
Abstract
Node localization plays a key and basic role for wireless sensor network. Existing range-free localization approaches suffer from precision limit of positioning, while range-based solutions may obtain good accuracy but pay high costs for ranging hardware. Instead of directly mapping received signal strength values into physical distances, a novel localization scheme with signal-based signature distance estimation is proposed for wireless sensor network. More specifically, we first quantify the near-far relationship between neighbor nodes through received signal strength comparison, and then the distance between non-neighbor nodes is calculated by an improved shortest path algorithm. Based on the obtained node distance, a relative map can be constructed by multidimensional scaling technology. Eventually, the locations of nodes can be acquired by virtue of Procrustes analysis method. For purpose of verifying the effectiveness of our design, several simulations are made in a sensor network with 200 randomly deployed nodes, and two experiments are implemented in real outdoor environments: a linear network and a two-dimensional grid network with 25 nodes. It is remarkable from results that the proposed scheme performs better in positioning and reduces localization errors by as much as 37% compared with state-of-the-art methods.
Introduction
Wireless sensor network (WSN), which consists of autonomous sensors, is an important technology to monitor the physical world, for example, indoor localization, 1 environment monitoring, 2 battlefield surveillance, 3 item tracking 4 . In such data-driven WSN, the location is essential information. Besides, some of the routing protocols 5 and data forwarding mechanisms are built on the assumption that nodes’ location information is available. Although node localization makes fundamental contributions to many applications, it still remains a challenging problem due to the limitation of low-cost and tiny nodes.
There currently exist many excellent localization algorithms in WSN. The first type is range-based localization, in which the ranging is completed by the received signal strength (RSS), time, or angle. In practice, these types of approaches are often accompanied by higher localization accuracy, while may not meet the demand of low-cost system design. The second one is range-free localization, in which wireless connectivity, 6 anchor proximity, 7 or localization events detection are adopted for location estimation. These algorithms have low cost but suffer from poor accuracy. Lately, another localization technology is proposed which is based on the channel status information (CSI). 8 Such methods provide better positioning accuracy, but the CSI is often hard to extract for the general sensor nodes.
Our work is motivated by the finding that the change trend of the RSS values from their neighbors is similar if two nodes are placed near each other. Based on the observation, in this article, we further quantify the near-far relationship between neighboring nodes from two aspects: neighbor pair comparison and RSS difference. After obtaining the relative distance between neighboring nodes, the relative distance among non-neighboring nodes can be calculated by an improved shortest path algorithm. Thus, we can construct the relative location map of the whole network based on the multidimensional scaling (MDS) technology. 9 Finally, given at least three anchors, the physical coordinates can be solved by Procrustes analysis. Specifically, our main contributions are as follows:
Different from the traditional hop-based distances, this article investigates the proximity information embedded in neighborhood RSS, which owns a more accurate sub-hop resolution.
The near-far relationship between neighbor nodes is carefully quantified based on neighbor pair comparison and nodes’ RSS difference, which has a high correlation with physical distance.
Instead of directly using the shortest path algorithm, this article explores the angle relationship between neighbors and adopts an integral calculation method to obtain the distance among non-neighbor nodes.
Extensive simulations and two experiments with 25 nodes are conducted for verifying the effectiveness.
The rest of the article is organized as follows: Section “Related work” surveys the related work about the localization. Section “Motivation” describes the motivation with empirical data. The main design is introduced in section “System design.” Section “Simulation” gives the simulation results and section “Experiments” reports the prototype outdoor experiments. Finally, section “Conclusion” concludes the article.
Related work
Generally, the localization approaches can be classified into three categories: 10 range-based,11,12 range-free,7,13–15 and CSI-based. 16 In the following, we will analyze and discuss them one by one.
Range-based methods can be further divided into three types: RSS-based methods, 17 which convert the signal strength into distance by virtual of logarithmic attenuation model. The direct converting of RSS using the model is always inaccurate, due to the unknown radio path loss factors, multi-path effects, hardware discrepancies, antenna orientation, and so forth. Time-based methods like time of arrival (TOA), 18 time difference of arrival (TDOA), 19 round-trip time of flight (RTOF), and so on, calculate the distance based on the arrival time and radio transmitting speed. Such localization solutions often require high precision timer. Angle-based methods, like angle of arrival (AOA), 20 locate the tag by measuring the phase difference at different antennas. Those methods generally first estimate distances or angles among nodes and then calculate positions by triangulation. Due to per-node additional hardware or intensive tuning, range-based methods could achieve good performance in localization accuracy, but may pay higher price on system cost.
Range-free solutions try to estimate node location through a low-cost and smart design. There are three stages. Early solutions mainly employ the proximity information to anchor nodes like centroid 21 and approximation point-in-triangulation test (APIT). 22 These methods, however, often require a high anchor density for the sake of good localization accuracy. In the second stage, many localization solutions with wireless connectivity are proposed, such as distance vector-hop (DV-Hop), multidimensional scaling-map (MDS-MAP), amorphous. Given the hop-based distances among nodes, such methods only require a small number of anchors for constructing the global coordinates, which significantly reduces the cost. In the third stage, there are some works that help solve problems of holes 23 in practical irregular deployment with obstacles. We note that although the above works are effective, they do not fully extract the location information available from local neighborhood sensing.
Lately, the CSI-based localization strategies are proposed like SAIL 24 and Tagoram. 25 They utilize physical layer information to compute the propagation delay of the straight path, eliminating the adverse effect of multi-path and yielding sub-meter distance estimation accuracy. The adopted wireless technologies are WiFi or radio frequency identification (RFID). Although CSI is a better choice for distance estimation in many scenarios, it is hard to be extracted for low-cost sensors.
Considering that RSS can indeed provide more than just connectivity information among neighboring node pairs, but also other useful distance information, this article fully extracts the proximity information from the neighbors’ RSS and presents a novel method of quantifying the distance among neighbors. The design can effectively improve the system accuracy with little extra cost.
Motivation
Our work is motivated by one of outdoor experiments. We have ever constructed a two-dimensional grid network with a

RSS versus distance.
In view of this, we change the observation method of RSS values. From the viewpoint of a single node, there is another phenomenon. Figure 2 depicts the line charts recording all RSS values from a single node to the rest of other nodes in sequence, which is denoted as RSS change trend. Then, we attempt to compare the distinction of RSS change trends between closer node pair (nodes 1 and 2) and farther node pair (nodes 1 and 8). As shown in Figure 2, node 1 and node 2 almost have the similar RSS change trend, while there exist many inverse trends of RSS values for node 1 and node 8. This intuitive phenomenon inspires us to further extract the distance relationship behind the RSS change trend, and the latter simulations and experiments will verify the effectiveness of proposed design.

RSS change trend among closer and farther node pairs: (a) RSS change trend of nodes 1 and 2 and (b) RSS change trend of nodes 1 and 8.
System design
The whole system design is shown in Figure 3. Based on the RSS values collected from physical layer, this section first presents the main design of quantifying the near-far relationship among neighboring nodes. Next, an integral approach is designed to accumulate relative distances among multi-hop node pairs. Then, the section describes the construction process of relative map of the whole network. Finally, the converting procedure of the physical coordinates is given in the last part.
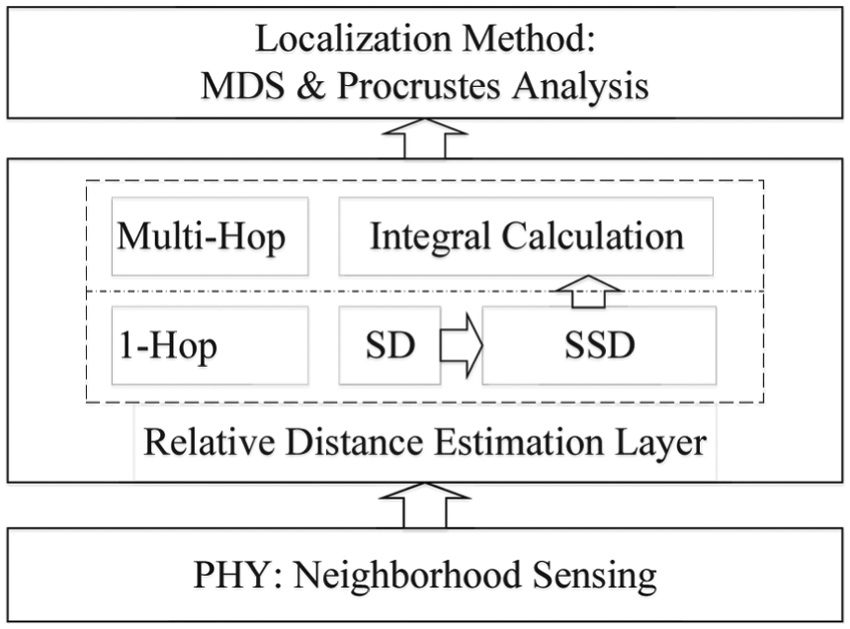
The localization system architecture.
Relative distance quantization
Sequential distance estimation
Without loss of generality, we can evaluate the near-far relationship of neighboring nodes
In order to illustrate our design, we give a simple example in Figure 4, in which the problem is to evaluate the distance between

An example of relative distance quantization.
RSS values from all their neighbors (dBm).

Now we classify the neighbor pairs of nodes
Next the distance estimation between nodes
Definition 1
The sequential distance (SD) between two neighboring nodes is equal to the ratio between the number of discordant pairs and the number of effective neighbor pairs, namely

Taking
We use the ratio of unordered neighbor pairs for evaluating the node distance. SD reflects a relation that the more inverse RSS change trends two neighbor nodes have, the farther away these two nodes are, which accords with the phenomenon mentioned above. In addition, we can also learn from the example above that the SD between a neighboring node pair can be obtained through
Furthermore, we explore the hidden geometrical relationship behind equation (1). We consider any two neighboring nodes and draw a perpendicular bisector to the line connecting their positions. This perpendicular bisector divides the localization space into two different regions that are distinguished by their proximity to either neighboring node. In the same way, if perpendicular bisectors are drawn for all the

Nodes with bisectors.
Signal-based signature distance estimation
In the above analysis, we only consider the change trend of RSS. However, the RSS values can also inflect the distance between two nodes, especially in the outdoor open-air scenarios. Next, we further introduce the differences of neighbor RSS values into the relative distance estimation.
For nodes

Note that in equation (2), the RSS differences are used to estimate the distance instead of RSS values, which can in part eliminate the effect of the environment factor and is more robust. Based on the SD and difference-based distance, we propose a signal-based signature distance (SSD) for relative distance between one-hop neighboring nodes.
Definition 2
SSD between a one-hop node pair is equal to the product of the SD and a polynomial based on the difference-based distance, which is shown as follows
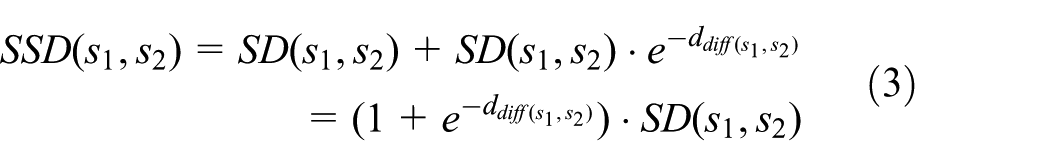
From equation (3), it can be seen that SSD combines the ideas of RSS differences (
The rational behind the equation is that we employ the RSS differences to correct the SD. Since the values of RSS differences are relative large, directly integrating them into the SD will bring extra errors. Hence, we adopt the widely used exponential form to construct a new distance metric. Thus, the distance is jointly determined by the sequence of neighbor nodes, as well as the RSS difference of one node itself.
SSD integral calculation
In last subsection, we start from the concepts of neighboring node pairs and their RSS change trends and then quantify the SD and propose SSD based on comparison of RSS values and RSS differences. However, SD and SSD can only reflect the near-far relationship between two neighboring nodes. As for non-neighboring node pairs, there will be a exploration about an existing approach, as well as an introduction of an integral method for calculation of relative distances between two non-neighbor nodes.
The existing design of regulated signature distance (RSD)
26
uses the smallest accumulated RSD along a path between two nodes instead of the shortest path hop-count as the estimated relative distance. If we draw on the experience of RSD, the relative distance between two non-neighbor nodes is the addition of SSD along the shortest path from one node to the other. Taking Figure 6(a) as an example, the relative distance between

Relative distance with (a) 2-hop and (b) multi-hop node pairs.
However, it is widely known that the sum of two sides is greater than third side in a triangle. Thus, directly treating the third side as a relative distance instead of accumulated RSD can cut down the cumulative errors. Under this circumstance, the only requirement is the angle

where

Two extreme cases: (a) α = 60° and (b) α = 180°.
As for multi-hop (hop > 2) through two unconnected nodes, we adopt an iterative method for estimating the relative distance. The iterative procedure first arranges the SSD values of each hop along the shortest path in sequence. Second, equation (4) calculates the first two SSD values, and its result together with the next SSD value is the initial input of the following iteration. Third, repeating the second step until the final SSD has been involved in calculation. Figure 6(b) illustrates an iteration procedure for a three-hop node pair
Physical coordinate generation
Given the relative distances between any two nodes, we can construct their relative map and further obtain physical coordinates when more than three anchors’ positions are known.
Relative map construction
This recreation process is exactly the MDS
9
method. Intuitively, it is obvious that the
First, a symmetric relative distance matrix

MDS assumes that all coordinates are at the origin, so that relative coordinates can be obtained from relative distance information only through linear transformation. First, converting

Third, using singular value decomposition, it yields that

where V is an orthogonal matrix whose column vectors are eigenvectors, and
Procrustes analysis
Procrustes analysis
27
determines a linear transformation (translation, reflection, orthogonal rotation, and scaling) of the points in the relative map matrix of anchors to best conform them to the points in the real-position matrix of anchors. As a result, Procrustes analysis outcomes a structure
The matrix Y is calculated with the following equation, which represents the estimated physical coordinates among all unknown nodes

Simulation
In this section, we evaluate the localization performance of our design over the following aspects: first of all, the correlation between relative distance and physical distance; then the localization performances; moreover, the statistical comparison on maximum, minimum, and mean errors with existing localization methods.
Simulation configurations
As illustrated in Figure 8, an irregular WSN is modeled in a square area without any obstacle like ‘holes,’ where radio signals can broadcast to anywhere within communication areas. Figure 8(a) presents the network layout. Figure 8(b) shows the connectivity graph of the whole network, where each one-hop link is painted as a line segment. As shown in Table 2, there lists the default simulation configurations for this whole section.

Simulation setup: (a) network layout and (b) connectivity.
Default configurations.

RSS: received signal strength.
It can be seen from Table 2 that the widely used logarithmic attenuation model 28 is applied for RSS sensing
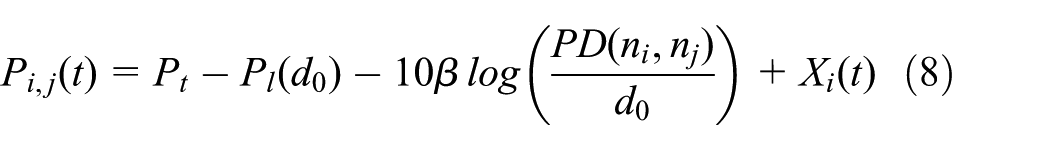
At time instance
Distance correlation
For either traditional hop-based distance or SSD, the correlation coefficient between their values and physical distances is a significant index to judge the validity of regarding them as relative distance.
Figure 9 illustrates the distance correlations among hop-count, SSD, and physical distance, and correlation coefficient

Distance correlation comparison: hop versus SSD: (a) hops versus distances within 1-hop, (b) SSD versus distances within 1-hop, (c) hops versus distances among multi-hops, and (d) SSD versus distances among multi-hops.
Figure 9(c) and (d) plots all the node pairs (including one-hop and multi-hop node pairs) with their hop distance, SSD, and physical distance. Figure 9(c) represents that there are only discrete integer hop distances among node pairs. Figure 9(d), meanwhile, indicates that physical distances can be mapped to continuous values, which may nicely avoid the ambiguity problem in the following localization process. Furthermore, these values of correlation coefficients verify the effectiveness of taking SSD as relative distance rather than hop-based distance.
Localization performance
The effectiveness of our design is evaluated by comparing the localization graphs and the localization errors with other three classical localization schemes. We use the terminology “DV-Hop” and “multidimensional scaling-hop (MDS-Hop)” for the original hop-based approaches, “multidimensional scaling-regulated signature distance (MDS-RSD)” for corresponding MDS method where the relative distance turns to RSD instead of shortest path hops, and “multidimensional scaling-signal based signature distance (MDS-SSD)” for the newly designed method. Special note is that in the simulations, errors are defined as offsets of Euclidean distances between expected nodes coordinates and real nodes coordinates.
Let us first look at these four localization graphs from Figure 10. Under the default configuration parameters, Figure 10 plots the localization results of our method “MDS-SSD” and other three compared algorithms. In all sub-figures, the line segments are plotted starting from nodes real positions, and pointing to the corresponding estimated positions. These four sub-figures can be treated as two groups. Namely, localization methods are driven from hop-count distance (DV-Hop and MDS-Hop) and relative distance (MDS-RSD and MDS-SSD).

Localization results of four algorithms: (a) DV-Hop, (b) MDS-Hop, (c) MDS-RSD, and (d) MDS-SSD.
It is obvious that for two approaches based on hop-count distance, there are many more long black line segments than other two methods. In addition, many nodes are located to identical estimated positions, which means discrete integer mapping of hop distances mentioned by last subsection can really lead to clustering mapping in localization process. On the contrary, as shown in Figure 10(c) and (d), the latter two methods effectively reduce the ambiguity problems because that continuous mapping of relative distances may capture tiny distinction of distances with the same one-hop. The results confirm that relative distances can offer a unique sub-hop resolution while hop distances cannot. In addition, all error statistics of above four sub-figures are listed in Table 3. It can be observed that MDS-SSD achieves better localization accuracy than other three methods. Specially, MDS-SSD shows slight superiority than MDS-RSD, which owes to the combination idea of RSS comparison and RSS difference, while RSD only takes the former factor as consideration.
Localization errors of four algorithms (in feet).

DV-Hop : distance vector-hop.
For the purpose to eliminate the possible bias caused by anchor selection, we increase the number of anchors from 4 to 10 in step of 1 for the network in Figure 8, whereas other system configurations remain invariant. All the statistics reported are averaged over 500 runs, and each run picks anchor nodes randomly. Figure 11(a)–(c) shows the maximum, minimum, and mean errors, respectively. As expected, the localization errors decrease with the increasing of anchor numbers for all methods. From Figure 11, we can give three remarks:
Two dashed curves are lower than two solid curves, meaning that relative distances rather than hop distances can help improve the localization accuracy. Just as mentioned above, hop distances are mapped to discrete integers, which enlarges the deviation in localization.
The novel introduced SSD method shows the best localization performance as the errors are smallest among three sub-figures.
SSD method achieves approximately 61%, 37%, and 29% performance gain by average compared with DV-Hop, MDS-Hop, and MDS-RSD, respectively.

Localization errors with different numbers of anchors: (a) maximum error, (b) minimum error, and (c) mean error.
Experiments
In this section, we conduct two types of outdoor test-bed experiments: a linear network and a grid network, respectively, with 25 sensor nodes. 29
Experiment I: linear network
Experiment setup
Figure 12 includes a sketch map of experiment scene of the linear network and a partial in-field view. There are 25 motes deployed with the whole length of 420 ft on a side of playground, and each node is apart about 16 ft from next one.
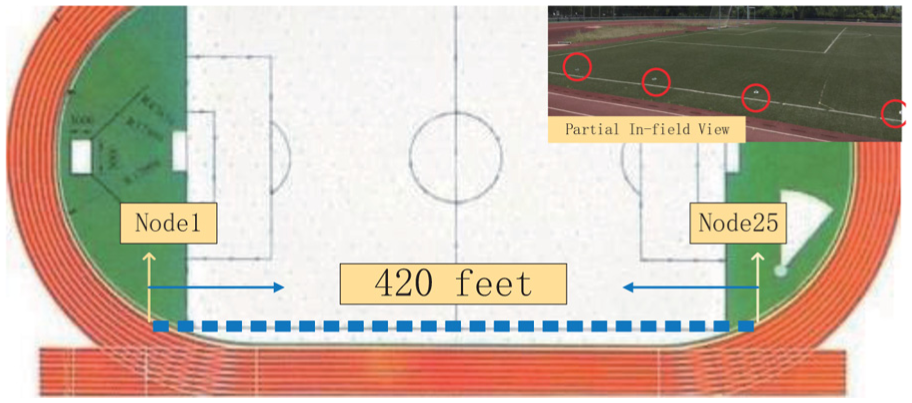
Diagrammatic sketch of experiment I: linear network.
Every node in this experiment broadcasts 100 sets of packets to the entire sensor network at the sending power of 0 dBm. After receiving several packets containing the information of node ID, RSS values and identifiers of the packets from other sensor nodes will be stored. The receiving nodes will store them in flash memory and upload them to the data platform when broadcasting has accomplished. We collect the RSS values from all the nodes and process them in the MATLAB.
In our experiments, the threshold of RSS value is regarded as −100 dBm. Namely, if the RSS value in the received packet is less than −100 dBm, the two nodes (the sender and the receiver) are considered to be non-connected and the packet can be decoded incorrectly. In other words, if the RSS value in the received packet is greater than −100 dBm, the two nodes are considered as a neighboring node pair, and then relative distance between them can be quantified through the proposed metric.
Localization performance
With four randomly picked anchors, Figure 13 shows the localization results from MDS-Hop and MDS-SSD in linear network. The dots depict sensor nodes’ real positions, and the segments are pointed to their corresponding estimated positions from real ones. Obviously, MDS-SSD has better localization performance than MDS-Hop as the segments in Figure 13(b) are much shorter than that in Figure 13(a). However, considering the singularity issues in matrix decomposition, 26 it is not difficult to understand that MDS-Hop is not stable for linear or close-to-linear networks. In addition, hop-based distances may cause ambiguity problems in MDS-Hop while MDS-SSD can reduce that as far as possible.

Localization results of (a) MDS-Hop and (b) MDS-SSD methods.
Experiment II: grid network
Experiment setup
Figure 14(a) shows the outdoor experiment scenario with 25 sensor nodes. They are deployed in a
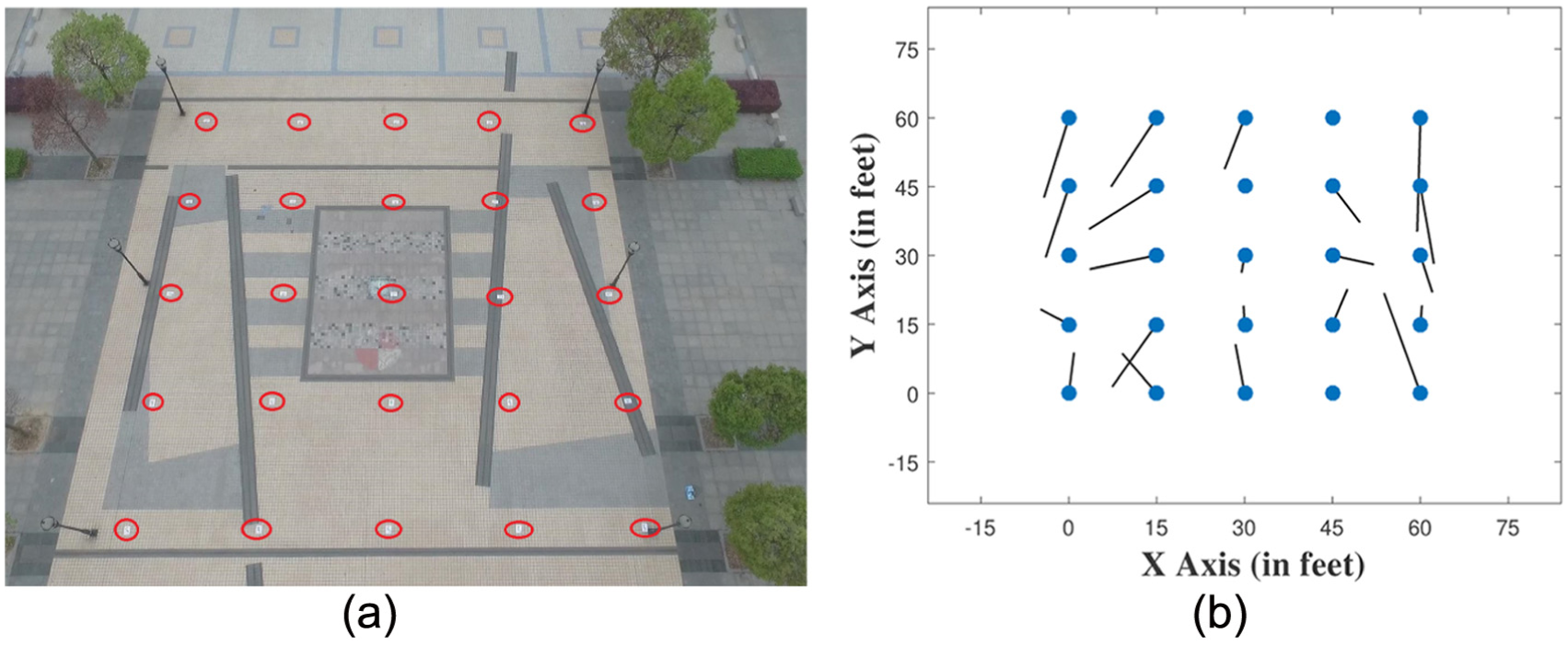
Experiment: regular 2D network: (a) node deployment and (b) localization graph.
Localization performance
Figure 14(b) displays the localization result from the experiment with four randomly selected anchors in the network. The blue dots record the real locations of all nodes, and the black line segments are directing to the estimated positions. From the collected data, we can obtain that the localization error is about 7.9 ft averagely.
Conclusion
This article first introduces a new metric for relative distance estimation by comparing their RSS values. According to the remark from triangle cosine theorem, a novel integral approach is applied to replacing the accumulate relative distance, which finally forms SSD. Second, we describe the specific process of node localization based on MDS method. Extensive simulations and outdoor experiment are carried out to evaluate the system effectiveness from several aspects. And the results demonstrate that SSD helps improve the localization accuracy.
Footnotes
Handling Editor: Suparna De
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported, in part, by the Fundamental Research Funds for the Central Universities (grant no. 2017XKQY080).