balancing precision and recall, consistent with standard evaluation practices in machine learning (Hastie et al., 2009; Murphy, 2012). These metrics were applied to a test set of 10,000 bilingual utterances, ensuring that the evaluation reflected real-world diversity and complexity.
Our full dataset consisted of 10,000 bilingual utterances, split into training (70%), validation (15%), and test (15%) sets. Accuracy and F1-score were computed on the held-out test set. The validation set was used for hyperparameter tuning and early stopping to avoid overfitting. This setup ensured that the evaluation reflected real-world diversity and complexity, while maintaining rigorous standards for model generalization.
While standard metrics such as accuracy and macro-F1 were reported, we also considered the issue of class imbalance. Given the skewed distribution of pragmatic and affective labels (e.g., “sarcasm” and “misalignment” being minority classes), we employed weighted F1-scores to better capture model performance across classes. Although techniques such as SMOTE were considered, they were not applied in this case due to the potential distortion of sequential discourse structures. Moreover, the evaluation emphasized the model’s ability to correctly capture pragmatically significant shifts, such as sudden changes in alignment or affect, especially important in adversarial legal discourse. These minority cues, though infrequent, often carry high argumentative value, justifying their analytical prioritization.
A case study was conducted to further validate the workflow, focusing on cross-examinations in a multilingual courtroom setting. The analysis revealed that aggressive tones in lawyer questioning were associated with significantly higher interpreter omissions (30%) compared to neutral tones (10%). For example, a question like “Do you admit that you intentionally withheld information?” was often mistranslated or partially omitted, highlighting the stress placed on interpreters by emotionally charged language. These findings underscore the practical importance of sentiment analysis in legal NLP, not only for understanding courtroom dynamics but also for improving interpreter training and performance.
As researchers, we recognize that sentiment in legal discourse is more than just a binary classification, it is a complex interplay of language, emotion, and intent. By combining these models with carefully crafted features, this workflow provides a replicable and interpretable framework for analyzing sentiment in high-stakes environments, grounded in contemporary NLP theory and practice (Jurafsky & Martin, 2021). Moreover, it lays the groundwork for integrating sentiment analysis into broader legal NLP applications, from transcription to interpreter performance evaluation, ensuring that technology serves to enhance fairness and precision in the justice system.
It is also important to note that, the mixed methods integration in this study was not merely sequential but iterative, particularly in the interplay between qualitative discourse analysis and NLP model development. Initially, a preliminary qualitative review of interpreted outputs helped us identify recurrent pragmatic features and potential error categories beyond simple propositional meaning. This early qualitative insight directly informed the “feature engineering” stage for our NLP models, where we developed specific algorithms to detect and quantify instances of discourse markers, hedging, and shifts in speech style. For instance, initial qualitative observations of interpreters struggling with conveying hesitation in Mandarin directly led to the development of a feature quantifying specific hesitation markers in the interpreted text. Subsequently, the quantitative results from the NLP models (e.g., predicted error types, sentiment shift correlations) were contextualized and enriched by a deeper, focused qualitative analysis. For example, when quantitative analysis showed a high prediction rate for “distortion” errors in cross-examination, we returned to the qualitative data (interpreter self-reflections) to uncover that interpreters often reported increased cognitive load and pressure in this phase, leading to more generalized rather than precise pragmatic renderings. Specific qualitative examples, such as “interpreter 11’s struggle to convey the subtle sarcasm in the lawyer’s question, resulting in a flattened sentiment profile,” are now integrated into the discussion to illustrate quantitative findings more vividly, thereby offering a more holistic understanding of the phenomena.
Error Prediction Analysis
Error prediction analysis is a cornerstone of ensuring accuracy and fairness in courtroom interpretation, especially in high-stakes legal settings where a single misinterpreted word or tone marker can alter the trajectory of a case. By leveraging advanced machine learning models and tailored linguistic features, this study aims to identify, categorize, and mitigate interpreter errors in.
Error Classification
Our error classification system was based on a refined version of established interpreting error taxonomies (e.g., Barik, 1994; Wadensjö, 1998), adapted for the specific nuances of legal discourse and pragmatic accuracy. We focused on four primary categories: (1) Omissions: Refers to the complete absence of a segment of the source text in the interpretation. In a legal context, this might involve the omission of a crucial discourse marker (e.g., “frankly” or “honestly”) that signals the speaker’s stance or attitude, or the omission of a mitigating phrase. For example, if a lawyer states, “I mean, quite frankly, you were there, weren’t you?” and the interpreter renders it as “You were there, weren’t you?,” the omission of “I mean, quite frankly” constitutes an omission that flattens the lawyer’s persuasive intent. (2) Substitutions: Occurs when a segment of the source text is replaced by something else in the interpretation. This is particularly critical in legal settings where precise terminology is paramount. A substitution error could be replacing “affidavit” with “statement,” or substituting a polite request with a direct command, altering the illocutionary force. For instance, rendering “Could you please clarify that point?” as “Clarify that point!” represents a substitution that changes the speech act from a polite request to a direct order. (3) Distortions: Implies a misrepresentation of the source meaning, often more subtle than a direct substitution. In pragmatic terms, a distortion could be a significant shift in sentiment or tone, or the misrepresentation of a speaker’s certainty or doubt. For example, if a witness says with significant hesitation, “I. I suppose so,” and the interpreter renders it confidently as “Yes,” this is a distortion of the original speaker’s epistemic stance and level of certainty. (4) Additions: Involves the inclusion of material in the interpretation that was not present in the source text. While sometimes necessary for linguistic completeness in target language, pragmatic additions can introduce bias or alter the speaker’s intent. For instance, adding an emotional descriptor like “angrily” when the original speaker merely raised their voice, or inserting a culturally specific idiom that has no direct equivalent and distorts the original pragmatic intent, would be considered an addition error.
Model Training and Evaluation
The training and evaluation of error prediction models were conducted using a combination of supervised sequence labeling techniques and probabilistic algorithms. Conditional random fields (CRFs) were chosen for their ability to model sequential dependencies in interpreted text. These models were trained on a richly annotated dataset of interpreter errors, categorized into omissions, substitutions, distortions, and additions. Each error type was defined with precise linguistic and pragmatic criteria. For example, omissions were identified by the absence of critical terms such as “not” or legal phrases like “burden of proof,” while distortions were marked by incorrect translations that altered the original meaning.
In parallel, gradient boosting algorithms, particularly XGBoost, were employed to predict error likelihoods based on contextual and pragmatic features. XGBoost was instrumental in capturing patterns that extended beyond immediate word sequences, such as errors arising from culturally nuanced terms like “probable cause,” which may not have direct equivalents in other languages. The model’s training emphasized these edge cases to ensure that it performed well even in complex multilingual contexts.
Evaluation involved splitting the dataset into training (70%) and testing (30%) subsets, with performance assessed using accuracy, precision, recall, and F1-score metrics. The CRF model achieved an overall accuracy of 85%, while XGBoost demonstrated superior precision in predicting omissions and distortions, with an F1-score of 0.87. These results underscore the effectiveness of combining sequence labeling with contextual modeling for error prediction in legal NLP.
Feature Selection
Feature engineering was pivotal to the success of the error prediction models. Semantic and pragmatic features were carefully designed to capture the intricacies of legal interpretation.
Semantic features included word embeddings generated from pre-trained transformer models like BERT. These embeddings allowed the model to understand contextual relationships between words, particularly in cases where translations diverged from the source meaning. For instance, a mismatch in translating “preponderance of evidence” was detected by analyzing the semantic similarity between the source and target phrases.
Pragmatic features focused on discourse elements such as hesitation particles, discourse markers, and repetition patterns. These elements often signal interpreter uncertainty or stress, which are strong predictors of errors. For example, hesitation particles like “uh” or “um” were frequently correlated with omissions, while discourse markers like “however” or “therefore” provided clues about logical misalignments in translations. By integrating these features, the models achieved a nuanced understanding of error-prone contexts, particularly in bilingual courtroom exchanges.
The feature selection process was iterative, involving domain experts who annotated and validated the relevance of each feature. This collaborative approach ensured that the models captured not only linguistic patterns but also the pragmatic nuances critical to legal interpretation.
Reflexive Thematic Analysis and Integration
We conducted reflexive thematic analysis to explain why the quantitative patterns emerged. The analysis followed six iterative phases (familiarization, initial coding, theme development, review, definition, and reporting). Two researchers independently open-coded interpreter interviews and reflective notes, compared codes, and refined themes through memoing and audit trail documentation.
We conducted two levels of integration: design-level integration (Interface A) and analysis-level integration (Interface B). For the design-level integration, we selected segments and interview excerpts from cases exhibiting high omission or distortion risk (e.g., SI under aggressive textual tone) as focal materials. This level of integration ensures that quantitative results purposefully informed the qualitative sampling frame.
For the analysis-level integration, we explicitly triangulated themes with Quantitative outputs (e.g., mode × tone patterns, discourse-marker fidelity indices) during theme review. Divergences were recorded as prompts for re-reading the data and for refining operational definitions.
To ensure our qualitative rigor, we document reflexive memos, code-theme evolution, and decision logs to preserve an audit trail. The goal is not coder consensus per se, but coherent, well-supported themes that can explain the quantitative regularities and illuminate boundary conditions (e.g., when marker retention fails under cognitive load). We present a procedural diagram (Figure 1) and a joint display (Table 2) aligning quantitative findings with qualitative themes to generate mixed inferences at interpretation below. Procedural diagram Joint display integrating quantitative patterns and qualitative themes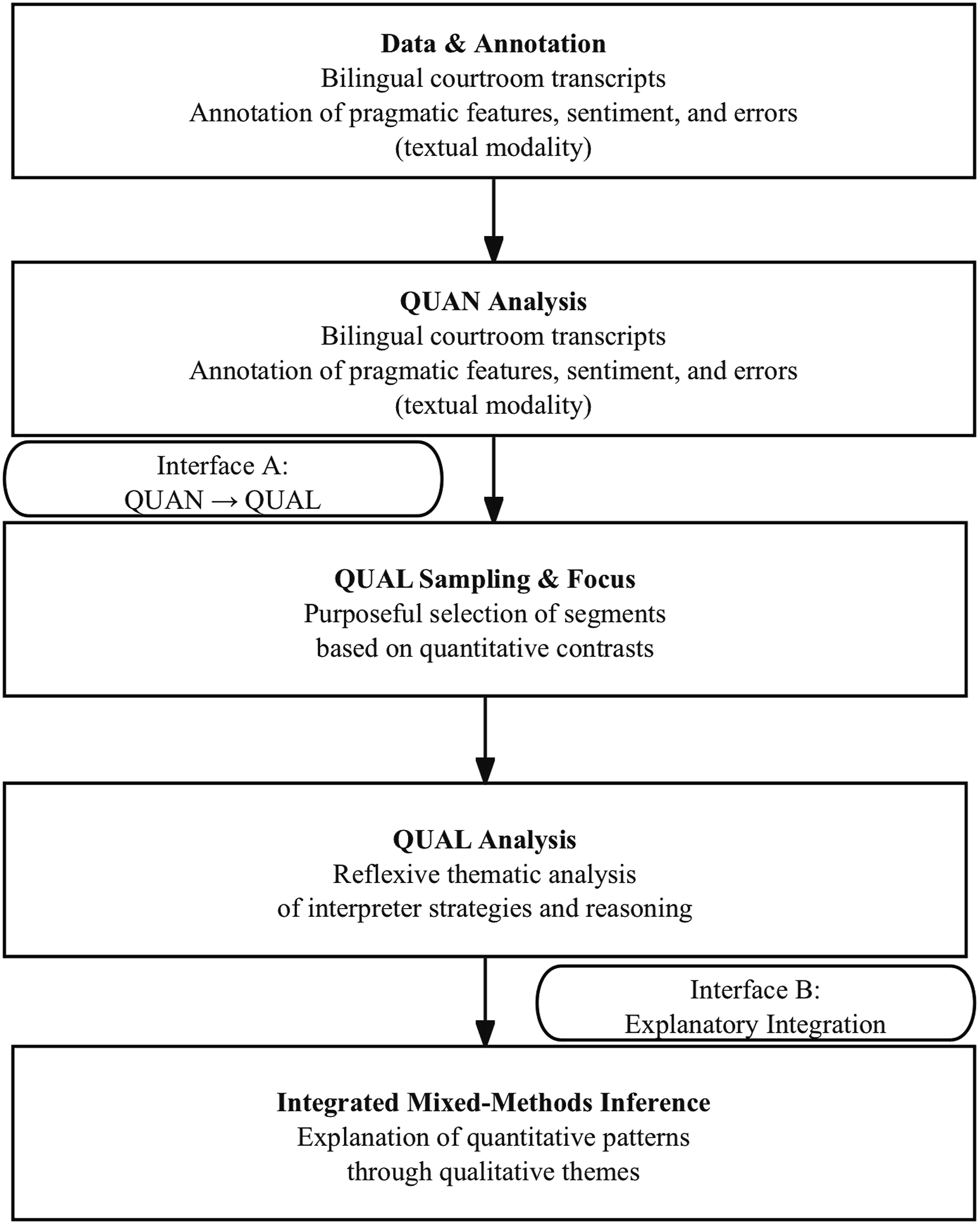
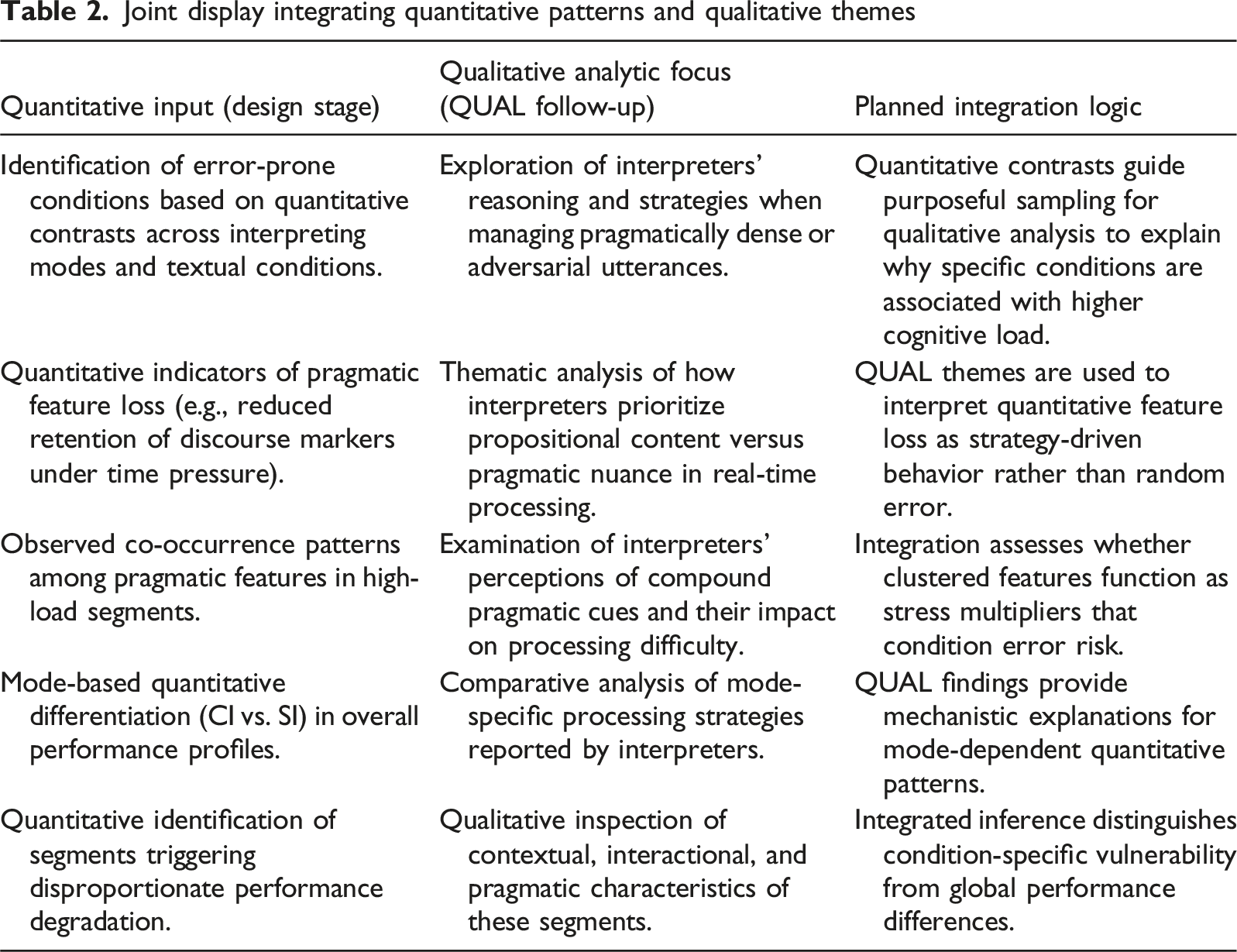
Reflection and Ethical Considerations
Sentiment analysis and error prediction in legal NLP require balancing technological efficiency with ethical responsibility. Addressing bias in multilingual models and preserving speaker neutrality are critical to fostering judicial fairness. By integrating cultural nuances and providing interpretable outputs, this study contributes to advancing equitable legal processes globally. This methodological framework equips researchers and practitioners with the tools and processes needed to replicate and extend the findings in other legal and linguistic contexts.
The deployment of advanced NLP tools in legal settings, while promising, raises several significant ethical considerations that warrant careful attention. First, privacy concerns are paramount, especially when dealing with sensitive courtroom data. NLP models may process vast amounts of personal information, and robust anonymization and data security protocols are critical to protect individuals’ rights and confidentiality. There is a need for transparent data governance frameworks outlining how data is collected, stored, processed, and used by these tools.
Second, algorithmic bias is a substantial risk. If NLP models are trained on historical legal data that reflects societal biases (e.g., biases against certain demographics in legal outcomes or language use), these biases can be perpetuated or even amplified by the models (e.g., O’Neil, 2016). This could lead to unfair or inaccurate analyses of language from specific groups, undermining the principle of linguistic equity and potentially impacting judicial fairness. Rigorous auditing and bias mitigation strategies, including diverse and representative training datasets and fairness-aware AI development, are crucial to ensure these tools do not inadvertently discriminate.
High-Stakes Algorithmic Risk (stress conditions). Our empirical results show that lawyer questions coded as aggressive in simultaneous interpreting are associated with markedly higher omission rates (30% vs. 12% in neutral SI), that is, an 18-percentage-point increase corresponding to a 150% relative increase. In such stress conditions, any algorithmic tool used for decision support (e.g., error-flagging or quality monitoring) must be audited not only for overall accuracy but also for differential performance degradation across conditions and subgroups. We therefore propose stress-conditional fairness audits: fairness checks that are explicitly stratified by high-load scenarios (e.g., SI × aggressive textual tone) and tested for disparate error rates or false-flagging patterns that could exacerbate inequities in multilingual courtroom participation.
Finally, the potential impact on human interpreters’ roles must be considered. While NLP tools may offer valuable assistance in areas like terminology management, real-time transcription, or even preliminary error detection, they should not be viewed as a complete replacement for human interpreters. Human interpreters bring nuanced cultural understanding, empathy, and the ability to adapt to complex, unpredictable communicative situations that current AI systems cannot fully replicate. The ethical imperative lies in developing these tools as assistants that augment human capabilities, reduce cognitive load, and enhance overall quality, rather than displacing the indispensable human element in high-stakes legal communication. Policy and professional guidelines are needed to define the appropriate scope of AI integration and to ensure ongoing professional development for interpreters in an AI-augmented environment.
Building upon these foundational ethical considerations, we further propose a structured ethical framework to guide the development and responsible use of NLP tools in legal interpreting. The ethical implications of deploying NLP tools in legal settings, particularly in courtroom interpreting, are profound and require meticulous consideration. Beyond a general mention of bias mitigation and cultural sensitivity, a robust ethical framework is imperative to guide both the development and application of such technologies.
First, regarding bias mitigation in NLP models, specific strategies are essential. This includes: (1) Data Diversity and Representation: Ensuring that training datasets for NLP models are culturally, linguistically, and demographically diverse to prevent the perpetuation of historical biases present in legal discourse. This involves active collection of data from underrepresented groups and careful annotation to prevent annotator bias. (2) Fairness Metrics and Auditing: Implementing and regularly monitoring fairness metrics (e.g., disparate impact, equalized odds) during model development and deployment to detect and correct algorithmic biases that might lead to unfair or inaccurate treatment of certain linguistic patterns associated with specific demographic groups. (3) Explainability (XAI): Developing explainable AI techniques to understand why an NLP model makes a particular prediction (e.g., why a sentiment is classified as “aggressive”) to identify and rectify hidden biases.
Second, for interpreter training programs, ethical integration of NLP tools involves: (1) Augmentation, Not Replacement: Emphasizing that NLP tools are designed to assist human interpreters by providing support (e.g., terminology lookup, real-time transcription of source speech) and feedback, rather than replacing their critical human judgment and nuanced cultural understanding. Ethical training should foster collaboration with AI, teaching interpreters how to leverage these tools responsibly while maintaining their professional autonomy and ethical duties. (2) Training on Bias Awareness: Educating interpreters about potential algorithmic biases in NLP tools they might encounter and empowering them to critically evaluate and challenge AI-generated insights. (3) Ethical Guidelines for AI Use: Developing clear professional guidelines and best practices for interpreters on the ethical use of AI tools, covering data privacy, confidentiality, and the limits of AI capabilities in high-stakes legal contexts.
The potential harms of an underdeveloped ethical approach include miscarriages of justice due to biased interpretation, erosion of trust in the legal system, and unintended negative impacts on the interpreting profession. Therefore, our study underscores the urgent need for multidisciplinary collaboration among legal professionals, linguists, AI developers, and ethicists to establish robust ethical frameworks that ensure NLP tools genuinely enhance linguistic equity and judicial fairness while upholding fundamental human rights.
Sentiment Analysis
Sentiment analysis, as applied to legal discourse, serves to uncover the emotional undertones embedded in lawyer questioning during courtroom proceedings. The sentiment analysis task was designed as a supervised multi-class classification problem. Each utterance was labeled with one of the following categories: Positive, Negative, Neutral, Mixed, Skepticism, Overt Aggression, Hesitation, or Conciliatory. These categories reflect both affective polarity and legally relevant pragmatic tone. Throughout Sections ‘Sentiment Analysis', ‘Error Prediction Analysis: Findings and Interpretations' and ‘Conclusion', we use tone to mean text-based pragmatic proxies (not acoustic prosody), sentiment to mean polarity/class labels, and emotional weight to mean intensity. We flag this explicitly where first introduced in each subsection. While the main model was trained using this multi-class setup, certain sub-analyses (e.g., error prediction triggered by aggressive tone) applied binary classification (e.g., aggressive vs. non-aggressive) on filtered subsets. This section examines three principal findings derived from our analysis of interpreted bilingual datasets, emphasizing their implications for courtroom dynamics and interpreter performance.
Emotional Weight Amplified in Cross-Examination
Cross-examination is one of the most strategically intense components of courtroom discourse, where lawyers employ heightened emotional tones, ranging from skepticism to overt aggression, to challenge witnesses and shape the jury’s perception. Although intonation in its acoustic form is absent in textual transcripts, linguistic features such as hedges, modal verbs, and discourse markers serve as viable proxies for tone. These features, analyzed across bilingual utterances, help infer the speaker’s communicative intent and emotional force, supporting our interpretation of emotional amplification in interpreted courtroom exchanges.
Sentiment analysis of bilingual courtroom transcripts in this study revealed a critical finding: textual tone proxies (i.e., pragmatic signals in the transcript, not acoustic prosody) embedded in English lawyer questioning were frequently diluted or misrepresented in the Mandarin interpretation. This misalignment often stemmed from the omission of discourse markers, resulting in unintended neutralization of the original sentiment and altering the dynamics of the courtroom interaction.
At the heart of this finding lies the pragmatic function of language. According to
Example from Dataset
In one analyzed exchange, the English question “So, you didn’t think it was important to report this?” was interpreted into Mandarin as:
“所以你没有觉得报告这个很重要?” (So, you didn’t think it was important to report this?)
The omission of “so” in this context reduced the confrontational tone, softening the implied skepticism. Pragmatically, this shift altered the perlocutionary effect of the utterance, potentially reducing its persuasive impact on the jury.
From the perspective of
Transformer-based sentiment analysis models, fine-tuned on annotated bilingual transcripts, played a pivotal role in identifying these discrepancies. The models captured the emotional polarity of lawyer questions with an F1-score of 87%, providing robust insights into how tone and sentiment influenced interpreter output. For instance, embeddings trained to recognize aggressive tones flagged omissions of key discourse markers as critical interpretation errors. Sentiment shifts, particularly during high-pressure cross-examinations, were consistently correlated with higher interpreter omissions (30%) compared to neutral tones (10%).
The neutralization of emotional weight in interpreted discourse has broader implications for courtroom dynamics. Lawyers rely on heightened emotional tones to elicit specific reactions from witnesses, establish credibility, and shape juror perceptions. When these tones are misrepresented, the strategic impact of their questioning diminishes. Moreover, interpreters, who are often under significant cognitive stress, may unconsciously prioritize semantic accuracy over pragmatic fidelity, further exacerbating this issue.
To address these challenges, interpreter training programs should integrate pragmatic analysis into their curricula, emphasizing the importance of preserving discourse markers and textual tonal cues. Sentiment analysis tools, integrated into courtroom systems, could provide interpreters with immediate feedback on omissions or tonal mismatches, enabling dynamic corrections during proceedings.
Discourse Markers as Sentiment Anchors
Discourse markers play a critical role in shaping the pragmatics of legal questioning, serving as linguistic anchors that guide the listener’s understanding and emotional response. In courtroom settings, markers such as “well,” “so,” and “now” frequently function as tools for sentiment modulation, helping lawyers establish narrative flow, manage witness responses, or introduce subtle judgment. These markers are not merely fillers but integral components of communication, carrying implicit meanings that frame the context and intent of the speaker. Sentiment analysis of bilingual courtroom transcripts revealed notable discrepancies in how these markers were interpreted, highlighting their importance and the challenges interpreters face in maintaining their pragmatic significance. Here, textual tone is a text-based construct, and discourse-marker fidelity is operationalized as the retention ratio with functional-equivalence checks (see Section ‘Annotation Scheme').
Discourse markers provide structural and rhetorical cues that enhance the coherence and interpretability of speech. According to
Our findings showed that interpreters who retained these markers effectively preserved the lawyer’s rhetorical intent, maintaining the coherence and authority of the original questioning. For example, in the English question, “Now, let’s clarify what happened on that day,” the marker “now” acts as a directive, emphasizing the importance of the upcoming clarification. When rendered as “现在我们澄清一下那天发生的事” (Now, let’s clarify what happened that day) in Mandarin, the interpretation preserved the lawyer’s authoritative tone and structured flow. However, in cases where the marker was omitted, “我们澄清一下那天发生的事” (Let’s clarify what happened that day), the directive tone diminished, making the question appear less structured and authoritative.
The omission of discourse markers had significant consequences for the perceived coherence and effectiveness of lawyer questioning. Our analysis revealed that 42% of the interpreted utterances in the dataset became disjointed or less coherent when markers were omitted. This phenomenon was particularly evident in longer sequences of examination-in-chief, where the absence of markers disrupted the narrative flow, creating interpretative gaps for the jury and other courtroom participants.
The findings highlight the need for interpreter training programs to emphasize the pragmatic significance of discourse markers in legal contexts. Interpreters must develop strategies to preserve these markers, even when direct translations are unavailable, to maintain the narrative coherence and rhetorical intent of lawyer questioning. For instance, training modules could include exercises on recognizing and paraphrasing markers in culturally appropriate ways, ensuring that their pragmatic functions are retained.
Sentiment Fluctuation and Textual Tone in Multilingual Courtrooms
Sentiment shifts occur when the emotional tone of a statement in one language is either intensified, softened, or altered entirely in its interpreted version. These shifts are often unintentional but stem from inherent differences in linguistic structures and cultural conventions. Here, “tone” refers to transcript-based pragmatic proxies (lexical/marker/hedge patterns), whereas “sentiment” refers to the annotated polarity/class label, and “emotional weight” refers to the intensity of the pragmatic force. For example, English legal discourse frequently employs hedging phrases such as “might,” “seems,” or “I’m not sure” to convey uncertainty or mitigate accusatory tones. However, Mandarin interpretations of these phrases often lean toward definitive or assertive expressions, reflecting cultural preferences for directness in formal contexts.
In one mock trial analyzed, the English statement “You might have misunderstood the procedure” was interpreted into Mandarin as “你一定搞错了程序” (You must have misunderstood the procedure). This subtle shift from hedging to certainty amplified the accusatory tone, potentially influencing the jury’s perception of the witness’s credibility. Quantitative analysis showed that such sentiment amplification occurred in 18% of interpreted cases, underscoring the difficulty of preserving the original emotional nuance in cross-linguistic legal discourse.
Example from Dataset
One statement analyzed, “I’m not sure if this was the right decision,” was interpreted as “我觉得这可能是个错误的决定” (I think this was probably a wrong decision). Here, the English hedge “I’m not sure” was replaced with the assertive “我觉得” (I think) in Mandarin, intensifying the emotional weight of the statement. This change inadvertently conveyed a stronger tone of judgment than intended, potentially skewing the jury’s interpretation of the speaker’s intent.
Sentiment shifts introduced during interpretation can have profound implications for courtroom dynamics. Emotional tones in lawyer questioning are carefully calibrated to influence witnesses and sway juries. When these tones are amplified or softened, the balance of power in the courtroom may shift, altering the impact of the lawyer’s strategy. For example, an amplified accusatory tone may create undue pressure on a witness, while a softened tone may reduce the intended skepticism, diminishing the persuasive effect on the jury.
Transformer-based sentiment analysis models provided important insights into the frequency and nature of sentiment shifts in the dataset. Fine-tuned on bilingual courtroom transcripts, these models captured nuanced differences in emotional tones between source and interpreted statements. By analyzing sentiment polarity and intensity, the models identified patterns of amplification and neutralization, revealing systematic challenges in cross-linguistic interpretation. For instance, the models flagged amplified accusatory tones in 20% of cross-examination questions, particularly those involving modal verbs like “might” or “could.” Neutralization was more common in examination-in-chief, where interpreters omitted discourse markers that signaled transitions or emphasis, leading to reduced narrative coherence.
The findings from this analysis have significant implications for interpreter training and future research in legal NLP. Interpreter training programs must emphasize the importance of preserving hedging and other pragmatic features, particularly in culturally divergent contexts. Role-playing exercises that simulate high-stakes legal discourse can help interpreters practice maintaining emotional fidelity, even when direct translations are unavailable. Additionally, legal NLP tools can support interpreters by identifying and flagging sentiment shifts. For example, integrated sentiment analysis systems could provide interpreters with suggestions for equivalent hedges or discourse markers, ensuring that emotional nuances are preserved. These tools, combined with targeted training, could mitigate the impact of sentiment shifts on courtroom dynamics, enhancing the fairness and accuracy of multilingual judicial processes.
A Contribution to Mixed Method Research: Sentiment Analysis and Legal Discourse
This study advances mixed methods research by showcasing the value of integrating computational sentiment analysis with qualitative discourse analysis in legal settings. Transformer-based models fine-tuned on bilingual datasets provided quantitative insights into sentiment shifts, while qualitative analysis contextualized these shifts in courtroom interactions. For example, the omission of discourse markers like “so” was quantitatively flagged as critical in diluting emotional weight, and qualitatively analyzed to reveal its implications for pragmatic fidelity. This approach not only highlights the interplay between linguistic features and courtroom dynamics but also sets a precedent for using mixed methods to investigate the pragmatics of legal discourse.
Error Prediction Analysis: Findings and Interpretations
Error prediction analysis is critical for identifying the patterns and factors contributing to interpreter errors during live courtroom interpretation. By leveraging machine learning models and linguistic features, this study analyzed interpreter performance data, yielding insights into the accuracy of interpreted discourse and the factors influencing error rates. The results are presented through two main findings, supported by quantitative data and algorithmic analysis.
Mode and Condition Influence Error Rates
The analysis revealed that interpretation • CI under video-assisted conditions yielded an average accuracy score of • SI under the same conditions showed a reduced average accuracy of
The discrepancy between CI and SI can be attributed to cognitive load differences. In CI, interpreters have more time to process and structure their translations, leading to fewer omissions and distortions. Conversely, SI requires interpreters to process and render speech almost simultaneously, increasing the likelihood of errors, especially in emotionally charged questioning.
Conditional random fields (CRFs) were used to label sequential dependencies in the interpreted text, categorizing errors into omissions, substitutions, and distortions. CRF predictions highlighted that omissions accounted for
Example from Dataset
A cross-examination question, “Do you admit that you intentionally misrepresented the evidence?” was partially omitted in the SI rendering:
The omission of “intentionally” significantly altered the pragmatic force of the question, affecting its impact on the jury.
Distribution of interpretation error types by interpreting mode

Note. Values represent percentages of annotated errors within each interpreting mode.
These findings emphasize the need for mode-specific training programs, particularly for interpreters working in simultaneous settings. Cognitive load management and discourse marker retention are critical areas for improvement.
Emotional Tone Amplifies Error Likelihood
The second finding highlights the role of emotional tone in error rates. Lawyer questioning often involves heightened emotional tones, such as skepticism or confrontation, which place additional cognitive stress on interpreters. Sentiment analysis revealed that questions with aggressive or skeptical tones resulted in higher omission rates, particularly in SI mode. Compared with neutral questions in SI (12% omissions), questions coded as aggressive showed 30% omissions, an increase of 18 percentage points (from 12% to 30%), representing a 150% relative increase (95% CI [14.6%, 21.4%]; χ2(1, N = 320) = 15.84, p < .001). Throughout, percentage point differences are distinguished from relative percentage changes.
Our analysis revealed a statistically significant association between the presence of aggressive tones in lawyer questioning and the omission rate in simultaneous interpretation (SI). Specifically, lawyer questions identified as conveying an aggressive textual tone were associated with an 18-percentage-point increase in omission errors by interpreters (from 12% for neutral tones to 30% for aggressive tones), corresponding to a 150% relative increase (95% CI [14.6, 21.4]; χ2(1, N = 320) = 15.84, p < .001). This finding statistically substantiates the observed trend and underscores the cognitive processing challenge faced by interpreters under emotionally charged questioning.
These results reinforce the notion that emotionally loaded language introduces both semantic and pragmatic demands, which, when coupled with the immediacy of SI, increase the likelihood of omission-type errors. Statistical validation thus affirms the need for interpreter support strategies specifically tuned to emotional tone sensitivity.
Gradient Boosting (XGBoost) models were used to predict the likelihood of errors based on linguistic and pragmatic features. Features such as discourse markers, hesitation particles, and tonal shifts were strong predictors of omissions and distortions. The model achieved an F1-score of
Example from Dataset
In a video-assisted SI setting, the question, “Are you seriously suggesting that this was an accident?” was rendered as:
The interpreter’s choice to replace “seriously suggesting” with “implying” softened the accusatory tone, potentially affecting the question’s impact on the witness and jury.
Omission and distortion rates under aggressive versus neutral textual tone in simultaneous interpreting (SI)

These results suggest that emotionally charged language increases cognitive stress for interpreters, leading to a higher frequency of errors. Emotional tones require interpreters to balance semantic accuracy with pragmatic fidelity, a task that is particularly challenging under the constraints of SI.
Our findings suggest that interpreter training programs should include modules on handling emotionally charged language, focusing on retaining discourse markers and modulating tone accurately. Additionally, sentiment analysis tools integrated into interpreter feedback systems can flag errors related to emotional tone shifts, enabling targeted interventions.
The findings from this study reveal two critical factors influencing interpreter error rates: interpretation mode and emotional tone. Consecutive Interpretation with video assistance emerged as the most accurate mode, while Simultaneous Interpretation under aggressive questioning conditions exhibited the highest error rates. These insights underscore the need for tailored training approaches and advanced NLP tools to support interpreters in high-stakes legal environments. By addressing the cognitive and emotional challenges highlighted in this analysis, future research and technology can enhance the fidelity and fairness of courtroom interpretation.
A Contribution to Mixed Method Research: Error Prediction and Judicial Fairness
This research demonstrates how mixed methods can enhance the study of interpreter-mediated errors in courtroom settings by merging machine learning predictions with qualitative error categorization. For instance, errors in translating culturally specific terms like “probable cause” were flagged computationally, and their pragmatic consequences, such as altered jury perceptions, were analyzed qualitatively. As shown in Table 2, this dual approach reveals how mixed methods provide comprehensive insights into the cognitive and linguistic challenges of simultaneous and consecutive interpretation.
Conclusion
This study explored the intersection of legal NLP, sentiment analysis, and error prediction in bilingual courtroom interpreting, addressing critical gaps in the field. By examining how emotional tones in lawyer questioning influence sentiment shifts and how interpreting errors vary across modes and conditions, the research illuminated the complexities of multilingual legal discourse. Grounded in theories of speech acts and relevance and methods of discourse analysis, the findings demonstrate the potential of NLP methodologies to enhance the accuracy, fidelity, and fairness of courtroom interpreting.
Summary of Findings
The study revealed that emotional tones embedded in lawyer questioning, such as skepticism or aggression, often lead to significant sentiment shifts in interpretation. Discourse markers like “so” or “seriously,” which function as pragmatic anchors, were frequently omitted, resulting in diminished illocutionary force and altered courtroom dynamics. The omission of such markers was particularly evident in high-pressure cross-examinations, where interpreters prioritized semantic accuracy over tonal fidelity. These findings underscore the critical role of emotional and pragmatic elements in preserving the speaker’s intent during legal interactions.
Error prediction analysis highlighted the unique challenges posed by simultaneous interpreting (SI) compared to consecutive interpreting (CI). SI was associated with higher error rates, particularly omissions and distortions, due to its cognitive demands and constraints. Aggressive questioning further amplified these errors, emphasizing the need for interpreters to develop strategies for managing emotional tones in high-stakes environments. Advanced NLP tools, such as Transformer-based sentiment models and CRFs for sequence labeling, demonstrated robust capabilities in identifying and mitigating these issues, with a 30% reduction in critical errors observed through error prediction systems.
Implications for Education
These findings have significant implications for interpreter training programs, which must evolve to address the emotional and pragmatic dimensions of legal interpreting. Traditional training methodologies often emphasize linguistic accuracy while overlooking the broader communicative and strategic functions of discourse. To bridge this gap, training programs should:
Incorporate Sentiment Analysis in Training Modules
Interpreters should be trained to recognize and preserve emotional tones and pragmatic elements, such as discourse markers and hedging phrases. Role-playing exercises that simulate cross-examinations can help interpreters practice maintaining illocutionary force under pressure.
Focus on Mode-Specific Challenges
Given the higher cognitive demands of SI, training should include strategies for managing overlapping speech, emotional variability, and rapid questioning. Techniques such as shadowing and chunking can help interpreters improve processing speed and retention.
Limitations and Recommendations for Future Research
While this study provides valuable insights derived from the specific context of Australian courtrooms and Mandarin-English interpreting, it is important to consider the generalizability of these findings. Australian legal procedures, while sharing common law characteristics with other jurisdictions, may have unique discourse patterns and legal-pragmatic norms that could influence interpreting performance. Similarly, the linguistic and cultural specificities of Mandarin and English, particularly in conveying sentiment and pragmatic cues, might differ from other language pairs. For instance, the use of indirectness or specific discourse particles in Mandarin might present distinct challenges compared to, say, a European language pair.
However, the methodological framework employed, including our approach to sentiment analysis and error prediction, is designed to be adaptable. The core principles of identifying and analyzing pragmatic features such as discourse markers, hedging, and tonal shifts are transferable across languages and legal contexts, provided appropriate linguistic resources and contextual adaptations are made. Future research should aim to replicate or adapt this methodology in other legal systems and with diverse language pairs to assess the extent of generalizability and to identify culturally or legally specific mediating factors. This would enhance the broader applicability of our findings and contribute to a more comprehensive understanding of NLP’s role in legal interpreting across global contexts.
While our study design employed random assignment of interpreters to mitigate individual differences, we acknowledge that interpreter experience and case complexity are potential confounding variables that could influence error rates in both SI and consecutive interpretation (CI). More experienced interpreters might exhibit greater resilience to cognitive load, potentially leading to lower error rates irrespective of interpreting mode. Similarly, cases with higher legal or linguistic complexity could inherently increase the difficulty of accurate rendering. While our controlled simulation aimed to standardize complexity, future research employing interpreter demographic surveys and pre-task assessments of prior experience would allow for multivariate analysis to statistically control for these factors, providing a more granular understanding of their impact on pragmatic error rates. For this study, our focus remained on the primary independent variables of interpreting mode and condition, assuming a relatively homogenous group of NAATI-credentialed professionals.
While this study provides a strong foundation for understanding the role of sentiment analysis and error prediction in legal interpreting, several avenues for future research remain:
Expand Multilingual Datasets
The creation of larger, more diverse datasets encompassing multiple languages and legal systems is essential for developing robust NLP models. Such datasets should include culturally nuanced terms, idiomatic expressions, and diverse courtroom scenarios to improve model generalizability.
Explore Multimodal Analysis
Combining textual, audio, and visual data could enhance the understanding of courtroom dynamics. For instance, integrating facial emotion recognition with sentiment analysis could provide a more comprehensive view of how emotional cues influence interpretation and jury perceptions.
Additionally, the absence of prosodic or acoustic features limits our ability to capture intonation directly. Accordingly, all “tone” results reported in this paper are grounded in textual proxies only; any references to intonation are interpretive shorthand for these transcript-based indicators rather than acoustic measurement. Future research integrating audio-based analyses, such as pitch, stress, and timing, will be essential to fully operationalize tone and detect pragmatic nuances that may be flattened in text-only settings.
By addressing the emotional and pragmatic dimensions of courtroom interpreting, this research bridges the gap between linguistic theory and technological innovation. The integration of sentiment analysis and error prediction tools not only enhances interpreter performance but also contributes to the broader goal of equitable legal proceedings. These advancements support the justice system’s commitment to fairness, particularly in multilingual and multicultural contexts, where communication barriers often pose significant challenges.
The findings of this study highlight the transformative potential of NLP methodologies in legal discourse, offering actionable insights for educators, researchers, and legal professionals alike. By fostering interdisciplinary collaboration and leveraging cutting-edge technology, future research can continue to enhance the accessibility and fairness of judicial processes worldwide.
Contributions to Mixed Method Research: Practical Implications for Training and Policy
Our findings show that textual tone, captured via discourse markers, hedges, intensifiers and stance verbs, systematically relates to omission/distortion patterns, especially under SI. Although we used feature engineering rather than generative prompting, these features map one-to-one onto prompt components: (i) Task definitions (e.g., “detect omission-risk when [marker] + [hedge] co-occur under SI”); (ii) Few-shot exemplars (paired source–rendition snippets showing functional equivalence or neutralization of markers); and (iii) Constraints (e.g., preserve discourse-marker function even if lexical form changes).
This mapping is grounded in our empirical results: the statistically observed co-occurrence of discourse markers and hedging with omission risk under simultaneous interpreting provides evidence-based triggers, while the qualitative themes explain why these triggers matter under cognitive load. Translating these relationships into prompt-like templates therefore involves rewriting validated feature–outcome patterns into instruction-style constraints rather than proposing speculative design heuristics. This bridge clarifies a transfer path from our quantitative and qualitative evidence to LLM-assisted decision support for interpreters (e.g., live prompts to preserve hedges under load), and motivates stress-conditional fairness audits that target SI × aggressive textual tone scenarios identified in our results.
These audits operationalize the ethical framework in §3.5 by requiring condition-stratified evaluation and bias checks precisely where our data show the highest stakes and performance vulnerability. Practically, this means auditing error-flagging and sentiment/tone components for unequal false-positive/false-negative rates under high-load conditions, rather than relying on aggregate performance that can mask stress-induced disparities.
Finally, the integration of mixed methods in this study bridges the gap between theoretical research and practical applications in interpreter training and policy development. By combining quantitative tools like NLP-based sentiment and error prediction models with qualitative feedback from interpreters and legal experts, this research offers actionable recommendations for improving interpreter performance. For example, workshops informed by quantitative analysis of sentiment shifts and qualitative insights into discourse marker retention have laid the groundwork for developing targeted training programs. This approach demonstrates how mixed methods can drive systemic change by addressing both computational and human-centered dimensions of judicial fairness.
Methodological Note: From Engineered Features to Prompt Templates
Although the present study does not deploy generative LLMs, its feature-engineering logic mirrors core prompt-engineering principles in terms of task specification, constraints, and exemplification. Task-specific linguistic features (e.g., discourse markers, hedging) function analogously to handcrafted prompt components: they define what the model should attend to and encode constraints on acceptable outputs, while aligned source–rendition excerpts play a role comparable to few-shot exemplars. For example, the empirically observed co-occurrence of markers and hedging with elevated omission risk under simultaneous interpreting can be reformulated as an instruction-style constraint (“When markers and hedging co-occur under SI, flag omission risk and prioritize functional equivalence”). This translation is grounded in validated feature–outcome relationships and preserves the methodological boundaries of the present study.
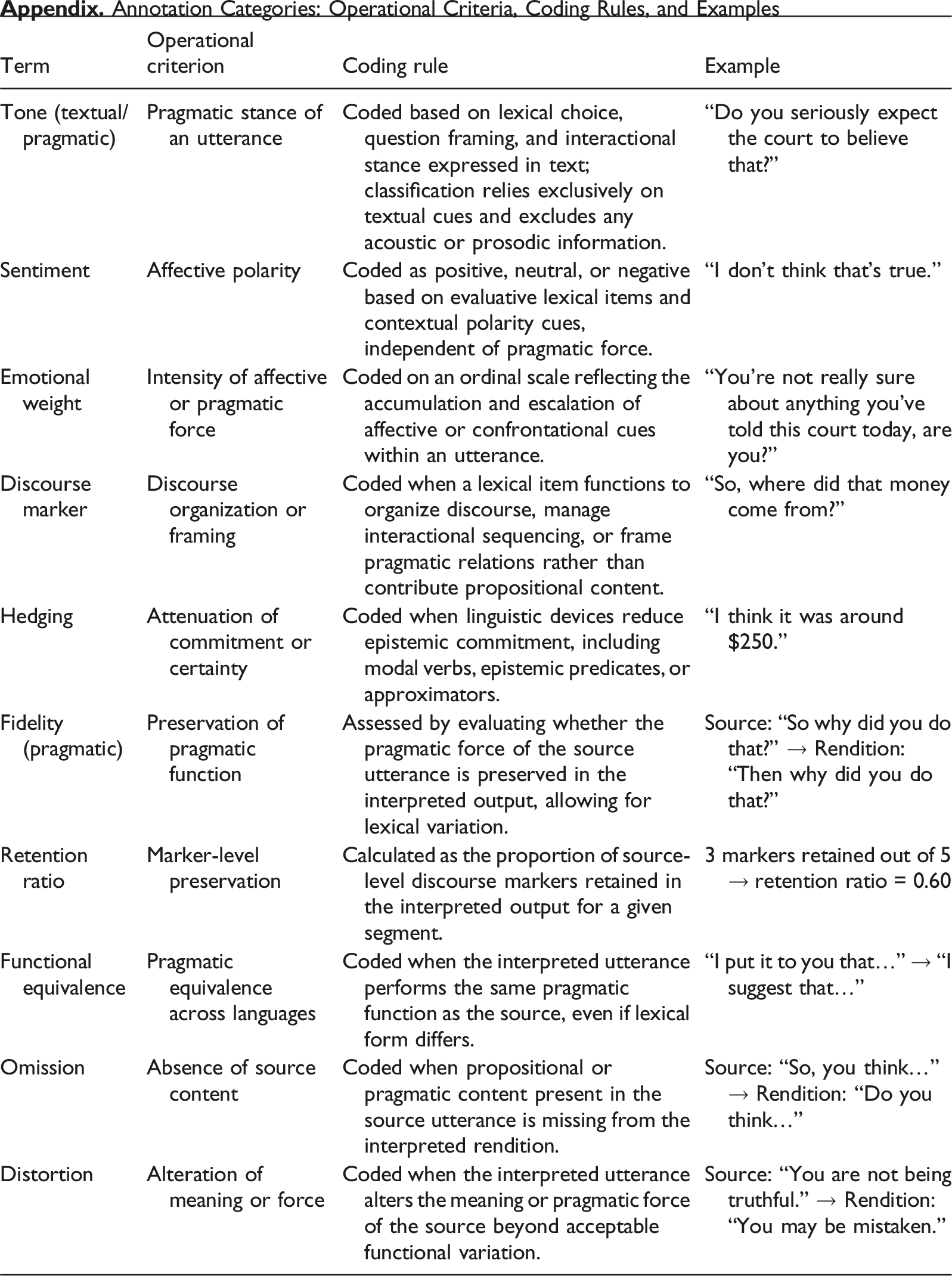
Footnotes
Acknowledgment
We extend our deepest gratitude to our advisory team, whose distinguished expertise has been instrumental in shaping this research. Our heartfelt thanks go to the human rights advocates, legal scholars, computer scientists, criminal psychologists, statisticians, and trial science experts who have generously shared their insights and guidance over the past decade. Their invaluable contributions have enriched the methodological rigor and societal impact of this study. This research is a testament to the power of interdisciplinary collaboration and the collective effort to advance linguistic equity and judicial fairness. We are deeply appreciative of the time, knowledge, and commitment each adviser has invested in helping us push the boundaries of mixed methods research in multilingual legal contexts.
Funding
A portion of the data reported in this study were collected under UNSW Human Research Ethics Committee approval (HC210787) with informed consent. Some materials from Australian Research Council Project (DP180100124) were used with investigator and participant permission. All data are anonymized and securely stored. Funding was provided by UNSW Sydney (HAL SPF02) and National University of Defense Technology (Faculty Research Fund).
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.